
基于人体骨骼关键点的吸烟行为检测算法
2022-01-05 02:32徐婉晴王保栋黄艺美李金屏
计算机应用 2021年12期
徐婉晴,王保栋,黄艺美,李金屏*
(1.济南大学信息科学与工程学院,济南 250022;2.山东省网络环境智能计算技术重点实验室(济南大学),济南 250022;3.山东省“十三五”高校信息处理与认知计算重点实验室(济南大学),济南 250022)
(∗通信作者电子邮箱ise_lijp@ujn.edu.cn)
0 引言
吸烟严重危害人类的身体健康,并且在公共场所吸烟存在很多潜在的危害,不少研究者采用不同方法对吸烟行为展开研究[1-4]。目前关于吸烟行为的计算机视觉检测算法主要是利用深度学习模型对烟头、烟雾、人脸进行检测,进而判断出吸烟行为[1-2]。尽管深度学习对图像数据特征都有着很好的非线性学习能力,但是需要大量且多样的数据集进行训练,并且当人物处于复杂环境时,识别难度会增加。仅利用目标检测的方法识别吸烟行为忽略了吸烟行为与吸烟者肢体动作之间的关系。一些学者在研究过程中将目标检测算法和动作识别算法进行了结合来检测吸烟行为,例如文献[3]中针对出租车司机设计了一种采用支持向量机(Support Vector Machine,SVM)对吸烟烟雾特征和抖烟动作特征进行建模和分类来检测吸烟行为的方法,由于出租车会挡住司机的吸烟动作,所以只能检测司机的抖烟动作以及飘出窗外的烟雾。文献[4]中利用帧差法与肤色检测法首先判断出人物手部运动轨迹,排除非吸烟行为,然后提取手部区域图像,使用颜色特征检测烟头。该方法的检测思路是先筛选出疑似吸烟行为,较大提升了算法的运算效率;但方法对于手部运动轨迹的判断较为粗糙,难以应对复杂场景中的干扰。
人体动作与骨骼关键点之间存在着十分密切的联系,并且随着人体姿态估计算法的发展[5-7],人体骨骼关键点定位的准确性也越来越高。已有学者利用人体的关键点进行吸烟行为的识别,如文献[8]中提出了一种基于人体关节点的吸烟行为识别方法,可检测多人场景中的吸烟行为,然而只能识别符合一定周期性的吸烟过程。
本文结合人体骨骼关键点信息与目标检测算法提出了一种吸烟行为检测算法,利用左手腕、右手腕、左眼睛、右眼睛、左嘴角、右嘴角共6 个关键点,计算出手腕到两嘴角中点的距离和手腕到同侧眼睛的距离,得出这两个距离的比值——吸烟动作比例(Smoking Action Ratio,SAR)。经过大量实验发现,SAR 值呈现出规律性,当人物存在吸烟动作时,SAR 总是集中在某一范围内,将人物存在吸烟动作时的SAR 命名为吸烟动作黄金比例(Golden Ratio of Smoking Action,GRSA),即判定为吸烟动作的最佳SAR 比例,与其他动作可以较好地区分。
本文主要工作是:
1)利用人体骨骼关键点(手腕、嘴角、眼睛)的位置关系,提出SAR 的计算方法,设定判别规则以检测吸烟行为,即人物的SAR是否处于当前环境下的GRSA。
2)利用YOLOv4检测视频中是否存在烟头,并结合GRSA和YOLOv4 算法对烟头的检测来确定吸烟行为的可能性高低,设定阈值得到吸烟行为的最终判定结果。
3)针对不同场景不同人员的吸烟行为进行检测,对比了单独使用YOLOv4、单独使用GRSA 方法以及将YOLOv4 和GRSA结合的实验结果,验证本文算法的有效性和可行性。
1 算法设计及模型原理
本文的算法流程如图1 所示。首先利用AlphaPose 模型检测出左右手腕关键点,利用RetinaFace 模型检测出左右眼睛和左右嘴角关键点,获得其坐标值。接着根据关键点的坐标可计算出SAR 值,与当前环境下的GRSA 比较,记录SAR 属于GRSA 的持续时间t,将t与阈值T比较,作出是否属于GRSA 的判定;同时,利用YOLOv4 模型作出是否存在烟头的判定。由这两个判定依据按照设定的规则得到吸烟行为可能性等级。
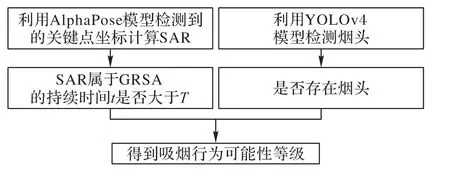
图1 本文算法流程Fig.1 Flowchart of the proposed algorithm
1.1 AlphaPose骨骼关键点检测模型
AlphaPose 是一个多人姿态估计的开源系统,在MSCOCO数据集上的平均精度均值(mean Average Precision,mAP)达到61.8%,在MPII 数据集上的mAP 达到76.7%[9]。该系统使用的是区域多人姿态估计(Regional Multi-Person Pose Estimation,RMPE)框架,见图2。RMPE 在原有的单人姿态估计模块(Single-Person Pose Estimator,SPPE)上增加了对称空间变换网络(Symmetric Space Transformation Network,SSTN)、由姿态引导的样本生成器(Pose-Guided Proposals Generator,PGPG)、姿态非极大值抑制器(Parametric Pose Non-Maximum Suppression,PPNMS)三个模块。SPPE 是针对单人图像进行训练的,而且对定位错误十分敏感,因此RMPE 引入SSTN 和平行的SPPE 来增强SPPE 的效果。SSTN 是由空间转换器网络(Spatial Transformer Network,STN)和空间去转换器网络(Spatial De-Transformer Network,SDTN)组成的,被分别放在SPPE的前、后,由STN获取人体样本,由SDTN产生姿态样本。Parallel SPPE 在训练部分作为一个额外的调节器,以避免局部最小值。最后的PPNMS 是为了消除冗余姿态估计。PGPG的作用是为了增加现有的训练样本。根据文献[9]在COCO和MPII 数据集上对多种骨骼检测模型进行的对比结果,本文采用效果较好的AlphaPose检测视频中的人体目标,得到人体的各个骨骼关键点在该帧图像中的(x,y)坐标,用到其中的左手腕、右手腕2 个关键点。AlphaPose 骨骼关键点检测效果如图2所示。
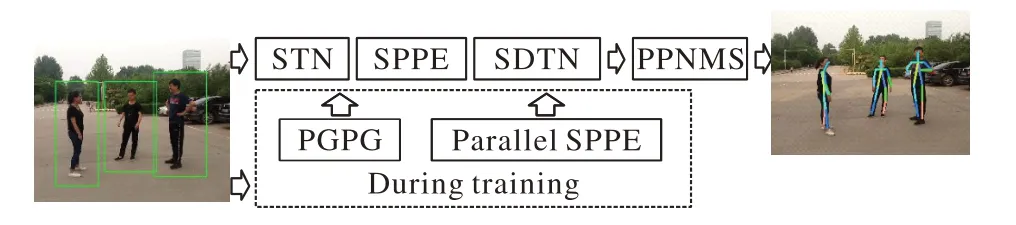
图2 RMPE框架的流程Fig.2 Flowchart of RMPE framework
1.2 RetinaFace 人脸检测模型
对现有的人脸检测算法[10-15]进行研究发现,RetinaFace 模型可以较好地应用于本文的吸烟检测问题。RetinaFace 是一种单级人脸检测算法,利用多任务联合额外监督学习和自监督学习的优点,可以对不同尺度的人脸进行像素级定位[15]。该算法是基于特征金字塔设计的,在主干网络的选择上使用了轻量级网络MobileNet,具有独立的上下文模块。根据上下文模块计算多任务损失函数,RetinaFace 可以在单个CPU 上实时运行完成多尺度的人脸检测、人脸对齐、像素级人脸分析和人脸密集关键点三维分析任务,可同时输出人脸框和5 个人脸关键点信息。本文用到其中的4 个关键点,分别是:左眼睛、右眼睛、左嘴角、右嘴角。RetinaFace 人脸检测效果如图3所示。

图3 人脸检测效果Fig.3 Detection effect of face
1.3 基于人体骨骼关键点的吸烟动作分析
1.3.1 思路分析
当人物有吸烟行为时,最显著的特征是手部十分靠近嘴部,而手部靠近嘴部的行为,也可能出现于喝水、挠头、扶眼镜时。基于人体骨骼关键点信息判定吸烟行为的关键就在于如何利用关键点之间的位置信息将吸烟行为与其他行为良好地区分开。考虑到若计算手部到嘴部的距离,当距离较小时,有可能是吸烟行为,但是由于视频中人物大小不确定导致阈值难以确定;若是在手部和嘴部关键点附近设定一个区域范围,当两个区域有重合时,计算交并比,存在的问题是设定多大的区域范围仍然难以确定;因此本文采用比值的方法去除量纲,解决了阈值难以确定的问题。利用(右/左)手腕部到嘴部的距离d1与(右/左)手腕部到(右/左)眼睛的距离d2的比值(如图4 所示),即SAR。SAR 的分母是手腕到眼睛的距离d2而不用手腕到其他部位的距离,主要是考虑到眼睛和嘴巴总是会处于同一个平面,当人侧身面对摄像头的时候,有一定的鲁棒性,并且不同人的手的大小和五官之间的距离相差不会太大,相对于身高更有普遍性。

图4 吸烟动作比例示意图Fig.4 Schematic diagram of SAR
1.3.2 数据处理
通过AlphaPose 和RetinaFace 得到6 个关键点的坐标,坐标以图像左上角为原点,如图5所示。
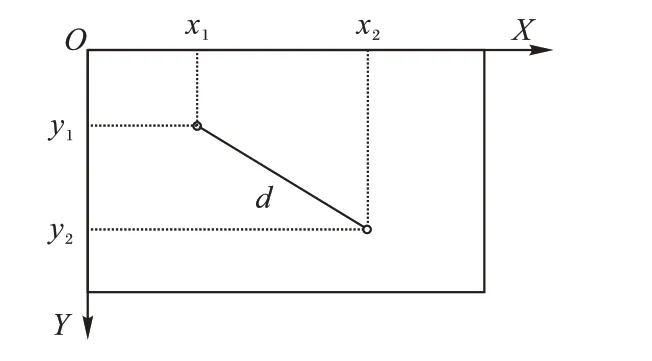
图5 以图像左上角为原点的坐标系Fig.5 Coordinate system with top left corner of image as origin
根据式(1)可计算出手腕到嘴巴的欧氏距离d1和手腕到眼睛的欧氏距离d2,由式(2)得到SAR值,即SAR。若由于关键点检测不准确或手腕与眼睛重合等原因导致d2的值为0,则令d2=1。
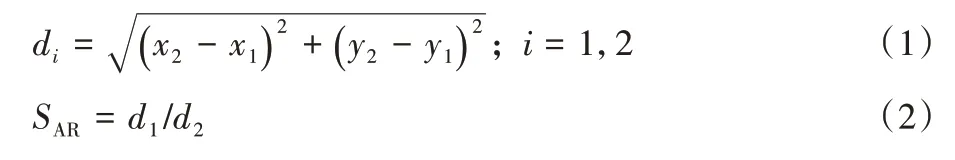
对视频进行逐帧处理,以视频当前帧数序列为X轴,以SAR 值序列为Y轴,画出实时曲线图。如图6 所示,点线代表的是左手腕的SAR 值,虚线代表的是右手腕的SAR 值,两条黑色实线之间代表当前环境下的GRSA 范围。图6(b)中标注的框1 对应图6(a)中的抽烟动作,框2 对应的是图6(a)中的扶眼镜动作。由于扶眼镜动作和抽烟动作之间的间隔动作序列含有的信息量很少,所以没有展示出来。两种动作均选取了关键帧以展示动作过程,图7、8 类似。图7(b)中框3 对应的是图7(a)中的左臂自然下垂,右臂晃动水杯的动作,框4对应的是图7(a)中喝水动作的过程,框5对应的是图7中检测不到某些关键点因而显示异常值的情况;图8(b)中框6 对应的是图8(a)中的挠头的动作。从实验中发现,本文的GRSA 吸烟检测算法可以较好地区分吸烟动作和非吸烟动作。

图6 吸烟动作和扶眼镜动作及其对应的SAR值Fig.6 Smoking and glasses-holding behaviors and their corresponding SARs
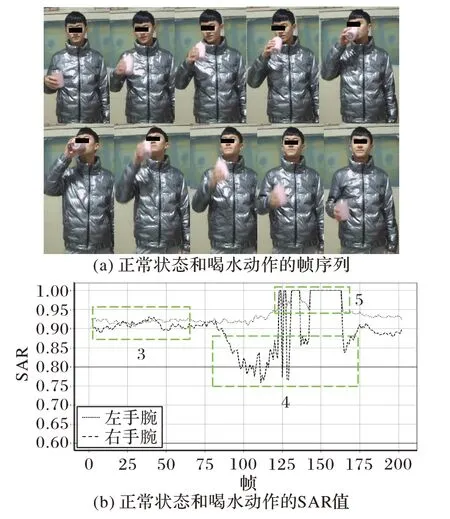
图7 正常状态和喝水动作及其对应的SAR值Fig.7 Normal condition and drinking water behaviors and their corresponding SARs

图8 挠头动作及其对应的SARFig.8 Scratching head behavior and its corresponding SAR
1.4 基于YOLOv4模型的烟头检测
YOLOv4 是一个简单且高效的目标检测算法,该算法在YOLOv3 的基础上,从各个方面引入一些优化方法[16]。其中训练时采用Mosaic 数据增强方法、跨小批量标准化CmBN(Cross mini-Batch Normalization)和自对抗训练SAT(Self-Adversarial-Training),保留了YOLOv3 的 head 部分,CSPDarknet53 作为主干网络,并使用Mish 激活函数和Dropblock 丢弃方式,同时Neck 结构采用了SPP(Spatial Pyramid Pooling)模块、FPN+PAN(Feature Pyramid Network+Path Aggregation Network)的方式。输出层的锚框机制和YOLOv3 相同,主要改进的是训练时的损失函数,采用CIOU_Loss 回归方式,以及预测框筛选方式由NMS(Non Maximum Suppression)变为DIOU_nms。基于YOLOv3 的改进使得YOLOv4 模型在检测速度和精度上达到了目前为止的最优匹配。本文利用YOLOv4 算法对4 900 张吸烟图片进行训练和测试,在GRSA 吸烟检测算法的基础上进一步提高吸烟行为检测的准确率。烟头检测效果如图8 所示,图中“smoke”表示检测到烟头,“smoke”后面的数字“0.97”表示置信率。通过实验测试发现,YOLOv4 在检测烟头的问题中有较好的效果,其准确率信息在表4中给出。
1.5 吸烟行为的判定
将视频中人物的SAR 属于GRSA 的持续时间t大于T作为判据一,将YOLOv4 是否检测到烟头作为判据二,通过这两个判据得出吸烟行为可能性高低。本文中,判据一所占的权重设置为60%,判据二所占的权重设置为40%。当SAR 属于GRSA 的持续时间t>T,且YOLOv4 检测到烟头,则吸烟行为可能性用概率可以表示为100%。依此类推,当满足判据一不满足判据二时,吸烟行为可能性用概率表示为60%;当不满足判据一而满足判据二时,吸烟行为可能性用概率表示为40%;当判据一和判据二均不满足时,吸烟行为可能性用概率表示为0%。为了公共场所的安全考虑,吸烟行为可能性若大于等于40%,则判定为存在吸烟行为,见表1。本文进行实验时,将视频以20 帧/s 进行提取,当SAR 属于GRSA 的图像大于15帧时,认为满足条件,相当于T取值为0.75 s。

图9 烟头检测效果图Fig.9 Cigarette butt detection effect diagram

表1 吸烟行为判定方法Tab.1 Method for judging smoking behavior
2 实验与分析
2.1 实验环境与数据集
实验运行环境为Python3.7 和Pytorch 1.5,硬件平台使用的GPU 为2080Ti,内存为32 GB。由于目前没有公开的关于吸烟视频的数据集,为了验证本文所提出算法的合理性与有效性,录制了300 个视频片段,每个片段约30 s,其中包含室内、室外不同环境下不同人物的不同动作,见表2。混合各种动作的视频除了包括吸烟、喝水、挠头的动作,还有其他一些例如挥手、拍手、弯腰等可以明显区分于吸烟的动作。视频可根据摄像头和人脸的相对高度分为两类,一类是摄像头和人脸大致处于同一水平线高度,另一类是摄像头处于人脸斜上方约45°。YOLOv4 中使用的数据集来源于网络上的吸烟图片和非吸烟图片,其中训练集包含4 410 张,测试集490 张,数据标注使用的是labelimg图像标注软件。

表2 不同视频类别及数目统计Tab.2 Statistics of different video categories and their numbers
2.2 实验评价标准介绍
根据本文算法中设定的判定规则,可知当吸烟行为可能性为中等、较高、高时,判定为吸烟行为;当吸烟行为可能性为低时,判定为非吸烟行为。在本文中,使用查准率P、查全率R两个指标评估算法的分类效果。查准率和查全率根据式(3)和(4)计算。

其中:a表示判定正确的吸烟行为的样本数量,b表示非吸烟行为被判定为吸烟行为的样本数量,c表示吸烟行为被判定为非吸烟行为的样本数量。
2.3 实验结果分析
2.3.1 阈值分析
为确定GRSA 的最佳取值,通过拍摄的吸烟视频测试,得到以下测试结果,如表3(加粗数字表示最佳性能),用标准①~⑥表示实验中GRSA 所设定的范围。当人脸和摄像头大致处于同一水平高度时,标准①的查全率最高,可以应用于对于吸烟把控非常严格的场所,但其对应的查准率太低;标准③对应的查准率最高,但其查全率在80%左右,会漏掉很多吸烟行为。相比之下,标准②将[0.6,0.8]设置为GRSA 来判定吸烟行为的效果最好,查准率对应92.8%,查全率对应92.4%。同样,当摄像头处于人脸斜上方大约45°的情况时,采用标准⑤将[0.55,0.75]设置为GRSA 来判定吸烟行为的效果最好,查准率对应91.3%,查全率对应93.2%。

表3 GRSA取值标准分析Tab.3 Analysis of GRSA value standard
2.3.2 与目标检测算法的对比
将利用GRSA 的方法和YOLOv4 算法检测烟头的方法进行结合可以有效提升吸烟行为的准确性。例如,当烟头较小、烟头的颜色与背景相似、光照强烈等因素导致烟头难以被检测到时,仅使用YOLOv4 目标检测算法检测到吸烟行为的比例较低。此时,利用GRSA 的方法可以有效检测到吸烟行为,如图10(a)和10(b)框2所示。当视频中人物有短暂的吸烟动作,即持续时间不超过T时,YOLOv4 若准确检测到烟头就可提升一定的准确率,如图10(b)框1 所示。将本文设计的GRSA与YOLOv4目标检测算法作对比,见表4(加粗数字表示最佳性能)。当摄像头处于人脸斜上方时,使用YOLOv4 检测烟头的方法稍好一些。由表中数据可知,将YOLOv4与GRSA结合起来对于吸烟行为检测效果有显著的提升。

图10 两种方法结合效果展示Fig.10 Combination effect of two methods

表4 不同算法效果对比Tab.4 Effect comparison of different algorithms
3 结语
本文结合姿态估计算法,通过对手部和脸部关键点的坐标信息进行处理,分析出吸烟行为与吸烟者肢体动作的潜在关系,能够准确检测到吸烟行为,扩大了吸烟检测算法的适用范围。本文提出的吸烟行为检测算法还有不足之处:
1)受制于人体姿态估计算法的准确性,因此对于低质量的图像或视频效果并不好;
2)算法目前对于检测人体正面的吸烟行为有较高的准确率,然而当摄像头处于人体侧面不同角度时,准确率会有所下降,因为嘴部极有可能被手部遮挡;并且在嘴部未被遮挡的情况下,GRSA 的范围需要有所调整。因此GRSA 吸烟检测算法中阈值的自适应设定将作为下一步的工作。
猜你喜欢
建材发展导向(2022年3期)2022-04-19
建材发展导向(2022年2期)2022-03-08
当代陕西(2019年20期)2019-11-25
环球时报(2019-10-24)2019-10-24
做人与处世(2018年9期)2018-06-25
广东教育·高中(2017年10期)2017-11-07
环球人物(2017年16期)2017-08-30
恋爱婚姻家庭(2015年27期)2015-12-19
新高考·高一物理(2015年5期)2015-08-18
恋爱婚姻家庭·养生版(2015年9期)2015-05-14
