
基于PCA-OS-ELM的大气PM2.5浓度预测
2022-01-13 08:47李济瀚李晓理王康崔桂梅
北京理工大学学报 2021年12期
李济瀚, 李晓理,2, 王康, 崔桂梅
(1.北京工业大学 信息学部,北京 100124;2.北京市计算智能与智能系统重点实验室, 教育部数字社区工程研究中心,北京 100124; 3.内蒙古科技大学 信息工程学院, 内蒙古,包头 014010)
随着环境被不断地破坏,大气污染颗粒物逐渐成为我国主要的监测指标. 如一氧化碳(CO)、二氧化碳(CO2)、二氧化硫(SO2)、臭氧(O3)和颗粒物(PM2.5和PM10)[1-2]. 而其中细颗粒物PM2.5是重金属污染物,对人类健康和出行构成了巨大的威胁[3-4]. PM2.5的形成受到多方面因素影响,如湿度、风速、温度、降雨等因素的影响. 因此,预测PM2.5浓度是一种典型的高纬度数据,很容易会出现冗余的数据. 所以需要提取有效的变量,然后再进行预测.
为了对空气污染的监测与预判,近些年不少学者也针对污染问题也开展了一系列的研究. WU等[5]利用改进的神经网络预测模型对武汉市区PM10的空气指标进行预测. 预测结果证明改进的神经网络模型预测精度更高. POLEZER等[6]分别采用3种人工神经网络模型研究空气污染对人类健康的影响,该方法证明PM2.5对呼吸系统疾病入院的人影响较大. VLACHOGIANNI等[7]以污染物(NO、NO2、NOx、CO、O3、PM2.5和PM10)的小时浓度和气象变量(环境温度、风速/风向和相对湿度)作为多元线性回归(MLR)模型的输入变量对雅典和赫尔辛基的NOx和PM10预测. 该方法更好地将多种污染物考虑进去,使模型预测更加准确. KUMAR等[8]采用自回归滑动平均模型预测日平均环境空气污染物(O3、CO、NO和NO2)浓度. 该方法针对污染物时间序列特点建立模型提高了预测污染物的浓度. PAN 等[9]利用灰色动态模型研究了天津市空气质量的变化趋势. 拟合结果表明该种模型在短期内对空气质量预测具有较高预测精度. DE RIDDER等[10]给出了一种卡尔曼滤波方法以确定性修正空气质量预测结果. 该方法通过确定性预报与前期观测值不匹配的信息,计算下一步预报的修正回归系数,从而实现每日O3和PM10浓度场模拟,提高了O3和PM10浓度的准确性.
上述研究方法往往只考虑如何提高模型的预测精度,很少考虑到模型的计算速度,导致模型预测时间过长. 在保证预测模型稳定和准确的前提下,为了减少模型运算时间,提高PM2.5浓度预测速度,本文提出了一种基于主元成分分析与在线序列极限学习机相结合(PCA-OS-ELM)方法[11-15]. 该方法是在传统神经网络基础上改进的一种前馈网络,广泛应用于故障诊断[16]、流量监测[17]、视觉跟踪[18]、风电[19]等领域. 它只需要确定隐含层个数就可以对网络进行训练,通过不同批次训练数据不断更新模型参数. 与传统BP神经网络相比,该方法计算量小,效率高泛化能力强. 文本将PCA-OS-ELM方法应用于大气PM2.5浓度预测中. 研究结果表明该方法所建立的PM2.5浓度预测模型不仅预测精度高,稳定性强,而且大大减少了模型的运算时间,提高了PM2.5浓度预测的速度,具有较好的实用性.
1 数据收集及特征提取
北京市是一个四季分明的城市. 因此,为了评估所提方法预测PM2.5浓度的准确性. 选取2018年6—7月之间采集的PM10、PM2.5、SO2、NO2、CO、O3、温度、湿度历史数据作为研究对象. 基于图1显示的大气监测设备平台对所提方法进行验证.
图1 北京市某校园965监测设备点Fig.1 965 monitoring equipment of a campus in Beijing
大气污染监测过程中由于影响大气变化因素较多,因此,本文通过PCA的方法对采集到的变量进行提取的过程为:首先通过采集的污染气体PM10、PM2.5、NO2、SO2、O3及气象条件(温度、湿度)的时间序列为样本. 其观测的数据矩阵如下式所示
(1)
式中:n为监测的样本数;p为监测的指标;x11,x12,…,xn1为样本数据中PM10、PM2.5、NO2、SO2、O3及气象条件(温度,湿度)的时间序列. 由于不同的采集样本量纲不一致,因此需要对采集的数据进行标准化处理并计算标准化后的相关系数矩阵,其计算公式如下所示
(2)

R=(rij)p×p
然后通过求出矩阵R的特征值(λ1,λ2…λp)和相应的特征向量(αj1,αj2,…αjp). 其主成分表达式为
Zi=αj1X1+αj2X2+…αjpXp,
i,j=1,2,…p,i≠j
(3)
式中:Zi为第p个主成分;X1~Xp=xi1~xip. 然后通过计算主成分的贡献率和累计贡献率来判定哪些变量因素对污染起着主要的作用. 其公式如下所示
(4)
式中Cr为贡献率. 累计贡献率达到85%~95%,确定为所对应的主成分个数. 通过对采集的数据影响因素进行计算,并从累积贡献率确定主成分个数如表1所示.
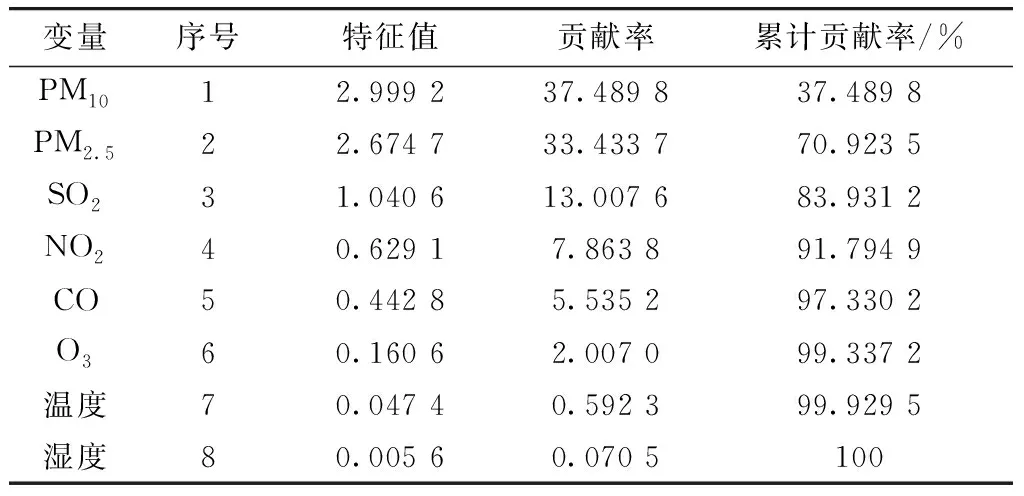
表1 主成分分析Tab.1 Principal components and contribution rate
从表1中可以看出,累计贡献率为85%~95%的主成分为前4个变量. 因此,本文选择PM10、PM2.5、SO2、NO2作为主要的研究对象. 为了进一步分析与PM2.5浓度相关的变量计算主成分因子载荷矩阵. 如表2给出了主成分因子载荷矩阵.

表2 主成分因子载荷Tab.2 Principal component matrix
表2显示了4个主成分的之间的相关性.x1~4为确定的主成分变量. 由于PM2.5浓度是造成污染的主要成分之一. 因此,本文主要对预测PM2.5浓度进行预测研究,从表2中的结果可以看出PM2.5浓度与其他4个变量因素关系密切,当PM10增加时,PM2.5浓度也会相应升高. 当SO2和O3浓度增加时,PM2.5浓度相应下降. 所以从表中可以看出提取出的主成分都与PM2.5浓度都有关系并影响着PM2.5浓度. 因此,本文最终选取PM10、PM2.5、SO2、O3作为主要的关键变量,并确定为所建PM2.5预测模型的输入变量.
2 在线序列极限学习机PM2.5预测模型
极限学习机(ELM)是HUANG 等[20]提出的单隐层前馈神经网络. 该网络具有输入层、隐含层和输出层. 假定有一组训练集(xi,yi),xi为网络的样本输入,该输入包括PM2.5、PM10、SO2、NO2.yi为网络的输出PM2.5浓度. 其L个隐含层神经元的ELM的一般形式可以如下式所示
(5)
式中:βi为输出权重;G(ai,bi,X)为激励函数;ai为网络的输入权重;bi为第i个隐含层单元阈值. ELM的网络结构如图2所示.
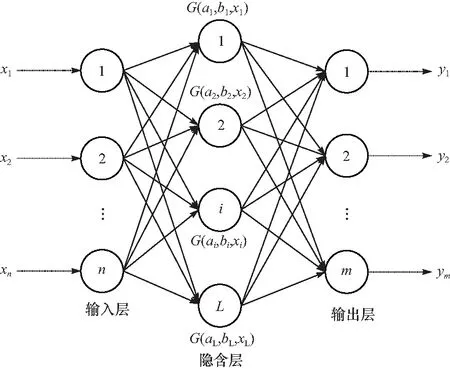
图2 极限学习机网络结构图Fig.2 The network structure chart of ELM
式(5)式也可采用矩阵形式表示,如下所示
Hβ=Y
(6)
式中:H为网络的隐含层输出矩阵,其计算公式表示如下
H(a1,a2,…,aN,b1,b2,…,bN,x1,x2,…,xN)=
(7)
(8)
输出权重的计算如下式所示
(9)
式中:H-1为隐含层输出矩阵的摩尔-彭罗斯广义逆[21],H-1由下式给出
H-1=(HTH)-1HT
(10)
(11)
式(11)为最小二乘解,通过此解的顺序实现OS -ELM方法. 只需要考虑最小化问题‖H0β-Y0‖.H-1可以通过奇异值分解(SVD)方法获得求解[21]. 当得到k+1组训练数据块时计算Hk+1,进而计算新的输出权值,如下式所示
(12)
(13)
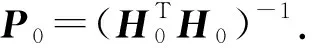
3 在线序列极限学习机预测PM2.5浓度
在建立完极限学习机预测模型后,利用该模型对大气PM2.5浓度进行预测. 利用监测的输入变量PM10、PM2.5、SO2、NO2训练数据集建立一个初始的OS-ELM模型. 首先从采集到的污染物数据中利用PCA方法提取主要的污染变量因素实现降维. 然后对所选的主要变量进行归一化数据处理. 再次确定G(ai,bi,X)以及隐含层的个数, 随机确定ai,bi. 最后通过若干批次的输入样本进行训练直到最后获得最终的β. 而在采样监测的过程中,新的数据被不断的收集. 因此,通过新采集的数据在线更新过程中,利用OS-ELM在线学习能力来更新现有的模型,而无需再训练. 为了更直观阐述PCA-OS-ELM方法预测PM2.5浓度过程,OS-ELM网络模型预测PM2.5浓度的流程具体如图3所示.

图3 基于PCA-OS-ELM的 PM2.5浓度预测流程图Fig.3 Flow chart of PM2.5 concentration prediction based on PCA-OS-ELM
通过图3描述了所提方法的运算过程,不断地利用训练数据更新输出层权值,准确地建立模型,达到更高的PM2.5浓度预测效果. 因此,为了更好地验证所提方法的有效性,通过实际观测数据与仿真实验预测大气PM2.5浓度,进而更直观地说明所提方法的准确性.
4 实验结果与分析
在实验中,前80%的数据被选为训练集,剩余的数据被用作测试集. 本文所提算法的代码在Intel(R) Core (TM) i7-6500U CPU 2.50 GHz 具有8 G内存的计算机上运行. 为了消除不同维数和量纲的影响,在数据处理过程中分别对采集样本的输入数据进行归一化处理. 其公式如下所示
(14)
式中:xp为归一化后的样本数据;xi为输入的原始数据;xmax和xmin分别为原始数据集中的最大值和最小值. 基于平均绝对误差(MAE)、均方根误差(RMSE)和决定系数(R2)对PCA-OS-ELM方法的检验分析和评估. 3个评估函数由如下式给出
(15)
(16)
(17)

在仿真预测过程中,本文提出了PCA-OS-ELM方法预测大气PM2.5浓度. 然后通过与ELM网络、BP网络比较预测PM2.5浓度的准确性验证所提方法的性能. OS-ELM方法中激励函数本文选择类型为Sigmoid函数. 极限学习机的网络隐含层的个数选定为6. BP隐含层网络设置为5,学习率为0.01,迭代次数为1 000次. 图4显示了监测的实际PM2.5浓度时间序列.
从图4可以看出不同时间段PM2.5浓度时间点PM2.5浓度变化明显. 受到不同其他污染物可能影响着它的变化,因此,非常有必要对PM2.5浓度进行分析预测. 为了更好了解不同方法预测PM2.5浓度的预测精度,分别采用不同方法对同一批采样样本运算比较,计算预测的误差. 图5所示为ELM方法预测PM2.5浓度预测结果. 图6所示为BP网络方法预测PM2.5预测结果.
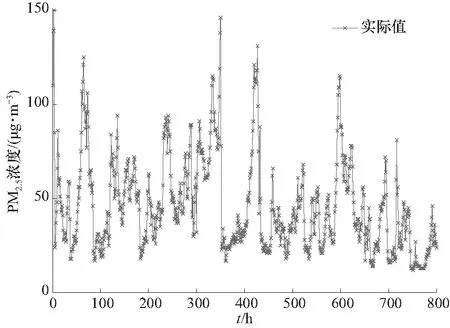
图4 PM2.5浓度的原始时间序列Fig.4 The original time series of hourly PM2.5 concentrations
从图5中可以看出ELM方法预测PM2.5浓度某时间点出现偏差. 如120~130时间段偏差较大,但是整个预测过程与实际值基本上一致. 相比于图6中BP方法预测PM2.5浓度的预测精度要高,并且BP方法预测PM2.5浓度存在某点的偏差较大.
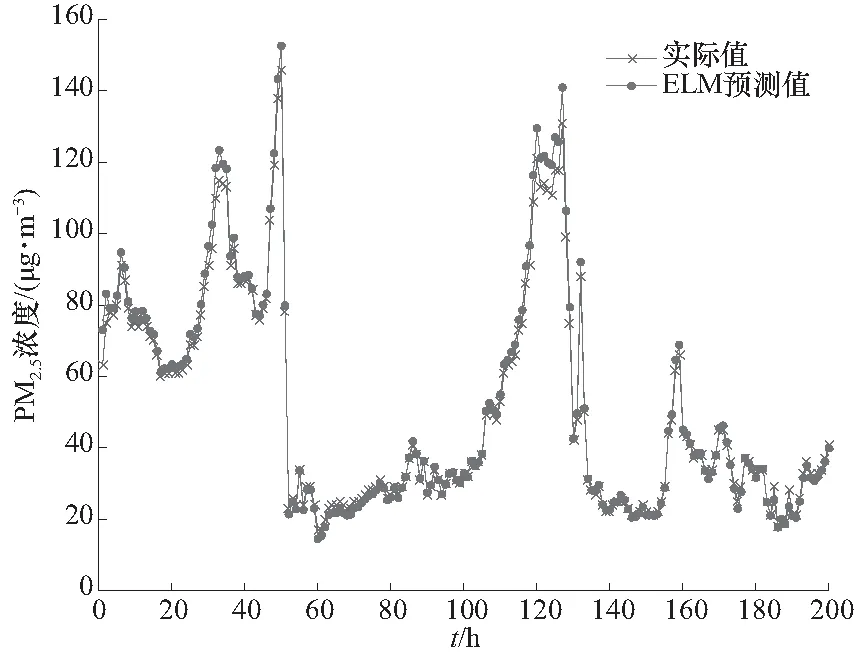
图5 基于ELM方法预测PM2.5浓度的结果Fig.5 The PM2.5 concentration prediction result based on ELM method
从图6中可以看出在40~60之间时间点上预测PM2.5浓度与实际值偏差较大,120~130时间点
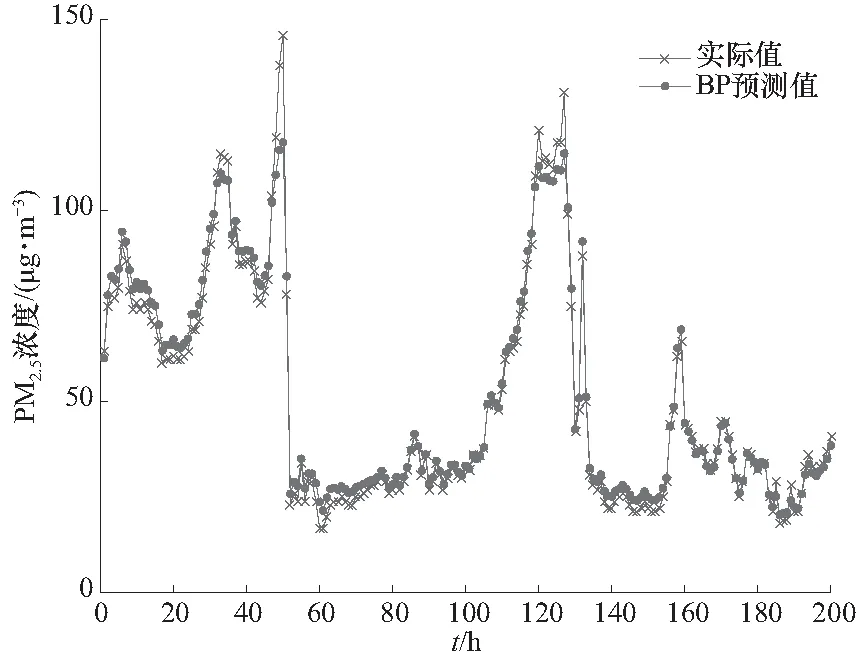
图6 基于BP方法预测PM2.5浓度的结果Fig.6 The PM2.5 concentration prediction result based on BP method
上预测偏差也较大,整体预测偏差较明显. 所以BP方法的预测精度还有待提升. 而仿真实验也证明了ELM方法学习速度更快且预测精度更高,充分利用只需设置隐含层神经元个数的特点,改善了BP神经网络训练时间长、易陷入局部极小值的缺点. 为了更精确地预测PM2.5浓度,在此基础上采用OS-ELM方法在线不断更新权值对大气PM2.5浓度预测. 图7给出了OS-ELM方法预测PM2.5浓度的结果.
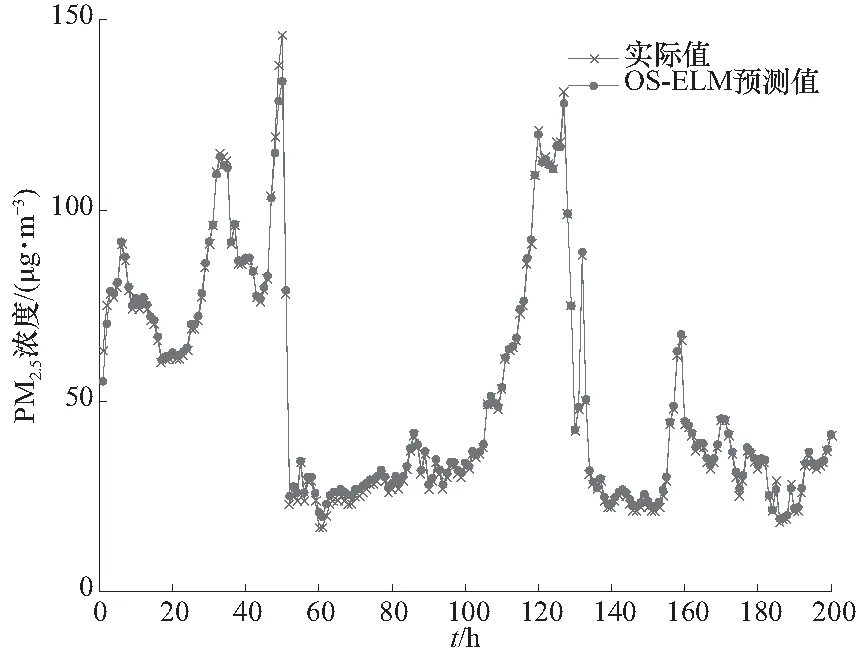
图7 基于OS-ELM方法预测PM2.5浓度的结果Fig.7 The PM2.5 concentration prediction result based on OS-ELM method
从图7可以看出OS-ELM预测PM2.5浓度值与实际值基本一致,并且在某单个点会有小的预测偏差,从预测趋势看很好地预测了PM2.5浓度. 因此,表明所提方法预测PM2.5浓度具有较好的效果. 从图7中可以看出此方法预测PM2.5浓度整体效果明显比ELM、BP方法预测效果更好. 而且表3给出4种方法之间的预测误差. OS-ELM预测误差的指标MAE为1.208 4,RMSE为1.754 5,R2为0.996 6. ELM的误差性能指标MAE为1.900 4, RMSE为2.909 3,R2为0.990 5. 很显然在4种预测方法中,OS-ELM预测误差是最小的,充分说明OS-ELM方法预测PM2.5浓度精度更高.
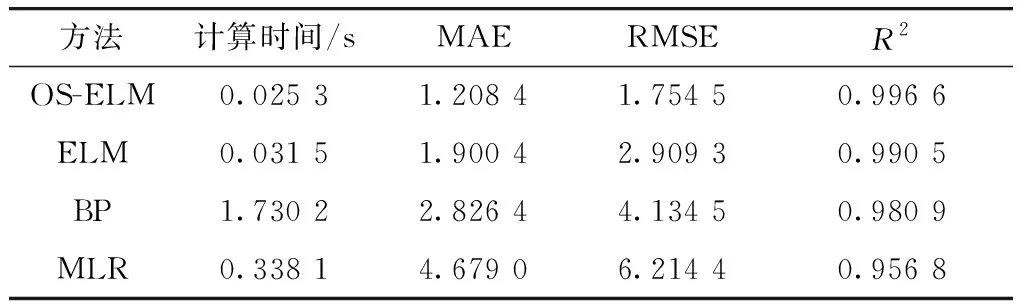
表3 4种方法的预测误差结果Tab.3 The Prediction error results of four methods
从图8中可以看出MLR方法在预测PM2.5浓度时,在0~40时间点和120时间点及180~190之间都出现了明显的较大预测偏差,从而证明在大气预测过程中污染物变量之间总是存在着非线性关系,而利用多元线性模型做预测PM2.5浓度时往往不够稳定易受外界影响而导致预测不精确. 为了更好地证明所提方法的有效性,图9给出了OS-ELM与其他3种方法的预测结果.

图8 基于MLR方法预测PM2.5浓度的结果Fig.8 The PM2.5 concentration prediction result based on MLR method
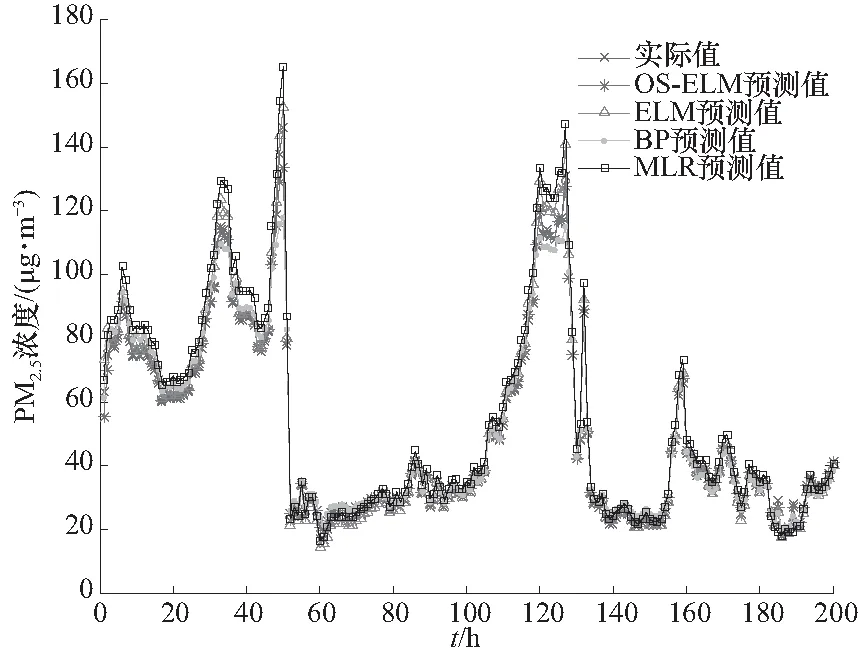
图9 4种方法预测PM2.5浓度的预测结果Fig.9 The comparison of PM2.5 concentration prediction results of four methods
图9体现了4种方法的预测PM2.5浓度的趋势效果,OS-ELM预测结果更加接近实际的PM2.5浓度值. 因此,证明所提OS-ELM方法在大气PM2.5浓度预测中的应用的有效性. 表3给出了不同预测算法的计算时间,从表中也可以看出所提算法计算时间为0.025 3,其计算时间是4种算法中最快的. 所以所提算法用时最短,误差最小.
5 结 论
本文基于PCA-OS-ELM方法预测大气PM2.5浓度. 利用PCA 方法从所监测的数据PM2.5、PM10、SO2、NO2、CO、O3、温度、湿度中提取主要影响大气变化的因素, 通过累积贡献率确定PM10、NO2、SO2、PM2.54个变量作为所需要建立的研究变量,研究了PM2.5浓度与其他变量之间的相关性,并采用OS-ELM方法预测PM2.5浓度. 仿真结果表明PCA-OS-ELM方法不仅解决了大气数据中高维数据冗余问题,并且在短时间内完成对PM2.5浓度的更精确预测. 与ELM、BP、MLR预测方法相比,PCA-OS-ELM方法能够通过不同批次大小的训练数据更新网络模型参数,在保证PM2.5浓度预测精度的前提下,可以实现更快速、稳定、准确地预测,弥补了其他所提预测方法的不足,验证了所提方法的有效性与实用性.
猜你喜欢
走向世界(2022年18期)2022-05-17
教育周报·教研版(2021年47期)2021-12-19
家庭影院技术(2021年8期)2021-11-02
百科探秘·航空航天(2020年8期)2020-07-29
中学生数理化·高三版(2016年9期)2016-05-14
新高考·高二数学(2014年7期)2014-09-18
福建中学数学(2011年9期)2011-11-03
中学生数理化·高一版(2009年6期)2009-08-31
中学生数理化·七年级数学北师大版(2008年5期)2008-10-14
小学教学参考(数学)(2006年7期)2006-12-31
