
基于改进高分辨率网络的多人姿态估计方法
2022-01-15 02:51张云绚董绵绵
中国新技术新产品 2021年21期
张云绚 董绵绵
(西安工业大学电子信息工程学院,陕西 西安 710021)
0 引言
随着科技迅速发展,信息化联合作业逐渐成为协作的基本形式,对有效侦察和监视情报的信息智能处理能在一定程度上提高作业人员的能力和效率[1]。因此,在新技术、新产品的推动下,可以进一步提高系统整体的信息处理能力,尤其在矫正人员位姿、理解传信员肢体语言以及训练机器人模仿作业人员等方面[2]。
多人姿态估计主要分为自上向下和基于构件的框架。方法一,先定位人体区域,然后进行姿态点定位,可以应对复杂场景下的姿态任务;方法二,先检测图像中所有关键点并组成肢体,然后对肢体构件进行匹配,受空间约束易出现关键点重叠,导致检测效果较差。同时,不同侦察设备反馈的监测图像不同,存在图像多尺度问题。易对关键点正样本进行检测,将困难点检测归为负样本,样本不均衡会影响检测结果。针对上述问题,该文提出一种多人姿态估计方法,首先,基于YOLOv4模型加入Ghost卷积模块,减少计算参数量,提高模型的响应速度。其次,基于高分辨率网络融合不同尺度图像的特征,结合特征金字塔融合不同层之间的特征信息。最后,使用梯度均衡机制解决关键点正负样本不均衡的问题,提高人体姿态估计准确率。
1 对称空间变换网络
空间变换网络(STN)是1个可学习的模块,能在网络中有效增加图像空间的不变性,空间反变换网络(SDTN)将估计结果仿射变换到原始图像数据中。二者合称为对称空间变换网络,其网络结构如图1所示。其中,θ表示空间变换参数,λ表示空间反变换参数,Tθ(G)表示二维放射变换函数,Tλ(G)表示二维反变换函数,{xiS,yiS}表示原图像第i个坐标点,{xiT,yiT}表示仿射变换后图像第i个坐标点。首先,通过定位网络得到回归输出参数θ。其次,经过网格生成器对特征图进行空间变换,将像素位置与得分进行映射。第i个输出坐标点位置的像素值如公式(1)所示。
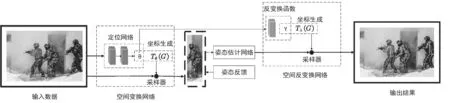
图1 对称空间变换网络结构图

式中:Unm为原始图像通道中坐标为(n,m)的像素值;Vi为第i个坐标点的像素值; k(·)为线性插值函数;φx和φy为插值函数参数;*表示卷积运算。
该文选择函数k(·)并采用立方卷积插值,如公式(2)所示。
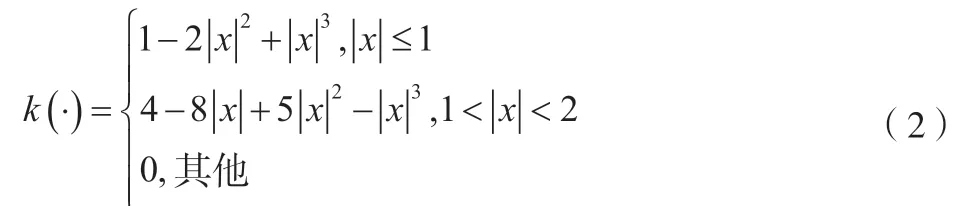
2 网络模型设计
该文所提出的多人姿态估计选择了自上向下的框架,其整体结构如图2所示。模型主要由人体探测器、对称空间网络、姿态估计网络以及姿态非极大值抑制网络4个部分组成[3]。首先,采用融入Ghost模块的轻量级YOLOv4目标检测模型,有效提高了人体探测器的运行速度。其次,基于高分辨率网络融合不同分辨率的图像特征,采用梯度均衡机制(GHM)解决关键点正负样本不均衡的问题,在改善模型尺度泛化性的同时提高模型的准确率。最后,采用欧式距离计算关键点的空间距离,除去冗余姿态。

图2 多人姿态估计模型整体结构图
2.1 基于Ghost模块重构人体探测器
通过选择使用轻量化的卷积模块有效地对卷积神经网络中的特征冗余问题进行处理。进行卷积运算时,输入数据为X∈Rc×h×w,c为通道数,h和w为数据的长和宽;卷积核为f∈Rc×k×k×n,k为卷积核尺寸,n为卷积核数量。由经典卷积公式得到特征图,如公式(3)所示。

式中:b为偏置项;Y为输出特征图;*表示卷积运算。
采用经典卷积生成m个通道层的原始特征Y',利用简单的线性变换得到阴影特征,如公式(4)所示。

式中:yi'为Y '中第i个原始特征图;φi,j为第j次线性运算,可以生成阴影特征yij。
最终得到m×s个特征图作为Ghost模块输出,在整个YOLOv4的网络中,将所有经典卷积替换为Ghost卷积模块,如图3所示。
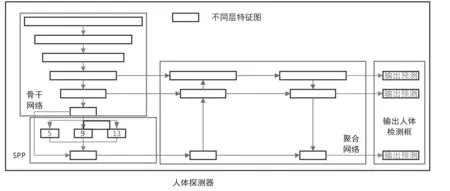
图3 基于Ghost模块的重构人体探测器示意图
2.2 姿态估计网络
针对实际目标存在多尺度识别率低、关键点正负样本不均衡等问题,该文提出了姿态估计网络模型。首先,骨干网络选取高分辨率网络HRNet-32,将图片输入高分辨率卷积流中,逐步增加高分辨率到低分辨率的流,形成新的阶段,并将多分辨率流并行连接,即后一阶段的并行流的分辨率由前一阶段的分辨率和1个额外的、更低的分辨率组成。不仅可以使模型一直保持高分辨率表示,而且还融合了更多分辨率表示,有利于更加有效地从输入图像中提取特征,进而获得高质量的特征图,将语义信息丰富为基本特征。其次,将骨干网络输出的高质量、不同分辨率的特征图作为特征金字塔的输入,连接不同层特征图后对其进行多尺度的若干特征图聚合并输出,再结合梯度均衡机制解决人体关键点正负样本不均衡问题,实现单个人体的关键点检测。最后,采用姿态非极大值抑制消除姿态估计网络中生成的冗余姿态,以产生最终结果。
骨干网络分为4个阶段且4个阶段并行连接,使采样后的特征图分辨率为输入图像的1/4,各层分辨率逐渐减少为1/2,与之对应的通道数是上一个阶段的2倍。第一阶段先选取2个3×3的卷积组成子网,降低原始图片的分辨率;第二阶段由上一层分辨率子网和下采样后的子网并联组成;第三阶段再次对邻近的上一层分辨率子网进行下采样,与第一阶段、第二阶段的分辨率子网并联连接;第四阶段,最近的一层分辨率子网继续进行下采样,将4个不同分辨率的子网并联连接。此时,将骨干网络的输出送至特征金字塔结构,经由逐级采样后的融合作为最后的输出。涵盖了更多的层次与尺度信息的交互,找出图像中人的所有关键点(例如头部、腕关节和脚踝等)。对于检测受到尺度变换影响的关键点,可能将易检测关键点转为困难关键点检测,从而增加关键点难例(负样本),造成关键点正负样本不均衡的现象,采用梯度均衡机制并根据梯度分布角度进行均衡,通过改变正负样本的权重让网络模型多学习复杂的困难关键点。姿态非极大值通过标签归一化的IoU预测分支来预测每个候选框的定位置信度,利用IoU所产生的预测值作为边框排列的依据,以抑制与当前选框IoU超过设定阈值的其他候选框,且采用积分的方式实现了更为准确的感兴趣区域池化,有效提升了关键点检测的准确度。
2.3 梯度均衡机制
考虑人体关键点检测正负样本的不均衡程度,结合梯度均衡机制(GHM)对关键点进行检测。因为在逐渐加深的训练过程中,网络会关注比例较多的正样本,也就是易识别的关键点,对于负样本即受到尺度变换影响、被遮挡等识别困难的关键点,网络的关注会逐渐降低,所以该文根据对训练损失函数的重构实现对关键点正负样本的关注平衡,使模型训练更加高效和稳健,并可以收敛到更好的结果。梯度密度函数如公式(5)~公式(7)所示。

式中:gk为第k个样本的梯度;GD(g)为梯度落在区域的样本数量;ϵ为梯度值的分布间隔;g为样本的梯度范数;δϵ(x,y)为x在y邻域内的样本数量;lϵ(g)为计算样本量的邻域区间长度。
再定义密度协调参数β(其中,N为样本数量),可以保证均匀分布时损失函数不变。
3 试验分析
该文姿态估计模型数据集为2017MS COCO数据集,试验环境为Ubuntu 18.04操作系统,内存为32 GB的Intel® CoreTM i7-8700CPU@3.20GHz,Geforce RTX 1080Ti显卡,并分别将算法的准确率与人体探测器的参数进行对比。
具体试验结果如下:分析对比了该文模型与YOLOv4检测模型的参数量,数据见表1;模型与其他姿态估计模型性能在验证集的对比见表2;(其中, AP为所有10个目标关键点相似性阈值的平均精确率;AP@0.5为目标关键点相似性为0.5时AP值;AP@0.75为目标关键点相似性为0.75时的AP值;APm为中等目标的AP值,面积大小范围为(322,962);APl为大目标的AP值,面积大小范围为(962,-));梯度均衡机制的作用对比见表3;部分模型可视化结果如图4所示。

表3 梯度均衡机制的消融试验
由表1可知,经过Ghost模块的操作后,模型运算量约减少了48%,模型体积缩小了46%,帧率提高了约8 f/s。

表1 人体检测算法参数规模对比
由表2可知,在使用了高效的人体探测器后,该模型对人体关键点的准确率相对HRNet有提高了大约1.1%,主干网络HRNet的使用为模型提供了可靠的分辨率,衔接的特征金字塔进一步对提取的高质量多尺度特征进行不同层之间的融合,最大化地使用图像的空间信息和上下文语义信息,并尽可能平衡关键点正负样本的比例,实现对负样本困难关键点的检测。

表2 不同模型姿态估计性能对比
为了验证该文模型中使用的梯度均衡机制解决关键点样本均衡性这一问题的有效性,该文进行了关于GHM的消融试验。
由表3可知,通过使用梯度均衡机制,该文模型的AP提升了2.1%,该机制可以有效地提升模型的性能。
图4(a)~图4(c)为不同角度与距离的结果对比。图4(d)~图4(f)表示在多人情况下不断改变距离的远近进行模型对比的结果。图4(g)~图4(i)是在光线不明亮的情形下,由单人至多人的姿态估计结果,图4(h)是带有部分遮挡条件下的姿态估计结果。可以看出,该文能够在尺度变换的影响、光照条件的改变以及带有部分轻微遮挡的情况下,很好地完成人体关键点检测工作。

图4 部分模型可视化结果
4 结论
该文所提出的自上向下的人体姿态估计模型将Ghost卷积加入了人体探测器的YOLOv4中,有效地提高了模型关键点的检测效率;基于高分辨率网络结合特征金字塔网络对尺度目标的人体关键点进行检测,采用梯度均衡机制的方式改善关键点正负样本不均衡的问题,提高关键点检测的准确率。在2017COCO数据集上,该文模型关键点检测的准确度比CPN提高了7.2%,比Alphapose提高了5.1%,比HRNet提高了1.1%,在该文的测试环境下,模型实时运行的帧率达到了25 f/s。今后,可以逐渐加大任务难度,构建面对密集伪装人群也能实现高精度、体积小以及运行效率高的多人姿态估计模型。
猜你喜欢
今日农业(2021年8期)2021-11-28
学生天地(2020年3期)2020-08-25
数学物理学报(2019年3期)2019-07-23
家庭影院技术(2018年9期)2018-11-02
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
中国卫生(2014年2期)2014-11-12
语文知识(2014年7期)2014-02-28
