
一种基于改进的YOLOv3的敏感目标检测方法*
2022-01-15 06:24童雪东任明武
计算机与数字工程 2021年12期
童雪东 任明武
(南京理工大学计算机科学与工程学院 南京 210000)
1 引言
当前,战场感知信息向着多源异构的方向发展,这要求侦察情报装备和武器打击装备具有系统化和智能化特点。同时,随着未来战争的人员伤亡“零容忍”趋势成为世界各国政府对战争的重要政治考量因素,地面无人车辆侦察系统(Unmanned Systems,US)正在为军队承担越来越多的作战任务,但地面无人车辆侦察系统任务的预置程序难以适应战场任务的动态变化特性,对复杂战场环境下的敏感目标检测就成为地面无人车辆侦察系统的一个重要研究发展方向。
地面无人车辆侦察系统主要分为基于雷达和基于图像两类。传统方法大多采用基于雷达的技术,这种方法在实际应用中侦察的区域范围较广,但是缺点在于战场侦察雷达的分辨率一般比较低,目标的特征信息有限,很难从中获得反映目标本身属性的信息。因此,基于图像的敏感目标检测系统具有更实际的应用价值。
目标检测[1]是计算机视觉中一个重要的研究课题。随着计算机技术的迅猛发展,目标检测与识别已在人脸识别、行人跟踪、车牌识别、无人驾驶等领域获得了广泛的应用。传统的目标检测的方法一般分为三个阶段:首先在给定的图像上使用不同大小的滑动窗口选取候选区域;然后对这些候选区域提取特征;最后使用训练好的分类器进行分类。但传统的目标检测存在两个主要问题:1)基于滑动窗口的区域选择是穷举的策略,计算冗余;2)手工设计的特征缺乏鲁棒性。这些弊端很大程度上限制了算法的应用。
深度神经网络的出现颠覆了传统的特征提取方式,通过大量的数据训练能够自主学习有用的特征。目前主流的通用目标检测方法主要分为两种:两阶段方法和单阶段方法。两阶段方法是指基于候选区域的目标检测器如R-CNN[2]、SPP-Net[3]、Fast-CNN[4]等,这类方法需要对每个区域建议进行一次前向CNN实现特征提取,因此精度较高,但计算量较大,无法应用于实时检测场景;单阶段方法比如YOLO[5]、YOLOv2[6]、SSD[7]、YOLOv3[8]等。其中YOLO将检测问题作为回归问题来处理,因此速度非常快,但由于YOLO隐含地将图片分为s×s个网格,每个网格至多预测一个类别,因此YOLO对靠地很近的物体以及小目标群体检测效果不是很好。YOLOv2借鉴了Faster RCNN[9]的思想,使用聚类算法产生anchors,虽mAP有所降低,但提高了recall,此外,YOLOv2加入了bn[10]层,使网络收敛更快,精度更高。YOLOv3引入多个残差网络模块[11],大大拓展了网络的深度,并且使用多尺度预测的方式重新设计了darknet-53网络,改善了YOLOv2对小目标识别上的缺陷,其检测的准确率高并且实时性好。
本文针对战场敏感目标检测中的高实时性和低漏检率需求,选择在速度和准确率上综合表现最好的YOLOv3算法。虽然YOLOv3已取得了较好的实时检测效果,但对于战场敏感目标检测来说仍有不足,主要表现在以下三个方面:1)YOLOv3的检测精度低于Faster R-CNN;2)YOLOv3网络的训练采用了COCO[12]和VOC[13]数据集,引入的anchor不能适应敏感目标;3)数据集中难样本识别率低。因此本文研究以YOLOv3网络为基础的改进算法。
2 YOLOv3原理
2016年Redmon等提出的YOLO算法,将目标检测任务转换成回归问题处理,大大加快检测的速度,但因为它隐含地将图片分割成s×s个网格,每个网格至多负责预测一个类别,因此,对小物体目标不友好。YOLOv2借鉴了Faster R-CNN的思想,使用了聚类算法产生anchors,使网络拥有更好的召回率。YOLOv3在YOLOv2的基础上提出,保持YOLOv2的检测速度,并且大大提高了检测的准确率,尤其在小目标的检测与识别上。
YOLOv3首先使用k-means算法[14]在数据集上产生聚类先验框(YOLOv3默认的聚类中心有9个,每个尺度分配3个框)。不同于YOLOv2采用的网络结构Darknet19,YOLOv3重新设计了更深的网络结构Darknet-53,它一方面借鉴了残差网络的思想,大大增加了网络的深度的同时避免训练过程中产生梯度消失的现象;另一方面,它借鉴了FPN[15]的思想,融合三种不同尺度的预测特征图,这三个特征图的规模分别为13×13、26×26和52×52。由于后两个特征图中每个网格对应原图的区域更小,且它们处在网络较低层,因此,模型可以综合利用低层信息以及高层语义信息,从而改进模型对小目标的检测性能。
3 本文的工作
3.1 数据集
在深度学习中数据集质量的高低直接影响了最终检测效果的好坏,同时由于网络要充分学习待检测目标的特征,这便需要大量的样本。由于缺乏现有公开的战场敏感目标检测数据集,本文在实验中采用手工标注制作数据集的方法。我们采集了16000张图片,样本示例如图1所示,我们为每幅图像标注其中四个类别:油桶、车、迷彩士兵和弹药箱,经统计,数据集中一共包括7680个车目标、17018个士兵目标、8870个油桶目标和6476个弹药箱目标。每个标注包括类别索引和目标的坐标(中心点坐标、包围框的宽、高)。采集的原始图片的分辨率为1920×1080。我们为数据集命名为sensitive-16k。

图1 数据集中部分样本展示
我们将数据集划分为三部分,其中12k张图片用于训练,1k张用于验证,3k张用于测试,在数据增强方面,我们对训练集中的图片执行裁剪、翻转等操作以生成更多的样本。
3.2 候选框维度聚类
YOLOv3借鉴 了Faster R-CNN中anchors的 机制,采用K-means对数据集中的标签进行聚类得到先验框,先验框的设计影响目标检测的速度与精度。YOLOv3的训练集是VOC和COCO,考虑到训练集分布的不同,我们使用K-means对sensitive-16k数据集中的标签进行聚类,从而得到相应的初始候选框的参数。聚类过程中我们采用的距离度量公式如下:
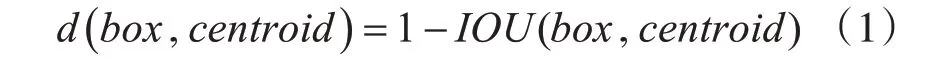
本文按照不同的候选边框数量k进行聚类后,最终得到的对应交并比如图2所示。综合检测速度和检测准确性的考量,我们选取候选框数量为9,具体的参数为(24,60),(82,46),(54,127),(95,162),(148,105),(318,152),(509,305),(248,646),(1120,720)。我们在三个预测尺度上分别分配三个候选框。

图2 不同k取值对应的交并比
3.3 损失函数微调
对于本文所研究的敏感目标检测问题,网络在训练过程中需要考虑三个方面:坐标预测损失、置信度预测损失以及类别预测损失,其中置信度又分为包含目标置信度和不包含目标置信度两部分。考虑到战场敏感目标检测问题的特性,我们认为,高召回率比高准确率更重要,因此,我们降低了不含目标置信度的权重,具体四部分损失函数的公式如下:
1.5 观察指标 ①两组患者治疗前、后激素水平变化:包括E2、FSH、LH、孕酮(T)、催乳素(PRL)和AMH,分别于治疗前、后抽取患者外周静脉血5 ml,离心10 min分离血清,置于-20℃下保存待测,采用化学发光法测定E2、FSH、LH、T、PRL和AMH含量;②观察两组患者治疗前、后双侧卵巢AFC数变化:采用美国GE公司彩色多普勒超声诊断仪进行阴道超声检查;③观察两组患者治疗前、后生活质量情况:采用健康状况调查量表评价,包括生理健康、情感职能、生理职能和生理功能4个量表,每个量表100分,评分越高生活质量越好;④观察两组患者成功排卵和妊娠情况。

上述式子中,K表示当前采用的预测图的尺寸,文中一共选用了三种尺寸,分别是13×13,26×26和52×52,M表示的是每一个网格所预测的目标边框的数量,本文选取的是2。式(2)是包围框损失,它包括中心点坐标预测损失和包围框宽、高预测损失,用于判断第i个网格中第j个包围框是否负责预测这个object,若是,为1,否则为0。λcoord为坐标预测的惩罚系数,文中设置为5。由于小框的偏移量比大框的偏移量更无法忍受,因此,用(2-wi×hi)来平衡大小框的损失;式(3)和式(4)分别为包含物体和不包含物体的置信度损失,为了使检测获得更高的召回率,我们使不包含目标时置信度的惩罚系数λnoobj为一个更小的值0.3;式(5)为类别预测损失,式中判断是否有目标的中心落入该网格中,若有,该网格就负责预测该目标的类别。对于包围框预测,采用误差平方和损失衡量,对于置信度预测损失,以及类别预测损失,采用交叉熵损失函数进行衡量。
4 实验结果与分析
4.1 实验配置与训练
实验中我们采用手工标注的sensitive-16k数据集,并对其执行数据增强。本文的实验环境配置如表1所示。

表1 本文实验相关配置
训练中,我们使用小批量随机梯度下降法,批次大小为16,动量为0.9,权重衰减为0.0002,学习率初始值设置为0.025,我们采用了一种“多”学习速率策略,其中每次迭代的初始速率乘以其中power为0.9。
网络的训练分为三阶段,第一阶段预训练分类网络,这一阶段分为两个步骤,首先使用低分辨率(224×224)的已标注的敏感目标数据集预训练分类网络,然后将网络调整到448×448,继续训练分类网络。第二阶段为训练检测网络,使用第一阶段预训练的权重初始化检测网络的部分权重,再在敏感目标数据集上进行微调。
4.2 实验结果
本节将从初始候选框选取、损失函数的改进两部分分析实验设置对实验结果的影响。
4.2.1 初始候选框选择对实验结果的影响
为了对比使用不同的初始候选框对模型性能的影响,首先使用YOLOv3原始的候选框参数进行训练,接着按照我们的数据集分别聚类得到6个边框和9个边框进行训练,训练集使用sensitve-16k,最终得到的模型在测试集上的性能见表2。

表2 初始候选边框对模型性能的影响
可见,重新聚类得到我们的候选框对模型在sensitive-16k数据集的性能表现有很好的提升。
4.2.2 改进的损失函数对网络性能的影响
考虑到敏感目标的特殊性,更改了损失函数中的不含目标置信度的惩罚项,以使网络更倾向于认为网格中含有目标,我们放弃了部分的准确度而选择了更高的召回率。
与改进损失函数的目的一样,为了更好地避免漏检,调整置信度阈值为0.3,使网络能够输出更多检测框。得利于模型学习的是整张图片的特征,网络输出的假阳性很低。
表3显示了我们的损失函数中不同惩罚项系数对模型的召回率和准确度的影响,最终确定选择惩罚项为系数,以在召回率和准确度之间取得一个较好的平衡。

表3 不同惩罚项系数对模型准确度和召回率的影响
最终我们的模型和原始YOLOv3模型在测试集上的检测性能如表4所示。图3展示了我们在测试集上的部分测试效果。
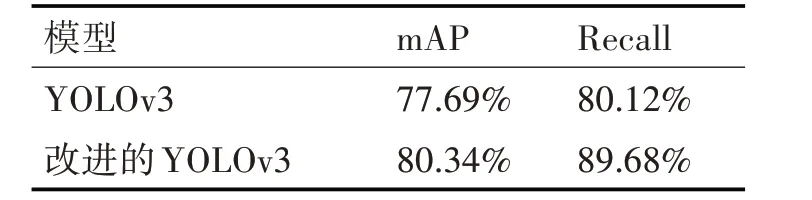
表4 在sensitive-16k数据集上测试结果

图3 检测结果展示
5 结语
本文通过改进YOLOv3,使用K-means算法聚类初始目标边框、微调损失函数、调整阈值以及预训练分类网络进行训练检测网络。实验结果表明,通过以上方法得到的检测模型对于复杂场景下的敏感目标可保证非常高的召回率以及较高的检测准确度。但是本文仍存一些有待改进的地方:为了保证召回率,造成了部分的假阳性效果,损失函数微调中使用的惩罚项系数是我们手动设置的,如何设置更优的参数,以在保证召回率的同时得到更高的准确度,未来会将解决上述问题作为重点的研究方向;由于数据集数据的缺乏,我们的模型仍有待被更加充足的数据集进行训练以得到更鲁棒、更精确的模型。
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
北京航空航天大学学报(2022年8期)2022-08-31
小型微型计算机系统(2022年4期)2022-05-09
计算机应用与软件(2021年7期)2021-07-16
小天使·二年级语数英综合(2019年10期)2019-11-08
舰船电子对抗(2017年6期)2018-01-11
中国科技纵横(2016年20期)2016-12-28
互联网天地(2016年1期)2016-05-04
共产党员(辽宁)(2015年2期)2015-12-06
读者·校园版(2015年19期)2015-05-14
