
计算机化线性测验与自适应测验的等效性研究
2022-01-21 02:03李心钰
现代教育技术 2022年1期
李心钰 陆 宏
计算机化线性测验与自适应测验的等效性研究
李心钰 陆 宏[通讯作者]
(山东师范大学 教育学部,山东济南 250014)
基于计算机的测验已逐渐普及,但不同的计算机测验形式在测量相同任务时可能会产生测验结果的偏差,从而导致教育测量与评价结果的不公平性。文章基于项目反应理论,探讨了计算机化线性测验与计算机自适应测验在测验效率、测验结果的统计学特征及其对考生个体心理特质的影响是否等效等问题,并以师范生“现代教育技术”课程为例开展了实证研究,结果显示:两种测验中考生的分数具有可比性,计算机自适应测验具有更高的测验效率与测验信度,但有无即时反馈对考生测验焦虑的影响较大;而计算机化线性测验具有更合理的内容效度,有无即时反馈对考生测验焦虑的影响较小。文章的研究不仅对教学评价中测验形式的选择是否公平合理进行了科学分析,而且为施测者根据测验场景有针对性地选择测验形式提供了理论参考。
计算机化线性测验;计算机自适应测验;等效性;即时反馈;测验焦虑
一 计算机化线性测验与计算机自适应测验
计算机技术与测验理论的发展日新月异,其中计算机化线性测验(Computerized Linear Testing,CLT)与计算机自适应测验(Computerized Adaptive Testing,CAT)已在教育评价领域中得到了广泛的认可。CLT是目前教育教学实践中常用的计算机测验形式,它不仅能针对各学科与测验群体的特点控制测验内容的平衡,还能提供文字、图像、视频、交互等多种形态的试题,在测验中给予考生实时反馈,对测验分数进行即时计分,通过计算机高效地进行数据统计,帮助教师了解学生的整体水平。然而,固定序列的CLT容易带来测验安全的隐患,增加试题曝光的风险,且测验的时间、地点也受一定的约束,在大型测验中这些弊端显得尤为突出。而以项目反应理论(Item Response Theory,IRT)为指导的CAT,在题库构建、能力与试题参数估计、选题策略及评分标准方面都与CLT有明显差异:CAT能在保证测量精确度的前提下,为不同考生选择符合其能力水平的试题,从而用较少的试题更精确地测出考生的真实能力,实现测验的个性化需求;另外,CAT的考生也可以灵活选择测验的时间、地点,使得测验方式更加便捷。简言之,CLT为考生提供的是固定试题,纵使在同一测验中采用多套平行试卷,考生所测的试题仍是出题人依据测验目标组合好的难度、内容大致相同的试卷,测验需统一时间,以免出现泄题事件;而CAT能够做到“对症下药”,为每位考生匹配最适合其能力水平的试题。
CLT、CAT是现代教育测量领域的两大主流测验形式,施测者可以根据测验目的自主选择。例如,在日常课堂测验中,CLT有助于教师掌握学生的阶段性学习成果,从而帮助教师合理地调整教学计划。而在常模参照测验中,CAT可以根据测验需求设定正答概率、选题策略,更好地发挥测验选拔人才的功能;另外,采用线上CAT的形式也便于教师灵活地选择测验时间、地点,不必过于担心试题的安全性与测验的公平性——而解决测量与评价形式不同所引发的公平性问题一直是教育领域的重要话题。例如,《美国国家教育技术计划》强调,在学习评价方面要通过技术的变革给学习者提供实时反馈,实现对学习者的自适应评价[1]。而在我国,《中国教育现代化2035》指出,在推进教育现代化的过程中,要注重因材施教,建立科学公正的考试评价制度[2];《深化新时代教育评价改革总体方案》强调,教育评价的重点任务之一就是改革学生评价,改变相对固化的试题形式、增强试题的开放性[3]。由上可以看出,在将信息技术融入教育测量与评价、为学习者提供个性化的评价方式方面国内外已达成共识。
评价是教学活动开展的重要环节,评价学生学习结果的主要方式是测验。当前,测验的形式已从最初的纸笔测验逐步发展至计算机化测验,受新冠肺炎疫情影响,越来越多的测验采用计算机进行,大到招生招聘测验,小到课程日常测验。随着CLT与CAT在教育实践领域的广泛应用,这两种测验形式的测量结果是否具有等效性的问题引起了研究者的关注。美国在2014年修订的《教育与心理测试标准》中指出,由于多种测验形式并存,不同测验形式在执行相同的测试任务时,测量结果的比较研究是非常必要的,包括测验分数的分布、测验信度、考生的排名等[4]。基于此,本研究梳理了CLT与CAT等效性研究的定义与内容,并以师范生“现代教育技术”课程为例开发了CLT与CAT系统进行实证研究,探究两者的等效性。需说明的是,本研究中的CLT、CAT试题均基于项目反应理论进行设计开发,两种测验的终止规则相同且提交答案后无法返回上一题进行修改。不同的是,CLT的选题策略、组卷方式与传统的计算机化测验相似,需要经过严密科学的人工组卷确定测验试题,考生面对的是一套固定序列的试卷;而CAT以极大似然估计的方法逐题对考生的能力水平进行评估,每位考生面对的试题因其能力水平的高低不同也各不相同,且随着测验的进行,试题的难度值将逐渐趋近于考生的真实能力水平。
二 等效性研究的定义与内容
等效性研究是指进行不同形式的测验时,对具有相同测试任务的测量结果在测验形式与效率、统计学特征、个体心理特征等方面是否效果等同的研究[5]。等效性研究涉及的内容主要如下:
1 测验形式与效率的比较
在测验形式的比较方面,CLT允许考生对答案进行反复检查与修改,而检查与修改答案的行为在CAT中受到约束。究其原因,在于CAT的选题策略是以考生先前的作答结果为依据,若允许考生返回修改答案,不仅会影响考生能力水平的估计值和测量的精确度,也必然会增加选题算法的复杂性。现今大规模应用的CAT均无法返回修改答案,虽然已有学者对允许修改答案的CAT展开了研究,但暂未推广至实践中进行应用,其效果还有待考量[6]。
在测验效率的比较方面,由于CLT与CAT的测验原理存在本质差异,两者的测验效率亦有不同:CLT是将传统的纸笔测验变换到计算机上,运用计算机全面管理测验数据,其测验效率并没有发生实质性的改变;而CAT为考生选择信息量最大的试题进行测试,这种“量体裁衣”的测验方式使CAT可以更快地达到与CLT相同测量精确度的测验要求。邓远平等[7]运用特质焦虑量表进行了CAT模拟测验,发现59.2%的考生仅作答了原有试题30%的题量即完成测验,可见测验效率显著提升。在大型测验中,CAT的高测验效率能有效降低题库试题的曝光风险,在测量精确度与CLT要求一致的情况下缩短测验长度与测验时长,可快速、高效地获取测验结果。而在日常测验中,为了便于查找考生的知识短板、查缺补漏,虽然CLT的测验效率较低,但在试题内容的全面性上更具优势。
2 统计学特征的比较
在考生分数与试题参数的比较方面,传统的纸笔测验按观测分数的权重线性累加赋分,考生分数和试题参数的估计具有对测验难度、样本水平的依赖性。而以IRT为指导对考生分数与试题参数进行估计时,常采用极大似然估计、贝叶斯估计等方法,得到的考生分数与试题参数不随测验和考生样本的变化而变化,体现了参数不变性的特点(此为理想状态)[8]。在实践过程中,有研究者提出,在对CLT、CAT的考生分数和试题参数进行比较时,对参加CLT、CAT的同组考生而言,纵使最终得到的能力值与试题参数存在差异,只要两者的排列顺序相似,就可作为等效的标志之一[9]。在信度的比较方面,在经典测量理论中,信度的概念建立在平行测验假设的基础之上,对参加同一测验的不同能力的考生而言,其信度系数均为固定值。而IRT中的信度与测量精确度有关,信度的大小取决于测验的终止规则——若以固定测量精确度作为终止规则,那么不同考生的信度系数均相同;若采用固定长度法(即测验达到一定长度即终止),那么考生呈现出的测量精确度不同,其测验的信度也就有所差异,这时需计算出信度范围再加以比较。在内容效度比较方面,CLT可以按照试卷编制的原则、教师的教学经验等进行科学严格的组卷,确保其具有良好的内容效度;CAT则因使用最大信息量选题策略,或对内容效度产生一定的负面影响。而在效标效度比较方面,可以选取客观、可靠的校标作为参照,将其与CLT、CAT的测量结果进行相关分析,验证其等效性。
3 个体心理特质的比较
目前,研究者在CLT、CAT比较中关注的个体心理特质主要是测验焦虑。测验焦虑在我国各学龄阶段的学生当中普遍存在,过度的测验焦虑会影响学生的学业成绩、记忆力、注意力等认知能力,甚至有学生会产生肺部功能、免疫系统等身体健康问题[10]。部分研究者认为,在传统的纸笔测验中,大多数考生需要作答高于自身能力水平的试题,会产生较高的测验焦虑[11];而CAT凭借其选题策略,能减少考生能力水平之外的试题,从而有效降低考生的测验焦虑。但Ortner等[12]的研究发现,与固定序列的测验相比,在正答概率为0.5的CAT中,部分考生会产生更高的测验焦虑,其结果可能导致测验不公平的问题。因此,关于CLT、CAT中个体心理特质的比较研究,相关结论尚处于争议与探索阶段。
目前,国外对CLT、CAT的等效性探讨多聚焦于对某一维度或某项具体指标的比较,而缺乏全面的对比;国内相关研究多从理论层面展开,少有实证分析。与以往研究不同,本研究一方面将通过实验对CLT、CAT的差异进行整体性比较,包括对两者测验效率、统计学特征的比较和两种测验环境对考生个体心理特质的影响研究,从而使教育工作者对这两种测验形式的优劣有更全面的理解。另一方面,依据桑代克“效果律”中有关反馈的观点,测验中的反馈不仅能为考生提供有效信息[13],而且会影响考生的测验焦虑。但是,在CLT、CAT中反馈对测验焦虑的影响有何不同,目前还鲜有研究涉及。基于此,本研究将采用双因素方差分析法,来探究不同测验环境下、有无即时反馈对测验焦虑的影响。
三 等效性研究的案例设计
1 实验被试与流程
本研究以华东地区S大学在2020-2021学年开展的“现代教育技术”课程为例进行等效性研究实验。该课程前17周为教学周,第18周为复习周,第19、20周为考试周,测验时间选在第18周进行。实验被试为文学院学习该课程的469名师范生,这些学生通过独立组测验设计的方式被随机分为四组:①有即时反馈CAT组,有学生124名;②无即时反馈CAT组,有学生128名;③有即时反馈CLT组,有学生114名;④无即时反馈CLT组,有学生103名。四组学生参加的测验均设有75道选择题(含63道单选题、12道多选题),测验时长均为50分钟。测验结束后,所有学生立即作答计算机版本的测验焦虑量表,量表回收率达到100%。
由于CAT在国内测验领域的普及程度有限,故在本次测验开始前,工作人员对参加CAT测验的考生进行了考前培训。培训分为两个部分,每部分均历时45分钟:第一部分的培训主要向考生介绍CAT的基本原理,如CAT通常是从一道中等难度的试题开始,通过动态的选题策略为每一名考生提供与其能力相匹配的试题;第二部分的培训主要向考生讲解在CAT测验过程中应该注意的问题,如不能随意切换某道试题,必须作答当前试题后才能跳转至下一题试题,且不能回顾并修改已经做过的试题。
2 测量工具
(1)测验题库
本研究中的CLT、CAT试题均来源于S大学“现代教育技术”题库。题库试题依据“现代教育技术”课程的教学目标与教学内容进行编制,试题内容涉及现代教育技术概述、现代教育技术的理论基础、教学设计与教学评价、教学媒体与信息化教学环境、网络教育资源检索、素材的采集与处理、教学课件的设计与制作、技术推动下教育的发展和演变等八个主要知识点,共设有单选题198道、多选题42道,总计240道题。
(2)CLT系统
参加本次测验的考生均已按要求修完“现代教育技术”课程。为了保证CLT、CAT在考查内容、试题难度、测验题型等方面的公平性,CLT的试卷由学科教师与教育测量学的专家共同进行编制,试题内容及认知层次与“现代教育技术”题库相符,试题的难度、区分度均体现了题库的统计学特征。同时,试题采用并列直进式(即按知识点由易到难的顺序)的排序方式,将1~63题设为单选题、64~75题设为多选题。
(3)CAT系统
本研究使用的CAT试题库已通过有效性检验,且满足单维性和局部独立性假设。CAT试题库中的试题均符合双参Logistic模型,试题参数分布合理,能满足CAT测验的实际施测需求。另外,CAT利用最初5道试题的应答结果作为初始能力,通过最大信息量法进行选题,采用极大似然估计法进行考生能力参数估计,以测验长度达到75道试题时即终止答题作为CAT测验的终止规则,而试题类型、题型顺序均与CLT相同。
(4)测验焦虑量表
测验焦虑量表(Test Anxiety Inventory,TAI)简表由美国心理学家Spielberger编制的TAI简化而成[14]。TAI简表由TAI忧虑性、情绪性分量表以及不属于任何一个分量表的五道题目组成,经过长期的实践应用,TAI简表的信效度已经得到充分验证[15]。考虑到本次实验主要用于测量考生在测验过程中的状态焦虑,不涉及考生在测验之前、之后的焦虑感受,因此本研究使用的测验焦虑量表是对TAI简表进行部分修改而成:保留了原有TAI简表中的2道试题,同时在TAI量表中筛选出3道适用于测量考生在测验中焦虑程度的试题,最终的测验焦虑量表设有五个测验焦虑指标,如表1所示。其中,每个指标按Likert四点量表计分,得分越高,表示考生的测验焦虑越高。经计算,此量表的内部一致性信度系数是0.892,表明该量表能够有效测量考生的状态焦虑程度。
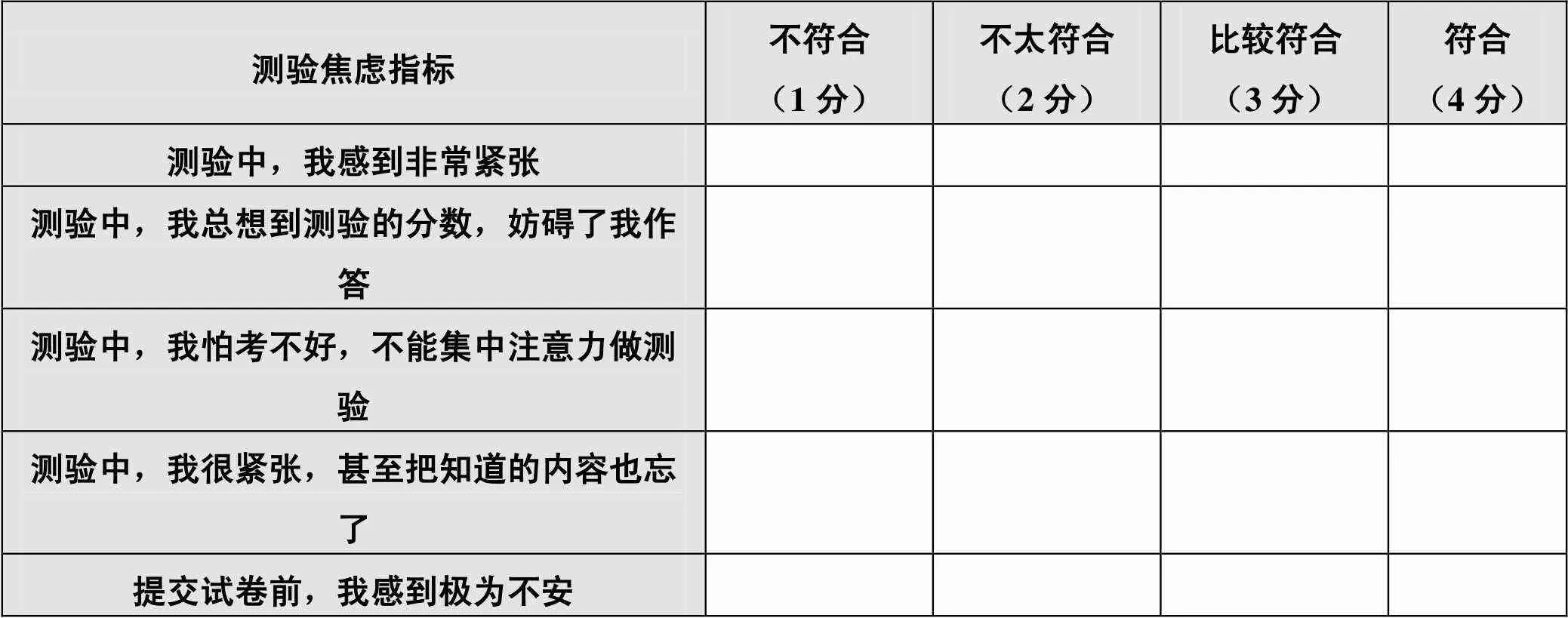
表1 测验焦虑量表
四 等效性研究的结果分析
本研究采用MySQL对四组学生(有即时反馈CAT组、无即时反馈CAT组、即时反馈CLT组和无即时反馈CLT组)参与“现代教育技术”课程CLT、CAT测验的考试成绩和所填测验焦虑量表的数据进行了统计。基于上述数据分析,本研究从测验效率、考生分数、测验信度、测验效度、个体心理特质等五个方面全方位、多角度地分析两种测验的等效性。
1 测验效率的比较
在本研究中,IRT以测量的标准误表示测量精确度,考生标准误的大小取决于测验信息函数,如公式(1)所示。在CLT中,即使两组学生(即时反馈CLT组和无即时反馈CLT组)面对的试题内容、数量相同,但对不同能力水平的考生而言,试题所提供的信息量不同,考生标准误也不同。如前所述,CAT的标准误取决于其终止规则,本研究中的CAT终止规则采用固定长度法,因此对不同能力水平的考生而言,他们参加CAT得到的测量精确度各不相同。由上可知,若要对CLT、CAT的测验效率进行比较,以CLT、CAT标准误的范围作为比较的指标更为合理。
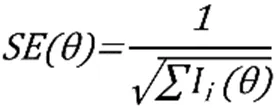
2 考生分数的比较
如前所述,本研究中的CLT、CAT试题均来源于同一个题库——S大学“现代教育技术”题库。该题库试题的相关参数在先前的研究中已进行标注,故本研究不再进行试题参数方面的比较。CLT、CAT的测验方式虽不同,但其测量目标与测量内容相同,因此本研究依然将考生分数的比较作为两种测验形式是否等效的考察维度。CLT、CAT测验中考生的能力值均依据项目反应理论计算,其范围控制在区间(-4, 4)。由于参加CLT、CAT的考生不同,实验数据无法对同组考生的分数排列顺序进行一致性比较。但因实验分组方式为随机分配,故可以比较两组考生分数的部分统计学特征是否相似,由此判断两种测验的考生分数是否具有可比性。
本研究根据实验统计获得的考生分数与频次数据,分别绘制了CLT、CAT考生分数直方图(如图1、图2所示),可以看出:CLT、CAT考生分数曲线均呈现一定程度的负偏态,但偏斜程度较小,几乎趋近于正态分布,大多数考生的能力值分布在0~1之间。本研究中的CLT、CAT属于标准参照测验,这与选拔性较强的常模参照测验不同,故测验的主要功能是考查考生对“现代教育技术”课程基础知识与基本技能的掌握情况,而不是根据分数高低对考生进行区分从而选拔出高分考生,因此考生分数呈现出略微的负偏态分布具有合理性。
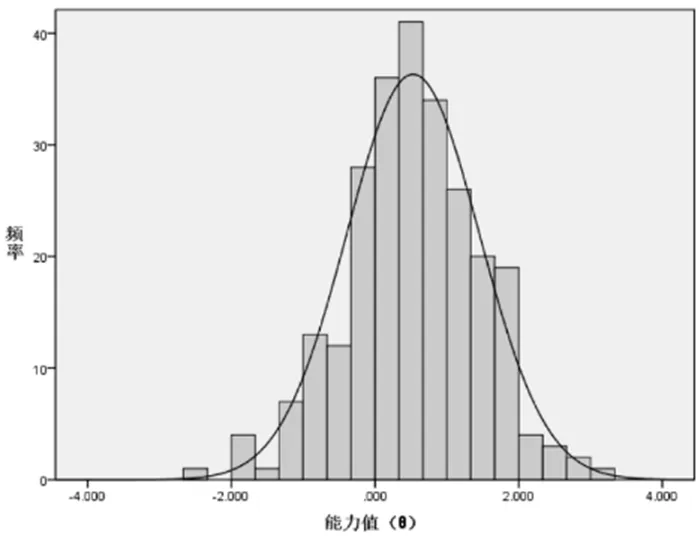
图1 CLT考生分数直方图
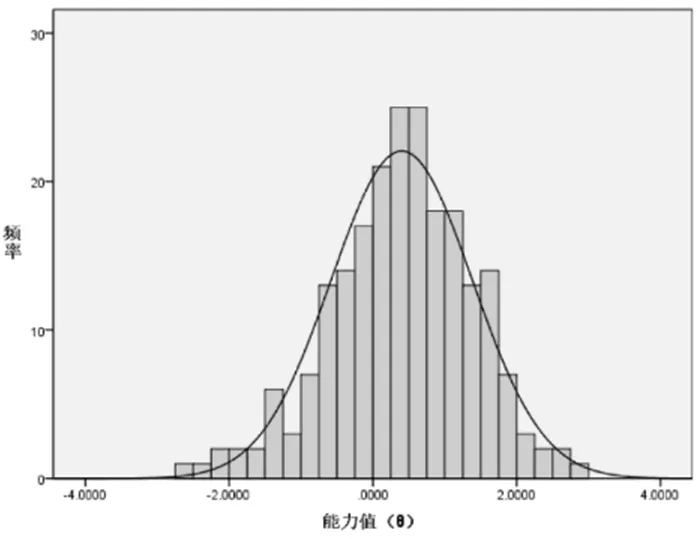
图2 CAT考生分数直方图
CLT、CAT考生分数的描述性统计如表2所示,可以看出:CLT与CAT中考生分数的平均值、最大值、最小值差异甚微,确有可比性。

表2 CAT、CLT考生分数的描述性统计
3 测验信度的比较
通过前述测验效率的比较,本研究中CLT、CAT的标准误范围已明确,而两者的信度范围可在此基础上通过公式(2)加以求解(其中,r为测验的信度系数)。经计算,本研究得到CLT、CAT的测验信度系数值,如表3所示。一般来说,当能力与学业成就测验的信度系数<0.7时,既不能用测验分数对个体做评价,也不能在组别间做比较;当信度系数>0.7时,可用于组别间比较;只当信度系数>0.85时,才可用于评价个体。由表3数据可知,CAT的测验信度系数的平均值接近于0.9,可靠性程度较高且能用于个体评价;而CLT的测验信度系数的平均值偏低,可用于组别间比较但不能用于个体评价,其测验结果的稳定性、一致性还有待商榷。
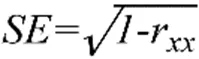

表3 CLT、CAT的测验信度系数值(rxx)
4 测验效度的比较
本研究重点关注CLT、CAT在内容效度方面的等效性。CLT、CAT的组卷方式不同:CLT试题编制由“现代教育技术”课程的任课教师与学科专家依据课程目标、丰富的教学及考试命题经验从题库中选取而成,并按知识点由易至难排列,使得本次CLT试题具有良好的内容效度;而CAT采用最大信息量法进行适应性选题,未对试题考查的内容范围加以控制,这就意味着考生的能力水平不同,其所做的试题不同,试题考查的知识点亦存在不平衡性。
针对上述情况,本研究按照考生能力水平范围分布,将参加CAT的考生能力值划分为三个区间:(1.264,3.020)为高能力值,(0.525,1.234)为中能力值,(-2.573,0.508)为低能力值;同时,选择每个区间的中间值作为考生代表,分析其所做试题的内容效度。CLT、CAT中各部分知识点的试题数量与所占比例如表4所示,可以看出:在本次测验主要考查的八个知识点中,CLT各知识点的试题数量依据题库相应知识点所占的比例进行组卷,试题设计较为科学;而CAT试题中各知识点的试题数量与CLT中各知识点的试题数量存在较大差异,且CAT中高、中、低能力值考生代表的知识点试题考查所占比例也有明显不同,可见CLT内容效度明显优于CAT。
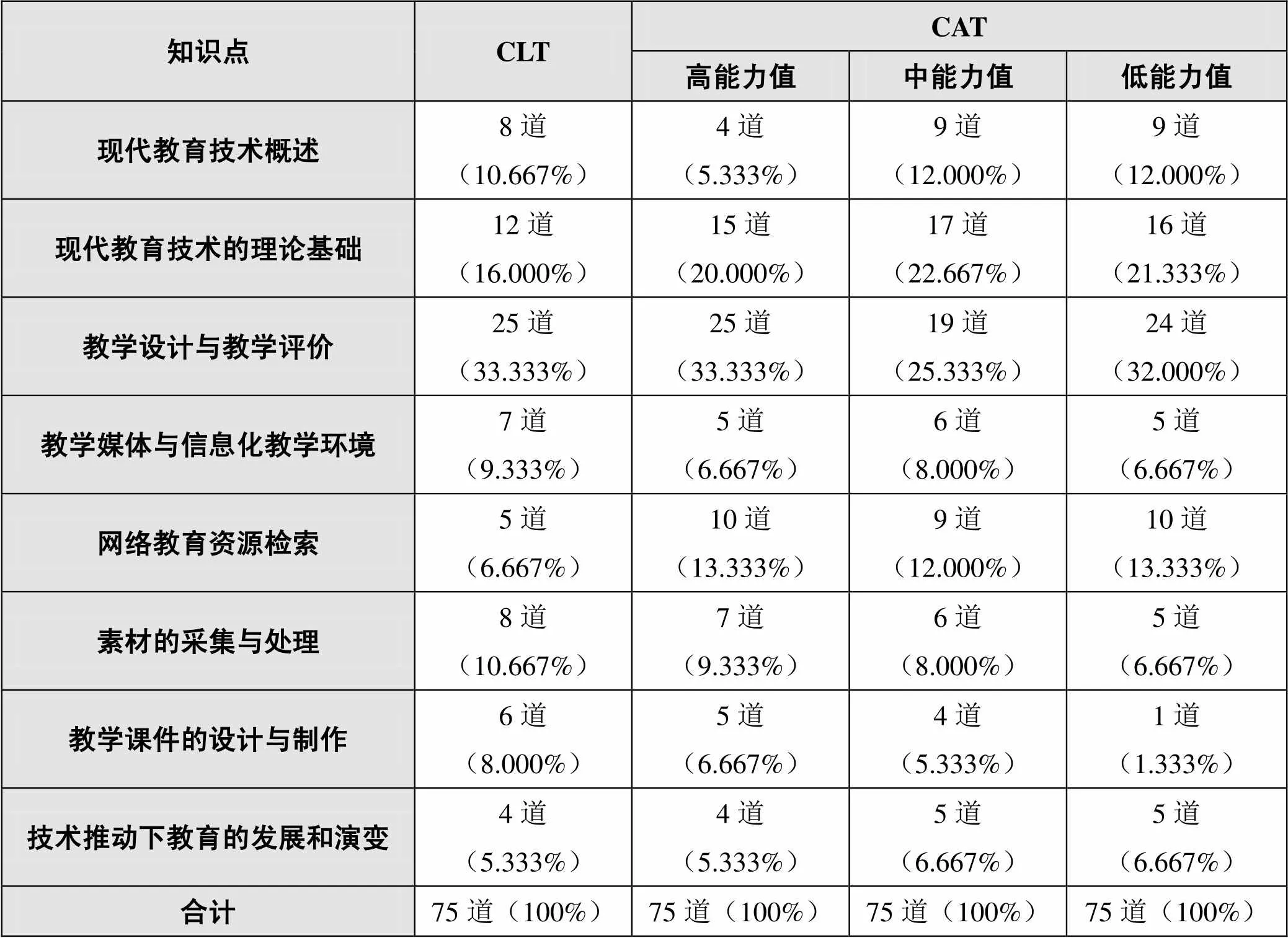
表4 CLT、CAT中各部分知识点的试题数量(道)与所占比例(%)
5 个体心理特质的比较
为了更全面地探讨CLT与CAT测验的等效性,有研究者通过双因素方差分析,验证了不同测验类型、测验有无即时反馈对考生测验焦虑的影响[16][17]。在此基础上,本研究进行了测验类型、测验有无即时反馈对测验焦虑影响的双因素方差分析,结果如表5所示,可以看出:测验类型对测验焦虑的主效应影响不显著(=0.517),测验有无即时反馈对测验焦虑的主效应影响显著(=0.000***),测验类型、测验有无即时反馈的交互效应对测验焦虑的影响显著(=0.047)。

表5 测验类型、测验有无即时反馈对测验焦虑影响的双因素方差分析
注:因变量为测验焦虑,***≤0.001。
本研究采用SPSS可视化呈现了测验类型与测验有无即时反馈的交互效应,结果如图3所示。图3显示,整体而言,有即时反馈测验中的考生平均测验焦虑明显高于无即时反馈测验中的考生;无即时反馈时,参与CLT测验的考生平均测验焦虑略高于参与CAT测验的考生,这与Fritts的研究结果一致[18];有即时反馈时,参与CLT测验的考生平均测验焦虑明显低于参与CAT测验的考生。导致出现上述结果的原因,可能在于CAT测验中的试题难度与考生的能力水平更为匹配,使有无即时反馈对考生测验焦虑水平的影响更大[19]。
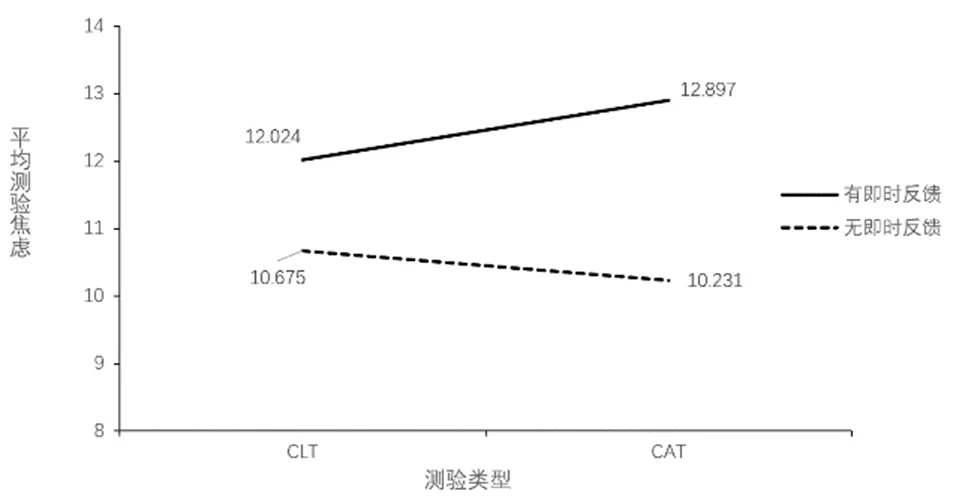
图3 测验类型与测验有无即时反馈的交互效应
五 结语
本研究基于高校师范生“现代教育技术”课程的评价内容,从测验效率、考生分数、测验信度、测验效度、个体心理特质等五个方面,对CLT、CAT测验的等效性进行了探讨。实验结果显示,两种测验中考生的分数具有可比性,且测验效果互有优劣。具体而言,CAT具有更高的测验效率和测验信度,这与以往的研究结论一致;CLT则表现出更为合理的内容效度。另外,双因素方差分析结果显示,CAT中有无即时反馈对考生测验焦虑的影响更大,参加有即时反馈的CAT考生的测验焦虑水平最高。需要指出的是,本研究中的CAT采用最大信息量法进行选题,选题过程会过度依赖题库试题的统计学特征,难以控制CAT试题知识点内容的平衡。此外,本研究中的CAT正答概率设定在=0.5水平,即考生答对或答错试题的概率均为50%,对考生而言这是一个颇具难度的测验环境。为解决上述问题,后续研究可通过变化CAT的选题策略,如增加控制试题曝光度、采用内容平衡的程序算法,来改善CAT内容效度较低的问题;同时,可以尝试将CAT正答概率设定在=0.7水平,以弱化测验环境对考生测验焦虑水平的影响。
[1]U.S. Department of Education Office of Educational Technology. Future ready learning: Reimagining the role of technology in education[OL].
[2]新华网.中共中央、国务院印发《中国教育现代化2035》[OL].
[3]教育部.中共中央国务院印发《深化新时代教育评价改革总体方案》[OL].
[4]American Educational Research Association, American Psychological Association, National Council on Measurement in Education. Standards for educational and psychological testing[M]. Washington, DC: American Educational Research Association, 2014:59-61.
[5][9]关丹丹.纸笔考试与计算机自适应考试的等效研究探讨[J].中国考试,2011,(10):13-16.
[6]高旭亮,涂冬波,王芳,等.可修改答案的计算机化自适应测验的方法[J].心理科学进展,2016,(4):654-664.
[7]邓远平,戴海琦,罗照盛.计算机自适应测验在特质焦虑量表中的运用[J].心理学探新,2014,(3):272-275、283.
[8]罗照盛.项目反应理论基础[M].北京:北京师范大学出版社,2012:1-7.
[10]黄琼,周仁来.中国学生考试焦虑的发展趋势——纵向分析与横向验证[J].中国临床心理学杂志,2019,(1):113-118.
[11][18]Fritts B E, Marszalek J M. Computerized adaptive testing, anxiety levels, and gender differences[J]. Social Psychology of Education, 2010,(3):441-458.
[12]Ortner T M, Caspers J. Consequences of test anxiety on adaptive versus fixed item testing[J]. European Journal of Psychological Assessment, 2011,(3):157-163.
[13]李中亮.桑代克成人学习理论及其启示[J].成人教育,2007,(1):30-32.
[14]Taylor J, Deane F P. Development of a short form of the test anxiety inventory (TAI)[J].Journal of General Psychology, 2002,(2):127-136.
[15]董云英,周仁来,高鑫,等.考试焦虑简表在大学生中应用的信效度[J].中国心理卫生杂志,2011,(11):872-876.
[16]Beckmann J F, Beckmann N. Effects of feedback on performance and response latencies in untimed reasoning tests[J]. Psychology Science, 2005,(2):262-278.
[17][19]Ling G, Attali Y, Finn B, et al. Is a computerized adaptive test more motivating than a fixed-item test[J]. Applied Psychological Measurement, 2017,(7):495-511.
Research on the Equivalence of Computerized Linear Test and Adaptive Test
LI Xin-yu LU Hong[Corresponding Author]
Computer-based tests have gradually become popular, while, different patterns of computer tests may produce deviations in test results when measuring the same task, leading to unfairness in educational measurement and evaluation results.Based on item response theory, this paper explored the question of whether computerized linear tests and computer adaptive tests were equivalent in testing efficiency, the statistical characteristics of test results, and the effects on the individual psychological characteristics of the test takers. Meanwhile, this paper conducted empirical research by taking the course “Modern Educational Technology” as an example. The results demonstrated that the scores of the candidates in the two tests were comparable. and the computer adaptive test had higher test efficiency and testing reliability, but the presence or absence of immediate feedback had a greater influence on examinees’ test anxiety. Nevertheless, computerized linear test had more reasonable content validity, and the presence or absence of immediate feedback had less influence on examinees’ test anxiety. The research of the paper not only scientifically analyzed whether the choice of test format in teaching evaluation was fair and reasonable, but also provided theoretical reference for the tester to choose the test format in a targeted manner according to the test scenario.
computerized linear test; computerized adaptive test; equivalence; timely feedback; test anxiety
G40-057
A
1009—8097(2022)01—0085—09
10.3969/j.issn.1009-8097.2022.01.009
李心钰,山东师范大学教育学部科研助理,硕士,研究方向为计算机教育应用,邮箱为Echo_lixinyu@163.com。
2021年6月30日

编辑:衍洐
猜你喜欢
山西教育·招考(2021年5期)2021-11-30
世界科学技术-中医药现代化(2021年7期)2021-11-04
山西教育·招考(2019年6期)2019-09-10
学生导报·初中版(2019年5期)2019-09-10
中学课程辅导·高考版(2019年4期)2019-04-25
统计与决策(2018年14期)2018-08-22
趣味(语文)(2018年7期)2018-06-26
考试周刊(2016年88期)2016-11-24
听力学及言语疾病杂志(2015年5期)2015-12-24
中国康复理论与实践(2015年7期)2015-05-09
