
移动网络满意度贬损用户预测方法研究与应用*
2022-01-25 14:11齐辉
通信技术 2021年12期
齐 辉
(中国移动通信集团河北有限公司,河北 石家庄 050000)
0 引言
随着用户对移动网络质量要求的不断提高,运营商之间的竞争越来越激烈[1-2]。为了充分发掘自身差异竞争力,达到收入增长的目的,运营商正把用户满意度作为评估用户忠诚度的一个重要维度。
净推荐值(Net Promoter Score,NPS)是度量“用户向他人推荐某品牌/产品/服务倾向”的指标,评价体系包含网络、服务和业务三大方面,本质上是一种对用户口碑及行为忠诚[3-4]的度量。NPS 问卷基于调研用户打分结果和推荐意愿,将用户分为推荐者、被动者和贬损者三类,推荐者与贬损者是对企业实际的产品口碑有影响的用户,这两部分用户在用户总数中所占百分比之差,即为NPS。
虽然在NPS 或满意度调查中有网络质量专项问卷调查,但其依然受套餐资费、服务水平等因素的影响,且各因素之间难以量化。用户主观反馈与实际体验也有差异,且调研无法避免样本比例低、用户过度友好、盲从差评等不足,还存在满意度测评结果与网络“规建维优”联动不紧密的现实矛盾[5]。同时运营商发现即使已经采取大量的网络优化措施,NPS 并未得到明显改善[6-7]。
本文首先基于获取的调研样本和相关网络侧数据进行主客观样本分离,识别有效调研样本;其次通过数据建模的方式输出满意度预测模型并进行迭代优化,根据构建模型完成全网贬损用户的预测和贬损用户画像,实现贬损用户的聚类分析;最后得到贬损用户常驻位置、质差业务等信息,使运营商能够更有针对性的采取网络优化调整措施,并配合对用户的主动关怀,来减少网络NPS的贬损型客户,提升网络NPS 和市场竞争力。
1 调研样本分离
由于不同用户对移动网络质量的认识、要求及喜好等各不相同,用户满意度调研过程中获取的调研样本并非都能如实反映真实的网络质量问题[8-9],势必存在部分用户的主观反馈会与客观体验出现较大的差异,从而导致调研样本的公正性较差。因此,有必要对调研样本进行主客观分离,识别有效调研样本,为后续满意度预测模型的构建奠定基础。
本文综合利用用户调研样本、运营域(O 域)和业务域(B 域)数据,采用数据挖掘技术实现调研样本的主客观分离。主要实现过程如下:
(1)以获取的调研样本数据为基础,从网络和业支部门分别获取调研用户的网络侧数据和业支侧数据,剔除无相应数据的调研样本;
(2)根据调研结果过滤无效样本,过滤推荐或贬损原因只选择服务或资费原因的用户,过滤推荐原因或体验不好原因只选nothing的用户,这些用户可能不是真正的推荐者或贬损者;
(3)构建网络侧用户体验关键指标,基于数据挖掘技术,将用户打分和网络侧用户体验指标进行关联分析,分离非客观调研样本,如图1 所示。
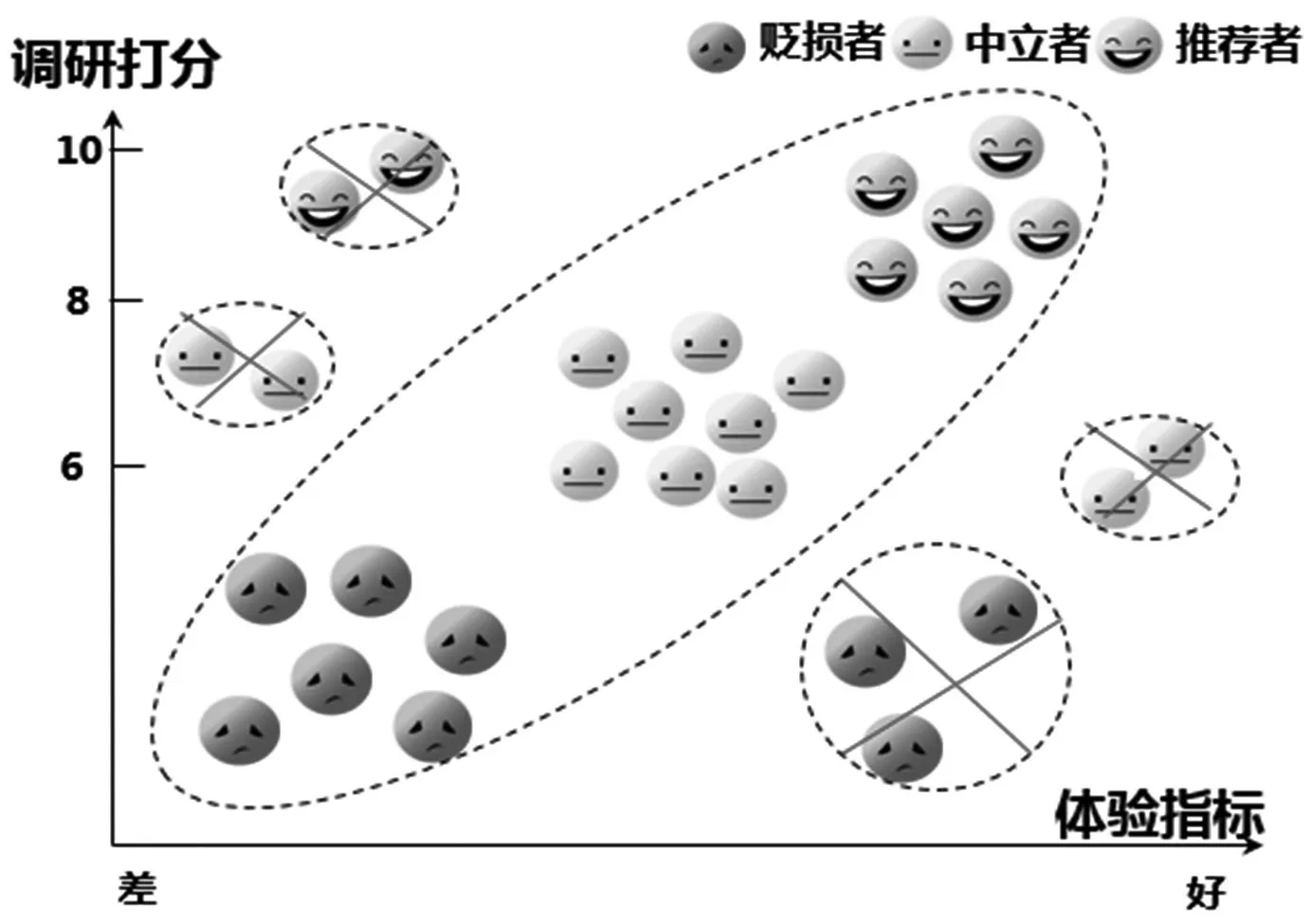
图1 调研样本分离
其中,网络侧用户体验指标考虑网页、视频、游戏和即时通信四大类业务,判定规则为:
(1)页面下载感知优良率=1-页面下载速率质差次数/页面下载速率总次数;
(2)视频下载感知优良率=1-视频下载速率质差次数/视频下载速率总次数;
(3)即时通信时延感知优良率=1-即时通信响应时延质差次数/即时通信响应时延总次数;
(4)游戏交互时延感知优良率=1-游戏交互时延质差次数/游戏交互时延总次数;
(5)用户体验感知优良率=页面下载感知优良率×0.3+视频下载感知优良率×0.5+即时通信时延感知优良率×0.15+游戏交互时延感知优良率×0.05,指标≥90%为体验优秀,指标≥70%为体验良好,其他的为体验差;
(6)将调研用户结果与用户体系感知优良率进行比较,调研结果为推荐者的用户体验感知优良率≥90%,调研结果为贬损者的用户体验感知优良率<70%的判定为客观样本,用户体验感知优良率差但调研结果为推荐者的用户判定为好感用户,用户体验感知优良率好但调研结果为贬损者的用户判定为差感用户;
(7)经过以上步骤过滤后的调研样本作为后续满意度预测模型的输入样本。
2 贬损用户预测模型构建
基于调研样本分离结果,得到有效的主观调研样本,将其与用户客观网络体验数据进行主客观关联建模,构建网络NPS 预测模型并进行迭代优化,从而识别网络潜在的贬损用户[8]。
模型构建的主要内容如下文所述。
(1)指标数据合并。将各业务、各粒度表(天、周、月)按照宽表(schema)顺序合并,每个移动台国际综合业务数字网号码(Mobile Subscriber Integrated Services Digital NetworkNumber,MSISDN)对应一条记录,得到全网用户指标宽表数据,其中指标数据来源于统一深度报文检测(Deep Packet Inspection,DPI)采集的核心网单据和业支相关用户数据。
(2)主客观数据关联。将用户指标宽表数据和调研样本数据按MSISDN 进行关联得到调研用户的主客观关联建模数据,原则上主客观数据需要在时间维度及区域维度上保持一致性。
(3)NPS 标签确定。为了能够对模型的学习提供原始的用户标签数据,需要按照用户调研分数将用户进行分类,其中0-6 分为贬损用户(Detractor);7-10 分为非贬损用户(Non-detractor),分别标记为0 和1。
(4)样本分区。对于预测型分类方法,模型的准确率定义为在给定测试集上的被模型正确分类的测试样本的百分比。对于每个测试样本,将已知的类标号与该样本的模型学习类比较。将原始数据集分为两部分,一部分为训练集(80%),另一部分为测试集(20%)。
(5)模型算法与输出逻辑。结合用户在各业务层面的体验感知构建建模指标,将用户的客观数据(网络侧数据和业支侧数据)和主观数据(调研结果)进行关联。通过分类算法训练出能区分Detractor 用户和Non-detractor 用户的有效规则并进行验证,并基于模型规则预测全网用户所属的类别(Detractor 或Non-detractor)。
3 贬损用户识别和聚类分析
为了精准识别潜在的贬损用户,采用基于随机森林的算法[10-11]进行贬损用户预测,具体分为如下几个步骤。
3.1 预测模型建立
预测模型建立的流程如下文所述。
(1)假设调研样本一共有M1=5 000 个,数据业务指标集为M2=50 个。
(2)选样本:按照调研样本的8 ∶2 划分训练集(用于模型训练)和测试集(用于模型验证),则训练集对应的样本数共4 000 个,在这4 000 个样本中,用随机且有放回的方式抽取4 000 次,作为一个样本集。因为有放回,所以一个样本集中实际样本数可能会少于4 000 个。
(3)选指标:从指标项中随机抽取d个指标,d默认等于M2的开平方。
(4)定门限:决策树中每一项指标,通过机器学习,基于基尼(Gini)系数判别找到最佳的切分点(即贬损门限),即为构成一棵判断是否有贬损的决策树。
(5)生成树:用如上选取的样本集以及随机抽取的d项指标及门限,生成一棵决策树。
(6)建模型:重复步骤2 到步骤5 共k次,k≤800,形成包含k颗决策树的大森林,然后通过不同步长(默认50)分成多个小森林,用训练集中的用户在每个小森林中进行预测,最终选择预测结果好的小森林作为最终的决策树集合。
(7)看评估:将测试集中的1 000 个用户,通过模型进行预测,并和实际结果比对,得出预测模型的查全率和查准率。
3.2 贬损用户预测
3.2.1 决策树模型应用
进行现网用户预测时,用预测用户的每个特征和决策树中的特征进行比对,当用户的特征指标超过贬损门限时,就会认为此用户具有贬损倾向。
3.2.2 输出贬损用户
用户遍历完k颗决策树,也即k个“评委”对该用户进行判定,最终算出用户贬损的置信度=贬损问题决策树/k,如果大于阈值P(通常为0.6),即定位是贬损用户,决策树中如果判定为贬损以后即停止判定,进行下一个决策树判定,如图2 所示。

图2 决策树判定
识别贬损用户后,为了便于分析和处理,需要对贬损用户进行聚类获取其常驻小区信息。根据贬损用户驻留的小区业务量和频度的统计结果,按照如下规则输出贬损用户的常驻小区。
用户数据业务常驻小区识别规则如下:
(1)按天统计每个贬损用户在每个小区的数据业务的流量,统计周期一般为7 天。
(2)以用户为单位计算统计周期内每个小区的业务天数(有流量的天数)和数据业务总流量。
(3)以用户为单位对每个小区的业务总流量进行从高到底排序,输出小区流量排名次序。
(4)以用户为单位计算每个小区业务总流量占比和流量百分位排名。
(5)对于一个贬损用户,某小区同时满足,业务天数≥2,小区流量排名次序≤5,小区业务流量占比≥10%,流量百分位排名≤80%,则该小区为此贬损用户的数据业务常驻小区。
用户语音业务常驻小区识别规则与数据业务相似,区别仅在于统计指标为语音呼叫次数。根据贬损用户的数据和语音业务常驻小区识别结果,统计每一个小区去重后的数据或语音业务贬损用户数。如果一个小区的贬损用户数超过设定门限,则判定该小区贬损用户常驻小区。
为了便于网络问题优化处理,可以对贬损用户业务属性进行识别,方法如下:
(1)在统计周期内统计每个用户(小区)的视频/网页/即时通信/语音/游戏的业务量,统计周期一般为7 天,视频/网页/即时通信业务量为时长,语音业务量为呼叫次数,游戏业务量为游戏时长;
(2)基于每个业务对所有的用户(小区)的业务量从高到低进行百分位排名;
(3)如果用户(小区)的该业务的百分位排名小于20%,则认为该用户(小区)为该业务的重度用户(小区)。
4 结果与分析
4.1 调研样本数量的选取
调研样本数据作为模型训练的关键输入之一,其数量和质量对模型的预测准确性有很大影响。根据统计学中样本容量的定理可知:唯一完全精确的样本是普查,随机样本并不精确,必定会产生抽样误差,随机样本容量越大,精确度越高,抽样误差越小[12-13]。但是考虑到时间、人力成本,实际中不可能对全部用户进行调研,通过图3 所示样本数量与抽样误差之间的对应关系可知,样本数量X=5 000 时的抽样误差较小,建议实际调研中X选择5 000 或10 000,本文采用X=5 000的样本。

图3 样本数量与抽样误差的关系
4.2 评估指标的选取
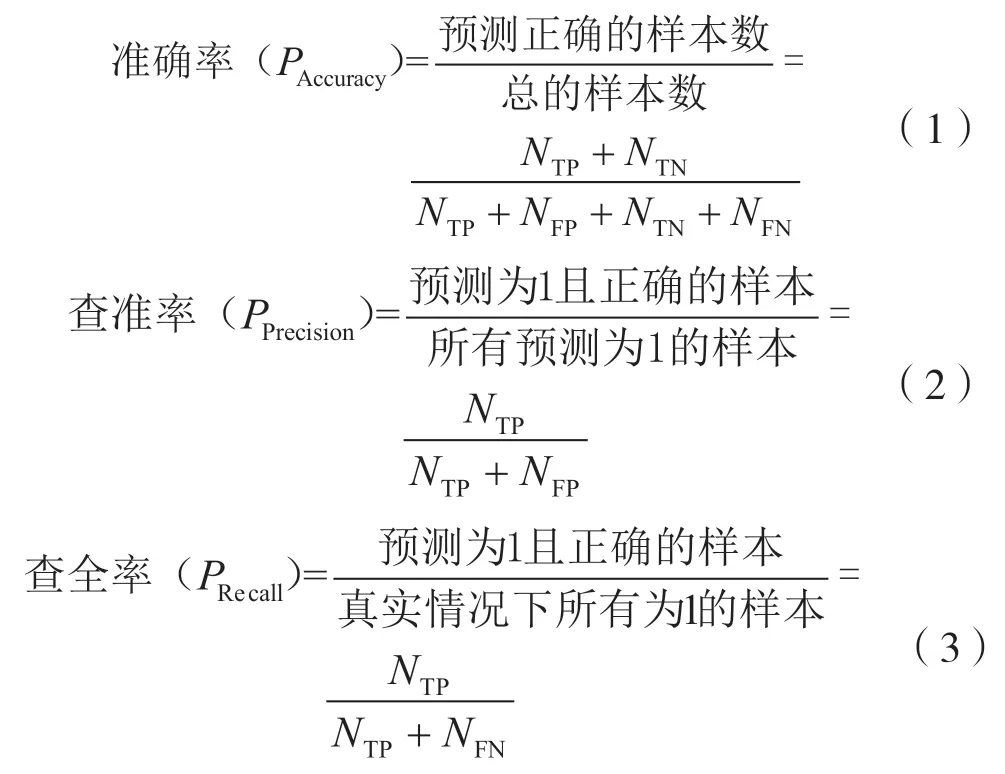
为了有效评估贬损用户预测结果的准确性,本文在预测准确率(Accuracy)评估的基础上,引入查准率(Precision)和查全率(Recall)指标进行综合评估[14]。假设P 表示预测某样本为1(贬损用户),N 表示预测某样本为0(非贬损用户),T 表示预测正确,F 表示预测错误。其中TP 代表的是正确的标记为1,即预测为贬损用户,实际也是贬损用户,NTP表示对应样本的数量;FP 代表的是错误的标记为1,即预测为贬损用户,实际为非贬损用户,NFP表示对应样本的数量;FN 代表的是错误的标记为0,即预测为非贬损用户,实际为贬损用户,NFN表示对应样本的数量;TN 代表的是正确的标记为0,即预测为非贬损用户,实际为非贬损用户,NTN代表对应样本的数量。则有:
本文基于5 000 个调研样本,选取3 个地市分别进行预测,评估模型准确性,结果如表1 所示。
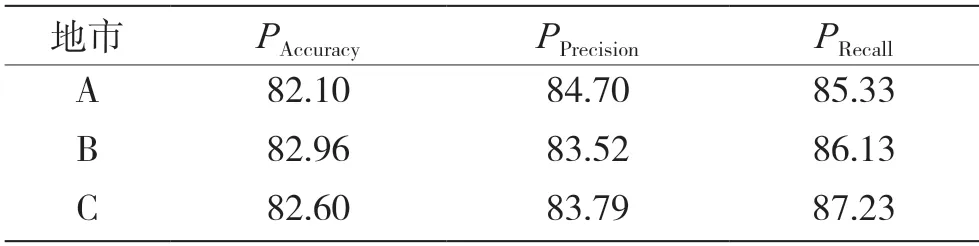
表1 贬损用户预测结果 %
4.3 贬损用户聚类识别准确性评估
为了评估贬损用户聚类后的常驻小区与实际的差异,分别选择3 个地市各200 个小区进行现场验证。小区筛选原则:预测贬损用户数量≥30;常驻小区贬损用户占比≥10%;贬损用户聚焦小区常驻用户数≥100。整体情况如表2 所示。

表2 贬损用户聚焦小区与实际匹配情况
5 结语
对于运营商来说,网络质量满意度管理工作是一件需要持续投入的重要工作,也是通过用户问题牵引网络质量改善的重要手段[15],精准、快速地识别潜在的贬损用户就显得非常重要。本文结合实际工作经验,通过调研样本主客观分离、多维数据关联及基于随机森林算法的贬损用户模型构建等方法,构建了一种贬损用户预测的机制,并通过实验证明了其有效性。
从实际应用情况看,文中选取的调研样本主要源于移动集团或省公司三方调研数据,并不包括日常用户的投诉数据,在调研样本的多样性方面还存在一定问题。文中仅实现了贬损预测模型和常驻信息的功能,还不具备端到端的问题分析能力,对于一线网络优化人员的支撑力度不够,需要结合无线相关数据,如告警、性能、MR 等数据实现问题小区的关联分析。同时当前贬损用户聚集小区预测的准确率不足90%,在匹配规则和模型调优方面仍需进行加强。后续仍需持续加强预测模型的优化,同时结合贬损用户聚类情况进一步研究问题定界和分析的能力,支撑运营商有针对性地进行网络优化调整,提前消除潜在用户投诉,提升网络整体质量和用户满意度。
猜你喜欢
当代水产(2021年8期)2021-11-04
人大建设(2019年6期)2019-10-08
人大建设(2019年2期)2019-07-13
人大建设(2018年10期)2018-12-07
电子制作(2018年16期)2018-09-26
中国医药科学(2017年18期)2018-02-07
科学与财富(2016年32期)2017-03-04
电子制作(2017年24期)2017-02-02
决策与信息·下旬刊(2013年1期)2013-03-11
网吧世界(2009年1期)2009-02-26
