
基于卷积神经网络的服饰纹样风格自动标注
2022-01-26 06:58刘静伟
纺织高校基础科学学报 2021年4期
刘 雪,刘静伟,赵 莹,薛 媛
(西安工程大学 服装与艺术设计学院,陕西 西安 710048)
0 引 言
随着生活水平的提高,人们越来越注重个性的表达。中国历史上,每个时代特有的文化属性造就了不同的时代特征,创造出很多经典的风格表达[1],民族文化图案作为风格的载体,是中华民族的宝贵财富,对民族文化图案进行语义标注与分析,是挖掘其文化价值,实现文化图案数字化深入研究以及进行再创作与应用的基础[2]。
传统的方法在图像标注领域已经有了一定进展,但其需要人工选择特征,会造成信息缺失,存在标注精度不够、召回率低的问题[3]。卷积神经网络具有图像特征自学习方面的优势,近年来已经被广泛应用在计算机视觉领域[4-6],取得了令人满意的实际效果[7]。卷积神经网络模型具有较强的泛化能力并且能够通过池化运算降低网络的空间维度,在图像分类方面优于其他神经网络模型[8],多位学者基于卷积神经网络进行了纹样自动分类标注,其中文献[8-9]对瑶族纹样符号进行了分类标注,文献[10]对壮族纹样中的元素类别进行了自动标注,贾晓军等对蓝色印花布进行分类标注[11],但以上研究均针对纹样本体进行了分类标注,对于纹样风格自动标注的研究较少。本文自建的纹样风格数据集中,每个纹样图像包含多个风格语义标签,本质上可以把其看作一个多标签学习的问题[12],即对于给定的包含多个语义标签的图像,计算机在通过一定的操作后,对其完成多个标签的标注[13]。很多研究者直接将卷积神经网络应用在多标签分类任务上[14-16],AlexNet[17]是近年来效果较好的一个卷积神经网络模型,许多之后提出的方法[18-19]也是在其基础上进行的研究与改进,并在其他领域实现了图像多标签语义自动标注,对本研究具有参考意义。文献[20]实现了电影风格多标签自动标注,其中视觉表示部分也构建了类似于AlexNet的卷积神经网络,也可尝试将此方法应用在纹样风格多标签自动标注上。
基于此,本文以卷积神经网络为基础,对AlexNet模型结构及参数进行调整,并将文献[20]中提出的方法应用在纹样风格自动标注方面,提出了2种纹样风格多标签自动标注模型,并在自建的纹样风格数据集上进行训练与测试,通过量化评估选取最优模型。
1 标注算法与模型结构
1.1 多标签标注算法
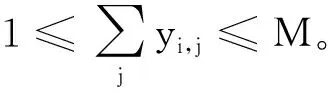
1.2 模型结构
本文采用的2种模型均参照AlexNet结构,在其基础上进行调整。将2种模型分别命名为Model-1、Model-2,模型结构见图1。
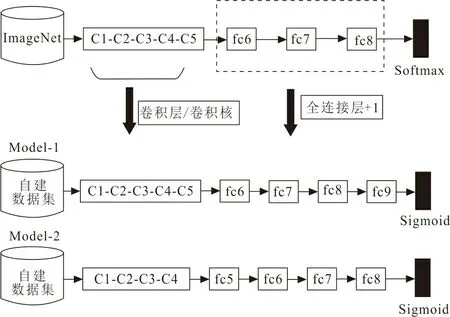
图 1 模型结构Fig.1 Model structure
1.2.1 Model-1模型结构 Model-1在AlexNet结构基础上进行调整,首先经过5个卷积层获取图像视觉特征,之后经过4个全连接层,最后,根据多标签损失函数得到多个标注标签。模型的参数与AlexNet模型基本类似,对其中部分参数进行试验和分析,做出以下修改:①在AlexNet模型结构基础上将5个卷积层的卷积核个数缩小至原来的一半;②修改了全连接层,增加了一个全连接层,全连接层输出大小为4 608、256、128、9,输出层节点为9个节点,即对应自建纹样风格数据集的9个语义风格标签;③用Sigmoid激活函数替换AlexNet中的softmax激活函数。AlexNet最后一层选用的softmax激活函数适用于多类图像分类,各类概率依赖于其他类,当一个类的概率增大时,另一个类的概率则会减少。但是对于多标签问题,一个图像可以有多个标签,希望概率彼此独立,此时使用softmax激活函数并不合适,而Sigmoid激活函数可以在内部创建n个模型(其中n为总类数),每个类可以作为一个模型,从而可以预测出每个类的概率。
1.2.2 Model-2模型结构 文献[20]中视觉表示部分构建了类似于AlexNet的卷积神经网络。模型首先经过4个卷积层,每个卷积层后接一个最大池化层,得到图像的视觉特征,其中4个卷积层中的卷积核大小均为5,卷积核个数分别为16、32、64、64,最大池化层中池化大小均为2。之后经过4个全连接层,使用Dropout防止过拟合,概率设置为0.5,全连接层输出大小为9 216、128、64、9。输出层输出节点为9个节点,对应自建纹样数据集的9个风格语义标签,使用Sigmoid激活函数,最后根据多标签排名损失函数得到多个标签。
2 实验和结果分析
2.1 数据集
数据集为本文自建的清代服饰植物纹样风格数据集,数据集中纹样图像主要是从服饰上进行抠取与预处理。数据集中包含3 000张大小为256×256的彩色纹样图像,以及明丽、素雅、繁缛、简洁、灵动、饱满、庄重、华丽、质朴等9个风格语义标签,平均每个纹样图像包含语义标签2.35个,按8∶2的比例划分训练集与测试集。将数据集转换为结构化格式,包含所有训练图像的名称及其对应的真实标签,建立图像与图像对应标签之间的关系。其次对图像的标注标签进行预处理,图像对应的所有风格类型一共有9种可能性,因此对于每个图像,将有9个目标,即纹样图像是否属于该类型,这9个目标值为0或1,并转换为纹样图像的目标数组。
2.2 模型训练
实验环境为:Linux操作系统,GPU型号为Tesla T4,显存容量为15 GiB。代码的实现均基于Keras框架,采用序贯模型。首先在Sequential的输入层需要明确一个关于输入数据shape的参数,之后隐藏层便可以自动推导出中间数据的shape。输出层等于风格类型的数量,所以有9个神经元。2个模型在模型编译时均使用binary_crossentropy作为损失函数。为了判断学习状态,从训练集中随机选择600张图像作为验证集,分别对2个模型参数进行多次实验,实验结果表明Model-1使用ADAM作为优化器、迭代的大小(batch_size)设置为32、迭代次数(epoch)设置为50、学习率设置为0.01时模型训练效果较好;同样Model-2模型使用与Model-1相同的参数时,模型训练效果较好。模型训练完成后,将模型分别保存为Model-1、Model-2,在测试时进行调用。
2.3 评价指标
模型的客观评价指标采用文献[21]的评价方法,采用平均准确率P、平均召回率R以及准确率和召回率的调和平均数F1作为实验结果的评价标准,其中F1值越大,图像标注性能越好。为了分析标注性能,对测试集中每一个标签求平均值得到平均准确率、平均召回率;P、R、F1值的计算公式为
(1)
(2)
F1=2PR/(P+R)
(3)
2.4 实验结果
加载训练好的模型在测试集上进行预测,Model-1与Model-2在模型测试阶段的实现一致。测试完成后分别计算2个模型预测结果的P、R、F1值,表1为2种标注方法的实验结果。
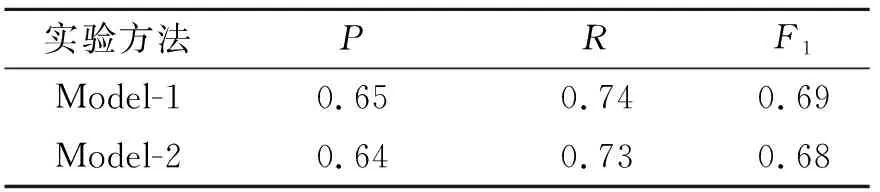
表 1 各图像标注方法实验结果
表1中Model-1评估结果最优,因此选择Model-1作为本文的纹样风格自动标注模型。图2为Model-1模型的部分预测结果。模型输出为预测的概率向量,表示测试样本与9类风格语义相关联的概率,因为样本平均标注词的个数是2.35,向上取整,所以选择3个概率输出值最高的标注词作为每个测试样本的标注结果。图2(a)的前3个输出风格语义及对应的概率分别为素雅(0.997)、简洁(0.91)、灵动(0.783),图2(b)的前3个输出风格语义及对应的概率分别为饱满(1.0)、庄重(1.0)、华丽(1.0),图2(c)的前3个输出风格语义及对应的概率分别为明丽(0.987)、饱满(0.827)、质朴(0.17),图2(d)的前3个输出风格语义及对应的概率分别为饱满(1.0)、华丽(1.0)、庄重(0.999),图2(e)的前3个输出风格语义及对应的概率分别为素雅(0.998)、简洁(0.358)、灵动(0.354),图2(f)的前3个输出风格语义及对应的概率分别为饱满(0.999)、华丽(0.974)、素雅(0.843)。

(a) 预测图1 (b) 预测图2 (c) 预测图3
模型整体预测效果较好,但也存在以下问题:按平均值选择3个最高的概率输出值作为标注结果,会存在个别标注结果与测试样本不完全匹配的问题。针对以上问题,可以尝试优化输出方式进行改进。
3 结 论
提出了一种基于卷积神经网络的纹样风格多标签自动标注方法,以AlexNet模型结构为基础,提出了2种纹样自动标注模型,采用P、R、F1评价指标对模型测试结果进行了量化评估。结果表明,Model-1在P、R、F13个指标上的值均高于Model-2,最终选择Model-1作为纹样风格自动标注模型。然而以下方面值得改进与研究:
1) 使用更大规模的数据集进行模型训练,进一步提高模型预测精度。
2) 针对卷积神经网络的结构作优化调整,不断提升模型标注效果。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
紫禁城(2020年6期)2020-07-24
西夏学(2020年2期)2020-01-24
长江学术(2016年4期)2016-03-11
Coco薇(2015年10期)2015-10-19
长江学术(2015年1期)2015-02-27
