
跨模态行人重识别的对称网络算法 *
2022-01-26 12:56张艳,相旭,唐俊,王年,屈磊
国防科技大学学报 2022年1期
张 艳,相 旭,唐 俊,王 年,屈 磊
(安徽大学 电子信息工程学院, 安徽 合肥 230601)
行人重识别旨在多摄像头多场景下寻找同一个目标人物,因其在目标追踪、公共安防、视频监控等领域起到重要的作用,行人重识别受到了学者们的普遍关注。行人重识别难点主要在于视角变化、遮挡、行人姿态变化、光照差异和背景杂乱等,目前已经提出了大量行人重识别算法[1-6],推动了行人重识别的快速发展。传统的行人重识别属于单模态的检索任务,是仅在可见光图像之间进行检索的技术。但随着社会发展,传统行人重识别并不能满足社会需求,跨模态行人重识别便从行人重识别衍生出来,它比传统行人重识别更具有挑战性。跨模态行人重识别旨在红外光图像与可见光图像之间匹配同一个目标人物的技术,跨模态行人重识别作为一个新兴的研究课题, 已成为当前的一个研究热点。
在夜间,可见光摄像机无法捕获足够的行人外观信息,行人的信息由红外摄像机或深度摄像机来获取。由于红外摄像机和可见光摄像机成像机制不同,两种模态之间存在巨大的模态差异。可见光图像和红外光图像示例如图1所示,两类图像在外观上有很大的不同,可见光图像比红外光图像包含更多的颜色信息,模态差异成为跨模态行人重识别需要解决的另一个难题。

图1 可见光图像和红外光图像示例Fig.1 Examples of visible images and infrared images
可见光模态和红外光模态之间的模态差异可分为特征差异和外观差异。为了减小特征差异,文献[7-9]试图利用统一的嵌入空间来对齐跨模态特征,但忽略了两个模态之间巨大的外观差异。文献[7,10]使用生成对抗网络(Generative Adversarial Networks,GAN)来实现跨模态的图像转换,从而减少外观差异的影响。虽然由GAN生成的虚拟图像与原始图像相似,但是并不能保证生成与身份相关的细节信息。文献[11]采用双流网络分别处理不同模态的图像,并将隐藏层卷积特征与网络输出特征进行融合以增强特征的鉴别能力。这表明隐藏层卷积特征具有描述结构和空间信息的能力,利用隐藏层卷积特征来缩小两种模态间差异是一种有效的解决方案。
针对模态间和模态内差异问题,本文提出基于对称网络的跨模态行人重识别算法。针对模态间差异,受文献[12]的启发,本文算法将基于概率分布的模态混淆这一思想与对抗学习结合,为可见光模态和红外光模态分别构造分类器,构成了对称网络,通过最小化两个分类器输出概率分布的差异来产生模态不变特征,从而达到模态混淆的目的;本文还提出混合三元损失,并在对称网络的不同深度对齐特征,以减少模态内差异带来的影响;针对可见光模态和红外光模态之间存在的外观差异,本文利用隐藏层卷积特征增强网络学习空间结构信息的能力,以减少外观差异带来的影响。
1 方法实现
1.1 问题描述
从可见光图像集V中选取一个样本Vi,再从红外光图像集T中选取一个样本Tj,其中Vi和Tj是同一个人y在不同模态下的图像,y∈Y,Y是行人身份(IDentification, ID)的集合。将Vi和Tj输入到主干网络中提取模态特定特征,然后将特征嵌入公共空间中,获得特征X,最后输入到对应的分类器中,获得相应的概率分布Di、Dj。在检索过程中,给定一个待检索图像,通过网络提取图像特征X,然后将待检索行人图像特征和检索库中的图像特征逐一进行距离相似性度量计算,根据距离的大小排序得到前k张与待检索行人最为相似的图像。
1.2 网络结构
本文提出了一个对称网络,网络由生成器和鉴别器组成,网络结构如图2所示。生成器由两列独立的ResNet50和两列独立的全连接层构成,生成器模块通过两列ResNet50提取特定模态下的特征,全连接层将特定模态特征嵌入公共空间中,学习两种模态下的公共特征,以减小模态间差异的影响;生成器通过学习数据分布来减小模态差异,混淆鉴别器。鉴别器由可见光分类器和红外光分类器组成,通过各分类器得到相应的类别概率分布以区分数据来自哪一模态。本文算法通过对鉴别器与生成器进行交替训练,减小可见光模态和红外光模态间的模态差异。
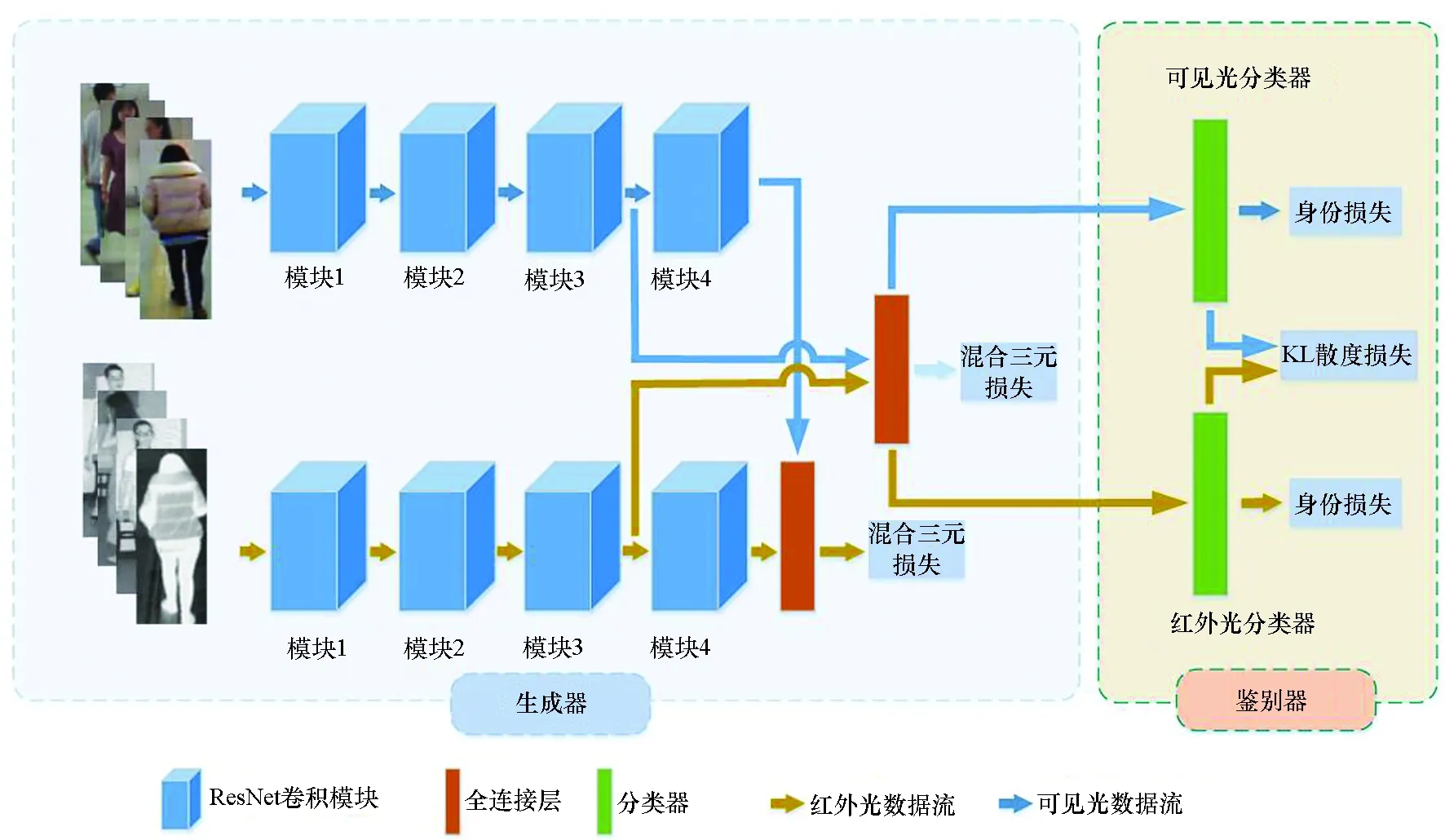
图2 本文提出的网络结构Fig.2 Network structure proposed in this paper
1.3 基于类别概率分布的模态混淆
从V、T中分别选取一个样本Vi和Tj,并将它们输入到对应的ResNet50分支中提取模态特定特征,然后输入到对应的分类器中,获得Vi和Tj的概率分布Di和Dj。如果将Tj的特征输入到可见光分类器中获得D′j,则概率分布D′j与Di是不同的,甚至有很大的偏差,因为可见光分类器无法很好地对红外光特征进行分类。据此,本文认为特定模态分类器只能对特定模态特征进行准确的分类,在已知Vi和Tj以及y的情况下,分类器能够通过D′j与Di概率分布的差异来判定数据来自哪个模态。本文使用KL散度来衡量D′j与Di之间的概率分布差异,定义KL散度损失为:
Lkl=KL(D′j,Di)
(1)
式中,D′j与Di是分类器输出的概率分布。
本文采用交叉熵损失作为分类器的身份损失,则两个分类器的身份损失为:
(2)
式中,N1和N2是该训练批次下相应模态下的样本数量,等号右边第一项是可见光分类器身份损失,第二项是红外光分类器身份损失。
1.4 混合三元损失
为了解决模态间差异和模态内差异问题,常见的思路是提取特定模态下特征,然后通过三元损失来缩小模态间差异和模态内差异。图3为模态间差异和模态内差异示意图,其中模态间差异指可见光域图像和红外光域图像因成像原理不同而导致成像后图像上的差异;模态内差异是指在同一模态下由于行人的姿态不同、行人类别不同、遮挡、摄像机视角变化等造成的差异。图3中,Va代表样本1的可见光图像,Vp代表样本1姿态不同的另一可见光图像,Vn代表样本2的可见光图像,Vn与Va包含的ID信息不同;而Ta、Tp代表样本1的红外光图像,Tn代表样本2的红外光图像。可见光域图像V与红外光域图像T之间存在模态间差异;Va、Vp、Vn之间,以及Ta、Tp、Tn之间存在模态内差异。为解决这些差异,文献[11,13]将三元损失分为模态间损失和模态内损失两部分。
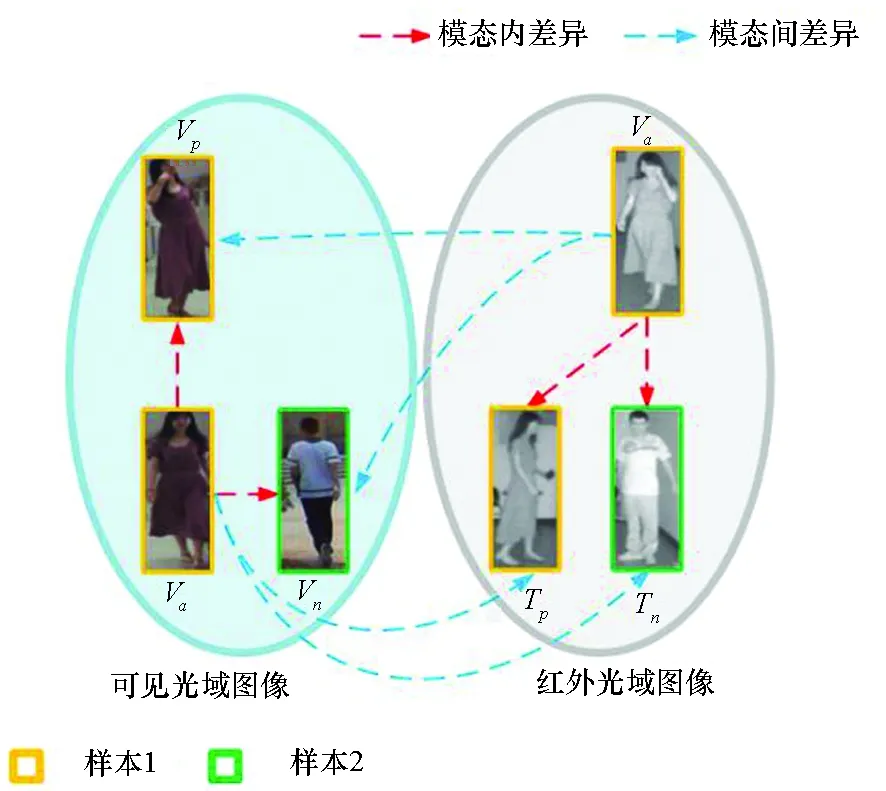
图3 模态间差异和模态内差异示意图Fig.3 Schematic diagram of the inter-modal differences and the intra-modal differences
与之前方法不同,本文将三元损失与对抗学习结合,提出了一种混合三元损失来减小模态间的差异。当通过对抗学习达到模态混淆时,不再需要区分样本来自哪个模态,即在不区分模态的情况下选择正样本特征和负样本特征,以进行特征对齐,减小模态差异。根据文献[14],混合三元损失定义为:
(3)
式中,Xa代表锚点样本的特征,Xp代表正样本的特征,Xa代表负样本的特征,D代表样本特征之间的欧式距离,ρ为混合三元损失中预定义的最小间隔。设置每个训练批次大小为P·K,其中选取P个行人ID身份,并从训练集中随机为每个行人ID选取K张可见光图像和K张红外光图像,在将所有的样本图像输入网络后,获得相应特征,本文采用欧氏距离度量的方式来衡量样本特征之间相似度的大小。首先选取一个特征作为锚点样本特征;然后从中选取与锚点样本特征ID信息相同,但是与锚点样本特征欧氏距离最远的正样本特征作为最不相似的正样本特征;最后从中选取与锚点样本特征ID信息不同,且与锚点样本特征欧氏距离最近的负样本特征作为最相似的负样本特征,以此组成混合三元损失来训练网络。
根据文献[11]的思想,为了使网络能够学习到更多的空间结构信息,减小颜色差异的影响,本文采用隐藏层卷积特征即来自ResNet50模块3的特征作为后面全连接层的输入。在ResNet50的模块3和模块4的输出层使用混合三元损失来优化网络,则总的混合三元损失定义为:
Ltriall=Ltri1+Ltri2
(4)
式中,Ltri1是表示模块3的混合三元损失,Ltri2是表示模块4的混合三元损失。
1.5 训练细节
本文的网络属于端到端的对称网络结构,具体的算法步骤如下所示。
Step1:训练网络的生成器和鉴别器,使网络能对样本正确分类。使用身份损失和混合三元损失训练网络,使网络能够捕获模态可鉴别特征。则该步骤总损失为:
L1=Lid+βLtriall
(5)
Step2:训练鉴别器,固定生成器的参数,通过最大化D′j与Di的概率分布差异,提升网络分辨图片模态属性的能力。该步骤总损失为:
L2=Lid-αLkl
(6)
Step3:训练生成器以最小化D′j与Di的概率分布差异。此时冻结鉴别器的参数,在训练过程中,该步骤循环三次以平衡生成器和鉴别器。总损失为:
L3=αLkl+βLtriall
(7)
在对样本正确分类前提下,通过对生成器和鉴别器的交替训练,使D′j与Di的概率分布差异最小化,达到模态混淆的目的。
2 实验设置
本节首先介绍实验所用的数据集和评价标准,其次介绍实验环境及参数设置。
2.1 数据集及评价标准
2.1.1 跨模态行人重识别数据集介绍
SYSU-MM01[15]是由4个可见光摄像机和2个红外光摄像机收集的大规模跨模态数据集。该数据集一共有室内和室外两种场景,训练集包含395个行人ID数据,其中包括11 909张红外光图像和22 258张可见光图像。测试集包含96个行人ID数据,本文采用文献[15]的设置,将测试集3 803张红外图像作为查询集,并随机选择可见光图像作为测试集。
RegDB[16]共有412个行人ID数据,这些数据由双摄像头系统捕获。每个ID包含10张可见光图像和10张红外光图像。采用文献[8,13]的设定,将数据集随机分为两个部分,每部分随机选择一半数据分别用于训练和测试。
2.1.2 评价标准
本文采用首位命中率(Rank-k,R-k)、平均准确率均值(mean Average Precision,mAP)和累积匹配特征曲线 (Cumulative Matching Curve,CMC)作为评价指标。CMC为在检索库图像集合中与待查询图像匹配相似度最高的前k张图片命中查询图像的概率,其常以R-k的形式体现。其中mAP的定义为:
(8)
式中,Q代表查询集数量,CMC可认为是Rank list的可视化。
(9)
2.2 实验环境及参数设置
本文实验环境如下:操作系统为ubuntu16.04,深度学习框架为Pytorch1.1,编程语言为python3.6,GPU为NVIDIA GeForce RTX 2080Ti。本文采用ResNet50作为骨干网络,并采用在ImageNet上预训练的参数初始化网络权重,行人的特征维度设置为1 024。在数据处理阶段,将输入图像大小调整为288像素×144像素,然后对边缘进行10层补零填充,将其随机左右翻转并裁剪为288像素×144像素进行数据增广,设置K=4,P=16,N=P·K=2N1=2N2张图像构成一个批次。本文使用自适应梯度优化器对网络模型进行优化,其中指数衰减率被设置为b1=0.9,b2=0.999。网络在训练时,遍历整个数据集总次数为80次,初始学习速率设置为0.000 01,然后在第50次中衰减为原来的0.1倍。对于本文提出的混合三元损失,预定义的最小间隔均设置为ρ=0.5,对于KL系数α和混合三元损失系数β,设置为α=1和β=1.4。
3 实验结果及分析
本节首先对比分析本文算法与现有的跨模态行人重识别算法,最后,通过全面的消融研究,来分析模中每个组成部分对算法性能的影响。
3.1 与现有算法对比
将本文方法与跨模态行人重识别算法[7-9,11,13,15,17-18]等实验结果进行对比,对比结果见表1,表1中加粗数值是最大值。由表1可知,本文算法提取到的特征更具有表征能力,这证明了本文算法的有效性。
对比跨模态算法[8-9,15,17],本文算法有很大的提升。本文算法在SYSU-MM01数据集的R-1结果比文献[13]的跨模态行人重识别算法的R-1结果提升10.98%,比文献[7]的跨模态行人重识别算法的结果提升8.96%;mAP结果也比文献[7]的算法结果提升10.02%,与文献[7,13]的两种对抗学习相关的方法对比,证明了本文算法的有效性。本文在这两个数据集上的结果比文献[11]的跨模态行人重识别算法有所提升,在RegDB的R-1结果比文献[11]的算法提升1.16%,R-20提升1.59%,对比文献[11]的算法通过跨层融合的方式来使用隐藏层特征,本文使用隐藏层特征的策略更为有效。本文算法在SYSU-MM01数据集上mAP的结果略低于文献[11]的算法,但检索算法在实际应用中更注重于R-k指标,R-k代表在样本按照相似度排序后,前k个样本的命中概率,更能体现检索算法的实用性和检索准确度。本文算法在R-1,R-10,R-20的结果均优于其他跨模态算法,通过R-k的结果足以说明本文算法的有效性和鲁棒性。
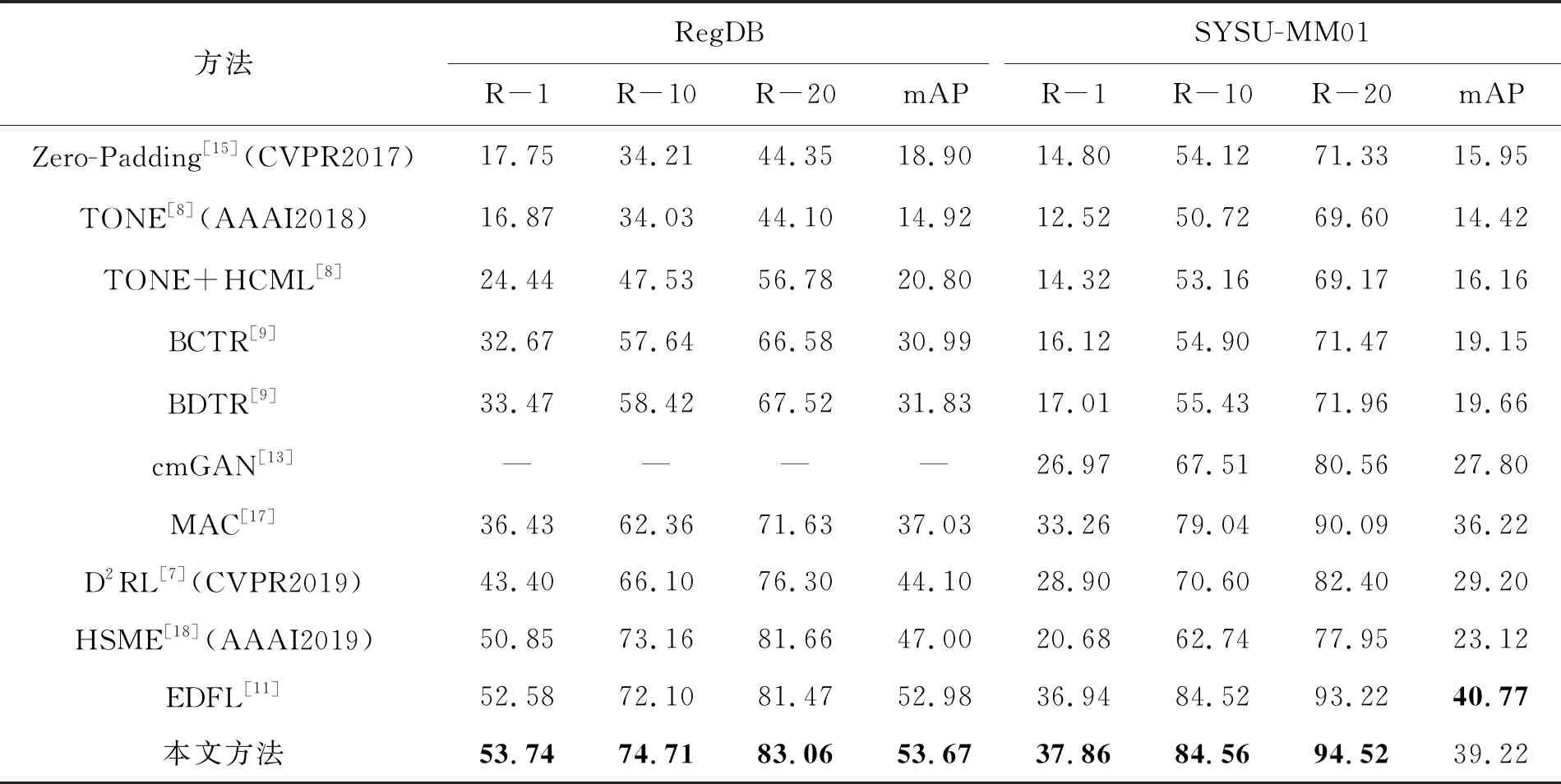
表1 在RegDB 数据集和SYSU-MM01数据集上的比较实验结果
3.2 消融研究
首先,研究参数α和β取值对模型性能的影响。不同α值在RegDB数据集上的结果如图4所示。当α=1时,网络的性能达到了最优,R-1结果为53.74%,mAP结果为53.67%。不同α值在SYSU-MM01数据集上的结果如图5所示。当α=1时, R-1结果最高为37.86%,mAP结果为39.22%,此时在该数据集上的结果达到了最优。
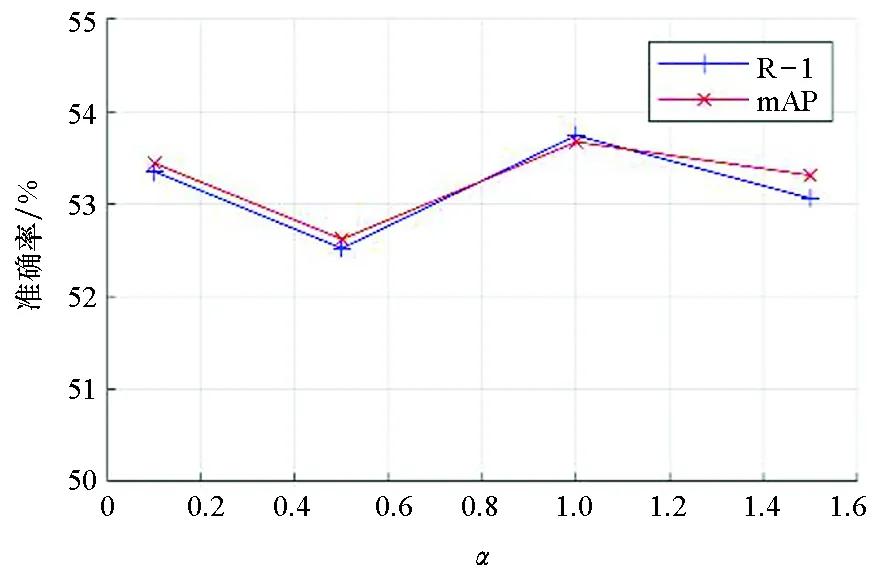
图4 不同α值在RegDB数据集上的结果Fig.4 Results of different α values on the RegDB dataset
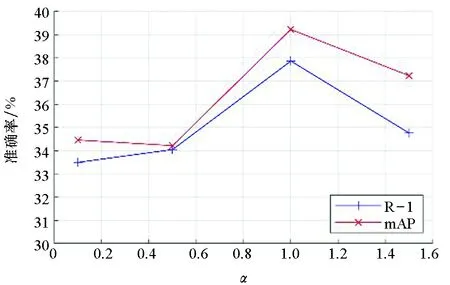
图5 不同α值在SYSU-MM01数据集上的结果Fig.5 Results of different α values on the SYSU-MM01 dataset
图6和图7给出了在β不同取值下,网络在两个数据集上的性能,当β=1.4时,网络性能达到最优。当β=1.4时,在RegDB数据集上, R-1为53.40%,mAP为53.75%;在SYSU-MM01上,R-1为37.86%,mAP为39.22 %。从以上实验还可以看出,本文提出的模型在α和β较宽泛的取值范围内都能取得较好的结果,这也反映了模型的鲁棒性。
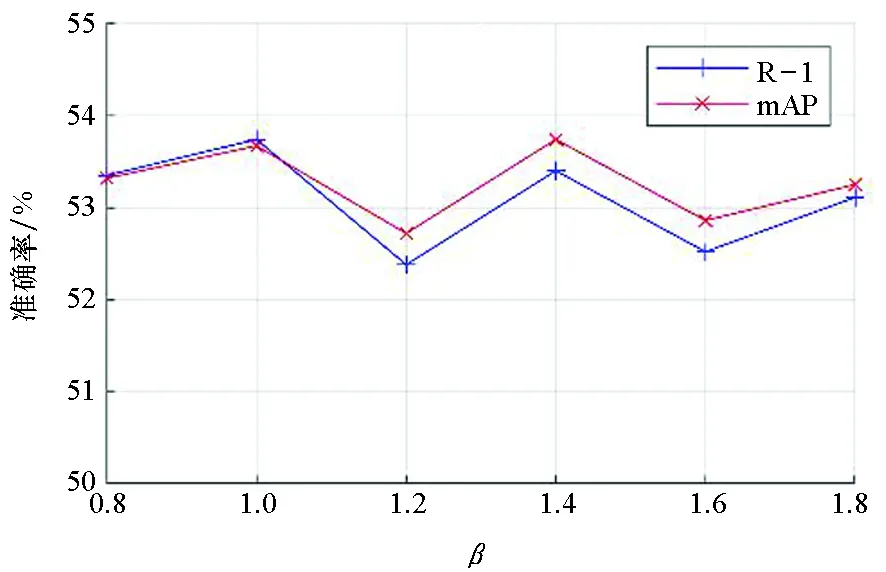
图6 不同β值在RegDB数据集上的结果Fig.6 Results of different β values on the RegDB dataset
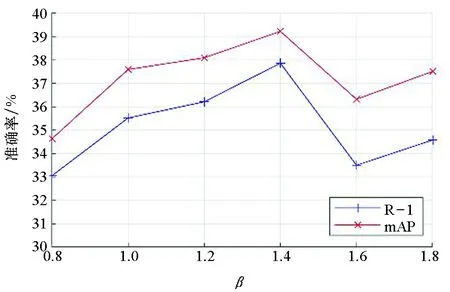
图7 不同β值在SYSU-MM01数据集上的结果Fig.7 Results of different β values on the SYSU-MM01 dataset
本文方法在SYSU-MM01数据集上的消融实验结果见表2。基准网络(baseline)由两个并行独立的ResNet50以及两列共享的全连接层构成,baseline仅采用身份损失。baseline的R-1结果为12.96%,mAP为17.12%。第二组实验仅增加混合三元损失模块(即mtri,模块4的特征),与baseline结果相比,增加混合三元损失模块后, R-1结果提升了10.07%,mAP结果提升了9.13%,这证明了混合三元损失的有效性。此外,将第二组实验与第三组实验(baseline+AL+mtri(4) ,AL代表基于概率分布的模态混淆)进行对比,当增加基于概率分布的模态混淆模块后,R-1的结果提升了3.87%,mAP也提升了5.86%,这也证明了基于概率分布的模态混淆模块的有效性。
baseline+AL+tri(4,3)从不同深度优化网络(即从模块4,3优化网络但不使用隐藏层特征),对比baseline+AL+mtri(4)的结果,其R-1结果提升了6.02%,mAP提升了2.72%;对比baseline+AL+mtri(3,4)(即从模块3,4优化网络,使用隐藏层特征)和baseline+AL+mtri(3)实验结果,在都采用隐藏层特征前提下,证明了从不同深度使用混合三元损失优化网络,可以使网络获得更好的表征能力。对比baseline+AL+mtri(3)和baseline+AL+mtri(4)的结果,当网络采用隐藏层特征时,baseline+AL+mtri(3)的R-1结果提升了3.37%,mAP结果提升了2.06%;对比baseline+AL+mtri(3,4)和baseline+AL+mtri(4,3)结果,从不同深度优化网络的前提下,(3,4)使用隐藏层特征,(4,3)不使用隐藏层特征,证明了隐藏层特征可以使网络更好地学习空间结构信息。
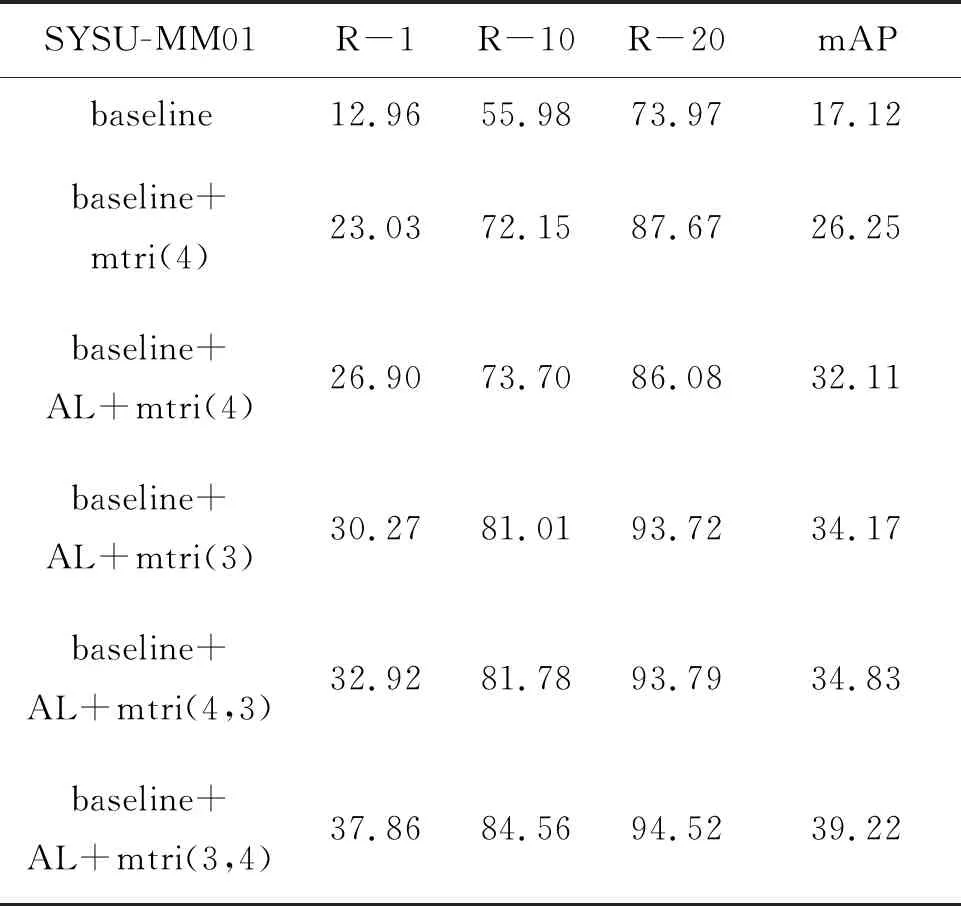
表2 在SYSU-MM01数据集上的消融实验结果
4 结论
本文根据基于概率分布的模态混淆思想,提出了基于对称网络的跨模态行人重识别算法。将基于概率分布的模态混淆、对抗学习以及混合三元损失结合在一起,解决模态间差异和模态内差异,提高网络对空间结构的关注度,降低外观差异带来的负面影响。此外,充分利用了隐藏层特征,提高了特征对空间结构的表征能力。在RegDB和SYSU-MM01的实验结果证明了本文方法的有效性。
猜你喜欢
红外技术(2022年11期)2022-11-25
中国典型病例大全(2022年7期)2022-04-22
电子产品世界(2022年4期)2022-04-21
意林(2021年5期)2021-04-18
纺织科学研究(2021年1期)2021-03-19
计算机系统应用(2021年2期)2021-02-23
电子技术与软件工程(2019年18期)2019-11-18
扬子江(2019年1期)2019-03-08
电子技术与软件工程(2017年14期)2017-09-08
小天使·一年级语数英综合(2017年6期)2017-06-07
