
基于特征工程和支持向量机的甲烷预混火焰当量比测量
2022-02-18 06:44陈长友傅钰雯涂沛驰舒文杨健晟
数据采集与处理 2022年1期
陈长友,傅钰雯,涂沛驰,舒文,杨健晟
(1.贵州大学电气工程学院,贵阳 550025;2.贵州交通职业技术学院物流工程系,贵阳 550025)
引 言
化石燃料是我国最主要的能源形式。随着我国经济发展对能源需求与日俱增,在提高化石燃料燃烧效率和减少污染物排放方面都提出了更高的要求。在燃烧工业领域中,检测燃烧炉内火焰相关参数判断燃烧状态,有效控制燃料与空气的供给关系,是提高能源转换效率和减少燃烧污染物生成的有效手段。其中,燃空当量比是表征燃料与空气混合的一个重要参数,是确定系统性能的因素之一,也是影响燃烧污染物生成的重要因数[1]。因此测量火焰当量比对节能减排具有重大的意义。
火焰是燃料和空气燃烧过程中释放的可见光和热辐射的形式,是燃烧过程的综合表征。对于碳氢火焰而言,火焰发出的蓝绿光是由于燃烧反应中产生的激发态自由基CH(*430 nm)和C2(*516 nm)等回归基态时在可见光谱内释放相应光子引起的化学发光,而火焰的红黄光是不完全燃烧生成的碳黑在连续光谱段的黑体辐射[2]。有研究表明,碳氢火焰自由基CH*和C2*的化学发光与预混火焰燃烧当量比之间存在密切的关系,通过测量自由基CH*与C2*浓度比值可以间接测量当量比[2⁃4];Clark等[5]研究发现自由基C2*与CH*的比值可以用来近似表示当量比,Haber等[6]也证实了自由基化学发光CH*/C2*的比值与当量比具有相似的响应。由于颜色是光谱的表征形式,所以通过测量火焰颜色也可以间接获得自由基化学发光信息。2008年,Huang等[7]发现在RGB(Red⁃green⁃blue)颜色模型中,预混甲烷火焰图像的蓝色和绿色通道的中值强度与CH*和C2*化学发光强度非常匹配,以此为依据提出了首个基于火焰颜色测量火焰当量比的软测量模型,该模型以蓝色/绿色(B/G)的比值作为输入,以对应火焰当量比值作为模型输出,通过线性拟合建立B/G与当量比的函数关系。随后,Huang等利用该方法分别对甲烷和乙烯两种燃料在不同当量比下的化学发光进行测量,通过对比传统的光谱仪法和滤波片法,证实了在RGB模型下的B/G值可以用来测量燃空当量比[8]。通过颜色建模测量当量比方法对成像设备要求低、操作简单、数据处理便捷,因此很快受到其他研究者的关注。2014年,Mi⁃gliorini等[9]利用光谱仪法、滤波片法和数字颜色建模法,对不同当量比下甲烷预混火焰中CH*和自由基化学发光进行了测量,实验结果验证了数字颜色建模法对燃空当量比测量的可行性。目前,基于颜色建模的火焰当量比检测方法已经应用于多类基础燃烧研究,并取得了一定的成果[10⁃14]。
由于成像颜色会受到彩色图像传感器光谱响应函数差异的影响,2019年Yang等[15]等通过标定相机传感器的光谱响应,改进了利用蓝色和绿色通道测量CH*和化学发光的方法,优化了基于图像颜色与化学发光之间的数学模型。2020年龙凯等[16]试图通过白平衡处理校正成像颜色来提高火焰当量比颜色模型的普适性。Trindade等[17]也曾设计了4种不同的颜色输入构建模型,试图通过对比寻找最优的表征火焰当量比模型的数字颜色输入。由于成像过程影响因素较多,如光学镜头色偏、图像传感器滤波片光谱特性不一致、制造工艺差异以及插值算法区别等,使得这些方法仅通过单一颜色比值简单拟合得到的颜色与当量比软测量模型存在较大的不确定性及误差。近年来,随着机器学习智能算法的快速发展,为燃烧过程中生成的中态产物、终态产物以及相关参数的软测量建模提供了新的方法。以支持向量(Support vector machine,SVM)、BP神经网络和极限学习(Extreme learning machine,ELM)等为代表机器学习算法已经逐步应用于燃烧诊断领域。例如:通过提取研究对象时间和空间上的相关特征,包括颜色、纹理和运动等,进一步应用机器学习算法实现火焰、烟雾和燃料的识别以及燃烧污染物排放预测,并取得很好的识别率和回归预测效果[16⁃21];通过融合火焰静态和动态特征,基于ELM算法对特征数据集进行训练与测试,进而实现火焰的检测,实验结果表明,该方法在环境干扰较小的情况下具有较高的时效性和检测精度;把目标集中在算法的改进与优化方面,通过优化算法来提高识别率和降低预测误差[22]。目前这些研究主要基于特定数据集或特定应用取得了良好的表现性能,并未有通过机器学习火焰颜色特征检测火焰当量比的相关研究。
因此,本文基于火焰颜色⁃自由基化学发光⁃当量比之间的物理转换原理,通过特征工程构建火焰多维颜色特征数据,利用SVM机器学习算法实现甲烷预混火焰燃烧当量比的软测量。
1 实验方法
1.1 实验对象与平台
甲烷是天然气、煤层气等能源的主要成分,为此本文主要针对甲烷预混火焰燃烧当量比测量展开实验研究。实验平台包括3个部分。
(1)燃烧实验平台
本文使用的燃烧实验平台为自制本生灯预混/扩散火焰基础燃烧装置,包括空气压缩机、甲烷(99.9%)气瓶、气体流量计、压力表、预混管以及燃烧器(本生灯)等装置组成,基本架构如图1所示。其中气体流量计MFC300最大量程为500 sccm,精度高达±0.5%FS,本生灯燃烧管口直径为6 mm。试验中通过Labview控制流量计使得甲烷(CH4)与空气(Air)分别从不同的气路管道输送至预混管进行充分混合(为保证混合均匀,每组工况点燃前预混5 min),然后送至本生灯进行点燃燃烧。
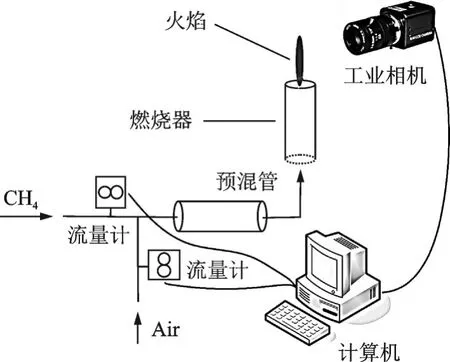
图1 燃烧平台基本示意图Fig.1 Schematic of combustion platform
(2)成像实验平台
本文所采用的成像装置为WP⁃030 CMOS微型工业相机,5 Gb/s传输宽带,采集传输速度可达2×109像素/s,最高帧率达到815帧/s,最高像素500万,内置64 MB缓存,确保图像数据传输更加稳定,成像镜头光圈为F1.4、焦距f=15~30 mm。
(3)数据样本处理及训练平台
数据样本处理及训练平台采用的是CPU为Intel酷睿I5⁃4210U、可超频至2.7 GHz的计算机、64位操作系统,编程软件为MATLAB。
1.2 技术路线
建模过程的技术路线大致可分为火焰图像数据采集、火焰颜色特征工程构建与SVM训练数据建模3个部分,如图2所示。火焰图像使用WP⁃030微型工业相机进行采集并将其送至计算机,在计算机上运用数字图像处理技术对采集的火焰图像进行预处理,以获取火焰图像目标区域,即感兴趣区域(Region of interest,RoI)。进一步在RoI提取不同颜色空间多颜色特征,以此设计并构建火焰颜色特征工程。最后,在构建的火焰颜色特征工程基础上结合改进的SVM算法训练得到甲烷预混火焰燃烧当量比测量模型。
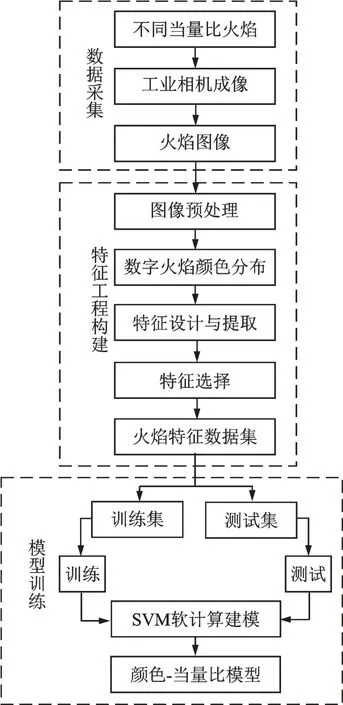
图2 本文提出的甲烷预混火焰当量比测量系统框图Fig.2 Diagram of the proposed methane premixed flame equivalent ratio measurement system
1.3 样本数据采集
对于数据样本采集,采用WP⁃030工业相机采集了当量比Φ从0.7~1.5不同工况下的火焰图像,其中,甲烷流量恒定设置为100 sccm,根据理论空燃比、实际空燃比以及当量比之间的变换关系,例如Φ=1.0时,CH4为100 sccm,此时空气为171 sccm;通过改变空气流量值进而实现不燃烧工况;在稳定燃烧状态下以当量比间隔Φ=0.05为一组样本工况进行采集。成像快门时间设置为0.005 s、帧率为100帧/s,每种当量比工况连续采集时间t=1 s数据,共计100张火焰图像。所有工况下共采集1 800张火焰图像数据,不同工况火焰图像样本数据示例如图3所示。
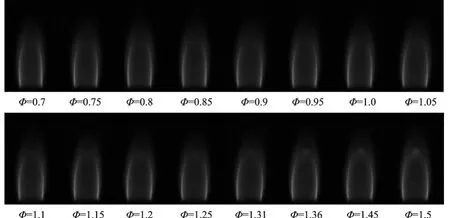
图3 不同工况火焰图像数据Fig.3 Flame image data under different working conditions
2 特征工程构建
2.1 图像预处理
随着当量比值增加,从图3不同工况火焰图像数据可以明显看出,火焰图像在Φ=1.15~1.5工况下火焰顶部存在黄色区域,由于黄色火焰与蓝色火焰产生机理完全不同,为了避免这种黄色火焰对当量比软测量实验结果造成影响,需要采用相关图像处理技术对火焰图像进行预处理。本文根据预混火焰与扩散火焰的数字火焰颜色分布(Digital flame colour distribu⁃tion,DFCD)[13]存 在 明 显 的 分 布 差 异,利 用DFCD技术实现火焰区域的分割,并对分割的火焰图像进行滤波处理以滤除图像背景噪声的干扰。考虑到由于中值滤波算法在去除图像噪声同时也会对图像细节造成影响,因此对初步处理后RGB图像进行中值滤波后的区域图像不能视为目标区域,需要进一步将原始图像在RGB、HSV、YCbCr不同颜色空间模型分布下的各颜色通道值分别与DFCD技术处理之后得到的二值图像进行逻辑乘运算,通过逻辑运算最终得到火焰图像目标区域,详细的火焰图像目标区域获取算法流程如图4所示。其中,HSV是根据颜色的直观特性得到一种颜色空间模型,具体指色相(Hue)分量H、饱和度(Satura⁃tion)分 量S和明度(Value)分量V[23],而对 于YCbCr颜色空间模型,其中Y指亮度分量,Cb指蓝色色度分量,Cr指红色色度分量,YCbCr模型来源于YUV色彩模型[24]。根据算法流程使用MATLAB软件编程实现火焰图像RoI获取,如图5所示。其中图5(b,c)清晰地展示了采用DFCD技术可以很好地实现黄色火焰与蓝色火焰的分离以及火焰图像目标区域的获取。
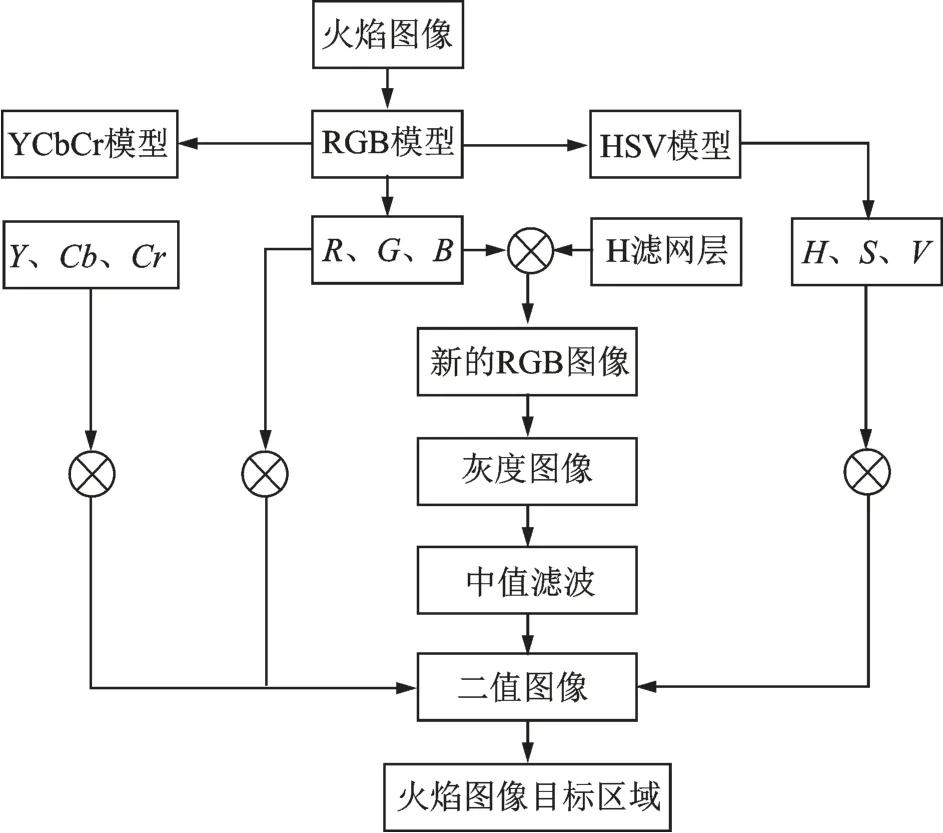
图4 基于DFCD技术的火焰图像目标区域获取算法流程Fig.4 Diagram of flame RoI using DFCD

图5 基于DFCD技术的火焰图像分割结果Fig.5 Flame image segmentation by DFCD
2.2 特征设计与提取
对于火焰颜色特征提取,常用的颜色空间模型有RGB、HSV和YCbCr等,火焰图像在不同的颜色空间模型下具有不同的颜色分布,其中RGB应用最为广泛,并且HSV和YCbCr颜色空间模型可以由RGB颜色模型通过相应的线性变换或者非线性变换得到[25⁃26]。
通过图像预处理阶段获取火焰图像ROI,设计并提取甲烷燃烧预混火焰图像特征:选取不同颜色空间模型下的基本颜色分量及相互间比值作为颜色特征,以RGB颜色空间模型为例,设计了R、G、B、B/G、R/(R+B+G)等12维火焰颜色特征,其中R、G、B分别指RGB颜色模型中的红色分量、绿色分量和蓝色分量,类似地提取HSV和YCbCr颜色空间模型的颜色特征,设计并提取了36维火焰图像颜色特征,如表1所示。

表1 火焰图像颜色特征Table 1 Color features of flame image
2.3 特征选择
特征选择是从多种特征中选择出较为有效的特征,即数据挖据,是特征工程构建中的关键环节之一。因为特征的选择对甲烷预混火焰燃烧当量比测量模型的表现性能具有重要的影响,主要体现在模型计算复杂度和泛化能力2个方面。为此,本文采用基于Spearman[27]相关性分析和随机森林算法(Random forest,RF)[28⁃29]相结合手段实现特征的降维处理。
2.3.1 基于Spearman的特征选择
对于特征提取的36维火焰颜色特征,采用统计学习理论中的Spearman相关性分析剔除冗余特征,即该类特征所包含的信息可以从其他特征中推演出来或者存在一些特征它们所包含的信息具有相似性,Spearman相关系数法通过计算特征之间的相关系数进而筛选出相关性较小的特征,其基本原理为

式中:di表示秩序;N表示样本容量;以RGB颜色空间模型的颜色特征为例,计算其12维颜色特征Spearman相关系数,得到火焰颜色特征之间相关系数矩阵如表2所示。
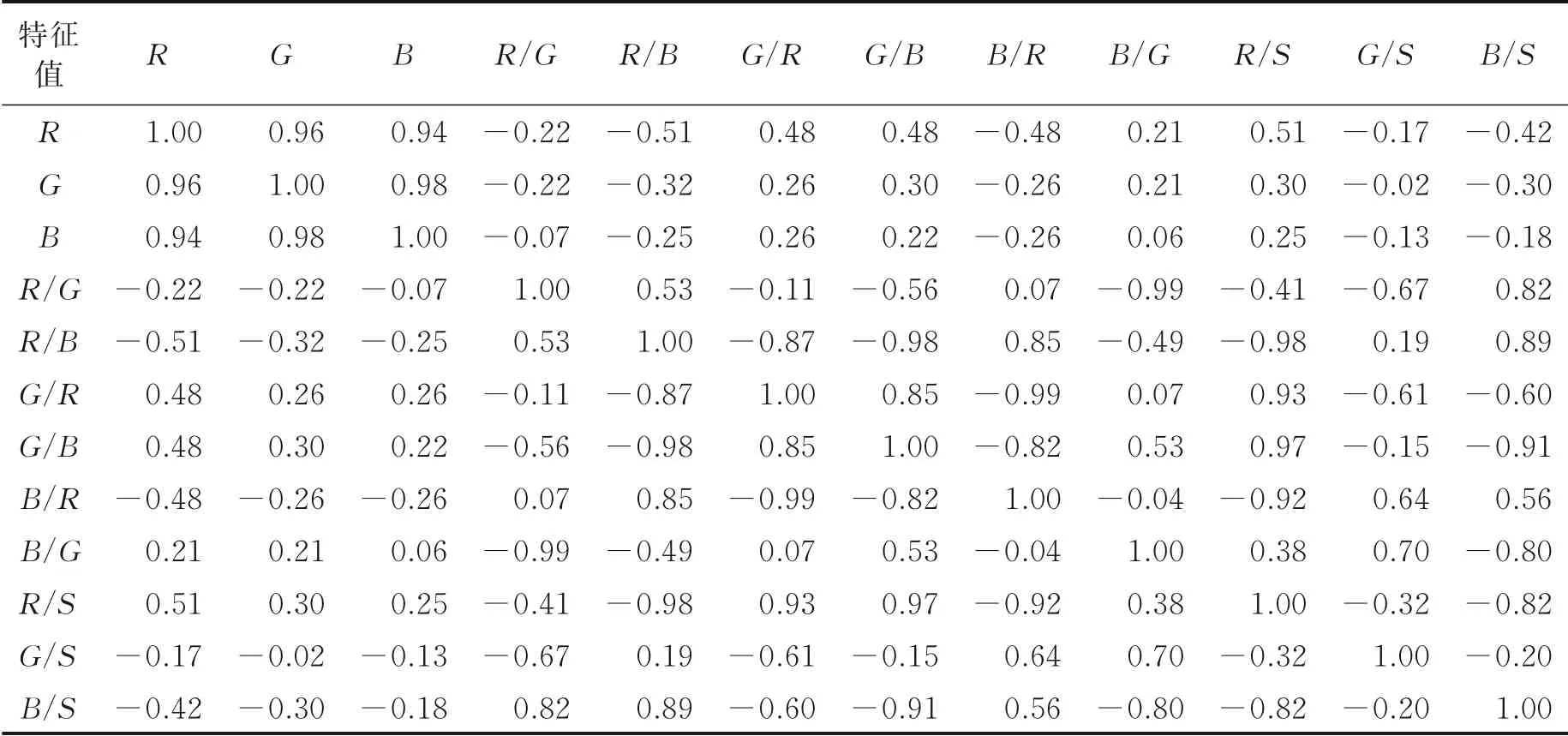
表2 RGB颜色空间特征之间的相关系数矩阵Table 2 Correlation coefficient matrix between RGB color space features
设置阈值为0.95,相关系数大于0.95表示特征之间相关性较高,从表2中可以看出特征R与G、R与B、G/B与R/S、R/B与B/S之间的相关性较高,因此剔除G、B、R/B、G/B颜色特征,最后得到8维的火焰颜色特征。类似地,计算HSV、YCbCr颜色空间的火焰颜色特征之间的相关系数,剔除相关性较大的特征,最终得到22维颜色特征子集。
2.3.2 基于RF的特征选择
RF算法是一个包含多棵决策树的集成学习方法,每棵决策树代表一个分类器。RF算法学习过程中会得到多种决策结果,然后根据决策结果评估最后的分类效果。因此,本文采用RF算法对基于Spearman算法相关性分析得到的22维火焰颜色特征进行选择,通过进一步降维处理,选择出相对较为重要的特征,即筛选与预混火焰燃烧当量比相关性较大的特征。其基本思想通过分析每个特征在随机森林中的每颗树上所做的贡献,然后求取平均值,对比特征之间的贡献大小,最后筛选出贡献较大的特征。这里采用基尼指数(Gini index,GI)指标进行衡量贡献,表达式为

式中:N,m分别表示类别和树节点;Pmk表示节点m中类别k所占的比例。在Python软件上实现RF算法,通过相关性分析得到火焰颜色特征属性为22,并以此建立决策树数目为22随机森林,进一步分析不同特征在每一颗决策树上的贡献。碳氢预混火焰燃烧当量比作为标签,通过学习得到火焰颜色特征与火焰燃烧当量比之间相关性排序,火焰颜色特征重要性如图6所示。图中展示每个火焰特征在每颗决策树上贡献大小,选择GI大于0.02的火焰颜色特征作为特征数据集,完成火焰颜色特征的选择,最终样本数据维度降至16维。
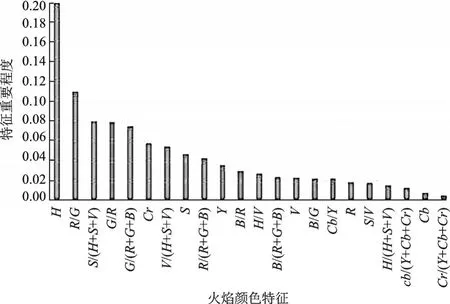
图6 基于RF算法火焰颜色特征重要性排序Fig.6 Importance ranking of flame color features based on RF algorithm
3 基于SVM的燃烧当量比软测量模型
SVM是一种寻求全局最优解和实现结构风险最小的机器学习算法,常用于分类和回归预测[30]。与当前发展较为迅速的深度学习算法[31]相比,SVM可以通过核函数映射关系在高维空间实现低维空间的回归预测,而深度学习网络模型表现性能很大程度上取决于特征样本数据集容量,同时对硬件设备要求非常高,即成本较高。因此本文采用SVM实现碳氢预混火焰燃烧当量比软测量模型的构建。
SVM核心思想是寻求最大分类间隔,对于回归问题,其思想和分类非常类似;区别在于不同的维度空间。分类问题是在二维空间中进行,而回归通常是在高维空间中寻求最优超平面以实现低维空间的不可分问题。对于预混火焰燃烧当量比软测量建模,该数学模型为典型的多输入单输出结构,给定训练数据集{(xi,yi),i=1,2,…,n},其回归估计预测模型[31⁃33]表达式为

式中:xi∈Rl为输入变量,l表示维度;w表示权重向量;φ(x)为训练样本的高维非线性映射;b表示偏置。
约束条件为
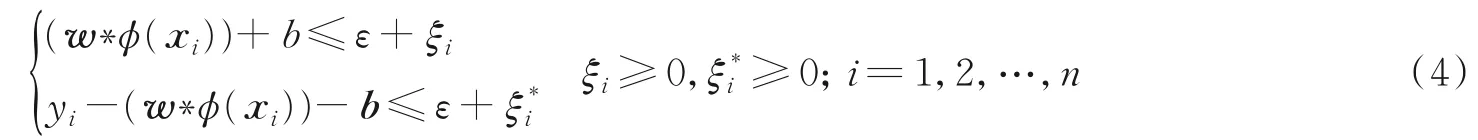
优化目标为
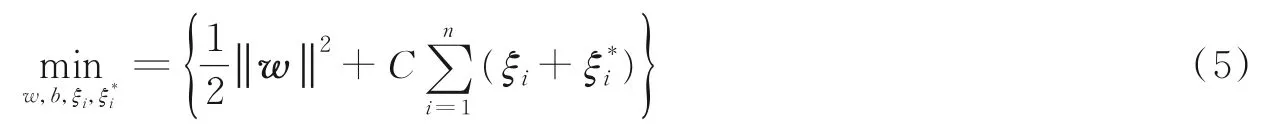
式中:ξi,为松弛因子;ε为损失函数;C(C>0)为规则化参数,也称惩罚因子。
综上所述,约束条件与优化目标构成了原所求的回归估计问题,根据式(4,5)可构建拉格朗日函数对该问题进行求解,分别对w,b,ξi,求偏导数并令其等于零,结合支持向量机拉格朗日乘子与不等式约束的乘积[34]条件最终求解出回归估计数学模型为
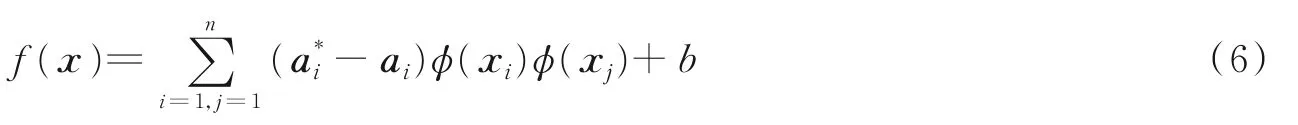
式中:,ai为拉格朗日乘子向量,根据Mercer条件,特征空间中的内积[φ(xi)φ(xj)]可以用核函数k(xi,xj)代替,SVM的表现性能很大程度依赖核函数的选择,基本的核函数有线性核函数、多项式核函数、径向基核函数(Radical basis function,RBF)和Sigmoid核函数。其中RBF核函数应用较为广泛,所需确定的参数较少,计算相对简单、复杂度小,计算公式如式(7)所示。因此本文选RBF核函数代替特征空间的内积,则式(6)可改写为式(8)。
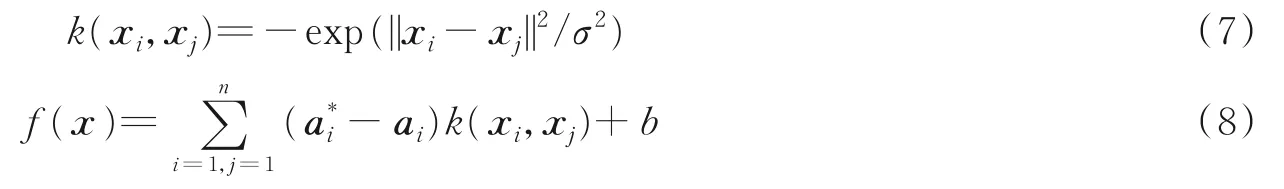
式(7)中σ为设定的参数。针对多输入多输出回归问题,只需运用上述求解方法分别对多个多输入单输出系统进行求解便可得到,对于火焰燃烧当量比软测量模型而言,某一种工况对应是多输入但输出系统,但是多种工况就形成了多输入多输出回归估计问题,因此不同工况下的火焰燃烧当量比软测量模型具体描述为
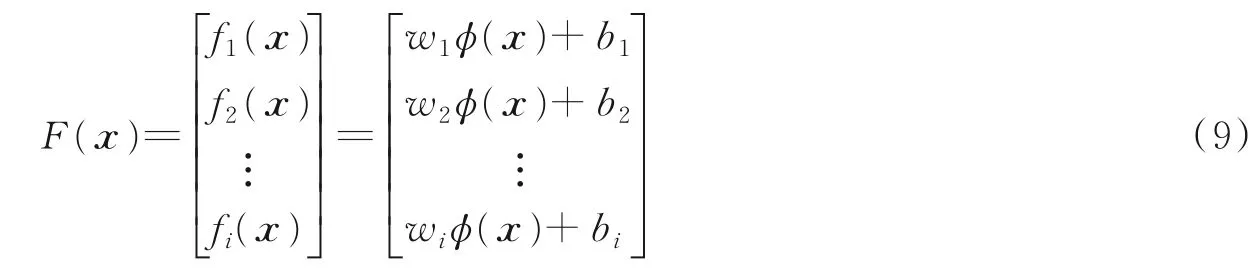
式中:i表示工况情况,即不同当量比的情况。
4 试验结果与分析
试验中将火焰不同燃烧当量比作为SVM机器学习算法训练预测标签,每种工况下选择100张火焰图片,结合特征工程构建得到16维火焰颜色特征,用于学习SVM。学习前,需要将特征数据集进行简单的归一化处理,以避免较大的火焰特征数据掩盖较小的数据,使得最终的训练结果不佳[19]。学习中80%特征数据作为训练集,20%特征数据作为测试集,通过训练SVM得到基于火焰颜色特征的甲烷预混火焰燃烧当量比软测量模型,其回归预测模型评价指标采用均方误差(Mean square error,MSE)和平方相关系数R2(Squared correlation coefficient)进行评判,表达式为
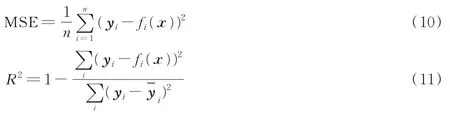
式中:n表示样本容量;yi表示真实值,表示yi的均值;fi(x)表示预测值。
本文选择RBF径向基核函数进行预测,其惩罚参数c与g核函数参数对SVM算法的表现性能起着决定性的作用。这里采用网格搜索法[35]寻求最优参数优化SVM算法,基本步骤如下:
(1)粗略设置网格搜索法搜索初始范围,c与g的初始范围设置为[2-10,210],根据参数结果选择的等高线图进一步改进c与g的搜寻范围。
(2)采用k折交叉验证方法对训练集进行测试,这里k是指将原始数据分成k组,常采用默认值k=3。
(3)根据测试结果确定c与g搜索范围分别为[2-4,24]和[2-4,26],搜索步长设置为0.5,k=3,寻得最优参数c=16、g=64;并将该最优参数优化SVM。通常,算法的效率主要表现为模型的训练与测试整个过程,而参数的选择对模型的表现性能与时效性具有至关重要的作用。本文选择GSM算法优化SVM参数选择,并不断改进参数搜寻范围,其目的是为降低时间消耗成本,同时确保模型的回归预测精度。因此,优化后的SVM算法具有很好的时效性和表现性能,其寻优结果如表3所示。
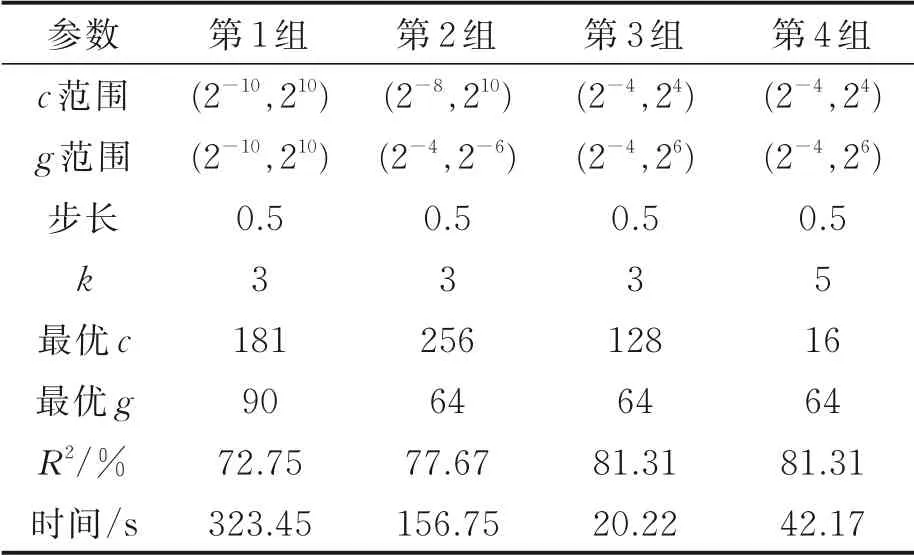
表3 参数寻优结果对比Table 3 Comparison of parameter optimization results
通过测试得到预混火焰燃烧当量比预测误差结果如图7所示。从图7中可以清晰看出,基于SVM预混火焰燃烧当量比预测取得很好的预测结果,相对误差都集中在-0.3~0.5之间,通过计算其均方根误差MSE=0.023,R2=81.31%。
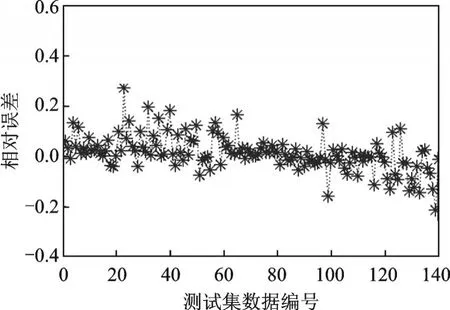
图7 基于SVM预混火焰燃烧当量比预测结果相对误差Fig.7 MSE of prediction result based on SVM pre⁃mixed flame combustion equivalent ratio
为了进一步验证该数学模型的效果,本文将该算法与传统BP神经网络[36]、ELM算法[37]进行对比分析。在同一特征数据集下,BP神经网络和ELM极限学习网络模型的隐含层统一设置为25,其中BP神经网络是一种由输入层、隐含层和输出层组成误差反向传播的前馈神经网络;本文构建的网络结构为16-25-1,网络最大训练次数为1 000、训练要求误差为1e-3、学习率设置为0.1;而ELM算法仅设置隐含层节点数目就可以获得唯一最优解,其训练速度较快。通过训练与测试得到基于不同算法的预混火焰燃烧当量比的预测结果,如图8所示。由于采集的火焰图片数据间隔Φ=0.05采集一次,采集间隔较小,因此相邻2组当量比工况下的火焰图像数据分布非常相近。在试验中,为了使试验结果便于分析与讨论,选择间隔Φ=0.15的火焰图片数据作为本文实验数据,共有7种不同工况,分别为当量比Φ=0.7、Φ=0.85、Φ=1、Φ=1.25、Φ=1.31、Φ=1.4、Φ=1.5。20%的火焰数据作为测试集,并且每20组测试数据对应同一个工况,通过对比不同算法的预测结果发现,SVM表现性能优于BP神经网络与ELM极限学习,基于SVM算法的预测结果相对于目标值其相关性高于其余2种算法。
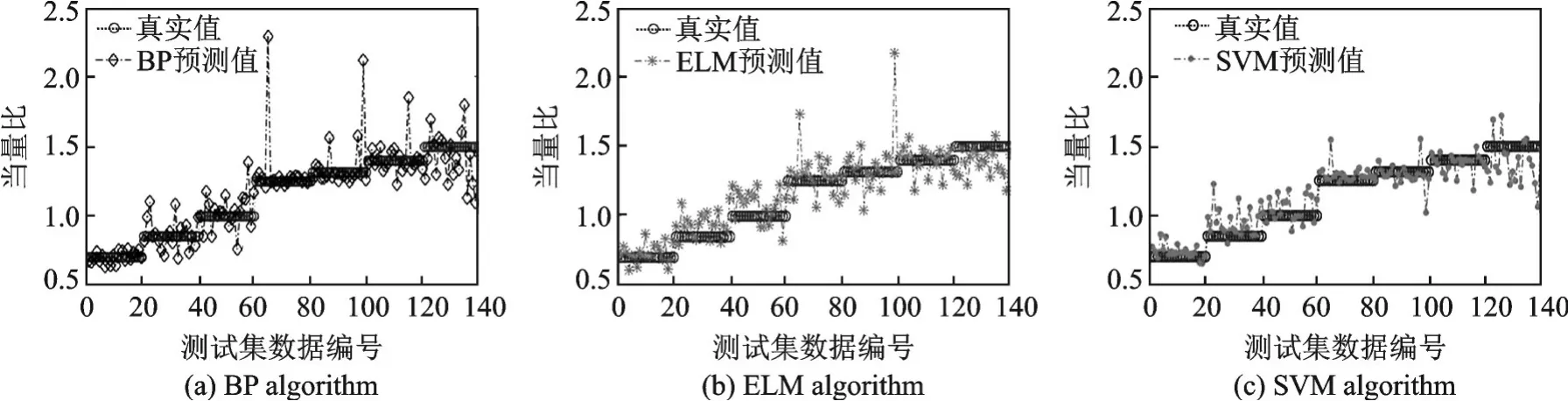
图8 基于不同算法的预混火焰燃烧当量比预测结果对比Fig.8 Combustion equivalence ratio prediction result comparison of premixed flame based on different algorithms
从图8中可以看出,在当量比Φ=1.25与Φ=1.31时,基于BP神经网络和ELM算法预测值与参考值波动较大,BP神经网络易陷入局部最优,同时收敛速度较慢。ELM是针对传统神经网络训练速度较慢和易陷入局部最优的一种改进网络学习算法,通常其网络隐含层数目很难确定,相比较而言,基于GSM算法优化SVM实现甲烷预混火焰燃烧当量比预测具有一定的优越性,寻求的是全局最优解,总体预测效果较好。进一步计算基于不同算法下的火焰燃烧当量比预测绝对误差(Abso⁃lute error,AE),AE结果如图9所示。图9中展示了3种不同算法对预混火焰燃烧当量比预测误差结果图,对于同一个数据集,基于3种不同算法的最大AE分别为1.14、0.9、0.42,AE指标很好地反应了预测结果的可信度。表4展示了基于不同算法表现性能结果对比。通过对比不难发现SVM算法总体回归预测较好,结果表明本文模型具有较好的回归预测效果,同时,其决定系数优于其余2种算法。
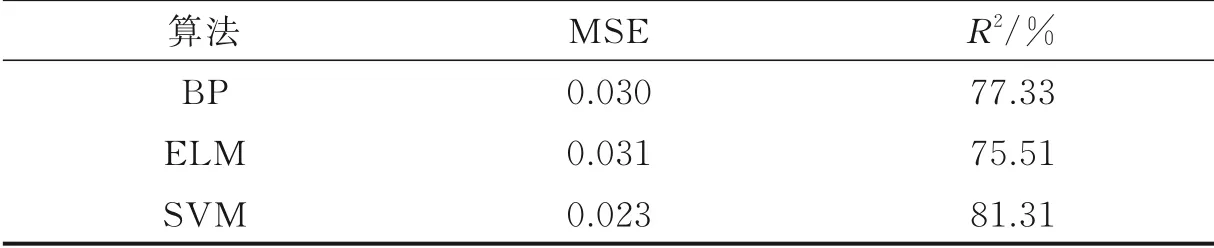
表4 不同算法表现性能结果对比Table 4 Comparison of performance results of different algorithms
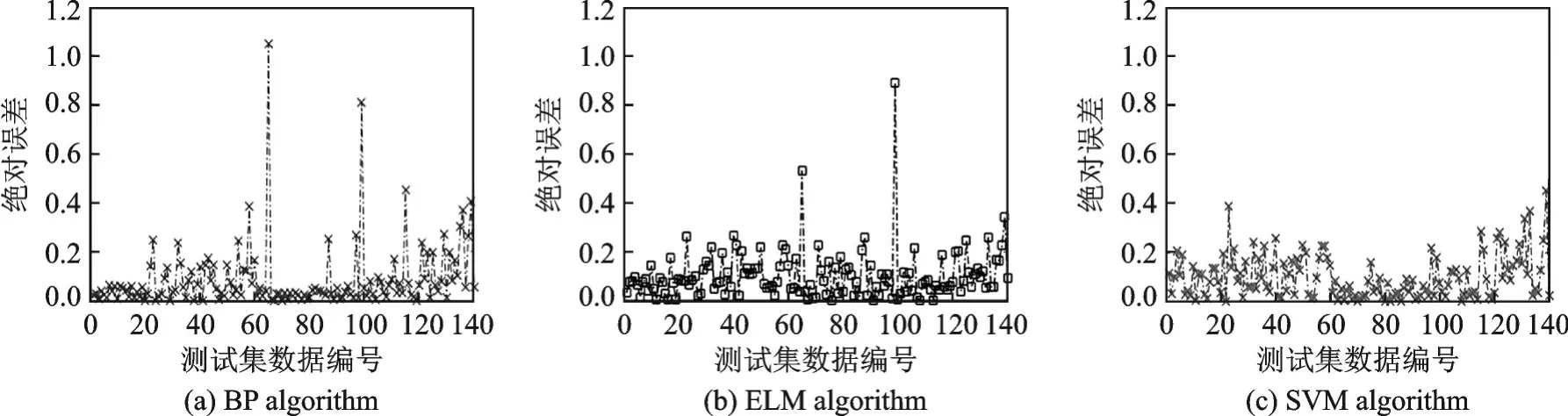
图9 基于不同算法预混火焰燃烧当量比回归预测绝对误差结果对比Fig.9 AE comparison of combustion equivalence ratio regression prediction for premixed flames based on different al⁃gorithms
5 结束语
本文提出一种基于火焰图像颜色特征工程的甲烷预混火焰燃烧当量比软测量模型构建方法。相比传统单一颜色特征作为模型输入,本文在RGB、HSV和YCbCr不同颜色空间模型下,设计了多种颜色分量以及颜色分量之间的比值共计36维数据作为颜色特征,进而应用Spearman相关性分析和RF算法实现火焰颜色特征选择进行降维处理,最终筛选出表征燃烧当量比更深层次的16维火焰颜色特征作为模型输入,构建了甲烷预混火焰颜色特征工程。同时,相对传统简单的拟合数据建模方法,本文提出了通过改进GSM寻求最优参数优化SVM算法建模,结果显示在构建的火焰颜色特征工程数据集上表现出较好的回归预测结果。最后,通过与传统的BP神经网络和ELM算法对比发现,SVM算法回归预测效果在构建的特征数据集上优于BP与ELM。
尽管本文提出的甲烷预混火焰燃烧当量比测量方法取得了较好的回归预测结果,但是仍然存在一些不足之处:(1)针对基于Spearman相关性分析和RF算法特征选择阈值设置主要参考相关研究选择与对比,并没有深入研究与系统分析;(2)模型评估仅采用均方误差和平方相关系数指标进行评价。下一步工作将把本文方法应用到不同燃料燃烧当量比检测,同时对本文存在的不足作进一步的研究,包括多元颜色模型选择(例如引入与设备无关的CIE 1931颜色模型等)、参数选择以及引入多评价指标的模型评估方法。
猜你喜欢
音乐天地(音乐创作版)(2022年1期)2022-04-26
军民两用技术与产品(2021年10期)2021-03-16
学苑创造·A版(2021年2期)2021-03-11
石油化工应用(2021年12期)2021-01-15
水上消防(2020年1期)2020-07-24
动漫星空(兴趣百科)(2019年5期)2019-05-11
疯狂英语·新读写(2018年3期)2018-11-29
北京航空航天大学学报(2017年5期)2017-11-23
文学港(2016年12期)2017-01-06
太空探索(2016年5期)2016-07-12
