
基于语义信息共享Transformer的古文机器翻译方法
2022-02-18 05:05周成彬刘忠宝
情报工程 2022年6期
周成彬 刘忠宝,2,3
1.中北大学软件学院 太原 030051;
2.北京语言大学语言智能研究院 北京 100083;
3.泉州信息工程学院软件学院 泉州 362000
引言
中国古代历史典籍不仅是中国独特的文化遗产,也是世界文明的瑰宝。然而,随着语言在漫长的历史演变过程中,现代人要理解甚至创作古代作品变得相当困难。首先,现代文追求通俗易懂与口语化,而古文追求行文简练且有许多特殊句式,两者的语法顺序大不相同。其次,古文单词多为单音节词,而现代文单词多为双音节。因此,翻译在弥合这两个时代方面发挥着关键作用。对于传统的人工翻译而言,中华古籍的翻译是一项非常困难且耗时的工作,虽然能够取得高质量的译文,但是对翻译者的文化水平要求很高,且需要耗费大量的人力和时间,成本太高。而随着计算机科学技术的发展,为了顺应时代的需要,利用计算机进行自动翻译的机器翻译(Machine Translation,MT)技术越来越成熟。近年来,随着大数据、云计算、人工智能等技术的快速发展,基于语料库的机器翻译逐渐占据主流,其中,又以基于深度学习的神经网络机器翻译最为典型。通过使用基于深度学习的神经机器翻译技术对古籍文献进行自动翻译对我们了解历史、学习优秀传统文化,继承和发扬中华民族精神具有重要意义。
机器翻译是利用计算机自动将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程[1]。机器翻译是自然语言处理的一个研究分支,也是人工智能的终极目标之一,具有重要的科学研究价值。机器翻译于20世纪30年代初露端倪,如今已取得突破性进展。从历时视角来看,机器翻译大致经历过两种范式:语言学范式和语料库学范式,前者为基于规则的机器翻译,后者则为基于语料库的机器翻译。目前主流的机器翻译为的神经网络机器翻译[2](Neural Machine Translation,NMT), 相 比于传统的统计机器翻译[3](Statistical Machine Translation,SMT)而言,NMT能够训练一张从一个序列映射到另一个序列的神经网络,输出的可以是一个变长的序列,NMT其实是一个Encoder-Decoder[4]系统,Encoder把源语言序列进行编码,并提取源语言中信息,通过Decoder再把这种信息转换到另一种语言即目标语言中来,从而完成对语言的翻译。随着基于循环神经 网 络[5](Recurrent Neural Network,RNN)的序列到序列框架[6](Sequence to Sequence,seq2seq)、注 意 力机 制[7](Attention Mecha-nism)以及基于纯注意力机制的Transformer模型[8]的提出,NMT的翻译质量得到了巨大的提升,彻底取代了SMT成为了主流的机器翻译技术。
目前NMT在许多双语翻译研究上取得了巨大的成效,如中英、中俄,英德等不同语种间的互译,然而在古文到现代文之间的语内互译的研究还比较少。本文根据古文与现代文属于同一语言,共享大量词汇的特点,提出一种基于语义信息共享的Transformer机器翻译模型。使用由NiuTrans Open Source(NOS)①https://github.com/NiuTrans/Classical-Modern开源的古今平行语料数据集,并使用BLEU(Bilingual Evaluation Understudy)[9]值对模型进行评估,取得31.4的BLEU值,译文质量良好,达到了机器翻译的效果。
1 相关工作
目前古文到现代文的翻译还是以人工翻译为主,人工翻译需要专家准确的理解古文,这就要求翻译者有较高的文化水平,翻译者的数量有限。人工翻译需要耗费大量的人力和时间,且难以实现即时翻译。随着计算机和互联网的发展,利用计算机技术实现即时自动的翻译成为了研究热点。Liu[10]提出了利用知识图谱理论从古文到现代文的翻译思路,知识图谱具有很强的句子表达能力,对人工翻译有巨大帮助,但是难以实现自动翻译。王爽等[11]利用基于规则的机器翻译技术实现了一个古文自动翻译系统,能够实现部分古文献的翻译和标注。韩芳等[12]利用句本位句法相关规则构造知识库,使用词义消岐算法,对古文进行基于规则和统计相结合的机器翻译研究。基于规则的机器翻译需要构建大量的规则,成本高,且翻译的句子比较生硬,译文质量低。郭锐等[13]建立古文句子的全文索引,基于汉字的信息熵完成最相似古文句的高效检索,为基于实例方法的古今汉语的机器翻译奠定了基础。王爽等[14]提出了基于实例的古文机器翻译系统,该系统需要构建一个句对齐和字对齐的语料库,系统根据语言学知识对源语句进行语法分析,然后在语料库中进行匹配分析,结合一定的语法规则输出译文。基于实例的机器翻译方法有明显的缺点,系统复杂,效率低,翻译质量不高,对于语料库中没有的句子难以实现正确的翻译。杨钦[15]基于对统计机器翻译系统Moses进行优化实现古汉语到现代汉语的翻译。统计机器翻译有很强的词汇和短语翻译能力,但是对译文语序的调序能力较差,难以实现对长句子和复杂句子的顺畅翻译。Zhang等[16]提出具有复制机制和局部注意力机制的端到端的神经网络模型来实现古文到现代文的互译。由于使用神经网络模型需要大量的基于句子对齐的平行语料数据进行训练,他们提出一种无监督算法,该算法利用古今对齐的句子对之间存在许多相同的汉字的特点来构建古今句子对齐的语料库。为了获得更多的古今句对齐语料来提高翻译质量,Liu等[17]根据古现代汉语的特点提出了一种古今从句对齐方法,该方法将词法信息与统计信息相结合,数据集的构建包括平行语料库的爬取和清洗、段落对齐、基于对齐段落的子句对齐以及通过合并对齐的相邻子句来扩充数据等四步,创建了一个包含1.24万对古今双语句对齐的语料库。在平行语料匮乏的情况下,Chang等[18]将翻译任务构建为多标签预测任务,模型除了预测出翻译外还预测出古文的年代信息,将年代信息作为辅助,再加上按时间顺序的上下文作为辅助信息来提高模型的翻译质量。魏家泽[19]构建了基于外部知识协同的古文到现代文的机器翻译模型,通过句内片段协同、注释信息协同和语言知识协同的三维外部知识的联合使用,有效提升了古文到现代文的机器翻译性能。
对以上相关研究进行梳理可以发现,古文的机器翻译研究还存在以下几点问题:一是平行语料匮乏,缺乏大规模高质量的古今平行语料集,难以在深度学习[20](Deep Learning,DL)模型上获得令人满意的效果。本文使用的数据集是由NOS开源的古今平行语料集,该语料集大小为151 MB共97.5万条古今平行句子对,基本涵盖了大部分经典古籍著作,是目前已知的最大规模的古今平行语料集,可以满足本模型的需求。二是未能有效的利用古文与现代文属于同一语种的优势。基于此,本文提出了一种简单有效的方法,通过共享词表和嵌入层参数实现古文与现代文中相同词汇的语义信息共享,通过实验证明这有效的提升了机器翻译性能。三是汉语时代差异的问题,我国汉语历史悠久,每个朝代的语言风格不同,不同朝代的文字,即使相同,含义相差也很大。在已有研究中,大多是通过以年代信息或者引入外部知识作为辅助来提高翻译的准确性,但是在对未知年代信息和没有外部知识的古文进行翻译时,效果就会下降。本文旨在训练一个对古文进行翻译时无需引入任何外部知识,可以直接对原始古文句子进行高质量翻译的模型,故本文使用完全基于注意力机制的深度学习模型Transformer进行训练,相比于传统的基于RNN或CNN[21]的seq2seq模型,Transformer对句子有更强的全局信息感知能力,可以学习到句子的内部依赖关系,只要各个朝代的平行语料足够,模型就可以学到各个朝代的翻译风格,在对多义词进行翻译时,模型会结合上下文信息对该词进行最符合句子语境的翻译。
2 语义信息共享的Transformer
Transformer是一个Encoder-Decoder架构,其整体结构如图1所示,它由编码器和解码器两部分组成。输入古文,通过编码器输出对应的上下文向量,与RNN将源语句压缩为一个上下文向量不同,Transformer的编码器将会得到与输入序列等长的上下文向量,且可以对输入的每个单词进行并行处理。解码器将编码器输出的上下文向量作为输入,最终输出现代文。
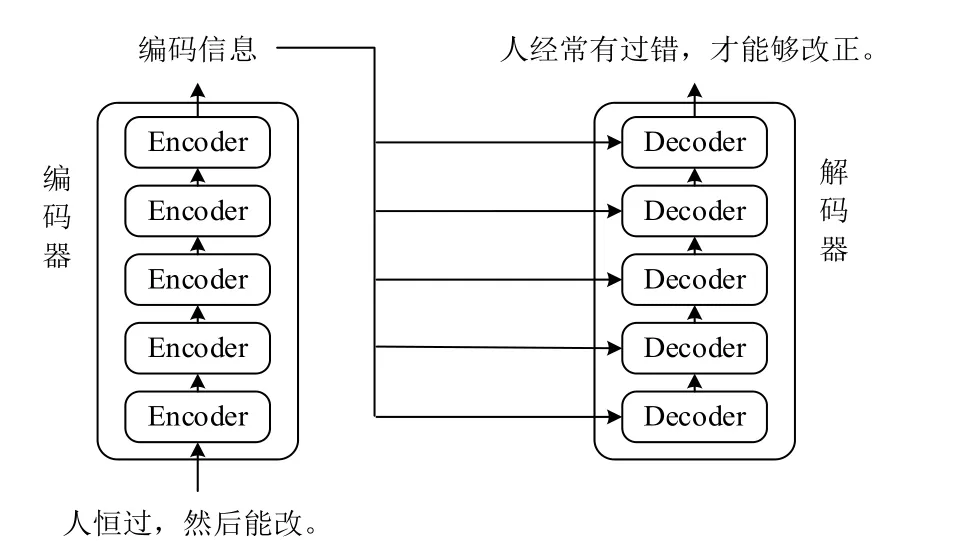
图1 Transformer整体结构
Transformer的编码器部分和解码器部分都是由多个相同的层叠加组成的,其内部结构如图2所示,左边是编码器部分,右边是解码器部分。每个编码器层由两个子层组成,第一个子层是多头自注意力层,第二个子层是一个基于位置的全连接前馈网络。为了更好的优化深度网络防止网络退化和避免梯度爆炸或消失,每个子层都添加了残差连接[22]和进行了层归一化[23]。每个解码器层由三个子层组成,且每个子层也都使用了残差连接和层归一化。第一个子层为掩码多头自注意力层,其掩码机制使得模型保留了自回归属性,确保预测仅依赖于已生成的输出词元[8]。第二个子层为多头注意力层,用来接收编码器的输出。解码器的输出结果最后还需要通过一层线性层和softmax层,线性层输出一个大小等于目标语言词汇表大小的向量。然后通过softmax层得到每个词向量的概率,并选择概率最高的词向量作为当前位置的输出。
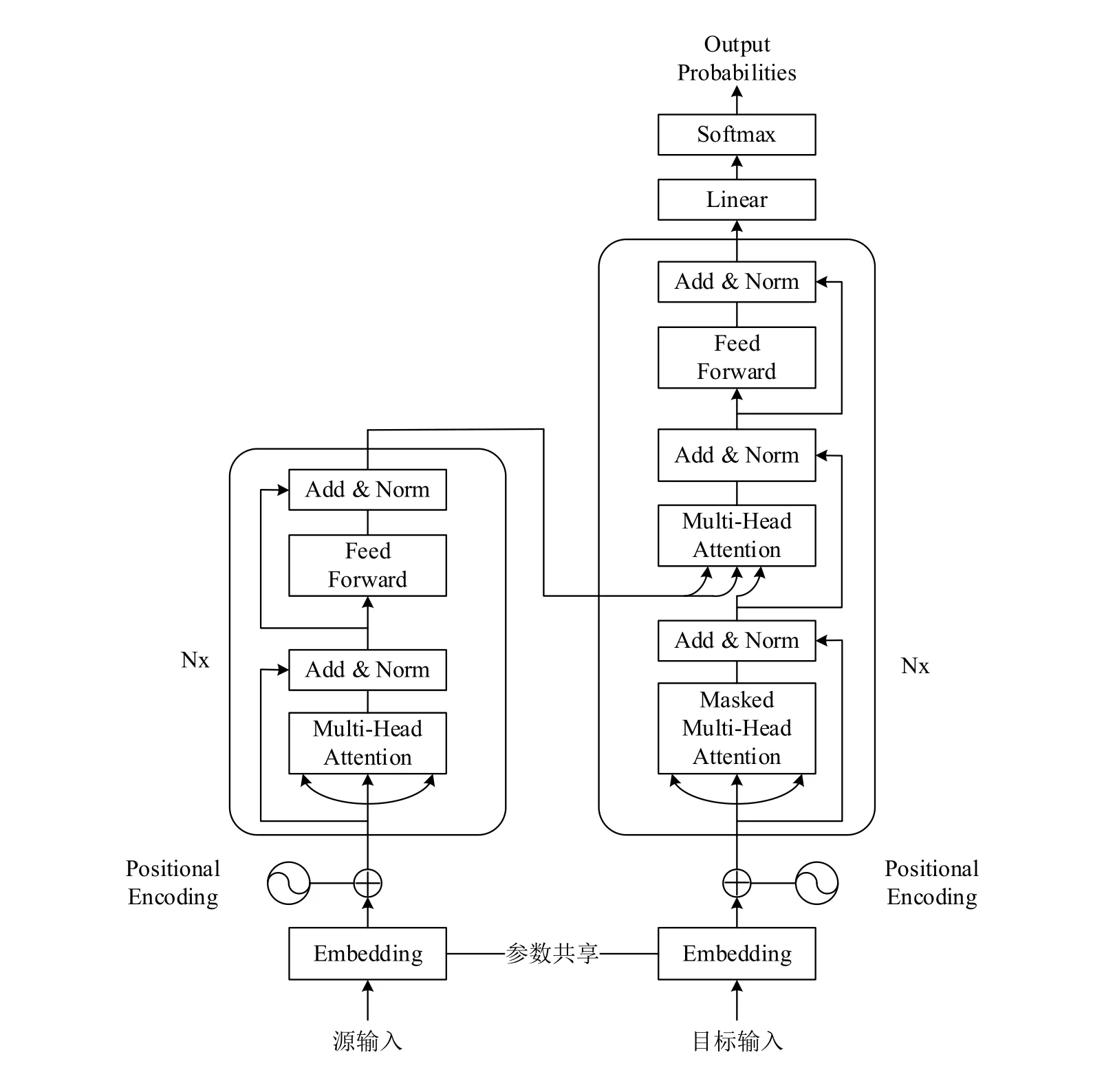
图2 Transformer内部结构
2.1 语义信息共享的嵌入层
古文与现代文之间存在大量语义相同或相近的词元,为了使模型的编码器和解码器能共享这些语义信息,本文提出了两个简单有效的方法。一是在构建词表时,古文与现代文共用一个词表,在对句子做嵌入时,编码器只激活古文的Embedding,解码器只激活现代文的Embedding,虽然词表变大了但是并不会影响模型的性能,且可以帮助编码器和解码器共享语义相同的词。针对汉语中同一个文字在不同词组中含义不同的问题,本文在构建词表时以词为粒度对句子进行切分,模型对多义字进行翻译时会根据其所组成的词组进行对应的翻译。而针对同一个词在不同朝代含义不同的问题,则是通过模型对该朝代大量平行句子对进行训练从而获得该朝代的表述特征和特有语义,结合句子上下文信息对多义词进行翻译。共享词表还可以有效的减少低频词,增加模型的泛化能力,提升机器翻译的效果。二是Transformer的编码器和解码器共享嵌入层参数,嵌入层的作用是通过向量化对句子进行表征,共享嵌入层可以有效利用古文与现代文属于同一语种的优势,对于语义信息相同的词在翻译过程中的一致性可以更好的建模。共享嵌入层参数还可以减少模型的参数数量,加快模型的收敛速度。
2.2 位置编码
Transformer模型没有使用任何循环神经网络或卷积神经网络,而是完全依赖于注意力机制进行计算。而注意力机制是对序列进行并行计算,不是进行顺序计算,不能获取到序列间的位置信息。为了使模型知道输入序列的位置信息,所以在模型底部的嵌入层后加上了位置编码层。位置编码向量的维度与嵌入表示的词向量维度相同,二者可以直接进行相加。位置编码可以是可学习也可以是固定的,本文使用的是基于正弦函数和余弦函数的固定位置编码,位置编码的计算如公式(1)、(2)所示。

其中PE指的是位置编码矩阵,pos表示当前词在序列中的具体位置,i表示词向量的第i个维度,dmodel表示词向量的维度大小。假设输入序列的长度为60,向量维度为32,其位置编码如图3所示,横坐标表示序列中每个词的位置,纵坐标表示位置向量的值,每条曲线表示每个维度的位置向量。
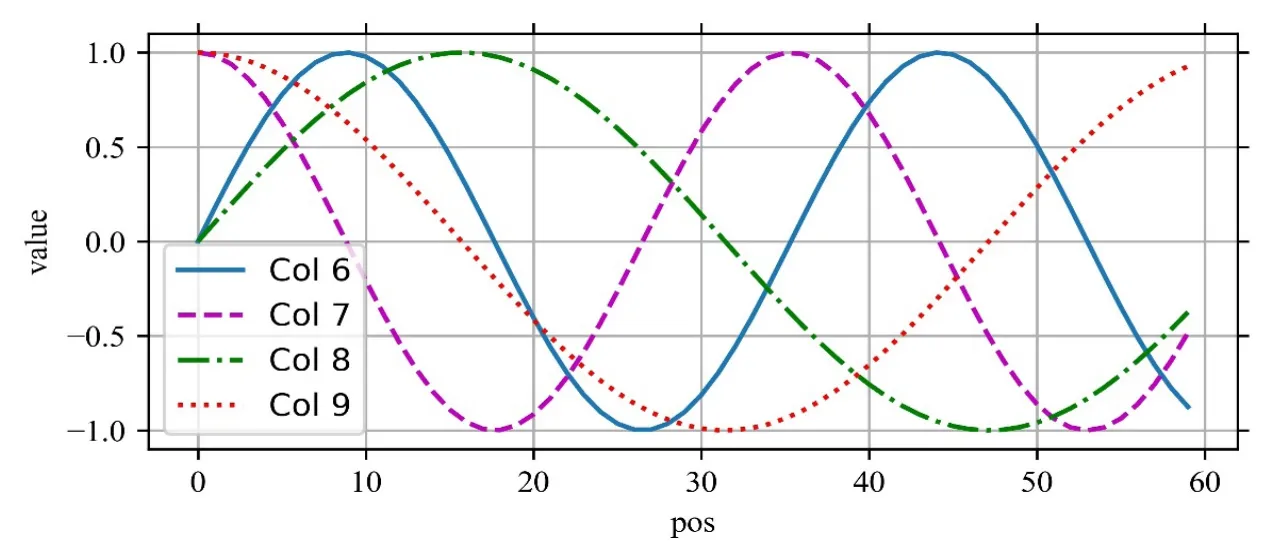
图3 长度为60,维度为32的正余弦位置编码示例图
2.3 多头注意力机制
Transformer的核心就是注意力机制。注意力机制可以使神经网络有选择性的关注重要信息,忽略无关信息。其核心内容为根据query、key和value,通过注意力函数后输出value的加权和,query、key和value都是向量。注意力函数的具体计算过程可以分为三步:第一步使用注意力评分函数sim计算出query、key二者的相似度得到注意力分数,第二步使用softmax函数将注意力分数进行归一化得到一个概率分布作为注意力权重,注意力权重系数之和为1,第三步根据注意力权重对value做加权求和。在计算时,一般将一组query、key、value分别组合成矩阵Q、K、V。注意力函数的计算公式如式(3)所示。
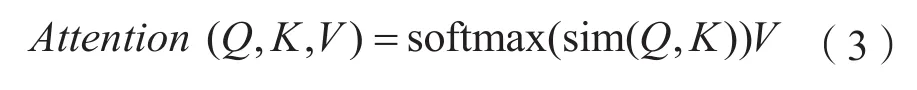
Transformer使用的是缩放点积注意力,其结构如图4所示,注意力评分函数使用的是点积函数。为了避免点积的值太大,在计算出Q和K的注意力分数后要除以进行缩放。dk是矩阵K的维度,如果dk太大,点积得到的值会较大,经过softmax操作之后产生的梯度太小,不利于模型的训练。
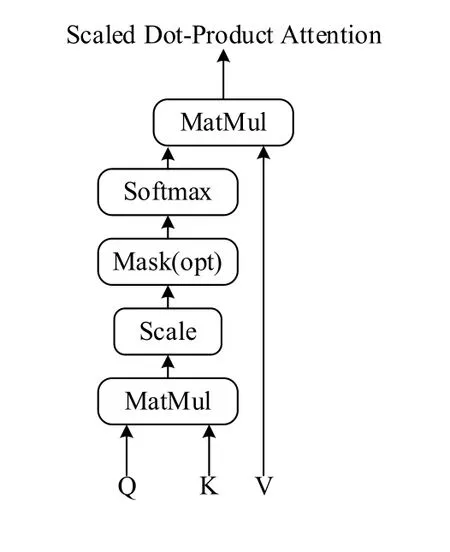
图4 缩放点积注意力
缩放点积注意力的公式如式(4)所示。
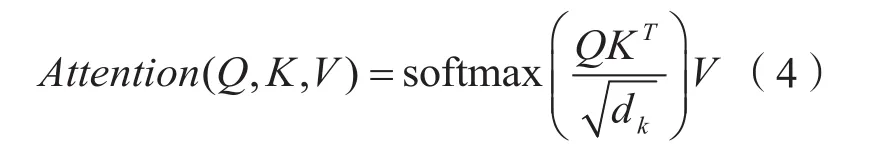
对于自注意力而言,Q、K、V都是由同一个输入序列X(a,……,an)分别乘以三个权重矩阵Wq、Wk、Wv进行线性变换得到的,如公式(5~7)所示。
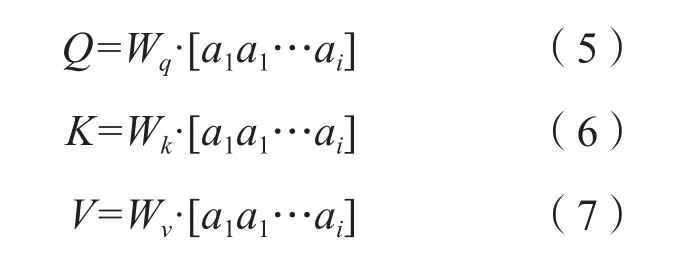
由于Q、K、V都来自于同一个序列,在对句子进行注意力编码时,当前位置的词会过度关注于自身,而忽略其他位置。为了解决这个问题,模型使用了多头自注意力机制,其结构如图5所示。多头自注意力机制就是将Q、K、V映射到多组不同的子空间进行自注意力计算,然后再将每个不同的自注意力结果进行拼接,最后进行一次线性变换输出。多头注意力机制可以使模型学习到不同子空间的信息,增强了模型的表达能力。
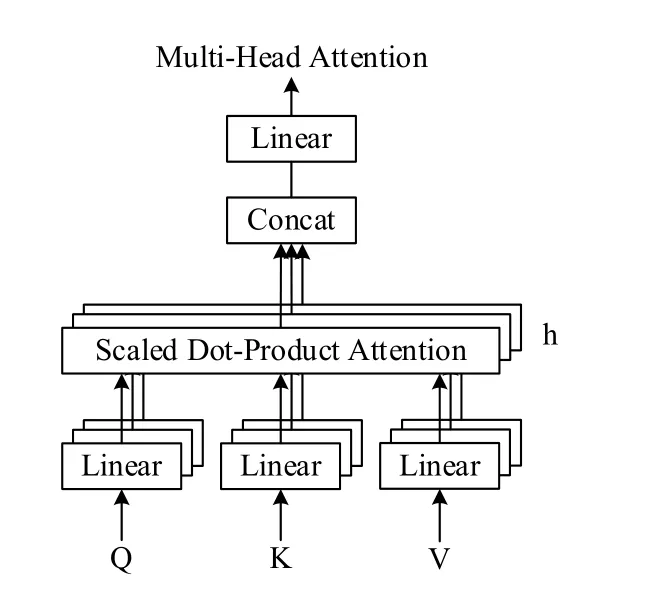
图5 多头自注意力
多头自注意力机制的公式如式(8~9)所示。

2.4 位置前馈网络
位置前馈网络(Feed Forward Neural Network,FFN)是由两层线性变换组成的多层感知机,两层线性变换之间使用Relu激活函数进行连接,且参数不共享。位置前馈网络的公式如式(10)所示。
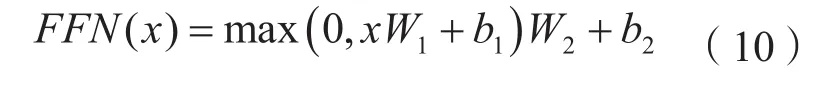
其中,x代表输入,W1表示第一次线性变换的参数矩阵,b1表示第一次线性变换的偏置向量,W2表示第二次线性变换的参数矩阵,b2表示第二次线性变换的偏置向量。
3 实验分析
3.1 数据集
本文使用的数据集是由东北大学NLP实验室和Niutrans Research维护的NOS开源的中文古今平行语料集,该语料集共约97万句对,基本涵盖了大部分经典古籍著作,部分样本数据展示如表1所示。

表1 古今对齐语料展示
在使用数据集训练模型之前,需要对数据集进行划分。首先将所有数据进行随机打乱以增强模型的泛化能力,然后将模型划分为三组:训练集、验证集和测试集,大致按照8:2:2的比例进行划分,三个数据集的统计信息如表2所示,训练集共955096条句对,验证集和测试集都为10000条句对。

表2 数据集划分
3.2 数据集处理
机器翻译模型不能识别原始数据,在进行机器翻译训练前需要对数据集进行以下几步处理:分词、制作词表、将文本序列转化为数字序列、构造小批量数据。
第一步分词也叫做词元化,就是将文本切分为一个个独立的词。本文对古文使用的Jiayan②https://github.com/jiaeyan/Jiayan分词,Jiayan是一款专注于古汉语处理的NLP工具包,Jiayan分词有两种分词算法,一是利用无监督、无词典的N元语法和隐马尔可夫模型进行古文自动分词,二是利用词库构建功能产生的文言词典,基于有向无环词图、句子最大概率路径和动态规划算法进行分词,本文使用的是第一种分词算法。本文对现代文使用的是Jieba③https://github.com/fxsjy/jieba分词,Jieba分词是一款优秀的中文分词工具,其分词原理为首先基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG),然后采用了动态规划查找最大概率路径,找出基于词频的最大切分组合,对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。古文使用Jiayan分词后的效果如表3所示,现代文使用Jieba分词的效果如表4所示。

表3 古文分词

表4 现代文分词
第二步制作词表,就是根据分词后的结果对源语言和目标语言别分建立一个字典。由于古文与现代文使用的都是简体汉字,属于语内翻译,所以本文中使用古文分词后的结果和现代文分词后的结果共同建立了一个词表。在机器翻译中,只需要使用训练集的数据进行词表的创建而不使用验证集和测试集的数据。还指除此之外,定了三个额外的特殊词元,<unk>用以统一表示低频词和未知词,<pad>用来进行填充,<bos>作为开始词元,<eos>作为结束词元。统计去除低频词后的训练集的词表大小如表5所示。
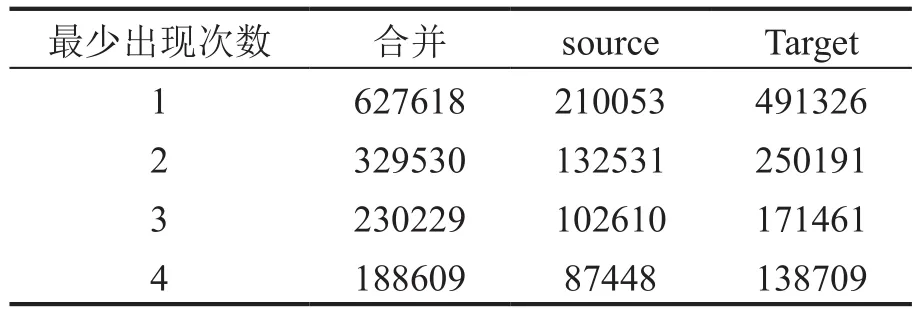
表5 词表统计
第三步将文本序列转化为数字序列,就是将分词后的文本序列通过查表转化为数字序列。数字化的效果如表6所示。

表6 文本序列数字化
第四步是构建小批量数据。由于计算机的内存有限,模型进行训练时不能一次性进行全局训练,而是将数据打包成批量大小相同的小批量数据(batch)进行训练。由于每条句子的长度不相同,在构造小批量数据时,以每个batch中最长的序列为标准,使用<pad>进行补齐,同时在序列的开始添加<bos>,在结尾添加 <eos>。
3.3 实验环境
实验环境如表7所示。
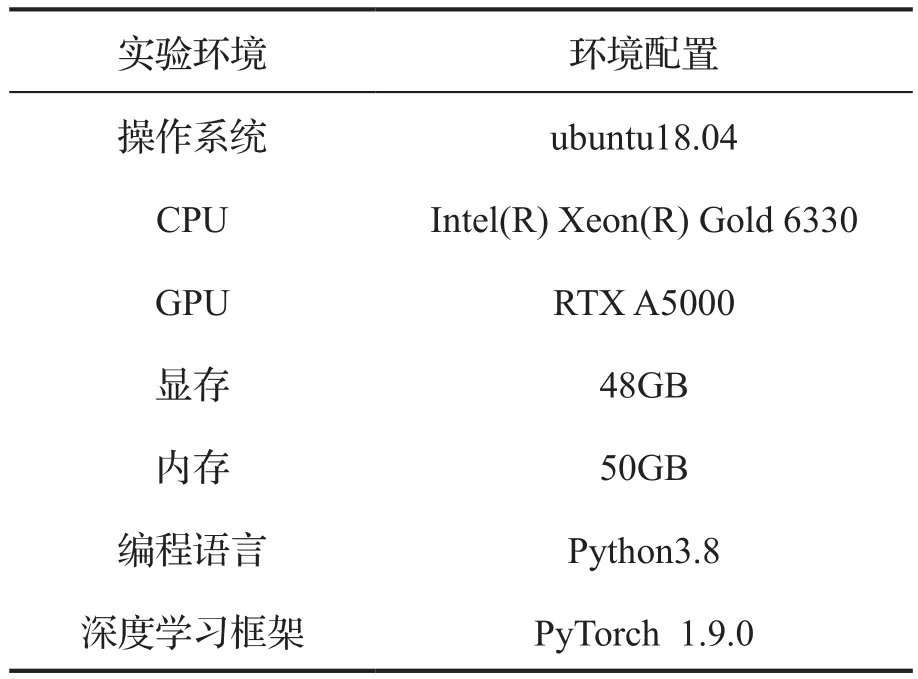
表7 实验环境与配置
3.4 参数设置
模型的相关参数设置如表8所示。模型训练时使用带掩码的交叉熵损失函数(CrossEntropyLoss),在计算损失时会自动忽略所有的<pad>。模型使用的优化器为Adam。模型进行预测时使用搜索策略为束搜索(beamsearch),束宽(beam_size)设置为5。
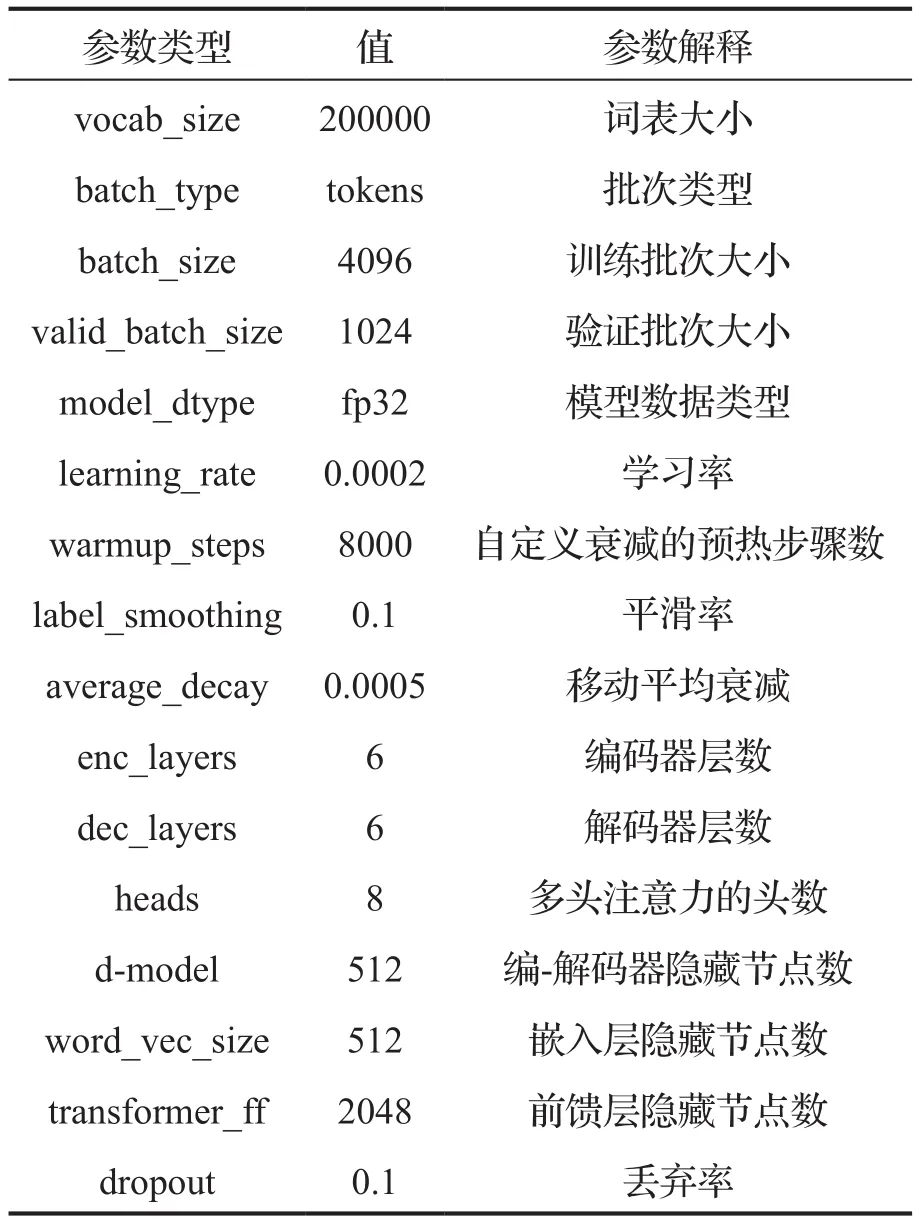
表8 模型参数设置
3.5 评价指标
BLEU是机器翻译中常用的评价指标,它可以对模型生成的句子和实际的目标句子进行相似度评估,BLEU的取值在0到1之间,0表示两个句子完全不匹配,1表示两个句子完美匹配。通常也可以将BLEU的值乘以100来作为指标。BLEU的原理是通过对预测句子的N-grams的与实际句子的N-grams词进行匹配,计算出各阶N-grams词的精度,由于预测的句子越短,匹配的难度越容易,所以引入了简短惩罚因子(Brevity Penalty,bp)。BLEU的计算公式如式(11)所示。
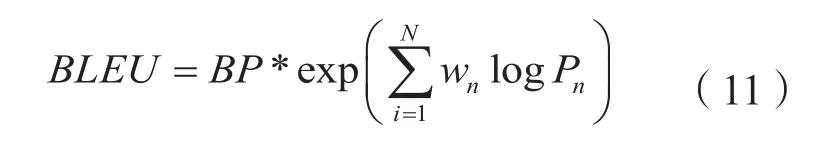
其中,N最大值取4,即4-grams。BP为惩罚因子表达式如式(12)所示,Pn为N-grams精度表示式如式(13)所示。
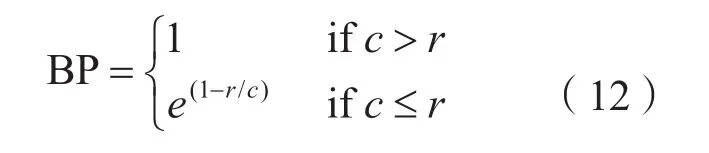
其中c是机器翻译句子的长度,r是实际句子的长度。
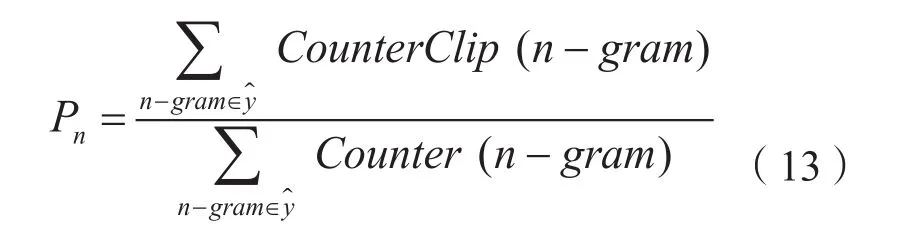
其中,分母为机器翻译句子中n-gram词组的总数,分子为机器翻译句子中的词组能与实际句子匹配得上的个数。
3.6 实验结果
本文使用的模型为基于语义信息共享的Transformer模型,为了验证本模型的有效性,使用相同的数据集在以下几个经典模型上进行实验,此外本文还对比了相关研究中所提文献的实验结果。
(1)以单层GRU[24]构成seq2seq模型。
(2)以两层LSTM+Attention构成的seq2seq模型。
(3)基准的Transformer模型。
(4)seq2seq+Copy+Local Attention模型[16]。该模型是由Zhang等提出具有复制机制和局部注意力机制的端到端的神经网络模型。
(5)Transformer+Augment模型[17]。该模型是由Liu等提出的基于数据增强的Transformer模型。
(6)Time-Aware Ancient Chinese Text Translation模型[18]。该模型是由Chang等提出的具有时间感知的古文翻译模型。
(7)Seg+sub+stage-M5模型[19]。该模型是由魏家泽提出的基于外部知识协同的古文翻译模型,是通过注释信息协同(Sub)、句内片段协同(Seg)和语言知识协同(Stage)综合起来的三维联合协同的翻译模型。
(8)语义信息共享的Transformer模型,即本文所提出的模型。
各模型的实验结果如表9所示。从实验的结果可以看出,两层LSTM+Attention模型比单层的GRU模型的BLEU值高出了11.57,证明更深的网络和Attention机制的引入能给模型带来巨大的提升。基准Transformer的机器翻译模型比两层LSTM+Attention模型的高了1.78的BLEU值,这是因为Transformer对比LSTM有更强的序列建模能力和全局信息感知能力,Transformer能更好的提取句子的语义信息,在语义表达上也更强。语义信息共享的Transformer比基准Transformer的BLEU值高了13.41,能取得如此大幅度提升的原因在于,共享词表和嵌入层参数能有效利用古文与现代文是同一语种的优势。此外,本文所提出的模型效果也高于其他文献中所提出的模型,证明了使深度学习模型自动学习和利用古文与现代文之间语义相同的特征比通过对模型使用复制机制或引入外部知识更有效果。从人工翻译的角度来看,不同语种之间的翻译比同一语种内的翻译要困难得多,因为同一语种不但使用同一种文字,还共享很多意思相同或相近的词。共享词表与嵌入层参数即对源语言和目标语言使用了同一种表达,更容易获得两者之间的联系。

表9 实验结果
同一句古文使用不同的模型进行翻译,更能看出各模型的翻译效果,由于缺少其他文献的样本数据,本文只展示传统模型及本文所提模型的翻译样本。样本展示如表10所示。

表10 模型翻译样本展示
从表中可以看出基于语义信息共享的Transformer模型的翻译效果最佳,特别是在对长句子的翻译上。虽然本文提出的模型在古文翻译上要优于其他模型,但是还是存在一些缺点。如在对句子“孝文三年坐不敬,国除。”的翻译中,模型翻译为“孝文帝三年前,他犯有不敬之罪,封国被废除。”,其中由于缺了上文,模型未能识别出主语,而是将“孝文”作为了主语翻译成了“孝文帝”,而实际上“孝文”在此处是和“三年”一起组成“孝文三年”指代时间。此外,模型在处理通假字时也会出现误翻,如“身尽府种”,模型将其翻译为“人的身体可以全部于官府播种”,实际上,“府种”为“浮肿”的意思,府,通“胕”。种,通“肿”。出现这些情况的原因是模型往往会将古汉语按照最常用的方式去进行翻译,除了古文中的这些特殊情况外,总体来说,本模型的翻译效果良好,可以帮助人们更好的阅读古文。
4 结论
本文提出的基于语义信息共享的Transformer机器翻译模型在对古文的翻译中,优于传统seq2seq模型、基准Transformer模型以及相关研究中所提文献的模型。本文主要基于基准Transformer做了两点改变,一是在数据处理阶段源语言和目标语言共享同一个词表,二是在模型训练阶段编码器和解码器共享嵌入层参数。通过对实验结果的分析,本模型的翻译效果良好,但在处理古文的通假字和缺乏上下文等特殊情况上还有待改进。在后续研究中应针对上述问题进行探讨,以更进一步提高译文的质量与准确性。
猜你喜欢
新世纪智能(语文备考)(2021年4期)2021-08-06
校园英语·月末(2021年13期)2021-03-15
英语世界(2021年13期)2021-01-12
——三份医学英语词表比较分析
江西理工大学学报(2020年2期)2020-05-21
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
新世纪智能(语文备考)(2018年9期)2018-11-08
中学语文(2015年18期)2015-03-01
图书馆建设(2012年3期)2012-10-23
对联(2011年20期)2011-09-19
