
面向乳腺癌图像的浅层高识别卷积神经网络研究
2022-02-19 10:23王兵锐杨晓非姚行中
计算机应用与软件 2022年2期
王兵锐 杨晓非 姚行中,3
1(河南省智能应急研究中心(南阳师范学院) 河南 南阳 473007) 2(华中科技大学光学与电子信息学院 湖北 武汉 430074) 3(火箭军研究院 北京 100085)
0 引 言
乳腺癌严重威胁着女性的生命健康,且乳腺癌在女性恶性肿瘤发病率中居首位,患乳腺癌的人数在持续上升以及发病年龄年轻化。乳腺癌的早发现、早诊断,是降低致死率的关键。然而,乳腺癌的诊疗过程复杂度高、不确定性高。通常,医生们根据自身经验进行诊断,但同一患者不同阶段的治疗方案不同,不同医生对同一患者的治疗方案也不同,诊断效率不高,有时易导致误诊,从而加剧病情的恶化。卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积运算的前馈神经网络,是深度学习技术应用最典型的网络之一。CNN具有十分广泛的应用,如获取超分辨率视频[1]、中文文本探测[2]、输入图像噪声的即时调整[3]、极化合成孔径雷达图像的分类[4]、X射线行李安全中图像的分类和检测[5]、遥感技术中的高光谱图像分类[6]、集成电路方面的晶圆缺陷分类与检索[7]。采用CNN辅助医生加速和精准乳腺癌诊断是十分必要的。
近年来,科研人员根据CNN对乳腺癌展开了研究。Tan等[8]针对正常、良性肿瘤和癌症三种乳腺X光图片,执行预处理操作将乳腺X光图片转换成计算机能够识别的图像,利用CNN对这些图像进行检测分类。实验结果表明,分类精度可以达到82.71%。Zhang等[9]建立不同的CNN模型对二维乳腺X光图片和三维断层合成图片进行分类,并且根据活组织检查和专家确认来评估每个分类器。使用转移学习和数据增强建立的CNN模型具有自动乳腺癌检测的良好潜力。但该文献采用的数据集较少,只有3 200张左右。采用乳房超声波诊断乳腺癌,Chiang等[10]提出一种三维CNN聚合重叠候选者方案辅助诊断。测试集偏少,为171个。一般而言,病理组织检测的准确度要大于乳房超声波检测。褚晶辉等[11]针对乳腺肿瘤核磁共振图像,为了区分肿瘤与非肿瘤,基于迁移学习构建一种诊断系统且获得不错的性能。孔小函等[12]提出改进的CNN模型,辅助三维乳腺超声分类,可以接受图像和文本同时输入。采用880幅图像进行试验,多信息融合的CNN模型可以达到75.11%的准确率。Zou等[13]对CNN结合乳腺X光图片诊断乳腺癌技术进行综述,把诊断技术分为三种,一是设计浅层模型降低时间成本;二是通过转移学习训练模型;三是利用CNN模型进行特征提取,同时指出基于CNN的乳腺癌诊断技术还于早期阶段。周孟然等[14]主要针对乳腺癌的周长、面积、平滑程度等文本特征进行研究,本研究直接针对图像进行识别分析。
目前的研究主要集中在乳腺癌X光、超声波、核磁共振图像等,对乳腺癌病理图像识别分类研究较少,且图像数据集较小。本文针对乳腺癌病理图像开展诊断识别研究,但癌症图像的纹理特征比较细腻,一般采用插值放大进行处理,但放大过大会引入更多的噪声从而失去意义,同时会导致更多的计算量,放大的程度需要仔细设计。此外,卷积神经网络一般涉及大量参数,加大训练复杂度和训练时间,设计一种浅层且高效的网络是值得研究的。
1 浅层W型CNN网络
1.1 CNN构成
CNN一般包括卷积层、激活层,池化层、全连接层。针对卷积层,一般采用的是二维矩阵卷积,具体的计算过程类似感知机的数学表示形式:
X*Wt+b=Z
式中:X为输入数据,一般是矩阵形式。Wt为权重或称作卷积核,表明不同的输入数据对输出值贡献的大小不同,也就是不同的输入其重要性是不同的。b是偏置量,即一个附加值,有时可以省略。下面针对二维卷积运算进行举例,如图1所示。
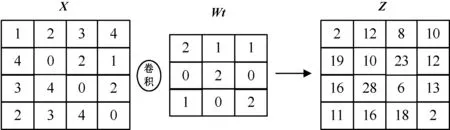
图1 卷积运算
图1中,4阶矩阵与3阶矩阵进行卷积,产生一个4阶矩阵。这里面涉及的一种算法叫作补0扩充,原输入数据X是4阶矩阵,把X周围填补一圈0变成5阶矩阵,那么X与Wt卷积后便能得到5阶矩阵。如果不进行补0,得到的Z将是2阶矩阵,输入数据由4阶变为2阶,同时导致输入数据的有用边界信息丢失,所以补0扩充操作非常有必要。
在补0操作完成后,矩阵X左上角的元素1和Wt矩阵的中心元素2对齐,然后依次向右向下滑动,做卷积运算。卷积运算的关键原理是对应元素相乘相加,比如Z的左上角第一个元素2的由来,0×2+0×1+0×1+0×0+1×2+2×0+0×1+4×0+0×2=2。值得注意的是,CNN的卷积运算和信号处理中涉及的卷积有不同之处,CNN卷积中的Wt矩阵不需要翻转,因为初始的Wt不一定是最优值需要不断调节,Wt矩阵的元素是在不断变化的,Wt作为一个变量参数,不需要额外的翻转操作。同时Wt矩阵具有共享性,一旦Wt矩阵数量确定,无论有多少个输入数据X,都有相同个数的Wt矩阵与X进行卷积。输入数据X一定的情况下,Wt权重矩阵的大小与多少,决定了卷积的复杂度。
下面介绍激活层。激活层的作用是在CNN中引入非线性,使得CNN可以扩展到多层。如果没有激活函数,多层CNN就相当于一层,网络具有线性组合性质,不利于学习更多的特征。同时激活函数还使得特征大的数据区域向后传输得到激活,使特征小的数据区域趋于0,停止传输。常见的激活函数为Sigmoid和ReLU函数。为了具体描述激活函数的作用,给出一个CNN中简单的基本处理单元,如图2所示。
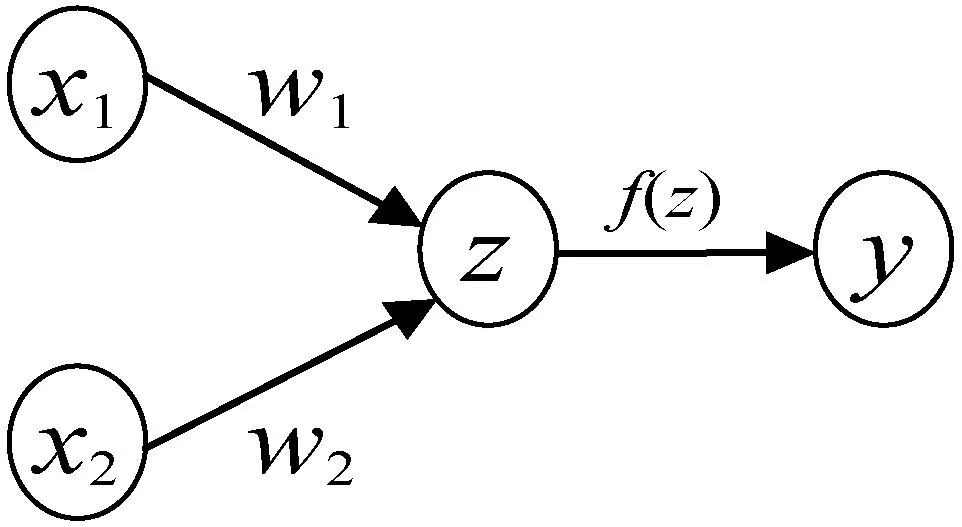
图2 CNN基本单元
根据图2,有x1w1+x2w2=z,对于激活函数f,有f(z)=y。输出值y与真实值yr的误差函数为:
(2)
根据泰勒展开式,推导出的权重更新公式[15-16]为:
(3)
其中η称为学习率。
对于权重w1,结合式子的求导部分,有:
(4)
激活函数采用Sigmoid函数1/(1+e-z)时,其导数为:
(5)
当z为0时,导数取得最大值1/4。当CNN有多层时,更新权重时需要多次乘以Sigmoid导数,会导致式子的导数部分趋于0,出现w1=w1的情况导致权重无法更新。采用ReLU激活函数时,导数最大值为1,通常不影响权重的更新,是常用的激活函数。
池化层的作用是提取区域数据中最显著的特征并降维。当输入数据在邻域内移动时,经过池化层可以使输出与未移动时保持不变,从而对微小位移具有抗干扰的作用。全连接层综合前面提取到的散碎的特征,具体运算类似与卷积层,只是此处的权重矩阵和输入数据的维度要匹配。
1.2 W型网络
提出5卷积层的CNN,其示意图如图3所示。卷积层主要作用是提取输入数据的特征,一个权重矩阵只能描述少量局部特征。单一的权重矩阵进行卷积运算是不够的,需要多个权重矩阵提取不同的特征,使得特征多样化、详尽化,避免提取的特征单一。先提取局部特征再汇总,符合人们对事物的认识过程。权重矩阵的阶数一般是奇数,方便中心对齐。
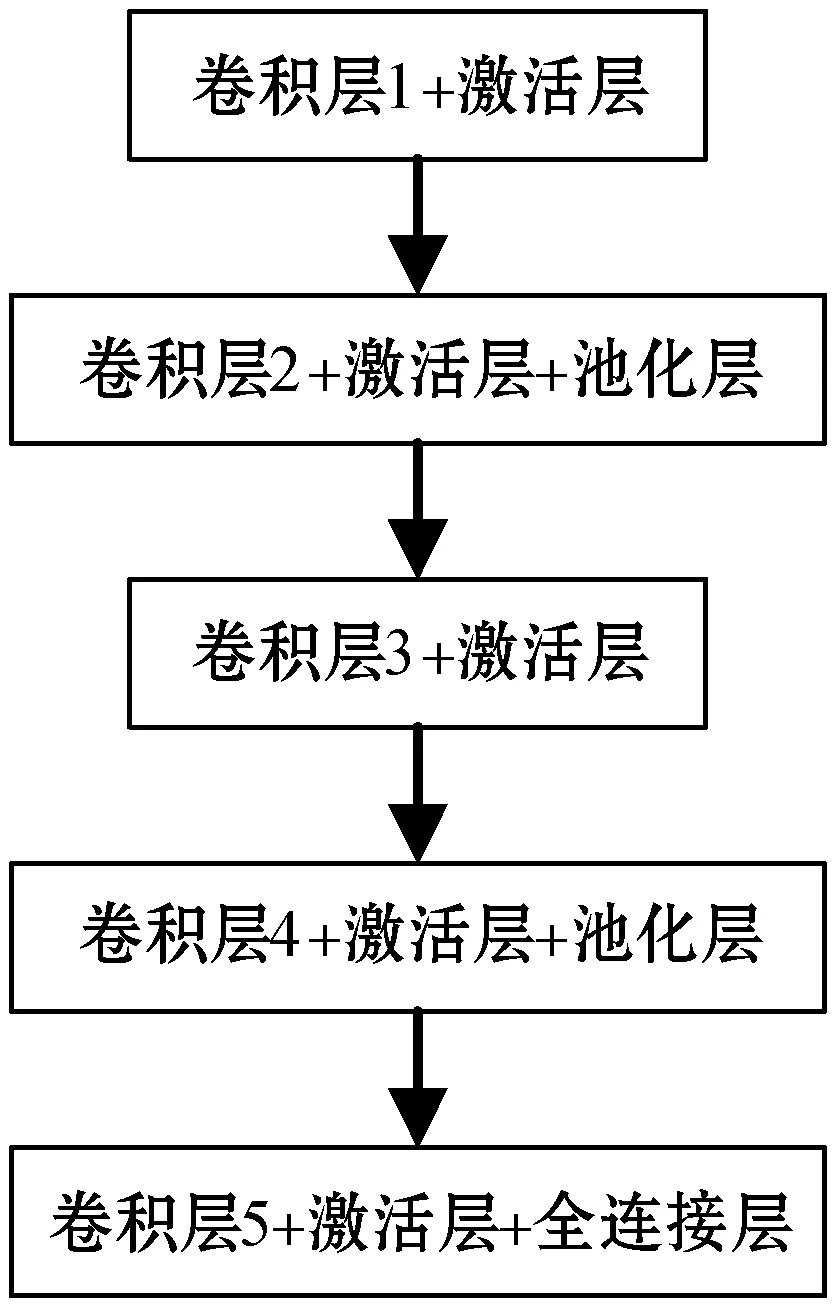
图3 提出的网络结构
图3采用的权重矩阵都是3×3矩阵,每个卷积层含64个以上的权重矩阵。卷积运算可以描述为:
(6)
式中:l表示第l层;i表示第i个权重矩阵。当l表示第1层到第5层时,相应i的最大取值分别为64、128、64、128、64,即5个卷积层采用的权重矩阵个数为64→128→64→128→64,如图4所示。传统CNN网络的权重矩阵采用的是从小到大的排列,即64→64→64→128→128。卷积层1相应的权重矩阵所占存储大小为3×3×3×64=1 728。其他4个卷积层对应权重矩阵存储值都为3×3×64×128=73 728,那么总权重参数为296 640。经典的深度学习结构VGG16,其权重参数有1亿3 000万。和VGG16相比,提出的CNN的存储空间复杂度大大降低。而且VGG16有13层卷积运算,提出的结构只有5层,少了8层大型卷积,降低了运算时间复杂度。
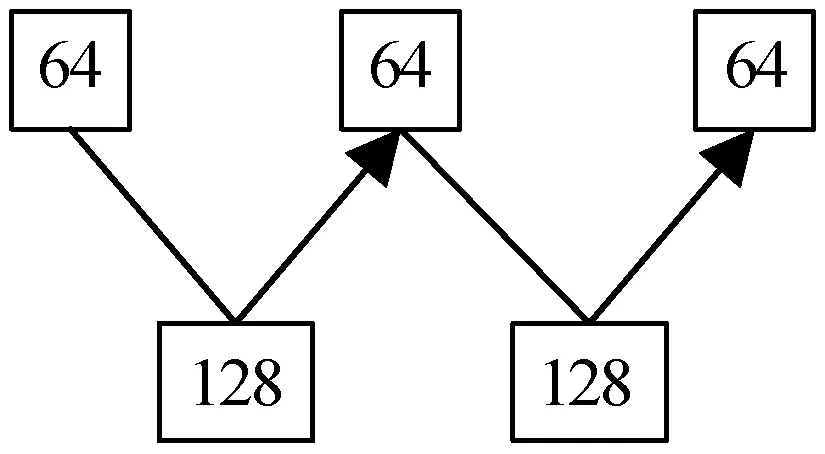
图4 W型结构
传统网络容易导致过拟合。过拟合是指学习模型在训练样本中表现得过于优异,导致在验证数据集以及测试数据集中表现不佳。也就是说模型对未知样本的预测表现一般,泛化能力较差。从数学层面描述,就是学习到的特征的协方差偏大,导致验证测试集上的损失函数的值过大。例如训练识别白天鹅,天鹅的形状、颜色都学习得很详尽,那么碰到黑色的天鹅时将不能识别。如果不学习天鹅的颜色,即有些特征不学习,那么黑天鹅也能被识别。
采用W结构,其权重矩阵的大小在不断变化,就相当于在训练不同的网络。权重矩阵由小到大,数据的特征学习的比较丰富和详尽,但这样容易导致过分学习,产生过拟合。传统的顺序结构,学习到的特征越来越大,越来越详尽,特征量十分丰富,容易导致过拟合。权重矩阵由大到小,利用卷积提取到的特征就会减少,有些特征没有学习太深太详尽,学习到的网络在不断变化,从而起到抗过拟合的作用。W型网络具有一定的优越性。
2 本文CNN与传统CNN对比
2.1 精度损失实验对比
采用的数据是Kaggle提供的转移型乳腺癌数据集,分癌症图像和健康图像两类,像素为96×96。从中随机抽出72 000幅图片作为训练集,12 000幅作为验证集,16 600幅作为测试集。这3类数据集里面,正负样本数量相等,也就是说,癌症和健康图像各占一半。癌症图像并不像手写数字,数字图像属于粗粒度,更容易分析识别。而癌症图像属于细粒度,识别分类有难度。为了更好地分析癌症图像,对图像进行插值放大,将96×96扩展115%倍后为110×110。此外,batchsize设为64,Epoch为35。
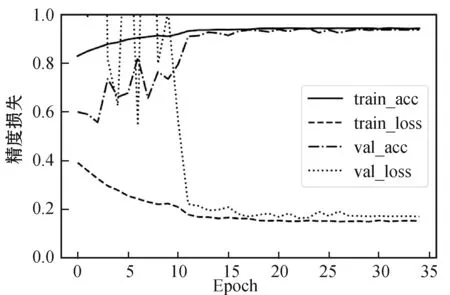
(a) 5层W型CNN
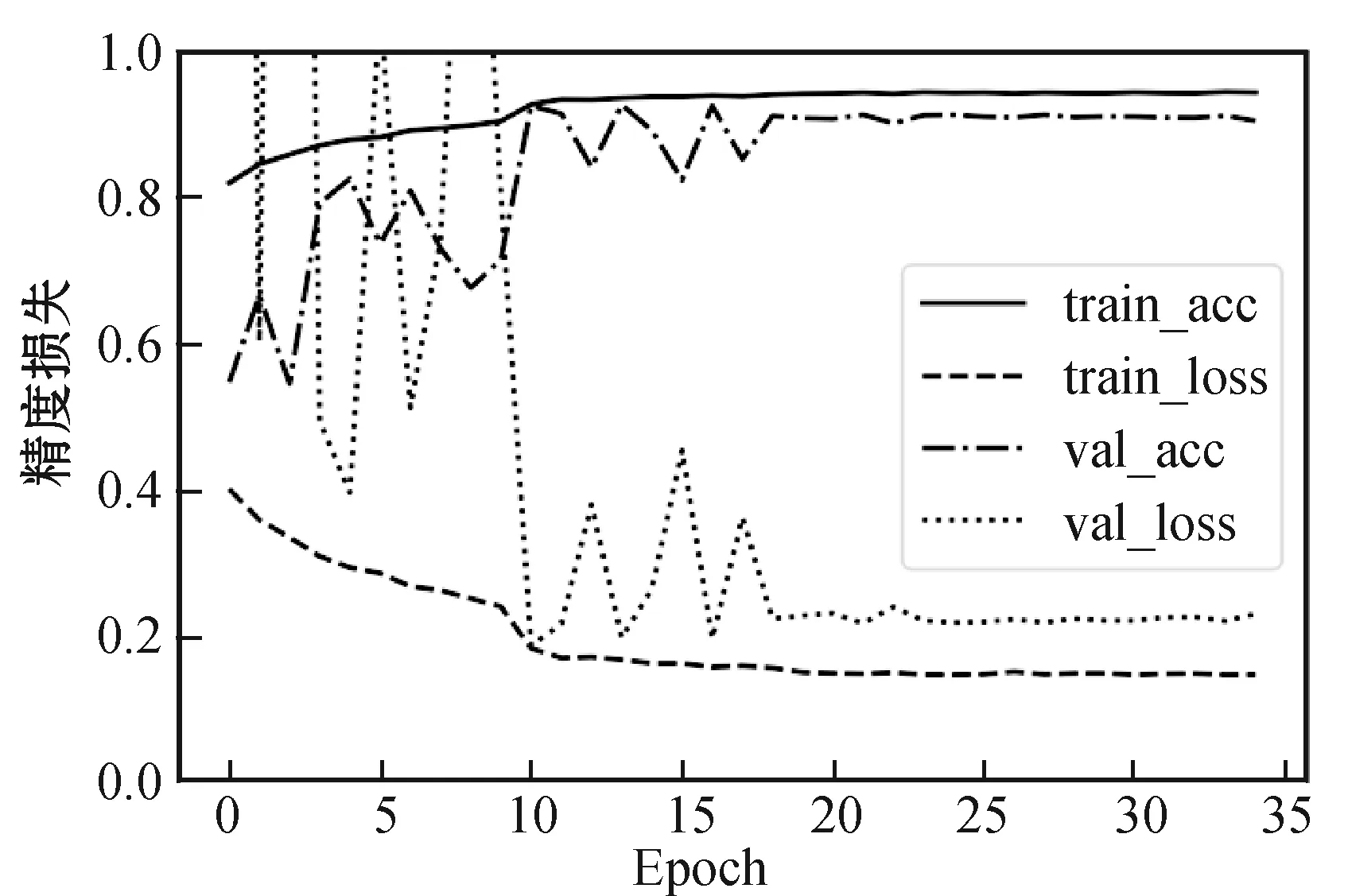
(b) 5层传统CNN图5 精度损失曲线图
应用W型CNN和传统顺序CNN,得到精度损失曲线如图5所示。从图5中可以发现,随着Epoch的增加,5层W型CNN的训练精度和验证精度贴合的非常紧密,几乎重合在一起。训练损失和验证损失曲线也趋于一致。5层传统CNN,精度曲线有一定偏离,损失曲线偏离的更大。
2.2 混淆矩阵实验对比
除了分析精度损失曲线,采用混淆矩阵做进一步的探讨。混淆矩阵是对网络模型预测结果的一种总结分析,列出测试集的真实类别与模型预测类别,以矩阵形式呈现出来。测试集中健康病理图像占8 600幅,乳腺癌病理图像占8 000幅。经过实验测试,得到混淆矩阵如图6所示。列方向上也就是斜体字对应的部分,是模型预测的结果,行方向上是真实值。
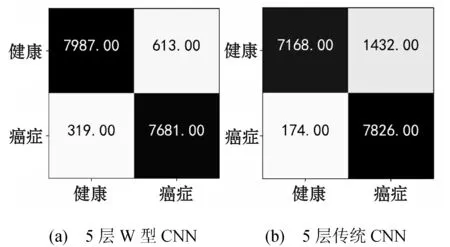
图6 混淆矩阵实验对比
图6中,两个矩阵的左上角表示真实值为健康,模型也认为健康的图像数量,称作真阴性(True Negative,TN)。右上角表示真实值为健康,但模型却认为是癌症的图像数量,称作假阳性(False Positive,FP)。左下角表示真实值是癌症,但模型却认为是健康的图像数量,称作假阴性(False Negative,FN)。右下角表示真实值是癌症,模型认为是癌症的图像数量,称作真阳性(True Positive,简写为TP)。混淆矩阵里面列出的是图像数量,为了更加直观衡量模型的优劣,在混淆矩阵的统计结果上给出准确率(accuracy)这个评价指标。准确率是指被网络模型识别正确的图像数量除以所有的样本数,一般而言,准确率越高,分类器越好。计算公式定义为:
(7)
Nahid 等[17]采用LSTM(Long Short Term Memory)模型,对放大40倍的乳腺癌图像进行分类识别,得到TP所占比例为94.76%,相应的TN所占比例为53.55%,而本文提出的CNN,得到的TP和TN所占比例分别为96.0%和92.9%,即7 681/(7 681+319)和7 989/(613+7 989)。Spanhol等[18]针对40倍的乳腺癌图像,采用 PFTAS (Parameter-Free Threshold Adjacency Statistics)提取特征,且使用QDA(Quadratic Disriminant Analysis)方法进行识别分类,得到的准确率为83.8%。采用PFTAS+SVM (Support Vector Machine)和PFTAS+RF(Random Forests)方法,得到的识别准确率分别为81.6%和81.8%。马慧彬[19]针对乳腺恶性肿瘤和良性肿瘤的X射线图像,采用由RBM(restricted Boltzmann machine)构成的深度置信网络进行识别,准确率为83.32%。根据公式和图6,5层传统CNN的准确率为90.3%,而提出的CNN的准确率为94.3%,在识别上具有一定的优势。
3 结 语
针对乳腺癌诊断治疗,提出一种精简的5卷积层W型结构的CNN,可以快速精确地对乳腺癌图像进行分类识别。和传统结构的5层CNN相比,提出的神经网络具有更好的抗拟合性质,训练精度曲线和验证精度曲线较好的重合在一起。进一步通过混淆矩阵测试,测试结果再次表明,提出的网络具有更好的准确率。又因提出的网络只采用5个卷积层,网络参数得到精简便于硬件高效实现。提出的网络能优化和加速乳腺癌分析,从而更加可靠地、高效地向乳腺癌患者提供诊疗方案,将具有重要的理论研究意义和临床实践价值。两种CNN结构进行对比,主要在中小数据集下进行,对于大型数据集的情况还要做进一步分析。下一步研究采用可编程逻辑硬件,用一个芯片把W型CNN进行硬件实现,主要进行推理测算,采用并行编程实现且参数较少,能快速进行推理。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
心理学报(2022年5期)2022-05-16
计算技术与自动化(2022年1期)2022-04-15
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
当代陕西(2020年17期)2020-10-28
上海师范大学学报·自然科学版(2019年5期)2019-12-13
