
基于机器学习的心脏病预测模型研究
2022-02-19 14:19辛瑞昊董哲原苗冯博王甜甜李英瑞
吉林化工学院学报 2022年9期
辛瑞昊,董哲原**,苗冯博**,王甜甜**,李英瑞**,冯 欣
(1.吉林化工学院 信息与控制工程学院,吉林 吉林 132022;2.吉林化工学院 理学院,吉林 吉林 132022)
世界卫生组织(WHO)提供的数据显示,全球近31%的人口死于心脏相关疾病.据世界卫生组织统计,近1520万人死于心脏相关疾病或心血管疾病[1].心脏病在全世界造成了巨大的死亡率,并威胁着许多人的健康.早期预防心脏病可能挽救许多生命,通过常规的临床数据分析,检测心脏病发作、冠状动脉疾病等心血管疾病是一项艰巨的挑战.机器学习(Machine Learning)可以为决策和准确预测带来有效的解决方案.在医疗行业中,使用机器学习技术方面取得了巨大的进展.
Pahwa K[2]使用支持向量机递归特征消除(SVM-RFS)进行特征选择,利用随机森林和朴素贝叶斯应用于心脏病的预测.Shan X[3]采用最佳首次搜索算法(CFS)选择关键特征以降低特征维度,通过改进的随机森林算法对心脏病进行预测,该方法具有很好的预测效果.刘宇[4]使用基于聚类和XGboost算法对心脏病数据进行预测,实验表明该方法能够有效地提高预测的准确率.已有工作在对心脏病预测的准确率上仍有很大提升空间,不能达到心脏病临床诊断的性能要求.因此,为了进一步提高心脏病预测模型的准确率,通过特征选择、不同机器学习模型对比、可解释性分析等方法实现对心脏病的准确预测,为模型的一线临床应用打下基础.
1 数据来源及分析方法
1.1 数据资料
本实验验证过程数据集选取来源于克利夫兰数据库(Cleveland Clinic UCI)所构建的开源心脏病例数据集.该数据集分为心脏病样本和正常样本两类,共计303个样本数据,其中包括心脏病样本165个,健康样本138个,正负样本数目总体上相对平衡.本实验以数据集中14个变量作为研究对象,在14个变量信息中,13个指标为特征变量,最后一个作为预测变量,其中性别、血糖值、运动性心绞痛类别和目标变量为布尔类型(Boolean),年龄、胸痛类型、血压值、心电图、最大心率、运动ST峰值坡度、血管数量和心脏缺陷是整数类型(Int),胆固醇值和运动ST值是浮点类型(Float),具体如表1所示.

表1 数据集特性列表
1.2 数据探索和预处理
数据探索和预处理是心脏病数据分析的首要环节,这一环节直接影响后续机器学习模型分类效果.在数据分析过程中,符合正态分布的数据可以解决异方差和线性度的问题,有利于统计推断和假设验证.使用的心脏病数据直接从UCI网站下载,其中的离散特征数据已经经过数值编码,UCI提供的数据集是编码后的数值矩阵,不需要再进行额外的编码,能够直接对该数据集进行预处理.本研究python版本为3.8.3上,采用0.22.1版本Sklearn-processing库中StandardScaler包对原始数据中所有特征和标签均进行标准化预处理.利用StandardScaler进行标准化的原理为计算每列数据间的均值和方差,然后基于计算出的均值和方差转换数据,从而使数据符合标准正态分布.对数据标准化后,不仅可以提升机器学习模型的收敛速度,甚至还能提升模型分类效果.
1.3 研究方法
1.3.1 特征选择算法
数据特征被广泛应用于大数据挖掘、分析及机器学习等领域中,解决了医学数据“少样本高纬数”的难题.此外,选择重要数据特征也是识别疾病生物标志物的关键因素.从原始数据集中选择最大相关、最小冗余的特征子集,能够提高模型分类准确性,减小模型时间复杂化度,可进一步挖掘心脏病潜在性的生物标记物.利用T检验(T-test)和卡方检验(CHI)进行特征选择,通过P-value值和卡方值挖掘显著差异性特征,通过该方法能快速找到影响心脏病的关键性特征因素,选择出最大相关、最小冗余的特征子集.
1.3.2 机器学习模型

1.3.3 评价指标选取
对于心脏病存活性预测模型的评估,使用7个医学领域广泛使用的评价指标对10种机器学习模型分类效果进行评估[5],其中包括精确率(Precision)、特异性(Specificity)、敏感性(Sensitivity)、马修系数(MCC)、准确率(Accuracy)、F1指标(F1-score)和AUC(Area under roc curve).
为了评估论文提出方法的可行性,分别评估了精确率、敏感性、特异性和马修系数.其中,精确率指模型预测为正的样本中实际也为正的样本占被预测为正的样本的比例,计算公式为:
(1)
敏感性指实际为正的样本中被预测为正的样本所占实际为正的样本的比例.计算公式为:
(2)
特异性指实际为负的样本中被预测为负的样本所占实际为负的样本的比例.计算公式为:
(3)
马修系数通常在两个类别样本数量差异比较大的时候仍然能够有效地缓解样本不均衡带来的敏感度.其本质上是一个描述实际分类与预测分类之间相关系数的指标,计算公式为:
(4)
其中,真阴性(TN)是预测为健康标签与真实为健康标签匹配的数量;真阳性(TP)是预测为心脏病标签与真实为心脏病标签匹配的数量;假阴性(FN)是指心脏病样本标签被错误识别为健康的数量;假阳性(FP)是健康样本标签被预测为心脏病样本标签的数量.
准确率评估不同机器学习模型的总体分类精度,具体指的是机器学习模型正确预测心脏病患者和健康患者能力,计算公式为:
(5)
其中Npredicted表示预测正确的样本总数;Ntotal表示样本总数.
F1-score为精确率和召回率的调和均值,通过计算F1分数分别衡量心脏病和健康样本的分类表现,计算公式为:
(6)
AUC(Area under curve)指的是ROC(Receiver operating characteristic curve)曲线所覆盖的面积.由于ROC很难反映模型之间的差异,AUC作为数值可以明确地反映出模型之间的差异,其中AUC越接近1,模型的性能越好[6].计算公式如下:
(7)
其中positiveclass表示类别为正例;xi为第i个样本;rank为模型预测实例中属于正例的概率大小的排序;M是实际为正例的个数;N是实际为负例的个数.
1.3.4 特征可解释性方法
心脏病分析过程中,除了要得到准确的分类结果,同时需要得到重要特征对模型预测结果的影响,从而为精准医疗提供决策支持.通过机器模型进行分类的过程中,模型往往被当作黑盒子,不能表现出每个特征对分类结果的贡献[7].因此,利用SHAP方法对数据集的特征进行分析,可视化每个特征在模型中的重要程度,进而表现每个特征对分类结果的影响[8].
为了能够了解单个特征在机器学习模型中的贡献,通过利用SHAP对特征进行可解释性分析.SHAP值的计算公式如下:
(8)
其中yi为样本的预测值;ybase为整个模型的基线(通常是所有样本的目标变量的均值);f(xij)表示第i个样本中第j个特征对最终预测值yi的贡献值,当f(xij)>0,表明该特征起正作用,增大预测值,反之,说明该特征起反作用,减小预测值.
利用Python的SHAP方法对心脏病预测模型中每个特征的作用进行可视化分析,该方法为不依赖于机器学习模型的可解释性方法,适用于多种机器学习模型.特征可解释通过对训练集中的患者的样本数据进行计算,得到每个特征的SHAP值数据,进而确定单个特征对预测结果的作用.
2 模型对比实验和基于SHAP方法的可解释性分析
2.1 特征选择
心脏病数据集包含13个特征,所以在筛选差异特征时,T检验和CHI检验更有利于高纬特征样本间的特征筛选.利用T检验模型计算每个特征的显著性水平(P-value),按照P<0.05进行筛选,获得差异表达的特征.通过卡方检验计算每个特征的卡方值,CHI值越大,特征区分度越强.通过计算13个特征P值和CHI值,绘制-Log(P-value)如图1所示,绘制CHI值柱形图,如图2所示,可以观察到前13特征之间存在显著差异性.然后,通过P-value值降序排列进行特征递减实验,进而得到最优特征组合.

特征图1 T-test特征排序
2.2 与已有工作的实验结果对比
通过对13个特征按照P-value值降序排列进行特征递减实验,选取Bagging作为分类模型,验证1~13个特征组合下,模型分类的准确性.特征递减组合在Bagging模型上ACC曲线如图3所示.

特征数图3 不同特征组合在Bagging模型上ACC曲线
选择5个特征组合,在10种机器学习算法上进行模型训练,并使用医学上常用的7个指标评估上,验证模型分类效果,其结果如表2所示.在10种机器学习模型中,Bagging算法分类结果最优,各项评价指标均为1.
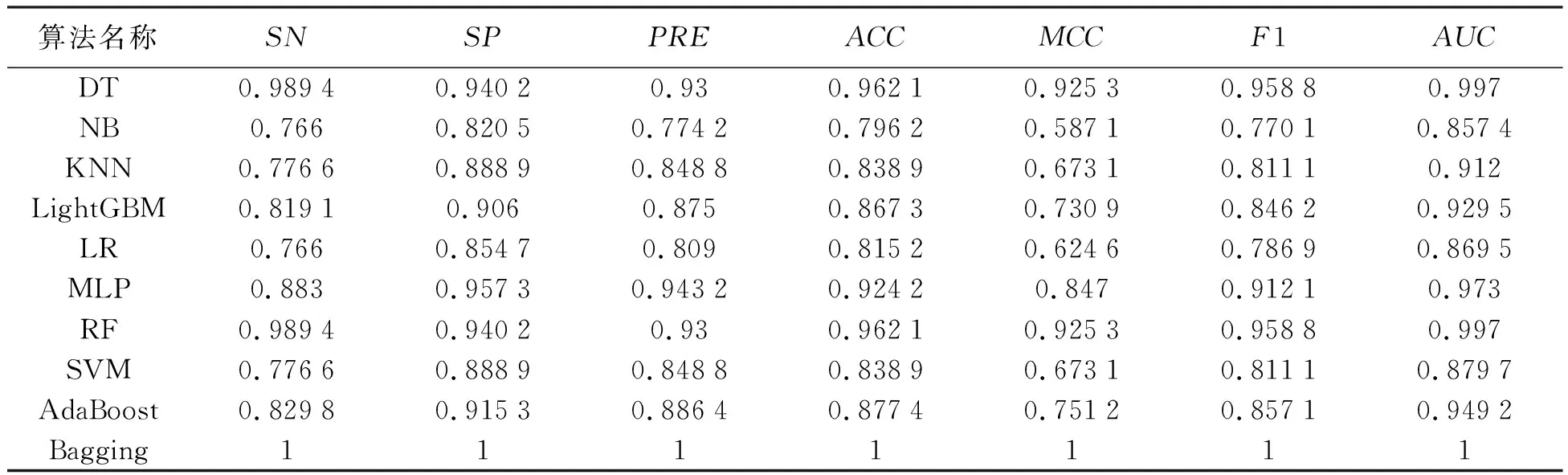
表2 10种机器学习模型指标对比结果
本节将Bagging模型与已有工作提出的粒子群优化支持向量机(PSO-SVM)、概率神经网络(PNN)和随机森林(RF)进行性能对比,其对比结果如表3所示.

表3 与已有工作的对比结果
利用T检验得到5个特征组合,在Bagging模型上得到各个评价指标均为1,其结果远优于已有工作的实验结果.
2.3 特征可解释性分析
特征的可解释性分析主要通过SHAP方法实现,通过心脏病预测模型结果进行解释性分析,挖掘单个特征对心脏病预测模型产生的影响.图4为SHAP特征蜂群图,该图反映各个特征取值的高低对SHAP取值的影响.图5为SHAP特征摘要图,该图根据特征重要性对影响心脏病特征进行分析.
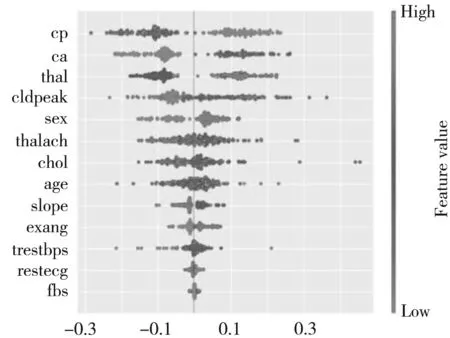
SHAP value(impact on model output)图4 SHAP特征分析
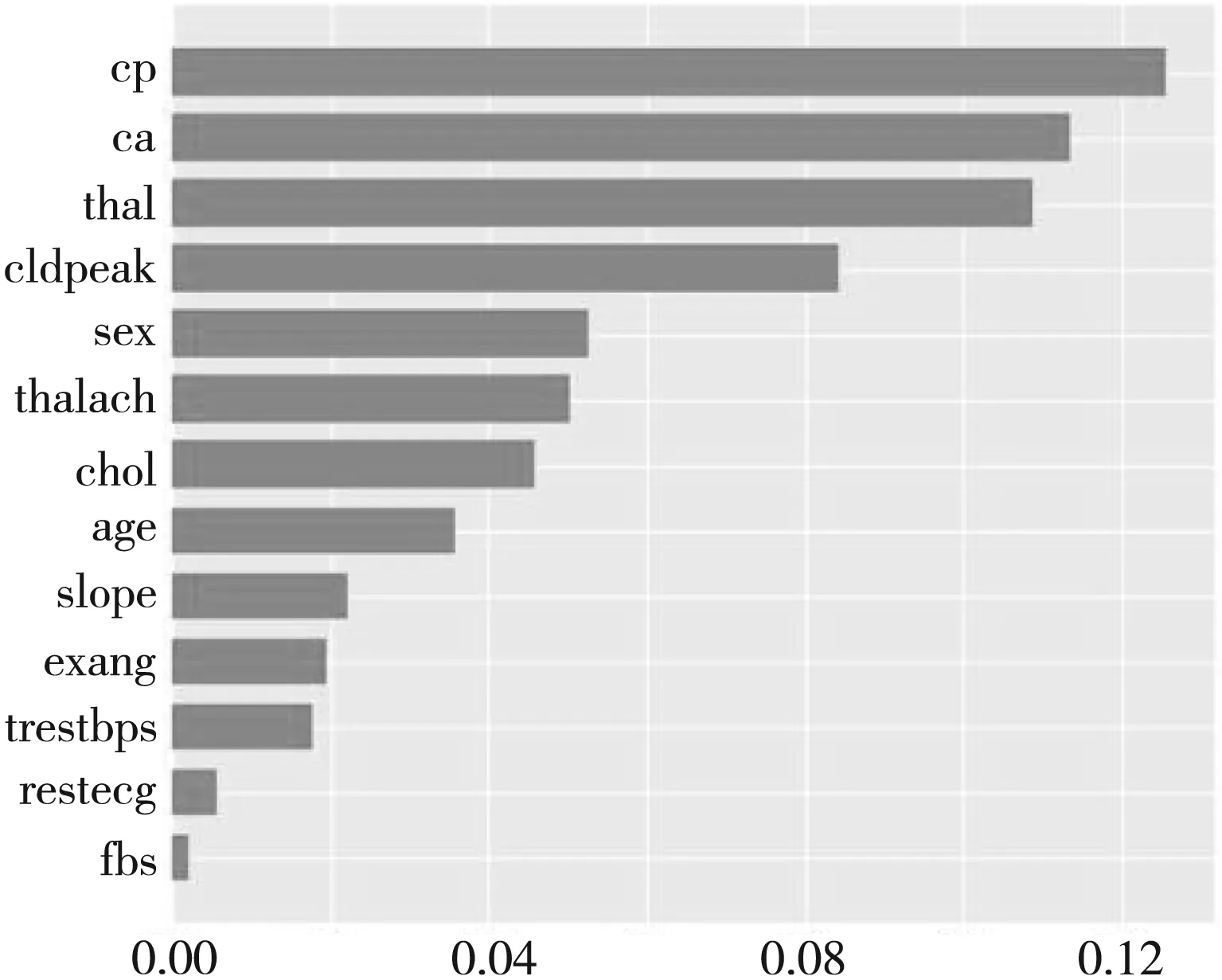
mean(|SHAP value|)(average impact on model ourput magnitude)图5 特征重要性排名
如图4和图5所示,Cp(胸痛类型)、Ca(主动脉数量)、Thal(心脏缺陷)、Oldpeak(运动ST值)等特征对模型影响较为显著.通过韦恩图可视化T-Test、CHI检验和SHAP特征图的前5特征交集如图6所示,3种特征选择前5个特征的交集为CP、CA、Oldpeak.

图6 3种特征选择方法前5特征韦恩图
结合SHAP图对韦恩图3种特征选择方法的交集特征进行分析,影响心脏病的最重要特征为Cp(胸痛类型),该特征对心脏病的影响呈现出线性关系.Ca(主动脉数量)和Oldpeak(运动ST值)对心脏病也有着显著影响,随着主动脉数量和运动ST值增大,患心脏病的风险不断增大.
3 结 论
利用T检验来挖掘特征之间的显著差异性,利用10种机器学习模型来预测心脏病.采用公开UCI中的心脏病预测数据集来测试提出的方法,通过SHAP值对来挖掘单个特征对模型的影响.结果显示,与对比论文结果相比,利用T检验与Bagging模型相结合的方法,在5个特征组合时,各项评价指标为1,能够准确对心脏病进行预测.同时通过SHAP可视化分析方法,表明胸痛类型、主动脉数量与心脏病之间的关联,对心脏病的精准医疗有指导意义.
猜你喜欢
中老年保健(2022年2期)2022-08-24
中老年保健(2022年5期)2022-08-24
法律方法(2021年4期)2021-03-16
文教资料(2018年30期)2018-01-15
妈妈宝宝(2017年4期)2017-02-25
电子制作(2017年23期)2017-02-02
中国宪法年刊(2016年0期)2016-05-20
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
中学科技(2014年12期)2015-01-06
