
综合交通多源异构大数据治理技术应用研究
2022-02-28 22:39钟卫东王庭基肖隆妍张明俊黄俊浦
交通科技与管理 2022年3期
关键词:聚类分析
钟卫东 王庭基 肖隆妍 张明俊 黄俊浦



摘要 随着信息化的快速发展,交通运输行业累积了大量多源异构的数据资源,治理综合交通多源异构大数据,实现信息资源融合共享是交通运输行业信息化管理的关键问题。文章通过分析综合交通多源异构数据类别、研究多源异构数据治理技术,并运用聚类分析方法挖掘交通运输行业数据资源价值,对实现“用数据决策、用数据管理、用数据创新”,提升行业治理能力和服务水平,促进行业转型升级具有重要意义。
关键词 大数据治理;多源异构;综合交通;聚类分析
中图分类号 D631.5 文献标识码 A 文章编号 2096-8949(2022)03-0019-03
0 引言
2019年7月和12月,交通运输部先后印发《数字交通发展规划纲要》和《综合交通运输大数据发展行动纲要(2020—2025)》,提出要以“数据链”为主线,构建数字化的采集体系;提出推动大数据与综合交通运输深度融合,有效构建综合交通大数据中心体系,为加快建设交通强国提供有力支撑。
随着交通信息化的快速发展,通过智能交通终端采集的轨迹、流量、视频、图像等数据和通过业务系统产生的多源异构数据越来越多。面对综合交通多源异构大数据,传统的数据存储、处理以及分析方法已经不能充分挖掘出具有高价值密度的数据信息。因此,治理多源异构交通大数据,成为制约综合交通信息化发展的瓶颈,必须积极采取有效措施加以解决。
1 综合交通多源异构数据分析
综合交通数据包含公路(高速公路、国省干线、农村公路)、运输管理(公交、出租、网约车、两客一危、普货、维修、驾培)、港航、质监、综合执法、铁路、民航、公安交警、气象、自然资源、互联网数据等。详见表1。
从表1可知,综合交通数据来源与交通行业内外多个部门,同类的数据在不同的系统中类型和数据结构也各不相同,呈现多源异构特点,给数据的采集增加了难度。同时,大量的智能交通终端设备,如卫星导航定位、视频监控、交调、治超等,实时采集大量数据,而业务系统也不断在产生业务数据,导致了综合交通数据量的庞大。但是大量的数据价值密度却不高,因为数据可能存在样本不完整、连续性差、重复冗余等情况。因此,综合交通大数据的治理变得尤为重要。
2 综合交通多源异构数据治理
数据在采集过程中会存在设备故障、信号干扰、人为失误操作以及环境影响等误差因素,导致所获取多源异构数据存在不同程度的质量问题,影响后续数据分析研究。必须采取科学的理论方法控制数据质量。
2.1 冗余数据处理
可以利用Hadoop平台处理存在于大数据中的冗余数据,步骤如下[1]:
(1)通过Eclipse开发平台编写MapReduce关键字统计程序,将程序导成jar包运行在Hadoop数据平台处理相应文件存在的冗余数据。如交通流量数据以经过时间和车辆号码为关键字;道路事故数据以事故时间、事发地址为关键字;执法数据以执法记录时间、执法地址以及号牌号码为关键字。
(2)若某条数据的统计结果=1次,则该条数据不属于冗余数据,应正常输出;若某条数据的统计结果>1次,则该条数据属于冗余数据,因此,输出该数据首次出现的信息即可。经过冗余数据处理后的不同类型数据需要重新存储在HDFS分布式文件系统,以备后续数据处理所需。
2.2 缺失数据处理
综合交通大数据普遍存在缺失现象,无法为分析研究提供准确信息,因此,需要采取相关数据处理方法补充缺失值。同样可以采用Hadoop数据平台检测处理缺失数据。
针对道路事件、治超违法等非连续数据存在缺失的情况,可以通过编写MapReduce程序Map函数判断Value所含字段内容是否为空值,如某条元素数据字段为空值则删除该数据,输出不存在字段为空元素数据;在Reduce阶段通过编写Reduce函数将Map阶段输出数据保存至HDFS文件系统。
而针对交通流量等具有连续性和实时性的数据,数据的缺失值处理方法与非连续数据有所不同。通过查阅相关文献可知,修复此类数据可采用历史数据修复法[2]、时间序列分析法[3]等修复方法进行缺失数据处理:
(1)历史数据修复法:数据缺失值采取赋予前几天同一时刻以及同一天前一时刻的历史数据不同权重且相加的方法填补。该方法的优势在于既体现历史数据的价值,又考虑实时数据的影响。
(2)时间序列分析法:利用同一天与数据缺失时刻相邻时刻交通流数据,修复缺失数据的数据处理方法。它通过赋予不同时刻数据不同的权重体现影响程度的大小进行综合计算。
具体适用情况如表2。
3 综合交通多源异构数据聚类分析
聚类分析是大数据挖掘的主要方法,其核心思想是依据不同数据具有相同属性的原理上,通过计算数据集中不同数据之间的相似性度量函数(欧式距离、曼哈顿距离等),將距离最近的数据划分为相同类并且计算每类的聚类中心,不断重复上述过程直至所有数据聚合至特定类[4-5]。
数据聚类与分类有所不同,聚类分析的数据特征以及聚合类数均未知,属于无监督学习算法;然而,数据分类已明确数据的类数和特征,属于监督学习算法。随着国内外学者不断努力完善聚类理论,聚类分析算法的研究已经越来越成熟,根据聚类算法的原理,主要包含划分聚类、层次聚类、密度聚类以及网格聚类等四种方法[6-7]。四种不同聚类分析算法的原理和特点各不相同,查阅相关参考文献总结,不同聚类分析算法特点如表3。
划分聚类方法:最基础的聚类算法,原理简单便于理解以及计算收敛速度快,非常适用于球形以及类似球形分布的数据集。基于划分聚类的代表性算法主要包含K-means(均值)聚类算法、K-medoid(中心点)算法。
层次聚类方法:将指定的数据集按照层次的方法进行分解,通过逐步更新迭代分解使得类的个数以及每个类中所含元素数据的个数不断调整,最终以树状图的形式清晰展示聚类结果。
密度聚类方法:依据样本数据集的密度进行聚类。适用于凸形以及球形等任意形状分布的数据集,可以解决不规则分布的数据聚类分析问题。
网格聚类方法:将样本数据集划分为有限网格数据单元,不同网格单元可代表多条元素数据,通过距离度量不同网格单元之间的相似性,合并距离相近的网格单元为相同类别。
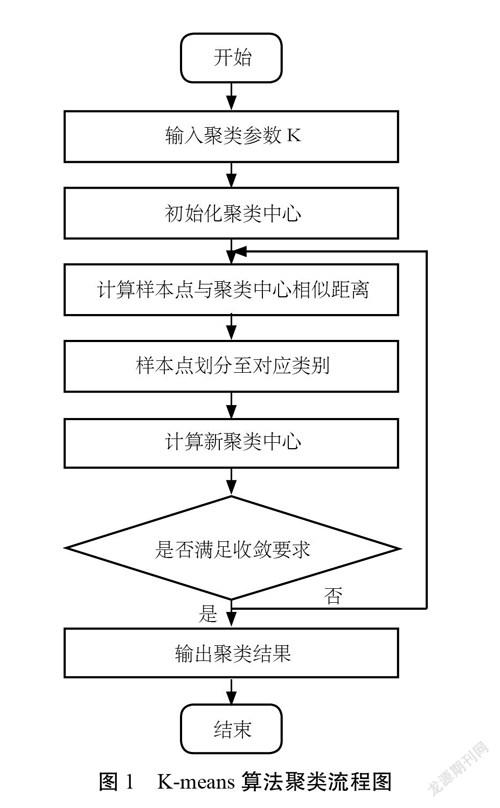
针对综合交通多源异构大数据,建议采取划分聚类分析方法,且因K-means聚类算法时间复杂度低、原理简单便于理解、计算速度快以及扩展性良好,可采用K-means算法聚类分析多源异构交通大数据(流程图如图1)。
K-means算法的核心思想是根据需求将数据集聚类个数设置为K,目标是通过度量不同数据之间的相似距离,将数据集根据相似性强弱划分为K类。K-means算法聚类时,首先在数据集中选取K个数据聚类中心点,计算不同数据与每个聚类中心点之间的距离,然后,根据距离大小将相近数据合并为相同类别。虽然,该算法的数学原理简单,但是聚类效果却明显优于其他聚类算法。
4 结论
综合交通大数据以不同形式从不同角度诠释了交通数据的多样性,为多源异构大数据治理提供了丰富的数据源,同时也使得运用K-means聚类方法智能分析交通大数据成为可能。
数据驱动服务是综合交通信息化的核心,随着综合交通数据的种类和数量快速增長,治理多源异构大数据成为关键核心。该文通过分析综合交通多源异构数据情况,研究多源异构数据治理方法,并比较出适用于综合交通多源异构数据的聚类分析方法,对于开展智慧交通数据中心暨展示平台建设,整合大数据资源实现数据综合展示提供技术支撑。
参考文献
[1]游兆权.基于Hadoop大数据平台的交通拥堵预测研究[D].北京:中国人民公安大学,2018.
[2]王腾辉.基于Spark平台的短时交通流预测研究[D].广州:华南理工大学,2016.
[3]王远强.面向交通数据的事故分析与预测[D].天津:天津大学,2017.
[4]LAKSHMI K,VISALAKSHI N K,SHANTHI S.Data clustering using K-Means based on Crow Search Algorithm[J].Sadhana,2018(11):190.
[5]KHAN S S,AHMAD A.Cluster center initialization algorithm for K-means clustering[J].Pattern Recognition Letters,2004(11):1293-1302.
[6]卢跃凯.面向海量移动互联网用户行为的聚类算法研究与实现[D].北京:北京邮电大学,2019.
[7]吕峰.主动半监督 K-means 聚类算法研究及应用[D].石家庄:河北地质大学,2018.
猜你喜欢
软件导刊(2016年11期)2016-12-22
科技创新导报(2016年21期)2016-12-17
对外经贸(2016年8期)2016-12-13
数学学习与研究(2016年19期)2016-11-22
商场现代化(2016年26期)2016-11-21
大经贸(2016年9期)2016-11-16
中国市场(2016年33期)2016-10-18
科技视界(2016年20期)2016-09-29
企业导报(2016年9期)2016-05-26
