
基于IABC-LSSVM的瓦斯涌出量预测模型研究*
2022-02-28 13:55刘志中齐俊艳
传感器与微系统 2022年2期
王 磊, 刘 雨, 刘志中, 齐俊艳
(河南理工大学 计算机科学与技术学院,河南 焦作 454000)
0 引 言
在矿井建设和生产过程中,准确预测出瓦斯的涌出量,对预防和控制瓦斯事故的发生具有重要的实际意义。在采煤工作面上,瓦斯涌出量受煤层厚度、埋藏深度、瓦斯含量等诸多因素的影响,并且这些因素之间往往存在复杂且动态的非线性关系,用矿山统计法、分源预测法等一般的线性模型很难满足预测精度的要求[1]。
随着人工智能技术的发展,国内外学者结合机器学习的相关算法提出了很多有效的非线性预测方法,包括CART[2]、神经网络[3]、主成分回归分析法[4]、支持向量机(support vector machine,SVM)[5]等,这些方法都取得了较理想的预测结果,但是经典的CART回归算法稳定性较差,即使数据发生很小的改动也可能会导致生成一个完全不同的树;神经网络适用于样本数量趋于无限多时的场景,忽视了各影响因素之间的物理关系,易陷入局部最优;回归分析法会因为因素之间存在着复杂的动态关系,而导致拟合效果不太理想;SVM能有效表达数据间的非线性的关系,比较符合瓦斯涌出量预测的应用,但是预测精度取决于其参数的选取,若选取不恰当,准确度就会比较低。
本文在考虑SVM的适用性及易受参数干扰的基础上,以进一步提高瓦斯涌出量预测精度和泛化能力为出发点,提出了一种基于改进的人工蜂群算法(artificial bee colony algorithm)与最小二乘支持向量机(least square SVM,LSSVM)相耦合的预测方法。结合IABC的优点,来解决LSSVM中参数的选择寻优问题[6],通过构建基于IABC-LSSVM的瓦斯涌出量预测模型,对煤矿工作面上的实际涌出量展开预测。
1 ABC优化算法
1.1 标准ABC算法
标准ABC[7]算法是一种模拟蜜蜂群体采蜜行为的智能优化算法,将蜂群分为采蜜蜂、观察蜂和侦查蜂3种类型。采蜜蜂负责搜索蜜源,并测量蜜源质量即适应度函数值,同时将蜜源信息分享给其他蜜蜂;观察蜂则是通过采蜜蜂分享的信息,以一定的概率选择蜜源进行搜索;侦查蜂是随机搜索蜜源。
标准ABC算法实现的具体步骤如下:
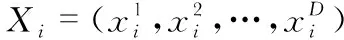
(1)
式中δij为(-1,1)间的随机数,j∈{1,2,…,D},每次求解后都要根据适应度函数值判断优劣,适应度函数为
(2)
2)采蜜蜂阶段:采蜜蜂的职责是增加花蜜量(适应度),并且在蜜源附近随机产生一个候选解
vij=xij+θij(xij-xkj)
(3)
式中xij为第i个蜜源的第j维分量,xkj为随机选取的不同于xij的蜜源,k∈{1,2,…,SN},θij为(-1,1)间的随机数,利用式(3)生成新参数vij,如果vij的适应度高于xij,则将xij用vij代替。
3)观察蜂阶段:根据采蜜蜂分享的蜜源信息重新计算蜜源的适应度和访问蜜源的概率进行进一步的开采
(4)
式中fj为Xi的适应度。
4)侦察蜂阶段:如果一个蜜源被开采到上限后适应度值仍未做出更新,则被淘汰,采蜜蜂也将变成侦察蜂。同时侦察蜂将放弃当前蜜源并根据式(1)重新随机生成一个新的蜜源,进行下一轮的搜索。
1.2 IABC优化算法
1)引入混沌序列产生初始蜜源。一般情况下,在ABC算法中往往会生成一系列的-1~1之间的随机数,通过式(1)转换成初始蜜源。但是这种方法常常会导致最优参数集中在局部区域,并且在后续的迭代中达到局部最优。而混沌序列是遍历的、不规则的、随机的,因此,引入混沌序列来代替原始的随机序列可以有效避免局部单一性,保证了种群的多样性,以获得更好的初始种群。混沌序列是正弦序列的简化形式,公式为
b(m)=sin(πb(m-1))
(5)
式中m=1,2,…,n,n为混沌序列总数。将b(0)和n(n>SN)代入式(5),以获得混沌序列下的初始种群,进而求得初始蜜源。
具体改进过程如下:首先,确定初始种群的数量,且该数值大于初始蜜源的值,然后利用式(6)替换式(1)产生初始种群,并通过距离函数估计的初始种群来确定蜜源
(6)
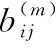
(7)
距离函数值D越小,说明两个解越相似,保留一个最佳结果,删除另一个,最后按照适应度函数的顺序确定其余初始种群的最终初始蜜源。
2)参数搜索步长的自适应调整。由于混沌序列的随机性和遍历性,搜索时会更加随机,但也可能造成ABC算法陷入局部最优的结果。为了解决这一问题,本文提出了一种自适应方法来调节搜索步长,将搜索步长从一维逐渐转变为多维,相应的搜索功能也会跟着变动。在搜索前期,应取较大的步长,保证收敛速度,加快向最优解靠拢;在搜索后期,应逐步减小范围实现最优解的细化搜索,降低在最优值附近的动荡的频率,提高收敛精度。基于此,引入了一种自适应因子来更新步长,其公式为
(8)
(9)
式中L为搜索步长,D为总参数维数,iter为当前迭代数,MEN为总迭代数。若当前迭代数小于等于总迭代数1/2,步长随着迭代数的增加而逐渐增加;若当前迭代数大于总迭代数1/2,搜索步长随迭代数的增加而逐步减小,提高收敛精度,并且使算法有效的摆脱局部最优的陷阱。
2 LSSVM算法
LSSVM是由文献[8]中Suykens等人在SVM的基础上提出的一种改进算法,用等式约束代替不等式约束,从而使求解二次规划问题转换成方程组求解问题,降低了算法的复杂度。由于瓦斯涌出量受多个因素的影响,属于非线性模型,因此使用LSSVM算法更具优势。其具体思想为:
给定一个训练数据集Q={(xi,yi)|i=1,2,…,N|},其中xi为n维向量,yi为输出向量,N为训练样本总个数,采用误差e的二次范数作为损失函数,LSSVM的优化问题可表示为
(10)
yi=wTψ(xi)+s+ei
(11)
式中w为权值变量,λ为正则化参数,ei为误差值,s为阈值,ψ(·)为核空间一个非线性映射。采用拉格朗日乘数法将原问题转换成乘子αi(ai≥0)求极大值的问题,构造如下函数
(12)
按照求极值的条件,则需设函数对于每个变量的偏导数为,可得
(13)
根据四个条件可以列出一个关于α和s的线性方程组
(14)
式中R=[1,…,1]2;A=[a1,a2,…,aN]T;Y=[y1,y2,…,yN]T;K为核函数,选择结构简单、泛化性能优异的径向基函数[9]作为核函数,可表示如下
(15)
式中σ为核宽度。在确定核函数后,LSSVM需要进一步确认的参数有:核宽度σ和正则化参数λ,采用IABC算法对两个参数进行寻优。
3 基于IABC优化的LSSVM的模型预测
IABC-LSSVM模型的建立过程如下:1)选取主要的影响因素作为训练样本,利用极差化的处理方法,对原始数据进行归一化预处理,并划分训练样本与测试样本;2)根据预测模型,对改进的ABC算法的各个参数进行初始化处理,设置初始种群数量、蜜源数目、最大迭代次数等参数;3)使用混沌序列生成若干初始种群,根据距离函数值择优,确定相应种群,同时求出每个种群对应的适应度值,得出最终的初始蜜源解;4)采蜜蜂根据式(9)查找新蜜源,同时求出对应的适应度.若该蜜源的适应度优于原有的蜜源,将进行替换的操作,否则维持不变;5)求出所有蜜源被选择的概率,然后观察蜂按照轮盘赌的策略选择蜜源进行采蜜,同时根据自适应因子调整步长在其附近搜索新蜜源;6)判断是否达到循环终止次数,若小于终止次数,则返回步骤(4),若到达循环终止次数后,蜜源的适应度值没有变化,则侦查蜂放弃该蜜源并产生新蜜源;7)到最大迭代次数后,输出最大适应度值对应的蜜源解,否则回到步骤(4)继续搜索;8)将最优解λ和σ2代入 LSSVM 模型,然后用测试样本对 LSSVM 进行训练,然后求解,再把所获得的参数代入式(15)得到回归估计函数。
4 瓦斯涌出量预测实验与分析
4.1 样本数据训练
本文根据开滦矿业集团钱家营矿区现场[10]的实际情况及主要影响因素,随机筛选出22组实测数据作为研究对象,其中,前15组为模型的训练数据,后7组为测试数据。选取影响瓦斯涌出量的9个主要影响因素,即煤层埋藏深度(X1/m)、煤层瓦斯含量(X2/(m3·t-1))、煤层厚度(X3/m)、层间岩性(X4)、工作面采出率(X5)、工作面长度(X6/m)、煤层倾角(X7/(°))、临近层瓦斯含量(X8/(m3·t-1))和邻近层厚度(X9/m),瓦斯涌出量(Y/(m3·min-1))为预测目标,各影响因素的数据见表1所示。

表1 各种影响因素原始数据
4.2 数据预处理
由于在样本空间中特征向量具有不同的物理意义和量纲,需在实验前对数据进行归一化处理,本文的归一化区间为[0.1,0.9],其数据的归一化公式为
(16)
式中X为当前特征的原始数据,Xmin为数据中的最小值,Xmax为数据中的最大值,Y为归一化后的输出值。预测过程完成后,需对数据进行反归一化处理,反归一化公式为
(17)
4.3 评价标准与参数设置
本文选取决定系数(coefficient of determination,R2)[11]和平均相对误差(MRE)[12]作为评价瓦斯涌出量预测模型的标准。决定系数也称拟合优度,越接近1,则表示数据拟合优度越好,相反,越接近0,表示拟合优度越差;平均相对误差是多个实测值与估计值之间相对误差的平均值。其具体计算公式为
(18)
(19)
本文模型的参数设置为:初始种群数量为80,蜂群规模为60,采蜜蜂和观察蜂的数目都为30,最大迭代次数MEN=100,最大混沌迭代次数为200,规定循环终止次数为50。同时设置核宽度和正则化参数搜索范围分别为:σ∈[0.01,5],λ∈[0.01,700],在经过IABC算法寻优后,得到其最优参数为:σ2=1.127,λ=206.73。
4.4 实验结果与分析
在相同的训练次数下,选取后7组数据进行对比分析,通过MATLAB仿真本文的IABC-LSSVM模型与基于遗传模拟退火算法与回归型支持向量机(genetic simulated annealing algorithm-regression support vector machine,GASA-SVR)[13]模型、基于灰狼优化的支持向量回归算法(support vector regression algorithm based on gray wolf optimization,GWO-SVR)[14]模型、基于改进人工蜂群的随机森林算法(random forest algorithm based on improved artificial bee co-lony,IABC-RF)[15]模型分别对瓦斯涌出量进行预测,采用相对误差率、MRE和R2对比这几种预测模型的性能,如表2。
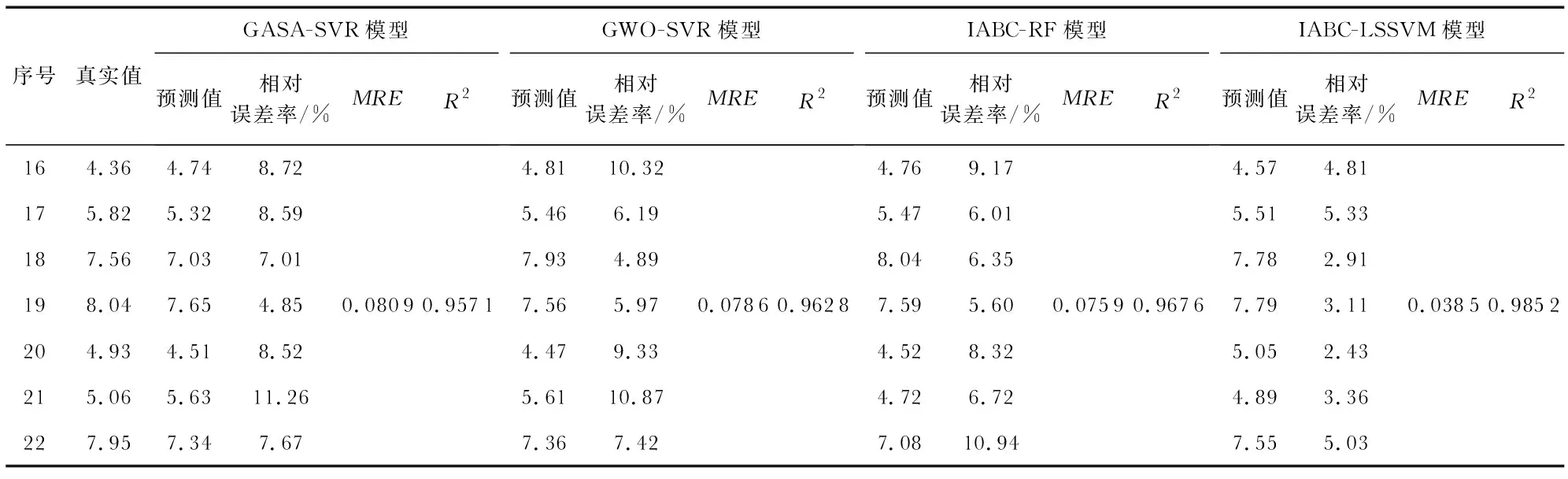
表2 四种算法的预测性能对比
由表2可知,在7组实测数据中,IABC-LSSVR模型的R2值高于GASA-SVR模型2.81 %,高于GWO-SVR模型2.24 %,高于IABC-RF模型1.76 %,同时相对误差率在不同程度上都有所下降,说明了IABC-LSSVR模型拟合优度较好,并且预测精度得到了明显的提高。从MRE这个指标上来看,IABC-LSSVR模型的MRE值相比于GASA-SVR模型降低4.24 %,相比于GWO-SVR模型下降4.01 %,相比于IABC-RF模型下降3.74 %,这说明IABC-LSSVM模型在保证了较高的预测精度的情况下也具有良好的泛化能力,模型的稳定性较强,能够更加准确预测出瓦斯涌出量。图1为四种模型预测的相对误差率的对比折线图,通过对比图可以看出,GASA-SVR的最大误差率达到11.26 %,GWO-SVR的最大误差率为10.87 %,IABC-RF最大误差率为10.94 %,IABC-LSSVM模型相对于其他三种模型,对于样本的预测误差率都是最低的,平均误差率仅为3.83 %,说明该模型拟合精度高,并且能够达到更加理想的预测效果。
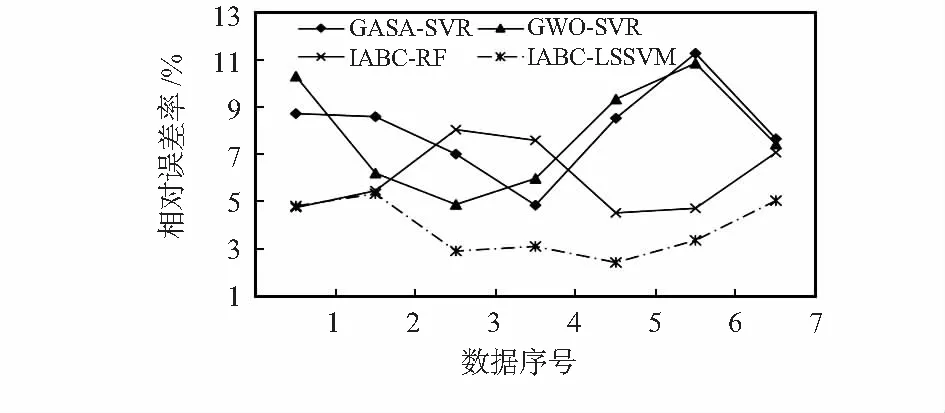
图1 相对误差率对比
图2为IABC-LSSVR模型预测的收敛过程,通过收敛曲线可以看出IABC-LSSVM在迭代中,前期蜜源进化保持着快速收敛状态,迅速搜索到最优解,后期个体适应度差异变大,避免发生早熟现象,即到达120代以后,IABC-LSSVR已经基本完全收敛,样本的拟合误差趋于最小。
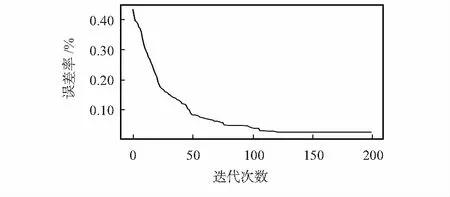
图2 收敛过程
为了更加直观地观察模型的预测值与真实值之间的差异,根据表2中的7个样本的实际数据,绘制真实值—预测值以及预测相对误差率的对比折线图,从图3可知,GASA-SVR模型、GWO-SVR模型、IABC-RF模型的真实值与预测值之间的上下浮动较大,而IABC-LLSVR模型的浮动较小,说明该模型在真实场景中能够最大程度地接近真实的变化曲线,具有较高的实用价值。

图3 四种算法的预测对比折线图
5 结 论
针对瓦斯涌出量的预测,提出了一种结合IABC和LSSVM相耦合的非线性学习模型。IABC算法中增加了混沌序列确定初始蜜源以及通过自适应因子调节搜索步长,增加了蜜源的多样性,使得蜜源的更新效果得到了一定的提升,有效避免了陷入局部最优解。同时利用IABC算法优化LSSVM的参数,并使用优化后的参数重建瓦斯涌出量预测模型,对瓦斯涌出量的预测有了进一步推动作用。实验结果表明:LSSVM预测模型相较于同类其他三种预测模型,具有更高的预测性能和更强的泛化能力,能够有效地实现煤矿瓦斯涌出量预测的目标。但由于煤与瓦斯突出影响突出的因素具有不确定性,如何在数据量较大的情况下进一步提高在预测准确性是下一步的研究重点。
猜你喜欢
肇庆学院学报(2022年5期)2022-09-29
林业与生态(2022年5期)2022-05-23
成都信息工程大学学报(2021年5期)2021-12-30
西安邮电大学学报(2021年1期)2021-04-19
健康大视野(2020年1期)2020-03-02
科技创新与应用(2019年26期)2019-10-24
高中生·天天向上(2018年1期)2018-04-14
电脑知识与技术(2017年2期)2017-04-25
学苑创造·B版(2015年12期)2016-06-23
中小企业管理与科技·中旬刊(2016年6期)2016-06-20
