
内容感知的图像重定向方法综述
2022-03-02 08:31郭迎春郝小可
计算机工程与应用 2022年4期
郭迎春,张 萌,郝小可
河北工业大学 人工智能与数据科学学院,天津300400
在计算机图像处理和计算机图形学中,图像重定向是指对数字图像的大小进行调整,以此来适配不同显示终端的长宽比。随着互联网和5G 技术的迅速发展,无论是技术方面还是用户体验方面都在不断提升,除了设备性能不断优化外,显示屏幕也在逐渐改进来满足人们的不同需求,如图1 所示。面对不同的显示屏幕大小,如何确保在屏幕的各种形态下,图像内容显示既完整又美观是研究者们面临的又一新问题,因此寻找一个合适的图像重定向技术是十分重要的。当图像的长宽比与显示屏幕的长宽比不匹配时,利用图像重定向技术,改变图像的尺寸大小来适应显示设备,从而可以提高显示设备的利用率并优化视觉终端的显示效果[1]。

图1 不同显示设备的图像重定向Fig.1 Image retargeting results on different display devices
传统的图像重定向方法主要包括均匀缩放和剪切。均匀缩放通过最近邻域插值[2]、双线性插值[3]等方法改变图像大小,适用于目标图像与原始图像变化比例不大的情况,且运算速度快。当这个变化比例较大时,会出现明显的拉伸或挤压变形。剪切是通过去除不重要的区域获得目标图像,方法简单但会导致图像内容显示不完全,通常结合美学感知获得具有高美感的图像[4-11]。
传统的图像重定向方法主要包括均匀缩放和剪切。均匀缩放通过最近邻域插值[2]、双线性插值[3]等方法改变图像大小,适用于目标图像与原始图像变化比例不大的情况,且运算速度快。当这个变化比例较大时,会出现明显的拉伸或挤压变形。剪切是通过去除不重要的区域获得目标图像,方法简单但会导致图像内容显示不完全,通常结合美学感知获得具有高美感的图像[4-11]。
基于内容感知的图像重定向是目前主流的方法。该方法根据图像内容使图像变形尽量发生在非重要的区域,从而获得更好的视觉效果,具有代表性的是基于内容感知的图像重定向[12],其特点是获取重要度图,根据重要度图进行重定向。重要度图的获取对于图像重定向至关重要,而获取符合人类视觉感知的重要度图是具有挑战性的任务。
随着深度学习的发展,大量有标注的数据为图像重定向提供了新的研究途径。然而基于深度神经网络的图像重定向仍处于研究的初级阶段,本文从图像重定向的发展入手,对基于重要度图和深度神经网络在图像重定向领域的发展问题进行归纳总结。此外,还介绍了一些常用的数据集以及评价方法,并探讨该领域在未来的研究方向。
总体来说,本文主要有以下三方面贡献:
(1)以重要度图的获取为线索,回顾了经典图像重定向方法的原理以及优缺点。
(2)详细总结了基于深度神经网络的图像重定向方法,虽然较传统方法文献数量较少,但是深度神经网络可以弥补手工特征的缺点,更好地表示图像语义结构,获取更准确的重定向图像。
(3)介绍了常用的图像重定向数据集以及评价方法,针对现阶段存在的问题,简单探讨了该领域未来的研究方向。
1 基于重要度图的图像重定向方法
图像重定向技术对于长宽比相同的显示设备的重定向在现阶段的发展较为成熟,比如对图像进行按比例均匀缩放,但对于长宽比不同的图像重定向技术还在探索阶段。面对这样的问题,早期的方法是剪切或像素填充,剪切的方法容易造成图像主体内容丢失,填充的方法会影响图像的美观并且降低显示设备的利用率。
为弥补早期方法的缺点,2007年Avidan和Shamir[12]首次提出基于内容感知的图像重定向方法。该方法专注于保护图像主体内容,首先检测出图像在视觉上重要的区域,从而获得重要度图,以此确定图像中各个区域的重要程度;然后根据像素的重要程度进行重定向处理,对重要度高的区域尽量保持不变或采取均匀缩放,将由于纵横比改变所产生的形变尽可能隐藏在重要度较低的区域,这样就可以保护图像的主体区域,以此获得较好的视觉效果。因此,基于内容感知的图像重定向技术可分为两步:获取图像重要度图和基于重要度图的重定向。
1.1 重要度图的获取
图像重要度图反映的是人眼对图像中不同内容区域变化的敏感程度[13]。不同的观察者有不同的主观看法,并且不同的应用场景也有不同的理解。在深度学习技术出现之前,大多是利用低层特征构造重要度图,通过手工特征进行图像重定向。该类方法属于无监督学习方法,通常利用图像梯度、显著度、对比度等信息计算重要度图。随着深度学习的发展,基于深度学习的图像重定向技术获得了广泛的研究。该类方法大多属于有监督的方法,需要大量有标注的数据集训练网络。由于深度学习具有强大的表征能力,能够弥补低层特征缺乏的高级语义信息,获得图像的语义特征,从而能够准确检测出复杂场景的重要度图。表1按照基于手工特征和基于深度学习方式归纳总结了多种获取重要度图的方法。

表1 重要度图获取方法Table 1 Importance map acquisition method
1.2 基于重要度图的重定向技术
基于重要度图的重定向技术大致可分为三类:以线裁剪为代表的离散型重定向算法[12,17,28-33],以变形为代表的连续型重定向算法[14,16,34-41]和多操作重定向算法[42-47]。
(1)离散型重定向算法
线裁剪(seam carving,SC)[12]是最早的基于内容感知的图像重定向算法,主要分为计算像素的重要度和增删裁剪线两个步骤。本着保护高能量像素,增删低能量像素的原则,该算法首先利用梯度图获得图像重要度图,然后采用动态规划算法找到累积能量最小的八连通路径作为最佳裁剪线,通过插入或删除该裁剪线达到放大或缩小的目的。对于一幅大小为n×m的图像,其垂直裁剪线S可表示为:

式中,x(i)表示映射x:[1,…,m]→[1,…,n],S是一条从第一行到最后一行的八连通路径。每条裁剪线S的能量计算由对应像素的重要度决定,若像素(i,j)的重要度为e(i,j),则S的能量表示为,因此最优裁剪线S*定义为S*=minE(S)。最优裁剪线通过动态规划算法获取,其中像素点(i,j)的累积能量M(i,j)可表示为:

获取累积能量图后,在能量图的最后一行找到最小累积能量的像素点,然后向上进行回溯,即可得到累积能量最小的最佳裁剪线。该算法能够有效地实现长宽比不同的图像重定向,但其仅仅将梯度图作为重要度图的参考条件,没有考虑当图像主体内部平滑区域梯度值较小时裁剪线会大量穿过图像主体区域的情况。由于裁剪线一般将最边缘的行(列)累积能量最小的像素作为起点,这会导致裁剪线穿过面积较小的重要区域或集中于一个区域生成,发生扭曲变形的情况。文献[30]针对线裁剪算法对图像过度裁剪造成的失真问题,提出基于图像分块的线裁剪算法,将分块的思想融入到线裁剪并优化累积能量图。为保护图像内容不丢失的同时还要保证图像的视觉美感,文献[48]引入美学原则来指导裁剪线的生成。离散型算法在图像重定向的长宽比变化不大时,效果较好,但是当目标图像的长宽比变化过大时,往往会丢失图像的信息,造成图像主体内容扭曲变形。
(2)连续型重定向算法
以变形为代表的连续型重定向算法是将图像分成网格,并计算各个网格内像素的重要度值,在重要度值及边界条件约束下,保障重要度值高的网格不发生形变或进行均匀拉伸,而使形变发生在重要度值低的网格中。文献[14,16,34-37]采用四边形网格,文献[38-41]采用三角形网格,其中Guo 等人[38]利用三角网格参数化,提出了基于显著性的网格参数化重定向方法,旨在估量划分的不同区域的目标网格的边长。网格变形算法在图像背景复杂时,会使图像重要区域在重定向过程中产生压缩或拉伸等变形失真现象。为解决图像保护不足的问题,Du 等人[49]融合梯度值、显著性、颜色等多种特征确定可变形空间,确定最优变形尺寸,从而保护不可变形区域的内容。谷香丽等人[50]运用弹簧近似法控制网格变形,对三角形网格设置弹簧系统,与已有的网格变形算法相比,效率变高。
(3)多操作重定向算法
早期的多操作重定向算法(multi-operator,MULTIOP)[42]是结合线裁剪、裁剪和缩放算法实现重定向。该算法考虑到对图像的多种影响因素,如图像内容丢失程度、主体对象变形程度、图像结构损坏程度,然后折中选择,确定各个操作算法的执行顺序和数量,保证图像的整体效果不失真变形。MULTIOP算法比单一算法具有更好的泛化效果,不足之处是该算法时间花费较长,而且大部分多操作算法的优化过程并没有找到最优的结果,只是得到相对较优的结果。因此,如何设计各种操作算法的顺序以及操作时间是相对较难解决的问题。表2 总结了三种典型的图像重定向技术SC[12]、缩放和拉伸(scaleand-stretch,SNS)[16]以及MULTIOP[42]的优缺点。

表2 三类典型图像重定向方法的比较Table 2 Comparison of three typical image retargeting methods
大多数基于内容的重定向方法在获取重要度图时,都使用加权结合的特征信息,例如梯度表示的边缘信息,颜色代表的颜色对比度信息,显著性定义的每个像素的重要性,但是在高层语义信息的表示,以及融合高层语义信息和低层细节信息方面还存在局限性。随着深度学习的出现,研究者尝试将深度神经网络应用在图像重定向领域。深度神经网络可以提取丰富的语义信息,并且能够更好地表示图像语义结构,这让深度学习在图像重定向领域中逐渐占有主导地位,因此近年来有大量相关研究成果涌现[18-26,51-52]。
2 基于深度神经网络的图像重定向方法
基于手工特征的图像重定向方法中重要度图是由低层信息获取,缺乏高层语义特征,通用性受到限制。因此,研究者利用深度神经网络的优势,通过网络获取图像语义信息,弥补这一局限。大量实验证明[18-26],基于深度学习的图像重定向方法无论是定性结果还是定量结果都超越了传统方法。当然,图像重定向深度学习方法也经历了一个从简单到复杂的发展过程。起初研究者关注于利用神经网络改善图像的重要度图,虽然深度学习的研究工作大多属于有监督的学习范畴,但是图像重定向研究者也在无监督或弱监督的方向上进行尝试。近年来,随着美学感知在计算机视觉领域中的应用发展,一些结合美学质量评估的图像重定向方法被提出,这类方法有的通过美学评价模型选出美学评分最高的区域进行图像裁剪[4,6-8],有的结合深度强化学习的思想[10-11],利用美学评价模型计算奖励分数,从而找到全局最优的重定向结果。
2.1 基于深度神经网络的图像重定向算法
基于深度神经网络的图像重定向方法按照实现过程可分为四种类型,分别为神经网络直接生成目标图像、生成对抗网络生成目标图像、神经网络提取重要度图进行图像重定向以及结合注视点Gaze进行图像重定向。表3对各类代表性算法进行总结。

表3 基于深度神经网络的图像重定向方法Table 3 Comparison of image retargeting methods based on deep neural network
(1)神经网络直接生成目标图像
Cho 等人首次将卷积神经网络应用于图像重定向领域,提出了一种弱监督和自监督的深度卷积神经网络(weakly and self-supervised deep convolutional neural network,WSSDCNN)[18],通过输入原图像和目标比例,让网络学习从原图像到目标网格的逐像素移位映射,从而输出目标图像,实现了一种端到端的内容感知图像重定向框架,其中还隐含地学习图像的注意力图引导移位图的生成。Arar 等人提出一种利用神经网络深层特征调整图像的方法DNR(deep network resizing)[20],该方法在图像特征空间中应用线裁剪对图像大小进行调整,利用已训练的VGG19 网络进行图像检测,再通过网格采样层优化图像,减少伪影产生。同样,为了在深度特征空间将原始图像重定向到目标长宽比,Lin 等人提出深度图像重定向方法(deep image retargeting,DeepIR)[23],设计一种利于保持语义结构的均匀重采样(uniform re-sampling,UrS)方法,通过逐步最近领域(nearest neighbor field,NNF)[53]融合方式,有效地将高层语义内容和低层细节信息结合,实现由粗到细的图像重构结果。UrS的设计保留了深度网络特征的重要语义信息,避免由于过度移除列/行像素而导致的内容丢失、结构混乱。由于大多数的深度学习需要带有标注的数据集进行训练,Tan等人提出了一种无监督双循环深度学习网络(deep cyclic image retargeting,CycleIR)[19],不需要任何注释信息,将图像进行两次重定向操作,生成与原图同样大小的图像,引入循环感知一致性损失训练网络。利用神经网络直接生成目标图像的流程图如图2所示。

图2 利用深度神经网络直接生成目标图像的流程图Fig.2 Process of using deep neural networks to directly generate target images
(2)生成对抗网络
生成对抗网络(generative adversarial network,GAN)[54]作为一种生成模型,也可应用在图像重定向领域。Shocher等人利用GAN学习图像内部分布,提出InGAN(internal GAN)模型[51],如图3,无需任何训练样本,在单个输入图像上进行训练,合成大量大小、形状和长宽比不同的新图像,所有图像都具有与输入图像相同的内部分布,实现图像的扩充和拉伸。与InGAN不同的是,Mastan 等人提出深度上下文内部学习的图像重定向方法(deep contextual internal learning,DCIL)[52],同样使用生成对抗网络,在损失计算上考虑到原图像与目标图像之间上下文特征的差异,使生成器输出的分布与自然图像的分布相似。但是,这类基于GAN 的重定向方法受限于每幅图像都要经过大量训练才能学到其内部的分布情况,并且适用于纹理结构连续的自然图像。
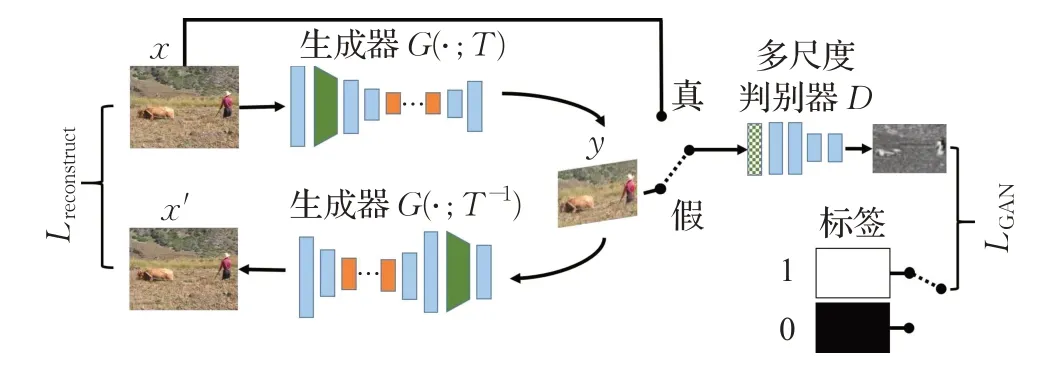
图3 InGAN网络结构Fig.3 Architecture of InGAN
(3)神经网络提取重要度图
如图4,一些研究者利用神经网络检测图像重要度图,再结合传统重定向方法,如线裁剪、线性缩放、多操作、网格变形、像素融合[55]等生成目标图像。例如Song等人[21]利用编码器解码器结构提取图像深度能量图,再结合线裁剪算法实现重定向;Wu 等人[22]提出结合深度神经网络的图像变形方法,通过融合预训练网络[56]生成的视觉重要度图和前景掩码图来引导图像变形。为保证重要度图与人类主观感知保持一致,一些研究方法还结合显著图、图像上下文和高级语义信息来检测图像中背景区域和前景区域。为保护始图像的语义成分,Liu 等人提出了语义保持的深度图像重定向框架(semantics preserving deep image retargeting,SP-DIR)[24]。该方法首先通过深度解析网络提取多个语义分量图,包括前景、上下文和背景,然后利用分类引导融合网络将各种语义分量图融合成具有像素级重要度的语义合成图,最后结合现有的重定向方法生成目标图像。设计的分类引导融合网络将图像分类为面向对象或面向场景两种类别,并为不同类别的图像学习不同的融合参数,保留了原始图像的语义信息。Yan等人[25]提出了一种基于语义分割和像素融合的图像重定向方法,采用预训练的RefineNet[57]生成高分辨的预测图像,然后结合显著图获取最终的重要度图,最后采用像素融合方式得到目标图像。Ahmadi等人[26]考虑到图像上下文对图像语义部分的重要作用,提出一种混合型显著性检测方法,最终的显著图由基于颜色、基于对比度和基于语义分割的显著图线性组合获得。其中语义分割网络使用预先训练的PSPNet[58]将整个网络分成编码器和解码器两部分,编码器提取的特征用于解码器生成分割图和上下文检测,考虑到不同的分割对象在不同的上下文语境中具有不同的重要性,因此根据检测的像素类别和所属的上下文语境给图像像素分配显著值,最终利用像素融合的方法进行图像重定向。

图4 深度神经网络提取重要度图引导图像重定向的流程图Fig.4 Process of using deep neural networks to obtain importance map to guide image retargeting
(4)注视点
生物学和心理学实验都表明,人类在观察一幅图像时,首先会聚焦在图像中最显著的区域,然后再将目光转移到第二个区域。为更加符合人类的视觉感知,考虑到人眼注意力分配情况,Zhou等人[1]提出了一种新的重定向框架,利用人眼的注视行为快速缩小照片,网络模型如图5。该模型首先利用几何保持图排序算法(geometry-preserved graph ranking)有效地选择多个显著目标块来模拟人眼注视移动路径(gaze shifting path,GSP);然后利用聚合的CNN网络分层学习每个GSP的深度表示;在此基础上,构建出用于学习高质量美学照片先验知识的概率模型[59]。同样,Wang等人[27]提出一种感知引导的多通道视觉特征融合方法,利用简单线性迭代聚类(simple linear iterative clustering,SLIC)[60]将图像分割成超像素,用于构造小图,随后通过所设计的稀疏约束算法选出最显著的小图并将它们连接起来,形成GSP。GSP 的提出弥补了现有方法不能有效编码人类视觉机制的缺点,它可以很好地反映人眼的注意力分配和选择。

图5 结合Gaze的图像重定向算法Fig.5 Gaze-based image retargeting method
2.2 基于深度强化学习的多操作算法
一般情况下,由于图像中不同区域具有不同的特征,多操作图像重定向比单操作算法具有更好的泛化效果。早期的MULTIOP[42]会有陷入局部最优的可能性,并且时间复杂度按指数增长,效率低下。近年来,研究者提出了基于深度强化学习的多操作算法,这类方法既具有深度学习的感知能力,又具有强化学习的决策能力,可以直接获取操作符的序列,而不用遍历每一个操作符后再进行选择,大大减少了计算时间。下面将介绍两种应用深度强化学习的多操作算法。
Zhou等人首次应用深度强化学习实现多操作的图像重定向,提出了一种基于语义和美学感知的弱监督多操作图像重定向框架(aesthetics aware multi-operator image retargeting,SAMIR)[61]。与之前使用相似度测量的多操作算法不同,该模型利用语义和美学感知度量作为奖励函数,保证图像内容不丢失以及重定向后的图像具有高质量的视觉效果。具体网络模型如图6所示,智能体根据全局特征和局部特征从动作空间中选择适合当前的操作符,得到这一步的重定向图像,再根据语义和美学度量计算当前的奖励,用来更新智能体,重复这个过程,直到达到目标大小。其中语义感知度量采用PatchMatch[62-63]计算,美学度量用视图查找网络(view finding network,VFN)[4]计算美学得分。
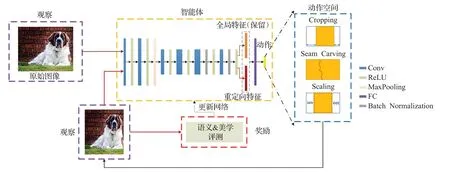
图6 SAMIR网络结构Fig.6 Architecture of SAMIR
在MULTIOP[42]中,定义了一种新的图像双向相似度测量指标(bi-directional warping,BDW),但是基于深度强化学习的方法中不能直接采用BDW分数作为奖励计算,因为每幅图像的BDW 评分差异很大。为解决这个问题,Kajiura 等人[64]提出了一种自我博弈的奖励机制,通过让智能体与它的副网络进行较量,即BDW分数的比较,并根据胜利或失败计算奖励,这样可以处理BDW 分数差异大的问题。另外,该方法提出了一个动态改变选择每个动作权重的方法,根据选择动作的频率改变损失的权重,让相对强和相对弱的动作的选择概率相等,避免网络一直选择较强的动作。在该方法中其他评估功能(如美学评估[65])也可以用作奖励。
2.3 基于美学感知的图像裁剪算法
图像裁剪常用于图像编辑,其目的是通过去除图像的外部区域改善图像,试图找到比输入图像更好的构图。一般来说,专业摄影师会用到一些构图技巧获得高质量的照片,如黄金比例、三分法、视觉平衡和简洁。然而建立计算机模型模拟这些技术产生高质量的照片是一个具有挑战性的任务。
早期研究者利用这些专业技巧改善图像构图[66-70],但是从这些文献中可以看出,传统方法非常依赖研究者对摄影领域知识的理解,这将限制他们的工作进展。由于深度学习的快速发展和新提出的大规模数据集,利用卷积神经网络完成图像裁剪的研究不断涌现,这些方法可分为基于注意力的裁剪方法和基于美学感知的裁剪方法。基于注意力的裁剪方法[5,71-72]是在原始图像中找到视觉上最显著的区域,然后对候选框进行排序,这样可以保证最终的裁剪图像中保留原有的主体内容。然而这些方法只是单一地考虑注意力,未考虑图像构成,可能无法产生视觉上高质量的裁剪图像,因此研究者加入美学感知的思想,试图从输入图像中找到视觉上令人愉悦的裁剪窗口,利用提取的图像特征评估图像美学分数。本节将介绍几种代表性的基于美学感知的图像裁剪方法,表4对这些方法进行总结。

表4 基于美学感知的图像裁剪算法总结Table 4 Summary of aesthetic-aware image cropping algorithms
(1)滑动窗口策略
基于滑动窗口策略的图像裁剪方法一般分为两阶段,如图7,第一阶段通过滑动窗口策略提取多个裁剪候选框,第二阶段对每个裁剪候选框图像进行美学评估,选出美学得分最高的候选框图像作为最终裁剪图像。Chen等人考虑到专业摄影师拍出的照片一般具备较好的构图,而如果从专业图像中随机裁剪一块,就会影响原来图像的构图,因此原图在构图方面的分数应该高于随机裁剪的图像。基于这样的假设,他们提出视图查找网络VFN[4],如图8,利用Hinge 损失实现网络训练,如式(3):

图7 采取滑动窗口策略的图像裁剪流程图Fig.7 Flow chart of image cropping with sliding window
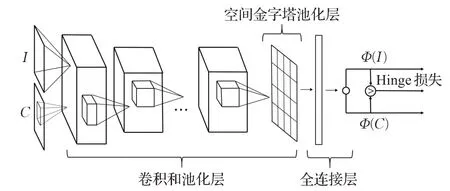
图8 VFN网络结构Fig.8 Architecture of VFN

其中,Ij、表示原始图像及其对应的裁剪图像,Φ(Ij)、Φ()表示原始图像及其对应裁剪图像的美学分数,g为间隙参数,表示Φ(Ij)、Φ(之间的最小距离。该模型只能知道图像构图的好坏,无法自动从原图中裁剪出构图好的裁剪图,因此在裁剪方面,采用的是滑动窗口策略,根据网络输出的分数决定最终美学分数高的裁剪框。
(2)注意力感知策略
基于滑动窗口的图像裁剪方法通过反复计算所有滑动窗口的美学得分才能确定最优的裁剪窗口,这样的方式耗时严重,效率低下。Wang 等人设计了一种基于深度学习的注意力矩形框预测和美学质量分类的级联模型(attention box prediction and aesthetics assessment,ABP-AA)[6]。该方法不需要通过滑动窗口搜索图像域内所有可能的位置,而是通过注意力预测网络初步确定一个包含重要内容的区域,缩小裁剪候选框的搜索范围,时间效率有所提高。这种基于注意力感知的图像裁剪方法(如图9)采取由“确定”到“调整”的方式进行裁剪,通过ABP网络生成注意力矩形框作为初始矩形框,然后在其周围生成一组裁剪候选框,再由AA网络评判出美学质量最高的候选框作为最终的裁剪区域。

图9 采取注意力感知的图像裁剪流程图Fig.9 Flow chart of image cropping with attention-aware
(3)回归网络策略
无论是基于滑动窗口的裁剪方法还是基于注意力感知的裁剪方法,它们在多个候选框提取和美学评估的问题上效率低下。为学习和分析视觉显著性区域与图像美学区域之间的关系,Lu等人[7]设计了一个用于图像裁剪的回归神经网络,如图10。该方法首先检测图像中的显著区域,利用文献[5]提出的方法寻找图像中包含感兴趣对象的最优初始裁剪框,然后将具有视觉显著性的初始裁剪图像输入到基于VGG16[74]的回归网络中,预测出坐标偏移因子,得到最终的裁剪区域。与其他提取多个候选框的方法不同的是,该方法只产生一个包含感兴趣对象的裁剪框,并直接从回归网络中获取美学质量高的裁剪框,大大提高了时间效率。

图10 采取回归网络策略的图像裁剪流程图Fig.10 Flow chart of image cropping with regression network
同样,Lu等人[8]提出的基于深度学习的端到端图像自动裁剪框架也是利用深度神经网络提取图像的显著特征图,确定图像中包含感兴趣对象的候选裁剪区域,然后利用回归网络得到最终的裁剪矩形框。值得注意的是,文章汲取传统数字图像处理方法的优点,在生成的显著特征图后加入软二值化层(soft binarization layer),通过这一层,可以增强显著性的效果。
(4)弱监督学习策略
Lu等人提出一种基于图像分布的弱监督图像裁剪框架[73],该框架利用高质量美学图像与裁剪图像的似然分布差异来指导裁剪框坐标的预测训练,无需裁剪框的标注信息。另外,该框架还加入显著性损失,确保网络更多地关注图像中视觉显著的区域。Li 等人将图像裁剪过程设计为序列决策的过程,提出了一个弱监督的美学感知深度强化学习框架(aesthetics aware reinforcement learning,A2-RL)[10],并通过美学评估模型计算奖励分数,网络模型如图11 所示。该模型是第一个基于深度强化学习的图像自动裁剪方法,根据决策子网络输出的概率分布从动作空间中选择对应的操作算子,利用新得到的裁剪框的美学分数和上一步得到的裁剪框的美学分数之间的差值计算该操作获得的奖励,从而让奖励函数引导智能体在每一次迭代中找到令人满意的裁剪框。因此,它不需要依赖滑动窗口策略,可以在数步或十几步内完成裁剪过程,大大减少运行时间,并且可以获得任意尺寸位置的裁剪窗口。

图11 A2-RL网络结构Fig.11 Architecture of A2-RL
Li等人在A2-RL模型上进行改进,提出了一个快速美学感知的对抗强化学习框架(fast aesthetics-aware adversarial reinforcement learning,Fast A3RL)[11]。与之前不同的是,Fast A3RL模型是对提取的特征图执行动作空间中的裁剪操作,并且加入对抗学习的思想,即同时训练裁剪网络和美学评估网络,让美学评估网络对裁剪后的图像输出较低的美学分数,让裁剪网络尝试输出得分较高的裁剪图像,形成对抗学习。
3 实验评价方法
图像重定向技术的目标是使调整后的图像达到与原始图像相同的人类视觉美学要求,虽然图像质量评价方法已经相对成熟,但是图像重定向质量评价仍处于起步阶段[75]。一般地,图像重定向质量评价方法可分为两类:主观评价方法和客观评价方法。
3.1 主观评价方法
主观评价方法依靠人的主观感觉评判图像的质量,不同的人对图像质量的感知也不同[76]。为定性地评价重定向图像的质量,研究者除了视觉比较同一幅图像的不同重定向目标图像外,还采取用户调查的方式进行定性评价。用户调查一般会将不同的重定向方法进行两两比较,具体方法是每幅图像根据不同的重定向方法生成对应的目标图像,并且在同一时间给志愿者展示同一幅图像的两种重定向结果图,让志愿者在一定的时间内从中选出质量高的一幅,根据最后的比较结果看哪种方法更符合人类的视觉观感。还有的研究者要求志愿者在观察评价时,从五个质量等级中选择一个等级来评价重定向图像,这五个评价等级包括坏、差、合格、好、优秀。
3.2 客观评价方法
3.2.1 基于重定向图像的评价指标
(1)FRR(feature remain ratio)[23]:该指标测量的是重定向图像在深度特征中的保留比例,计算如式(4),其中FO、FR分别代表原始图像和重定向图像,FRR 值越大,表示图像质量越好。
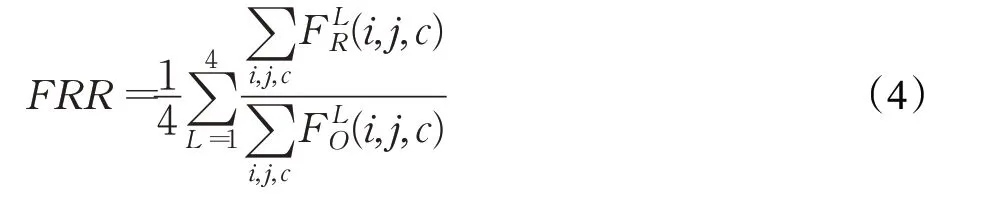
(2)FD(feature dissimilarity)[23]:该指标计算的是在特征空间中原始图像和重定向图像之间的平方差,如式(5)。FD值越小,表示图像质量越好。
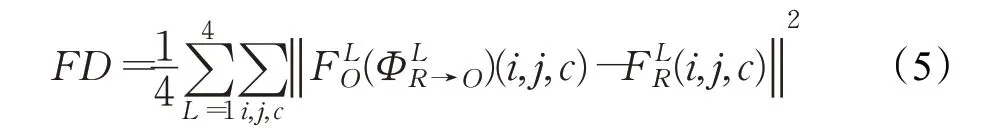
(3)结构相似性SSIM(structural similarity)[77]:该指标用来衡量两幅图像的相似程度,它分别从亮度、对比度、结构三方面对图像进行相似度评估,如式(6),其中α、β、γ均大于0。在实际应用中,SSIM 简化表达式如式(7),其中x、y分别表示参考图像和测试图像,μ、σ分别表示图像的均值和标准差,σxy表示参考图像和测试图像的协方差,C1、C2表示常数。SSIM分值越大,说明两幅图像的相似度越高。在文献[27]中,研究者提出了一种改进的SSIM 指标计算方式,如式(8),与之前方式不同的是,该公式加入深度特征比较,图像深度特征计算如式(9)。

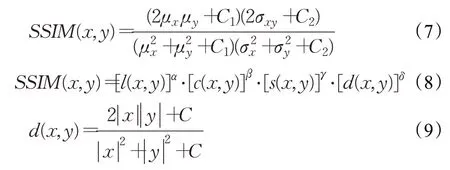
(4)IoU(intersection over union):该指标常用来评估算法的裁剪精度,计算如式(10),其中C表示真实裁剪区域,C′表示预测的裁剪区域。IoU的值越大说明裁剪的窗口与真实裁剪窗口越接近,即裁剪效果越好。

(5)BDE(boundary displacement error):该指标用来评估裁剪窗口与真实裁剪窗口四条边之间的距离,如式(11),其中Bi与分别表示真实裁剪窗口和预测裁剪窗口的边界坐标。BDE 值越小说明预测的裁剪窗口与真实窗口越接近,即裁剪效果越好。

(6)排序比较:为验证重定向方法的有效性,研究者提出了一种排序比较的方法,根据重定向图像的客观评价指标分数对重定向方法进行降序排序。对于一幅图像,指标分数最好的重定向方法排名第一,以此类推,根据排名给每一种方法进行打分(1 为最好,往后越来越差),然后将采取同一种方法的所有图像的分数相加,进行比较,数字越小说明排名越高,即重定向效果越好。有的研究者会计算各排序得分的均值和标准差,然后比较不同方法排序顺序的平均值和标准差,均值最小和标准差最小的重定向方法越优秀和稳定。
重定向技术的发展离不开重定向客观评价方法的发展,为衡量不同重定向方法的重定向效果,研究者提出了一些重定向质量评价算法。例如MULTIOP[42]中提出采用双向相似度BDW 来度量图像间的相似性,计算如式(12),式中S和T分别表示原始图像和目标图像,Si和Ti分别表示原始图像和目标图像的第i行,h表示图像的高度,A-DTW 是一种非对称动态时间变形算法(一种度量两个1D 信号或时间序列之间相似性的算法)。BDW 分数反映的是原始图像与目标图像之间的差值,即目标图像中有多少不属于原始图像的内容信息以及目标图像对原始图像内容信息保留的完整程度,该方法测量每一行/列之间的相似性,然后将最大对齐误差作为度量距离。其他方法,如SIFT-flow[78]、ARS(aspect ratio similarity)[79]、MLF(multiple-level feature)[80]、BDS(bidirectional similarity)[81]、EH(edge histogram)[82]、CL(color layout)[83]常作为客观评价指标来评估不同的重定向方法。具体的,SIFT-flow 在两幅图像之间匹配密集采样的像素级SIFT 特征;ARS 可以观察出图像在重定向过程中的几何变化;MLF利用纵宽比相似度、边缘组相似度等多级特征衡量图像质量的退化;BDS为双向相似度,通过设计的优化函数来满足不同大小图像的双向相似性度量,当BDS 值较大时表明目标图像中包含尽可能多的原始图像信息,尽可能少地引入新的伪影;EH 是一种用来捕获图像边缘特征的方法,先将图像划分为小图并计算小图的边缘直方图,再进行归一化,最后计算图像的直方图;CL 则是一种提取图像局部颜色特征的方法,能够反映图像颜色的空间分布,具有计算成本低,匹配计算速度快,识别准确率高等优点。

3.2.2 基于语义分类的评价指标
在图像重定向任务中,为定量确认重定向后的图像中主体内容是否保存完好,采用语义分类相关的评价指标来评估重定向图像的质量。例如平均精度均值(mean average precision,mAP)是多标签图像分类任务中常用的评测指标,用于评估重定向前后图像的分类精度,利用所有类别的平均精度值求和后再除以所有类别的数目来计算,如式(13)~(15)。

此外,在DNR模型中,为了评估重定向操作对语义细节的保留情况,Arar 等人[20]计算语义分数(semantic score,SS),即比较重定向前后图像经过VGG19 网络层的激活程度,如式(16),其中Fi(I)、Fi(O)分别表示原始图像和重定向图像。如果重定向操作破坏了语义区域,原始图像的激活值会增加,那么这个分值会低,反之,这个分值会增大。

3.2.3 基于显著性的评价指标
通常显著性检测相关的评价指标也被用来评估网络预测的重要度图。例如:EMD 距离(earth mover’s distance),是一种度量距离的指标,用于测量两个分布之间的距离;皮尔逊相关系数(pearsons linear correlation coefficient,CC),用于评估预测图与真实图之间的线性关系,CC指标越大说明该模型性能越好;KL散度(Kullback-Leibler divergence),用于衡量预测图和真实图间概率分布的差异,当两个分布相同时,该指标为0,反之,该指标会增大;直方图交叉核(histogram intersection),常用于评估两个离散概率分布(直方图)的相似度;平均绝对误差(mean absolute error,MAE),用于计算预测图和真实图对应位置的差值,是最常用的评估指标,MAE分值越小说明该算法的性能越好。
3.2.4 GSP评估
在基于人眼注视点的重定向方法中[1,27],为评估预测的人眼转移路径与真实的人眼转移路径是否一致,研究者设计一种评价方法度量人眼转移路径与预测的人眼转移路径的重叠率。一般使用眼动仪EyeLink II2记录观察者的注视路径,然后沿着这条注视路径将所有的分割区域连接起来,得到真实的人眼转移路径。重叠率计算如式(17)。

4 相关数据集介绍
因为深度神经网络的训练依赖大量训练数据,所以图像重定向研究从基于手工特征的传统方法发展到基于深度学习的方法离不开重定向数据集的发展。下面将介绍目前常用于深度学习方法的数据集。
4.1 图像重定向数据集
(1)RetargetMe[84]:该数据集是图像重定向质量评估(image retargeting quality assessment,IRQA)第一个发布的基准数据集,共包含80幅图像,其中37幅图像用于用户研究,属性包含线条/边、人/脸、纹理、前景目标、几何结构以及对称性,并且这37幅图像使用8种不同的重定向方法,生成对应的8 种重定向结果,重定向方法包括CR(cropping)、SCL(scaling)、SC、MULTIOP、SM[32]、SNS[16]、SV[85]、和WARP[86],选择的重定向比例为原图像高度或宽度的50%或75%。该数据集的图像主观评价方案是以配对比较的方式[87]进行,每次展示同一幅图像的两种不同重定向方法的结果图像,由测评者投票选出质量更好的图像,每种重定向结果的主观评分由受欢迎程度即测评者投票记录确定,选择的客观评价指标为BDS、BDW、EH、CL。
(2)CUHK[88]:该数据集共收录57 幅原图像以及对应的171 幅重定向图像,包含的图像属性有人/脸、清晰的前景目标、自然场景(包括平滑或纹理)、几何结构,数据集中每幅原图像采用3 种不同的重定向方法,生成3种重定向结果。这3 种重定向方法从10 种具有代表性的方法中随机选择,包括RetargetMe数据集中使用的8种方法以及SCSC(optimized seam carving and scale)[43]和ENER(energy-based deformation)[14],重定向比例为原图像高度或宽度的50%或75%。该数据集选择的主观评价方案与RetargetMe 数据集使用的配对比较方案不同,该数据集采用5 种离散质量评测表(例如坏、差、合格、好、优秀)为每幅图像进行主观评分,得到每幅图像的平均主观分数(mean opinion score,MOS),选择的客观评价指标为EMD、BDS、EH、SIFT-flow。
(3)NRID[89]:该数据集包含35 幅原图像,并且每幅图像采用5种重定向方法,包括MULTIOP、SCL、SC、SM和WARP,重定向比例为原图像高度或宽度的75%。该数据集的主观评价方案与RetargetMe 数据集中的评价方案一样。此外提出了一种有效的客观度量方法来评估重定向图像的视觉质量,该度量是基于图像的SIFTflow[78]向量场的局部方差来测量图像前后的几何失真,还结合了基于显著图评估的信息损失。实验结果表明,所提出的客观度量方法与主观排名高度一致。
上述图像数据集的总结如表5,包括数据集中原图像的数量、重定向比例、重定向图像数量、重定向算法、主观评价方法。还有一些数据集,如显著性检测的数据集HKU-IS[90]、语义分割的数据集Pascal VOC 2007[91]、美学评估的数据集AVA[92],也常用于训练网络。

表5 常见图像重定向数据集Table 5 Summary of common image retargeting datasets
4.2 图像裁剪数据集
(1)CUHK-ICD(CUHK image cropping dataset)[70]:该数据集是由香港中文大学发布的专门用于图像裁剪的数据集,共包含950幅图像,涵盖各种图像类别,包括动物、建筑、人类、风景、夜景、植物和静物,每幅图像都由3位专业摄影师手动裁剪,因此形成3个标注数据集。
(2)FCD(Flickr cropping dataset)[93]:该数据集中的每幅图像都是从Flickr上下载后经过人工筛选得到的,共包含1 743 幅经过人工标记裁剪窗口的图像以及31 430 对与原始图像相匹配的裁剪图像对。在FCD 数据集中,有两种类型的注释:裁剪窗口以及排序,以大约4∶1的比例将1 743幅图像分为训练集和测试集,因此有348幅测试图像用来评估图像裁剪的性能。
(3)HCD(human crop dataset)[94]:该数据集共包含500幅测试图像,每幅图像由10位专业人士进行裁剪标注。HCD 中对每幅图像的注释比前两个数据集多,因此评价指标有些不同,一般将预测的裁剪窗口与10 个GroundTruth窗口进行指标计算,选择最大的作为结果。
5 代表性算法总结
本章将对上述提到的基于深度学习重定向方法进行总结,包括文献的发布时间、使用的测试数据集、采用的评价方法、模型的优缺点。
基于深度神经网络的图像重定向算法总结如表6。采用深度神经网络提取深度特征直接引导图像重定向的算法有WSSDCNN[18]、DNR[20]、DeepIR[23]、CycleIR[19]。其中WSSDCNN 是第一个采用深度网络解决内容感知图像重定向的方法,由于人为设置卷积核的大小,不能输入任意大小的图像。DNR利用已训练的VGG19网络进行图像检测,获取图像重要区域,在图像特征空间中应用线裁剪对图像大小进行调整,当VGG19 网络不能提供准确的重要区域时,重要目标的不同区域仍然具有较低的像素值,可能导致最终的结果目标失真。另外与其他深度学习方法相比,该方法借鉴线裁剪的方法,重定向同一幅图像的处理时间花费也很大。DeepIR中设计的UrS 方法避免了由于过度移除列/行像素导致的内容丢失,结构混乱,但是图像重建过程中耗费时间长。CycleIR 不需要任何注释信息,将图像进行两次重定向操作,生成与原图同样大小的图像,但是当背景与主体对比度较低时,获取的重要度图不准确而导致重定向结果不佳。随着GAN 生成效果的提升,研究者将图像重定向问题转化成分布匹配问题,利用GAN 学习图像内部的分布情况,实现图像的扩充和拉伸,例如InGAN[51]、DCIL[52],但该类方法适用于纹理结构连续的自然图像,并且受限于每幅图像都要经过大量训练,网络才能学到其内部的分布情况。
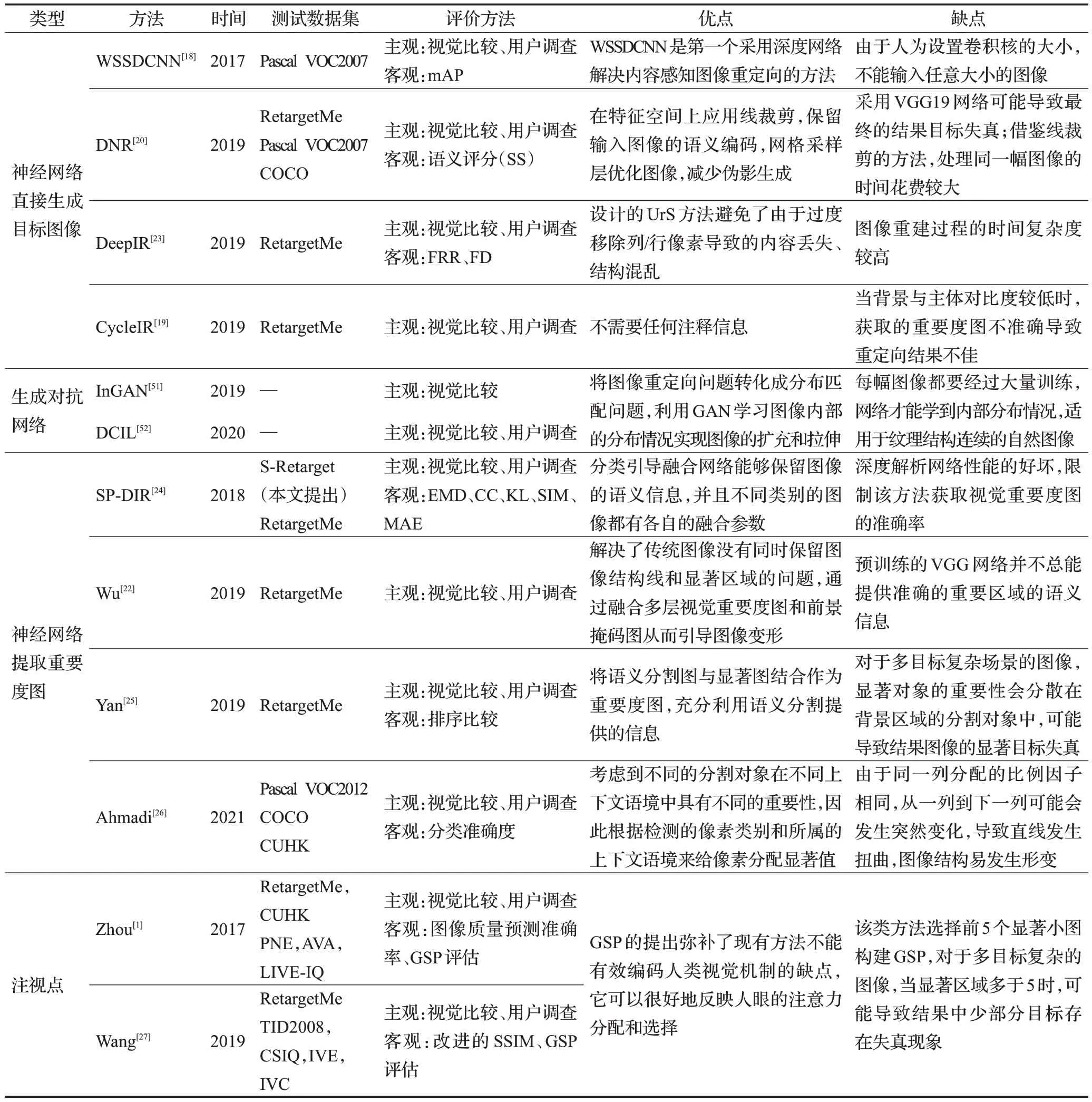
表6 基于深度神经网络的图像重定向算法总结Table 6 Summary of image retargeting algorithms based on deep neural network
另外,利用深度神经网络提取重要度图再进行图像重定向操作的算法还有很多,如Song等人[21]、Wu等人[22]利用深度网络获取视觉重要图从而引导图像重定向,但预训练的VGG网络性能的好坏限制该类方法获取视觉重要度图的准确度,当重要区域太大或者过于分散时,提取的重要度图不能完全将重要目标分割出来,因此会产生不准确的重要区域语义信息。还有一些方法,如SP-DIR[24]、Yan 等人[25]、Ahmadi 等人[26]的模型不仅仅考虑低级特征,还结合语义、上下文等信息构造重要度图。其中,Yan 等人的方法将显著图与语义分割图进行融合,但对于多目标复杂场景的图像,显著对象的重要性会分散在背景区域的分割对象中,可能导致结果图像的显著目标失真。Ahmadi等人的方法考虑到不同的分割对象在不同的上下文语境中具有不同的重要性,因此根据检测的像素类别和所属的上下文语境给图像像素分配显著值,然而由于同一列分配的比例因子相同,从上一列到下一列可能会发生突然变化,导致直线发生扭曲,图像结构易发生形变。为更加符合人类的视觉机制,Zhou 等人[1]、Wang 等人[27]结合GSP 构建显著区域,GSP 的提出弥补了现有方法不能有效编码人类视觉机制的缺点,它可以很好地反映人眼的注意力分配和选择。此类方法利用CNN 体系结构来深度表示GSP,最后通过建立概率模型学习专业图像的先验知识,然而该类方法选择前5个显著小图构建GSP,对于多目标复杂的图像,当显著区域多于5 时,可能导致结果中少部分目标存在失真现象。
基于深度强化学习的多操作算法总结如表7。虽然早期的MULTIOP算法仍然可以与现在最先进的方法相媲美,但MULTIOP 算法需要大量的时间生成多个操作算子的结果才能找到操作算子的最佳组合,而基于深度强化学习的多操作算法大大减少了MULTIOP算法的时间花费。SAMIR[61]是第一个应用深度强化学习实现多操作的算法。Kajiura等人[64]不仅采用深度强化学习,还加入自我博弈机制以及动态改变动作选择权重的方法,根据胜败计算奖励实现快速有效的多操作方法。同时以上两种方法都可以将美学感知评估用作奖励来指导智能体的优化以及动作因子的选择,以获得高质量的重定向结果。但是多操作中的裁剪方法会导致图像内容显示不完整,获取的结果少部分会出现周围目标内容丢失的情况,并且每次同一幅图像测试时选择的动作序列不相同,因此也无法保证每次选择的操作因子序列是全局最优的。

表7 基于深度强化学习的多操作重定向算法总结Table 7 Summary of multi-operation retargeting algorithms based on deep reinforcement learning
基于美学感知的图像裁剪算法总结如表8。采用滑动窗口策略的算法耗时太长,效率低下,如VFN[4]通常预设置大小和比例对整个图像进行扫描,提取丰富的候选框,然后再对每个候选框进行美学评估,选择得分高的作为最优的裁剪结果。后来研究者采用“确定-调整”的方式缩小提取候选框的空间,提出基于注意力感知的图像裁剪模型,如ABP-AA[6],通常先经过视觉显著性检测确定初始裁剪框,再对周围区域进行扫描和美学评估,大大缩小了候选框的搜索范围。也有一些如Lu 等人的方法[7-8],利用回归网络直接输出预测的坐标因子,这些方法远远小于传统裁剪方法所需的候选框的数量。也有一些研究者提出弱监督的裁剪框架,无需边界框去监督,如Lu等人[73]、Fast A3RL[11]、A2-RL[10],其中后两个模型加入深度强化学习的思想,根据决策子网络输出的概率分布从动作空间中选择对应的操作算子,采用美学分数计算操作获得的奖励,从而让奖励函数引导智能体在每一次迭代中找到令人满意的裁剪框。另外,本文也总结了这9 种算法在CUHK-ICD、FCD、HCD 数据集上的裁剪性能,如表9 所示,使用两个有代表性的质量评价指标,即IoU、BDE来定量比较不同的裁剪方法。

表8 基于美学感知的图像裁剪算法总结Table 8 Summary of image cropping algorithms based on aesthetic-aware

表9 基于美学感知的图像裁剪算法在CUHK-ICD、FCD、HCD数据集上的比较Table 9 Comparison of aesthetic-aware image cropping algorithms on CUHK-ICD,FCD and HCD datasets
6 总结与展望
深度学习的迅速发展,有力地推动了图像重定向技术的研究。本文详细介绍了近5 年几种典型的基于深度学习的图像重定向方法,这些方法有的结合传统的重定向技术,有的利用深度神经网络直接生成重定向结果。它们通过改进重要度图对图像进行调整,在现有图像低层信息的基础上,不仅结合高级语义信息和上下文信息获取视觉显著区域,还考虑到结合人眼转移路径、美学评价来鉴别图像重要区域,获取符合人类视觉感知的高质量图像。
但任何的方法都有优缺点,例如在CycleIR 模型[19]中,当生成的图像效果不好时,产生失败的原因有两点:背景与主体的对比度较低,模型将背景区域划分为视觉重要区域;视觉重要区域缺乏关注,只检测出部分视觉重要内容,因此该类方法适合背景与主体对比度大、主体明显的图像。在根据重要度图分配缩放因子的方法[26]中,通常为同一列的像素分配相同的缩放因子,容易导致某一列到下一列的缩放因子发生突变,线性区域扭曲偏移,因此该类重定向方法不适合包含大量线性结构的图像。
从上述文献中来看,目前还没有一种通用性强的图像重定向方法,要想让图像重定向技术走向成熟,依然还有一些需要解决的问题。关于未来的研究方向,可以从以下几方面进行考虑:
(1)采用其他学习方法。大多数基于深度学习的重定向方法都是采用弱监督或自监督的方式训练网络,例如WSSDCNN 是第一个采用深度网络解决内容感知图像重定向的方法,使用图像及其像素级注释计算内容损失和结构损失达到训练网络的目的。有的方法采用无监督的方式,如CycleIR将图像进行两次重定向操作,通过引入循环感知一致性损失训练网络,无需任何图像注释信息。深度学习初期由于缺乏用于训练深度模型的图像重定向数据集,还没有将监督方式应用在重定向领域。因为构造带有注释的重定向图像,需要采集大量图像,标注数据集的代价也很高,而最近文献[95]提出了一种解决方案,在多种重定向方法的结果基础上,使用IRQA算法,创建了一个新的用于重定向任务的数据集,该方法的提出让监督方式应用在重定向领域成为了可能,实现了图像在特征空间中得到精准训练。另外,结合强化学习也是一种新的尝试领域。强化学习任务可表述为马尔科夫决策过程,通过不断“试错”进行探索式学习,具有很强的决策能力,不需要特定的数据,只需要根据奖励或惩罚来学习新的知识,更加适应环境。而深度网络在图像处理领域取得了一定的成功,但其缺乏一定的决策能力,将其感知能力和强化学习的决策能力相结合来处理图像数据的感知决策成为很多研究者的研究方向。基于深度强化学习的重定向技术已经有了一些研究工作,例如文献[10,11,61,64]等,这类方法无论是多操作算法还是裁剪算法,都是根据决策网络输出的概率分布从动作空间中选择对应的操作算子,利用新得到的图像计算奖励因子,从而引导智能体在每一次迭代中得到满意的结果,最终的效果很大程度上取决于动作空间的操作算子,操作算子性能越好,最终效果也会越好。不过强化学习通常需要计算奖励来引导智能体向“正确”的方向发展,在上述文献中,有的采用语义感知计算奖励函数,有的采用美学感知计算奖励,有的借助BDW分数差异计算奖励,但是通过实验测试可以发现,输入同一幅图像得到的操作序列是不同的,无法保证每次选择的操作因子序列是全局最优的。因此,设计一个奖励函数来引导未来行动,同时还要保证智能体可以不断地优化学习避免陷入局部最优是一件具有挑战的事情。
(2)对重要度图的改进。现有的图像重定向方法在处理简单场景或单一目标的图像上效果不错,但是在处理具有多个目标的复杂图像时,大多数检测方法平等地给予不同显著目标相等的显著值,无法区分不同目标的重要程度,出现重要区域不是丢失就是把背景区域划分为重要区域的情况,导致重定向结果中次显著目标或面积小的显著目标保护不周、结构变形的情况。但事实上,人类在观看复杂场景的图像时,注意力会优先聚焦于最显著的目标,其次关注到第二显著目标,以此类推。针对多目标图像,文献[96]通过设计的实例级相对显著性排序模型来获取图像的重要区域,再利用线裁剪算法进行图像重定向。其中实例级相对显著性排序模型先通过改进实例分割网络获取目标,然后增加图卷积的网络用于预测目标显著性排名,得到的显著性排名图能够很好地反映不同显著目标的重要性。实验结果表明,这种方式获取的重定向结果中最显著的目标保存较好,变形较少,而较不显著的目标先发生变形或者在目标比例较大的情况下被删除。另外,可以采用人眼注意图,同样考虑到人类视觉注意力的优先级分配问题,可以在原有视觉重要度图的基础上结合人眼注意图,利用两者的互补性提升重要度图的检测质量。但是如何建模人眼注意图符合真实人眼注意路径以及如何将两者有效结合起来,也是值得探究的问题。
(3)图像重定向与美学评价相结合。目前大多数的图像重定向方法重点关注图像内容的保护,忽略了图像美学对于重定向结果的影响。一方面现有的基于美学感知的图像重定向技术大多只应用在图像裁剪上,而裁剪会导致图像语义内容不完整,另一方面美学评价是一种人类主观感知而不是客观评价,由计算机建模人类的美学感知也是一大难题。文献[97]提出一种结合美学的图像重定向方法,通过主干网络获取多层级的图像美学特征,再由注意力机制自适应地融合得到图像的美学信息,在此基础上与图像显著图、直线检测图、梯度图进行融合生成重要度图来指导图像多操作算法。实验结果表明,结合美学信息能很好地保护图像的整体美学结构,生成的重定向图像既保留了原始图像的语义内容,又保证较高的视觉质量。不过,美学特征难以适应不同类别的图像,因此建立一个适用于不同图像类别,并且兼顾图像语义和美学感知的重定向方法也是一大挑战。
(4)采用轻量级网络模型。深度学习方法采用神经网络作为基础网络,并且需要大量数据进行网络训练,时间复杂度高。考虑到重定向移动端的需求,如何设计一种轻量级的网络模型,使得图像重定向方法更加简便快捷,也是研究人员未来的研究方向。近年来一些轻量级网络如MobileNet、ShuffleNet 和Xception 等的出现,为轻量级网络的图像重定向提供了实现的可行性,相比于传统的深度模型,在保证准确率的前提下,通过不同于传统的卷积方式来减少网络的参数,满足实时性的需求。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
快乐学习报·教育周刊(2022年16期)2022-05-01
美食(2022年2期)2022-04-19
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
开放教育研究(2020年2期)2020-03-31
文苑(2019年22期)2019-12-07
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
Coco薇(2017年8期)2017-08-03
中国修辞(2017年0期)2017-01-31
