
深度学习在场景文字识别技术中的应用综述
2022-03-02 08:31刘艳菊伊鑫海李炎阁张惠玉刘彦忠
计算机工程与应用 2022年4期
刘艳菊,伊鑫海,李炎阁,张惠玉,刘彦忠
1.南京特殊教育师范学院 数学与信息科学学院,南京210038
2.齐齐哈尔大学 计算机与控制工程学院,黑龙江 齐齐哈尔161000
文字是人类记录信息并将信息文明久远传递的方式和工具[1]。随着时间的推移,大量的文字需要被转换为数字形式存储,于是文字识别技术开始被提出并发展。文字识别技术就是计算机利用不同算法识别出文字内容的技术。常见的如光学字符识别(optical character recognition,OCR)[2]。早期的OCR技术就是将含有光学字符的图片或文档中的字符转换为字符格式。随着对文字识别的需求日益复杂,对自然场景下的文字识别的需求也愈发强烈。场景文字识别(scene text recognition,STR)成为研究热点。它是OCR 的一个子问题,主要任务是将自然场景中的文字提取出来并转化成字符形式[3]。相较于传统OCR 技术,STR 具有更多的挑战,例如字体多样性、多尺度、任意形状、光照、背景、模糊等[4]。深度学习在STR中的应用有效解决了上述问题。
1 基于深度学习的自然场景文本检测方法
传统的文本检测方法多利用手动设计的特征捕捉场景文本的属性,通常无法解决复杂背景、光照、遮挡、曲线文字、旋转文字等对检测结果的影响[5],而在基于深度学习的方法中,有效的特征是直接从训练数据中学习的,该方法的出现突破了上述瓶颈,使得检测方法更加灵活。目前的场景文本检测方法大致可分为基于回归的检测方法和基于分割的方法,以及将两者有效结合的方法。
1.1 基于回归的检测方法
该类方法通常先初始化默认检测边框参数,通过回归的方法不断学习参数值来拟合文本实例区域。通常基于卷积神经网络(convolutional neural networks,CNN)的检测方法是将多个预测得到的候选区域输入到CNN进行特征提取,并通过分类确定候选区域是否包含目标实例。文献[6]基于全卷积网络(fully convolutional networks,FCN)[7]和YOLO(you only look once)[8]的思想,提出了一种霍夫投票的变体,利用平移不变性将局部预测器作为CNN 的最后一层,模型同时密集地预测各像素的类别标签以及基于该像素的预测边界框的参数,显著提高了检测性能。但是整个网络结构仍然过于复杂,严重影响了训练时间,且不能很好地检测旋转文本。文献[9]中的深度匹配先验网络(deep matching prior network,DMPNet)首次提出用四边形检测旋转文本。该模型首先利用四边形滑动窗口粗略地召回文本。然而利用滑动窗口定位文本的方法,通常无法避免不必要的滑动窗口与文本实例之间的区域重叠甚至信息丢失。为此提出了一种共享蒙特卡罗方法,使得在计算重叠区域面积时更加高速和精准。该模型摒弃了传统的矩形检测框,有效解决了检测旋转文字时的背景冗余和信息缺失等问题。但是DMPNet 所使用的滑动窗口是人工设定的,在检测某些极端角度的文字时不够灵活。模型直接预测矩形框的顶点坐标,这样会出现坐标的顺序混淆问题。Liu等人[10]进一步将预测边框离散化为关键边缘,然后利用一个多分类器学习得到正确的文本匹配。但是这种基于参数回归的方式检测旋转文本存在边界间断的问题。
Liao等人[11]提出的TextBoxes是一种基于单例多框检测器(single shot multibox detector,SSD)[12]的全卷积网络模型。由于文字往往有较大的长宽比,SSD在检测横纵比较大的单词时会出现失误。为此文中设计了多个不同比例的默认框,并且为每个默认框设置了垂直偏移量,以避免各框之间竖直方向过于稀疏而导致检测性能变差。而且TextBoxes 只能检测水平方向的文字,在不规则场景文本的检测上,如处理弯曲、旋转程度较大等问题时,成比例的单一矩形框已经不能满足需求。为此,文献[13]对TextBoxes 进一步地优化,不再使用传统的单一矩形框作为检测文本的预测边框,而是通过回归文本多边形的端点坐标来检测多向文本,使用四边形或旋转的矩形有效解决了旋转文字的检测问题。在测试阶段使用非最大值抑制来合并所有文本框层的结果。但是整个网络步骤繁杂,训练时间较长。Zhou等人[14]优化了检测流程,仅包括两个阶段:FCN 阶段对输入图像进行特征提取,提取出不同水平的特征映射,其结构如图1所示;非最大值抑制阶段则对特征进行自顶向下的合并。模型可以对旋转文本进行检测,预测边框可以是任意四边形。该模型减少了候选框建议、单词划分等中间步骤和组件,有效提高了处理效率和性能。但是EAST(efficient and accurate scene text detector)模型的感受野受到网络接收域大小的限制,在检测长文本时性能不佳。为此,文献[15]通过在特征金字塔上构造双向卷积来将多尺度特征映射到尺度不变的空间,使得模型对多尺度文本的检测更加鲁棒,对长文本或小文本的检测性能也更好。但是模型并没用舍弃后处理步骤,在训练时间上不如EAST。
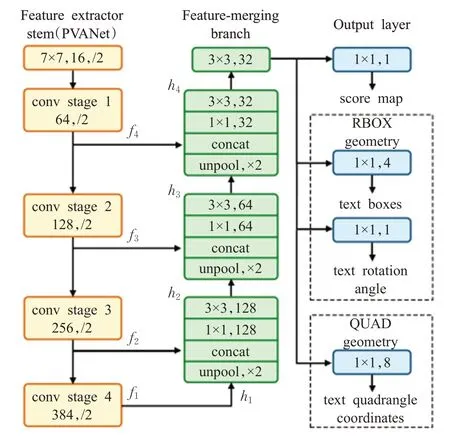
图1 FCN模型结构Fig.1 Architecture of FCN
自底向上的检测方法在检测弯曲文本和长文本时的性能远比自顶向下的方法好,但是检测场景密集文字时效果不佳,且后处理复杂。Shi等人[16]提出的SegLink是一种自底向上的检测方法。该方法基于分段(segment)-链接(link)的思想,其中segment是覆盖单词或文本行一部分的多方向边框,link 链接两个segment 表示它们属于同一文本内容。最终根据它们的置信度得分将相关的segment融合为最终的文本行。该模型有效摆脱了人工设定的默认框比例对结果的限制,使网络可以成功检测多方向文字和长文本行文字。但是该模型不能检测曲形文本和字符间距较大的文本行。为此,文献[17]进一步将分块之间的关系明确为吸引链接或排斥链接,以辅助分离密集的文本,并利用实例感知损失函数对检测不良的检测区域和链接给予更多的损失权重,实现了后处理。但是模型缺少语义信息,在文本行方向的判断上容易出现失误,进而导致检测失败。文献[18]利用基于图卷积网络的链接关系预测模块生成多个不相交的分段,这种方法可以充分利用文字的上下文关系,对大小间距的文本都能很好地检测,避免了链接过程中过度分解的问题。文献[19]生成一批有角度的四边形框定位场景文本,但是生成的预测边框仍然是高度重叠的,五参数法容易因为角度周期性问题而出现边界不连续的问题。
文献[20]首先利用不同尺度的锚点生成候选区域,然后在Fast R-CNN[21]阶段回归出更精确的文本框。Zhang 等人[22]发现对于检测较长文本,“只看一次”可能只会看到文本行的一部分,由此提出一种多次处理文本实例区域的模型LOMO(look more than once)。该模型通过直接回归器(direct regressor,DR)生成一个粗略的覆盖目标区域的四边形检测框,但是因为感受野的限制,DR很难把长文本检测完整,故提出了迭代优化模块(iterative refinement module,IRM)。IRM 不断优化迭代来自CNN 和自身提取的特征,并引入端点注意力机制回归每个端点的坐标偏移量,使得模型可以完整地检测到整个文本行。IRM 的具体结构如图2 所示。最后通过形状表达模块,根据场景文本的几何属性重构出更加灵活、接近文本的文字区域表达。LOMO模型摆脱了传统的基于四边形检测框表示目标区域的方法,有效拟合了复杂文本的区域边界,并分别利用IRM模块解决超长文本检测问题,利用形状表达模块解决了曲线文本检测问题。但是文献[20,22]都面临着一个共同的问题:它们都是利用一个基于实例掩码预测的模块来为每个弯曲文本预测一个更精确的检测框,但是这种方法在检测长曲型文本时检测框建议高度重叠,有可能在非最大值抑制阶段被错误地抑制,最终召回率会受到影响。文献[23]提出的多尺度形状回归模型(multi-scale shape regression,MSR)同样解决了对曲线文本的检测问题。该模型将文本区域每个像素回归到该像素最近边界生成密集的边界点,并链接边界点以生成预测区域边界,避免了在回归稀疏顶点过程中预测长文本时造成较大的回归误差。多尺度的网络特征提取和融合,规避了文本尺度比例异常或较大时对预测结果的影响。
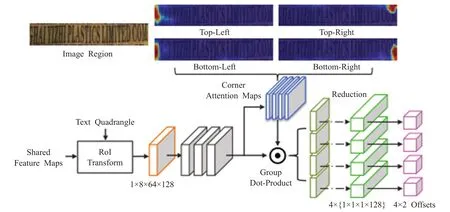
图2 IRM模型结构Fig.2 Architecture of IRM
基于回归的检测方法的回归方式、检测文本类型及优缺点如表1所示。

表1 基于回归的场景文本检测方法Table 1 Natural scene text detection methods based on regression
1.2 基于分割的检测方法
基于分割的场景文本检测方法通常利用语义分割的基本思想,将文本检测问题视为一种对文本/背景的分类问题,该类方法常用经典的FCN、全卷积实例感知网络(fully convolutional instance aware,FCIS)[24]等方法预测像素级别的文本/背景标签。Long等人[25]提出的TextSnake模型以一种更加灵活的方式表示文本的几何属性。该模型以圆环为基础,通过FCN 不断预测文本中心线和文本区域,以及这些圆环的表征属性,堆叠多个圆环构成的序列表示文本行的几何特征。表示方法如图3 所示。每个圆环的圆心位于文本区域的中心轴线上,并有确定的大小和方向。TextSnake 可以很好地解决不规则场景文本的检测问题,但是该方法是在“蛇形”文本行实例的前提下进行检测的,即文本行有唯一的起始点和终止点,对于多文本行之间有连接或重叠情况的,就可能出现检测误差。文献[26]基于TextSnake的思想,把识别问题转换成一个技术问题,将累计的类预测和标签标注看作所有类的概率分布,并利用交叉熵比较这两种概率分布,使用了一系列局部四边形来定位复杂的文本。但是文献[25-26]同样对字符间和字符内间距是敏感的,在检测间距较大的文本时容易出现过度分割的情况。

图3 TextSnake模型结构Fig.3 Architecture of TextSnake
文献[27]提出了一种基于分割的渐进尺度扩张网络(progressive scale expansion network,PSENet)。该网络首先将图像输入到特征金字塔网络,提取不同尺度的特征再融合特征。然后通过基于广度优先搜索的渐进尺度扩展算法根据核的尺度由小到大逐步扩增,直到核与原文本实例大小相等,最小的核可以把原本紧靠的文本实例分开。最终根据文本形状应用相应方法获得最终的边界框。PSENet对密集文本的文本行分割和字符间分割更加准确,并且对任意形状都是鲁棒的。但是该模型网络结构以及后处理过程复杂,导致处理时间较长。为此,文献[28]提出的像素聚合网络(pixel aggregation network,PAN)进一步降低了计算成本以及后处理的复杂程度。该网络模型使用轻量级的CNN 进行特征提取,但是轻量级网络提取到的特征感受野较小且表达能力较弱。随后PAN利用分割头对特征进行细化处理,解决了上述问题。分割头包括两个主要模块:特征金字塔增强模块是一个U形可级联模块,可以通过融合不同层级信息增强不同尺度的特征深度和表达。特征融合模块将不同深度的特征融合为最终的分割特征。最后,提出了一种可学习的基于聚类思想的像素聚合方法,将文本实例像素聚合到正确的核以重建完整的文字实例,抑制相邻文字的粘连与重叠。PAN 模型极大地提升了检测效率,而且对长文本、密集文本的检测性能非常好。
文献[29]提出利用文本中心-边界概率和文本中心方向检测文本,充分利用了文本实例内部的关联关系,摆脱了感受野的限制。然后利用与文献[14]相似的方法回归文本框,并且其中有两条边可能是弯曲的,可以更好地检测曲线文本。但是该模型要针对文本实例区域中逐像素地生成标签,在实际应用过程中训练标签的生成速度较慢。Liao等人[30]借助边框学习的思想,提出了一个可微的二值化(differentiable binarization,DB)模型,并将其插入到分割网络中进行联合优化,在优化过程中对每个像素点自适应地学习得到鲁棒的二值化阈值,以更好地区分文本区域和背景区域,大大简化了后处理的负担。该模型的主干网络无论是ResNet-50还是轻量级的ResNet-18,都可以达到极佳的检测性能,且在ResNet-18的情况下可以达到实时推理。但是当文本实例正好位于另一个文本实例的中心区域时,它会失败,这是基于分段的场景文本检测器的一个常见限制。
1.3 基于回归和分割混合的检测方法
基于分割的方法通常需要多信息分割、融合的操作,影响了检测速度,但检测方式灵活,更适合不规则文本的检测。基于回归的方法检测多文本尺寸不够鲁棒,但能够检测小文本。因此综合两种方法的优势往往可以更好地检测不规则文本。文献[31]提出了一种基于Mask R-CNN[32]的金字塔掩码文本检测器(pyramid mask text detector,PMTD)。该模型不再进行像素级二进制分类,而是将形状和位置信息编码到监督中,并为每个文本实例预测一个软文本掩码。PMTD 模型又将二维软掩码重构到三维空间,并提出了一种平面聚类算法,从这些三维点回归出最优金字塔。但是该模型仍然使用四边形检测框表示文本实例区域,在检测不规则文本时效果不佳。
文献[33]主要针对检测曲线文本问题,提出了一种基于特征金字塔网络和分割思想的监督金字塔文本检测网络(supervised pyramid context network,SPCNet)。该模型还通过引入上下文语义信息和对所有预测文本实例的重新评分机制,有效地抑制了误报问题。基于类似问题,Wang等人[34]提出了ContourNet模型。该模型提出一种对尺度不敏感的自适应区域提议网络,通过只关注预测边界框和真实边界框之间的交集值来生成初步文本区域提议,提高了文字候选区域生成质量。又将传统边缘算子思想融入到局部正交纹理感知模块中,用一组轮廓点来表示文本实例区域。随后采用方向解耦思想的重新评分算法,利用水平和竖直方向模块分别预测目标文字实例的轮廓,两者融合,有效提升了检测正确率。
1.4 其他检测方法
复杂场景中的文字通常带有重叠、遮挡等问题,文献[35]利用深度置信网络提取到的文字纹理特征进行分类,并提出了针对重叠文本的检测方法。该方法将复杂场景图像分解成若干个单一背景图像,利用级联Adaboost 分类器得到最终的文本实例区域。Adaboost分类器是多个弱分类器组成的一个强分类器,因为各个弱分类器采用级联的方式组合,所以大部分的分文本连通分量会在前几个弱分类器中被剔除,这样有效解决了文字重叠的问题。但是单一的特征在解决复杂背景问题时往往效果不佳,可以从纹理特征、边缘特征和颜色特征相结合的角度提升文本定位的精度。
文献[36]主要针对自然场景中的不均匀光照、模糊问题,通过融合积分通道特征和特征池的思想,并使用卷积策略整合图像的特征表达,让整个模型对光照不敏感,可以更加关注文字的本质特征。但是模型使用经验的方式对文本实例区域和背景区域设置一些二值化阈值,当文字边缘与背景出现粘连问题,尤其是文字处于一块复杂背景区域时,模型存在严重的漏检情况。
1.5 总结
基于回归的文本检测方法通常分为“自顶向下”和“自底向上”的方式。而“自顶向下”的方法通常先生成粗略的候选框建议,然后利用回归的方式生成更精确的文本实例区域的表达。近几年的研究大部分都是回归出预测边框的端点坐标,这样就存在坐标顺序的混淆问题。“自底向上”的方法可以避免候选框建议的限制,这种方法通常将检测到的文字或句子片段根据添加的属性合并成完整的文本。但是对于字符间隔较大的文本或字符本身较大的情况,就有可能出现过度分割的问题。
基于分割的方法通过预测像素级的文本实例,可以检测多角度的文本,但是由于后期处理复杂,这种基于分割的方法通常要消耗大量的时间。对于文本重叠的情况,这种方法很难精确地分别检测出来。
2 基于深度学习的自然场景文字识别方法
场景文字识别技术在计算机视觉和机器智能领域受到越来越多的关注,识别场景文本对于场景理解具有重要意义。在近几届的国际文档分析与识别大会中(International Conference on Document Analysis and Recognition,ICDAR),针对识别场景文字的问题,基于深度学习的识别方法在性能上远远超过传统的文本检测方法,体现出了应用深度学习的优势[37]。在不受约束的环境中识别文本仍然是当下面临的最具挑战的问题,通过研究者们的不懈努力,已经有了很多针对上述问题的基于深度学习的文字识别模型。
2.1 基于CTC的识别方法
连接主义的时序分类(connectionist temporal classification,CTC)[38]机制通常被用在预测阶段,CTC通过累加条件概率将CNN 或RNN 输出的特征转换为字符串序列。在文本识别技术中的应用可以解决时序类文本的对齐问题,即确保预测文本序列与实际文本序列顺序一致,长度相同。
He 等人[39]提出了深层文本循环网络(deep-text recurrent network,DTRN)识别模型。该模型将CNN和RNN 放在一个网络中进行端到端的联合训练,把场景文本识别问题视为序列标记问题。DTRN首先利用32×32 大小的滑窗滑动截取图像,并依次输入到Maxout[40]CNN 进行提取特征,然后由RNN 进行解码,最后通过CTC将长短记忆网络(long short-term memory,LSTM)[41]的序列输出映射到其目标字符串中,对结果进行调整。RNN 对结构信息的理解能力很强,但是也使得模型的并行性更差,效率更低。
Shi 等人[42]在2017 年提出了卷积循环神经网络(convolutional recurrent neural network,CRNN)。该网络在深度双向LSTM中堆叠多个双向LSTM的结果,并将CTC 模型连接在双向LSTM 网络的最后来实现端到端的文字识别。CRNN模型由卷积层、循环层和转录层三部分组成。其结构如图4 所示。循环层由一个深度双向LSTM构成并设计于卷积层的顶部,用来预测特征序列的标签分布。转录层将RNN所做的每帧预测转换成标签序列。CRNN 网络可以在无字典或基于字典的任务中使用,并且不涉及水平归一化或限制长度等操作,大大提高了识别性能。但是由于字符位置的不确定性,在循环层对字符的多个预测值的累加操作就会导致模型的计算量大大增加,而且如果对数据集进行字符级坐标的标注也需要消耗大量的人力。整个网络未考虑特征间的关联关系就可能导致CNN学习到的特征不如人意,最终识别失败。
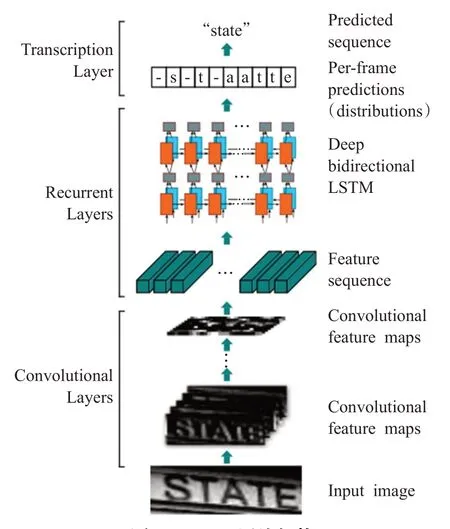
图4 CRNN网络架构Fig.4 Structure of CRNN
2.2 基于Attention的识别方法
目前主流的场景文本识别模型都是基于编码器-解码器框架的,而传统的编码器-解码器框架只能将输入序列编码成一个固定长度的向量表示。引入Attention机制的编码器输出的是不定长向量组成的序列,对目标数据以及相关数据赋予更大的权重,使得解码器的“注意力”集中到目标数据,获取到更多的细节,并且可以学到较长输入序列的合理向量表示。注意机制通常与RNN结合作为预测模块。
文献[43]提出了一种具有自动矫正功能的鲁棒文本识别器(robust text recognizer with automatic rectification,RARE)。该模型包括一个空间变换网络(spatial transformer network,STN)[44]和一个序列识别网络(sequence recognition network,SRN)。其中STN 利用薄板样条(thin-plate splines,TPS)[45]变换对带有不规则文字的输入图像进行矫正,矫正后的字符沿水平线排列,更适合于SRN 的识别。SRN 则将矫正后的结果作为输入,将识别问题建模为基于Attention机制的序列识别问题,使得整个模型可以进行端到端的识别。SRN由编码器和解码器组成,编码器采用了卷积-递归结构,解码器对各步骤的Attention机制所确定的内容进行解码,并循环生成输入图像的字符序列。该模型大大提高了自然场景下不规则文本的识别性能。但是RARE 模型采用非线性函数tanh作为最后全连接层的激活函数,虽然保证了采样点在图片之内采样,但是减缓了收敛速度。定位网络获取控制点的图片略大,导致预测时需要更多的参数。为此,文献[46]对RARE模型进行了改进,提出了具有灵活校正功能的注意力场景文本识别器(attentional scene text recognizer with flexible rectification,ASTER)。该模型仍然包括空间变换网络和序列识别网络两部分,通过TPS变换对不规则文本进行矫正,并利用双向长短记忆网络(bidirectional long short-term memory,Bi-LSTM)[47]和Attention 来做端到端的联合训练。与RARE不同的是,在最后一个全连接层中并没有使用tanh 作为激活函数,而且对采样器中的值进行裁剪,既降低了反向传播过程中梯度的保留,又确保了有效采样。同时,ASTER 在STN 中使用不同大小的图像用于定位网络和采样网络,定位网络将从更小的图片中获取控制点,减少了预测所需的参数。ASTER 在解决不规则场景文本识别任务上表现出了良好的性能,但是基于校正的方法往往受到字符几何特征的限制,并且模型更容易被背景噪声影响。为了克服这个问题,Luo等人[48]提出了多目标矫正注意力网络(multi-object rectified attention network,MORAN)。MORAN 由多目标矫正网络和基于Attention 机制的序列识别网络构成。其中矫正网络是一个像素级矫正网络,该网络生成一个与输入图像相同大小的偏移图,偏移图中的每个值表示对应输入图像位置像素相对于原始位置的偏移量。序列识别网络的主要结构是CNN-BLSTM-Attention 框架。此外,还提出了一种分数拾取方法来扩展基于注意力的解码器的视野。该矫正网络不受几何约束,因此比仿射变换更加灵活,但是缺点也很明显,它只能对横排文字进行矫正,无法解决竖排文字的畸变。MORAN网络虽然可以处理不规则文本识别问题,但是对于曲线角度过大的情况,会识别失败。文献[49]在解决不规则文本的识别问题时同样采用矫正的思想,模型将文本图像分成几个不重叠切片,小的切片更容易被矫正,但是直接利用仿射变换在合成完整图像时容易出现严重的不连续问题,随后模型利用网络投影来平滑变换图像,最终合成完整图像的文字更加平滑、完整。但是模型利用几个全连接层预测仿射变换参数,参数量大大增加。
Cheng等人[50]发现在处理低像素/复杂的图像时,基于注意力机制的方法表现不佳,主要是由于注意力网络无法将这种特殊图像中字符的注意中心准确地集中到对应的目标区域的中心,并称这种现象为“注意力偏移”。因此,文献提出了一种聚焦注意力网络(focusing attention network,FAN)。FAN 首先通过注意力网络计算出目标区域与特征区域的对齐因子,将注意中心与目标区域对齐。然而,计算出的注意中心通常是不准确的。然后FAN又通过聚焦网络来检测并矫正注意力中心,有效解决了“注意力偏移问题”。但是FAN 网络将二维特征展平为一维连续特征向量,破坏了各像素之间的空间和结构联系,像素之间的全局上下文和字符之间的潜在依赖性被忽略,特别是对于自然场景文本识别问题,笔画结构是区分字符的一个关键因素。而且它还需要额外的字符集边界框注释来训练,成本大大增加。
基于Attention 机制的识别网络通常依赖于传入的解码信息,因为Attention 机制与解码信息的耦合关系,解码信息的误差必然会累计和传播,所以传统的Attention机制总是出现严重的对齐问题。Wang等人[51]将传统注意力机制的解码器解耦为卷积对齐模块和去耦解码器。该模型在识别长文本、手写体文本时表现出很好的性能,但是仍然无法避免噪声的影响,即使是类似文本的噪声也会尽力对齐文本。Lu等人[52]认为在基于RNN的局部注意机制下,编码特征之间的高度相似性会导致注意力混乱,因此这种方法总是存在注意力偏移问题。于是提出了一种多方向的非局部自我注意模块。而且在训练阶段有所调整,通过创建下三角形掩码矩阵,解码器可以同时输出所有时间步长的预测,提高了训练过程的并行性,训练时间也大大缩减。文献[53]显著提高了每个时间步长的对齐因子的准确性。而且通过相互引导的方式解决了模糊、不规则文本的难题,但是该模型只是针对26个英文字母和10个阿拉伯数字的识别问题,面临大规模标签种类的数据集性能会大大降低。
基于Attention的识别方法的主要思想、检测文本类型及优缺点如表2所示。
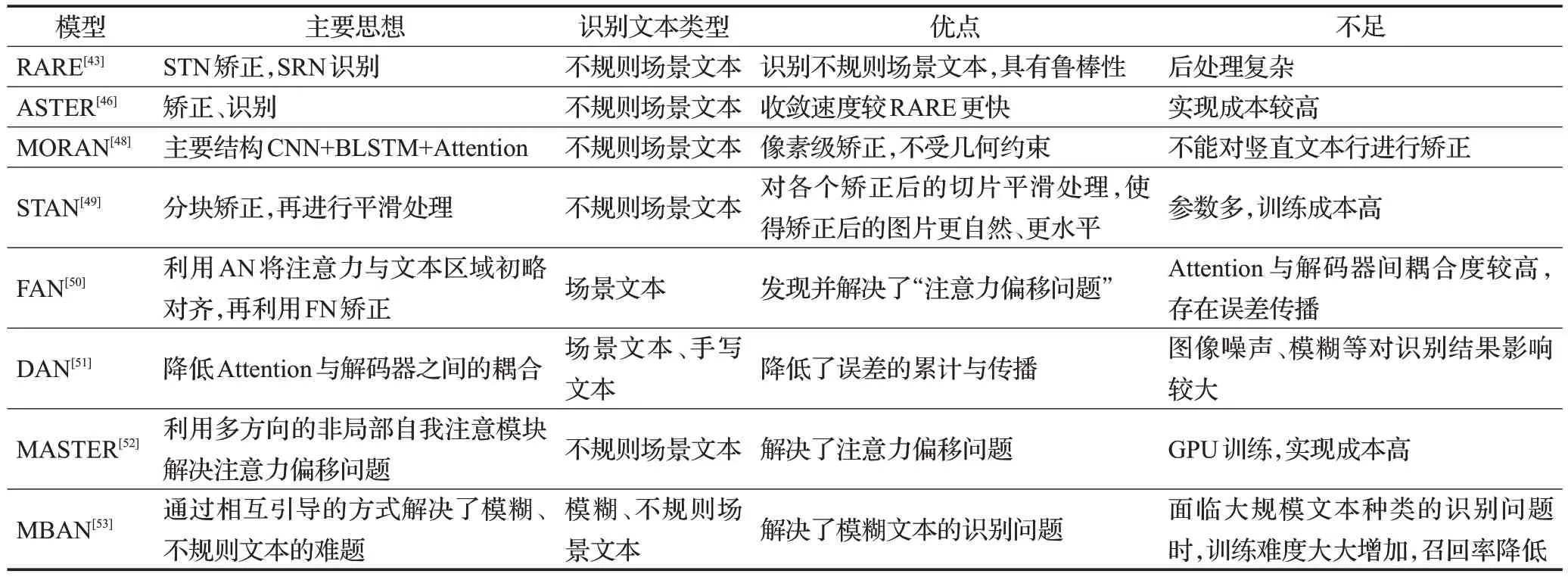
表2 基于Attention机制的场景文字识别方法Table 2 Natural scene text recognition methods based on Attention mechanism
2.3 基于CTC和Attention的识别方法
由于Attention 机制生成的是预测文本序列与实际文本序列对齐的概率,可能增加对齐误差,CTC 机制则可以引导Attention 更好地对齐,因此两者结合往往可以相互促进,提高识别性能。文献[54]融合了CTC 和Attention的思想,提出了选择性上下文注意力文本识别器(selective context attentional text recognizer,SCATTER)。SCATTER首先使用TPS变换对输入图像进行矫正。堆叠多个Bi-LSTM 编码器,用CTC 的辅助训练设计了一个级联的Attention 的选择性注意力解码器。通过采用二步一维注意力机制同时解码CNN 层的视觉特征和Bi-LSTM层计算的上下文特征。SCATTER利用堆叠的思想成功训练了更深的Bi-LSTM 编码器,识别性能大大提高,通过中间监督、选择性解码器使得整个网络更加稳定、鲁棒。尽管Bi-LSTM 可以有效地对文本上下文进行建模,但它的计算量大且耗时,并且在训练中它可能会导致梯度消失/爆炸。文献[55]同样使用混合思想,利用Attention 去监督CTC 做更好的识别,提出了CTC 指导训练模型(guided training of CTC,GTC),有效解决了文献[42]中缺乏聚焦于局部区域能力的问题。GTC模型将提取到的特征分别传入CTC解码器和注意力指示器。其中注意力指示器利用Attention 机制并使用CE 损失函数不断优化STN 模块的矫正和CNN层的特征提取。CTC 解码器在LSTM 层前增加了图卷积网络来利用空间上下文相关性,并且将从更好的特征表示中不断更新自己,以解码出更准确的识别结果。
2.4 其他识别方法
近几年还有学者认为语义、语料也是文本识别的一个重要因素。文献[56]提出用一个预训练好的语言模型,把它集成到识别器去做联合优化,能比较好地提升它的识别效果,但是这样又增加了训练负担。语义模型中存在全连接层,也意味着输入图像需要被缩放到固定大小,这样就会导致一部分信息的丢失。
文献[57]以全监督和弱监督结合的方式训练模型,有效利用了弱标注文本的40万大规模数据。为了从弱标注数据中挖掘丰富的信息,模型在监督学习框架下设计了一个在线建议匹配模块,通过共享参数来定位关键词区域进行端到端的训练。模型加入弱监督辅助训练之后的识别性能明显好于全监督训练,但是利用大量的数据集将带来更大的计算成本。文献[58]针对序列域迁移问题提出了一种序列域自适应网络模型,域自适应可以更好地利用无标注数据集减少序列域的偏移。该模型还引入了一个新的门控注意相似单元,采用门控函数控制模型聚焦于最有效的字符级特征,而不是通过全局特征来执行域自适应。该模型应用范围广泛,可以应用到自然场景文本、手写体文本甚至公式识别中。
2.5 端到端识别方法
目前大部分的研究都是针对场景文本检测或者识别的单个任务,端到端的识别方法则是一个模型可以同时完成以上两个任务。
为了解决复杂场景中极端光照对边缘检测效果不理想的问题,文献[59]对训练样本的颜色信息进行判断,对预处理得到的图像进行高斯滤波处理,消除了部分噪声,通过先验概率和SVM模型剔除非文本区域,进而确定文本实例区域。在文本识别阶段,模型将传统的LeNet-5[60]中的输出神经元增加到65 个,并且在改变神经元数量的同时对应调整训练样本的种类分布。该模型在复杂场景中尤其是极端光照情况下可以达到较高的识别精确率,鲁棒性较好。但是在目标区域由于磨损导致其断裂粘连时,相应的分割提取方法仍可以进一步改进,而且模型结构复杂,处理时间较长。
文献[61]提出用三阶自适应贝塞尔曲线对文本矫正,然后在参数空间里面去回归这些控制点,而不是在图像上回归文本框,因此在检测多方向多尺度文本时它的检测框更加平滑,并且速度很快。识别阶段采用CNN+Bi-LSTM+CTC 结构,最终实现端到端场景文字识别。但是模型是通过合成数据集训练的,在测试时文本漏检问题较严重。文献[62]利用分割建议网络解决了其过去版本[63]严重依赖手动设计锚点的问题。此外,由分割建议网络生成的精确建议可以解耦相邻文本实例,因此该模型可以避免背景噪声、模糊问题对检测性能的影响,最后利用一个空间注意力模块对检测到的文本实例区域进行识别,并且对极端长宽比文字的识别也是鲁棒的。但是基于分割的方式后期维护代价高,且计算成本也较高。文献[64]在检测阶段利用局部四边形回归和中心线分割的思想处理任意形状的文本。在识别阶段引入了一种基于CNN 和CTC 机制,让框架无需标注字符位置,并且识别效率要比传统的基于Faster RCNN[65]+Attention的模型要高很多,但是模型仍然很难应用到实时识别的任务中。
2.6 总结
CTC机制通常预测一维的特征序列,通过累加所有文本可能性的概率预测出最终的文字序列,可以最大化输出序列的正确性。但是CTC 的计算方式复杂,计算成本高,而且很难对二维特征进行预测,这就损失了很多场景文本的空间属性。
Attention 机制使得解码器可以更关注与目标文本相关的信息,并且更容易扩展到二维预测问题。但Attention机制生成的是对齐概率,特别是对于长文本识别问题,有可能出现对齐误差,即“注意力偏移”现象。将Attention 机制应用到场景文字识别任务中是当下的一个热点方向,但是目前很少有Attention模型是针对标签种类较多的数据集的,如何减少在大规模标签种类识别任务中的计算成本是下一步应解决的问题。
端到端的识别方法可以共享文本检测与识别的信息,并且可以对其进行联合优化,避免了级联检测与识别模块方式的误差累计。端到端模型的整体推理速度要比级联方式更快,但是如何维护检测与识别间收敛时间与难度的平衡仍然是一个挑战。
3 常用数据集
目前较常用的场景文本检测与识别的数据集包括:水平数据集ICDAR2013[66]、ICDAR2015[67]、SVT[68]、KAIST[69]等,任意形状数据集MSRA-TD500[70]、OSTD[71]、COCOText[72]、SCUT-CTW1500[73]等,多语言数据集ICDAR2017-MLT[74]、ICDAR2019-MLT[75]、EvArEST[76]等,中文数据集ICDAR2019-LSVT[77]、ICDAR2019-ReCTS[78]、CTW[79]、ShopSign[80]等。上述数据集的详细信息如表3所示。

表3 场景文本检测与识别常用数据集Table 3 Common datasets of natural scene text detection and recognition
4 发展与趋势
文字是人们信息传递的载体,通过对文本检测与文字识别技术的分析,可以看出随着深度学习在文本检测与识别技术中的应用,所能解决的问题也越来越复杂,但是同样存在大量的问题需要被解决,如对密集文本和不规则文本的检测性能仍远远低于检测水平文本的性能。对多语言(非拉丁文)检测与识别技术的需求日益提升。无论对文本的检测还是识别,其目的都是提取图片中的文字并利用其文本含义,因此对文本视觉问答技术的研究尤为重要。综上所述,场景文本检测与识别技术可以从以下几方面进一步扩展。
(1)密集文本、曲线文本的检测与识别
当前针对复杂文本检测问题的模型多是通过回归边框的方式确定文本实例区域,如TextBoxes、TextBoxes++,如果可以通过回归文本位置的控制点替代回归文本框端点,则可以让最终的文本框的表达更加灵活、精确。很多学者对不规则文本识别的研究是先矫正再识别,如RARE、ASTER,而字符级的矫正相对于其他矫正方式来说,旋转角度较小并且更容易被识别,如果可以设计一个好的字符级的检测识别器,就可以极大地提升不规则文本的识别率。
(2)提高模型的性能与泛化能力
算法的迭代旨在增强算法的实用性、易用性以及轻量化。随着互联网的发展和大数据时代的来临,大量的数据需要被处理,这就使得在保证识别性能的基础上识别效率的提升尤为重要。如EAST模型、PAN模型都在简化模型结构的基础上提升了检测性能。另外,从参数空间的角度提升模型性能也是很好的解决方法。过去的研究多是定义一组文本框最终标识检测到的文本,如果将这种二维的方法拆解成一维的表达方式,则可以简化问题并且减少计算量。虽然目前利用合成数据集训练的算法在标准数据集的评估上表现出了比较好的性能,但是它对多尺度、多样式的文本适应能力较差,除了丰富训练数据的样式外,怎样提升模型的泛化能力仍是一个挑战。可以从文字本身带有的基本属性如语义、结构等方面进行研究。
(3)多语言场景检测与识别
近几年ICDAR发表的数据集都有一个多语言的版本,如2017-MLT、ICDAR2019-MLT,这也预示着多语言文本的检测与识别的地位日益提升,对多语言文本的检测与识别技术的需求也日益增加。当前的数据集中存在部分注释不完善的问题,例如不规范的标点符号或者不区分外文字母大小写,还应该为这些数据集提供新的更全面的注释,如字符级、像素级的注释。利用合成数据进行训练,然后在标准数据集上评估是目前模型的一个趋势,如何让合成数据集对模型的训练更有价值是比较重要的问题,另外提出一个更好的数据扩充方法也是需要思考的问题。
(4)对无约束的场景文字的检测
由于场景文本检测与识别技术都将应用在实际场景中,无约束的场景通常带有强烈光照、模糊、遮挡等问题,虽然当前的场景文本检测技术已经达到较好性能,但是针对无约束场景的性能较差。有些模型只是针对某个数据集的检测效果很好甚至过拟合,因此可以在训练模型时多增加一些对抗样本让模型更鲁棒。
(5)中文数据集和检测识别方法
中国是个多民族国家,目前针对中文以及各民族文字的数据集和识别方法数量有限。建立公开的中文数据集、少数民族文字数据集对中文检测与识别技术有重大的意义。
(6)语义、语料在场景文本识别方法中的应用
由于场景文字通常带有语义信息,目前已经有相关的研究如SEED用一个预训练好的语言模型,然后把它集成到识别器去做联合优化。用语义信息去监督场景文字识别通常可以提升识别准确率。
5 结束语
光学字符识别技术已经十分成熟,对自然场景下文本的检测与识别是当今的热点问题。本文分别对场景文本检测技术和文字识别技术进行了分析。文本检测技术中基于分割的方法可以更加灵活地检测不规则文本,但是对于小文本区域的召回率较低。而基于回归的方法能够检测到小文本,然而不能适应文本的多尺度。混合方法结合两者的优点,通常可以达到更好的性能。文本识别方法中CTC机制有效解决了目标文本序列与实际文本序列的对齐问题,但由于CTC 损失函数和字符位置的不确定性,且未考虑特征间的关联关系,对长文本的识别可能出错。Attention 机制使得解码器可以更关注与目标文本相关的信息,但Attention机制生成的是对齐概率,有可能出现对齐误差。CTC与Attention的结合可以相互监督以提升识别性能。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
小天使·一年级语数英综合(2021年9期)2021-09-22
小雪花·小学生快乐作文(2020年6期)2020-10-13
文苑(2020年12期)2020-04-13
当代陕西(2019年10期)2019-06-03
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
互联网周刊(2009年13期)2009-07-29
阅读(中年级)(2009年11期)2009-04-14
