
加权犹豫模糊集的Lance距离测度及其应用
2022-03-05 02:51贾新玲王拥兵
安庆师范大学学报(自然科学版) 2022年1期
贾新玲,王拥兵
(安庆师范大学 数理学院,安徽 安庆 246133)
自Zadeh提出模糊集理论[1]以来,该理论成功地应用于各个领域,模糊集的各种拓展形式也相继被提出,包括区间模糊集[2]、直觉模糊集[3]、区间值直觉模糊集[4]和模糊多集[5]。在实际决策过程中,因为相关知识的缺乏和决策者受时间的限制,所以模糊集的隶属度很难确定。为了解决这一困难,文献[6]和[7]提出了犹豫模糊集的概念,允许其隶属函数在[0,1]区间上有多个可能值。与模糊集的其他拓展形式相比,犹豫模糊集能够有效地表达决策者之间偏好不一致性,吸引了学者们的广泛关注。
为了解决犹豫模糊集信息不确定性的测度问题,距离和相似性度量相继被提出,并广泛应用于多属性决策过程中,如文献[8]和[9]分别基于规范化的Euclidean距离和Hamming距离,提出了犹豫模糊集之间的Euclidean距离和Hamming距离;文献[10]考虑了犹豫模糊集的犹豫指数,提出了具有犹豫度的犹豫模糊集的距离测度。目前,在研究犹豫模糊集的距离测度时,常常通过添加或者删减一些犹豫模糊元,使得两个犹豫模糊集中犹豫模糊元的基数相等,再进行决策分析。但这种方法会使决策过程中原始信息丢失,致使决策结果与实际情况不相符。文献[11]提出了一种新的犹豫模糊距离测度,该距离测度不需要考虑添加犹豫模糊元来保证不同的犹豫模糊元长度相同,可直接进行决策分析。文献[12]通过同时扩张两个犹豫模糊集的两个犹豫模糊元,提出了两个犹豫模糊元长度的最小公倍数的补齐方法。文献[13]基于规范化的Lance距离,给出了犹豫模糊集降维的方案。上述研究充分考虑了决策的原始信息,但在实际决策过程中,还需要考虑对给定的犹豫模糊集中犹豫模糊元赋予不同的权重。因此,本文基于犹豫模糊集中的加权犹豫模糊元,提出加权犹豫模糊集的Lance距离,给出加权犹豫模糊集的Lance距离的TOPSIS方法,并通过具体案例说明该方法的可行性和有效性。
1 预备知识
1.1 犹豫模糊集及其运算
定义1[14-15]给定论域X,称为X上的犹豫模糊集(HFS),其中h A(x)是[0,1]中一些数值的集合,表示元素x关于集合A的一些可能的隶属度,并称h A(x)=h(x)为一个犹豫模糊元(HFE)。
定义2[16]设h(x)为犹豫模糊元,则称为h(x)的得分函数,其中l h为h(x)中元素的个数。对于犹豫模糊元h1和h2,若s(h1)>s(h2),则称h1优于h2,记为h1>h2;若s(h1)=s(h2),则称h1和h2无差别,记为h1~h2。
在实际问题中,常常出现s(h1)=s(h2)的情况,难以判断它们的优劣。为了更好地描述这一问题,Chen等定义了偏差度的概念[17]。
定义3[17]对于给定的犹豫模糊元h(x),称
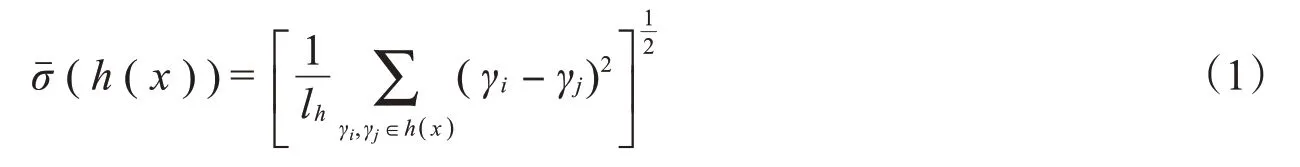
为h(x)的偏差度。
对于犹豫模糊元的大小比较,Liao等给出如下法则[18]:
(1)如果s(h1)>s(h2),则h1>h2;
(2)如果s(h1)=s(h2),则当(h1)>(h2)时,有h1<h2;当(h1)=(h2)时,有h1=h2。
定义4[19]设A1和A2为X上的犹豫模糊集,则A1和A2之间的距离定义为d(A1,A2),它需要满足下列条件:
(1)0≤d(A1,A2)≤1;(2)d(A1,A2)=0,当且仅当A1=A2;(3)d(A1,A2)=d(A2,A1)。
下面给出一些经典犹豫模糊集的距离[20-21]。
(1)标准的Euclidean距离:

(2)标准的Hamming-Hausdorff距离:
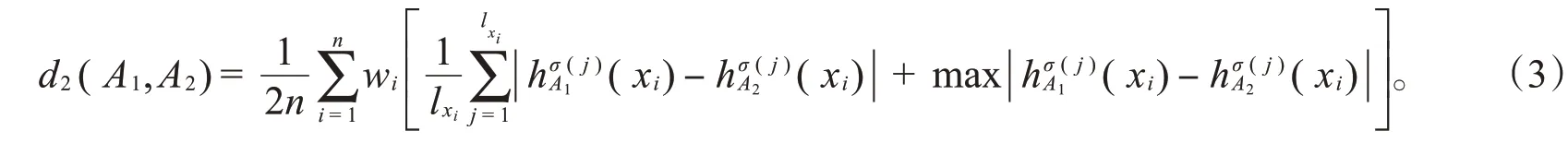
(3)标准的Lance距离:
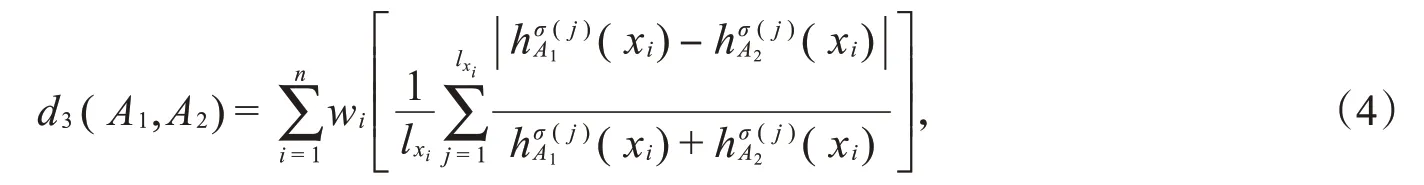
2 加权犹豫模糊集的Lance距离
在实际决策过程中经常遇到这样的情形,如某个公司要对两名员工A和B进行年终考核,请了10位公司的高管对他们进行评估。给A打分时,其中有9位给了0.9,1位给了0.7;给B打分时,其中4位给了0.9,6位给了0.7。公司的领导很可能在这两个值之间犹豫,这时采用犹豫模糊集{0.9,0.7}来表述较为合适。按照一般情况理解,A的评价结果为{0.9,0.7},B的评价结果也为{0.9,0.7},从而他们的评价结果是相同的,但是,这与实际情况不符,此时需要考虑对犹豫模糊集中的模糊元赋予不同的权重。由于Lance距离是聚类分析中确定样本点之间距离的一种常见方法,其最大优势在于克服了量纲的影响。因此,我们基于标准的Lance距离,给出加权犹豫模糊集的Lance距离。
2.1 加权犹豫模糊集的Lance距离
定义5给定论域X,设A1和A2为X上的加权犹豫模糊集,则称

为A1和A2之间的Lance距离,其中和l h A2(x i)分别表示A1和A2中元素的个数表示ωkiγki中第j大的元,ωki为γki的权重,且满足
若A1和A2中犹豫模糊元个数不相等,则需要在较短的犹豫模糊集中添加犹豫模糊元。若决策者厌恶风险,则添加隶属度最小的元素;若决策者喜好风险,则添加隶属度最大的元素;若决策者风险中立,则添加集合中隶属度最大值与最小值的平均值,并要求添加元素的权重为零。添加原则反映了决策者的偏好[22-23],数据的原始信息不会受到影响,且计算结果保持不变。
定理加权犹豫模糊集的Lance距离d hl(A1,A2)满足定义4中的3个条件。
证明(1)d hl(A1,A2)≥0是显然的。现只需证明d hl(A1,A2)≤1成立。对任意的i,j=1,2,3,…,n,i<j,有,从而

因此,d hl(A1,A2)≤1,于是0≤d hl(A1,A2)≤1。
(2)若d hl(A1,A2)=0,显然有
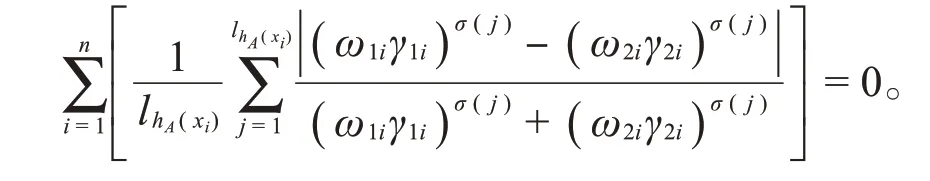
现在证明当d hl(A1,A2)=0时,有A1=A2。利用反证法并结合数学归纳法证明。
若A1≠A2,当i=1时,有
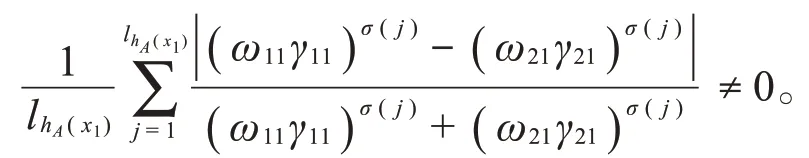
假设当i=n-1时,有

因此,当i=n时,由于A1≠A2,从而有
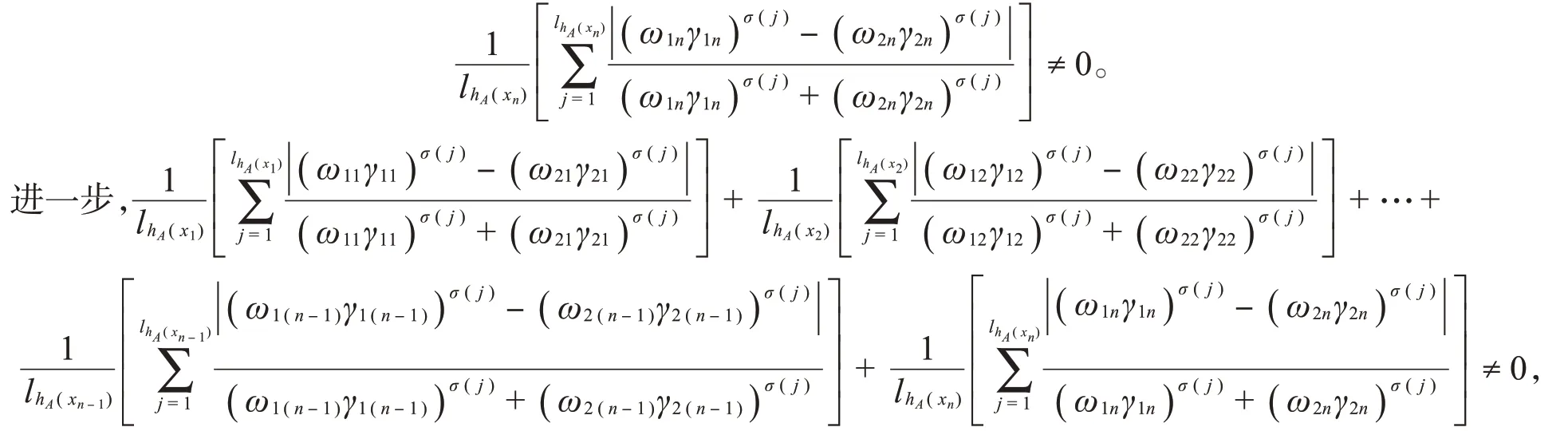
故d hl(A1,A2)≠0,这与条件d hl(A1,A2)=0矛盾,于是A1=A2。
若A1=A2,对任意的i,j=1,2,3,…,n,i<j,有,从而

则d hl(A1,A2)=0。
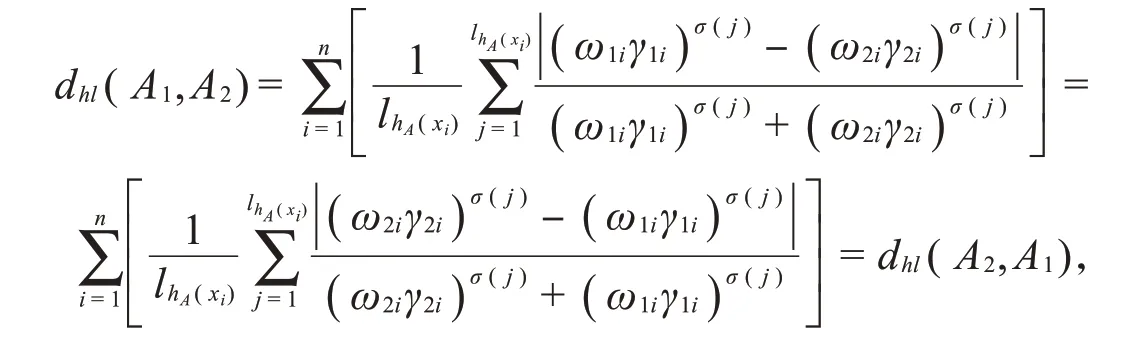
(3)由于 故d hl(A1,A2)=d hl(A2,A1)。
例1 设A1={(0.2,0.8),(0.6,0.2)}和A2={ }(0.8,0.8),(0.4,0.1),(0.3,0.1)为X上的加权犹豫模糊集,根据定义5,这里添加隶属度最大的元素,并排序得到
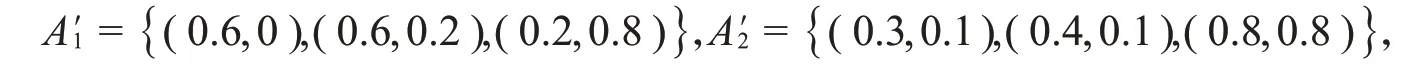
则A1和A2的距离为
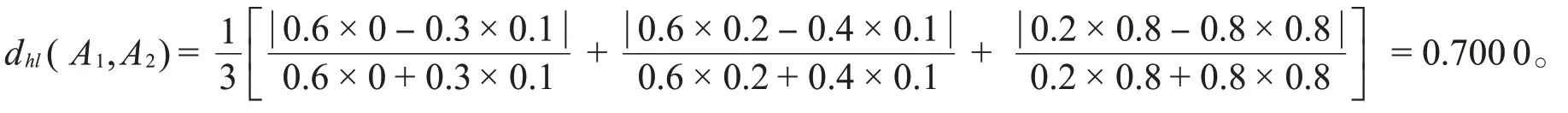
若采用文献[13]中的距离公式,有
文献[13]中的距离公式没有考虑隶属度的权重,在计算过程中忽略了数据的一些信息,从而影响最终的比较结果。从实际情况来看,本文提出的距离d hl(A1,A2)能够更好地保留原始信息,更形象地刻画加权犹豫模糊集A1和A2之间的关系。下面给出其他类型的距离公式。
基于规范化的Euclidean距离,改进的加权犹豫模糊集的Euclidean距离:
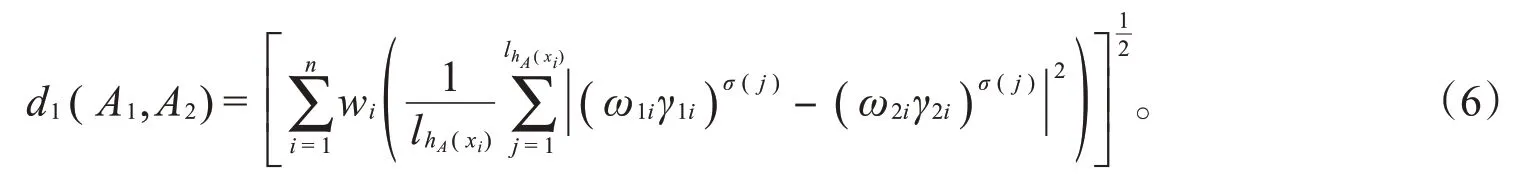
基于规范化的Lance距离,改进的加权犹豫模糊集的Lance距离:
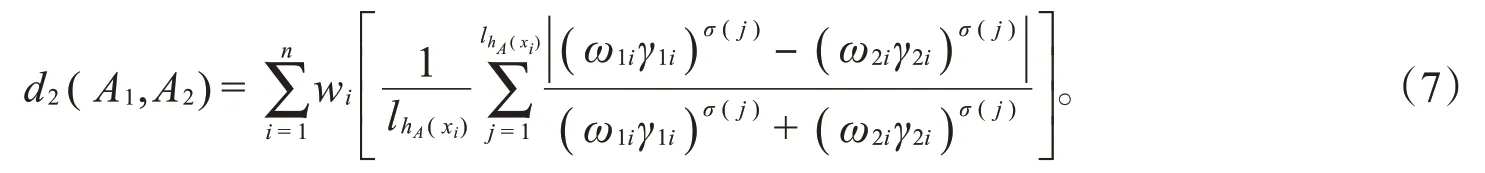
基于规范化的Hamming-Hausdorff距离,改进的加权犹豫模糊集的Hamming-Hausdorff距离:
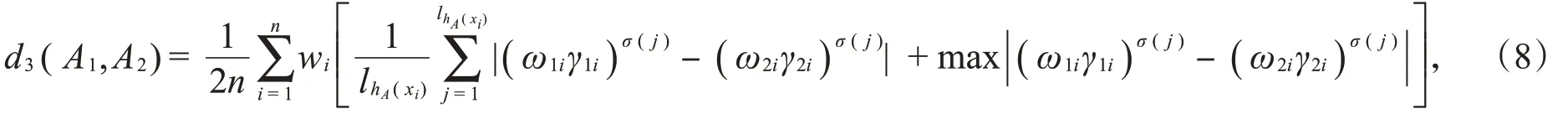
2.2 熵权法确定属性权重
在加权犹豫模糊集多属性决策问题中,假设方案集为A={A1,A2,A3,…,A m},属性集为C={C1,C2,C3,…,C n}。属性通常分为效益型和成本型,为了克服不同属性对决策结果的影响,本文采用效益型属性。属性C j(j=1,2,3,…,n)的权重向量为w=(w1,w2,w3,…,wn)T,其中,
令加权犹豫模糊集决策矩阵为
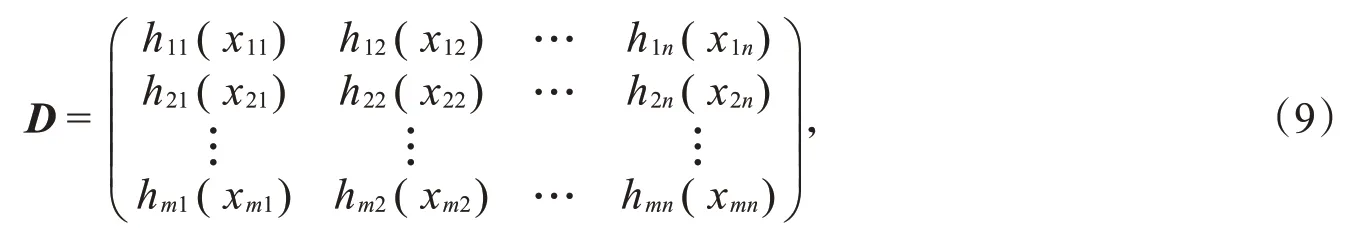
其中,h ij(x ij)(i=1,2,3,…,m;j=1,2,3,…,n)表示第A i个方案关于属性C j的评价信息。
矩阵D对应的期望决策矩阵为

定义属性C j的熵为

2.3 加权的犹豫模糊集的Lance距离计算方法
本文从供货商评价信息出发,将专家评价信息与专家的权重相结合,得到各供货商的综合评价信息,采用TOPSIS方法对供货商择优排序,并与现有的距离公式进行分析比较。给定待选方案A={A1,A2,A3,…,A n},专家组E={e1,e2,e3,…,e n},根据与方案A相关联的属性C={C1,C2,C3,…,C n}给出评价结果。设x ij∈[0,1]表示专家e k在属性C j下给方案A i打出的评价结果,于是,决策者将根据这些评估结果判定所要选择的方案。
Step1在每个属性C j下,考虑方案A i的评估结果。为构造加权犹豫模糊元,分以下两种情形讨论。
1)专家权重未知的情形下构造加权犹豫模糊元。令
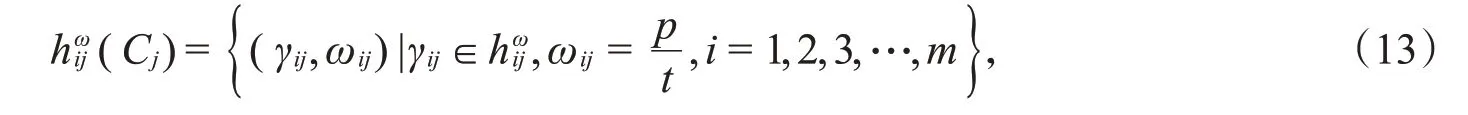
其中,p表示方案A i在属性C j下的隶属度值的个数,t表示专家数。
2)专家权重已知的情形下构造加权犹豫模糊元。设专家e1,e2,e3,…,e n对应的权重向量为w=(w1,w2,w3,…,wn)T,其中,wk≥0,且构造加权犹豫模糊元:
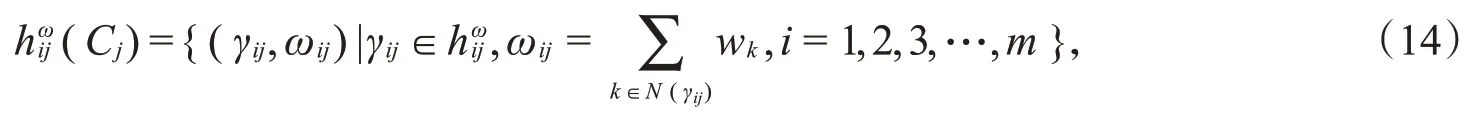
其中,N(γij)表示所有给出评估值γij的专家数。
Step2若两个加权犹豫模糊元中元素个数不同,则按照定义5添加元素并排序。
Step3根据计算期望矩阵D,再利用式(11)计算各属性的熵、式(12)计算各属性的权重。
Step4根据加权犹豫模糊集的Lance距离公式(5),计算每个备选方案与理想备选方案的距离。
Step5对每个备选方案与理想备选方案的距离进行排序,选出最优的备选方案。
3 算例分析
例2流感疫苗可以有效减少接种者感染流感的几率或减轻流感症状,是预防和控制流感的主要措施之一。在注射疫苗时会考虑诸多因素,医院对于流感疫苗供应商的选择就显得至关重要。下面从影响流感疫苗安全性、稳定性的因素中选择4个作为属性集C={C1,C2,C3,C4},其中,C1:工艺过程;C2:原料制造;C3:制剂;C4:贮存和运输。邀请4位流感疫苗专家对3家疫苗供货商进行综合评估,如表1所示。

表1 疫苗供货商的评价信息
情形1专家权重未知的情形。
Step1构造加权犹豫模糊元,如表2所示。
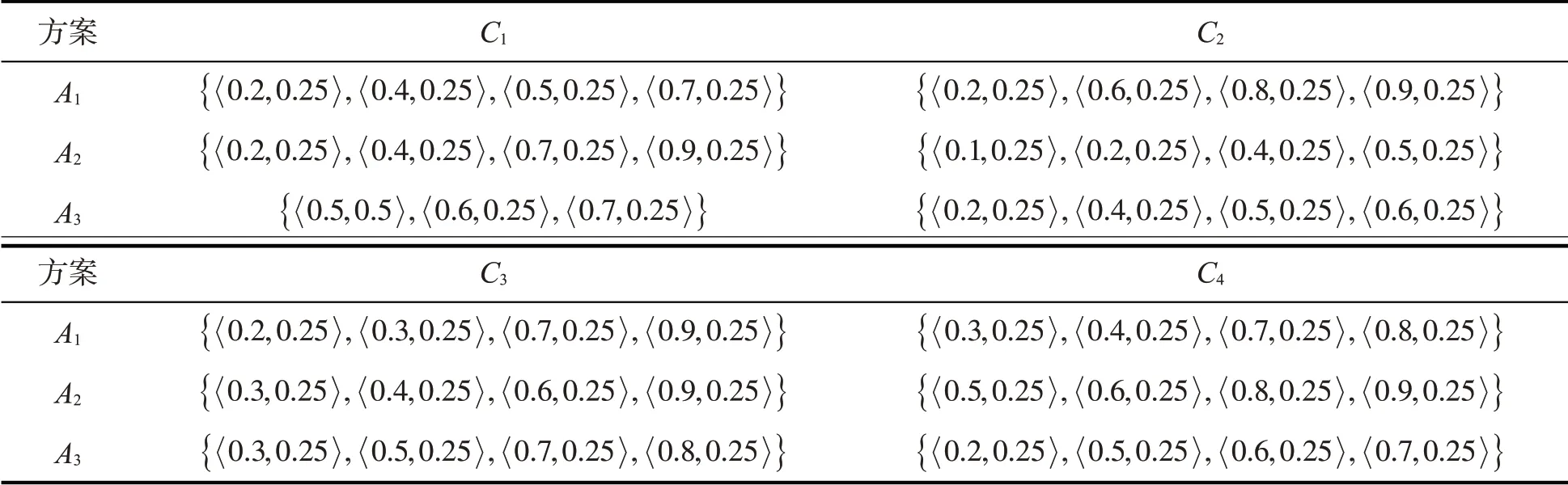
表2 加权犹豫决策矩阵元素值
Step2添加最大的元素并排序,得到表3。

表3 修正的加权犹豫决策矩阵元素值
Step3计算相应的期望矩阵,见表4。
根据式(11)计算各个属性需求的熵值:e1=0.995 1,e2=0.959 9,e3=0.999 4,e4=0.990 5。进一步,根据式(12)计算各属性需求的权重w1=0.088 9,w2=0.727 8,w3=0.010 9,w4=0.172 4。
Step4由表3,得到理想方案为
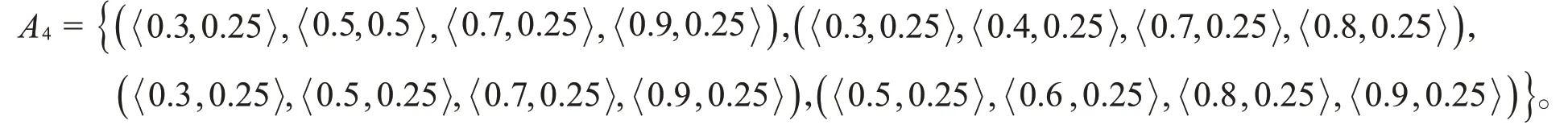
根据加权犹豫模糊集的Lance距离公式(5),计算每个备选方案与理想方案的距离:
Step5按照d的大小,得到备选方案的排序:A2≻A3≻A1,从而最佳选择方案为A1。
情形2专家权重已知的情形,假设专家的权重δ=(0.35,0.25,0.2,0.2)T。
Step1构造加权犹豫模糊元,如表5所示。

表5 加权犹豫决策矩阵元素值
Step2添加最大的元素并排序,得到表6。
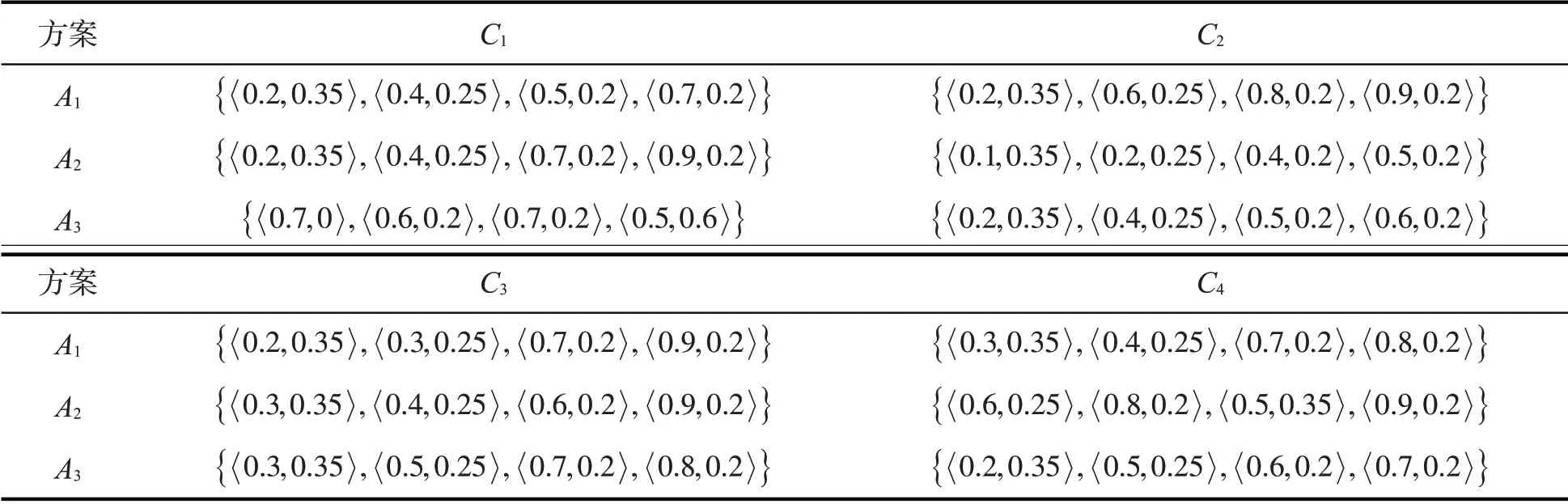
表6 修正的加权犹豫决策矩阵元素值
Step3计算相应的期望矩阵,见表7。

表7 期望决策矩阵元素值
由式(11)计算各个属性需求的熵值:e1=0.992 7,e2=0.959 3,e3=0.998 7,e4=0.987 9。再根据式(12)计算各属性需求的权重:w1=0.118 9,w2=0.662 9,w3=0.0212,w4=0.197 1。
Step4由表6,得到理想方案为
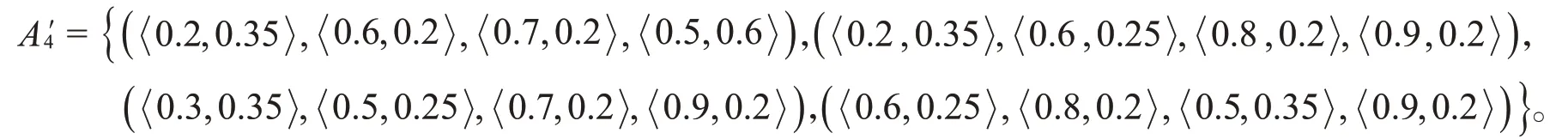
根据加权犹豫模糊集的Lance距离公式(5),计算每个备选方案与理想方案的距离:
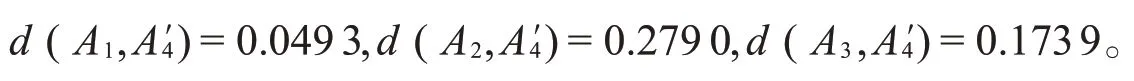
Step5按照d的大小,得到备选方案的排序:A2≻A3≻A1,从而最佳选择方案为A1。
比较分析:计算标准的Euclidean距离[12]和标准的Lance距离[13],并取相同的属性权重向量w=(0.118 9,0.662 9,0.0212,0.197 1)T,结果对比如表8和图1所示。
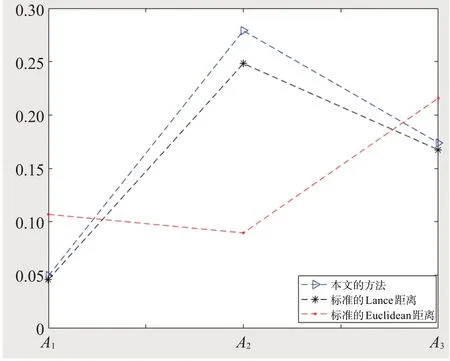
图1 综合评价对比
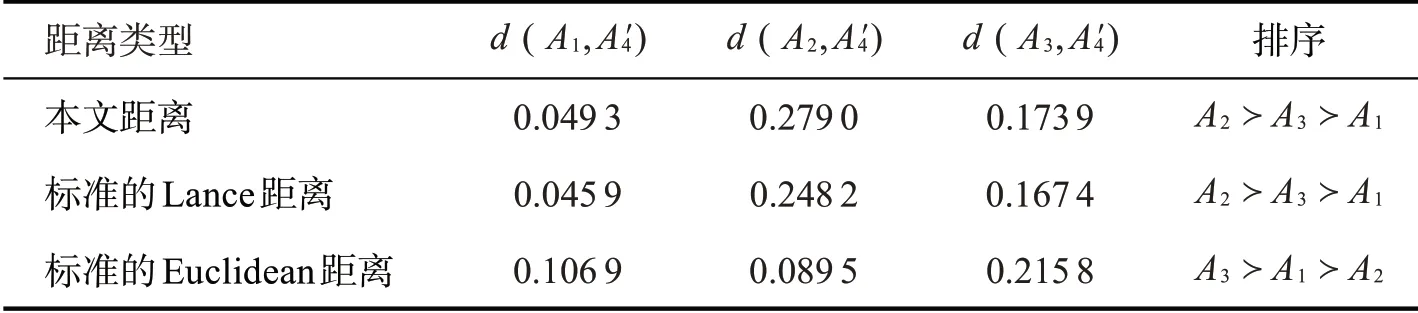
表8 三种距离结果对比
根据表8可以得到以下结论。
(1)与标准的Lance距离相比,距离的排序和最终选择的供货商都与本文计算结果相同,这充分说明本文提出的加权犹豫模糊集的Lance距离是有效的。从例1的分析来看,两个加权犹豫模糊集之间相差比较大,而本文提出的对于每个犹豫模糊集的犹豫模糊元赋予一定的权重,在一定程度上保留了原始信息,适用性更广,在处理多属性群决策问题方面更加灵活。
(2)与标准的Euclidean距离相比,流感疫苗供货商的最终选择和排序都与本文结果有差别。从原始数据来看,方案A1优于方案A2,这也说明本文考虑给犹豫模糊集的犹豫模糊元赋予一定的权重,能够更好地保留数据的原始信息,使计算结果更加合理。
4 结论
在多属性群决策过程中,需要考虑对给定的犹豫模糊集中犹豫模糊元赋予不同的权重,于是提出了加权犹豫模糊集的Lance距离,进一步利用加权犹豫模糊集的熵公式,给出了属性信息权重的确定模型,并结合专家权重已知和未知的情况,给出了加权犹豫模糊集Lance距离的TOPSIS方法以及生成算法。最后,通过流感疫苗供货商的选择问题,将本文所提的距离公式与现有部分距离公式的计算结果进行比较分析,进而验证了本文方法的可行性和有效性,完善了犹豫模糊集的测度理论。
猜你喜欢
西北大学学报(自然科学版)(2022年4期)2022-08-10
湖北大学学报(自然科学版)(2022年1期)2022-01-05
名家名作(2021年4期)2021-05-12
科学与财富(2021年33期)2021-05-10
价值工程(2020年19期)2020-07-23
价值工程(2020年19期)2020-07-23
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
青年与社会(2017年24期)2017-08-10
中国经贸(2017年10期)2017-06-09
