
基于最小边集的De Bruijn图定位算法
2022-03-08 08:25于长永金建宇赵宇海
东北大学学报(自然科学版) 2022年2期
于长永, 金建宇, 刘 鹏, 赵宇海
(东北大学 计算机科学与工程学院, 辽宁 沈阳 110169)
DBG(de Bruijn图)是生物信息学中最有用的数据结构之一,例如,DBG最初用于组装数十亿个短基因组序列[1-2],DBG也被用于其他领域,如基因组序列比对[3-6],在人群中发现基因多样性[7-8],预测细菌的毒性[9],以及检测共线性块[4].
近年来,由于DBG具有能够处理基因组重复区域[10-11]的特性,而基因组的高度重复问题也是目前大多数现有方法的瓶颈,因此DBG常用于处理基因组序列.对于基于FM-index的方法,高重复的子字符串可能会导致后缀的定位过程耗时较长;对于基于gram的方法,由于存在过滤失败的情况,高度重复的子字符串可能会造成候选集较大.为了避免重复子字符串的影响,提出了很多种子选择方法,以OSS[10]为例,将频率最小的种子定义为最优种子,提出一种求解种子选择问题的动态规划算法.此外,在文献[11]中,用DBG处理参考序列重复引起的问题,但忽略了其他信息,如分支节点和由分支节点组成的路径.DeBGA是一个功能强大的映射器,但它可能会丢失由DBG模型中的分支节点和路径表示的映射位置.
DBG的一个重要特性是,参考序列的每个子字符串都是图上的路径,但并非所有DBG上的路径都是参考序列子字符串.如果一个路径是参考序列的子字符串,则称它为真路径,否则为假路径.DBG模型不仅可以对参考序列进行索引,还可以在参考序列上定位图的每条边和路径.近年来有关DBG的研究主要集中在图的索引和快速构建方面.例如,文献[12-13]提出了有效构造DBG的方法,文献[14]提出了一种时间和空间友好的压缩染色DBG的索引方法,文献[15]提出了一个DBG的紧凑表示,它允许无限数量的节点和边的增加和删除.然而,关于在参考序列上定位DBG的节点、边和路径的方法却很少.文献[16]提出了一种新的图数据组装结构,称为连接的de Bruijn图(LdBG),但该模型不能用于定位参考序列上的路径,显然也无法存储所有边的位置列表.
本文提出了一种DBG模型,称为MiniDBG,可以用于在read-mapping中索引参考序列.该模型存储了最小边集的位置列表.有了位置列表,MiniDBG可以有效地定位任何边、节点和路径.实验结果表明,MiniDBG能有效地在参考序列上定位边和路径,且存储成本较低.
1 基础知识
X为字母表Σ={A,C,G,T}上的基因组参考序列,A,C,G,T是生物学DNA中的四种碱基.X长度用|X|来表示.X[i]表示X上的第i个字符.索引从1开始,用X[i,j]表示X上从i到j的子字符串,X的前缀和后缀由X[*,i]和X[i,*]来表示.给定一个参考序列X和子字符串k-mer,k-mer是基因组参考序列X中长度为k的字符串,用DBG(X,k)来表示X的 de Bruijn图:
V={vi|vi是k-mer并且vi是X上的字符串};
E={eij|vi[k-1,*]=vj[*,k-1],|pij|≠0};
P={pij|pij=list(eij)}.
其中V,E,P分别为图的顶点集合、边集合和位置列表集合.集合V由序列X上出现的一系列长度为k的字符串组成.eij是一条从vi到vj并且满足vi[k-1,*]=vj[*,k-1]的边,并且|pij|≠0.pij是eij的位置列表(将eij看作X上长度为k+1的子字符串),能够按照从前到后的顺序保存eij在X上出现的位置.|pij|表示pij的长度.
给定参考序列X和整数k,找到边的位置列表的集合,用Pmin表示,并需要满足以下条件:
①DBG′(X,k)=(V,E,Pmin)可以通过Pmin的位置列表的并集定位每一条边;
②对于任意的P′⊂Pmin,DBG″(X,k)=(V,E,P′)不能满足条件1.
DBG′(X,k)=(V,E,Pmin)为参考序列X上字符串长度为k的MiniDBG.
2 路径定位算法
2.1 MiniDBG模型
MiniDBG是传统DBG的一种压缩存储形态,通过对分支、非分支节点进行区分,找到图中的超级边,以及超级边所对应的最小边,最终生成最小边的位置列表.对最小边及最小边位置列表进行存储,从而实现传统DBG的压缩存储.
定义1(非分支节点、单路径):
如果DBG(X,k)上的一个顶点vi满足:入度与出度相等且为1,则vi被称为非分枝节点,否则为分支节点.对于一个DBG(X,k)上的一条路径h=vi1vi2…vik,如果其每个节点都是非分支节点,则称之为单路径.如果vi的入度不为1,则称vi为入分支节点;如果vi的出度不为1,则称vi为出分支节点.对于一条边eij,如果vi是出分支节点,则eij为一条出边.
假设边a和b是相邻的,a为节点的入边,b为节点的出边,相邻边位置的关系分为4种:
①a是非分支入边,b是非分支出边;
②a是非分支入边,b是分支出边;
③a是分支入边,b是非分支出边;
④a是分支入边,b是分支出边.
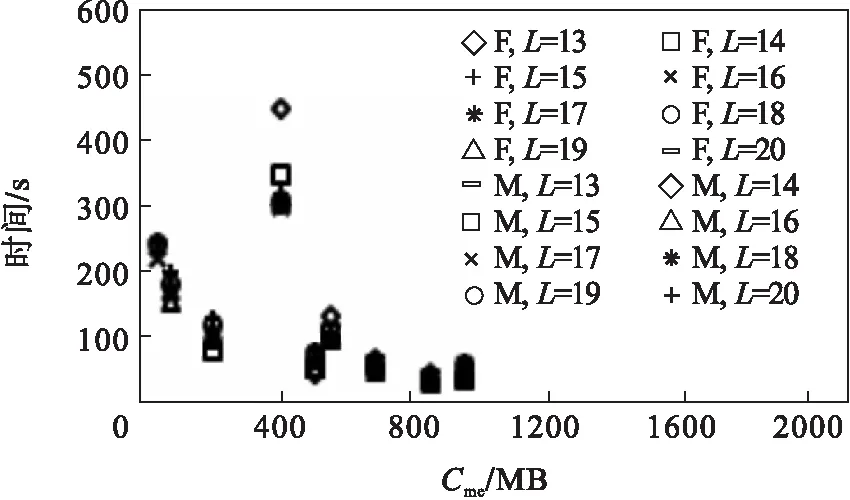
用a=b,a>b,a 定义2(超级边): 在移位操作下,超级边内各边的位置列表相同,因此将超级边的位置列表定义为其第一条边的位置列表: 在某些情况下,边的超级边仍然是它本身.因为超级边上的边的位置列表彼此是等价的,超级边的位置列表可以表示超级边上所有的边.为了消除超级边中等价位置列表的影响,DBG可以看作是一个新的图,称为super-DBG,它由分支节点和超级边组成. 表1 四种邻接边的关系 算法1给出了超级边的生成过程.T表示用于保存结果的节点列表,第2~6行为向右扩展边缘的过程,直至到达分支节点.同样,第7~11行向左扩展边缘,直至到达分支节点.T在扩容过程中按顺序依次保存节点. 算法1 生成给定边的超级边Gen_super_edge(ei0j0): 输入: 图DBG(X,k)=(V,E), 一条边ei0j0; 1:T=∅;k=0;l=0; 2: while 1 3: insertvjkintoTat the tail termination; 4: ifvjkis branching 5: break; 6:vjk+1=vjk.successor();k++; 7:while 1 8: insertvilintoTat the head termination; 9: ifvilis branching 10: break; 11:vil+1=vik.precursor();l++; 12: ReturnT. 定义3(最小超级边): 算法2描述了基于MiniDBG模型计算一条边的位置列表的过程.第3~4行对应于输入边的超级边是最小超级边的情况(Δ为偏移量),超级边中第一条边的位置列表保存在MiniDBG模型中.第5~18行对应输入边的超级边不是最小超级边的情况;这里分两种情况:①超级边从入分支节点开始;②超级边在出分支节点结束.其中El-表示从顶点l出发的边的集合,E-k表示在顶点k结束的边的集合. 显然,超级边可以从入分支节点开始,同时又在出分支节点结束.在这种情况下,位置列表可以通过情况①或②计算. 算法2 计算每条边的位置列表Gen_list(eij): 输入:图DBG(X,k)=(V,E,Pmin), 一条边eij; 输出:list(eij),其中list(eij)=Gen_list(eij); 1:list(eij)=∅; 5:else ifvlis out-branching 6: foreluinEl- 8: ifvyis in-branching 9: 10: else 11: list(eij)=list(eij)∪(Gen_list(elu)+Δ); 12:else ifvkis in-branching 13: foreukinE-k 15: ifvyis out-branching 17: else 18: list(eij)=list(eij)∪(Gen_list(euk)+Δ); 19: Return list(eij). 定理1DBG中的闭环路径示例如图1所示,对于一个闭环路径,在循环路径中至少存在一个入分支节点和一个出分支节点. 图1 DBG中的闭环路径 定理2将整条路径h=ei0i1ei1i2…ein-1in进行分割,得到路径片段hseg=eikik+1eik+1ik+2…eik+l-1ik+l,则有以下结论: ①∃q,k≤q≤k+l-1满足list(hseg)=list(eiqiq+1)-(q-k). ②eiqiq+1是最小超级边. ③hseg中除eiqiq+1之外没有任何边是最小超级边. 定理3 图DBG(X,k)上的路径h=ei0i1ei1i2…ein-1in一定满足以下结论: ①h可以用一个超级边序列等价地表示 ②路径上的边有相同的位置列表list(h)=list(h′); ③ 根据定理3可以推得基于MiniDBG模型的路径位置列表计算方法,如算法3所示.第1行,L=Ω表示结果位置列表,并初始化为一般集合.Rpre表示初始的边与当前的超级边之间的关系.类似地,Rcur表示当前超级边和下一条边之间的关系.l表示当前超级边的长度.Get_relationship(*,*)表示根据连接两条边的节点的类型获取两条相邻边之间的关系.第4~5行,算法跳过“=”关系,如果某一步骤后的交集为空,则算法返回的路径为假路径. 算法3 计算给定路径的位置列表: 输入:DBG(X,k)=(V,E,Pmin), 一路径 ei0i1ei1i2…ein-1in; 输出: list(ei0i1ei1i2…ein-1in); 1:L=Ω;Rpre=′′;Rcur=′?′;l=1; 2: for(k=0;k 3:Rpre=Rcur;k=k+l-1;l=1; 4: while(Rcur=Get_relationship(eik+lik+l+1,eik+l+1ik+l+2)=′=′) 5:l++; 6: ifRpre=′?′orRpre=′>′ 7: ifRcur=′?′orRcur=′<′ 8:L=L∩(list(eikik+1)-k); 9: ifL=∅ 10: returnL; 11:k=k+l-1; 12: ifRcur=′>′orRcur=′?′ 13:L=L∩(list(ein-1in)-n+1); 14: ReturnL. 为了定位一个点vi,MiniDBG方法必须定位从vi开始或在vi结束的边.然后结合所有边的位置生成节点vi的位置列表.定位节点比定位边花费更多的时间.然而,k为n+1的图上的节点列表相当于k取n的图上的边列表.因此,MiniDBG可以通过设置较小的k来减少定位所花费的时间. 对于边的定位,如果是一条最小边,MiniDBG将返回边的位置列表;对于非最小边,MiniDBG会生成一组最小边,并结合最小边位置列表得到原始边的位置列表.这个过程递归地调用定位边的方法,直到所有边都最小为止.对于路径,MiniDBG首先检查所有的节点和边是否在图上:如果不是,则返回空列表;否则,MiniDBG将使用定理3中的公式计算路径的位置列表.在此过程中,一旦获取的位置列表的交集为空,算法返回并且路径的位置列表为空.所有这些操作都是为了避免在定位假路径上浪费时间. 所有实验在一台搭载了4个Intel(R)Xeon(R)E5-2640 2.40 GHz CPU的服务器上完成,每个CPU有10个核心,服务器内存空间为160 GB ,并搭载了4台 NVDIA Tesla K40 显卡.操作系统为 Ubuntu 16.04.SHDex算法在eclipse中实现,并使用 C 和C++ 编程. 本文使用了以下数据集:从NCBI RefSeq数据库下载了所有的62E大肠杆菌菌株数据[17](http://www. ncbi. nlm. nih. gov/refseq/),选取其中之一称为 D1数据集;62E中全部数据集称为D2;文献[12]中引用的人类基因组数据在本文中被用作数据样本D3. k-mer长度为k的顶点对应的图和k-mer长度为k-1的边对应的图是一样的;因此,MiniDBG可以设置较小的k-mer长度.对于FM-index,当后缀数组间隔为空时,路径为假路径,定位过程结束. 测试MiniDBG在增加查询长度的同时定位字符串的性能.当字符串长度L增加时,查找子字符串的时间开销Cme增加.结果如图2所示.MiniDBG的内存开销非常小.随着字符串长度L的增加,MiniDBG耗费了可接受的时间来定位这些字符串.在图2c中,随着查询子字符串长度L的增加,时间成本增加得非常缓慢. 图3~图5为在数据集D1,D2和D3上定位子字符串的时间开销,图例中F和M分别代表FM-index和MiniDBG.查找子字符串是由参考序列上的滑动窗口生成的.查询总数为5 521 840,图中显示了定位查找子字符串的总时间开销.对于FM-index,查找的子字符中长度分别从9/10/15到17/20/23.对于MiniDBG,查找的子字符串长度从k+1到k+9,参数k分别为9/10/19 到 14/15/21. 从实验结果中得到如下结论: 1) 对于非频繁查询(特别是在参考序列上只出现一次的查询),FM-index比MiniDBG效率更高,如图3所示.对于在参考序列上出现超过10次的频繁查询,MiniDBG的效率更高,如图4所示,这是因为FM-index和MiniDBG的工作方式不同.FM-index首先计算查找字符串的后缀数组间隔,然后针对间隔内的每个索引计算后缀数组的值;因此,间隔越大,花费的时间就越多.对于MiniDBG,它可以一次性获得所有位置,而不像FM-index需要依次计算每个后缀数组. 2) MiniDBG在字符串定位时比FM-index更灵活.在原子串上增加一个字符的定位问题中,FM-index 需要重新计算后缀数组的所有值.例如,给定“CGT”的位置,只添加一个基数的“ACGT”或“CGTA”的位置必须重新计算得出;而对于MiniDBG,只需要添加一条边,可以通过将新边的列表与原始列表合并来计算. 图2 子字符串长度增加时查找子字符串的时间成本 3) MiniDBG查找字符串的时间开销比FM-index更低,即使它比FM-index占用更少的内存.如图4所示,在数据集D2上,FM-index在需要566 MB内存的情况下,耗费104,94和 94 s 来分别定位长度为14,15和16的字符串;而MiniDBG能够分别使用519,221和221 MB内存进行同样的查询操作,分别只需要41,76和93 s.如图5所示,在数据集D3上,FM-index使用5 GB的内存,在2 150,1 715,1 396和1 132 s内定位长度为20,21,22,23的字符串;而MiniDBG分别使用3.6,3,3和3 GB的内存进行相同的查询操作,仅需515,955,900和902 s. 图3 在数据集D1上定位子字符串的时间开销 图4 在数据集D2上定位子字符串的时间开销 图5 在数据集D3上定位子字符串的时间开销 本文提出了MiniDBG模型,用于存储最小边位置列表,以便在参考序列上定位图的边和路径,并给出了基于MiniDBG模型的路径定位算法.讨论了k-mer长度增加时位置列表所占内存的大小.通过实验验证了模型和算法的有效性.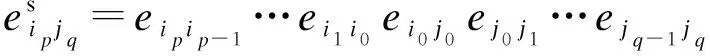

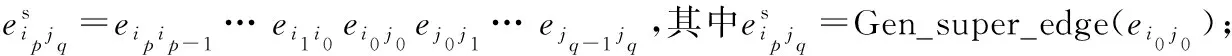


2.2 MiniDBG路径定位算法
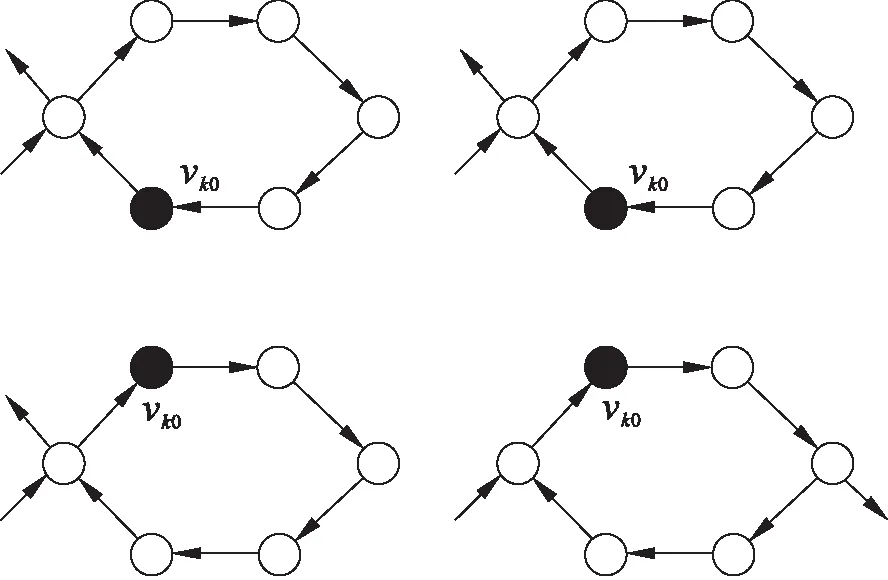
3 实验结果



4 结 语
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29计算机系统应用(2021年10期)2022-01-06课堂内外(初中版)(2020年5期)2020-06-19上海师范大学学报·自然科学版(2018年3期)2018-05-14数字技术与应用(2017年3期)2017-05-17中学生数理化·教与学(2017年4期)2017-04-22科教导刊·电子版(2016年30期)2016-12-26中国新通信(2016年17期)2016-11-17中国信息技术教育(2015年21期)2015-09-10中学生数理化·中考版(2015年10期)2015-09-10
