
含抑制剂体系下天然气水合物形成预测模型的建立与应用
2022-03-08 06:20徐小虎方惠军王创业王海深
天然气化工—C1化学与化工 2022年1期
徐小虎,方惠军,王创业,高 洁,王海深
(1. 中国石油煤层气有限责任公司,北京 100013;2. 中联煤层气国家工程研究中心有限责任公司,北京 100013;3. 中国石油物资有限公司,北京 100029)
在深水油气田开发过程中,高压低温的环境极易使天然气生成水合物。油气混合物中充足的水分子与天然气分子接触,水分子颗粒形成的晶格状氢键将气体分子困在其内,宏观表现为形成冰晶状结构,即笼形天然气水合物。形成的天然气水合物在不断生长、聚集、着床及沉积,水合物生成量达到一定程度会严重影响油气田的生产安全[1-3]。在实际生产中,天然气水合物带来的问题需要的解决时间较长,期间无法进行正常的生产活动,从而带来较大的间接经济损失。研究天然气水合物的形成解离模型可及时预测管道内天然气的存在状态,对保障安全高效生产具有重要意义,同时可为天然气水合物的生长和沉积模型提供理论依据[4,5]。
1941年至1945年,Katz等[6,7]采用图表技术建立了基于气体重力法的低硫天然气水合物预测模型。Ghiasi[8]、Bahadori等[9]、Towler等[10]分别对Katz所建立的模型进行了修正。1949至1954年,Katz与其他学者合作[11-13]建立了基于气固平衡系数的水合物解离预测模型。其中,平衡系数依据经验选取,降低了模型的精确性。建立该模型的基础假设为N2不参与水合物的形成,n-C4和乙烷具有相同的气固平衡系数(KVS)。这些假设显然不成立,因此,该模型的精度较低,适用范围受限。1959年,Waals[14]建立了统计热力学方法,成为天然气水合物预测模型的理论基础。在1966年至1980年,Dharmawardhana等[15]和Ng等[16]分别对Waals的统计热力学方法进行了改进以建立天然气水合物形成的预测模型,但这些模型仅适用于介质为纯水的情况。对于单一组分的纯气体,1981年,Makogon[17]建立了纯气体的水合物经验模型。1987年,Ballie等[18]借鉴Katz所建立的图表模型,建立了适用于酸性气体的另一种图表方法。2000年至2004年,Nasrifar等[19]考虑van der Waals提出的固体在水中溶解的概念,对天然气水合物模型进行了改进,使其可应用于水中存在热力学抑制剂的情况,但需要的基础参数较多,计算复杂程度较高。2009年至2015年,Zahedi等[20]和Zarenezhad等[21]建立了基于Back Propagation Neral Network(以下简称“BP神经网络”)模型的天然气水合物预测模型,该模型具有较高的预测精度,说明智能方法在天然气水合物预测方面具有较为出色的表现。但由于BP神经网络模型的理论基础是环境资源管理(Environmental Resources Management,ERM)传统统计方法,因此其稳定性较低,网络结构参数较难确定,易出现局部过优的情况。如果基础的样本数据较少,学习机器泛化能力也会随之降低。天然气水合物形成预测研究多集中在基础介质为纯天然气体系,通常不适用于含热力学抑制剂体系,且计算结果波动较大,稳定性较低[22-28]。2016年至2021年,马贵阳等[29]将遗传算法与支持向量机相结合建立了水合物相平衡预测模型,但其研究仅限于单一天然气和无添加剂的体系,适用范围受限。闫枭[30]和郑秋梅等[31]分别建立了天然气水合物生成支持向量机(Support Vector Machine,SVM)预测模型,并将其与深度神经网络等其他模型进行了对比分析,虽然预测精度有所提高,但SVM算法复杂程度仍然较高。郭平等[32]和王海秀[33]对天然气水合物生成模型的研究进展进行了总结分析,提出基于智能算法的天然气水合物形成预测模型近年发展较快,预测精度较高,取得了良好的应用效果,其中含热力学抑制剂等多元复杂体系为今后研究的重点。
天然气水合物图表技术预测模型精度较低,热力学模型参数繁多,计算复杂,智能模型中BP神经网络智能算法稳定性低。基于粒子群算法的最小二乘支持向量机(Particle Swarm Optimization-Least Square Support Vector Machine,PSO-LSSVM)模型相对于SVM模型而言,复杂程度有所降低,学习泛化能力较高。其理论基础是ERM模型的近似实现,在非线性、数据样本有限和维度较高的问题上具有较好的性能,且PSO算法可较精确且相对简单地确定LSSVM的超参数。PSO-LSSVM模型与BP神经网络智能算法的理论基础均为ERM理论,基于BP神经网络智能算法在天然气水合物预测的出色表现,为解决算法稳定性低、参数难以确定和适用范围局限于纯天然气体系的问题,本文以荔湾气田现场注醇工艺为依托,借鉴机器学习算法,建立了基于PSO-LSSVM模型的含热力学抑制剂天然气水合物形成预测模型,与BP神经网络模型模拟结果进行对比分析,并在荔湾气田现场管道进行预测应用。
1 模型的建立
1.1 实验数据库的建立
模型的可靠性和准确度在很大程度上依赖于其所使用数据库的优越性与普遍性。为提高模型的可信度及适用范围,建立了包含超过1500个实验数据点的广泛数据库。数据库覆盖了从1941年至2018年在国际著名期刊所发表的文献,涉及纯水及含热力学抑制剂的溶液与不同组分的天然气所形成的水合物,含括溶液-天然气-水合物等多相态油气水系统,广泛数据库中气液组分及温度压力范围如表1所示,部分实验数据参数如表2 所示,具体数据如图1 所示。利用广泛数据库内的实验数据作为基础变量输入PSO-LSSVM模型中,从而确定模型的核参数和正则化参数等,将建立的模型应用至荔湾气田现场管道,预测其水合物生成的温度和压力等条件。

图1 广泛数据库Fig. 1 Extensive database

表1 广泛数据库参数范围Table 1 Range of extensive database parameters
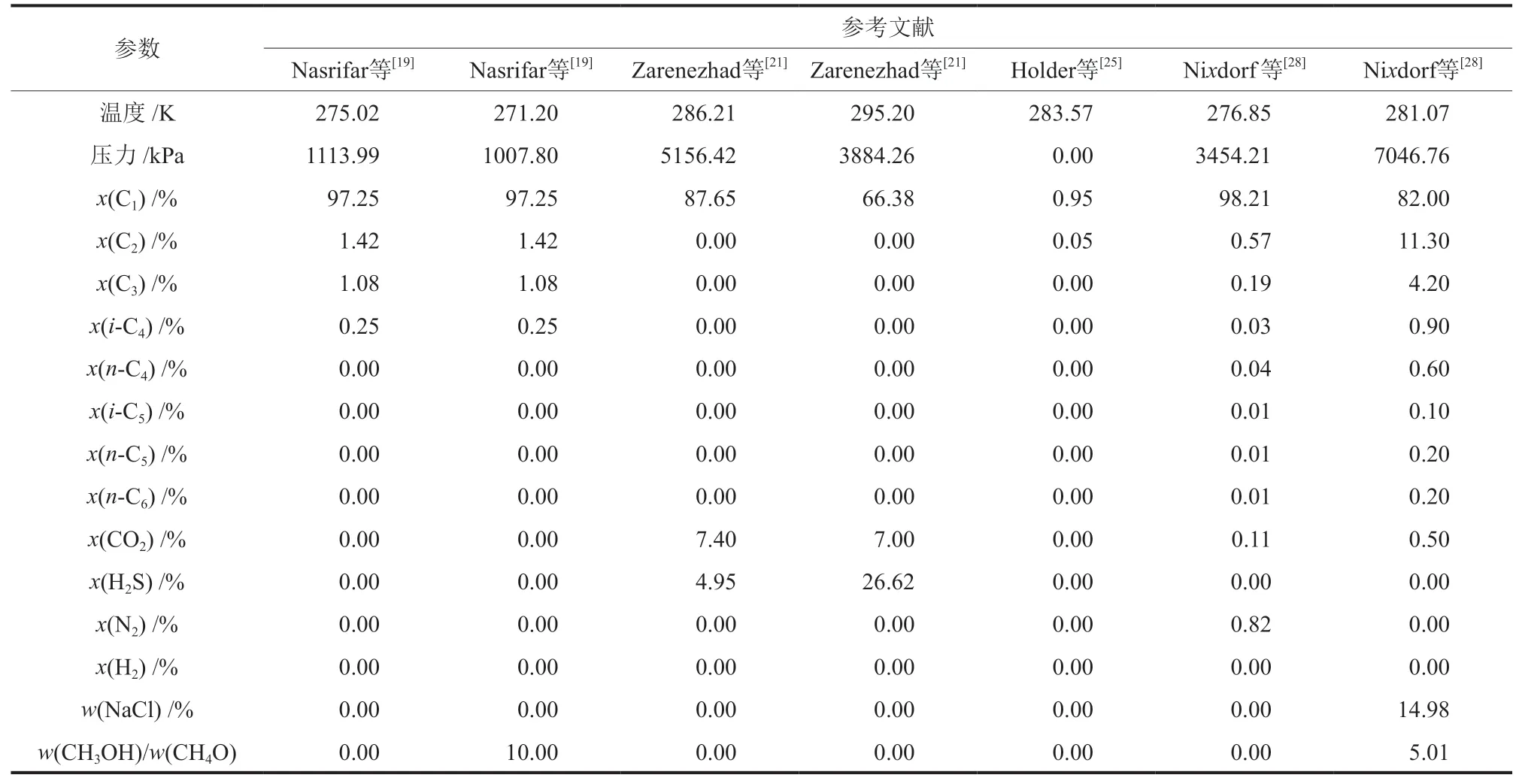
表2 广泛数据库中部分实验数据参数Table 2 Some experimental data parameters in extensive database
1.2 模型设计思路
本研究以广泛数据库作为样本支撑,建立了基于PSO-LSSVM模型的含热力学抑制剂天然气水合物形成预测模型,并将其应用至荔湾气田现场注醇管道。模型建立过程为:首先分析含热力学抑制剂天然气水合物的平衡特点及形成影响因素[34],即天然气水合物组分和热力学抑制剂种类及类型,确定LSSVM的输入变量为热力学抑制剂种类及类型和天然气水合物组分及压力,输出变量为天然气水合物形成温度。根据不同类型的核函数特点,选取径向基函数(Radial Basis Function,RBF)作为该模型的核函数,其可以削弱过滤样本数据中的噪声且具有较强的局部性和抗干扰能力。建立LSSVM模型后,基于Matlab编程,利用训练样本对模型进行模拟训练,确定模型中各参数的取值。采用PSO算法对LSSVM模型的核参数与正则化参数进行优化。技术路线如图2所示。
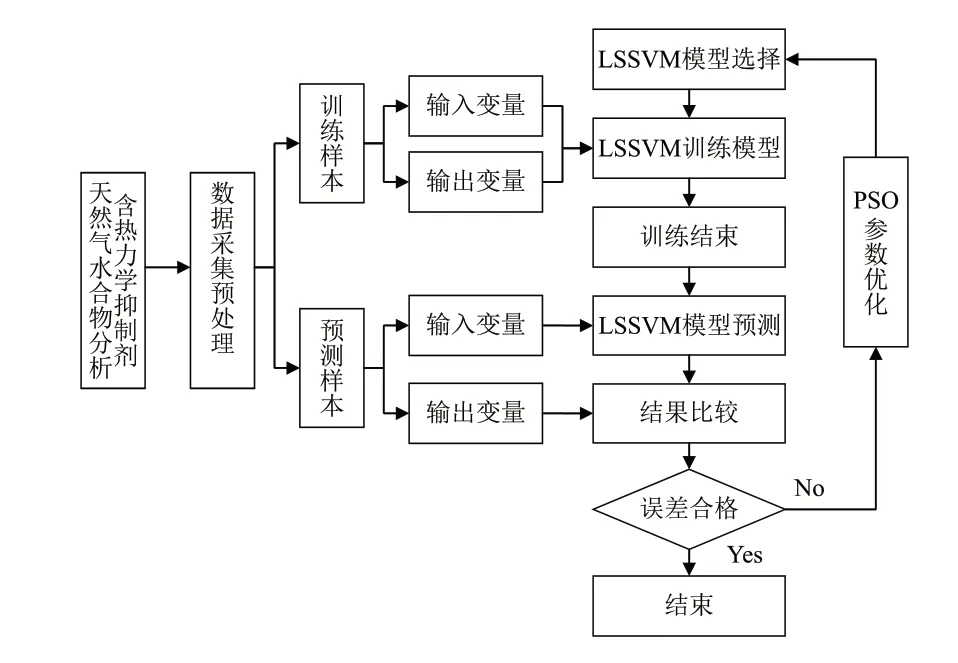
图2 PSO-LSSVM模型的技术路线Fig. 2 Technical route of PSO-LSSVM model
1.3 模型的前期处理
采用最大最小法对实验数据进行归一化处理,有利于提高算法的精准度(xi),如式(1)所示。
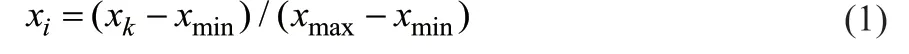
式中,xk为影响天然气水合物形成的某种因素,为处理前的数据,k代表某种影响因素,k= 1时为第1种影响因素,如C1含量,k= 2时为第2种影响因素,如C2含量;xi为影响天然气水合物形成的某种因素,为处理后的数据,i代表某种影响因素,i= 1时为第1种影响因素,如C1含量,i= 2时为第2种影响因素,如C2含量;xmin为实验数据中的最小值,xmax为实验数据中的最大值。
荔湾气田输气管道为气液两相流,水合物的形成主要与组分、压力和温度有关。将天然气组分、液态组分及压力作为模型的输入变量,形成天然气水合物的温度作为模型的输出变量。
苹果树适宜在年平均温度8~12摄氏度的地区栽植。贵州苹果主要集中在威宁县和长顺县种植。威宁县境内海拔1 800~2 200米的区域大多能满足苹果栽培的气候条件,长顺县苹果种植建议选择海拔1 200米以上区域种植。园地周边5公里无污染源,适合优质鲜食苹果生产生态指标,土壤较肥沃,有灌溉水源,交通便捷,通讯良好。
1.4 核函数的建立
核函数和参数的选取在一定程度上影响所建模型的精确度。荔湾气田输气采用注醇工艺,由于含热力学抑制剂天然气水合物的形成预测为非线性问题,因此,选用高斯核函数为建模基础。高斯核函数属于局部核函数,对实验数据中的噪声具有较强的筛选能力,如式(2)所示。
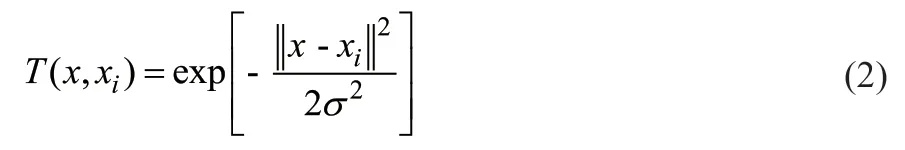
式中,T为天然气水合物的形成温度,K;x为影响天然气水合物形成的因素;σ为高斯函数的核参数。
引入含热力学抑制剂的水溶液对天然气水合物形成的影响,将热力学抑制剂质量分数与目标函数相关联,如式(3)所示。

式中,p为形成天然气水合物的压力,kPa;C为热力学抑制剂的质量分数,%;Z为气体组分的物质的量分数,%。
1.5 LSSVM模型的建立
设给定N个训练数据样本 ,其中,
为m维的数据样本输入, 为样本输出。将广泛数据库中70%的数据作为训练数据,30%的数据作为测试数据,采用随机抽样的方式划分训练样本和测试样本。LSSVM算法的优化如式(4)和式(5)所示。
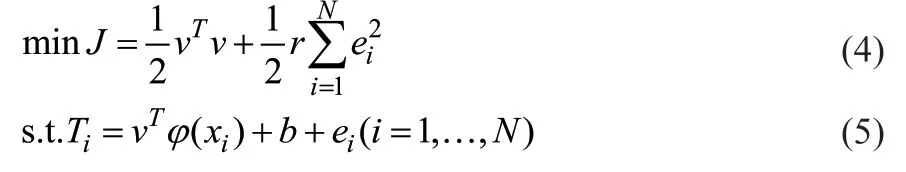
式中,s.t.的全称为subject to,中文含义为受限制于;min与s.t.联合使用的数学含义为在满足式(5)的前提条件下使式(4)中的目标函数J达到最小;φ(·):Rm→Rmf为从原空间到高维空间的映射函数;
根据目标函数和约束条件,建立拉格朗日函数并经过计算转换最终得到水合物形成温度的最优决策函数,如式(6)所示。

式中,K为拉格朗日函数;ai为拉格朗日因子;b为偏置量。
1.6 PSO算法优化LSSVM模型参数
在PSO中建立一个粒子种群,包含了各粒子的初始值,c1、c2取值为1.4959,种群数量N取值为30,迭代次数G最大值设定为300,惯性权重v取值设定为0.9。针对种群中的各个粒子,基于其所对应的实验数据,利用LSSVM模型计算各粒子所对应的位置值及误差,并将各粒子所对应的误差作为其适应度值。优选比较粒子本身的适应度值和目前位置的适应度值,将粒子适应度最优值所对应的位置作为当前位置,进而比较粒子的适应度最优值及种群的适应度最优值。若粒子的适应度最优值更优,则将粒子目前的位置作为种群的最优位置,并更新粒子的速度与位置,如式(7)和式(8)所示。当满足终止条件时,则输出此时的LSSVM参数值。

式中,c1、c2为常数,取值为1.4959; 和 为速度限制; 和 为位置限制;r1和r2为[0,1]区间内的一个随机数; 为直到第k次迭代微粒个体最优位置;为第k次迭代的输入值,即LSSVM模型的超参数,如核参数、正则化参数; 为直到第k次迭代整个群体的最好位置。
2 模拟结果分析
2.1 模型误差分析
根 据Zahedi等[20]和Zarenezhad等[21]的研 究 可知,BP神经网络天然气水合物预测模型具有较为出色的表现,但存在算法稳定性低且参数难以确定的问题。为测试PSO-LSSVM模型的计算精度和预测性能,建立了神经网络模型,并与该模型进行了对比分析。由于关于天然气水合物神经网络模型的研究较多,建模过程此处不再赘述。本文基于灵敏度分析,采用PSO算法优化LSSVM模型的超参数,得到核参数的值为1.0210368871948,正则化参数的值为321.1523642521。以压力数据作为输入参数,利用所建模型计算水合物形成温度,计算结果与实验结果进行比较,得到模型的计算误差,如图3所示。
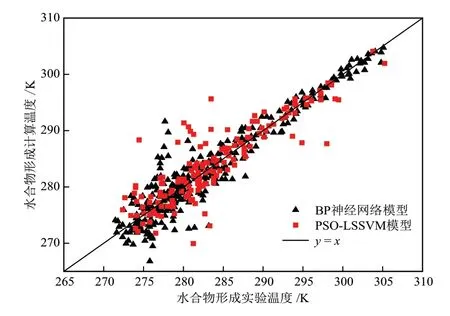
图3 模型的数据误差Fig. 3 Model data error
由图3可知,统计误差数据得出平均相对误差(Average Absolute Relative Deviation,AARD,%):
PSO-LSSVM模型为0.49%,具有更高的预测精度,而BP神经网络模型为1.92%;平均绝对误差(Average Absolute Deviation,AAD,%):PSO-LSSVM模型为0.04%,模拟数据更加均匀地分布在实验曲线两侧,而BP神经网络模型为0.13%。
统计模拟数据的误差分布规律,可得到PSOLSSVM模型和BP神经网络模型的相对误差分布图,如图4和图5所示。确度的指标,PSO-LSSVM模型相对误差的最大值为4.47%,最小值为0.03%。而BP神经网络模型相对误差的最大值为6.37%,最小值为0.06%,说明PSO-LSSVM模型具有更高的预测稳定性。
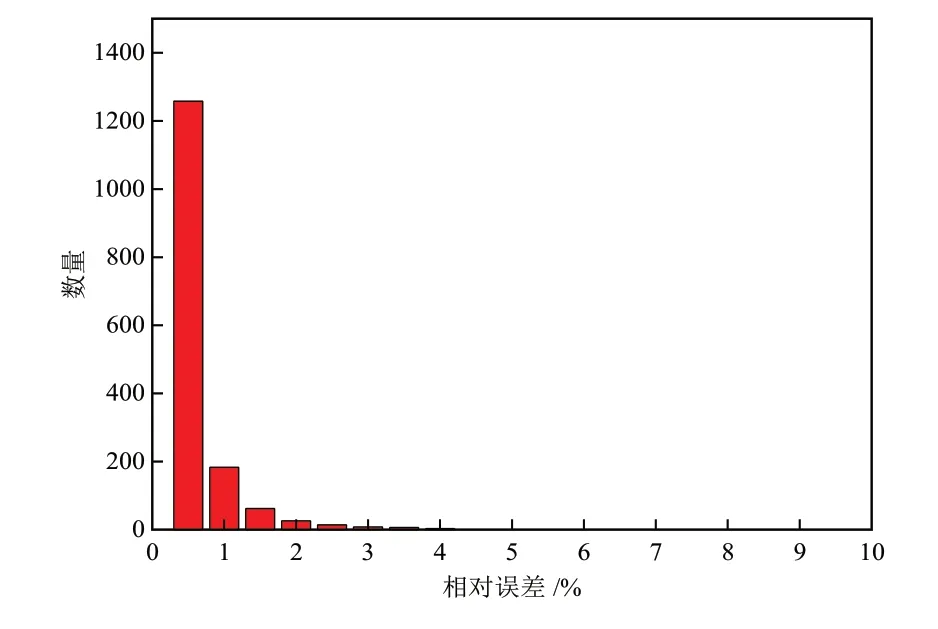
图4 PSO-LSSVM模型模拟误差分布Fig. 4 Simulation error distribution of PSO-LSSVM model
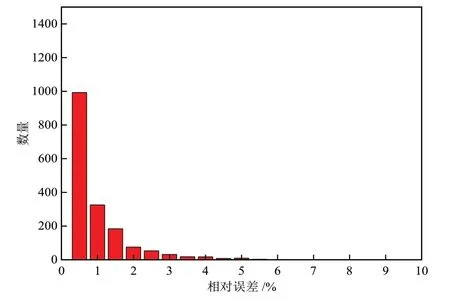
图5 BP神经网络模型模拟误差分布Fig. 5 Simulation error distribution of BP Neral Network model
2.2 纯水存在下天然气水合物形成预测
PSO-LSSVM模型的相对误差主要分布在0%~1%之间,在大于1%的误差区间内数据较少。虽然BP神经网络模型的相对误差亦主要分布在0%~1%之间,但在大于1%的误差区间内数据个数明显多于PSO-LSSVM模型的数据个数。因此,PSO-LSSVM模型具有更强的预测能力。此外,相对误差范围亦是评价模型精
由于荔湾气田部分管道未注入甲醇,因此,首先分析不同气体组分下天然气与纯水形成的水合物曲线,如图6所示,其中各气体组分组成如表3所示。PSO-LSSVM模型与实验数据[28]具有更高的吻合度,且波动较小,说明PSO-LSSVM模型的超参数选取较合理,可有效地预测纯水存在下形成天然气水合物的温度。BP神经网络模型在部分数据点具有较优的预测性能,但在其他数据点预测精度较低,预测曲线波动较大,这是BP神经网络模型过度学习而陷入局部极小值所造成的。
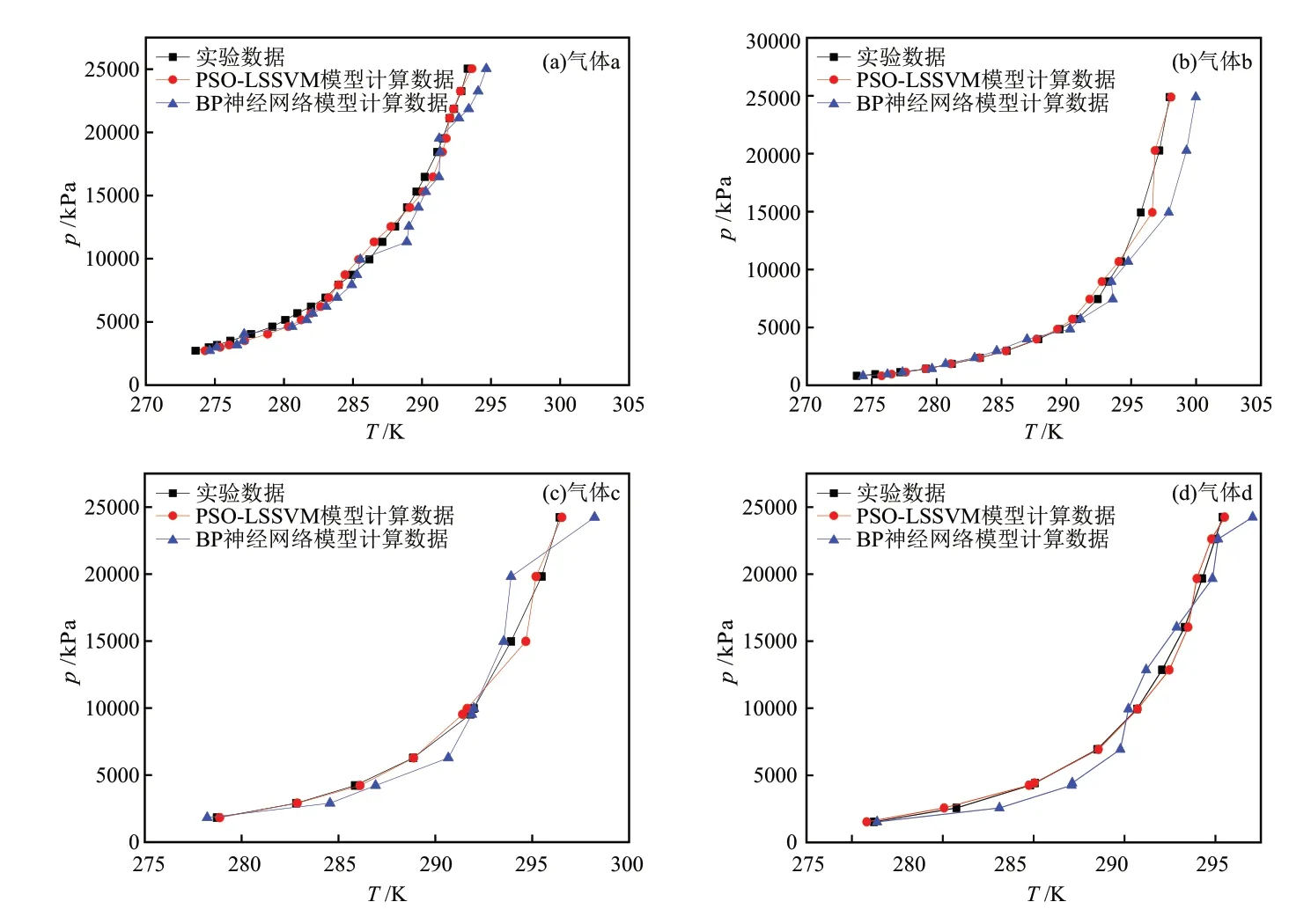
图6 纯水与不同气体组成天然气形成水合物的预测结果Fig. 6 Prediction results of hydrate formed by pure water and natural gas with different gas composition
2.3 热力学抑制剂水溶液存在下天然气水合物形成预测
荔湾气田多数输气管道均采用注醇工艺,因此,引入热力学抑制剂的水溶液分析天然气水合物形成,如图7所示,其中各气体组分组成如表3所示。以纯水为基础介质时,PSO-LSSVM模型和BP神经网络模型均具有较高的预测精度。以含热力学抑制剂水溶液为基础介质时,PSO-LSSVM模型仍表现出较为出色的预测能力,但BP神经网络模型的模拟曲线逐渐偏离实验曲线[28],预测能力明显下降。因此,PSO-LSSVM模型可较精确地预测含热力学抑制剂天然气水合物的形成与解离。

图7 含热力学抑制剂水溶液与不同气体组成天然气形成水合物的预测结果Fig. 7 Prediction results of hydrate formed by aqueous solution containing thermodynamic inhibitor and natural gas with different gas composition
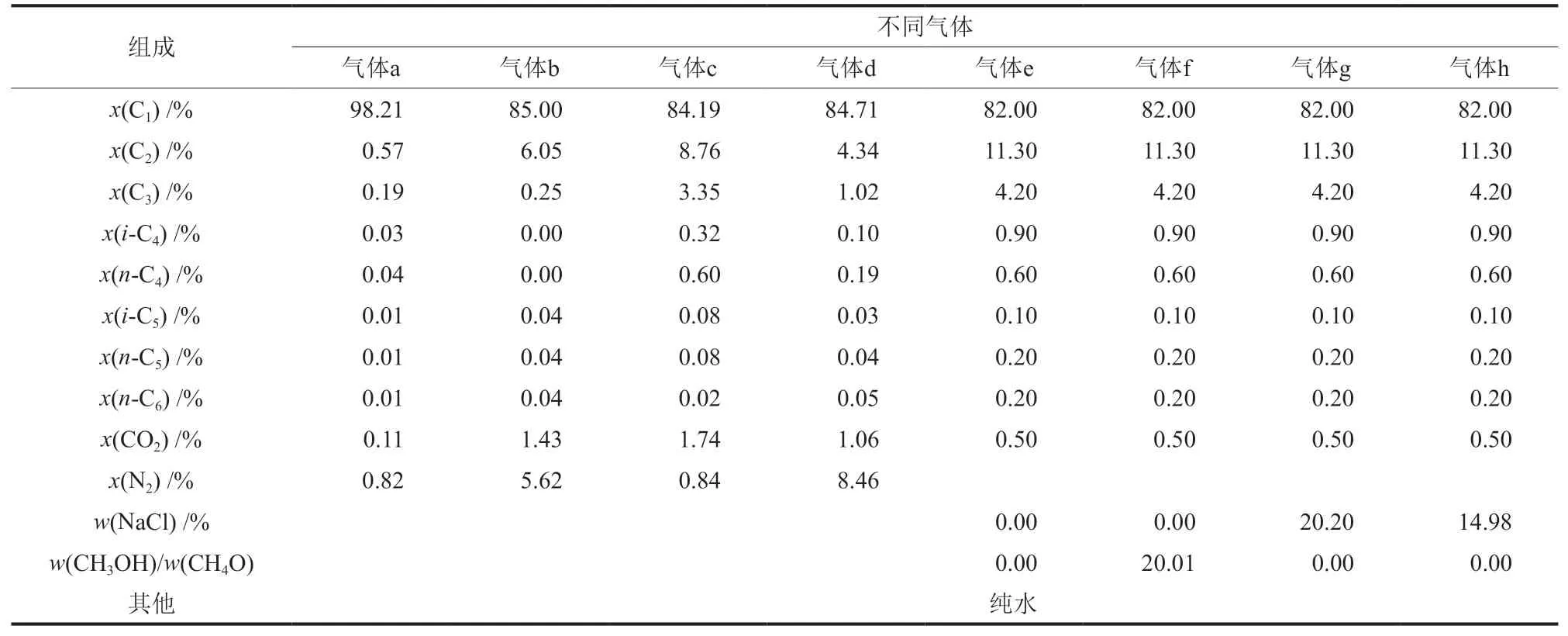
表3 不同气体组成天然气Table 3 Different natural gas composition
2.4 PSO-LSSVM模型现场应用
为分析PSO-LSSVM模型的现场应用效果,采用荔湾3-1气田立管回接平台处现场数据对模型进行分析,该气田气体组成如表4所示,模拟结果与现场数据如图8所示。由图8可知,PSO-LSSVM模型计算得到水合物形成了平衡曲线。同温度下,压力高于曲线数值则会产生水合物。荔湾气田现场形成水合物的红色数据点位于曲线上方,未形成水合物的绿色数据点位于曲线下方,与模拟结果相符,说明PSO-LSSVM模型对于现场生产具有较强的适用性。采用此模型进行模拟计算,可为甲醇注入量的确定和现场安全运行策略的制定提供理论依据。
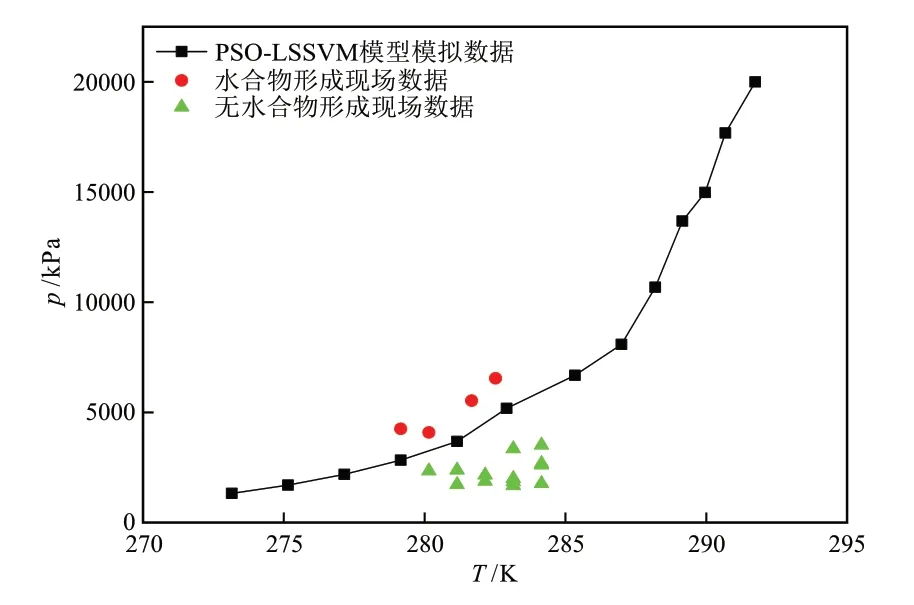
图8 荔湾气田现场数据与模拟结果比较Fig. 8 Comparison of data and simulation results in Liwan gas field

表4 荔湾气田气组成Table 4 Gas composition of Liwan gas field
3 结论
本文以荔湾气田注醇工艺为基础,建立了基于PSO-LSSVM的含抑制剂天然气水合物形成解离模型,并与BP神经网络模型模拟结果进行了对比分析。主要结论如下:
(1)PSO算法优化LSSVM模型的核参数选取1.0210368871948,正则化参数选取321.1523642521,验证了参数选取合理。PSO-LSSVM模型平均相对误差为0.04%,模拟数据均匀地分布在实验曲线两侧,具有较强的预测能力和稳定性。
(2)对于以纯水为基础介质的天然气体系,PSO-LSSVM模型模拟结果与实验数据具有更高的吻合度,且波动较小,BP神经网络模型因过度学习陷入局部极小值造成预测曲线波动较大;对于含热力学抑制剂的天然气体系,PSO-LSSVM模型预测精度较高,而BP神经网络模型模拟曲线逐渐偏离实验曲线,预测能力明显下降。
(3)PSO-LSSVM模型对于荔湾气田现场生产有较强适用性,可为甲醇注入量的确定和现场运行策略的制定提供理论依据。
猜你喜欢
化工进展(2022年10期)2022-10-30
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
都市人(2021年11期)2021-12-20
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
西南石油大学学报(自然科学版)(2021年3期)2021-07-16
新能源进展(2021年1期)2021-03-02
科学与财富(2020年27期)2020-11-10
都市人(2020年6期)2020-10-15
房地产导刊(2020年7期)2020-08-24
少男少女·校园(2020年5期)2020-05-20
