
耐久性感知的持久性内存异地更新
2022-03-09 05:41蔡长兴杜亚娟周泰宇
计算机研究与发展 2022年3期
蔡长兴 杜亚娟 周泰宇
(武汉理工大学计算机科学与技术学院 武汉 430073)
随着大数据时代的到来和人工智能技术的发展,海量数据存储和处理需求推动着计算机体系结构的进一步发展[1].大数据包含大量的、多种类的数据,这些数据的价值密度更低,但对处理时效和精确性的要求更高[2].为了满足这一需求,研究者们提出了持久性内存系统(persistent memory, PM)[3-4]等新型存储架构,如Intel公司最新推出的Optane[5]等,为传统DRAM内存构建的计算机体系带来巨大的变革.由于其非易失性、字节寻址、直接存取等优良的特性[3,6-8],持久性内存具有较高的研究价值和广阔的应用前景.然而,持久性内存系统故障发生后,部分数据持久保存在内存中,使数据恢复时产生不一致问题,从而导致严重错误.因此,故障一致性(crash consistency)问题是持久性内存系统需要解决的重要问题之一[9].
现有工作对持久性内存系统故障一致性保证机制开展了深入的研究,提出了日志、异地更新等技术[10-13].通过记录日志或多版本写的方式,使数据崩溃后仍可以恢复到一致性状态.然而,从时间和空间维度详细分析异地更新等现有技术,发现由于这些技术均引入了额外的写操作,导致总线延迟高、写放大等问题,对持久性内存系统的性能和寿命产生了一定的影响,从而导致了耐久性问题,因此亟需得到改进.
为缓解上述问题,本文提出了耐久性感知的持久性内存异地更新机制(endurance aware out-of-place update for persistent memory, EAOOP).基于对持久性内存系统硬件的改动,引入缓冲区提供耐久性感知的内存管理,为异地更新提供地址映射,并充分利用带宽写回数据.为了提升持久性内存的耐久性,故障一致性保证机制必须尽量减少对持久性内存的写入,本文运用异地更新技术,将划分为原始数据区域和更新数据区域的持久性内存交替使用,既保证了系统的故障一致性,又避免了冗余的数据合并操作,实现了对持久性内存的耐久性感知.同时,设计了轻量级垃圾回收,并与总线执行解耦,极大减少额外写放大和带宽占用,从而降低了故障一致性保证对持久性内存寿命和性能的影响.此外,本文还为该机制设计了系统恢复的方法,并详细描述了读写访问请求的工作流程.最后,通过模拟实验验证了EAOOP机制的有效性.基于微基准程序测试集和真实应用程序测试集,在模拟器McSimA+上实现并测试EAOOP机制.
本文工作的主要贡献有3个方面:
1) 分析了持久性内存故障一致性保证机制的性能优化问题.
2) 设计了耐久性感知的持久性内存异地更新机制,包括耐久性感知的持久性内存管理和轻量级垃圾回收.
3) 实现并评估本文提出的机制,EAOOP的事务处理吞吐量提升了1.6倍,总线延迟和写数量分别减少了27.3%和32.4%.
1 背景与研究动机
存储系统是冯·诺依曼计算机体系结构中的重要组成部分.在传统存储架构下,以动态随机存取存储器(dynamic random access memory, DRAM)为代表的传统计算机内存,因容量有限、能耗较高、与外存读写时延较长等问题[3],造成了输入和输出瓶颈[10],影响了大数据处理的效率和能耗,使得传统的存储系统已不能满足现有需求.
以Hadoop和MongodDB等系统为代表的现有工作[14-16],尝试从软件或软硬件结合层面改进传统计算机存储架构,但其仍然是基于传统的易失性内存,性能瓶颈依然不可避免.近年来,以自旋矩传输随机存取存储器(shared transistor technology random access memory, STT-RAM)[17]、电阻式随机存取存储器(resistive random access memory, ReRAM)[18]、相变化存储器(phase change memory, PCM)[19]和3D-XPoint[20]等非易失性存储介质(non-volatile memory, NVM)为代表的持久性内存的诞生和发展,以其拥有的非易失性、可字节寻址、随机读写速度快、能耗低、可扩展性强等特性,为传统的计算机存储架构带来了机遇和挑战.2019年Intel公司推出了持久性内存Optane DC Persistent Memory,更是加速了学术界和工业界对这一领域的关注.
持久性内存兼具传统内存和外存设备的优点,既可以用作外存,也可以用作内存.因为其可以被存储和加载指令直接访问[7,21-22],所以避免了开销较大的文件系统块页转换等操作.采用持久性内存单独做主存,持久性内存和DRAM的混合主存以及DRAM作为持久性内存的缓存,成为持久性内存系统这一新型存储架构设计的主要思路[23],如图1所示:

Fig. 1 Three common structures of persistent memory system图1 持久性内存系统的3种常见结构
然而,故障一致性问题一直是持久性内存系统发展的障碍.
1.1 故障一致性问题
故障一致性指的是当系统发生故障后,内存中数据能恢复到故障发生前、最近的一个与系统其他位置数据都一致的状态.传统的计算机存储架构因为易失性内存的存在,当系统发生故障时,内存中的数据即刻丢失.系统恢复后,内存中没有数据,因此不需要考虑故障一致性的问题.由于持久性内存的非易失性,在系统断电或崩溃等情况发生后,数据不会丢失.然而,留存的数据可能存在部分更新或悬空指针等问题[24-25],从而引发系统产生严重的异常或错误.
图2展示了持久性内存系统故障一致性问题原理.假设数据从缓存中被写入到内存时,由一个指针来引用,如图2(a)所示;将指针写入内存,如图2(b)所示;在写入数据之前,系统发生了故障,如图2(c)所示;此时只有指针留在了内存中,这个指针被称为悬空指针,此时系统中的数据处于不一致状态,在接下来的运行中悬空指针可能会引起系统异常或错误,如图2(d)所示.

Fig. 2 Principle of crash consistency problem in persistent memory system图2 持久性内存系统故障一致性问题原理
常见的持久性内存系统故障一致性保证的方法在软件层面有日志(logging)、写时复制(copy-on-write)和日志结构(log-structured)技术:1)日志技术主要有重写日志(redo log)和撤销日志(undo log),事务会在数据被提交(commit)前,将数据的原始版本写入撤销日志,或将数据的更新版本写入重写日志,也可能同时保存2种日志;2)写时复制技术的数据不在原始版本上更新,而是在新复制的版本上更新,更新后再删除原始版本;3)日志结构技术将更新后的数据以日志结构附加到日志结构中,写入持久性内存,并建立映射索引以便后续请求访问.在硬件层面常见的有检查点(checkpointing)和异地更新(out-of-place update)技术:1)检查点技术是程序执行过程中的一个快照,保存了某一节点系统中各个位置的数据版本,系统崩溃后,通过比对检查点中的数据可以快速将系统恢复到一致性状态;2)异地更新技术是将数据更新至持久性内存的指定区域,它与写时复制不同的是这种写入是由硬件支持的.
由于持久性内存自身读写不对称、写耐久性差等特性,上述经典方法在开销和性能之间还未取得较好的平衡.于是,研究者们基于经典方法开展了深入的研究,提出了如Mnemosyne[26],Kiln[25],ThyNVM[27],HOOP[10]等工作,但还存在一定的不足.因此,充分利用持久性内存特性,改进现有的故障一致性保证机制,对于优化持久性内存系统的性能、引领下一代计算机存储架构革新具有重要意义[26].
1.2 故障一致性保证优化
为了保证持久性内存系统的故障一致性,研究者们在多个方面提出了解决方案,这些机制虽然保证了故障一致性,但也不可避免地为持久性内存带来了开销,产生了性能上的下降,成为持久性内存系统取代传统计算机存储架构道路上的严重障碍.因此,在现有研究的基础上,进一步优化故障一致性机制的性能是十分有必要的.
软件透明的异地更新机制更能满足更少开销和更高性能这一发展趋势.现有工作HOOP机制就是一种软件透明的方案,采用硬件层面的优化思想,通过异地更新方法为持久性内存提供了硬件级别的故障一致性保证,使得其相较于传统日志方案充分利用了持久性内存写入带宽,提升了在故障一致性保证机制下持久性内存系统的性能.然而,该机制为了辅助异地更新而提出的垃圾回收机制存在冗余写入和总线占用的现象,引起了时间和空间维度的问题,存在一定的优化的空间.
从时间维度上来说,HOOP存在的问题主要有总线延迟和写延迟2个方面.首先,HOOP在执行垃圾回收机制时,后续的请求如果针对的是同一个数据,那么该数据就需要等待垃圾回收执行结束后,才能更新到持久性内存的异地(out-of-place, OOP)区域中,这个等待过程中,持久性内存无法执行读取或写入操作,从而产生了一定的总线延迟.其次,HOOP的垃圾回收机制虽然已经相较于传统的垃圾回收机制进行改进,但是,该机制仍需要对OOP区域已更新的数据进行扫描,再打包写入到Home区域中,也就意味着在已更新的数据写入持久性内存后,持久性内存中还会存在着与这些数据有关的再一次写入.虽然扫描和打包操作能尽量减少再一次写入的数据大小,但由于持久性内存的读写不对称问题一直是影响性能的重要因素,这种写入的存在必然对系统的执行时间产生巨大的影响,因此由于垃圾回收带来的写延迟问题也是需要优化的重要问题.
从空间维度上来说,HOOP主要存在的问题有写寿命和吞吐量2个方面.首先,由于持久性内存的写耐久性问题,HOOP提出的机制存在写放大问题,数据首先写入持久性内存,接着会再参与到内部的数据迁移中.这一机制的实现,对持久性内存的使用寿命会产生一定的影响,长远来看,对于持久性内存系统来说是得不偿失的,也不利于其进一步推广并替代传统内存系统.其次,HOOP机制对系统的吞吐量存在不必要的影响,随着垃圾回收时间间隔的增加,吞吐量也随之增大后变小,说明垃圾回收机制直接影响到了系统执行,这对于持久性内存系统来说其实是一笔不划算的开销.特别是对于不同微基准测试集,HOOP的吞吐量阈值并不一致.虽然现有工作HOOP机制相较于现有研究,已经在提升性能和减少开销上有了十分大的进步(1.7倍和2.1倍),但是从时间维度和空间维度上来说,其存在总线延迟、写延迟、写寿命和吞吐量等问题,还存在一定的优化空间,需要通过进一步减少写数量,解耦总线执行与垃圾回收来减少故障一致性保证机制带来的开销,提升持久性内存系统的性能.
2 EAOOP架构设计
基于现有研究,本文提出一种耐久性感知的持久性内存异地更新机制,如图3所示.该机制基于对持久性内存系统的硬件修改,采用持久性内存作为主存,对原有持久性内存系统的修改较少.在应用了该机制的系统上可以直接运行应用程序,而不必像传统机制一样需要实现相应的应用程序接口,对于用户更为友好和简单.
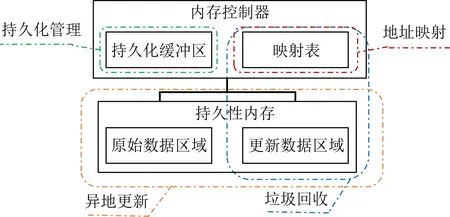
Fig. 3 Architecture design of EAOOP图3 EAOOP架构设计图
首先,在缓存和持久性内存之间加入了内存控制器一层,该层是易失性的.接着,在内存控制器中实现了持久化管理和地址映射,数据经过内存控制器中的持久化缓冲区和映射表处理后才能被读写.最后,在持久性内存中实现了异地更新和垃圾回收.
各模块的主要功能和原理为:
1) 持久化管理主要是在持久化缓冲区中进行的,在该模块中为数据持久化到持久性内存中做好准备.该过程将更新后准备写回的数据重新组成了缓存行后写入持久性内存,既保证了写入的顺序性,又减少了持久化过程中的顺序保证和持久化带宽开销.
2) 地址映射主要依靠的是映射表这一模块,承担了数据读写过程中的持久性内存地址映射功能,帮助数据确定异地更新的地址和垃圾回收的时机.同时,它也与其他方法的实现有着密切的关系,可以将数据的地址映射关系信息记录在此,服务持久性内存数据的多版本管理.
3) 异地更新在持久化过程中实现,持久性内存被划分为原始数据区域和更新数据区域,用于存放交替写入持久性内存的数据.为了保证后续请求的正确访问,在写入持久性内存之前,这些数据的映射关系已经在系统中被记录.
4) 垃圾回收在后台运行,主要处理持久性内存中的“无效”数据,同时会对映射表中的条目进行修改.针对现有工作中存在的时间和空间维度的问题,它既减少冗余写入操作,又解耦了垃圾回收与总线执行之间的关系,使得系统开销减少,性能提升.
由于持久化缓冲区的数据和映射表中的数据都在易失性的内存控制器中,因此当故障发生后,持久化缓冲区的数据和映射表中的数据将会丢失,使得持久性内存中的数据出现不一致的问题.因此,在一致性保证的基础上,本文还实现了对系统的恢复,主要在持久性内存中进行.同时,该过程也能够重建因故障丢失的映射表,在恢复结束后,服务持久化缓冲区中重新传入后续请求.
3 关键技术
本节我们详细介绍EAOOP机制中的关键技术.
3.1 耐久性感知的内存管理
由于持久性内存支持字节粒度寻址,可通过load或store指令直接访问内存中的数据,而不需要进行页交换(page swapping).本文充分利用了这一特性,通过引入易失性的内存控制器,对持久性内存进行高效灵活的管理,主要包括持久化管理、地址映射和异地更新3个部分.
数据持久化过程指数据写入持久性内存的过程.确保数据不会发生不一致性的情况,是持久性内存系统需要解决的基本问题,其中最重要的是要保证写入时的顺序性.部分现有工作都将持久性内存系统数据写回粒度设定为缓存行粒度,然而写入时数据如果不能完全占用缓存行,便会造成带宽的浪费,这对于持久化管理来说也是一种额外的开销,因此以缓存行粒度写入(64 B)是最为高效的方式.
本文提出的持久化管理方案,在内存控制器中加入持久化缓冲区模块,所有从缓存写回内存的数据,都需要经过该模块处理后,再写入持久性内存.在该模块中,数据主要经过了标记、组合和写回3个步骤:1)数据到达持久化缓冲区后,将为其添加元数据,这一过程被称为标记.后续操作可以根据标记判断,数据即将写入持久性内存的哪一个区域,以及写入的先后顺序.2)标记后的数据将被重新组合成缓存行,这个步骤的主要目的是为了充分利用写入带宽,减少写入的次数,提升吞吐量,如图4所示.3)按照既定的顺序,当缓存行准备好时,持久化缓冲区将把数据按照顺序,基于硬件的机制将数据刷新到持久性内存的指定区域.
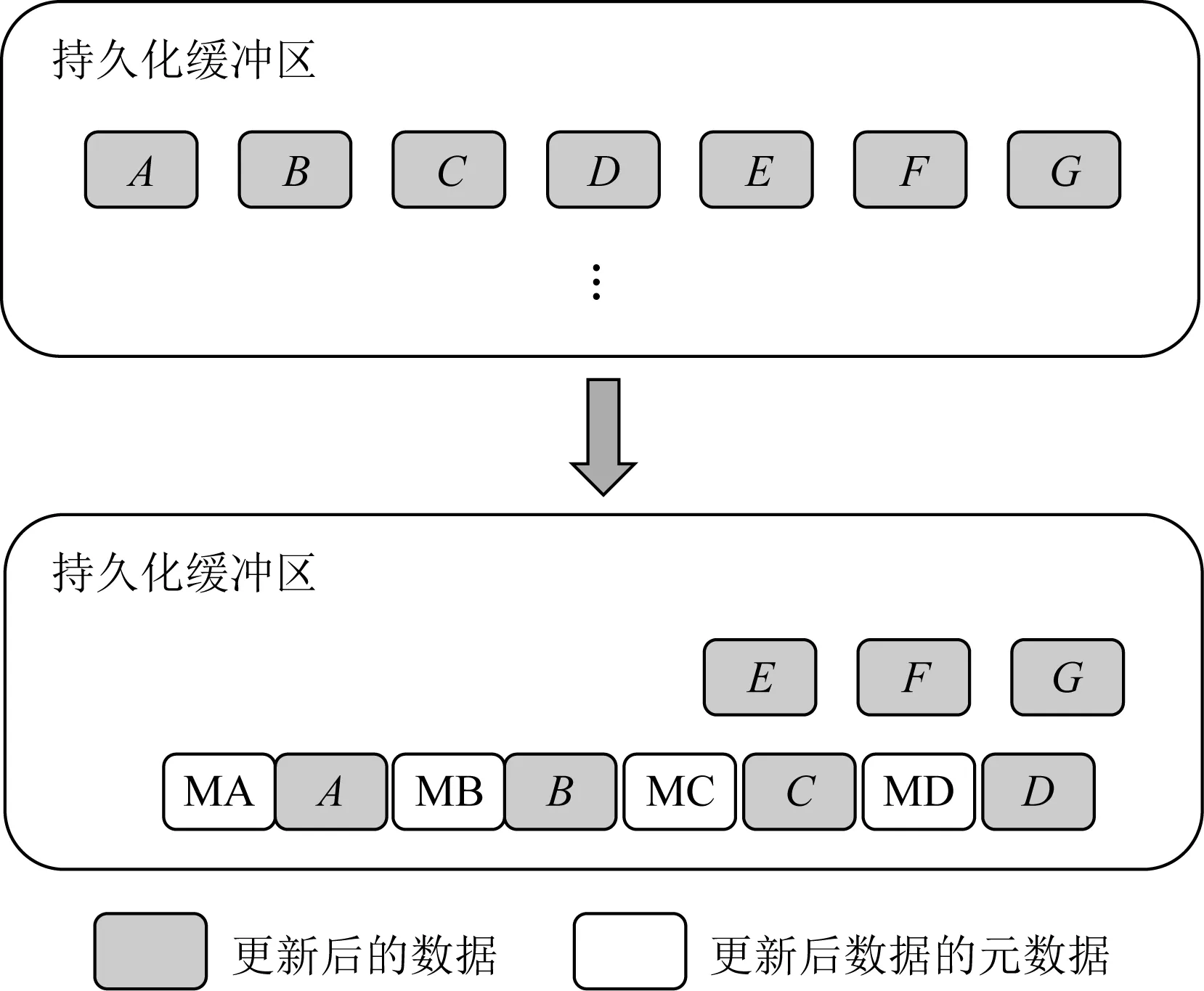
Fig. 4 Principle of combination图4 组合原理图
写入持久性内存时,根据数据的元数据,可以判断持久性内存即将写入的区域.本文实现的思路并没有将原始数据区域和更新数据区域从物理地址角度进行划分,而是通过元数据区分数据写入的区域.如算法1所示,首先检查缓存行状态.如果无缓存行,则初始化新的缓存行;反之,如果缓存行还没装满,则将数据继续加入缓存行,等待缓存行装满后,再遍历缓存行里的数据.接着,根据数据的元数据的原始地址区域,在映射表中查找该条目的更新次数.如果更新次数是奇数,则更新的是更新地址区域的数据;反之,如果更新次数是偶数,则更新的是原始地址区域的数据.最后,缓存行刷新结束后,将会向系统返回一个刷新结束的信号,数据持久化的事务提交完成.
算法1.数据持久化算法.
输入:已标记好的数据;
输出:刷新结束.
① while缓存行大小<64 B do
② if缓存行大小=0 then
③ 初始化新的缓存行;
④ end if
⑤ 将标记好的数据加入缓存行;
⑥ 缓存行大小+8;
⑦ end while
⑧ for each数据in缓存行do
⑨ 查找映射表条目;
⑩ if更新次数%2=1 then
本文使用散列表生成映射表,如图5所示.它包含了数据的原始区域地址、更新区域地址和更新次数.它会随着数据的更新和垃圾回收机制的执行,不断变化大小,但实际上在内存控制器中只占用极少的空间.在系统崩溃时,这一模块会随着故障一起丢失.而在系统恢复时,映射表会根据持久性内存中的新旧2个版本数据的映射关系再重建起来.
本文提出的故障一致性保证的方案以异地更新为基础,它指的是数据在写入持久性内存时,不更新原始地址上的数据,而在新的地址写入.在EAOOP机制下,每一次数据更新后的写入区域对于持久性内存来说是可预见的.如图6所示,在数据第1次更新前或垃圾回收后,持久性内存中的数据可能只有原始数据区域中的1个版本(A0).数据在第1次更新后和垃圾回收前,或系统恢复后,持久性内存中可能同时存在当前数据的2个版本,即新版本(A1)和旧版本(A0).当该数据再一次更新时,最新版本(A2)将会更新旧版本(A0),此时持久性内存中留下的当前数据的版本变成了最新版本(A2)和较新版本(A1).这种双版本共存的状态不会持续太长时间,因为持久性内存目前价格较高,考虑到空间使用效率,垃圾回收之后会对更新数据区域的数据进行处理,数据将回到只有1个版本(AN)留存的状态.
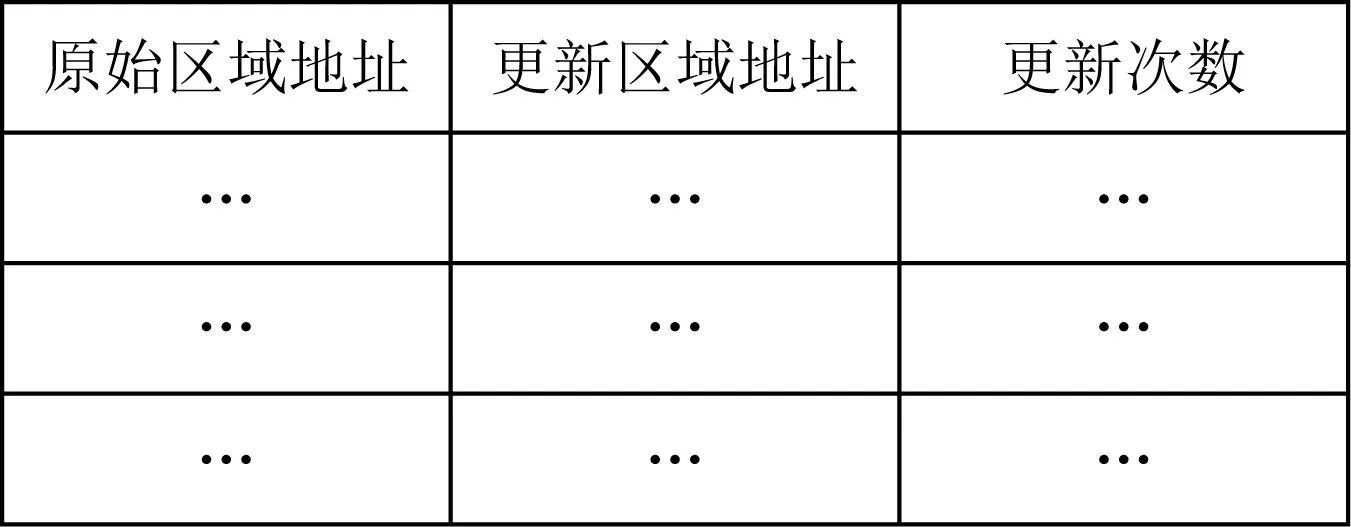
Fig. 5 Structure of mapping table图5 映射表结构图
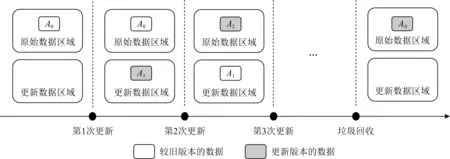
Fig. 6 Principle of out-of-place update mechanism图6 异地更新机制原理图
3.2 轻量级垃圾回收
本文提出的EAOOP机制将持久性内存划分为原始地址区域和更新地址区域2个区域,在每次写回时将数据更新至其中一个区域,这意味着在一段时间内这2个区域都分别保存了同一数据的不同版本,这一机制虽然保证了故障发生后,系统可以借助更新地址区域中的数据将持久性内存中的数据恢复至一致性,但也一定程度上浪费了持久性内存的空间,在数据不断更新的情况下是非常不经济的.
考虑到推广应用需求,现阶段在持久性内存的研究中,还需要尽可能地提高内存空间的利用效率,同时减少对内存寿命产生影响的操作.
本文设置被垃圾回收的数据是更新数据区域的数据,因此原始数据区域的数据在垃圾回收之后,可以被系统当作从未更新过的数据来使用.由于数据在写入持久性内存前,已经在映射表中记录了本次更新的次数,因此可以根据更新次数,以确定持久性内存系统中垃圾回收机制开始的时机.
更新次数的选取只能是偶数,因为这时最新版本的数据写入的是原始数据区域,而更新数据区域中的数据是较旧版本的,因此这个时候更新数据区域中的数据可以被看作是无效数据.而更新次数在垃圾回收中的阈值如果过大,持久性内存系统将容纳过多的数据,显然违背了高效利用内存空间的初衷.如果过小,垃圾回收将进行得过于频繁,虽然对系统整体性能不会造成影响,但可以预见的是,这对持久性内存的性能本身也是一种消耗.因此,本文将垃圾回收机制下的更新次数阈值设置为4,以确保垃圾回收机制在持久性内存中高效进行.
如算法2所示,轻量级垃圾回收的实现较为简单.当映射表的条目更新后,如果该条目的更新次数达到阈值,则记录映射表该条目的更新数据区域地址.接着,将更新数据区域地址上的数据删除.然后,删除映射表上该条目的记录.最后,向系统返回该数据的垃圾回收已经结束.
算法2.垃圾回收算法.
输入:持久性内存中的数据;
输出:垃圾回收结束.
① 映射表条目更新;
② if更新次数=阈值then
③ 记录映射表该条目的更新数据区域地址;
④ 删除更新数据区域地址上的数据;
⑤ 删除该条目;
⑥ end if
⑦ return垃圾回收结束.
3.3 系统恢复
在本文提出的EAOOP机制下,以数据写入持久性内存时系统发生故障为例.当故障发生后,持久性内存中可能存在同一数据的2个版本,分别分布在原始数据区域和更新数据区域2个区域中.其中某一个区域的数据更旧,在这次故障发生前一段时间内数据是没有变化的,而另一个区域中的数据在这次故障中受到了影响,可能存在部分更新的情况.另外,在内存控制器中的持久化缓冲区和映射表在故障中完全丢失,因此可能存在故障发生后还没有提交的事务,同时映射关系目前已经不存在了.
假设当前持久性内存中还存在未提交的事务产生的数据,无论受到故障直接影响的是原始数据区域或更新数据区域,由于持久化缓冲区的数据在故障中已经丢失,这部分数据都应当被清除.对于已提交的事务产生的数据,假设当前受到故障直接影响的区域是原始数据区域,那么可以认为当前数据的状态,是经过本文提出的轻量级垃圾回收机制处理后的数据.由于其本身也是一致性的,此时更新数据区域中的数据就可以直接被删除了.假设当前受到故障直接影响的区域是更新数据区域,这部分数据在原始数据区域中有更旧的版本.对于这种情况,在HOOP机制中是将OOP区域中数据打包后写回到Home区域,但是这种方法也会对持久性内存产生过量的写,会加剧写放大问题.而本文提出的EAOOP机制更加灵活,可以通过重建映射表后重新加入映射关系将系统恢复至一致性.
由于持久化过程是由持久化缓冲区进行分配并写入持久性内存的,而持久化缓冲区中的数据在故障中已经丢失,因此判断故障发生时受到最直接影响的区域,依靠的是已写入内存的数据的元数据中的事务编号.对于同一数据,事务编号更大的区域被认为是版本更新的区域,即在故障发生时受到直接影响的区域.在EAOOP机制下,原始数据区域中的数据,在任何时刻都多于或等于更新数据区域.从更简单地实现系统恢复的角度,应该以更新数据区域中的数据为主进行恢复,通过对其中的数据及其元数据进行遍历并建立散列表,表中包含原始数据区域地址、更新数据区域地址和事务编号(TxID)等标记信息,帮助系统恢复机制高效地比较数据版本和执行恢复操作.
基于上述分析,本文提出的EAOOP机制下系统恢复的实现如算法3所示.首先对更新数据区域中的数据进行遍历,将它们的元数据的原始数据区域地址、更新数据区域地址和事务编号记录在散列表中.接着进行恢复操作,如果该记录的事务编号比对应原始数据区域数据的事务编号更大,则说明该记录对应的数据是更新版本的数据,那么就要保留当前更新数据区域数据.同时将元数据中的映射关系写入重建后的映射表,并将其中的更新次数设置为1.反之,则直接删除更新数据区域对应的数据.如果此时所有恢复已经结束,则删除记录了遍历更新数据区域数据的散列表.反之,则继续执行下一条目的恢复程序直到结束.
算法3.系统恢复算法.
输入:持久性内存数据;
输出:恢复结束.
① 初始化恢复散列表;
② 初始化映射表;
③ for each数据in更新数据区域do
④ 在恢复散列表中记录当前数据元数据的原始数据区域地址、更新数据区域地址和事务编号;
⑤ end for
⑥ for each条目in恢复散列表do
⑦ if原始数据区域地址中的数据存在 then
⑧ if事务编号<原始数据区域数据事务编号then
⑨ 删除更新数据区域数据;
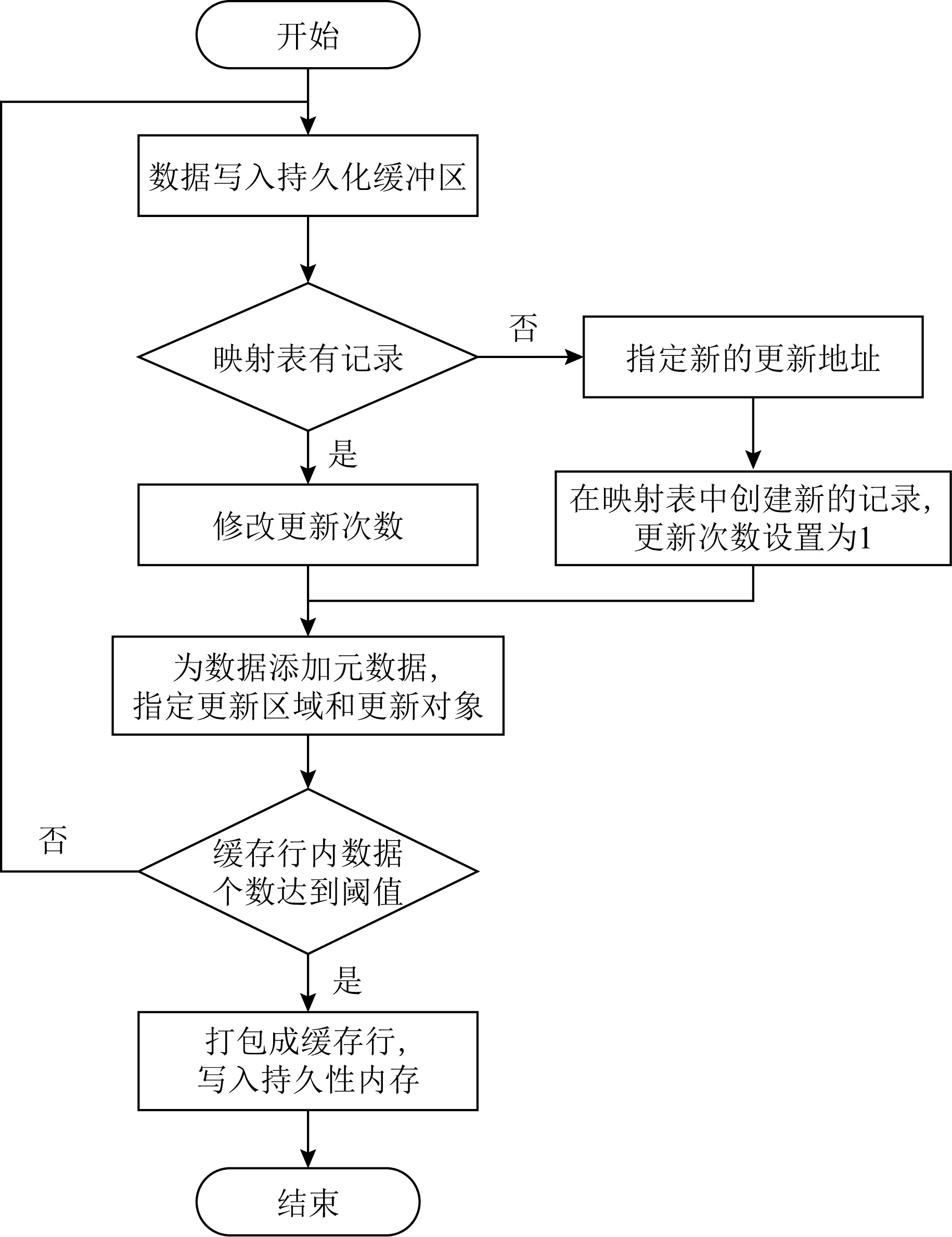
Fig. 7 Write flow of EAOOP图7 EAOOP机制写流程图
3.4 服务读写流程
为了服务一个内存写请求,EAOOP机制实现的写流程如图7所示.首先,数据会加入持久化缓冲区.接着,查看映射表中是否有该数据的记录.如果记录存在,则将更新次数加1;如没有记录,则首先要在更新区域中为该数据指定一个更新的地址.同时,在映射表中创建一条新的记录,填入新的映射关系,并将更新次数设置为1.然后,持久化缓冲区会为数据添加元数据,并为这些数据指定更新区域的地址.完成这些操作后,数据和元数据将被重新组合至缓存行中.当缓存行中的数据数量没有达到阈值时,将会继续重复执行上述操作.当缓存行中的数据达到阈值后,就会执行写入持久性内存的操作.至此,写请求完成.
为了服务一个内存读请求,本文设计的读流程相对于写更为简单,如图8所示.当处理器的读请求在缓存中没有命中时,读请求将会首先到达内存控制器中的映射表.如果在映射表中无法查到想要访问的数据,那么读请求会前往持久性内存中的原始区域,也就是请求本身的地址读取相应的数据;反之,如果查到了想要访问的数据的记录,那么将会根据更新次数来判断最新版本的数据所处的位置.如果更新次数为偶数,则不用变动请求本身的地址,直接前往原始区域,也就是请求本身的地址读取相应的数据;如果更新次数为奇数,则前往映射表中该数据对应的更新区域的地址读取数据相应的数据.至此,读请求完成.

Fig. 8 Read flow of EAOOP图8 EAOOP机制读流程图
4 实 验
本节通过微基准和真实应用,对EAOOP机制及其他对比系统的性能进行测试,包括事务处理吞吐量、总线延迟和写数量等测试,并分析其性能表现.
4.1 实验平台
本文选取的对比系统是undo log,redo log,HOOP,EAOOP等,它们都是在McSimA+[28]这一模拟器上实现,并进行测试.模拟器的主要配置设置如表1所示.持久性内存的相关时序特征如tRCD,tCL等参数设置与PCM相同.

Table 1 Configuration of Persistent Memory Simulator表1 持久性内存模拟器配置表
本文采用的测试基准程序分为微基准程序和真实应用程序,如表2所示.微基准程序包含了Queue,Vector,Rbtree,Hashtable这4种通用的微基准测试集.在本文的实验中,主要通过模拟Insert和Update的操作以测试系统性能.
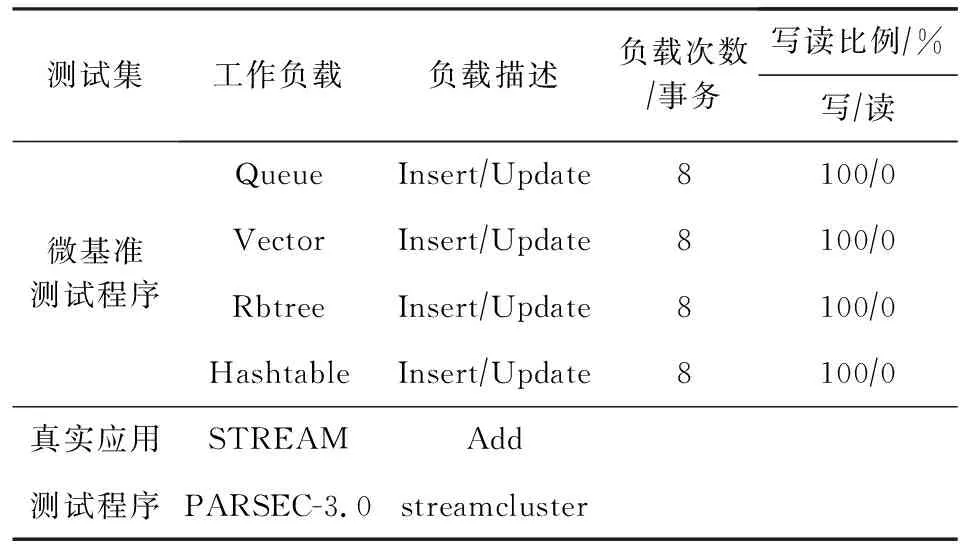
Table 2 Configuration of Evaluation Benchmarks表2 测试基准程序配置表
本文选取的真实应用程序是STREAM[29]和PARSEC-3.0[30].STREAM是由美国弗吉尼亚大学开发的一种内存系统基准测试工具,本文主要针对Add操作进行了测试.PARSEC-3.0是由美国普林斯顿大学开发的一种经典的内存系统基准测试套件,本文采用了streamcluster进行测试.
为了使测试结果简洁直观,本文以undo log为基线,对所有的测试结果及其图片进行了归一化处理.
4.2 微基准程序性能
1) 事务处理吞吐量
本文提出的EAOOP机制所应用的系统相对于undo log,redo log,HOOP机制各自系统的事务处理吞吐量平均分别提升了95.5%,71.2%,9.6%.因为undo log需要写入大量的日志,而持久化顺序保证使得写回的次数更多,带宽没有得到充分地利用,事务处理吞吐量也因此最低.而redo log的持久化顺序保证虽然没有undo log那么严格,但是也因为日志的存在,必须在更新数据的同时向持久性内存中写入大量的日志,总线上下一次更新的请求也因此受到了影响,事务处理吞吐量也因此不高.HOOP机制通过异地更新机制而避免了向持久性内存中写入过量的日志等内容,同时在数据写回前将数据打包成了2条缓存行,保证了写入的带宽,但由于异地更新而引入的垃圾回收机制在执行过程中,后续的请求将无法访问正在被执行的数据,只能等待垃圾回收结束以后,才能从Home区域中访问最新版本的数据,这对于系统的事务处理吞吐量也产生了一定的影响.EAOOP机制解耦了系统执行与垃圾回收之间的关系,当后续请求访问最新版本数据时,正在执行垃圾回收进程的是较旧版本的数据,同时在写入时采用了数据重组写回技术,充分地利用了写回带宽,因此系统的事务处理吞吐量相对更高.
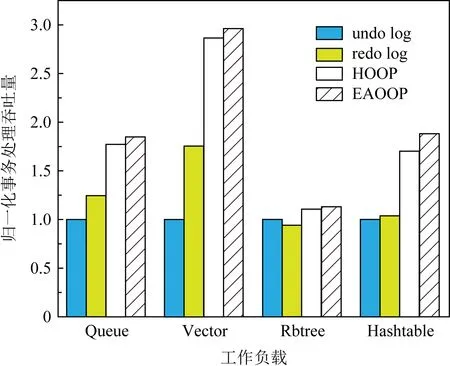
Fig. 9 Transaction throughput on micro-benchmarks图9 微基准下事务处理吞吐量图
2) 总线延迟
本文提出的EAOOP机制所应用的系统相对于undo log,redo log,HOOP机制各自系统的总线延迟平均分别减少了46.8%,28.8%,3.9%.因为undo log需要严格的持久化顺序保证,数据写入持久性内存必须等待日志写入的事务提交后才能进行,由于持久性内存写延迟显著,总线延迟也因此最高.而redo log只需要保证持久化过程中,日志先提交即可更新下一次数据,总线延迟因此相较undo log更低一些.HOOP机制在内存控制器中,通过OOP缓冲区对数据的打包,以及内存切片内部数据块之间的连接,实现了对持久化顺序性的保证,因此总线延迟相对较少,但是数据必须要等待垃圾回收的结束才能写回到Home区域,这一阶段对总线的占用以及读请求的等待增加了其总线延迟.本文提出的EAOOP机制首先是将持久化顺序性保证在持久化缓冲区中生成缓存行时就完成了,避免了反复的写入,以致于增加总线上的负担.其次,对于读请求只需要在映射表中查询1次就可确定读取地址,而非HOOP机制中需要在映射表和写回缓冲区中多次寻址.同时,垃圾回收机制的执行对总线上正在执行的读写请求没有影响,因此总线延迟相对更低.

Fig. 10 Critical path latency on micro-benchmarks图10 微基准下总线延迟图
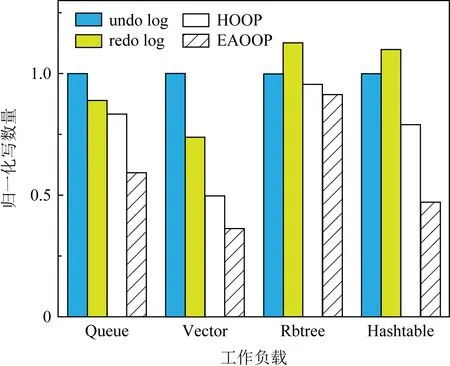
Fig. 11 Write number on micro-benchmarks图11 微基准下写数量图
3) 写数量
本文提出的EAOOP机制所应用的系统相对于undo log,redo log,HOOP机制各自系统的写数量平均分别减少了41.5%,37.8%,18.5%.undo log和redo log由于持久化过程中需要向持久性内存写入日志,因此产生了大量的写,其中redo log由于持久化顺序性保证的需求相对不严格,写入持久性内存的次数相对没有undo log频繁,因此写数量相对较少.虽然HOOP机制没有大量日志写入,但是其中的垃圾回收机制会将OOP区域的数据写回到Home区域,这部分写入依旧是较大的开销,增加了写数量.程序执行过程中,EAOOP机制对于持久性内存的写入主要是在数据从缓存持久化到持久性内存的阶段,而其他时间对于持久性内存是没有写入的,这得益于本文提出的轻量级垃圾回收机制,对于在异地更新中暂时无效的数据及时地处理,相较于HOOP机制进一步减少了对持久性内存写入的数量.
4.3 真实应用程序性能
1) 事务处理吞吐量
EAOOP机制的事务处理吞吐量分别提升了14.8%,14.8%,1.9%,6.9%.STREAM的吞吐量提升效果比PARSEC更多的原因以及STREAM随数据集增大性能提升变化不大的原因可能是由于STREAM应用程序本身局部性较小,减少了垃圾回收机制对后续更新请求的影响,但并没有显著增加因此而带来的操作数.在PARSEC的小数据集上提升效果不够明显的原因可能是需要聚类的数据量少,需要的操作和内存访问也较少.随着数据集的增大,需要的操作和访存次数也增多,充分体现EAOOP机制的带宽优势.
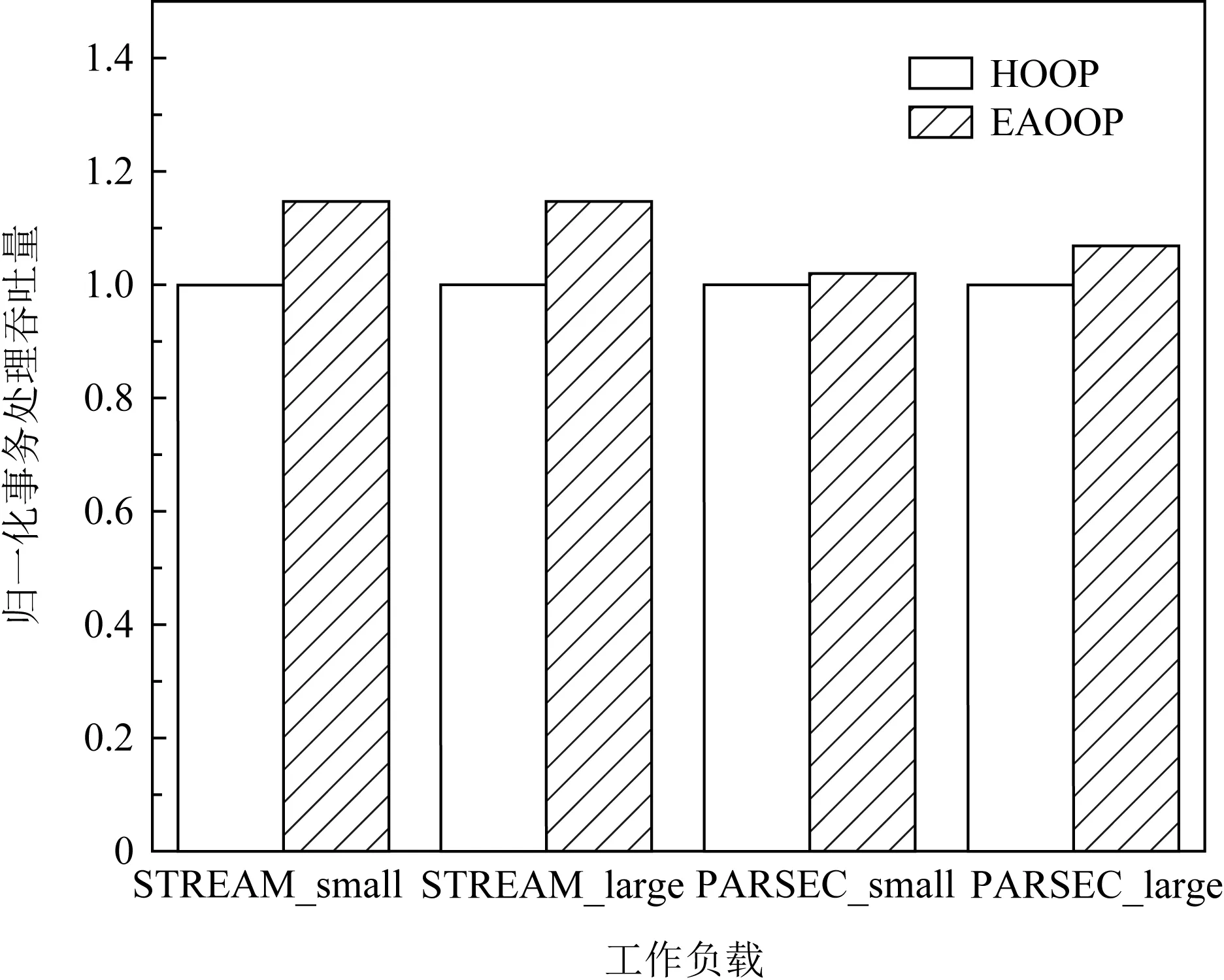
Fig. 12 Transaction throughput on real-world applications图12 真实应用下事务处理吞吐量图
2) 总线延迟
EAOOP机制的总线延迟在真实应用程序测试集上分别减少了14.1%,13.5%,0.6%,7.8%.在PARSEC上运行小数据集时,总线延迟几乎没有减少的原因可能是对持久性内存的访问较少,且局部性较高,后续请求在访问内存时受到HOOP中垃圾回收机制的影响也减少,因此性能提升不够明显.而随着数据集的增大,后续请求增多,针对同一数据更新而被迫等待更新的数据增多,总线延迟也进一步增大.而STREAM应用程序得益于EAOOP机制将垃圾回收机制与总线执行解耦,处理对持久性内存的后续访问更加快速,使得其总线执行性能提升明显.

Fig. 13 Critical path latency on real-world applications图13 真实应用下总线延迟图
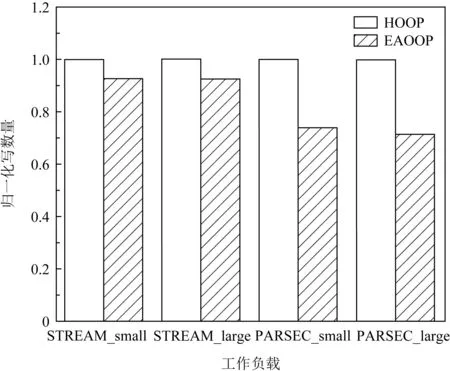
Fig. 14 Write number on real-world applications图14 真实应用下写数量图
3) 写数量
EAOOP机制的写数量分别减少了7.4%,7.5%,26.1%,28.7%.这是由于HOOP中的垃圾回收机制为持久性内存带来了大量的写,对于PARSEC这种应用程序来说,在持久性内存中的针对同一数据的更新次数更多,因此开销减少更多.而STREAM应用程序的局部性较小,则垃圾回收写入的数量在总的写数量中的占比也更少,随着数据集的增大,减少效果也不明显,因此其写数量的减少比例没有PARSEC应用程序大.
从实验结果可以看出,无论是微基准程序,还是真实应用程序上,本文提出的EAOOP机制在事务处理吞吐量、总线延迟和写数量等方面始终具有更低的开销和更高的性能.平均而言,事务吞吐量增加了1.6倍,总线延迟和写数量分别减少了27.3%和32.4%.
5 相关工作
本节从基于应用、软件和硬件的持久性内存故障一致性保证机制3方面介绍相关工作.
1) 应用层面基于具体场景,如特定的硬件模块、索引结构、数据类型等,将软件和硬件机制结合,开展针对性地优化,使持久性内存系统在故障一致性得到保证的前提下,性能在具体应用方面得到显著提升.
Zhao等人[25]提出了一种持久性内存系统Kiln.针对现有持久性机制对性能影响过大的问题,通过缓存设计了数据原子就地更新(atomic in-place update)和即时清理的提交(clean-on-commit)方法,降低了持久化开销.Zhao等人[31]提出了一种混合持久性内存管理机制FIRM.针对现有读写调度机制只适用于非持久性应用,造成了系统效率低下,同时无法有效处理密集流式写数据的问题,允许跨内存库更新持久内存,同时设计了持久感知存储调度系统,从而显著提高系统的并行性能.Kim等人[32]提出了一种基于持久性RAM的写前日志机制NVWAL.针对持久性内存中SQLite存在的顺序控制和频繁刷新带来的开销,以及内外存粒度不匹配的问题,首先设计了写前日志(write-ahead logging).接着,通过修改B树结构,实现字节粒度差分日志,减少了日志I/O开销.然后,通过用户堆管理各个元素块和页的状态,减少了内核管理的开销.最后,设计了事务感知的存储持久保证机制,将顺序控制范围扩大到一组写,减少了持久化开销.Hwang等人[33]提出了一种可忍耐瞬时不一致性的B+树.针对与缓存行粒度不匹配的故障原子写,以及持久化过程中的顺序控制开销过高的问题,设计了一种FAST&FAIR算法.它分别实现了数据的就地更新(in-place update),以及无需日志记录或写时拷贝情况下的B+树再平衡.同时,设计了无锁搜索算法,隔离了读事务,以允许系统对同一个树节点的并发访问,从而优化了读写不对称问题.Cohen等人[34]提出了一种细粒度检查点与缓存行日志结合的机制INCLL.针对持久化过程中数据更新顺序保证延迟,从而导致总线执行被阻碍的问题,以及检查点粒度和系统停顿开销过大的问题,在Masstree这一数据结构上设计了细粒度的检查点.同时,将undo日志嵌入到Masstree叶节点的缓存行中,显著降低了日志记录和刷新缓存的成本.
这一类方法的优点是性能较传统故障一致性保证的方法提升较大,方案更加灵活多变;缺点是对硬件架构和系统软件的设计与结合机制更加复杂,需要考虑更多因素,实际应用中面向的对象具有较大的局限性.
2) 软件层面主要围绕事务性内存系统来开展设计,在持久性内存系统中,研究者们主要依托日志、写时复制和日志结构等技术,开展了相关的研究.
Volos等人[26]提出了基于持久性事务内存的系统Mnemosyne.针对如何创建和管理非易失性内存,以及如何确保故障一致性,在内存中设计了一个持久化区域实现了对内存的用户模式访问,同时设计了持久化原语pstatic支持持久性内存编程.它的持久化内存事务还支持创建和修改持久化数据结构,从而实现了一致性更新.Liu等人[11]提出了基于持久性事务内存的系统DudeTM.针对现有事务的撤销日志和重做日志中,存在的持久化内存栅栏(mfence)保证开销,将2种日志模式结合.同时把事务分解为3个异步操作:①在影子内存(shadow memory)中创建日志并更新数据;②将日志写入持久性内存中;③在持久性内存中更新数据.Nalli等人[35]提出了基于持久性事务内存的系统HOPS.通过设计WHISPER这一持久性内存系统测试基准套件,得出了现有软件事务性内存系统的4点结论.同时将持久化过程中的flush和mfence操作改进为ofence和dfence操作,减少了强制刷新的开销,并实现了持久性和顺序性的解耦,在保证一致性的同时降低了开销.Gu等人[36]提出了基于持久性事务内存的系统Pisces.针对现有的持久性事务内存编程模型对实际较多的读操作优化较少,进而影响读的效率的问题,以及严格的持久化顺序限制了并行操作,从而导致的扩展性问题,提出了改进的MVCC机制DVCC.在增加了快照隔离(snapshot isolation)的同时,减少了遍历数据对象的开销.同时设计了3级commit机制,将数据对象的持久化和程序执行的过程分离,使得事务commit的效率对总线上的程序运行不会产生阻塞.Krishnan等人[37]提出了基于持久性事务内存的系统TimeStone.针对现有持久性事务内存存在的写放大问题和扩展性瓶颈,设计了TOC Logging机制.它分别在易失性内存中记录事务日志(TLog),在非易失性内存中记录操作(OLog)和检查点(CLog),从而减小了日志的体积和总的写入开销.同时引入了MVCC机制,允许事务在一定范围内并行运行,扩大了系统的运行规模.
软件层面的方案总是会为持久性内存带来过量的写,从追求更高的性能、更低的开销的角度来说,这一类型的方案代价较大.
3) 硬件层面主要是采用了软件透明的思想,即在不需要修改应用程序的情况下,为其提供由持久性内存系统支持的故障一致性保证.
Kannan等人[38]提出了一种软件透明的混合内存系统NVM-Checkpointing.通过将操作系统中的检查点技术引入到持久性内存系统中,同时采用Shadow Buffering将部分数据缓存到DRAM中,从而加快访存速度,并解决了NVM写入慢的问题.此外,通过引入虚拟机迁移中常用的Pre-Copy机制,将DRAM中的部分数据,先于检查点创建时间点写入检查点区域,从而缓解了检查点带来的系统暂停.Ren等人[27]提出了一种软件透明的混合内存系统ThyNVM.针对页粒度和块粒度、非易失和易失性内存的性能差异,设计了双模式检查点(dual-scheme checkpointing)技术,减少了因检查点产生的系统停顿.同时设计了协调不同粒度模式、转换数据状态的管理方法,使得系统始终可以自动权衡最佳模式.Wei等人[39]提出了一种软件透明的混合内存系统NICO.针对检查点创建和数据对象映射带来的性能开销问题,以及传统持久化方法带来的性能浪费问题,在持久化内存系统中设计了持久化缓冲区,将持久化操作放在后台进行.同时设计了轻量级检查点机制,加之写合并机制,只需要刷新和修改小部分数据即可实现一致性保证.Nguyen等人[40]提出了一种软件透明的持久性内存系统PiCL.针对现有软件事务接口、持久化对象和多版本管理的性能损耗、日志随机访问,从而产生NVM开销过大和局部性较低的问题,设计了多版本undo日志方法,允许多个时间周期并行执行undo日志.同时,设计了缓存驱动的日志机制,以优化传统的日志读写顺序.最后,通过异步缓存扫描方法将机制整合,减少了一致性保证开销.Cai等人[13]提出了一种软件透明的混合内存系统HOOP.针对现有软件事务方法在NVM上的大量写入和带宽利用等问题,设计了异地更新机制.它利用OOP缓冲区,将更新后的数据打包后写入NVM,减小了数据体积并增加NVM带宽利用率.同时设计了OOP区域和Home区域,利用垃圾回收机制更新持久性内存中的数据,保证了故障一致性.
硬件层面的方案虽然依赖于架构的特性,但更加灵活,可以充分发挥持久性内存的优点,也能弥补软件层面对顺序性和持久化过程改进能力不足的问题,同时也因其不需要用户层面的应用程序专门去适配接口而减轻了程序员的压力,更具研究价值和应用空间.
6 结 论
现有研究中,针对持久性内存系统的故障一致性保证机制,还存在时间和空间维度的不足,在未来持久性内存系统有望大规模推广应用的前景下,还存在一定的优化空间.针对这一问题,本文提出了耐久性感知的持久性内存异地更新机制,通过耐久性感知的内存管理机制,保证了系统的故障一致性,通过轻量级垃圾回收机制,进一步减少了系统开销和空间浪费.此外,本文还设计了系统恢复机制和读写流程.测试结果表明,EAOOP机制下的系统从时间维度和空间维度优化了现有研究,具有更高的性能和更少的开销.未来,将考虑通过基于Optane系列持久性内存的真实硬件测试,进一步验证该机制的优异性能.
作者贡献声明:蔡长兴提出了算法思路、实验并撰写论文;杜亚娟指导研究方案设计并修改论文;周泰宇协助设计实验方案.
猜你喜欢
汽车实用技术(2022年19期)2022-10-19
计算技术与自动化(2022年2期)2022-07-04
汽车实用技术(2022年9期)2022-05-20
华人时刊(2021年13期)2021-11-27
诗选刊(2020年12期)2020-12-03
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
山东工业技术(2017年7期)2017-04-10
科技经济市场(2016年5期)2017-02-05
