
基于近端策略优化的阻变存储硬件加速器自动量化
2022-03-09 05:41张兴军卓志敏纪泽宇李泳昊
计算机研究与发展 2022年3期
魏 正 张兴军 卓志敏 纪泽宇 李泳昊
1(西安交通大学计算机科学与技术学院 西安 710049)
2(北京电子工程总体研究所 北京 100854)
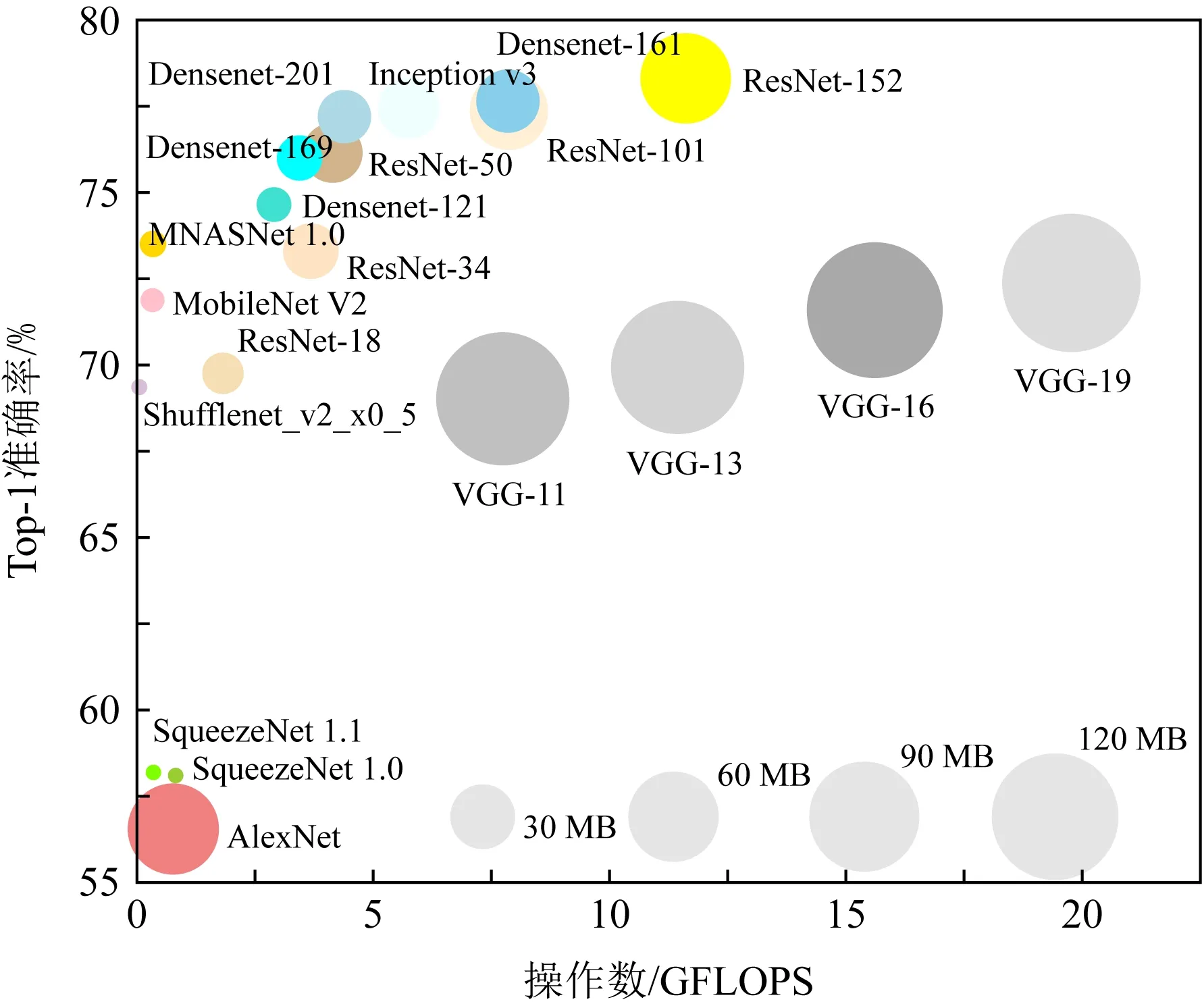
Fig. 1 Top-1 accuracy results of various CNNs on ImageNet图1 CNN模型在ImageNet上的Top-1准确率
卷积神经网络(convolutional neural network, CNN)在图像分类、语音识别和自然语言处理等领域取得广泛应用[1-3].但是,如图1所示,模型准确度的提升是以设计更深、更复杂的模型为代价,这导致了更大的模型文件和更高的计算复杂度[4].在使用基于冯·诺依曼架构的通用处理器进行训练和推理时,“内存墙”问题(memory wall)限制了CPU和片外存储之间的数据传输,成为性能瓶颈.此外,文献[5]的研究表明CPU和片外存储进行一次数据传输的能耗比进行一次32 b浮点数加法运算高约2个数量级,大量的数据传输将产生巨大的能耗,这在边缘计算和物联网等资源受限的应用场景下是不可行的,因此,需要新的体系结构来缓解“内存墙”问题.
内存计算(processing in memory, PIM)通过将计算单元和存储单元紧密结合,从而缓解了“内存墙”的问题[6].基于忆阻器的交叉阵列(memristor-based crossbar),由于具有高密度、低功耗等优势,被广泛应用于加速矩阵-向量乘运算(matrix-vector multiplication, MVM).近期,专注于硬件设计的工程师提出了许多基于非易失性阻变存储(resistive RAM, ReRAM)的硬件加速器设计[7-9].但是,由于数模(digital-to-analog converter, DAC)和模数(analog-to-digital converter, ADC)转换器件的分辨率(resolution)、ReRAM cell的精度和ReRAM交叉阵列的尺寸有限,基于ReRAM的加速器无法直接高效地进行32 b浮点数运算[10].因此,需要使用低精度数值(low-precision data).
模型量化通过降低数据位宽,从而减少计算存储开销,这对基于ReRAM的硬件加速器非常友好[10].ISAAC[7]和PipeLayer[9]都使用16 b的权值和激励,Prime[8]使用8 b权值和6 b激励.但是,这些专注于硬件设计的工作都为权值和激励分配统一的量化位宽,这种粗粒度的模型级量化忽略了神经网络不同层的结构和冗余,无法有效达到模型精度和硬件开销的最佳性能折中.因此,需要更细粒度的量化策略,例如逐层量化(layer-wise quanti-zation).逐层量化的问题使其量化策略空间巨大.假设一个模型有L层(L指卷积层和全连接层的总和),每层的权值和激励可采用M种量化位宽的选择,那么其量化策略的搜索空间为O(M2L).当M和L很大时,在如此大的量化策略空间上手工为每层搜索量化位宽非常耗时.近期研究提出使用自动机器学习(automated machine learning, AutoML)来自动选择量化位宽.文献[11-13]使用基于深度确定性策略梯度(deep deterministic policy gradient, DDPG)[14]的强化学习算法来进行自动量化.但是这些研究存在3个问题:
1) 量化动作本质上是离散数值,而DDPG算法适用于连续动作,因此基于DDPG的方法[11-13]需要动作空间转换步骤;
2) 在文献[11]中,通过手工递减位宽来满足资源约束条件,而不是通过学习获得,并且其搜索时间漫长;
3) 大部分基于强化学习的自动量化是基于FPGA[11-12]和传统冯·诺依曼架构的通用处理器的[15],缺少结合自动量化算法的ReRAM加速器软硬件设计说明.
此外,由于没有成熟的ReRAM加速器芯片,目前主要基于模拟器来评估ReRAM加速器的性能.文献[16-17]提供详细的电路级(circuit-level)仿真,可用于仿真ReRAM加速器的面积、时延和功耗.文献[18]提出一个快速评估ReRAM硬件性能的行为级(behavior-level)模拟器,支持混合精度计算,但不支持自动选择量化位宽.
基于上述分析,本文工作的主要贡献有4个方面:
1) 提出基于近端策略优化(proximal policy optimization, PPO)[19]的自动量化算法,使用离散动作空间,避免动作空间转换步骤;
2) 设计新的包含ReRAM加速器硬件开销和模型精度的奖励函数,使PPO Agent通过学习来自动搜索同时满足资源约束和精度需求的量化策略,不需要手工递减量化位宽步骤;
3) 在遵循ReRAM加速器设计原则的前提下,结合自动量化算法,分析支持混合精度计算的ReRAM加速器的软硬件设计改动;
4) 实验表明:与粗粒度的量化方法相比,提出的方法可以减少20%~30%的硬件开销,而不引起模型准确度的过多损失.与其他自动量化相比,提出的方法自动搜索满足资源约束条件的量化策略,避免手工递减步骤,搜索时间快,并且在相同的资源约束条件下可以进一步减少约4.2%的硬件开销.
1 背景与相关工作
1.1 CNN推理阶段workload分析
为了不产生歧义,首先统一CNN和神经网络(neural network, NN)的术语:
1) CNN卷积核(filter or kernel)的权值(weight)对应于NN中的突触(synapse);
2) CNN中输入/输出特征图(ifmap/ofmap)的激励(activation)对应于NN中的输入/输出神经元(input/output neuron).
CNN推理阶段涉及卷积、池化、非线性激活(sigmoid or ReLU)和归一化等运算.推理阶段的计算负载(workload)主要集中在卷积层和全连接层.式(1)给出了卷积的计算公式,表1列出了相应的参数说明:

Table 1 Parameters of A CONV/FC Layer表1 CONV/FC层参数说明
值得注意的是:

(1)
全连接层可以看成是当式(1)中参数Hin=Kheight,Win=Kwidth,U=1时的卷积层.因此,下面主要分析卷积计算的特点.结合图2绘制的卷积运算的示意图和式(1)分析可得,卷积层计算表现出2个特征:
1) 不连续的内存访问.这是由于卷积核在输入特征图上滑动时,滑窗(sliding window)内的数据是输入特征图的多行数据.因此,不论数据是按行存储还是按列存储,在不进行数据布局优化的条件下,滑窗内的数据内存访问都是不连续的.
2) 数据复用性.卷积运算中的数据复用主要分为权值复用(weight reuse)和输入复用(input reuse).权值复用表现为同一个卷积核的权重被多次用于输入特征图的不同区域.输入复用表现为输入特征图的同一个区域的激励被多次用于不同的卷积核.
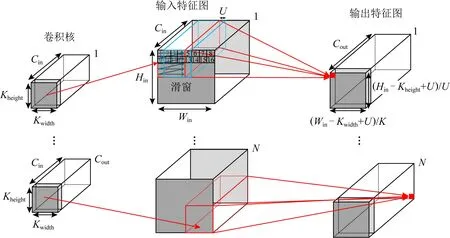
Fig. 2 Convolutions in CNNs图2 CNN中的卷积运算
直接使用for循环实现的卷积计算会引起非常高的缓存缺失,从而导致运算速度非常慢.因此,通常将卷积计算转化为矩阵-矩阵乘(matrix-matrix multiplication)或矩阵-向量乘(matrix-vector mul-tiplication, MVM).现有的深度学习框架(如Tensor-flow和Pytorch)底层都是通过调用通用矩阵乘库(general matrix multiply, GEMM)来实现高效卷积计算.此外,为减少不连续的内存访问并提高数据复用,在调用之前GEMM前,需要对数据进行转换和重排,最常见的转换方法是如图3所示的im2col,这是一种用空间换时间的优化策略.
除了在算法层面上优化卷积运算,实现高效矩阵-向量乘也成为硬件加速器设计的关键.TPU[20]作为工业界最成功的专用硬件加速器,采用65 536个8 b乘法器和加法器,组成脉动阵列(systolic array)架构的矩阵乘法单元,每秒峰值速度为92TFLOPS.TPU在进行计算时,首先将权值参数从内存加载到乘法器和加法器阵列中.然后,从内存加载输入数据,每次执行乘加运算时,都会将结果传递给后面的乘法器,同时进行求和.与传统的基于CMOS实现的加速器相比[21-23],基于ReRAM的硬件加速器的本质是在模拟域实现矩阵-向量乘运算,因此具有速度快、功耗低等优势.下面介绍基于ReRAM的硬件加速器的基本原理.
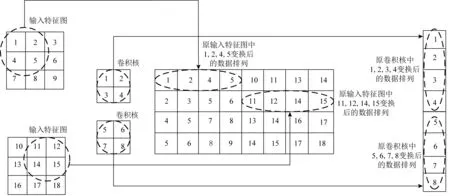
Fig. 3 The data rearrange of im2col图3 im2col的数据重排原理图
1.2 基于ReRAM的硬件加速器设计
基于ReRAM的硬件加速器通常采用分层结构(hierarchical architecture)[7-9].如图4所示,加速器由多个Tile和I/O组成,I/O用于从片外存储加载数据,并通过基于片上通信网络(network on chip, NoC)进行Tile间的数据交换.数据的编排和通信由控制器(controller)负责.Tile由缓冲(buffer)、移位-加法器(shift & adder)、用于计算非线性操作的特殊功能单元(special function unit, SFU)和多个PE(processing engine)组成.PE由输入/输出寄存器、移位-加法器、模数转换器(ADC)和多个ReRAM交叉阵列(ReRAM crossbar array, XB)组成.在推理阶段,输入数据通过DAC转换为模拟域的电压信号,便可通过基尔霍夫定律(Kirchoff’s law),在一个读操作的延迟内完成一次矩阵-向量乘法计算,之后通过ADC将模拟电流信号转为数字信号.和推理相比,神经网络的训练涉及误差和梯度的计算与更新,需要设计额外的外部电路和ReRAM交叉阵列,这使得ReRAM硬件加速器的电路级设计更加复杂.此外,训练阶段频繁地更新操作造成大量的写操作,这给ReRAM的写耐久性带来巨大挑战[24-26].目前,大部分研究使用基于ReRAM的加速器来加速神经网络的推理.ISAAC[7]结合新的数据编码,提出了支持原位乘加操作的基础单元(in-situ multiply accumulate, IMA),并使用基于ReRAM的块内流水线(intra-tile pipeline)设计加速推理.Prime[8]分别设计用于计算(FF subarray)、存储(mem subarray)和缓存(buffer subarray)的3个阵列,避免使用eDRAM缓存和输入输出寄存器.和Prime、ISAAC不同,PipeLayer[9]通过合理的数据复用、层内并行(intra-layer parallelism)和层间流水线(inter-layer pipeline)来提高吞吐量.但是,这些硬件设计都使用较高的数据精度,并且为所有层指定统一的量化位宽,忽略了神经网络不同层的冗余.

Fig. 4 The hierarchical architecture of ReRAM-based accelerator图4 基于ReRAM加速器的分层体系结构
为了快速评估ReRAM加速器的性能,研究人员提出了许多模拟器.文献[16-17]使用C++实现ReRAM加速器的电路级(circuit-level)仿真软件,可用于仿真ReRAM加速器设计的面积、时延和功耗,但不支持混合精度计算.文献[18]使用Python实现一个快速评估ReRAM硬件性能的行为级(behavior-level)模拟器,支持混合精度计算,可用于芯片早期设计阶段的快速仿真,但不支持自动选择量化位宽.
1.3 量化与AutoML
专注于ReRAM加速器设计的硬件工程师通常使用模型级量化.文献[16-17]都采用W2A8的量化策略,即将所有卷积层和全连接层的权值量化为2 b整型,激励量化为8 b整型.但是,这会导致模型准确度下降.手工为每一层确定量化位宽非常耗时.最近,专注于算法研究的工程师提出使用自动机器学习来自动选择量化位宽.文献[11]针对FPGA平台,提出了基于DDPG算法的硬件感知自动量化技术;文献[12]在文献[11]的基础上,也针对FPGA提出基于DDPG的卷积核级别(kernel-wise)的自动量化;文献[13]也在文献[11]的基础上,提出使用基于DDPG 2阶段强化学习,分别用于提高精度和ReRAM的存储利用率;文献[15]针对通用处理器CPU,使用强化学习来进行自动量化.由于DDPG适用于连续动作空间,而量化位宽本质上是离散数值.因此,文献[11-13]都需要动作空间转换步骤,这一转化步骤可以通过使用适用于离散动作空间的算法来避免;此外,文献[11]中的资源受限约束是通过手工递减量化位宽实现的,而不是自动学习的,这可以通过设计新的包含模型精度和硬件开销的奖励函数来实现.文献[27]使用基于神经架构搜索(neural architecture search, NAS)的方法,同时调整神经网络结构和量化策略来优化ReRAM加速器性能.本文不调整神经网络结构,主要探索量化策略对ReRAM加速器硬件开销的影响.
2 基于PPO的自动量化
本文使用基于PPO Agent的actor-critic模型来进行自动量化.下面详细说明状态空间、动作空间、奖励函数、量化方法和Agent的相关实现细节.
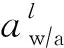

Table 2 Embeddings of the State Space表2 状态空间中的元素
3) 奖励函数(reward function).本文的奖励函数:

(2)
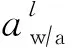
4) 量化方法.训练好的神经网络权值数据类型是32 b浮点数.由于ReRAM cell精度和ReRAM交叉阵列(ReRAM crossbar array, XB)尺寸有限,需要更多的ReRAM cell来表示更高位宽的数据.假设ReRAM设备的精度为1 b/cell,一个x位的整形数据将占用x个cells.本文将浮点数量转换为x位有符号整数(signed integer):
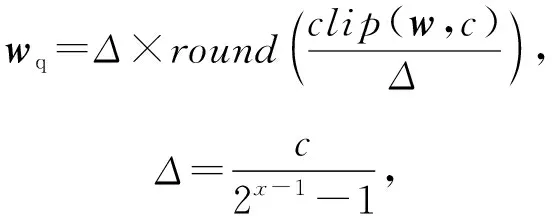
(3)
其中,wq表示量化后的权值,Δ表示量化步长,函数clip用来将权值w截断到[-c,c]的范围内,round表示向下取整.由于激励是非负的,在对激励进行量化时,函数clip会将激励截断到[0,c].参数c的值在训练过程中更新:
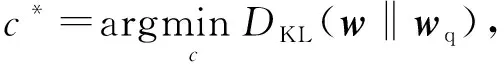
(4)
其中,DKL表示量化前的w和量化后wq的分布的KL散度,其值越小表示w和wq的分布越接近.
5) Agent.传统的基于策略梯度的方法很难确定步长(或学习率),若步长太小,学习很慢;若步长太大,容易学到不好的策略,模型很难收敛.为了解决这个问题,PPO算法在TRPO[28]的基础上,将约束作为目标函数的正则化项,并通过新旧策略的比值来衡量新旧策略间的差异,限制新策略的更新幅度.
本文使用带有截断目标函数的PPO算法(PPO-Clip)来最大化期望奖励.其中actor和critic网络的前2层结构一样,都包含2个隐含层,每层包含256个神经元.由于actor网络用来产生动作,因此,actor网络的最后一层的神经元个数为8-2+1=7,输出表示[2,8]上的概率分布;critic网络的最后一层的神经元个数为1,输出状态价值.在每个时间步,Agent为神经网络的特定层选择量化动作.一个回合(episode)指Agent遍历完所有层,由于神经网络的层数有限,因此回合长度是有限的.在探索过程中,使用ADAM[29]优化器,其中β1=0.9,β2=0.999;actor和critic网络学习率分别设为3×10-4和10-3.通过最小化目标函数来更新actor网络的参数θ:
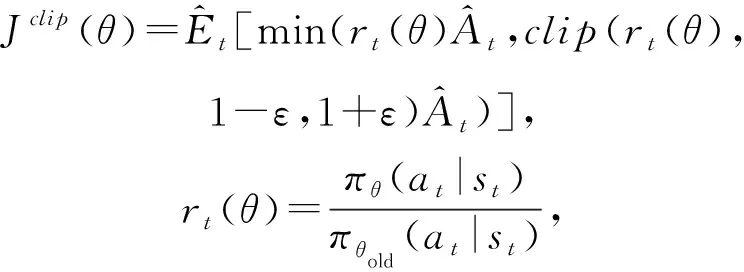
(5)
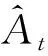
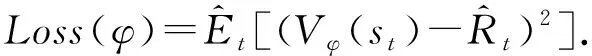
(6)
3 软硬件设计改动
自动量化后的模型的每一层的数据精度不一致,这就需要ReRAM加速器支持混合精度计算(mixed-precision computing).文献[30]设计了一个支持混合精度计算的ReRAM加速器设计,但是不支持自动量化.本节遵循文献[17]给出的ReRAM加速器设计指导,结合文献[18,30-31],介绍支持混合精度计算的ReRAM加速器软硬件设计改动.
3.1 硬件设计改动
权值存储和矩阵分割.当使用ReRAM交叉阵列存储权值时,需要解决2个问题:1)当权值的位宽高于ReRAM cell能表示的范围时,如何表示高比特权值;2)当权值矩阵超过ReRAM阵列大小时,如何存储整个权值矩阵.
对于权值存储,文献[31]指出1 b ReRAM设备更加稳定和可靠,其设备级和电路级的非理想特性对准确度的影响不大.因此,本文使用1 b ReRAM.此外,由于ReRAM设备的电导是正数,无法直接表征负权值,本文使用1组ReRAM交叉阵列来分别存储正负权值.由于量化后的权值的位宽被限制在[2,8],为支持最大8 b权值的存储,需要8组ReRAM交叉阵列.
对于矩阵分割,当权值矩阵大于ReRAM交叉阵列的尺寸时,需要按照ReRAM交叉阵列的尺寸分割权值矩阵,每个ReRAM交叉阵列存储一部分权值.在这种情况下,需要融合各ReRAM交叉阵列的中间计算结果来获得该层最终的输出.给出存储整个神经网络所需要的ReRAM交叉阵列数:
(7)
数据转换模块分析值和激励的位宽会影响数据转换模块的开销.量化后的激励需要通过DACs转换为输入电压,然后进行模拟域的MVM运算.假设DAC的分辨率为ResDAC,输入数据转化的总逻辑时钟数:
(8)
Qout=ResDAC+lb(SizeXB)+1,
(9)
理想情况下,ADC的分辨率ResADC应该等于Qout才能保证将模拟电流精确转换为数字信号.假设ResDAC=1 b,ReRAM交叉阵列的尺寸通常为{128,256,512},那么理想的ResADC应该为{9 b,10 b,11 b}.但是,高分辨率DAC/ADC的功耗很大,这会弱化ReRAM加速器的低功耗优势.因此,不宜选择较高分辨率的ADC,但是,ResADC和Qout间的差将引起硬件一级的量化误差.文献[16,30]表明ADC的分辨率大于等于6 b时,由ADC引起的精度损失可以忽略,因此,后续实验中默认使用1 b DAC和8 b ADC,忽略ADC引起的硬件一级的量化误差.同时为方便和其他ReRAM加速器公平比较,使用128×128的阵列.
其他组件.除了MVM操作外,ReRAM加速器还要支持ReLU和最大池化(max pooling)运算.采用类似文献[30-31]的方法,使用look-up-table(LUT)来实现ReLU,使用寄存器保存序列中的最大值来实现最大池化.此外,为支持混合精度计算,控制器需要有寄存器来存储量化位宽.
3.2 软件设计改动
基于3.1节分析,本文提出如图5所示的软件框架,其工作流程为:①用户(算法工程师或硬件设计工程师)给出模型精度和硬件约束要求;②使用基于PPO Agent的actor-critic模型来进行逐层自动量化,如图5中第l层的权值和激励分别量化为6 b和4 b(简写为W6A4);③待整个模型的量化策略确定后,对模型进行逐层量化;④通过分析每一层的结构信息和量化位宽,将权值矩阵分割,并进行数据映射;⑤通过模拟器评估ReRAM加速器的硬件开销,更新状态和奖励函数;⑥搜索结束,返回最优策略;否则重复步②~⑤.
根据分析,本文基于OpenAI开源的强化学习框架Spinning Up[32]实现支持自动量化的前端训练框架.为了与前段训练框架对接,本文在文献[18]的基础上,使用Python实现一个用于评估ReRAM加速器硬件开销的行为级模拟器.本文目前实现的ReRAM模拟器仅用于评估推理阶段的硬件开销,所使用的时延、能耗和功率模型与文献[18]类似.文献[11]使用查表的方式获取FPGA的硬件开销,而本文的框架中需要调用模拟器来评估ReRAM加速器硬件开销,因此,调用模拟器的次数将影响搜索时间(将在4.2.2节分析).
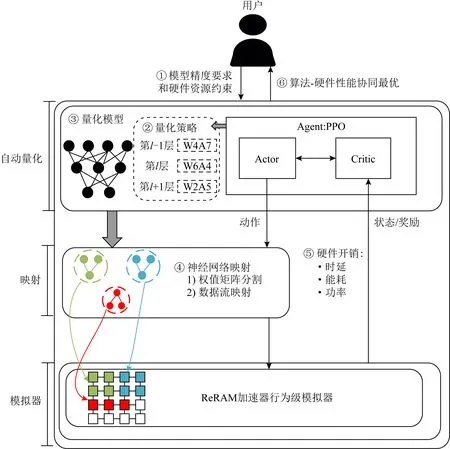
Fig. 5 The software framework of automated quantization图5 自动量化软件框架
4 实验结果与分析
4.1 实验环境与参数配置
实验的测试环境.本文使用的服务器配置信息为英特尔Xeon Silver 4110 CPU@2.10 GHz,内存为32 GB,GPU为NVIDIA Tesla P100,操作系统为Ubuntu18.04.实验用的软件为pytorch-1.6-gpu和基于文献[18]实现的ReRAM模拟器.
表3列出了实验所用的数据集、神经网络模型.本文选择使用LeNet-5和VGG-13这2个不同规模的模型,分别在MNIST和CIFAR-10数据集上实验.由于标准的VGG模型是针对ImageNet数据集设计的,因此,本文修改VGG模型以适用于CIFAR-10数据集.LeNet-5模型结构和文献[33]保持一致.表4列出了模拟器的配置信息,该配置是由3.1节分析得来的.本文使用NVSim[34]来评估ReRAM阵列的硬件开销,ADCs/DACs和减法器的开销直接从文献[7,35]获取,数字化电路和缓冲设计使用和文献[18]一样的评估方法.通过对所有组件的开销求和获得ReRAM加速器的硬件开销.
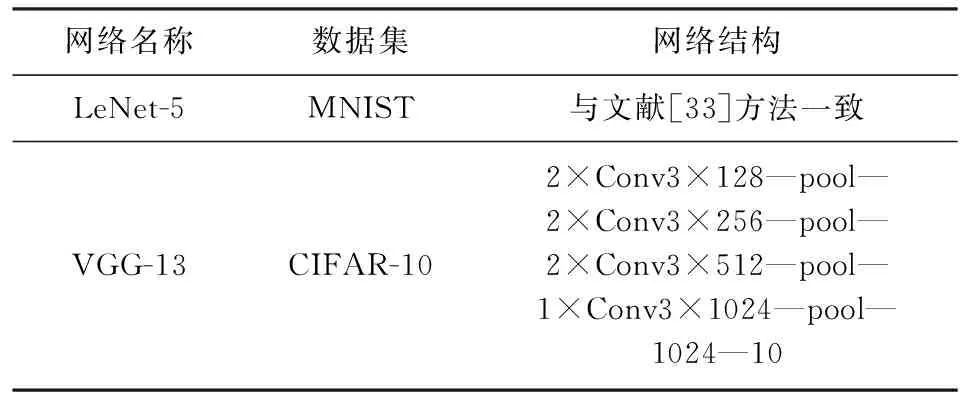
Table 3 The Configuration of the Neural Network表3 神经网络配置
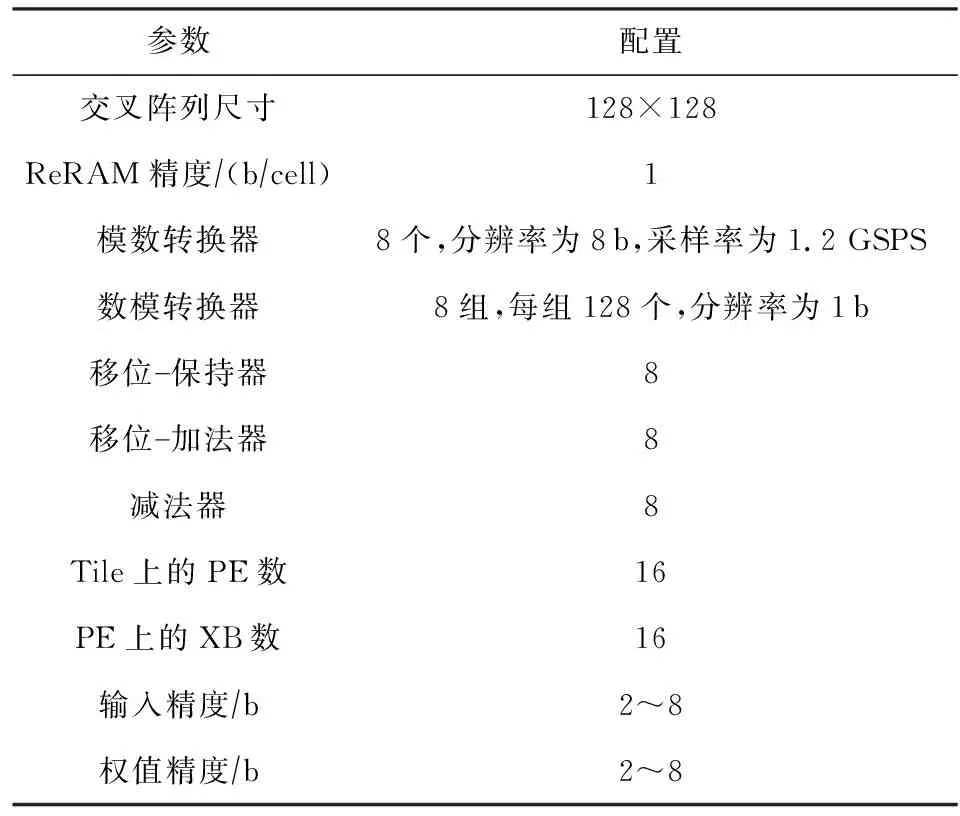
Table 4 The Default Configuration of the ReRAM Simulator表4 ReRAM模拟器默认配置
本文的对比实验主要包含2个方面:
1) 自动量化算法对比.由于基于NAS的方法改变神经网络结构,因此,为了公平比较,本文关注基于强化学习的自动量化算法.采用和文献[11]类似的设置,即神经网络的第1层和最后1层固定量化为8 b.对比文献[36]提出的模型级量化和文献[11]提出的自动量化在不同资源约束下的模型精度和硬件开销.此外,针对文献[11]对比搜索时间.
2) ReRAM硬件加速器对比.选择使用16 b数据精度的ISAAC[7]和PipeLayer[9],以及文献[31]提出的支持混合精度计算的加速器作为基线,对比功率效率(power efficiency).需要指出的是,本文的重点并不是要设计全新的ReRAM加速器,与使用相对较高数据精度的ISAAC和PipeLayer相比,本文强调使用自动量化来减少ReRAM硬件开销.
4.2 实验结果与分析
4.2.1 整体性能
为了证明所提方法的有效性,表5给出了在不同资源约束th下,所提出的方法与模型级量化[36]和基于DDPG的自动量化方法[11]的整体性能对比.从表5中可以看出,与文献[36]相比,所提出的自动量化方法可以减少20%~30%的硬件开销.在相同的资源约束th下,所提出的方法的模型精度与文献[11]方法的相差不大,但是硬件开销cost小于文献[11]方法的.对于LeNet-5模型,所提出的方法主要减少LeNet-5模型在ReRAM加速器上的能耗和功率,但造成1%~3%的精度损失.对于VGG-13模型,所提出的方法可以有效减少VGG-13模型在ReRAM
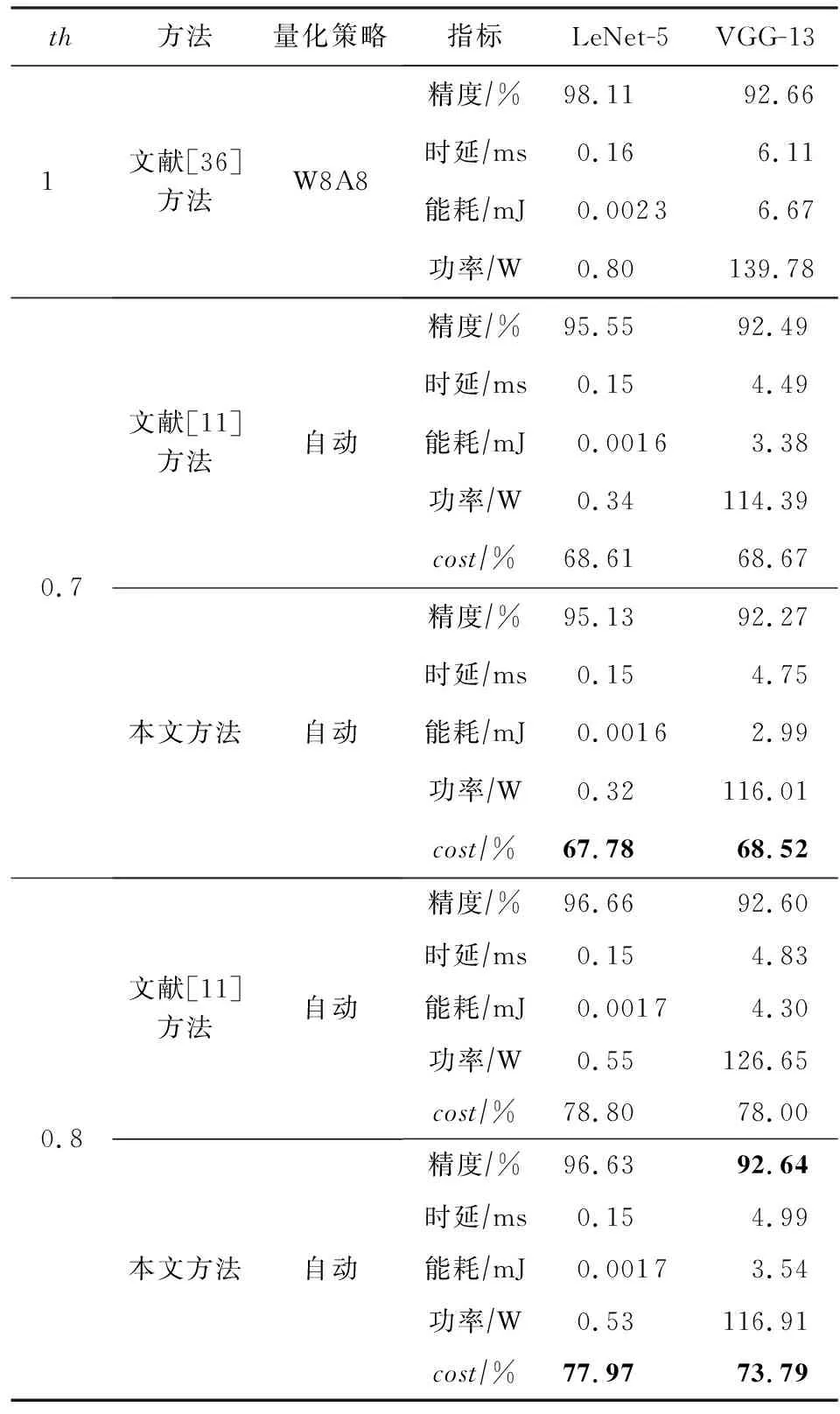
Table 5 Overall Performance for Different NN Models Under Different Resource Constraints
加速器上的硬件开销,且模型精度损失小于1%.与文献[11]方法相比,在相同的资源约束th下,所提出的方法比文献[11]方法可以多减少0.5%~4.21%的硬件开销.
图6显示了不同资源约束下的VGG-13模型精度在600个回合内的变化曲线,从图6中可以看出:1)当th=0.7和th=0.8时,模型精度在300个回合后收敛;但是当th=0.6时,模型精度很难收敛,这是因为在资源约束相对严格时,PPO Agent很难学到同时满足精度要求和资源约束的策略.2)th=0.8时的模型精度整体上高于th=0.7和th=0.6时的模型精度,这是因为在资源约束相对宽松的条件,所设计的奖励函数鼓励PPO Agent提高量化位宽来提升模型精度.
图7显示了当th=0.6,只考虑能耗(β=1,α=γ=0)时,VGG-13模型精度在600个回合内的变化曲线.从图7中可以看出,PPO Agent可以搜索到最优量化策略,并且模型精度收敛速度快(与图6中的虚线对比),这说明当硬件开销cost涵盖多个指标时(α,β,γ),优化变得更加困难.
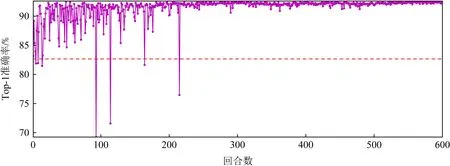
Fig. 7 Variation of Top -1 accuracy when th=0.6,α=γ=0,β=1图7 当th=0.6, α=γ=0, β=1时Top -1准确率的变化
4.2.2 自动量化算法对比
由于文献[12-13]都是在文献[11]的基础上进行的改进,因此本节主要和文献[11]进行对比.为了简化说明,本节以VGG-13模型在CIFAR-10数据集上的测试作为示例,从学习过程、量化策略和搜索时间3个方面进行对比.
1) 学习过程对比.图8显示了资源约束th=0.7时,不同自动量化算法的模型精度和硬件资源开销在300个回合内的的变化曲线.从图8中可以看出,2种方法都能搜索到满足资源约束的量化策略,并保持模型精度.但是,图8(a)显示了本文方法在前200个回合搜到量化策略导致精度和硬件开销波动较大,探索能力更强,这是因为基于PPO Agent的动作是基于最近的随机策略采样获得的,而文献[11]是通过增加噪声来增强DDPG的探索;图8(b)清晰地显示了本文方法在200个回合后,可以学习到满足资源约束的量化策略,这得益于所设计的奖励函数,而文献[11]的奖励函数只与模型精度有关,需要手工递减量化位宽来满足资源约束.
2) 量化策略逐层对比.图9显示不同自动量化方法所搜索到的最优量化策略.从图9中可以看出,2种方法搜到的最优量化策略的不同主要表现在权值的量化位宽上.文献[11]为每一层的权值选择较高的量化位宽(大部分为6 b),每一层的权值量化位宽平均为6.38 b;而本文方法为每一层的权值选择的量化位宽的范围更大(4~7 b),每一层的权值量化位宽平均为6 b,低于文献[11],因此当th=0.7时,本文方法的硬件开销(68.52%)比文献[11]方法的(68.67%)少.
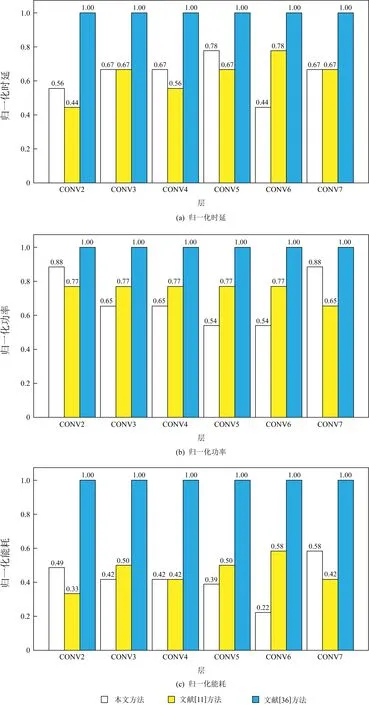
Fig. 10 Layer-wise analysis of hardware cost of different methods图10 不同方法的硬件开销的逐层分析
图10显示了图9中的量化策略对应的归一化的时延(latency)、功率(power)和能耗(energy),其值越小越好.从图10(a)中可以看出,激励的量化位宽越高,时延越大.这与式(8)描述的一致.从图10(b)中可以看出,权值的量化位宽越高,功率越大.从图10(c)中可以看出,除了第2个卷积层(CONV2)和第7个卷积层(CONV7)外,本文方法比文献[11]方法能降低更多的能耗.
3) 搜索时间对比.表6显示不同自动量化方法的搜索时间对比.从表6中可以看出,本文所提出方法的搜索时间比文献[11]方法的少很多,这是由于本文方法在每个回合只调用一次模拟器来评估硬件开销,而文献[11]方法每递减一次量化位宽就需要调用一次模拟器来评估硬件开销.此外,文献[11]方法中的奖励函数鼓励Agent提高量化位宽,以此提高模型精度,但是这容易打破资源约束条件,导致需要更多的手工递减步骤.
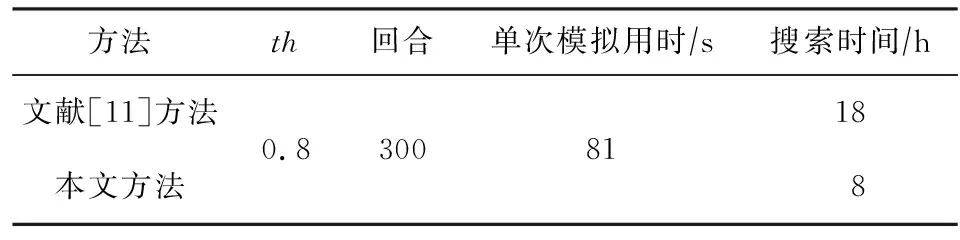
Table 6 Comparison of Search Time表6 搜索时间对比
图11展示了在300回合内,文献[11]方法在进行手工递减步骤前后的硬件开销的对比,其中有131个回合的量化策略超出了硬件约束th=0.8,需要进行手工递减位宽.表7给出了第43回合的手工递减步骤前后的量化策略,结合图11和表7可看出,经过7次递减后,硬件开销cost由90.88%减到79.17%,单在这一回合文献[11]方法比本文方法就需要多调用7次模拟器.当th更小时,这种情况更加严重.
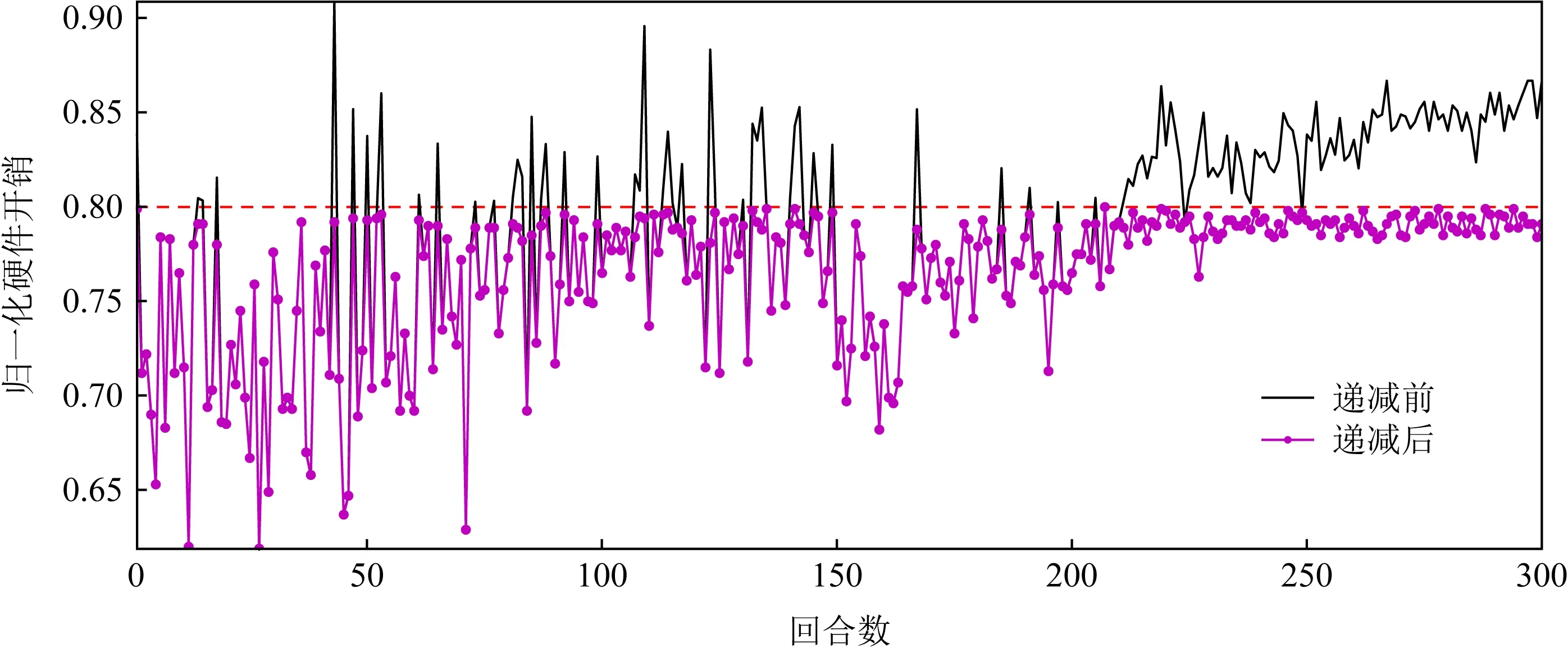
Fig. 11 Comparison of hardware cost before and after manual decrement step in ref [11]图11 文献[11]方法手工递减步骤前后硬件开销对比

Table 7 Comparison of Quantization Policy Before and After Manual Decrement Step in Epoch 43
4.2.3 和其他ReRAM加速器对比
表8对比了不同ReRAM加速器的功率效率.本文所提方法的功率效率为454.8GOPS/(s×W),低于ISAAC的627.5GOPS/(s×W),但高于PipeLayer的142.9GOPS/(s×W).文献[31]提出支持混合精度计算的ReRAM加速器设计,并使用贪婪策略选择量化位宽.和文献[31]相比,本文提出的自动量化算法将ReRAM加速器的功率效率提升了近1.50倍.
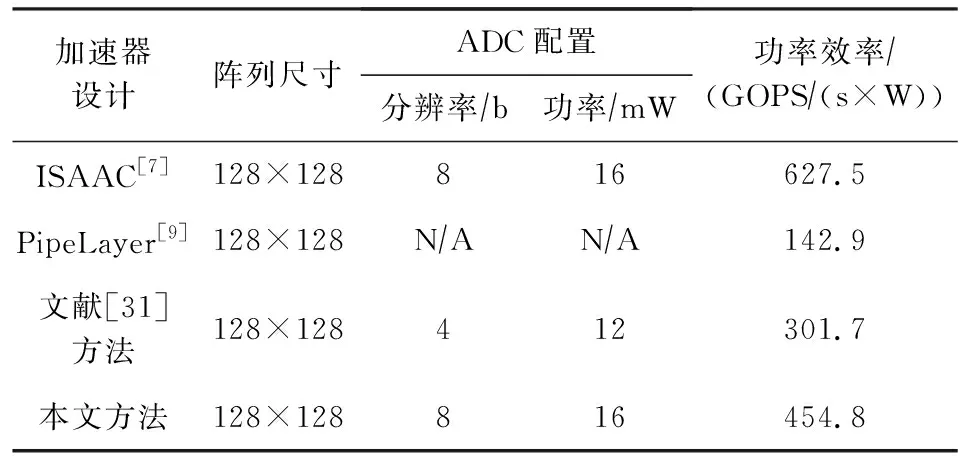
Table 8 Comparison of Different ReRAM Accelerator Designs on Power Efficiency
5 结 论
本文提出基于PPO的ReRAM神经网络加速器自动量化.使用PPO Agent来进行自动量化,通过设计新的奖励函数,实现了模型精度和硬件开销的最佳性能折中,并结合所提出的自动量化算法,给出ReRAM加速器的软硬件设计改动.实验结果表明:与模型级量化[36]相比,本文提出的方法可以减少20%~30%的硬件开销.与文献[11]相比,本文提出的方法通过学习来自动搜索满足资源约束条件的量化策略,避免手工递减步骤,并且搜索时间快.与文献[31]相比,本文提出的方法将ReRAM加速器的功率效率提升了近1.50倍.这为量化算法和ReRAM加速器的协同设计提供了借鉴.
作者贡献声明:魏正提出研究思路,负责算法与实验设计,并撰写论文;张兴军负责技术方案设计与最终版本的修订;卓志敏负责行政和材料支持;纪泽宇负责方案讨论与论文校对;李泳昊负责分析数据与辅助实验.
猜你喜欢
现代装饰(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
小哥白尼(趣味科学)(2022年5期)2022-08-15
现代仪器与医疗(2022年3期)2022-08-12
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
科技视界(2016年1期)2016-03-30
物联网技术(2015年7期)2015-07-21
