
基于语义层次建模的跨语言知识单元迁移方法
2022-03-15 09:45管子键颉夏青孙利娟
计算机仿真 2022年2期
管子键,吴 旭,3,颉夏青,孙利娟
(1.北京邮电大学网络空间安全学院,北京100876;2.可信分布式计算与服务教育部重点实验室,北京100876;3.北京邮电大学图书馆,北京100876;4.北京邮电大学经济管理学院,北京100876)
1 引言
不同语种知识在互联网中深度融合,形成的多语言知识库一方面弥补了单语言知识图谱知识不完备的问题,另一方面又为不同语言的知识重叠和知识互补研究带来了新的挑战。因此将迁移学习的思想就利用到跨语言知识图谱研究中,其核心思想是利用已知的跨语言对齐语料,基于语义特征表示和跨语言迁移模型来实现从一种语言到另一种语言的迁移学习,构建出语义丰富的跨语言知识图谱。跨语言知识图谱作为大数据时代的知识引擎,能够提升数据获取速率,降低知识应用门槛,提高知识利用效率,更好地服务于人工智能的各个领域。对跨语言领域知识的迁移更有助于多语言者工作学习和网络空间的内容治理。
近年来,基于嵌入的技术越来越收到研究者的关注,知识图谱嵌入是将实体、属性和关系等编码到一个低维的空间中,表示为向量(或矩阵、张量),通过嵌入之间转换关系的有效计算,完成对知识迁移。虽然基于嵌入的技术可以帮助提高单语知识的完整性,但对于跨语言知识在很大程度上还未被深度探索,匹配同一实体的语际链接(Inter-Lingual Links,ILLs)和表示相同关系的三元组对齐(Triple-Wise Alignment,TWA)问题,都对解决多语言知识库的知识融合和独立演化问题有着巨大帮助。由于以下几个原因,使得这种语际知识转换比单语实体链接更加困难:(1)各语言表达习惯和书写方式的不同;(2)各语言实体含义范围不尽相同;(3)跨语言已知对齐知识只占知识库的一小部分。此外,跨语言知识迁移对单语言知识图谱的完整性有着更高的要求。
为解决领域内跨语言知识的迁移学习问题,本文提出了一种跨语言领域知识单元迁移方法,通过基于语义层次建模的知识嵌入和跨语言知识单元对齐技术,完成对领域内知识从一种通用语言到一种小众语言的迁移,扩展了语料和标注稀疏的小众语言上的领域知识,同时也在一定程度上提升了跨语言知识单元对齐任务的表现。
2 相关工作
近年来,已有不少针对单语言的知识图谱嵌入模型被提出[16-23],单语知识图谱嵌入研究为知识图谱表示领域奠定了基础。现有跨语言知识图谱的不少研究就是基于单语知识图谱嵌入开展的。
多语言知识图谱对齐的主要目的是利用知识图谱嵌入相关技术,借助图谱中各类信息,完成图谱中各元素对齐,实现跨语言知识融合扩展。近些年有不少多语言知识图谱对齐技术被提出,主要分为以下几类:
1)基于结构信息的方法:其基础思想均为利用知识图谱的图结构信息,对跨语言知识图谱进行向量表示,从而完成实体对齐,不同的是其嵌入模型和对向量表示的利用方式不同。
MTransE[1],基于TransE模型[16]分别编码各个语言的实体和关系至一个独立空间,然后学习不同表示空间之间的转换,该模型保留了原语言空间的结构,提供了三种空间转换的方式:基于距离的轴校准、基于向量空间的向量转换、基于向量空间的线性变换。
BootEA[10]模型优化了负例选择方式,由以往的随机选择改为选择余弦距离最近的多个实体中的一个,通过自举的方式,为添加新实体对的操作增加了编辑和删除实体对的能力,能有效地解决IPTransE中错误信息的传播。
MtransD[4]模型是基于TransD[18]的知识嵌入模型,发挥嵌入向量语义信息和空间信息分离的特性,利用对齐三元组的语义相同、空间不同特性,实现跨语言实体的对齐。但计算复杂度较高。
2)融合额外信息的方法:除利用知识图谱的结构信息外,实体的属性信息、描述信息同样蕴含着深层次的语义信息。
JAPE[6]在结构之外利用了实体的属性信息,属性部分借鉴Skip-gram模型的思想,将对齐实体的属性作为当前实体属性的上下文进行学习,联合结构嵌入和属性嵌入,根据余弦相似距离得到最终结果。
KDCoE[7]利用了实体的描述信息,基于多语言的平行语料训练跨语言词向量,使用注意力门控的循环单元编码器得到实体描述嵌入向量,结构部分借鉴MTransE思想,两个模块共同训练一个迭代过程,并使用产生的新的跨语言对齐链接扩展训练集。
GCN-Align[13]基于GCN模型分别对多语言知识图谱的关系结构和属性进行编码,使用GCN来建模实体间的等价关系,通过实体-实体的邻接矩阵编码当前节点的特征向量。使用one-hot向量填充实体-属性邻接矩阵,使用GCN卷积编码属性信息,最后使用两部分表示共同计算实体间的跨语言距离。
REA[14]则是首次提出跨语言实体对齐中的噪音问题,提出一种基于迭代训练的除噪算法,从而进行鲁棒的跨语言知识图谱实体对齐,对后续跨语言实体对齐的去噪研究具有重要的开创性意义。
多语言迁移学习也被广泛用于知识问答、机器翻译等领域。M Bornea等人[15]提出通过在语义空间中拉近多语言嵌入来改善跨语言迁移策略,提出的两种新策略显著提高了跨语言(零资源)迁移的性能。
融合额外信息的实体对齐方法需要原始的多语言知识图谱具有除关系结构信息以外的其它更多信息,这对本就语料匮乏的领域小语种知识图谱增加了额外的负担,因此如何仅利用知识图谱的关系信息,高效且高质地完成对跨语言图谱的建模和知识的迁移就成为了当前亟需解决的问题。
3 基于语义层次感知的跨语言知识单元迁移模型
基于语义层次感知的跨语言知识单元迁移模型(Semantic Hierarchy-Aware based Cross-lingual Knowledge Units Transfer Model,SHACUT)的基本思想是通过知识图谱中知识单元的不同语义层次,将不同语言的知识图谱嵌入各自的向量空间,利用种子对齐库,挖掘出跨语言向量空间之间的转换,通过计算知识单元距离和置信度,完成链路预测和图谱补全,实现跨语言实体、关系、属性等知识单元(Knowledge Unit)的迁移(如图1)。

图1 SHACUT模型基本原理流程图
3.1 多语言知识图谱

本文所提出的模型由两个部分组成,一部分是对每种语言实现基于语义层次感知的知识模型,另一部分是利用现有的少量对齐集学习跨语言转换的迁移模型。
3.2 知识模型
知识模型(Knowledge Model,KM)是基于语义层次感知的知识表示,借鉴了HAKE[20]模型对于实体和关系的建模方法,本文将单语知识图谱中的知识单元根据语义层次的不同分为了两类,即:
1)层次结构不同级别的知识单元。例如:“哺乳动物”和“狗”、“树”和“棕榈树”;
2)层次结构相同级别的知识单元。例如:“狗”和“猫”、“棕榈树”和“杨树”。
为了对这两类知识进行建模,知识模型将同一语言的知识单元嵌入到一个极坐标系中,即一个知识单元的嵌入表示由模量部分和相位部分组成,图2为知识模型的一个简单示例。

图2 SHACUT知识模型的简单示例
用em(e为h或t)和rm表示知识单元的模部分的嵌入,用ep(e为h或t)和rp表示知识单元的相位部分的嵌入。在极坐标系中,径向坐标用于对不同语义层次的知识单元建模,角度坐标用于对同一语义层次的知识单元建模,两者组合实现语义层次感知的知识单元建模。
3.2.1 模部分
模部分的嵌入主要是对不同语义层次的知识单元进行建模,受“树”数据结构的启发,可以将具有关系的不同层次的知识单元看作“树”的各个“叶子”节点,用节点(知识单元)的深度来建模不同层次的知识单元,因此,模量信息可以对上述类别1)中的知识单元进行建模。hm和tm的向量表示为hm和tm,则模部分可以表示为
hm∘rm=tm
(1)
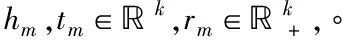
dr,m(hm,tm)=‖hm∘rm-tm‖2
(2)
其中,‖·‖2表示l2范数,dr,m(hm,rm)表示在关系r下,头知识单元h和尾知识单元t的模部分的距离。允许知识单元的嵌入项为负,不允许关系的嵌入项为负,即[rm]i>0,因为知识单元的嵌入可以帮助预测两个知识单元之间是否存在关系。
对于正例三元组(h,r,t1)和负例三元组(h,r,t2),目标是最小化dr,m(hm,t1m),最大化dr,m(hm,t2m),使得dr,m(hm,t2m)尽可能地大于dr,m(hm,t1m),以最大差异化正负三元组。此外,考虑到树结构的特性,层次结构较高的知识单元的模量尽可能得小,这样更接近于树的根。
只使用模部分来表示知识图谱,那么类别2)中的知识单元都将具有相同的模量,这使得这些知识单元很难被区分,因此,需要一个新的模块来对类别式(2)中的知识单元进行建模。
3.2.2 相位部分
相位部分的嵌入主要是对同一语义层次上的知识单元进行建模。受同一圆上的点(即具有相同的模量)可以相对于圆心具有不同的角度的启发,可以将同一语义层次上的知识单元看到是同一圆上不同相位上的节点,以此来建模类别式(2)中的知识单元。hp和tp的向量表示为hp和tp,则相位部分可以表示为
(hp+rp)mod2π=tp
(3)
其中,hp,rp,tp∈[0,2π)k,相应的距离函数为
dr,p(hp,tp)=‖sin((hp+rp-tp)∕2)‖1
(4)
其中,‖·‖1表示l1范数,sin(·)表示为每个输入的元素进行正弦函数操作,由于相位具有周期性,因此这里使用正弦函数来测量相位之间的距离,dr,p(hp,tp)表示在关系r下,头知识单元h和尾知识单元t的相位部分的距离。
3.2.3 知识模型表示
结合模部分和相位部分,知识模型可以将知识单元映射到极坐标系中,其中径向坐标和角坐标分别对应于模部分和相位部分,即知识模型将一个知识单元e表示为[em;ep],其中em和ep分别由模部分和相位部分生成,[·;·]表示两个向量的拼接。可以发现,[[em]i;[ep]i]是极坐标系中的一个2维点。可以将SHACUT的知识模型表示如下

(5)

dr(h,t)=dr,m(hm,tm)+λdr,p(hp,tp)
=‖hm∘rm-tm‖2+λ‖sin((hp+rp-tp)∕2)‖1
(6)
其中,λ∈,为模型学习得到的参数。相应的得分函数为
fr(h,t)=-dr(h,t)=-dr,m(hm,tm)-λdr,p(hp,tp)
(7)
当两个知识单元具有相同的模量时,模部分dr,m(hm,tm)=0,但相位部分dr,p(hp,tp)可以相差很大。通过模部分和相位部分的线性叠加可以建模类别式(1)和式(2)中的知识单元,实现基于语义层次的建模。
本文采用了HAKE原始论文中关于对dr,m(hm,tm)的优化,即在dr,m(hm,tm)中加入混合偏差(mixturebias)[20],以此来提高SHACUT知识模型的性能,优化后的dr,m(hm,tm)如下所示

(8)

3.2.4 知识模型损失函数
为了得到更好的训练结果,这里采用RotatE[19]模型中使用的负采样损失函数和自我对抗训练方法,最终单语知识模型的损失函数为
Sa,KM=S正-S负
(9)

(10)

SKM=Sa,KM+Sb,KM
(11)
3.3 迁移模型
迁移模型(Transfer Model,TM)是为了构造三元组对(Ta,Tb)∈A(La,Lb)在各自向量空间之间的变换,将跨语言对齐问题看作不同嵌入空间的拓扑变换,基于知识模型得到的各语言三元组嵌入空间,推导得到向量空间之间的线性变换,通过计算变换后知识单元的距离和置信度,得到新的对齐知识单元,从而进行链路预测和图谱补全。

(12)


(13)
对于跨语言知识图谱(GLa,GLb)以及对齐种子库A(La,Lb),首先分别对各自语言的KG进行基于语义层次建模的嵌入表示,再通过对子种子的链接训练得到GLa→GLb的向量空间转换矩阵,SHACUT的目标是最小化损失函数
S=SKM+αSTM
(14)
其中α是SKM和STM的权重超参数。
在实际应用中,跨语言对等体的查找通常是通过计算潜在对等体之间的距离来评估对齐的置信度,置信度越高就表明搜索到的目标知识单元是源知识单元的对等体的可能性越高,知识单元对的置信度con∈(0,1]

(15)
根据置信度大小,得到新的对齐知识单元,通过新的对齐知识单元可以预测源KG可能存在的潜在关系,实现“实体-关系-实体”、“实体-属性名-属性值”等的链路预测以及知识不完备的图谱补全,从而完成跨语言知识单元迁移。
4 实验
4.1 实验设计
在实际应用中,很多时候领域小语种知识图谱比较稀疏,不具备丰富的实体描述和属性信息,这就很难通过融合额外信息的跨语言知识单元对齐方法对领域稀疏小语种知识图谱进行对齐和补全,因此,通过对图谱结构信息的深度语义挖掘就成为一种行之有效的方法。本文所提出的SHACUT模型即是解决仅包含结构信息的跨语言知识图谱迁移问题。
为了最大程度地贴近实际应用场景,本文设计了两部分实验,一是在同样是解决仅针对结构信息的跨语言知识图谱迁移的MTransE模型上,二是在本文提出的模型上,同时对公开通用语种知识图谱和领域小语种知识图谱建模进行对照实验,通过纵向和横向两个维度的分析,验证本文所提SHACUT模型在仅包含结构信息的公开通用知识图谱上的正确性和在仅包含结构信息的领域小语种知识图谱上的有效性。
4.2 数据集
为了验证本文所提出模型的效果以及对于领域知识的适用性,本节选择包含英语(en)和法语(fr)KG的WK3l知识库[1]来验证SHACUT模型在公开数据集上的效果,选择包含中文(zh)和阿拉伯语(ara)KG的military领域知识库来验证SHACUT模型在领域知识集上的适用性。WK3l知识库中的多语言KG的数据为DBpedia’s dbo:Person领域,其中部分三元组通过验证知识单元的ILLS和DBpedia本体在某些关系上的多语言标签实现对齐,本文以WK3l_60k数据集作为实验对象。military领域知识库的多语言KG的数据主要由军事武装知识构成,其中部分三元组通过机器翻译后的人工审核校对实现对齐(见表1)

表1 WK3l_60k和military数据集数量统计
4.3 评价指标
参考此类任务模型的评价指标,本文使用hits@k、MR(Mean Rank)、MRR(Mean Reciprocal Rank)来评估模型的性能。知识单元对齐任务中的hits@k指标表示当前语言所有知识单元匹配知识单元时,真实的对齐知识单元在匹配对齐知识单元置信度排序前k个的概率,单位为%;MR指标表示所有真实的对齐知识单元在匹配对齐知识单元置信度排位的平均值;MRR指标表示所有真实的对齐知识单元在模型得出的匹配对齐知识单元置信度排位的倒数的平均值。本实验观察和比较了hits@1、hits@10、hits@50、MR、MRR的结果。
4.4 公开通用语种数据集上的知识单元迁移实验
此实验的目的是在公开数据集WK3l_60k上通过匹配来自不同语言的对齐知识单元来证明SHACUT在公开通用语种数据集上的有效性。由于匹配对齐知识单元的候选空间很大,该实验主要思想是强调对一组候选对齐知识单元进行排序,并非直接获得最佳答案。为了显示SHACUT模型的优越性,本文使用使用度广、适用范围大、且同样不使用额外信息辅助的MTransE模型作为对比实验。
4.4.1 模型参数设置
实验中的知识单元向量和关系向量均采用随机初始化。经过多次实验,对于WK3l_60k数据集,在SHACUT模型上的最佳配置为:知识模型:λ=0.01,k=[200,200],训练周期epoch=10000,批处理大小batch_size=256;对齐模型:λ=0.01,k=[200,200],训练周期epoch=500,批处理大小batch_size=128,每50epoch对学习率λ削减一半。在MTransE模型上的最佳配置为:知识模型:λ=0.01,k=100,训练周期epoch=400,批处理大小batch_size=128;对齐模型:λ=0.01*2.5,k=100,训练周期epoch=1200,批处理大小batch_size=128,每50epoch对学习率λ削减一半。对于两个模型的知识模块和对齐模块均使用l_2范数,对于知识模型,训练集、验证集、测试集的抽取比例均为:0.8:0.05:0.15,对于对齐模型,训练集、测试集的抽取比例均为:0.75:0.25。
4.4.2 实验结果与分析
表2展示了SHACUT和MTransE模型在WK3l_60k数据集(英-法)上的知识单元迁移效果,表明本文提出的SHACUT模型在跨语言迁移任务上具有优势,优于MTransE模型。

表2 SHACUT和MTransE模型在WK3l_60k数据集(英-法)上的实验结果
具体分析,可以观察到以下几点:
1)SHACUT模型在hits@k的各项指标上分别高出14.83%、10.86%、13%,充分表明了在WK3l_60k数据集(英-法)上进行的跨语言知识单元匹配的有效性,其中hits@1指标更是高出近15%,更加凸显出SHACUT模型的精准度。有超过42%的知识单元被命中在排名前50,体现出SHACUT模型的优势。
2)在MR指标和MRR指标的结果上,SHACUT的结果不如MTransE,高152.14,但考虑到WK3l_60k数据集(英-法)是通用数据集,其中包含的数据领域分布较广,这对基于语义层次建模的SHACUT十分不友好,但总得来看,SHACUT能够较好地完成具有语义层次深度的知识单元的跨语言匹配任务,但对于知识图谱中悬挂点知识单元的对齐匹配稍显薄弱,主要归功于MTransE的知识模型基于翻译的建模,在嵌入空间引入前后相关节点信息很好地解决了悬挂点问题。
4.5 领域小语种数据集上的知识单元迁移实验
此实验的目的是在领域知识数据集military上通过匹配对齐跨语言知识单元来证明SHACUT在领域小语种数据集上的有效性。military领域数据由中文和阿拉伯语知识图谱组成,中文和阿拉伯语的语言表达方式、书写方式、语言学特点均与公开通用的英语、法语等有着巨大差异,且中文和阿拉伯语两种语言之间本身就有着巨大差异,这就为本文提出的SHACUT模型带来了巨大挑战。此外,本文所使用的军事领域知识数据集具有稀疏度高、相关性大、语义层次深等特点,即知识单元间关系较为稀疏,知识单元基本属于同一领域,这直接考验 SHACUT模型的语义层次建模效果。为了验证SHACUT模型对于此领域特点和此类语言特性数据的有效性,本文同样使用MTransE模型作为对比实验。
4.5.1 模型参数设置
经过多次实验,对于military数据集,在SHACUT模型上的最佳配置为:知识模型:λ=0.00001,k=[500,500],训练周期epoch=80000,批处理大小batch_size=512;对齐模型:λ=0.01,k=[500,500],训练周期epoch=500,批处理大小batch_size=128,每50epoch对学习率λ削减一半。在MTransE模型上的最佳配置为:知识模型:λ=0.001,k=100,训练周期epoch=400,批处理大小batch_size=128;对齐模型λ=0.001*2.5,k=100,训练周期epoch=1200,批处理大小batch_size=128,每50epoch对学习率λ削减一半。对于两个模型的知识模块和对齐模块均使用l_2范数,训练集、测试集的抽取比例均为:0.75:0.25。
4.5.2 实验结果与分析
表3展示了SHACUT和MTransE模型在military数据集(中-阿)上的知识单元迁移效果,表明本文提出的SHACUT模型在跨语言迁移任务上具有优势,整体优于MTransE模型。

表3 SHACUT和MTransE模型在military数据集(中-阿)上的实验结果
具体分析,可以观察到以下几点:
1)SHACUT模型的各项指标均优于MTransE,表明SHACUT能够更好地对military数据中-阿知识图谱进行建模。其中hits@1指标远高出MTransE的该项指标41.6%,表明通过SHACUT匹配得到的对齐知识单元为真实对齐知识单元的概率更大,hits@10指标相比高出18.18%,hits@50相比高出3.79%,同样可以证明上述结论。对于MR指标,SHACUT模型高出253.76,可以直接表明SHACUT模型对于military数据集(中-阿)匹配知识单元效果整体要高于MTransE。
2)SHACUT模型hits@k指标随着k值的增加,增速相对于MTransE模型变缓,考虑到military数据集知识图谱稀疏度高,相关性大,语义层次分散的特点,表明SHACUT模型对于知识图谱的语义层次建模有着很好的效果,但由于知识单元间关系较为稀疏,很难对所有知识单元进行语义层次的建模,多语言知识单元在向量空间上的分布更为聚集,游离知识单元较多。
4.6 SHACUT模型跨数据集实验结果的横向对比
通过横向对比SHACUT模型在WK3l_60k数据集的英-法KG和military领域数据集的中-阿KG上的实验,可以发现在military领域数据集(中-阿)的结果相对于WK3l_60k数据集(英-法)的结果,hits@k指标的各项值分别高出15.83%、10.26%、12.02%,同时平均排名MR指标低211.9,可以表明SHACUT模型针对语义层次的建模具有显著的优势,巧妙地规避了语言本身在表达方式、书写方式、语言学特点等方面的差异性,很好地保留了各自语言的语义层次结构,同时更加有效地抽取单语知识的领域特征,对领域相关性高、语义层次深的知识图谱有着更好的结果。证明SHACUT模型能更好地捕捉深层次的语义信息,对领域相关性高的知识单元能做出更加精准的区分,以减少跨语言知识单元迁移过程中的邻近干扰,从而更好地完成领域跨语言知识迁移任务。
5 总结与未来工作
本文借鉴了HAKE模型基于语义层次感知的实体嵌入思想,将其引入到跨语言领域知识单元迁移任务中,通过在公开通用语言数据集和领域小语种数据集上的实验结果分析,可以发现本文所提出的SHACUT模型在解决无额外信息情况下的跨语言知识单元迁移问题,尤其是具有领域特点的跨语言知识迁移问题,能够很好地发挥其语义层次建模的优点,保留了单语知识图谱的语义层次信息,结果令人欣喜。但也发现可能会丢失小部分图谱结构信息,主要集中在对悬挂点知识单元的建模问题上。但这也指出了下一步工作和改进的可能,特别是,如何在不添加额外信息的情况下,更好地对知识图谱的语义层次和结构信息建模,将MTransE对图谱结构的建模与SHACUT对语义层次的建模相结合是一个有意义的研究方法,为跨语言领域知识迁移提供更加有效的工具。
猜你喜欢
军事文摘(2022年16期)2022-08-24
舰船科学技术(2022年11期)2022-07-15
新高考·高一数学(2022年3期)2022-04-28
新城乡(2018年6期)2018-07-09
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
长江学术(2015年1期)2015-02-27
中国报道(2009年12期)2009-01-15
