
基于异构数据的农产品冷链物流节点部署仿真
2022-03-15 09:45滕志霞
计算机仿真 2022年2期
张 慧,滕志霞
(1.吉林建筑科技学院管理工程学院,吉林 长春 130114;2.东北林业大学信息与计算机工程学院,黑龙江 哈尔滨 150040)
1 引言
农产品因具有较强的季节性与易腐烂性[1],对物流存储、运输条件具有极高的要求,但同时也促进了物流需求与模式的转变。为适用于农产品运输,作为特殊物流形态的冷链物流[2]模式脱颖而出,广受关注的食品质量安全问题更是进一步推动了冷链物流形态的发展,该模式通过摆脱传统物流在生产加工、库存仓储、配送运输等一系列限制条件[3],令消费者的品质要求得到满足,并慢慢演变为食品物流领域的翘楚。
以助推农产品冷链物流发展、完成冷链物流升级转型为目标,有学者提出物流节点的优化布置方法。文献[2]提出,以各成本作为目标函数,结合2-opt局部搜索的改进蚁群算法,实现物流低碳配送的路径优化;文献[3]提出,以最短路径、共同弧段和通道运能为重点构建多层级的物流节点协同布局模型,并结合点线能力约束进行优化;文献[4]提出,利用改进的蚁群算法搜索物流节点,并寻找到最优的物流配送路径。但上述方法普遍没有考虑到节点资源数据的全面性,对配送量等没有深入分析。
为此,本文基于异构数据,构建一种农产品冷链物流节点部署方法。引用可扩展标记语言文档,通过中间数据库完成转变,减少所需模块数量,并在一定程度上强化扩展性;通过集成物流异构数据,使物流链环环相扣,增加协作默契度,改善了物流节点部署时的内部数据覆盖的完整性;添加可视化图形交互功能,便于使用者运用XQuery语言查询功能;分析粒子群优化算法下参数取值范围,抑制负面影响发生,确保农产品冷链物流节点部署结果为最佳方位。该部署策略有助于降低物流成本,保证产品品质。
2 物流异构数据集成
物流初始阶段中尚未树立供应链理念,也不存在各环节间的共同协作关系,导致物流信息形成了规模庞大的异构数据源,对当前物流参与者间的协作关系产生了较大影响。为满足实际的物流业务需求与应用要求,引用XML[5](Extensible Markup Language,可扩展标记语言)文档,构建一个如图1所示的异构数据集成模型,强化物流各环节关联,增加协作默契度。

图1 异构数据汇总模型
该模型由集成中心与服务模块完成客户访问与操作,通过触发器机制[6]同步管理各物流环节信息与集成中心信息,模型结构组成如下所述:
1)数据源模块:用于生成信息与交换信息。信息从各类数据库中生成;交换信息包括传输、申请、采集等。
2)转变模块:用于双向转变数据源与可扩展标记语言文档。从数据源到可扩展标记语言文档的转变是将业务数据源封装为可扩展标记语言文档格式,逆向转变是完成业务数据源中可扩展标记语言文档格式数据的存储。
以数据源到可扩展标记语言文档的转变顺序为例,描述具体转变流程。根据数据源的相关性、字段等界定,得到XSD(XML Schemas Definition,可扩展标记语言文档结构定义)文件,将在数据源内获得的数据转变为可扩展标记语言文档,依据可扩展标记语言文档结构定义文件,完成可扩展标记语言文档节点数据界定,如图2所示。

图2 数据源到可扩展标记语言文档转变模型示意图
转变阶段里各数据源具有各不相同的数据库框架,所以,针对每个数据库的框架形式,采取对应的识别方法区别内部数据结构,按照可扩展标记语言文档结构,统一转变数据格式,将其存储在可扩展标记语言文档内。转变步骤如图3所示。

图3 数据源到可扩展标记语言文档转变流程示意图
利用SQL[7](Structured Query Language,结构化查询语言)提取数据库中相关的物流信息,通过XQuery语言查询存储于可扩展标记语言文档内的可扩展标记语言文件。经添加可视化图形交互功能,让使用者更熟悉XQuery语言查询功能。可扩展标记语言文档的查询流程如图4所示。

图4 可扩展标记语言文档查询流程示意图
3)集成模块:用于制定数据模式、提供相关服务。为满足不同用户需求,在自设的数据模式基础上,给予模式转变服务,比如转变模式的映射机制与规则、共享模式的映射任务等。
4)应用模块:用于实现使用者的程序运用。
由此,实现了对农产品冷链物流数据的集成,为优化冷链物流节点资源的配置与整合,提高整体冷链物流系统的运行效率提供保障。
3 基于异构数据的农产品冷链物流节点部署
经济发展大幅提升了优质农产品的需求量,各申请点需求量与冷链物流中心流通量也随之上升,导致冷链物流中心容量无法满足申请点需求;增设提供点与申请点,将更改整个冷链物流结构;若冷链物流中心选取不合理,会增加物流成本与质量损耗。因此,为解决以上问题,基于适应性、协调性、战略性以及经济性等原则,结合经过集成的物流异构数据,提出一种冷链物流节点部署方法,取得最优的冷链物流节点布局,使与日俱增的需求量得到满足,降低运营成本,提升产品品质。
3.1 冷链物流节点部署模型构架
假设农产品冷链物流整体布局用二维连续空间Z2界定,布局中的所有节点集合与覆盖范围集合分别用Ω、A表示,各指标表达式如下所示
Z2={(x,y),0≤x≤a,0≤y≤a}
(1)
Ω={T1,T2,…,Tn}
(2)
A={A1,A2,…,An}
(3)
其中,n表示节点数量。
从布局节点中随机选取节点Tk、Th,坐标分别为(xk,yk)、(xh,yh),采用下列计算公式求解两点间距dkh
(4)
若两节点间距比双倍节点感知半径小,则判定两节点呈相交关系,重合的覆盖范围为Akh;两节点与节点Tg呈相交关系时的重合覆盖范围是Akhg;由此推导出节点T1,…,Tn-1与Tn呈相交关系时的重合覆盖范围为A1,…,n。
设定P为优化节点部署的决策变量,即冷链物流布局中的节点部署集合,表达式如下所示
P={(x1,y1),(x2,y2),…,(xk,yk),…,(xn,yn)}
(5)
该决策变量的优化目标是最大化节点集合Ω中各节点覆盖范围,最终节点部署即为对应变量,即,冷链物流节点部署模型的目标函数F表示为
F(P)=maxσ
(6)
式中,σ表示n个节点的覆盖率,由下列计算公式解得
(7)
式中,S表示覆盖的范围总和,表达式如下所示
(8)
由此,通过求解覆盖率,并以覆盖率最大化为目标,实现冷链物流节点的部署模型构建。
3.2 冷链物流节点部署模型求解
引用PSO(Particle Swarm Optimization,粒子群优化)算法[8]完成冷链物流节点部署模型的计算,获取部署方案中的节点方位。具体求解流程描述如下:
1)初始化m群体规模的全部微粒,并使以下设定成立:微粒初始方位与速度分别为Xi、Vi,微粒初始方位是个体最佳方位Pi;微粒初始适应度是个体最佳适应度[9];群体最佳适应度是个体最佳适应度内的最佳适应度;对应于群体最佳适应度的微粒方位是群体最佳方位Pg;
2)根据微粒初始方位Xi与速度Vi,求解各微粒适应度f(xi);
3)对比各微粒适应度与其最佳方位Pi对应的适应度,适应度较大的对应方位即最佳方位;
4)对比各微粒适应度与其全局最佳方位Pg对应的适应度,适应度较大的对应方位即全局最佳方位;
5)利用下列两项计算公式,重新求解微粒的初始方位Xi与速度Vi,若指标满足越界条件,则设定成边界值:
vij(t+1)=vij(t)+c1r1j(t)(pij(t)-xij(t))
+c2r2j(t)(pgj(t)-xij(t))
(9)
xij(t+1)=xij(t)+vij(t+1)
(10)
式中,微粒i的维度为j,迭代次数为t,加速常数分别为c1、c2,随机函数分别为r1、r2,取值范围是0到1;j维下的微粒速度与方位各是vij、xij,其最佳方位与全局最佳方位各是pij、pgj。
6)设定最多迭代次数Gmax为停止条件,若未达到最多迭代次数,返回第(2)步;反之,则迭代终止。其流程图如下图5所示:
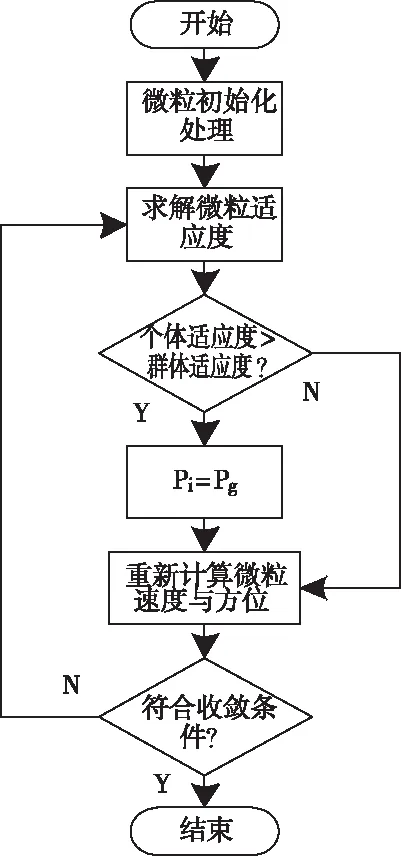
图5 基于粒子群优化算法的节点部署模型运算流程
利用微粒的最佳适应度对节点部署模型进行数次迭代求解,实现了各节点的模糊部署。
3.3 粒子群优化算法参数
为确保农产品冷链物流节点部署结果为最佳方位,深入分析严重影响粒子群优化算法寻优性能的极大速度vmax与加速常数c1、c2等指标参数[10-11]。各指标选取策略具体描述如下:
1)迭代时微粒可达到的最远运动长度随极大速度vmax改变,速度过快或过慢均会导致一定的负面影响,设定当前方位与最佳方位间的空间分辨率是极大速度vmax,通过动态限制速度vmax,随算法运行逐渐降低步幅。
2)各微粒往最佳方位Pi与全局最佳方位Pg运动时的统计加速项权值即为加速常数c1、c2,当常数值较小时,微粒不属于目标范围内;反之,将无法准确抵达目标范围中。因此,加速常数的取值范围一般在0到2之间。由此,确定了优化的冷链物流节点部署方案,能够改善节点规划不合理、效率低下等问题,保障农产品冷链物流的可持续发展。
4 农产品冷链物流节点部署仿真
4.1 冷链物流节点相关设置
根据某市农产品冷链物流布局实际情况,采用Witness仿真软件模拟布局中冷链物流中心、提供点以及申请点等十个物流节点的运作状况,各节点间距、堵塞时长,备选节点需求量、单价、运营成本,分别如表1、2所示。其中,设定物流油耗是0.5元/吨/公里,过路费是0.06元/吨/公里,其它费用是油耗与过路费的0.8%计提费率。

表1 冷链物流节点间距(单位:公里)

表2 冷链物流备选节点其它相关信息
4.2 节点部署效果分析
利用本文方法得到冷链物流节点部署方案,如下图6所示。

图6 冷链物流节点部署示意图
根据图6的部署方案,以配送成本与需求量满足度为评估指标,经仿真验证方法性能。对比方法为文献[2]方法、文献[3]方法和文献[4]方法,评估指标实验结果分别如表3、表4所示。

表3 配送成本对比(单位:元)

表4 供应量与需求量对比(单位:千克)
根据表3所示的节点最佳部署方案与其它部署方案成本对比结果可知,相较于其它部署结果,尽管本文部署方案的固定成本与运输成本相对较高,但因运营成本与惩罚成本的大幅下降,极大程度减少了成本总和,故总体来说,本文部署方案的总成本最低;由表4所示的申请点需求量、提供点供应量以及物流中心可配送量对比结果可知,提供点与冷链物流中心的供应量与可配送量远远大于申请点的需求量,即便申请点有额外数量的需求,依旧能够得到满足。本文部署方法的优越性能归功于构建的异构数据集成模型,强化了物流各环节关联,增加了协作默契度,基于此,利用设计的冷链物流节点部署方法,取得了最优的冷链物流节点布局,使冷链物流节点得到合理部署,满足了申请点的不同需求量。
农产品易腐蚀,配送时长对其品质有直接影响,故通过不同的惩罚系数取值,探讨农产品的时效性,具体结果如图7所示。

图7 惩罚系数与农产品时效性关系
从图7所示的成本曲线走势可以看出,总成本随着惩罚系数的变大而上升,而配送成本却与惩罚系数呈负相关性,说明惩罚系数的取值对农产品时效性有较大的决定性作用。从变化趋势上来看,将惩罚系数控制在1.3到1.5之间时,配送成本与总成本最为均衡,在确保不浪费运营成本的前提下,保证了产品品质。
5 结论
农产品冷链物流的区域分布不合理,不仅加剧了物流成本与食品损耗,而且阻碍了冷链物流形式发展。为此,以物流异构数据为基础,制定出一种农产品冷链物流节点部署策略,通过粒子群算法优化了节点部署方案。尽管本文方法降低了冷链物流运作成本,确保了产品品质与需求,但因节点部署策略中未考虑到实际物流运作中产生的中转与库存成本,所以,应在今后的工作中,将本文方法应用于实践,结合真实情况完善方法性能。由于现实情况中存在低价低质产品,为顺应市场发展,下一阶段应就农产品新鲜度与用户需求,构建准确的函数关系,探索低质产品的配送价值。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
电脑爱好者(2018年14期)2018-08-05
当代旅游(2016年10期)2017-04-17
电脑知识与技术(2016年8期)2016-05-19
科教导刊·电子版(2016年6期)2016-04-19
小学生时代·大嘴英语(2015年7期)2015-11-23
电脑爱好者(2015年20期)2015-09-10
财经理论与实践(2015年2期)2015-04-16
为了孩子(孕0~3岁)(2009年6期)2009-07-15
阅读(中年级)(2009年4期)2009-04-16
