
基于D维映射的布谷鸟哈希表
2022-03-15 00:39朱海婷何高峰宛俊美邓莹莹
南京邮电大学学报(自然科学版) 2022年1期
朱海婷,李 男,张 璐,何高峰,宛俊美,邓莹莹
(1.南京邮电大学物联网学院,江苏 南京 210003 2.南京审计大学信息工程学院,江苏 南京 211815)
随着云计算、物联网、社交网络等技术的快速发展,大数据时代已经到来,传统的数据处理、存储和分析技术存在着查询效率低等问题[1]。截至2021年6月30日,Facebook的全球每月活跃用户超过29亿,平均每天有19.1亿人登录Facebook进行浏览、上传信息,每日活跃用户同比增长7%[2]。因此如何在有限的资源内处理海量数据成为计算机科学及数理统计等领域的挑战。
键值存储通过键值对 (Key⁃Value Pairs,KV Pairs)的形式存储数据,是现代大规模存储系统不可或缺的一部分。哈希表是根据键(key)而直接访问内存存储位置的数据结构,能够支持快速查询,被广泛应用于数据挖掘、数据库、存储、网络等各个领域[3-6]。但当负载较高时,哈希冲突会频繁发生,为了更好地解决冲突,诞生了许多解决方案和哈希表存储结构。
线性探查法(Linear Hash)和双重哈希函数法(Double Hash)是传统解决哈希冲突方法中的开放寻址法,但其需要额外的时间和资源来解决冲突,会影响插入和查找的性能。经典哈希表数据结构还包括链式哈希表(Link Hash),孔雀哈希(Peacock Hashing)[7],d⁃left Hash[8]等。与传统哈希结构为每个数据元素提供一个候选位置不同,布谷鸟哈希表(Cuckoo Hash)[9]是一种通过多个哈希函数实现多位置选择来解决哈希冲突问题的数据结构。Cuckoo Hash能够实现高负载率,且其在最坏情况下具有常数级查找时间,目前已成为许多领域的首选散列技术,例如存储系统[10]、数据处理[11]等。
本文是在键值对存储的架构下,设计优化其中的内存数据组织结构——哈希表,以实现更高性能的键值对存储。布谷鸟哈希表作为经典的哈希表算法,具有其优点的同时也存在一些可以改进的地方:(1)布谷鸟哈希在一次查找过程中需要探查多个桶,当表太大时,会产生较多额外的访问,影响效率;(2)当在插入过程中无法解决冲突时,布谷鸟哈希建议进行重新哈希,极大浪费时间和空间资源;(3)布谷鸟哈希不能预知键值对在插入时是否存在空的候选桶,只能随机方式选择桶探测,需花费大量时间才能找到空余候选桶,甚至可能陷入无限循环。
为进一步解决上述问题,本文提出了基于D维映射的布谷鸟哈希算法 DC Hash(D⁃Dimensional Cuckoo Hash),主要思想如下:(1)通过对哈希表进行属性划分,在查找键值对时预先缩小可能包含该键值对的桶的子集范围,减少内存访问时间,有效提高了查找性能;(2)引入链表结构到布谷鸟哈希表结构中,以存储插入失败的所有键值对,而不必进行重新哈希;(3)增加辅助数据结构,以预知键值对在插入时是否存在空的候选桶,预先识别踢出是否有必要,减少操作时间,提高效率。最后在NYTimes数据集和来自CAIDA的被动测量数据集上进行了对比实验,结果表明,DC Hash有效改进了布谷鸟哈希存在的问题,且从平衡综合性能考虑优于其他几种常见的哈希表。
1 相关工作
近年来,布谷鸟哈希算法得到了广泛关注,且为了提高布谷鸟哈希在查找和插入方面的性能,提出了大量的改进方案。本节首先介绍了传统的布谷鸟哈希算法,然后对不同方向的改进方案进行简单介绍。
1.1 布谷鸟哈希表
为了解决哈希冲突,Pagh等[9]于2004年最早提出了布谷鸟哈希算法。布谷鸟哈希使用d个哈希函数为每个待插入的键值对提供多个候选存储桶,以减少冲突。它包含d个长度为n的哈希表(T1,T2,…,Td)和 d 个哈希函数(H1,H2,…,Hd),把每一个键值对在哈希表中的对应位置叫做一个桶(bucket)。需要插入的键值对(key,value)通过哈希函数求得d个散列值 H1(key),H2(key),…,Hd(key),对应于 d 个哈希表中的候选桶位置,将被存储在其中一个。因此当查询一个键值对时,只需要检查这d个桶。但是,如果在插入期间所有候选桶都已被占用,则需要“踢”出其中一个占用者以腾出空间放入需要插入的项。被踢出的项同样通过哈希函数寻找其他表中的候选桶是否为空,否则“踢出”将继续,直到每个项找到存储的桶。踢出机制使得Cuckoo Hash相比其他的哈希算法能够更高效灵活地解决冲突,且实现了高负载率。
d=2的布谷鸟哈希表的示例如图1所示,包含两个长度为4的哈希表(分别为T1,T2),每个哈希表对应一个哈希函数(分别为Hash1,Hash2)。图1分别展示了布谷鸟哈希在执行插入操作时可能会出现的3种情况。图1(a)中两个映射位置均为空,则任意选择一个位置插入;图1(b)中映射位置仅一个为空,直接插入该空桶;图1(c)中两个映射位置都已经存在键值对,选择<k1,v1>从当前桶中踢出,将<k2,v2>插入该桶,再将<k1,v1>重新在另一个表中使用相应哈希函数寻找位置插入桶中。在插入过程中,若被踢出的次数达到设定的阈值,则认为哈希表己满,进行重新哈希。

图1 插入Cuckoo Hash
重新哈希是指读取所有需要插入的项,并使用不同的哈希函数将它们放入一个更大的表中,在此期间哈希表完全不可用,这不仅极大浪费时间和空间资源,并且代价高昂。因此自从提出布谷鸟哈希以来这个问题就引起了广泛关注,接下来介绍常见的改进方案。
1.2 通过缓解哈希冲突
缓解哈希冲突的方法也有多种。第一种是对哈希表本身进行扩展缓解哈希冲突,例如 d⁃ary Cuckoo[12]和 blocked Cuckoo[13]哈希表将原始的布谷鸟哈希表从单个桶存储单个键值对的简单设计扩展到在每个存储桶中存储l个键值对,可将负载率提高到90%以上。由于这两种方法都是针对对象的“乘法”扩展,因此经常将两者结合起来,使数据结构更加灵活。另外一种是针对哈希冲突的特性,改变哈希冲突处理方式或者预先识别哈希冲突来处理。例如Min⁃Counter[14]在构造哈希表时统计了每个桶内发生哈希冲突的次数,发现在此过程中,每个哈希桶中发生冲突的频率不平衡。Min⁃Counter的核心思想是在键值对插入过程中发生踢出操作时,自主选择计数器数值最小的桶来形成“不忙碌”的踢出路径以尽快找到空桶,从而缓解哈希冲突和实现数据迁移,进而提高了空间效率和减少了插入延迟。
1.3 通过增加辅助数据结构
为了在插入过程中减少内存中不必要的桶探测,一种策略是在探测所有候选桶之前使用一个小的summary来确定键值对的位置。增加的summary需要足够小,以便存储在快速内存中(如 ASIC/EPGA中的SRAM、CPU缓存)。整个哈希表往往由于太大,只能存储在慢内存中(如 DRAM)。Fast Hash[15]是第一个在快速内存中使用summary来减少慢内存中内存访问的方案。另一种方法是使用Bloom Filter记录每个子表的存储情况。由于对快速内存的访问速度很快,此时哈希表的查询性能取决于慢内存部分所消耗的时间,因此可以使用桶探测数作为查询性能的衡量标准。例如孔雀哈希[7]和分段哈希[16](Segmented Hash),在这类哈希表中,由于Bloom Filter的误报率与插入的键值对数量成正比,一个关键问题是如何减少插入到summary中键值对数量。孔雀哈希很大程度上减少了这个数量,但由于它使用了多个Bloom Filter,这使得查询辅助数据结构更加复杂。对孔雀哈希进行改进的方案有移位哈希表(SHT)[17]。SHT中的哈希表部分将键值对分为 abroad和 at⁃home两类,在 summary中只插入abroad的项。在summary部分,提出使用一个增强的Bloom Filter来代替多个Bloom Filter,实现了更快的查询速度。
Kirsch等[18]提出 CHS 机制 (Cuckoo Hashing with a Stash)来缓解哈希冲突,CHS在Cuckoo哈希表的基础上增加一个额外缓冲空间(Stash)。Stash用于临时存储踢出次数超过阈值的键值对而不是立刻重新哈希。Multi⁃Copy Cuckoo Hashing[19]则将键值对的副本同时插入d个哈希表中,因此当有多个候选桶可用时,不必在插入时随便选择一个候选桶。
1.4 其他改进方案
其他改进方案如Single Hash[20]认为其他方案的哈希计算开销都很高,因为这些方案数据结构中需要多个哈希函数,而性能好的哈希函数通常都非常复杂。哈希函数的计算是在CPU上进行的,将占用大量CPU资源,进而影响系统性能。因此,Single Hash提出减少哈希函数的数量到一个。Single Hash显著提高了基于哈希的数据结构的速度,同时保持准确性不变。它可以应用于使用多个哈希函数的大多数数据结构,并提高它们的性能。
面向降低写操作开销的存储系统性能优化方法CoCuckoo[21]认为由于布谷鸟哈希表在执行查询操作时,需要探测多个位置,执行递归踢出操作,最终可能因循环踢出超过给定阈值而插入失败,表现出其慢写性能。基于这些,CoCuckoo则是一种面向降低写操作开销的并发布谷鸟哈希方案。CoCuckoo不仅会预判插入过程中是否会发生无限循环,并且通过图粒度锁机制使得一次只允许一个线程访问共享路径,从而支持并发写入和读取操作,提高吞吐量性能。
2 D维布谷鸟哈希表
本文在布谷鸟哈希的基础上进行改进,提出了基于 D维的布谷鸟哈希表,称为 DC Hash(D⁃Dimensional Cuckoo Hash Table,DC Hash),它包括哈希表数据结构和辅助数据结构两部分。本结构以布谷鸟哈希表的踢出机制为基础,不仅有效改善了哈希表中遇见冲突需要重新哈希的问题,并且能够预先识别踢出是否有必要,有效减少了操作时间,能够极大地提升哈希表的负载率。
2.1 数据结构
为了达到理想的插入查找性能,DC Hash建立哈希表数据结构。如图2所示,DC Hash的数据结构包括两个部分:哈希表及辅助数据结构。
(1)哈希表T包含t个子表(t是D的倍数,D为DC Hash的维数),各子表的大小相等,其中最后一个子表(Tt-1)为链式结构表。每个子表内有k个桶(bucket),每一个桶能存储一个键值对。DC Hash根据D的值对哈希表T进行划分,图2为D=2时的DC Hash结构图。当D=2时,对于哈希表部分,DC Hash 将 T0与 T1,T2与 T3,至 Tt-2与 Tt-1分别结合在一起,得到t/2组大小相等的哈希表,至此哈希表T 被分为两个属性(两个组):T0,T2,…,Tt-2为同一属性(同一组),T1,T3,…,Tt-1为同一属性(同一组),形成2维映射空间。
(2)辅助数据结构部分包含布隆过滤器(Bloom Filter)和位图(Bitmap)[22]。如图 2 所示,t个哈希子表(T0,T1,…,Tt-1)对应 t个布隆过滤过滤器(BF0,BF1,…,BFt-1)。当 D=2,DC Hash 将哈希子表进行结合时同样将其对应的布隆过滤器进行结合,得到t/2个大小相等的布隆过滤器(B0,B1,…,Bt/2-1),然后将这些大小相等的过滤器叠加在一起,形成一个统一的多位布隆过滤MB(Multi⁃bit Bloom Filter)。另外每个子表有一个相对应的 Bitmap,Bitmap中的每一个比特与其对应子表中的一个桶相对应;空桶对应位图中的比特为0,反之对应位图中的比特为1。利用上述哈希表数据结构和辅助数据结构,实现键值对的插入。

图2 DC Hash结构图(D=2)
接下来详细介绍DC Hash的基本操作,包括键值对的插入、查询和删除。
2.2 插入操作
插入给定键值对(key,value)的过程如图3和4所示,包括以下几个步骤。

图3 DC Hash 插入键值对(t=4,D=2,k=4)

图4 DC Hash的插入操作流程
(1)判定备选哈希表属性。将键值对中的key值经过主哈希函数Hm进行计算,得到对应哈希值p=Hm(key),根据 p 决定备选哈希表的属性(共 t/D个备选哈希表)。
(2)求得备选桶位置。将键值对中的key分别通过在步骤1中确定的备选哈希表对应的哈希函数H1、H2求得相应的哈希值 j1=H1(key),j2=H2(key),即为其在备选表中对应的备选桶位置。
(3)判断备选桶是否为空。通过位图判断这t/D个哈希表内的备选桶是否为空,B[p][j]=0 代表该位置为空,反之不为空。
(4)插入键值对。若备选桶中仅存在一个空桶,则直接插入;若备选桶存在多个空桶,则将键值对插入映射位置为空的负载率最小的哈希表中;若所有同属性子表不存在空桶,则采取踢出机制:按顺序选择出各个候选子表的对应桶的值,首先预判是否能找出另外一个能容纳候选桶,若有,选择负载因子最小的哈希表进行插入,若没有,则进行盲踢(盲踢与踢出机制类似,为第二个被踢出值采用同样方式寻找候选桶)。若盲踢达到阈值上限θ,在最后一个子表上挂链表,使用指针将键值对挂在链表上。
(5)更新多位布隆过滤器MB和位图。假设要插入的子表的索引为m(0≤m≤t-1),则更新m所在组的布隆过滤器,并更新对应子表的Bitmap。
图3在步骤4展示了插入操作备选桶的3种存在情况示例。情况1为仅有一个位置为空,直接插入该空桶;情况2为两个位置均为空,选择负载因子较小的表进行插入;情况3为两个位置均不为空,则为原本桶中元素寻找新的位置(通过哈希表对应的哈希函数),若能找到位置,将其从原位置踢出并放入新桶中,然后将待插入元素插入(踢出成功);若不能找到位置,则将待插入元素挂在最后一个子表的链表上。
2.3 查询操作
若要查询给定key的value值或者判断键值对是否存在哈希表中,则可以通过查询操作查询给定值。过程如图5所示,包括以下几个步骤。

图5 DC Hash的查询操作流程
(1)首先在多位布隆过滤器中查询key值的返回值。若返回i,表明key的所在组为Bi,则执行步骤 2;若返回 false,表明 key不存在于哈希表中。
(2)通过代入主哈希函数计算出键值对具体存在哈希子表的属性。
(3)在返回的哈希子表的对应位图中判断此处是否存在键值对。
(a)若存在,则查找对应哈希子表的映射位置的key是否与其相同:若相同,返回其value值,查找结束;若不相同且为最后一个哈希链表,则到链表中查询键值对。
(b)若不存在,说明不存在于哈希子表中。
2.4 删除操作
若需删除键值对,则首先需要在哈希表中查询到具体值,若查询到的相应key的value值与需要删除的键值对相同,则进行桶内部清空操作,最后将对应位置的位图置零;若value值不相同,则代表删除失败。
3 性能评估
3.1 实验环境
(1)硬件平台
所有实验在一台4核(8线程,Intel Core i5@4.0 GHz)电脑上运行,所有哈希算法均用C++实现。
(2) 数据集
实验数据共有两组,第一组来自DocWords中的NYTimes数据集。其来自于UCI机器学习存储库,它是数据库、领域理论和数据生成器的集合。NYTimes数据集总共包含大约7 000万个项,它包括5个单词包形式的文本集合,实验将DocID和WordID组合在一起以形成每个键值对的key,value是集合中的单词总数,选择前80 000个项组成键值对作为第一个数据集dataset1。
第二组来自CAIDA上的被动测量数据集,CAIDA通过操作主动和被动测量基础设施,并收集、管理、归档和共享这些设施测量产生的数据集。被动测量数据集包含CAIDA与各种操作网络基础设施的机构合作被动监测选定链路上的流量。实验选择2016年CAIDA的equinix⁃chicago监视器在高速互联网骨干链路上的一分钟匿名流量。将数据包中提取的源IP地址设置为每个键值对的key,将value设置为一分钟内此IP地址出现的频次。由于一分钟内产生了48万个不重复的IP地址,因此将这48万个键值对作为第二个数据集dataset2。
(3)实验设置
将采集到的数据集作为输入来对哈希表性能进行测试。数据集中每一条项目为一个(key,value)键值对,其中每个键值对的value值的大小固定为8位。使用β来表示所有子表中的桶的总个数与需要插入的总项目数的比率;使用n表示需要插入到哈希表中的键值对的数量,使用T表示哈希子表数量,则哈希子表的总大小(桶的个数)为β×n,每个子表大小为β×n/T;使用D表示DC Hash的维数;使用θ表示盲踢次数,踢出的次数达到阈值则会停止盲踢,并将此键值对插入到最后一个哈希链表中。
DC Hash的最后一个哈希表为链式哈希表:它是由一个带有b个桶的哈希表和一个哈希函数组成,具有均匀分布的输出。每个桶都有单元链,每个单元有3个字段组成,即键、值和指针,指针字段指向链中的下一个单元(如果有下一个)。每个哈希表的大小根据插入元素的个数决定。
3.2 性能指标
通过如下衡量指标比较不同哈希表之间的性能:
(1)哈希表负载因子(load factor):是指元素个数counter与空间大小Tsize的比值。计算方法如式(1)所示。当哈希表大小相同且插入相同的数据时,哈希表的负载因子越大,代表哈希表性能越好。

(2)插入代价(Insert Costs):插入一个元素的内存访问次数,在这里将插入一个元素对桶内的平均访问次数作为插入时间。内存访问次数越少,说明哈希表的性能越好。
(3)查询代价(Search Costs):查询一个元素的内存访问次数,在这里将查询一个元素对桶内的平均访问次数作为插入时间。内存访问次数越少,说明哈希表的性能越好。
3.3 性能比较
将不同维数的DC Hash与6种已知的哈希表即Link Hash、Linear Hash、Double Hash、布谷鸟哈希、d⁃left Hash和孔雀哈希进行比较。将盲踢次数θ设置为1,β从1.05变化到6。由于存在哈希链表,DC Hash不会出现插入失败的情况,但在Linear Hash、Double Hash和布谷鸟哈希中,每当插入过程中发生碰撞时,就会尝试探测另一个桶,而这种探测可能不断重复。实验将会为这3种方案设置探测递归的最大次数500次,每次插入的最大内存访问次数存在限制。在500次尝试之后,如果碰撞仍然存在,那么此次无法为键值对找到空桶,为插入失败。在孔雀哈希和d⁃left Hash中,为了避免插入失败,也将子表变成哈希链表来避免出现插入失败。接下来,实验比较这些哈希方法在负载因子、插入代价和查询代价方面的性能。
(1)负载因子
在不同的比例下,各个哈希表的负载因子变化如图6所示,负载因子随着β的增大而减小,两者成反比。从图中可以看出,对于DC Hash,当D=2时负载因子最高,且随着选择维数D的增加,负载因子呈递减的趋势,即越来越低。当β为1.05时,可以发现DC Hash(D=2,3),Double Hash 和 Linear Hash 均达到了0.9以上,Link Hash负载因子最小,为0.6左右。以情况最好的D=2时为DC Hash的代表,当β在1.05~4.00区间时,DC Hash的负载因子是最大的,能够达到Link Hash的1.5倍。也就是说,DC Hash可以在给定空间的大小下,存储更多的键值对,能够更充分地利用空间。当β更大时(到达6)Peacock Hash和d⁃left Hash才能获得高的负载因子,即它们需要更大的内存空间才能获得高的负载因子。

图6 不同比例下哈希表负载因子比较
(2)插入代价
在不同比例下,各个哈希表每次插入的内存访问次数如图7所示,插入时间随着β的增大而减小。从图中可以看出,在β较小时(1.05~2.00区间),随着选择维数D的增大,DC Hash的插入代价呈递减趋势,即越来越小。除了Link Hash每次插入时内存访问次数最少,DC Hash的访问代价均低于其他算法。当β大于2时,几乎所有哈希表每次插入内存的访问次数都在2次以下,而当β很小时,Cuckoo Hash和Linear Hash的插入速度非常慢,d⁃left Hash次之,Link Hash最小。DC Hash在所有的哈希表中,达到除了Link Hash之外的内存访问次数最少。这证明了,由于Bloom filters和Bitmap的辅助,DC Hash能够在实现高负载率的情况下还能够有较低的访问内存代价,而其他算法需要更大的内存空间才能获得与DC Hash相似的内存访问代价。
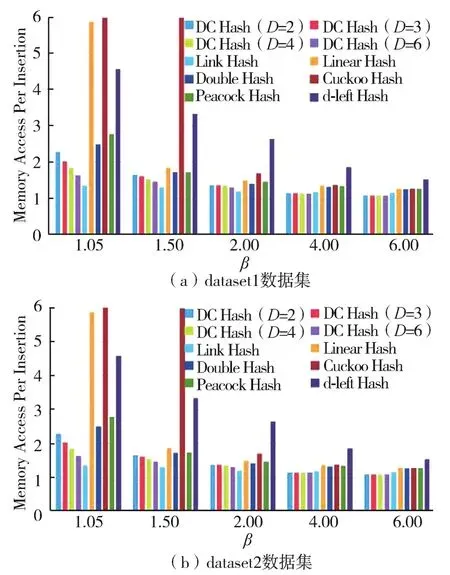
图7 不同比例下哈希表插入时间比较
(3)查询代价
在不同比例下,各个哈希表每次查询的内存访问次数如图8所示,插入时间随着β的增大而减小,两者成反比。从图中可以看出,随着选择维数D的增大,DC Hash的查询代价呈递减趋势,即越来越小。且DC Hash同一维数的查询代价随着β的增大并没有明显的变化。总体来看,Cuckoo Hash查询最快,其次是 Link Hash和 Double Hash。由于 DC Hash对哈希表进行了划分属性,所以查询代价相较于其他算法会略高一些。当维数D选取高于2的值时,可以实现与其他算法接近的查询代价。

图8 不同比例下哈希表查询时间比较
4 结束语
布谷鸟哈希算法是被广泛认可的高效利用存储空间的哈希算法,本文针对布谷鸟哈希表在进行哈希操作时,由于高负载而产生大量冲突导致最终有元素无法插入而重新哈希,浪费大量时间和空间的缺点,对哈希表进行属性划分,加入链表结构,并将哈希表数据结构和辅助数据结构两部分进行结合,提出了一种解决冲突的实现方法 DC Hash(D⁃Dimensional Cuckoo Hash),能够预先识别踢出是否有必要,有效减少了操作时间,提升哈希表的负载率。最后在NYTimes数据集和来自CAIDA的被动测量数据集上进行了对比实验,结果发现,在相同的内存空间下,当选用合适的维度D时,DC Hash的负载率大于其他哈希表,且最多能达到Link Hash负载率的1.5倍;插入时能够实现除了Link Hash之外的最少内存访问次数。从平衡综合性能考虑,DC Hash优于其他几种常见的哈希表。
猜你喜欢
红蜻蜓(2021年12期)2021-12-19
电脑爱好者(2021年8期)2021-04-21
课程教育研究(2021年23期)2021-04-13
电脑爱好者(2021年1期)2021-01-13
中国信息技术教育(2020年22期)2020-12-08
电脑爱好者(2020年20期)2020-10-22
剑南文学(2016年14期)2016-08-22
电脑爱好者(2015年13期)2015-09-10
计算机教育(2006年2期)2006-02-23
计算机教育(2006年2期)2006-02-23
