
基于文本挖掘的铁路信号设备故障自动分类方法
2022-03-24 09:56林海香陆人杰
云南大学学报(自然科学版) 2022年2期
林海香,陆人杰,卢 冉,许 丽
(兰州交通大学 自动化与电气工程学院,甘肃 兰州 730070)
铁路信号设备在保障铁路行车安全中发挥着重要作用,在日常的运营维护过程中,积累了大量故障文本数据[1],这些数据包含了铁路信号设备故障现象、原因及维修方法等非结构化的描述性数据,由于铁路信号设备故障文本数据通常保存在铁路电务部门,未被充分利用,且当前故障分类任务仍主要依赖铁路工作人员,分类结果可能具有随意性和不准确性[2]. 因此,在智慧铁路和铁路大数据时代的背景下,亟需采取智能手段,基于故障文本数据,挖掘故障记录与其对应故障设备类别之间的模式关系,得到故障记录文本自动分类器,实现铁路信号设备故障的智能分类;对故障文本数据的定量分析能为信号设备检修计划的变更与制定提供基本的数据支撑,而自然语言处理也在国发〔2017〕35 号文件中被视为关键共性技术[3],故充分利用文本数据能为智能化铁路的发展提供创新动力,且符合电务大数据智能运维需求.
实现故障文本自动分类的核心在于文本表示和分类器选择两个方面. 文本向量化的优劣会对分类器的性能产生较大影响,传统文本表示方法大多依赖于词袋模型,例如独热编码、词频-逆文档频率(Term Frequency–Inverse Document Frequency,TF-IDF)等. 李阳庆等[4]以铁路无线闭塞中心故障追踪记录表为数据来源,基于独热编码构建故障文档矩阵;刘浩[5]利用TF-IDF 向量化高铁列控系统车载设备的故障文本,但独热编码、TF-IDF 等方法未考虑字词间顺序和相关性,且形成的词向量维度过大. 而词嵌入模型[6]可有效避免这些问题,词嵌入模型能将字词表示成更低维度的向量,同时将上下文特征融入到字词向量中,当前已有故障文本分类研究[7-8]利用该类模型进行文本向量化表示. 在构建文本分类器时,支持向量机(Support Vector Machine,SVM)[9]、朴素贝叶斯(Naïve Bayes,NB)[10]、K 最近邻(K-Nearest Neighbor, KNN)[11]等机器学习方法已取得了不错的效果,例如钟志旺等[12]利用SVM 模型实现对高速铁路道岔故障文本的分类;赵阳等[13]以铁路车载设备故障文本为依据,通过LDA 主题模型完成特征提取后,将Bayes 结构学习算法应用于故障分类. 但上述传统机器学习算法为浅层学习算法,直接利用向量化后的文本进行分类,所用向量不能表达出语义的深层含义,分类能力受到限制. 较之传统机器学习算法,深度学习模型则依赖于自身的深层模型结构,关注对隐藏特征和高维度特征的抽取[14],可以在文本向量的基础上进一步自动抽取语义特征,实现端到端的学习,所以基于深度学习的故障文本分类模型逐渐成为当前研究热点. 此外,数据样本类别分布的均衡与否也会对最终分类结果产生较大的影响.
本文在已有研究的基础上,针对铁路信号设备故障文本记录数据,提出了一种基于Word2vec+SMOTE+CNN 的铁路信号设备故障文本自动分类方法,通过Word2vec 得到具有语义相似性关系的文本向量表示,接着采用SMOTE 算法实现小类别文本向量数据自动生成,从而解决故障文本数据不平衡问题,再利用卷积神经网络(Convolutional Neural Networks, CNN)进一步提取局部上下文深层特征并实现对故障文本的智能化自动分类,为信号设备的定期维护提供参考价值,也为故障文本数据的高效利用提供了解决方案.
1 铁路信号设备故障数据分析
铁路信号设备故障按照设备的功能和故障现象划分,可分为如图1 中所示的9 类故障,图1 中显示了某铁路局电务段于2016 至2019 年的铁路信号设备各故障类型的占比,通过统计可以看出故障类别存在明显的不均衡分布,数量上的不均衡比最大可达1∶42,若直接通过分类模型,则在分类时易忽略少数类对分类的影响从而造成少数类预测精度比多数类的预测精度低.
本文研究数据主要来源于电务工作人员记录的铁路信号设备故障文本数据,这里只展示出本文研究所需的信息,即故障现象描述及对应的故障类型,铁路信号设备故障文本数据示例如表1 所示. 由于当前缺乏统一的记录标准,以及故障文本的高维和稀疏特性,这给计算机识别和处理文本数据带来难度.
2 铁路信号设备故障自动分类方法设计
本文设计的铁路信号设备故障自动分类方法如图2 所示,主要包含4 个模块:故障文本预处理、Word2vec 词向量训练、故障少数类别样本自动生成以及CNN 分类模块. 该设计方法的优点主要有:①Word2vec 训练的词向量维度固定,并能较好表征词和词之间的语义相似性关系;②SMOTE 算法的使用有效避免在深度学习过程中出现欠拟合现象;③CNN 具有的权值共享的特性可以提高训练效率.

图2 铁路信号设备故障文本自动分类方法设计Fig. 2 Design of automatic classification method of railway signal equipment fault
2.1 信号设备故障文本预处理模块 第一个模块主要是对铁路信号设备故障文本进行中文分词和去停用词处理. 文本的精准分词是实现文本挖掘各项功能的必要条件,分词将自然语言文本这种非结构化数据切分成多个信息块,每个块都可看成可计数的离散元素. 去停用词则是将一些对铁路信号设备故障文本数据表征能力不强的介词、副词、虚词等过滤掉,因为这些词不仅对于文本分类结果几乎没有影响,还增加了文本表示的维度.
2.2 Word2vec 词向量训练模块 该模块实现对分词后的文本集合的数值向量化表示,向量化后才可被分类模型识别与计算. 本文以Word2vec 工具进行词向量训练,可将故障文本中的每个词转化为计算机可识别的分布式词向量,相同语境下的词在语义上也相似,通过余弦距离表征,其包含Skip-gram 和CBOW两种训练模式,前者的输入为当前词的词向量,输出为上下文词的词向量,而后者的输入和输出形式与前者相反. 以CBOW 模型为例,针对故障文本数据的模型训练过程示例如图3 所示.
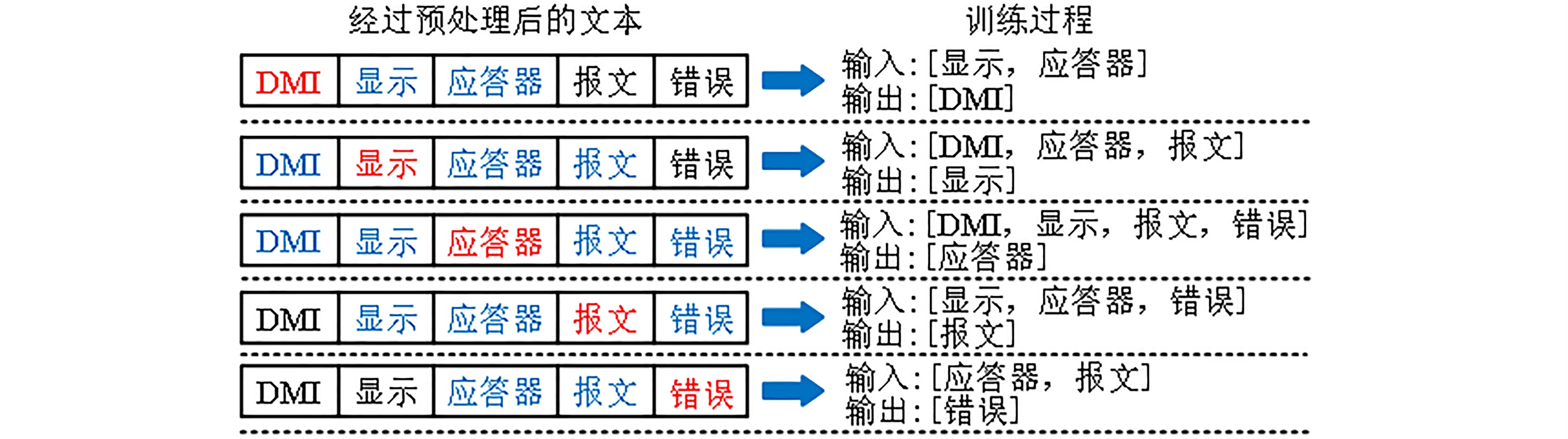
图3 CBOW 模型的训练过程Fig. 3 The training process of the CBOW model
2.3 故障少数类别样本数据自动生成模块 在传统分类问题中,大多会假设数据类别平衡,但在本文这种假设无法成立,铁路信号设备故障文本类别分布并不均衡,为了使数据不平衡现象对分类器精度的影响尽可能小,本文从数据本身层面出发对数据集重构,从而改变样本数量的分布结构,使不平衡数据集内不同类别之间的数量达到相对平衡,通过SMOTE 人工合成新的少数类别样本来减轻类别的不平衡. 图4 为SMOTE 算法示意,其基本思想是对每一个少数类别样本的K(K为大于1 的奇数)近邻进行分析,并对少数类别和其近邻之间通过式(1)以线性插值的方式生成新的少数类别样本.
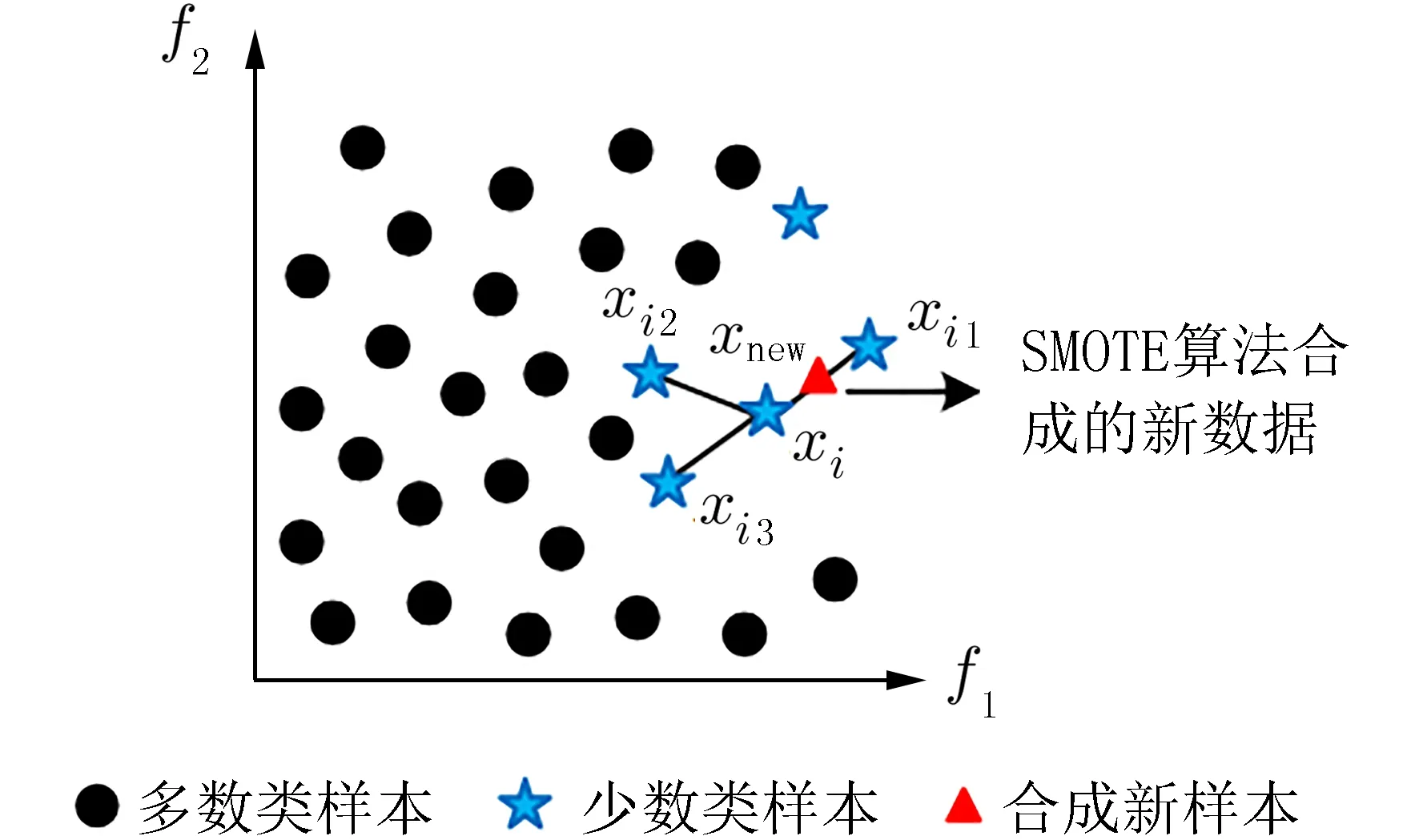
图4 SMOTE 算法示意(K=3)Fig. 4 Schematic of SMOTE algorithm(K=3)
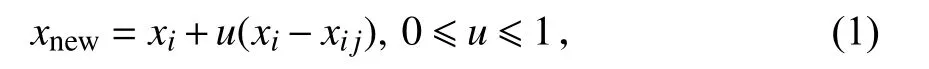
式中,xnew为新数据,xi为少数类别样本,xij为xi的近邻点,u为随机数.
2.4 CNN 自动分类模块 第4 个模块的主要功能是实现铁路信号设备故障文本数据的深层特征提取和自动分类,工作流程如图5 所示.

图5 CNN 模块工作流程Fig. 5 Workflow of CNN module
2.4.1 输入层设计 设输入的铁路信号设备故障文本数据中某个语句的长度为m,xi(xi∈Rn,n代表词向量维数)为语句中第i个词的词向量,则该语句可用文本矩阵呈现为:
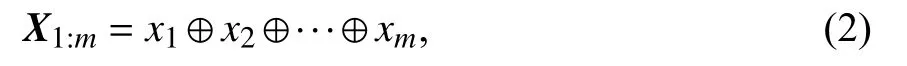
其中, ⊕代表串接操作.
2.4.2 卷积层设计 将文本矩阵X1:m经卷积核w∈Rh×n(h为卷积核窗口高度,宽度与词向量维数n一致)卷积运算后的结果作为非线性激活函数f的输入,通过f提取局部上下文高层特征,再输出特征图:
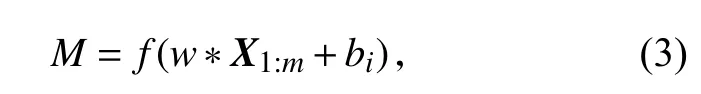
式中,“*”为卷积操作,bi为偏置项,它是一个常数,其数值可随模型训练而自动调整.
此外,在卷积核滑动时若越过文本矩阵边界,需采取补零方式以防边缘信息丢失.
2.4.3 池化层设计 卷积层仅提取了故障文本特征矩阵的局部特征,还需经过池化层来深度挖掘故障文本特征,对卷积后的数据实现进一步降维.池化方式主要有最大池化和均值池化,本文采用前者,即对每个特征图取一个最大值. 池化后的特征图可表示为:

铁路信号设备故障文本分类结果由softmax函数转换为0 到1 之间的概率数值所体现,数值最大的一类作为最终的分类结果,具体表达式如下:

式中,Pz为属于第z类故障的概率,A为故障类别数量,W和B分别为全连接层的权重矩阵和偏置项.
3 实验过程
3.1 实验环境 本文的实验环境采用Windows10操作系统,CPU 为Intel Core i7-8550U 1.80 GHz,内存为8 GB,采用Python 编程语言,词向量训练工具包为gensim,深度学习框架是以Tensorflow 为后端的Keras 框架.
3.2 铁路信号设备故障文本预处理 故障文本预处理过程如图6 所示,实验在通用词典的基础上构建了铁路信号设备专业领域词典,得到表征故障文本信息的特征词集合. 构建专业领域词典的目的是为了准确切分故障特征词,通常这些词隐含着关键的故障类别信息,因此在分词处理中应当做一个词项. 本实验采用jieba 库中的精确模式完成自动分词,该模式可将语句中的词精准地切分开.
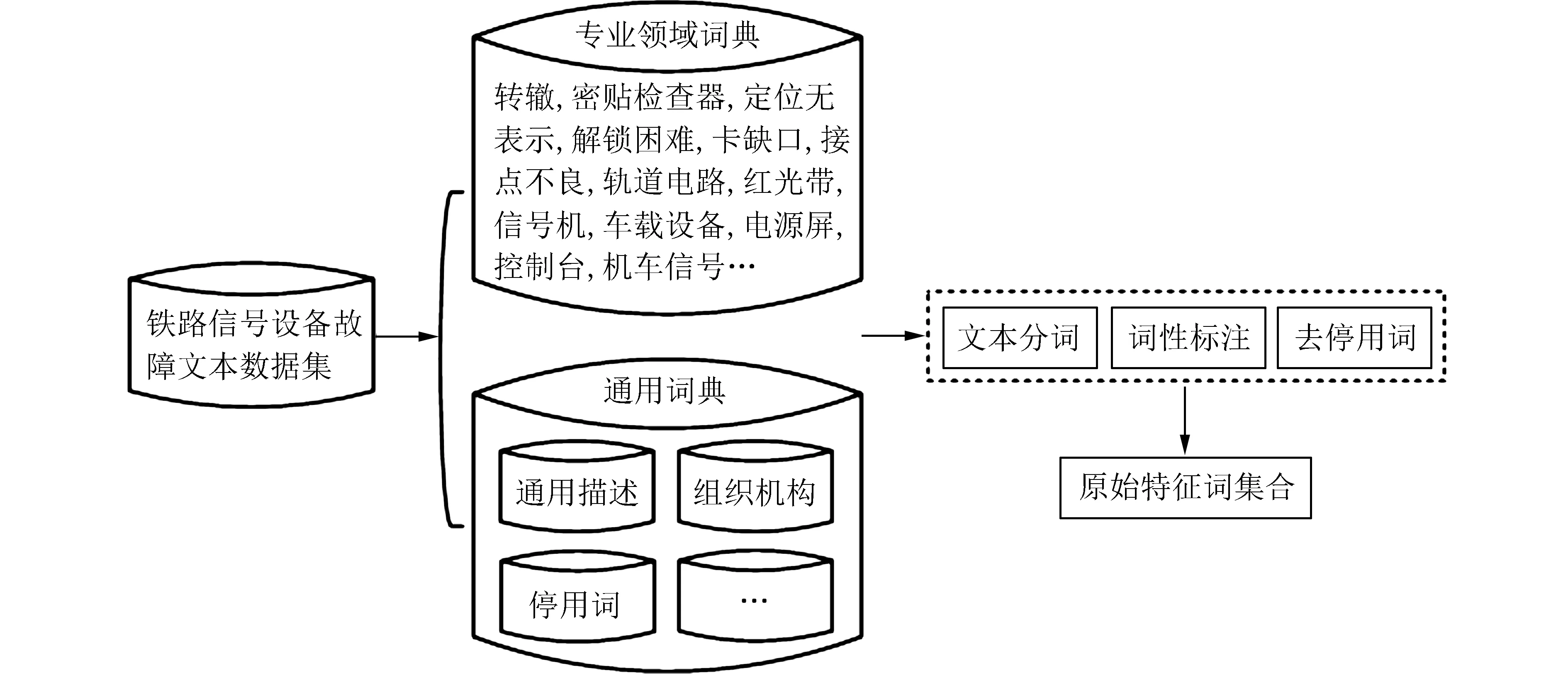
图6 故障文本预处理过程Fig. 6 The process of fault text preprocessing
3.3 词向量训练实验 将预处理好的文本语料保存到一个新的文本文件中,利用Python 提供的“gensim”库,完成铁路信号设备故障文本的词向量化. 进行词向量训练时,由于CBOW 模型的训练效率相对更高,因此本文选用CBOW 模型通过上下文词预测当前词构造语言模型,并在模型的输出层使用哈夫曼树算法提升词向量的训练效率. 该模型的窗口大小和词向量维数需要设置适当的两个重要参数,原则上窗口大小越大,考虑上下文的关系越全面,但也会导致训练时间较长. 由于本文的铁路信号设备故障文本大多为短文本数据,为避免关联到较多语义不相关的词汇,因此本实验的窗口长度不宜太大,设置为3 即可.
为了测定最佳的词向量维度,设定不同维度的词向量在故障文本数据集上进行验证,F1 值随不同词向量维度的变化如图7 所示,可以看出当词向量维度为200~300 维时,F1 值逐渐稳定,因此本实验将词向量的维度数设置成200.
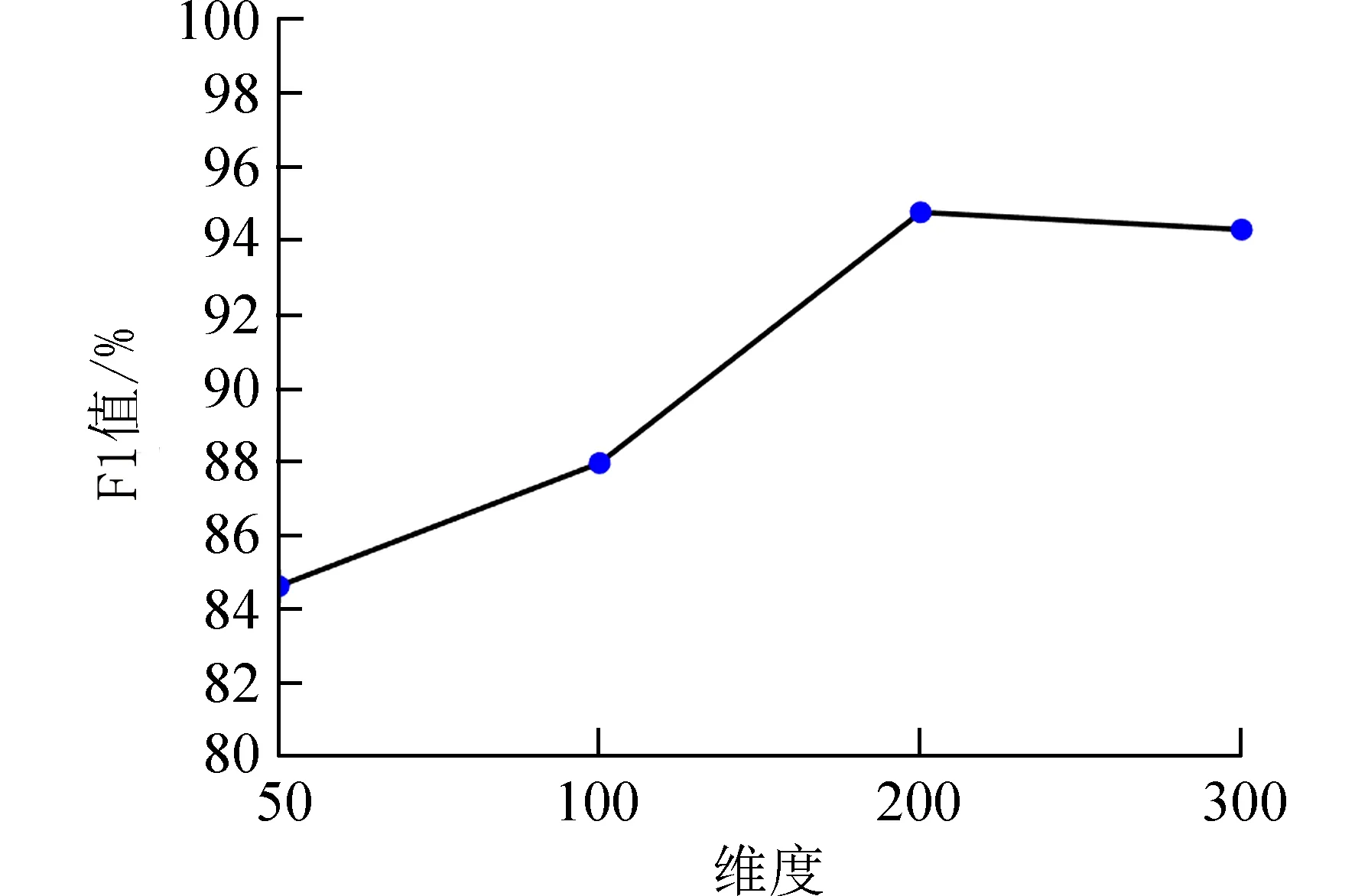
图7 不同词向量维度所对应的F1 值Fig. 7 F1-Score corresponding to different word vector dimensions
3.4 故障少数类别样本自动生成实验 通过SMOTE 算法自动生成小类别文本向量数据,原始数据量以及对少数类别的故障数据样本进行人工合成后的结果如图8 所示,可以看出少数类别样本数量得到提升,故障类别总体分布基本达到均衡,数据量由原来的2 464 条变为5 302 条.

图8 原始数据与经SMOTE 生成后的数据Fig. 8 Original data and data generated by SMOTE
3.5 CNN 模块构建实验 将经过SMOTE 算法生成后的数据中的每一类以0.90∶0.10 的比例划分成训练集和测试集(通过sklearn 包中的train_test_split函数). 本文将交叉熵损失函数作为误差代价,执行梯度下降使误差代价最小化训练CNN,使用AdamOptimizer 更新学习速率. 关于卷积神经网络相关参数的设定,由于在多尺寸卷积核的相互作用下能提取出更多的文本特征,因此实验选用大小为3、4、5 的3 种卷积核(每种128 个,维数为200)进行卷积;将ReLU 作为卷积后的激活函数;此外,为了增强CNN 模块的泛化效果,在模型训练过程中添加Dropout 层,如此可在每次迭代中随机让一部分神经元停止参与运算,避免在隐层神经元权重更新时产生过拟合情况;将批处理参数Batch 设为64,学习率和Dropout 率的取值分别是0.001 和0.5.
提升迭代次数,训练误差和测试误差的走势如图9 所示,从图9 中可看出当迭代到90 次时,训练和测试误差均达到较小的数值.
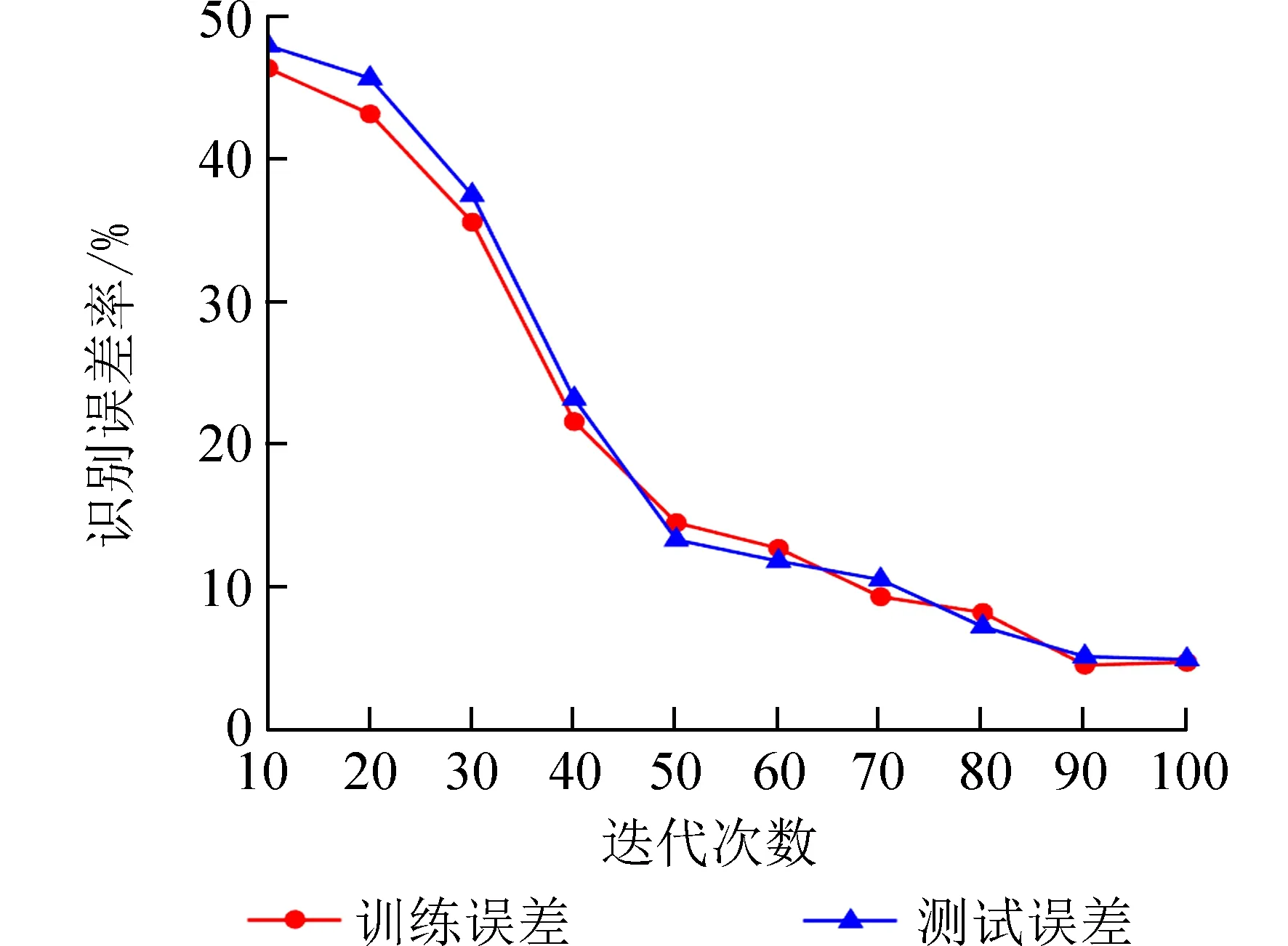
图9 识别误差随迭代次数的变化Fig. 9 Change of recognition error with number of iterations
4 实验结果与分析
4.1 评价指标 选取3 个指标对所提方法实施评价和对比:①准确率(Precision)、②召回率(Recall)、③F1 值. 第一项指标反映分类结果的精确程度;第二项指标反映分类结果的全面程度,它的值越大,表明分类结果越全面;F1 值为前两者的综合评价指标,它的值越大,表明分类的综合性能越出色. 上述指标由混淆矩阵中的参数决定,具体见表2.

表2 评价指标的参数Tab. 2 Parameters of evaluation indexs
准确率和召回率可以分别从查准和查全两个角度反映分类结果,计算公式分别为:

F1 值是前两项指标的调和平均,计算公式为:

4.2 结果评价 根据表2 的描述,利用混淆矩阵以可视化的方式直观地展现出本文所提方法对各故障类别在测试集上的判别结果,如图10 所示,该矩阵横纵坐标中的数字1~9 代表故障样本类别(按图8 横坐标的显示顺序),主对角线上的数字表示测试集中各类别正确分类的个数.
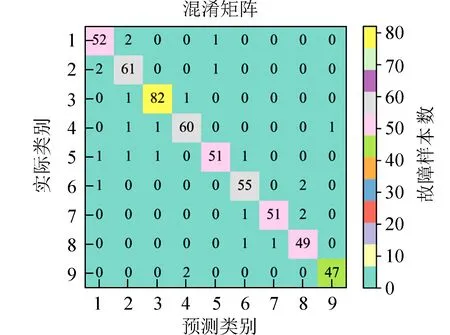
图10 测试结果的混淆矩阵Fig. 10 Confusion matrix of test results
图10 中统计的目标为样本个数,而当面对数量较多的数据时,不能仅通过计算个数衡量本文所提方法的性能优劣. 针对铁路信号设备故障文本的分类评价结果如表3 所示. 由表3 可以看出,本文方法可较好地对铁路信号设备故障文本进行自动分类,整体的分类准确率可达到90%以上,准确率、召回率、F1 值3 个指标的平均值分别是95.26%、94.32%、94.79%.
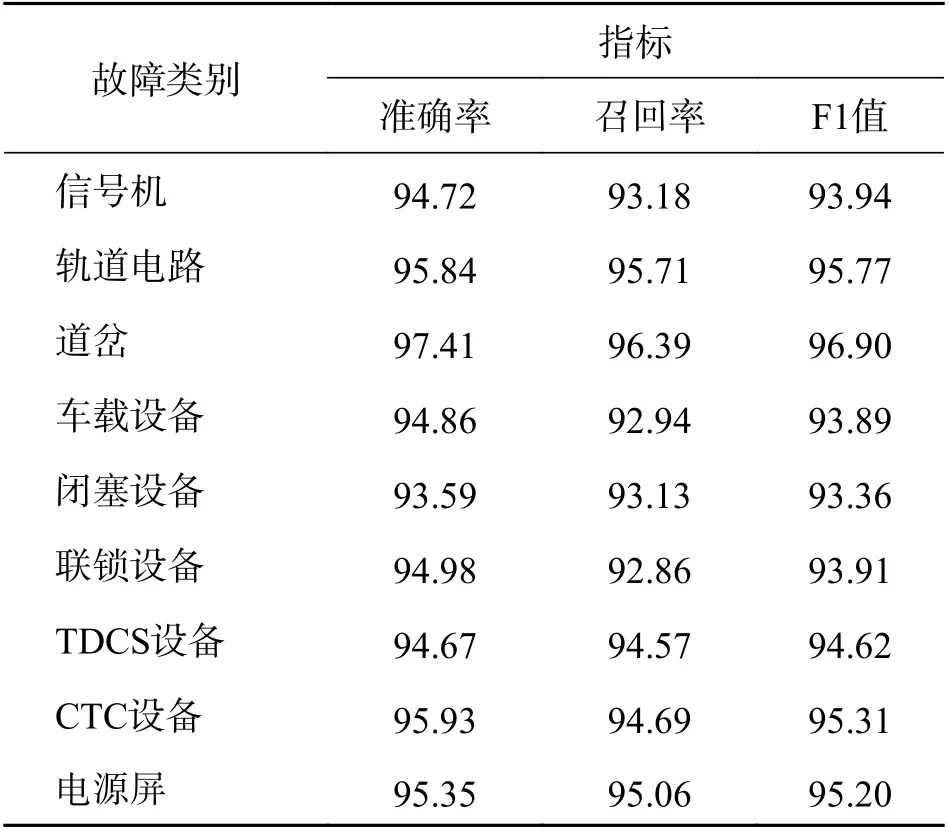
表3 铁路信号设备故障文本分类评价结果Tab. 3 Classification evaluation results of fault text of railway signal equipment %
4.3 对比实验分析 在文本特征表示部分,将本文使用的Word2vec 词向量方法与文献[4]中的One-hot 向量法、文献[5]中的TF-IDF 算法、文献[15]中的Glove 词向量法进行对比实验,上述4 种文本表示模型均与CNN 结合,应用于铁路信号设备故障文本分类时所取得的分类效果如图11 所示.
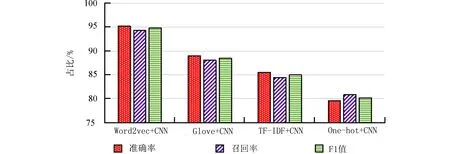
图11 不同文本表示模型的实验结果Fig. 11 Test results of different text representation models
图11 结果表明,使用One-hot 方法所得到的结果相较来说最差,这是因为该方法丢失了词和词之间的顺序,未能将词和词之间存在的语义关联性纳入考量,且有维数灾难的困扰,因此难以获得理想的文本抽象表示;TF-IDF 算法的本质也是属于词袋模型,无法有效识别同义词问题;Glove 和Word2vec 都是词的嵌入式表示方法,前者利用了共现矩阵的全局信息进行训练,准确率有所增加,训练效率也较高,但也同样无法获取对文本整体的精确语义信息. Word2vec 的特征表示方法则在3项指标上均取得了良好效果,证明该方法可为后续模型提供较为理想的特征表示形式,以期在此后分类模型的训练中通过不断调整优化,能更全面地表示铁路信号设备故障文本特征.
在分类器的比较实验方面,由于KNN、SVM、NB 是机器学习算法中已在故障文本分类任务中获得不错效果的分类器[16-17],因此将这3 种算法与本文方法进行对比实验,得到的具体结果如表4 所示.
由表4 可以看出,在铁路信号设备故障文本分类任务中,在与本文方法进行对比的3 种方法中,Word2vec+SMOTE+SVM 方法效果最优,但仍比本文所提方法的准确率低了6.96%,召回率低了4.75%,F1 值低了5.86%,因此本文所采用的方法相比另外3 种方法能有更好的分类结果. 能取得上述效果的原因,可以总结为两点:①相较于普通词袋模型生成的向量,本实验用Word2vec 训练生成的词向量能更好地表征词语间的特征;②CNN 所特有的卷积与池化操作能更好地提炼故障文本深层语义信息,是铁路信号设备故障文本分类中的有效模型.
5 结论
本文以铁路信号设备故障文本数据为样本研究故障分类方法,对故障文本进行预处理后引入Word2vec 训练词向量,针对故障数据的不平衡性,采用SMOTE 实现小类别故障数据的自动生成,再利用卷积神经网络实现故障文本数据的深层特征提取和智能化自动分类. 通过对某铁路局电务段的铁路信号设备故障文本数据进行试验分析,分类的准确率和召回率分别可达95.26%和94.32%,验证了本文所提方法能够有效提升铁路信号设备故障文本的分类效果. 未来研究方向还需针对铁路大数据平台研究文本数据的统计分析、存储及故障检索技术,加强对铁路信号设备故障知识的推理研究及应用.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
中国新通信(2022年4期)2022-04-23
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
艺术科技(2016年9期)2016-11-18
科学与财富(2016年28期)2016-10-14
科学与财富(2016年28期)2016-10-14
