
基于工程环境背景下安全帽佩戴检测算法研究
2022-03-29 02:13刘川
河南科技 2022年4期
关键词:目标检测
刘川





摘 要:针对当前安全帽佩戴检测算法存在结构复杂、鲁棒性差等问题,提出一种借助改进后的YOLOv3算法进行安全帽佩戴检测。利用包含通道注意力机制的SE-ResNeXt残差结构,替换YOLOv3模型中Darknet53网络的残差结构,在不加深网络结构的情况下,利用通道注意力机制,捕获特征有用信息,达到提高特征表示能力的目的。再利用空间池化金字塔模块,对待测图片进行多尺度提取,提高检测精度。最后將IOU损失函数替换成CIOU损失函数,在进一步提高检测精度的同时,加速模型收敛。通过自建数据集验证可知,改进后模型检测准确率相比于原始YOLOv3模型,检测平均精确度(mAP)提高了4.29%,每秒检测帧数(FPS)提高了8.67%。
关键词:目标检测;YOLOv3;SE-ResNeXt;SPP-Net;损失函数
中图分类号:TP391.41 文献标志码:A 文章编号:1003-5168(2022)4-0007-06
DOI:10.19968/j.cnki.hnkj.1003-5168.2022.04.001
Research on the Algorithm of Safety Helmet Wearing Detection Based on the Background of Engineering Environment
LIU Chuan
(School of Information Engineering, Chaohu University, Hefei 238014,China)
Abstract:In view of the complex structure and poor robustness of the current helmet wearing detection algorithm, a helmet wearing detection method is proposed with the aid of the improved YOLOv3 algorithm. The SE-ResNeXt residual structure including the channel attention mechanism is used to replace the YOLOv3 model. The residual structure of the Darknet53 network, without deepening the network structure, uses the channel attention mechanism to capture useful information of features to achieve the purpose of improving feature representation. Then use the spatial pooling pyramid module to perform multi-scale extraction of the image to be tested. Improved the detection accuracy. Finally, the IOU loss function was replaced with the CIOU loss function, which further improved the detection accuracy while accelerating the model convergence. It can be seen from the self-built data set verification that the improved model detection accuracy rate is compared with the original YOLOv3 model. The average accuracy (mAP) has increased by 4.29%, and the number of frames per second (FPS) has increased by 8.67%.
Keywords: target detection; YOLOv3; SE-ResNeXt; SPP-Net; loss function
0 引言
现如今安全生产已成为各施工单位最为重视的一环[1],为保障施工人员安全,依据国家安全生产相关法规条款规定,工作人员进入施工场地必须佩戴安全帽。然而由于部分施工人员安全意识淡薄、个别施工监管单位存在安全责任落实不到位等情况,常常导致施工场地安全事故频发。目前各单位对施工员工佩戴安全帽监管以人工监管形式为主,实际操作起来存在效率低下、浮于表面、效果不佳等情况。因此,利用计算机视觉来自动完成对施工场地实时安全帽佩戴检测,具有检测范围广、成效优、实时报警等特点,为施工场地安全监测提供了新方向。
目前利用计算机视觉完成对施工人员佩戴安全帽检测的方法主要分为以下几类。一类是利用传统算法实现,Rubaigat等人利用物体色彩信息以及结合物体形状特征来完成对施工人员安全帽佩戴检测[2]。李琪瑞运用机器学习领域中SVM分类器以及HOG方向梯度直方图特征相结合完成对人员佩戴安全帽检测[3]。在检测效果方面,虽然以上方法都取得了一定成效,但通过利用传统人为选取特征进行分类检测,会依赖较强的先验知识,实际工程应用背景下会出现鲁棒性差、泛化能力不足等问题。
伴随目标检测领域中深度学习等相关技术的快速发展,研究人员借助深度学习技术来完成对图像中待测目标检测与识别,并获得较佳的效果。依据检测步骤的不同,深度学习目标检测算法主要分成单步检测算法和两步检测算法。以Faster R-CNN系列为代表的两步检测算法虽检测精度优于单步检测算法,但检测速率下降很多。如徐守坤等人使用改进Faster R-CNN检测安全帽佩戴情况[4],该类方法不适用于实时性要求较高的应用场景。而以YOLO系列、SSD系列等为代表的单阶段检测算法,仅需要将待测图像送入网络一次即可预测出所有边界框;王秋余对YOLO网络结构进行优化调整,引入半监督学习的思想,完成对安全帽佩戴识别[5]。检测速度虽较两步检测算法明显提升,但在实际复杂检测环境下漏检和误检情况较多,尤其对于目标尺寸较小情况检测精度不佳。
综上,本研究提出一种基于YOLOv3为主干网络,进行优化改进后的安全帽佩戴识别检测算法。首先利用ResNeXt网络结构替换原始YOLOv3网络结构中的ResNet的残差结构,再引入通道注意力SE-Net模块以及在网络框架中加入SPP空间池化金字塔模块,然后再使用CIOU损失函数替换原有IOU损失函数并基于自建数据集重新聚类获得先验框,实现安全帽佩戴检测。最后,在同一测试集下与原始YOLOv3、SSD和Faster-RCNN等检测算法进行比较,验证改进后算法的性能。
1 YOLOv3算法介绍
YOLOv3网络框架是一种单步实时目标检测模型,在确保高检测精度的同时,检测速度要优于其他基于两步检测网络检测算法。其构建的主干网络由之前的Darknet-19网络结构改为Darknet-53网络结构,骨干网络结构如图1所示。YOLOv3模型中还增添了残差结构,保证网络结构在较深的情况,确保训练的模型能够同时收敛,降低了模型的计算量。YOLOv3中Darknet53网络主要由5个残差块构成,每个残差块由若干个数量不等的残差单元组成。此外,YOLOv3网络结构也采用多尺度检测技术,引入了类似于FPN(Feature Pyramid Networks)特征金字塔结构,实现了高维和低维信息融合,提升了检测的准确率。
YOLOv3网络具有检测准确率高、实时性好等特点,但在实际施工场景环境中存在着检测目标小,检测背景复杂等问题,因此本研究在原始YOLOv3网络模型基础之上,对其结构进行优化调整,使得模型在复杂场景检测下具有较高准确率和容错能力。
2 改进YOLOv3算法
2.1 残差模块设计
YOLOv3网络中的残差模块结构Residual单元[7]参考了Jie等人提出的ResNet网络结构,Residual网络结构相比于普通的卷积网络结构引入了跳跃连接,使得残差块之前的信息可以无阻碍地流入到下一个残差模块中去,既提高信息流入,也能防止由于网络结构过深所带来的梯度消失和退化问题。然而基于ResNet结构的网络模型进一步提高检测识别准确率,就需要进一步加深或加宽网络结构,进而会导致网络中超参数的数量进一步增加,使得整体网络开销变大。本研究提出利用压缩激发网络SENet和ResNeXt网络结构融合组成SE-ResNeXt结构替换Darknet53网络中的ResNet结构,使得改进后的网络在不增加模型网络开销基础上提高了检测性能。
压缩激发网络SENet通过在特征通道之间建立相关性,来调整图像特征图的通道权重,加强具有判别能力的特征,弱化非判别能力的特征,特征图通道的权重是采用学习方式获得的。进而增强了网络计算的针对性,达到了提升检测效果的目的。其中压缩Squeeze模块和激励Excitation模块,共同构成了其总网络结构。图2为SENet网络结构。
其中,Squeeze操作主要是对特征通道数分别为H×W×C的输入进行全局平均池化,使得输出为1×1×C的数据。Squeeze操作如公式(1)所示,其中z∈R是通过对特征u在空间维度H×W进行缩放产生的。
Squeeze操作后,则进行Excitation操作。其主要通过赋值操作,赋予两层全连接层各自一个权重值,来构建不同通道互相之间的非线性相互作用关系,如公式(2)所示。式(2)中的σ和δ参数分别表示为激活函数sigmoid和relu,W1∈R(C/r)×C,W2∈R(C/r)×C。
再进行Reweight操作,则将Excitation的输出的权重看作每个特征通道的重要性,然后将之前的特征通过乘法逐通道加权到原有的特征上,对原始特征在通道维度上重新校准。Fscale为通道上的乘积,计算过程如公式(3)所示,uc∈RH×W。
ResNeXt网络结构是在ResNet网络结构基础上优化得到的,其主要运用了Inception的重构网络结构的思想,将模型中采用叠加操作卷积层变成了自网络的叠加,在提高检测准确率的同时,克服了传统卷积神经网络模型为了提高模型的准确率需要加深网络的宽度和深度的困难,解决了网络结构加深带来的梯度消失问题。不同于Inception结构之处是,ResNeXt在多路径上采用相同的拓扑结构共享超参数,通过基数来控制卷积分支数,减少了需要手动调节控制的超参数,进一步提高了模型可扩展性。ResNet和ResNeXt的结构对比如图3所示。
结合SE-Net网络的特点,将ResNeXt网络结构与SE-Net网络相融合,通过SE-Net通道注意力机制的引入,对各个通道进行加权,从而侧重于权重值大的通道特征,削弱对当前任务不重要的通道特征,进而改善ResNeXt网络性能。改进后的SE-ResNeXt结构,既能避免在网络层数激增的同时所带来的梯度消失问题,又能确立特征通道之间的关联情况,提升结节分类的能力。
2.2 增加SPP模块
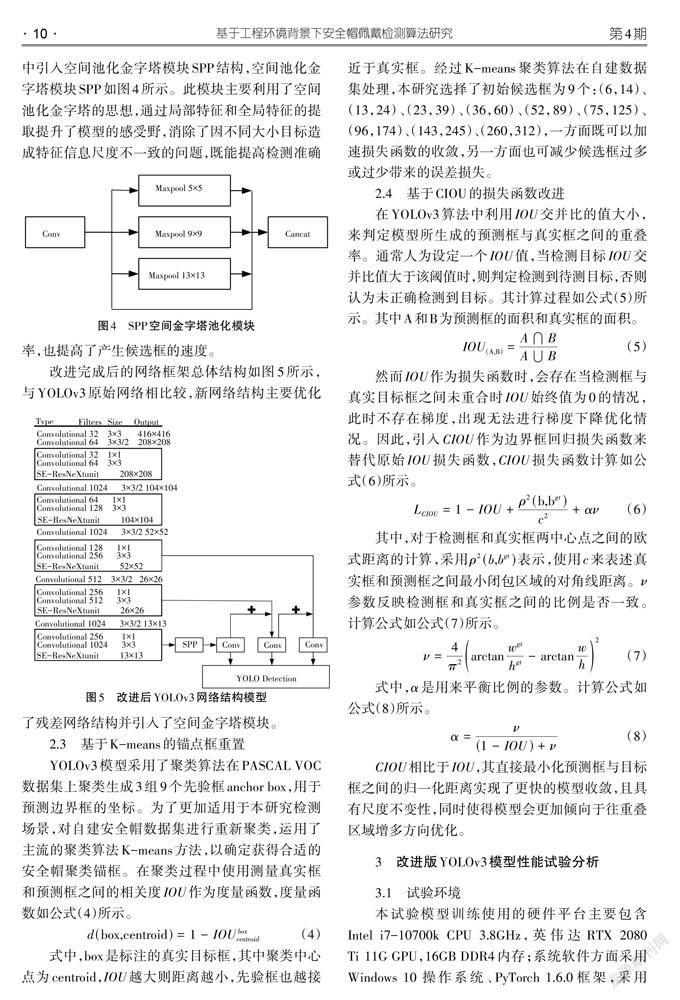
在实际检测中发现,检测距离的不同会导致输入检测网络中的安全帽信息尺度存在大小不一致问题。为了克服这一问题,在改进的模型骨干网络中引入空间池化金字塔模块SPP结构,空间池化金字塔模块SPP如图4所示。此模块主要利用了空间池化金字塔的思想,通过局部特征和全局特征的提取提升了模型的感受野,消除了因不同大小目标造成特征信息尺度不一致的问题,既能提高检测准确率,也提高了产生候选框的速度。
改进完成后的网络框架总体结构如图5所示,与YOLOv3原始网络相比较,新网絡结构主要优化了残差网络结构并引入了空间金字塔模块。
2.3 基于K-means的锚点框重置
YOLOv3模型采用了聚类算法在PASCAL VOC数据集上聚类生成3组9个先验框anchor box,用于预测边界框的坐标。为了更加适用于本研究检测场景,对自建安全帽数据集进行重新聚类,运用了主流的聚类算法K-means方法,以确定获得合适的安全帽聚类锚框。在聚类过程中使用测量真实框和预测框之间的相关度IOU作为度量函数,度量函数如公式(4)所示。
式中,box是标注的真实目标框,其中聚类中心点为centroid,IOU越大则距离越小,先验框也越接近于真实框。经过K-means聚类算法在自建数据集处理,本研究选择了初始候选框为9个:(6,14)、(13,24)、(23,39)、(36,60)、(52,89)、(75,125)、(96,174)、(143,245)、(260,312),一方面既可以加速损失函数的收敛,另一方面也可减少候选框过多或过少带来的误差损失。
2.4 基于CIOU的损失函数改进
在YOLOv3算法中利用IOU交并比的值大小,来判定模型所生成的预测框与真实框之间的重叠率。通常人为设定一个IOU值,当检测目标IOU交并比值大于该阈值时,则判定检测到待测目标,否则认为未正确检测到目标。其计算过程如公式(5)所示。其中A和B为预测框的面积和真实框的面积。
然而IOU作为损失函数时,会存在当检测框与真实目标框之间未重合时IOU始终值为0的情况,此时不存在梯度,出现无法进行梯度下降优化情况。因此,引入CIOU作为边界框回归损失函数来替代原始IOU损失函数,CIOU损失函数计算如公式(6)所示。
其中,对于检测框和真实框两中心点之间的欧式距离的计算,采用ρ(b,b)表示,使用c来表述真实框和预测框之间最小闭包区域的对角线距离。ν参数反映检测框和真实框之间的比例是否一致。计算公式如公式(7)所示。
式中,[α]是用来平衡比例的参数。计算公式如公式(8)所示。
CIOU相比于IOU,其直接最小化预测框与目标框之间的归一化距离实现了更快的模型收敛,且具有尺度不变性,同时使得模型会更加倾向于往重叠区域增多方向优化。
3 改进版YOLOv3模型性能试验分析
3.1 试验环境
本试验模型训练使用的硬件平台主要包含Intel i7-10700k CPU 3.8GHz,英伟达RTX 2080 Ti 11G GPU,16GB DDR4内存;系统软件方面采用Windows 10 操作系统、PyTorch 1.6.0框架,采用CUDA10.2和CUDNN7.6为GPU训练进行加速。
3.2 试验数据集
本研究试验数据主要由两个部分构成,一部分选用开源的安全帽数据集,包括SHWD、Hard Hat Workers Dataset等部分图片,另一部分图片主要为从施工场地现场进行视频拍摄帧截取得到的,避免单一从网上爬虫获取导致脱离实际应用背景。总数据集共包括了8 000张各种类型安全帽佩戴图片并参考VOC2007标注格式,利用开源数据标注工具Labeling对数据集进行标注。其中,正确佩戴安全帽标记为hat,未佩戴安全帽标记为no-hat。训练集、测试集及验证集分别从随机总数据集中抽取,对应训练集6 000张图片,测试集及验证集各1 000张图片。其中,测试集不含标注信息,且测试集和训练集无重复,从而达到验证目的。
3.3 评测指标
为了验证改进后的YOLOv3算法性能,本研究采用了平均精准度(mean Average Precision,mAP)以及每秒检测帧数(FPS)等指标来对算法模型进行评估。其中,单类别的平均准确率采用AP表示,mAP则为多类别的AP均值。mAP的值越大则整体的识别率越高。计算方法如公式(9)所示,Precision和Recall为准确率和召回率。其中,TP (True Positives)计算如下。
数据集中正确判定为正例的实例数FP (False Positives)为数据集被误标记为正样本的实例数。FN (False Negatives)为数据集中误标记为负样本的实例数。
3.4 试验结果分析
采用建立好的安全帽训练集对提出的模型进行训练,训练的参数主要参考了YOLOv3原始网络的训练参数,结合训练平台硬件参数,对训练中部分参数再进行优化,使得整个网络检测效果达到较佳,训练的参数设置如表1所示。
3.5 算法性能测试及其对比试验
为了验证改进后的网络模型的检测效果,本研究将改进版YOLOv3算法与原始YOLOv3模型、Faster-RCNN以及SSD模型运用相同的测试数据集进行对比验证,选择统计并计算使用mAP指标、每秒识别帧数进行对比,评估模型。其中输入测试集图像尺寸为[416×416],检测结果如表2所示。
3.6 结果分析
从试验结果分析可得,改进后的YOLOv3算法mAP相比于其他对比算法都更高,达到了92.14%,对比于原始的YOLOv3算法检测精度mAP提高了4.29%,且每秒检测帧数(FPS)提高了8.67%,达到了每秒28.8帧,基本上达到了实时检测的要求。尽管SSD算法相比于本研究算法其检测速度更佳,在实际检测过程中针对待测目标较小以及遮挡情况等出现了明显误检、漏检情况,整体检测精度较差。而本文算法在确保检测准确率的同时,检测速率也能达到实时检测,具备较佳的工程应用价值。
为了进一步展示原始YOLOv3算法以及改进后YOLOv3算法的检测效果对比,本研究从验证集中选取了部分样本进行检测,其中包含颜色形状干扰、脚手架遮挡以及小目标检测等情况,检测结果如图6所示。图7给出了不同状态下的部分测试结果,其中最左边为原始图像、中间为原始YOLOv3算法检测图像、右侧为改进后YOLOv3算法检测结果。由图7可以看出,在存在遮挡、检测目标小以及相似形状等复杂环境背景下,本算法均能正确识别与检测,而原始YOLOv3模型却存在着部分漏检、误检的情况。
4 结论与展望
针对在工程施工领域安全帽佩戴检测效果不理想情况,本研究在原始YOLOv3网络模型的基础上,通过引入SE-ResNeXt残差单元改进原始特征提取网络Darknet53中的ResNet残差结构,在加深网络深度、获取更高级别语义信息的同时,减少了由于加深网络深度带来的模型退化问题。在模型最后,引入了SPPNet空间池化金字塔模块,对待测图片进行多尺度提取,提高了检测精度。同时,使用CIOU替换原始的IOU损失函数,帮助模型在提高检测效率的同时,更快收敛。由在自建的数据集上测试验证可知,改进后的YOLOv3检测模型与原始的YOLOv3检测模型相比,准确率mAP从87.85%提高到92.14%,提高了4.29%,每秒检测帧数(FPS)提高了8.67%,达到了每秒28.8帧。通过对施工现场摄像头采集视频流图像识别结果表明,改进后的YOLOv3算法检测准确率较高,识别速度快,具备工程使用价值。
参考文献:
[1] 常欣,刘鑫萌.建筑施工人员不合理佩戴安全帽事故树分析[J].吉林建筑大学学报,2018,35(6): 65-69.
[2] RUBAIYAT A,TOMA T T,KALANTARI-KH-ANDANI M, et al. Automatic Detection of Helmet Uses for Construction Safety[C]// IEEE/WIC/ACM International Conference on Web Intelligence Workshops. ACM, 2017.
[3] 李琪瑞.基于人体识别的安全帽视频检测系统研究与实现[D].成都:电子科技大学, 2017.
[4] 徐守坤,王雅如,顾玉宛,等.基于改進Faster RCNN的安全帽佩戴检测研究[J].计算机应用研究,2020,37(3):901-905.
[5] 王秋余.基于视频流的施工现场工人安全帽佩戴识别研究[D].武汉:华中科技大学,2018.
[6] 郭玥秀,杨伟,刘琦,等.残差网络研究综述[J].计算机应用研究,2020,37(5):1292-1297.
猜你喜欢
软件(2016年4期)2017-01-20
科教导刊·电子版(2016年28期)2017-01-10
科学与财富(2016年28期)2016-10-14
电脑知识与技术(2016年5期)2016-04-14
科技视界(2016年4期)2016-02-22
现代电子技术(2015年14期)2015-07-22
