
基于CPU-GPU 异构并行的复杂场地近断层地震动谱元法模拟*
2022-03-31 08:06巴振宁赵靖轩吴孟桃梁建文1
地震学报 2022年1期
巴振宁 赵靖轩 吴孟桃 梁建文1,
1) 中国天津 300354 中国地震局地震工程综合模拟与城乡抗震韧性重点实验室
2) 中国天津 300354 天津大学土木工程系
引言
复杂场地地震波场模拟一直是地震学领域中比较活跃的研究课题(孙吉泽等,2017).目前较为成熟的数值模拟方法主要包括有限元法(finite element method,缩写为FEM)、有限差分法(finite difference mehod,缩写为FDM)和谱元法(spectral element method,缩写为SEM)等,其中谱元法自二十世纪末被引入,该方法集合伪谱法高精度和有限元法高灵活性的优势,目前已成为大尺度复杂场地地震波场模拟的主流方法(刘少林等,2021).
随着模拟场地范围的扩大和模拟频率的提高,整体模型的网格数量急剧上升,庞大的计算量和存储需求给数值模拟造成了一定困难.借助高性能计算手段可以解决这一问题,高性能计算主要包括中央处理器(central processing unit,缩写为CPU)并行和图形处理器(graphics processing unit,缩写为GPU)并行两种方法,其中CPU 并行主要通过提高CPU 并行的数量达到提高计算速度的目的(刘春成等,2019).国内外已有相关学者应用CPU 并行方法进行大尺度复杂场地的地震动SEM 数值模拟(Komatitschet al,2004;Stupazziniet al,2009;胡元鑫等,2011;Chaljubet al,2015;于彦彦,2016;刘启方,2020).但由于CPU 并行规模受计算机性能限制,并行规模越大维护成本相对越高,且当CPU 核数达到一定数量时,加速度比很难进一步提高,这些因素限制了CPU 并行计算在大尺度复杂场地波场数值模拟上的应用(陈曦等,2016).近年来,GPU 在通用计算领域应用十分的广泛,高端GPU 显卡的浮点运算最高约达每秒万亿次,在台式机或工作站内配置数块GPU 计算卡即可实现大规模并行计算(熊琛等,2016).这种并行计算方式相较于CPU 并行方法量级更轻,加速效果更为明显,而且在成本和功耗上也不需要付出额外代价(Liet al,2012).基于上述GPU 计算能力优势,Komatitsch 等(2009)将GPU 并行方法引入SEM 数值模拟之中,并取得较好的加速效果.然而目前GPU 并行计算在SEM 数值模拟中的应用尚处于基础阶段,应用于大尺度复杂场地近断层地震动模拟的研究较少,因此,基于CPU-GPU 异构并行架构进行复杂场地地震波场模拟,进一步研究GPU 对于数值模拟的加速效果具有十分重要的意义.
基于上述分析,本文拟通过建立基本的动力学断层模型,使用开源谱元程序SPECFEM3D分别在CPU 并行和CPU-GPU 异构并行系统下进行计算,比较分析CPU-GPU 异构并行计算的精度和效率;然后建立北京三河—平谷地区三维速度结构模型并根据已有文献确定近断层位置,构建含动力学断层的三维地形复杂模型,利用CPU-GPU 异构并行模拟1679 年三河—平谷M8.0 地震的近断层地震动作用下北京地区的地震动响应,以期得到近断层地震动特性以及复杂地形对近断层地震动产生的影响,可为近场复杂场地地震动估计、工程抗震设计以及利用GPU 加速技术进行复杂场地近断层地震动模拟提供参考.
1 CPU-GPU 异构并行方法
1.1 GPU 通用计算基本原理
目前流行的GPU 通用计算平台是NVIDIA 公司2006 年推出一种新的计算模式即统一计算设备架构(compute unified device architecture,缩写为CUDA),其具体内部架构如图1 所示,可以看出,GPU 相较于CPU 控制单元数量少,指令流控制能力较差,但其内计算单元的数量远多于逻辑控制单元,因此在CUDA 架构中,首先构造简单的数据计算模型,避免复杂的指令流控制;然后创建大规模的线程计算模型,在模型中由CPU 来控制主程序,GPU 作为协处理器,由GPU 处理模型中大量的并行计算部分,以达到提升计算速度的目的(Shiet al,2012),并且由于GPU 与主机通过卡槽相连,数据传输带宽高于传统的通信网络(Campaet al,2014).CPU-GPU 异构并行系统搭建方式如图2 所示,通过CUDA 并行计算架构将GPU 的计算任务映射为大量的可以并行执行的线程,并由硬件执行这些线程.内核函数(kernel)以线程网格(grid)的形式组织,每个线程网格由多个线程块(block)组成,每个线程块由多个线程(thread)组成(Machidonet al,2020).
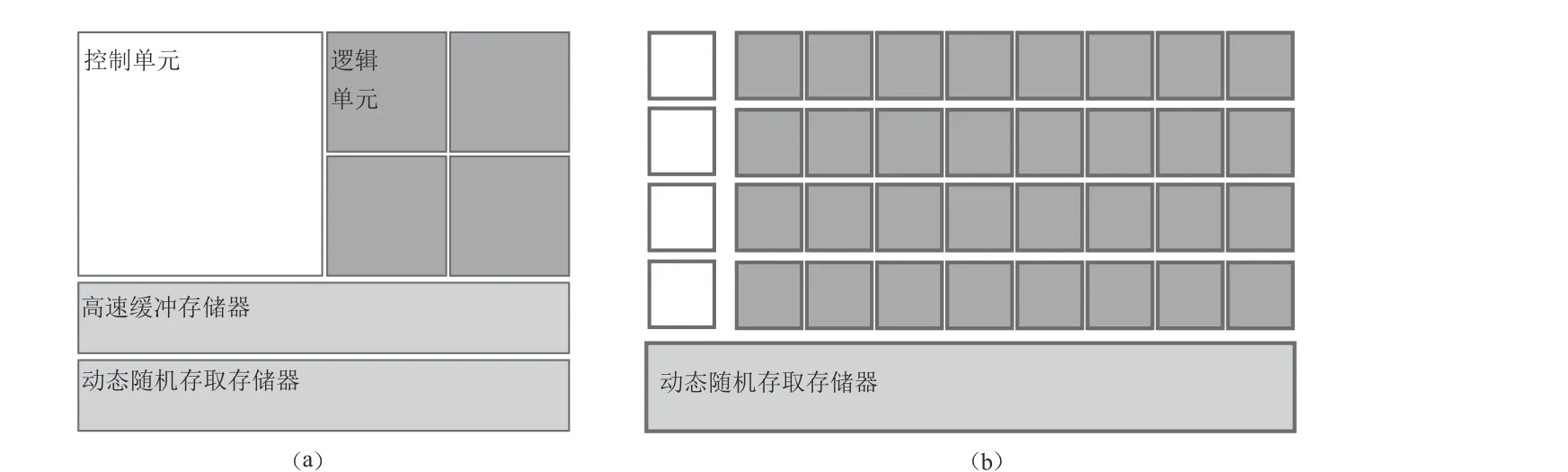
图1 CPU (a)和GPU (b)内部结构Fig. 1 Internal structure of CPU (a) and GPU (b)
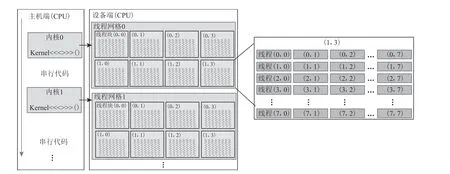
图2 CPU-GPU 异构并行架构Fig. 2 CPU-GPU heterogeneous parallel architecture
1.2 SEM 在CPU-GPU 异构并行系统中的实现
在SEM 数值模拟中,时间递进采用串行计算的方式,通常基于显式的二阶有限差分时间方法.在串行时间递进中进行大量迭代时所用的时间决定整个模拟过程的总时间,而在SEM 模拟中其它部分包括预处理和后处理阶段,其时间成本可以忽略不计,故本文将利用GPU 可并行计算大规模线程的优点,尽量缩短每个时间步内迭代的时间,有效地提高计算效率.并且由于数值计算中选用了静态网格划分方法和显示计算方法,导致时间递进中的每次迭代在内存和计算时间上均保持相同的成本,更有利于实现GPU 并行系统的加速效果.
在CPU-GPU 异构并行系统内,首先根据CPU 核心数将三维模型分解为相应个数的子域,各个子域通过消息传递接口(message passing interface,缩写为MPI)在每个时间步后进行各个子域之间的数据通讯,在每个时间步内采用CPU-GPU 异构并行计算模式,由CPU 负责逻辑运算和数据传输,GPU 负责执行大量线程的并行计算,计算完成后将数据传输至CPU 端.在单个时间步内GPU 执行的计算可以概括为以下三个步骤,其对应于图3 中的三个CUDA 内核函数.
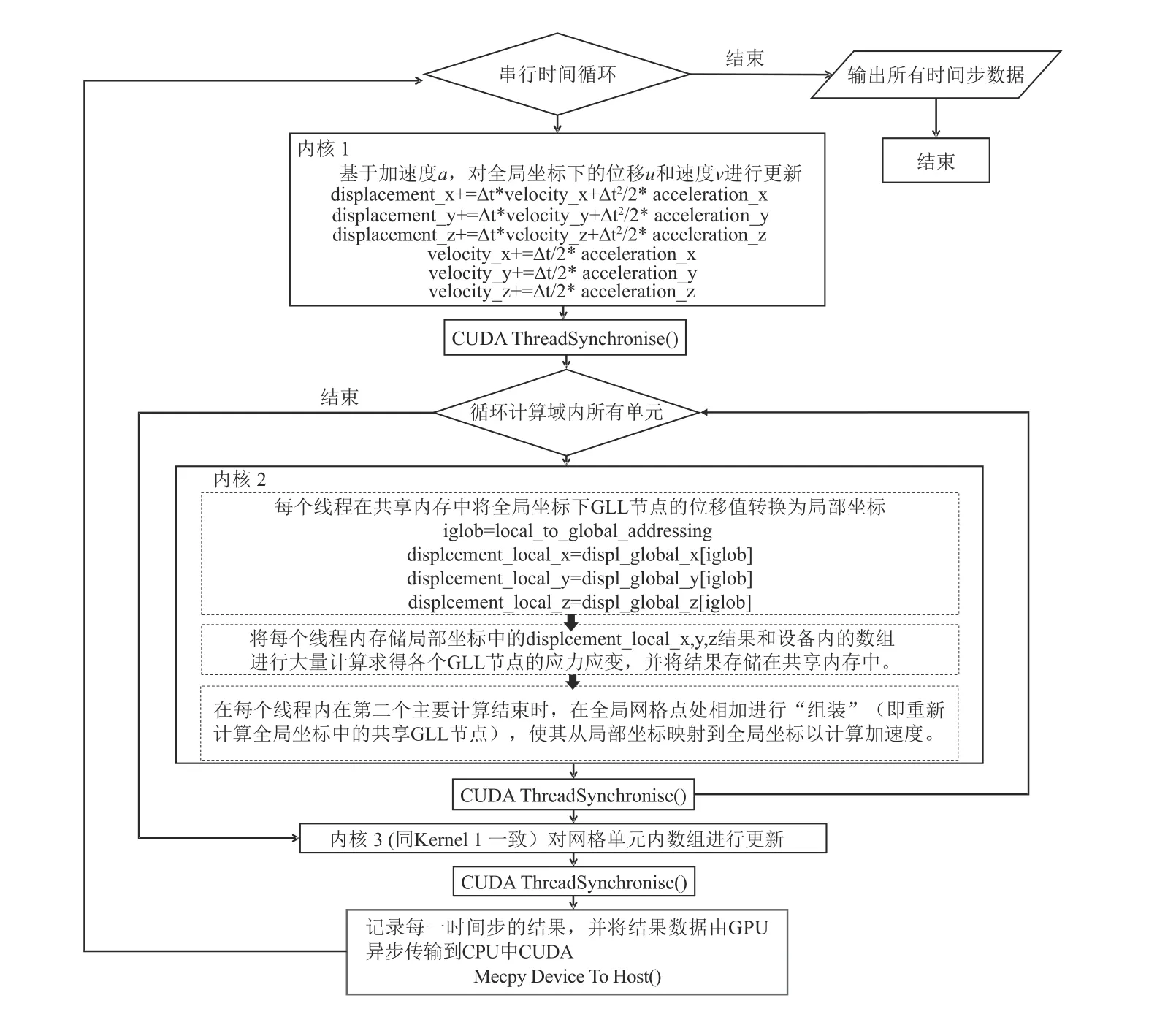
图3 SEM 中CPU-GPU 异构并行流程Fig. 3 CPU-GPU heterogeneous parallel process in SEM
1) 基于前一时间步计算的加速度a,采用纽马克(Newmark)时间方法对整体模型中所有网格点的全局位移u和速度v进行计算更新.
2) 首先将全局的位移结果映射到局部单元上,在每一个网格单元上的53个高斯-洛巴托-勒让德(Gauss-Lobatto-Legendre,缩写为GLL)积分节点中进行数组计算,得到GLL 节点的应力应变值,此时的单元之间应是相互独立的;然后将计算得到的值进行装配,相邻的单元之间共享的网格节点进行叠加;最后将局部映射到全局编号,再次计算加速度a.
3) 基于第二步计算的加速度a对全局坐标下所有GLL 节点的速度v进行更新.由于第二步计算中加速度结果发生了改变,因此无法进行合并只能在第三步中选择计算更新.
2 基本模型试算
本节通过南加州地震中心(Southern California Earthquake Center,缩写为SECE)和美国地质调查局(SUnited States Geological Survey,缩写为USGS)自发破裂程序验证项目(spontaneous rupture code verification project)提供的基准断层模型TPV15,分别在CPU 并行与CPU-GPU 异构并行系统下进行计算,通过对比同一观测点的位移和速度结果,测试在异构并行系统下计算结果的正确性和有效性,并在此基础上通过改变TPV15 模型的网格数量,对比工作站内单块CPU 共36 核并行、两块CPU 共72 核并行以及CPU-GPU 异构并行系统下的计算时间,进行并行计算效率分析.工作站内CPU 和GPU 型号说明列于表1.

表1 CPU 和GPU 硬件参数Table 1 CPU and GPU hardware parameters

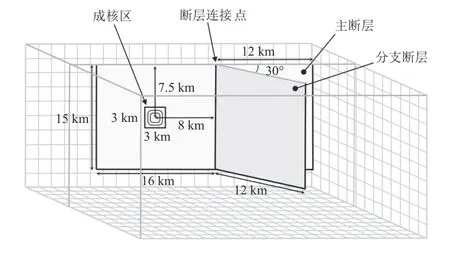
图4 TPV15 断层模型Fig. 4 TPV15 fault model

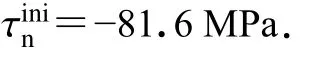
选取与SCEC/USGS 自发破裂程序验证项目TPV15 算例中一个相同观测点,位置如图5 所示(沿走向方向2 km,沿垂直方向−0.6 km,沿深度方向0 km),基于CPUGPU 异构并行系统下计算得出该观测点的位移和速度三分量结果,与提供的结果进行对比,如图6 所示,可见两曲线在波形和幅值上基本吻合,验证在CPU-GPU异构并行系统下模拟动力学断层震源具有较高的计算精度.
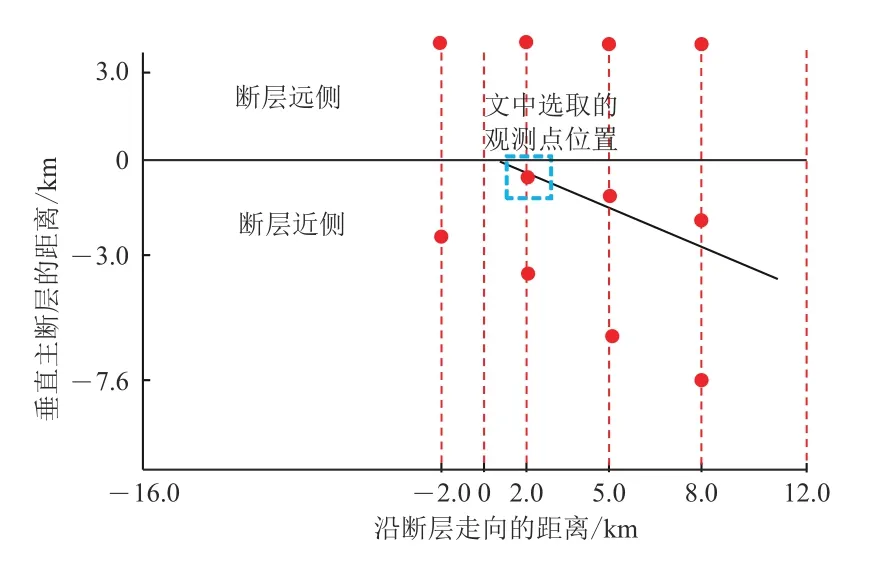
图5 观测点位置示意图Fig. 5 The diagram of observation point position
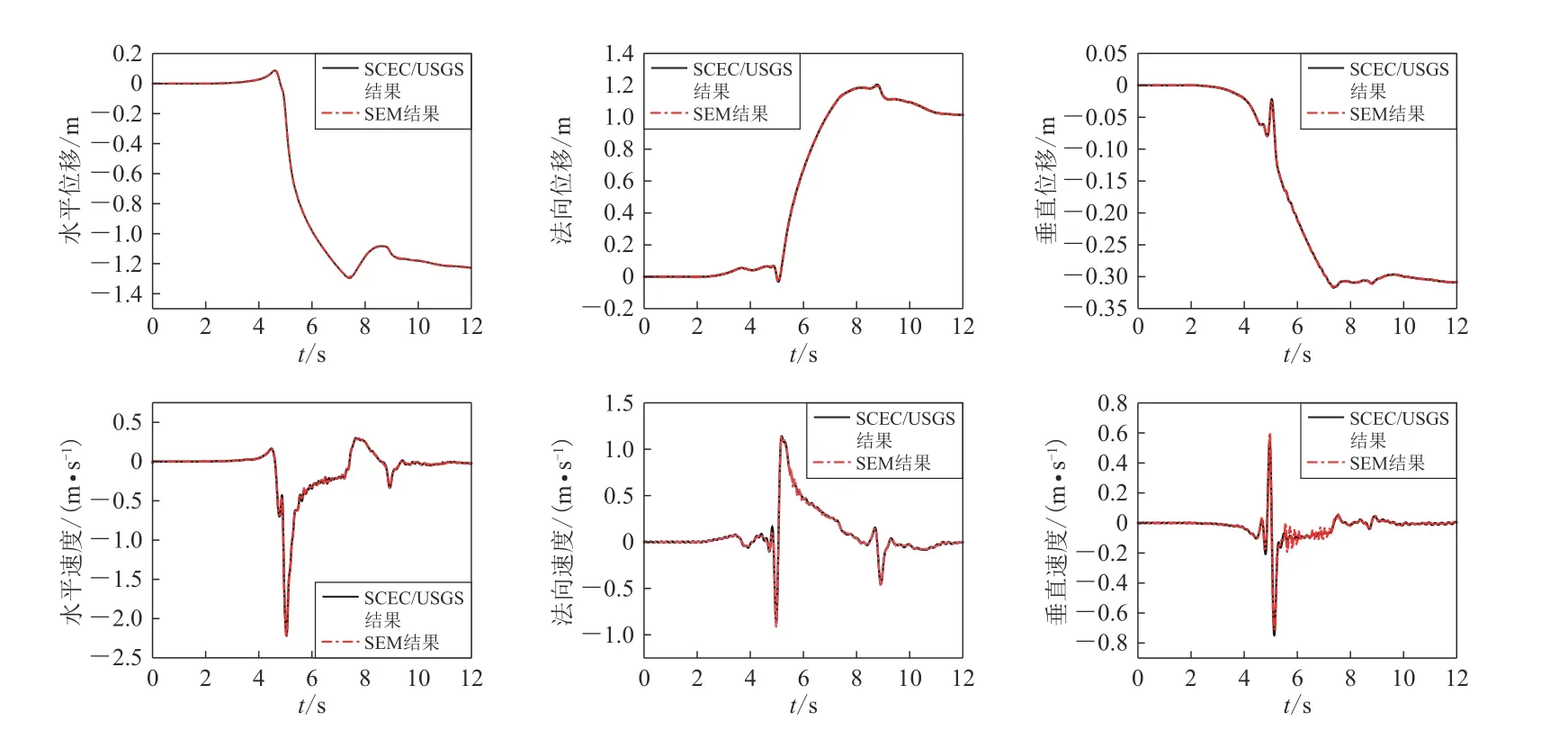
图6 CPU-GPU 异构并行系统计算的观测点位移、速度三分量与SECE/USGS 提供结果对比Fig. 6 The results of displacement and velocity in three directions at the observation point compared between CPU-GPU heterogeneous parallelism and SECE/USGS
同时为了测试CPU-GPU 异构并行系统的计算性能和计算效率,通过改变TPV15模型的网格尺寸来改变网格的单元数量并分别应用CPU36 核、72 核和CPU-GPU 异构并行进行计算,对比三者完成计算的时间(图7),发现应用GPU 参与并行计算取得的加速效果十分明显.相较于CPU36 核的计算时间,GPU 的加速比最高为其3.04 倍;与CPU72 核的计算时间相比加速比最高可达2.16 倍.综上表明CPU-GPU 异构并行系统在进行大尺度复杂区域地震波场模拟计算方面具有明显的优势.

图7 不同网格数量计算时间对比Fig. 7 Calculation time between different grid numbers
3 示意性算例
1679 年发生的三河—平谷地震是北京周边发生的有资料记载的最大地震,推断震级为M8.0,震中距北京市中心约50 km (刘培玄等,2019).据史料记载,此次地震由于震级较大、波及范围广、地震余震的持续时间长,造成了大量的人员伤亡和财产损失(朱耿尚,2014).然而由于很多历史大震特别是古地震缺乏地震记录,难以进行震源破裂过程的反演,只能采用实际地质考察和数值模拟结合的方法,大致复现出古地震发生时周围区域的地震动响应.在考察分析相关资料的基础上,研究人员对1679 年三河—平谷地震的震源参数进行了假定,并基于不同的数值方法对三河—平谷地震中不同的物理问题进行较为详细的研究,对深入理解震源模型的设置以及强地面运动模拟都起到一定的指导意义(高孟潭等,2002;刘博研等,2007;潘波等,2009;付长华,2012;张文强,2020).本文将参考上述研究成果,在CPU-GPU 异构并行系统下应用动力学断层震源模拟在三河—平谷地区发生M8.0 地震时北京地区强地面运动,研究近断层地震动特征及实际地形对近断层地震动产生的影响.本次模拟计算区域如图8 所示,其中模型经纬度范围为(116.0°—117.5°E,39.6°—40.5°N),根据目标区域得到计算模型沿东西长约为130 km,南北宽约为120 km,纵向高度约为40 km.借鉴付长华等(2015)对三河—平谷地震介质模型、断层面大小以及位置,其中断层面应力以及摩擦参数参考TPV15 模型进行设置.为保证计算结果的精确可靠,要求SEM 中最短波长中至少包含5 个网格点,本文设定能模拟的最大频率为1 Hz,网格总数约为270 万,GLL 节点个数高达1.94 亿,时间步距取为0.005 s.模拟90 s 内的地震波传播,分别基于CPU36 核、CPU72 核、CPU-GPU 异构并行系统进行计算,计算时间分别为25.3 h,14.6 h 和9.5 h,表明CPU-GPU 异构系统计算加速效果显著.三河—平谷地震发生时地表在不同时刻的地震波波场三分量快照如图9 所示.
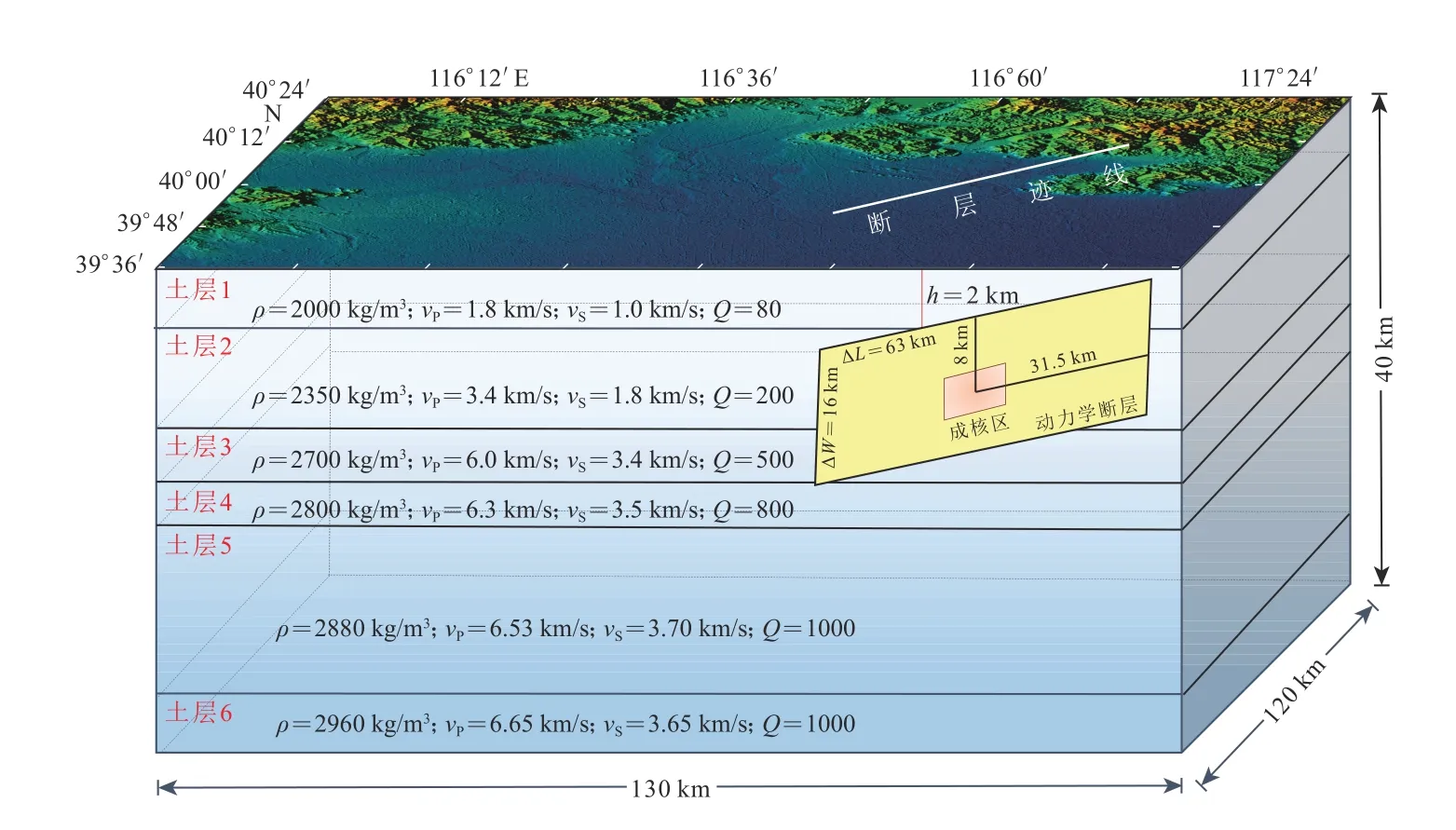
图8 北京地区断层投影位置及整体三维物理模型Fig. 8 Fault projection location and 3-D physical model in Beijing
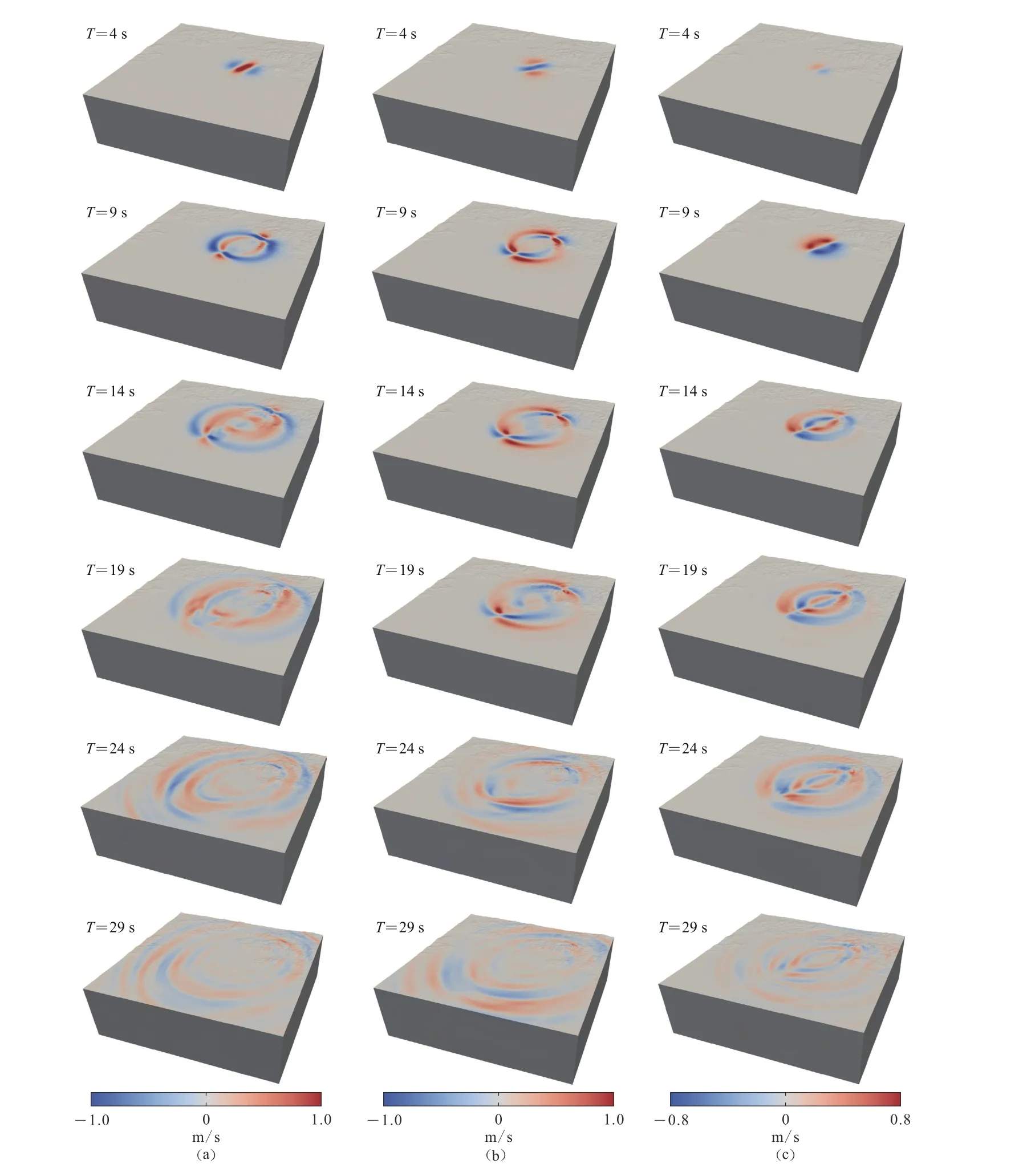
图9 不同周期下三维速度波场快照(a) 东西方向;(b) 南北方向;(c) 竖直方向Fig. 9 The snapshots of the three-dimensional velocity wave field under different cycles(a) EW direction;(b) NS direction;(c) Vertical direction
为研究近断层地震动对周围重点区域的影响,本文在三河—平谷断层周边选取8 个观测点,分别给出水平(EW)方向和竖直方向的加速度、速度和位移结果(图10),并将各个观测点对应的震中距和峰值地震动列于表2,以进一步研究近断层地震动特性,同时观察近断层破裂时对周边区域造成的影响.
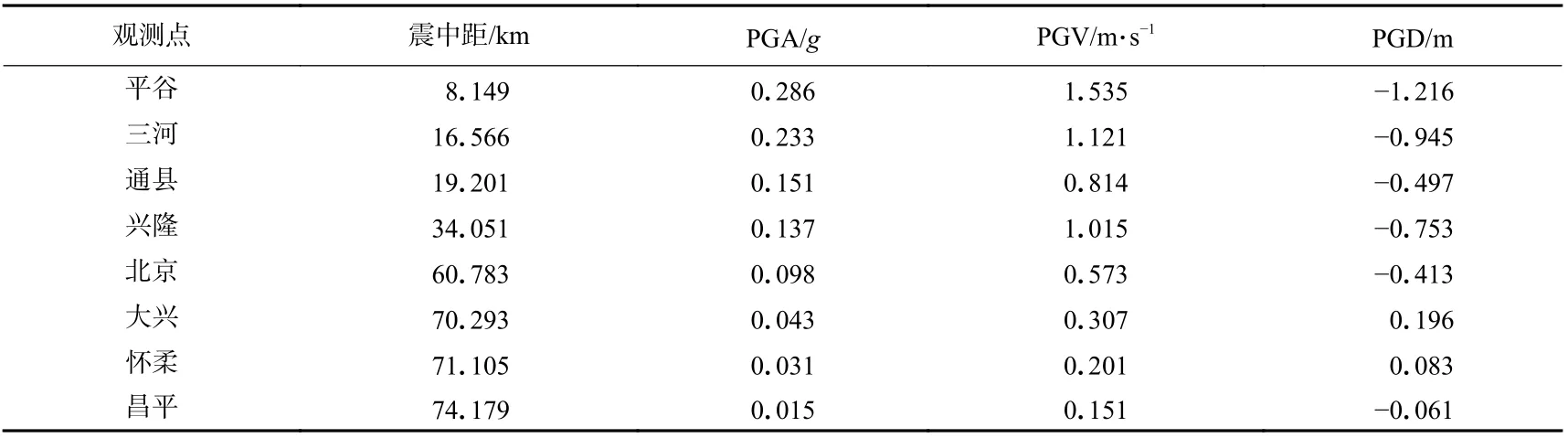
表2 不同观测点对应的震中距以及地震动峰值Table 2 Different observation points of epicenter distance and the peak value of ground motion

图10 各观测点水平 (左) 与竖直 (右)方向的加速度(a)、速度(b)和位移(c)时程Fig. 10 Acceleration (a), velocity (b) and displacement (c) time histories corresponding to each observation points in horizontal (left) and vertical (right) directions
由图10 可见,此次模拟很好地反映了近断层效应:加速度峰值主要集中在沿发震断层两侧一个狭窄的范围内,其中平谷地区的峰值加速度最大达到0.286g,并且随着断层距的增加,加速度峰值迅速衰减,昌平地区的峰值加速度只达到0.015g,这一近断层特征被总结为近断层的集中效应,该特征在一些大地震观测记录中也得到了实证(如1970 年通海地震、1995 年日本阪神地震、1999 年集集地震、2008 年汶川地震和2018 年精河地震等)(刘启方等,2006);近断层速度大脉冲现象显著,对比图10b 可以看出,靠近断层位置的三河、平谷等地区出现了速度峰值大、持时短的速度脉冲现象,平谷地区水平方向的峰值速度为1.535 m/s,三河地区水平方向的峰值速度为1.121 m/s,同时观察到由于断层设置为右旋的垂直走滑断层,沿水平方向的速度时程结果均高于竖直方向的结果,体现了近断层的方向性效应;近断层效应中比较重要的特性为地面的永久变形,该现象在靠近断层的位置相对明显,远离近断层的区域则永久位移现象并不明显,以平谷地区为例,模拟中水平最大位移达到1.216 m,永久位移达到0.63 m.
结果中除近断层地震动效应比较明显之外,地形效应对近断层地震动影响同样显著.以兴隆观测点为例,其地震动响应明显高于平原地区的位置水平峰值加速度达到0.137g,水平峰值速度达到1.015 m/s,同时三河—平谷地区地震动持时为25 s,通州地区地震动持时为30 s,对比可以看出兴隆地区地震动持时明显延长,地震动持续时间接近45 s.出现上述现象的主要是由于兴隆地区位于燕山山脉中段,地震波传播至山体地形时出现了明显的能量聚集效应(郝明辉,张郁山,2019),导致其地震动峰值增大,持时明显延长.
4 讨论与结论
本文为拓展单台工作站模拟大尺度复杂场地地震动的能力,有效提高谱元法模拟的计算效率,基于CUDA 编程平台实现了工作站级的CPU-GPU 异构并行方法,并利用该异构并行方法分别进行了SECE/USGS 提供的自发破裂模型TPV15 和1679 年三河—平谷M8.0 强地面运动模拟,得到主要结论如下:
1) 根据SECE/USGS 提供的自发破裂模型TPV15 以及计算结果,对比同一观测点的速度、位移三分量结果,验证了CPU-GPU 异构并行系统下谱元法模拟动力学断层的精度.改变网格数量对比CPU36 核、CPU72 核以及CPU-GPU 异构并行的计算时间,测试结果显示加速比最高可达到CPU 36 核和72 核并行的3.04 倍和2.16 倍,表明CPU-GPU 异构并行方法不仅满足计算精度要求,同时大大降低了计算时间,体现了工作站级CPU-GPU 异构并行方法的计算优势.
2) 本文模拟了1679 年三河—平谷M8.0 地震中北京地区强地面运动的取得良好的加速效果,模拟结果体现了包括集中性、方向性、地面永久位移等近断层地震动的基本特征,以及地形效应对近断层地震动产生的显著影响,验证了所提出的异构并行方法对真实设定地震动模拟的适用性.在未来可进一步增加GPU 并行数量,在工作站内基于CPU-GPU 异构并行系统拓展到更精细化和范围更广的复杂场地地震动模拟,为地震区划、抗震设防等工作提供参考依据.
猜你喜欢
中国奶牛(2022年9期)2022-10-16
猪业科学(2022年2期)2022-04-21
现代农村科技(2021年2期)2021-03-15
绿色科技(2019年12期)2019-07-15
北广人物(2019年20期)2019-06-04
中国公路(2017年14期)2017-09-26
科技视界(2016年19期)2017-05-18
杭州(2016年2期)2016-03-23
中小企业管理与科技·中旬刊(2014年10期)2015-02-03
中国卫生(2014年5期)2014-11-10
