
基于迭代训练的古文短文本聚类方法研究
2022-04-14 03:26李晓璐赵庆聪
现代计算机 2022年2期
李晓璐,赵庆聪,3,齐 林
(1.北京信息科技大学信息管理学院,北京 100192;2.北京信息科技大学经济管理学院,北京 100192;3.绿色发展大数据决策北京市重点实验室,北京 100192;4.北京世界城市循环经济体系(产业)协同创新中心,北京 100192)
0 引言
中国传统文化源远流长,中华民族创造了无数文化瑰宝,现阶段需要通过科技的力量将这些宝贵的文化财富融入现代生活中。但是由于传统文化体系庞大,加大了获取和理解传统文化的难度,因此实现中国传统文化的体系分类是一项需迫切解决的问题。本研究基于课题组的中国传统文化素材库进行主题聚类研究,该素材库的数据源为《四库全书》和《太平御览》。从上述数据源抽取出古文短文本数据集,通过自然语言处理以及聚类算法挖掘出该数据集的内在联系和潜在信息,得到每一条文本所属具体类别。该数据集表现为短文本词条的形式,短文本不同于传统文本,短文本包含的有效信息量少,具有特征稀疏等特点,且部分词条内容夹杂古文,基于机器学习的传统文本聚类算法效果不佳。
传统短文本聚类往往利用向量空间来进行文本的表示,而该文本表示方法具有特征稀疏、特征维度高,且忽略文本语义等特点。Shangfu Gong等在分析传统互信息缺陷的基础上,提出了一种基于二次TF-IDF互信息的特征选择方法,实验证明该方法对特征降维有效。郭颂等从信息增益的角度进行特征降维,提出了一种基于特征分布差异因子加权的算法,改善了文本表示的表征能力。这些降维方法可以有效的提高长文本的聚类效果,但是短文本由于其自身的特点并不适用。随着深度学习的发展,王月等使用BERT(Bidirectional Encoder Representation From Transformers)预训练模型来代替Word2vec的Skip-gram和CBOW来进行词向量的训练,实验表明,该方法极大地提高了词向量的表征能力。Rakib等提出一种基于迭代分类的聚类增强算法,实验表明,其可提高任意基线聚类算法的聚类结果。Pugachev等在Rakib工作的基础上,引入了BERT预训练模型,实验结果表明该方法提高了其在英文公开数据集上的聚簇效果。结合该古文数据集特征稀疏,上下文语义信息联系紧密等特点,本文尝试采用BERT预训练模型作为生成词向量的方法,结合K-means聚类算法+迭代分类模型进行训练,提出一种BERT+K-means+迭代分类思想的融合模型,对该古文短文本进行聚类研究。
1 相关研究
1.1 文本表示方法
短文本表示是文本挖掘、信息检索以及自然语言处理(NLP)等研究的基础,文本表示是为了将非结构化的文本数据转化为计算机可以处理的数据格式。学术界目前提出了多种文本表示模型,传统的文本表示方法有向量空间模型(Vector Space Model,VSM)、语言模型、本体等。利用高效的文本特征提取方法来构造文本表示模型是提高短文本聚簇效果的关键。随着计算机性能的不断提升,深度学习在自然语言处理(NLP)中也发挥着越来越重要的作用,基于语义信息的词向量表示模型成为现在研究的重点。
1.1.1 向量空间模型
向量空间模型(VSM)由G.Salton首次提出,是一种基于词袋模型的文本表示方法。向量空间模型将文本转换为空间中的向量形式,特征词的个数即为向量的维数。假如一个文本文档包含n个特征项,则文本可以表示为如下公式:D=((t,w),(t,w),…,(t,w)),其中t表示文本第i个特征词,w表示文本第i个特征词的权重值。表1描述了文档集-特征项矩阵表示的文本集。

表1 VSM文档集-特征项矩阵示例
传统的向量空间模型一般使用TF-IDF来计算文档中特征项的权重,TF-IDF是一种基于统计的方法,可以有效评估一个词对所属文档的重要程度。TF-IDF计算公式如下:

其中,n表示词i在文档j中的出现频次,|D|表示文档集中总文档数。
向量空间模型使用向量来表示文本,使模型具有了可计算性,可以有效评估不同词语对文档的重要程度,VSM简单直接但是由于维数过高而产生特征稀疏问题,并且VSM假设词与词之间独立,割裂了词语之间的上下文语义关系。
1.1.2 词向量模型
由于传统的文本表示方法具有维度高、性能差、并且不能发挥文本中同义词的作用等特点。Hinton首先提出了词向量的分布式表示,其基本思想是将每个词语映射到低维稠密且维度固定的向量表示中,也被称为词嵌入(Word Embedding)。经多年发展之后,产生了多种词向量模型。Bengio等提出了一种G-gram的神经概率模型,该模型使用Softmax作为输出层,模型复杂度会随着词汇表的增加而增大,无形中增加了训练的难度。随后,Morin和Bengio对该算法进行了改进,将输出层的Softmax与哈夫曼树相结合,该改变大大降低了训练的复杂度。
Mikolov等提出了将特征词转换为词向量的Word2vec语言模型,该模型包括两种词向量训练模型CBOW和Skip-gram,前者通过学习特征词上下文环境的独热编码,输出预测词的独热编码向量,后者与之相反。该模型根据上下文环境预测特征词的词向量,很好的保留了文本的语义相关性,也实现了特征项从高维到低维的映射。词向量训练模型CBOW和Skip-gram的结构图如图1所示。
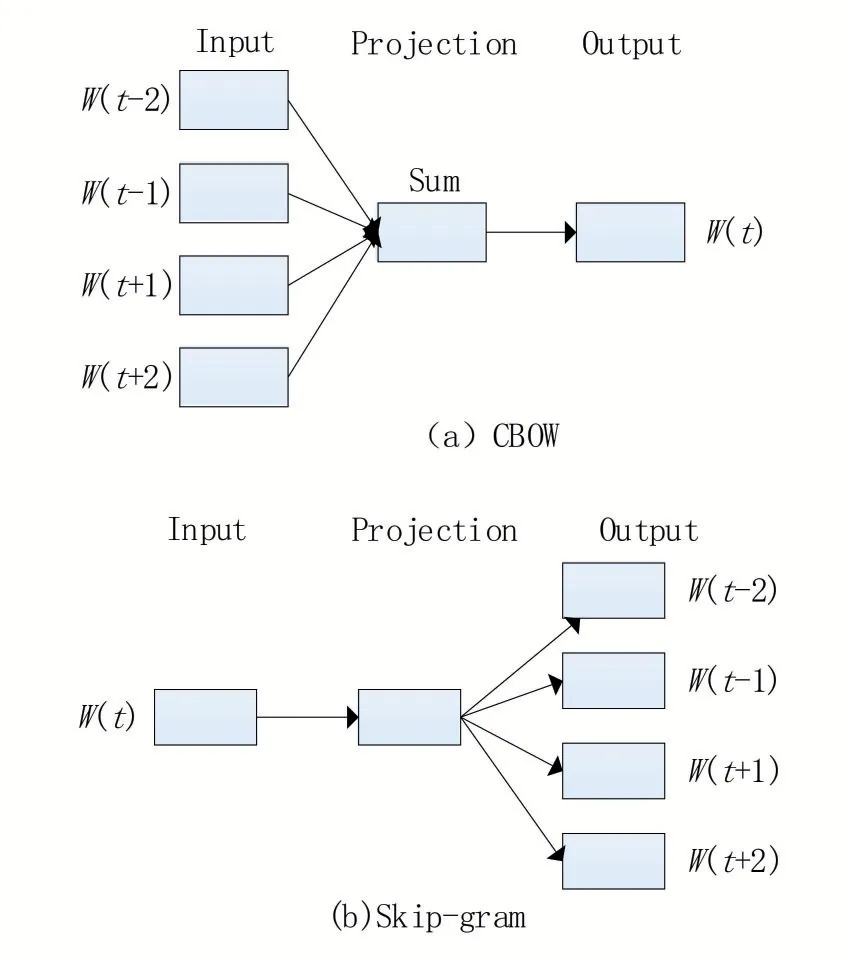
图1 CBOW和Skip-gram模型结构
随 着ELMo(Embeddings From Language Models)、GPT(Generative Pre-Training)、BERT等预训练模型的出现,不仅改变了自然语言处理任务中的模型结构,在自然语言处理领域中的诸多任务中也都取得了最优的结果。不同于Word2vec、Glove等词向量模型中一个词只对应一个词向量,上述预训练模型会根据上下文语料创建高度相关的词向量表示,解决了Word2vec、Glove等词向量模型无法解决的一词多义问题。
文献[15]提出了BERT预训练模型,该模型是一种基于Transformer模型的双层编码器表示,BERT模型根据上下文语料动态生成词语对应的词向量表示,解决了上述多义词问题。BERT不是只根据出现过的词来预测下一个词,而是将整个句子中的一部分词进行随机掩盖,使用双向Transformer来预测掩盖的词,BERT网络结构如图2所示。

图2 Bert网络结构
1.2 聚类算法
文本聚类就是将文档集中的文档根据一定的规则划分成不同的聚簇的过程,通过计算文本向量之间的相似度进行聚类,如果相似度高则说明为同一聚簇。常见的文本聚类方法大致分为基于层次的聚类和基于划分的聚类,层次聚类是将文本对象组织成一个聚类的树,然而层次聚类算法相比较而言时间复杂度高,不适合大量文本的聚类操作。基于划分的聚类恰恰相反,典型的有K-means算法,这是一种基于质心的聚类算法,其原理是首先选择k个文档作为初始的聚类点,然后通过计算文本相似度,将高于阈值的文档划分为一个簇,依次迭代计算。K-means聚类算法流程如下:
算法1 K-means聚类算法
输入:语料集D,聚类簇数K,误差平方差收敛条件
输出:聚簇划分C={C,C,C,…,C}
①从语料集中随机选择K个样本作为初始聚簇中心。
②采用欧式距离计算每个样本点与初始聚簇中心的相似度,按照最小距离原则将样本点划分到最临近聚簇中心。
③计算所有聚簇样本点的均值,并由此更新聚类中心。
④计算误差平方和,若满足收敛条件,则继续执行,若不满足,继续重复②③。
⑤输出聚簇划分C={C,C,C,…,C}。
2 基于迭代分类的古文短文本聚类算法
2.1 实验流程
本论文总体实验流程如图3所示。
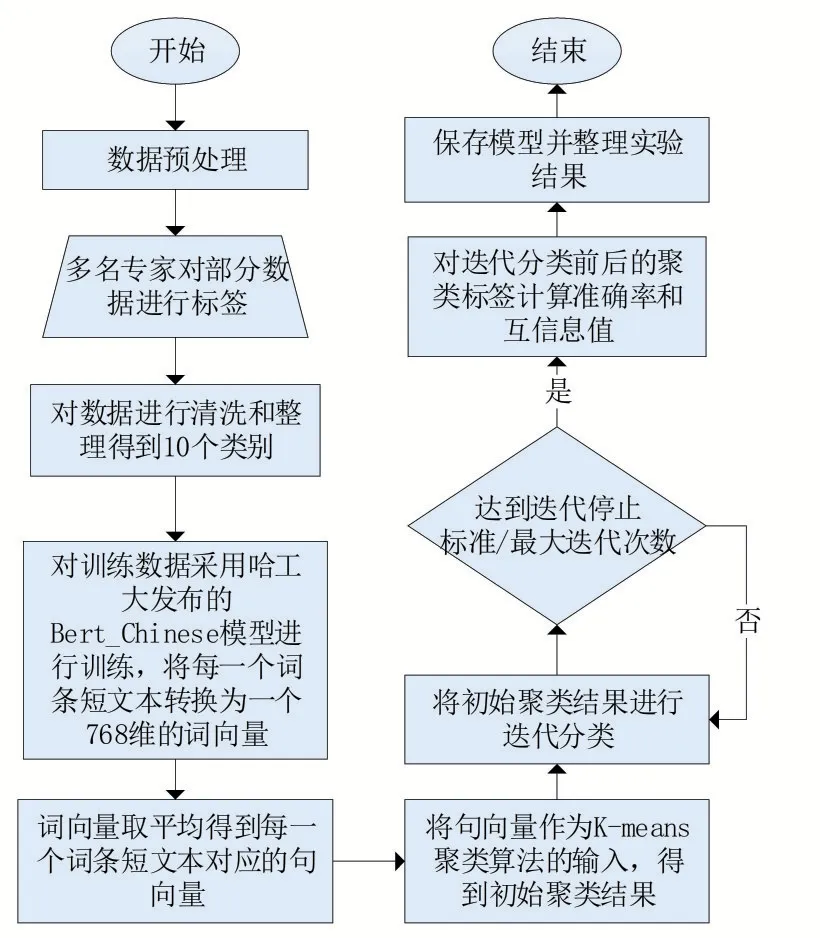
图3 实验流程
使用初始聚类结果进行迭代训练,对每一个聚簇结果采用孤立森林(Isolation Forest)作为离群值检测算法,记录每一个聚簇结果的离群值与非离群值。将非离群值作为训练集,离群值作为测试集。使用训练集训练分类器,然后利用该分类器对测试集进行分类,直到达到停止标准或者最大迭代次数。对迭代后的聚类结果计算准确率和互信息值,保存模型并整理实验结果,实验证明迭代分类增强了聚类结果。
2.2 数据预处理
分词是数据预处理的核心步骤,是指通过某些策略将没有分隔符的句子分成若干词语,这对于中文文本的处理尤为重要。目前中文分词技术主要包括三种:基于规则的分词技术(正向最大匹配法、逆向最大匹配法、双向最大匹配法等)、基于统计的分词(隐马尔可夫、条件随机场等)以及混合分词。Jieba分词作为一个开源的中文分词工具,采用基于规则和统计两种方法的混合分词技术。
首先基于词典的方式进行分词,得到一个包含所有分词结果的有向无环图,对于标注语料,采取动态规划的策略来获取最大概率路径。对于未登录词Jieba采用了隐马尔可夫模型,并通过Viterbi算法进行推导。Jieba分词包含三种切分模式:精确模式、全模式、搜索引擎模式。精确模式是指以最精确的方式将句子切分,适用于文本分析;全模式试图将所有可以组词的词语都切分出来,但没有解决歧义问题;搜索引擎模式则是基于精准模式的结果,对长词再进行下一步的切分,适用于搜索引擎问题。本文利用精确模式对文档集进行分词操作。分词示例如表2所示。

表2 分词结果
分词结束之后对分词结果进行去停用词操作,停用词是指文本中没有意义的语气词、助词等。本论文停用词表采用哈工大实验室的停用词词表,在该词表基础上,加入本文数据集中与古文相关的助词与语气词,进一步提高停用词的筛选效果。
2.3 BERT预训练
常见的主流预训练有两种feature-based和fine-tuning。feature-based将语言模型的中间结果即LM embedding作为额外的特征,引入到原任务的模型中。最典型的是ELMo,其首先对语料库进行训练,以language model为目标训练出bi-direction LSTM,再通过LSTM得到词语的向量表示。然而ELMo究其根本是两个单向语言模型的拼接,并没有实现真正的双向。fine-tuning是指在已经训练好的模型的基础上,加入特定任务的模型参数进行微调,进而更好的完成下游任务,OpenAIGPT采用了该方法,使用单向的transformer decoder进行训练。由于ELMo和GPT采用的都是单向的语言模型,无法充分的获取词语的上下文语义,2018年Google提出的BERT,才是真正采用了双向Transformer的预训练模型,能捕获基于字的序列信息、上下文语义信息等,解决了一词多义问题。BERT使用Transformer来代替Bi-LSTM,Transformer的并行能力远强于Bi-LSTM,并且可以采用多层注意力机制叠加的方式来提高表征能力。
BERT模型的主要创新点在于预训练方法上的改进,预训练阶段分为两个阶段,分别采用掩蔽语言模型(masked language model,MLM)和下一句预测(next sentence prediction,NSP)两种方法联合训练来获取词和句子层面的上下文语义表达,其中MLM真正采用了双向语言模型。
2.3.1 掩蔽语言模型(MLM)
MLM模型通过随机掩蔽一定比例的输入tokens,然后根据上下文预测得到这些被掩蔽的token,这个过程也可称为完形填空法。论文中mask每一句子中15%的token。由于在后续fine-tuning过程中,输入不会出现[mask],这就造成了预训练与fine-tuning不匹配的问题。为了减轻不匹配问题的影响,将这15%需要被mask的token分为以下三种情况:80%的概率用[mask]代替被掩蔽的token、10%的概率用一个随机词来代替、剩下10%采用原有单词不做改变。由于随机替换句子中token的概率只有1.5%(15%×10%),并不会对模型的语言表达能力造成太大影响。
2.3.2 下一句预测(NSP)
MLM是基于token级别的预训练,但是自然语言处理任务中的许多下游任务,比如问答、自然语言推理等,都需要句子关系层面的理解。然而这种句子层面的理解不能通过语言建模直接训练得到,于是BERT提出一种方法对获取下一个句子进行预训练。具体方法是:在语料库中选择50%正确句子对,有50%的概率A与B构成上下句,剩余50%情况不构成上下句。该训练过程类似于构建一个二分类模型,用来判断句子之间的关系。
2.4 迭代分类算法流程
迭代增强聚类算法流程如算法2所示:
算法2迭代增强聚类算法
输入:文档集D(n个文档),初始文档标签L,聚类簇数K
输出:增强后的聚簇划分C={C,C,C,…,C}
1.设定迭代次数max Iter=50
2.计算每一簇的平均文档数avgTexts=n K
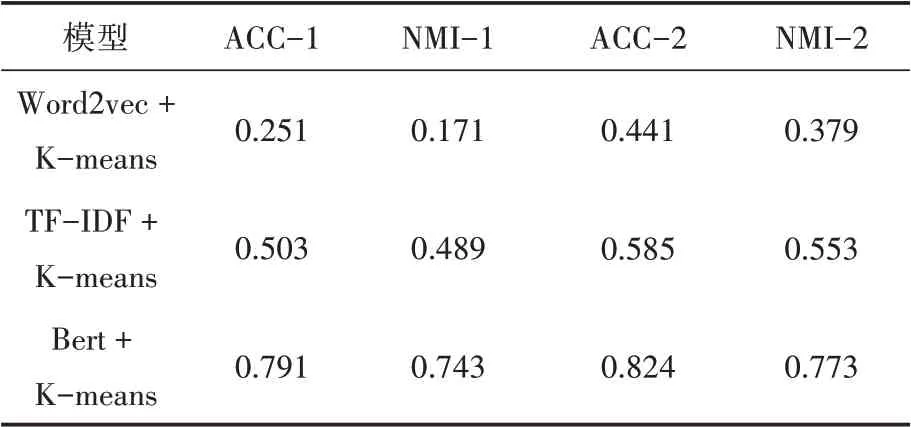
3.while i 4. 从区间[P,P]随机选择一个数P 5. 利用离群检测算法从D中根据标签P移除每一个簇的离群值 6. 若簇中的文档数n≥P×avgTexts: 7. 随机的移除簇中文档使得簇中文档数保持在P×avgTexts以内 8. 将步骤5、6、7中移除的文档作为testSet,剩余文档作为trainSet 9. 使用trainSet训练分类器对testSet中的文档进行分类,更新testSet中的L 10.end 本研究通过重复的将初始聚簇中的离群值重新分配来更新聚类的簇划分结果,并将这个重复过程称为迭代分类。在每次的迭代过程中,通过离群值算法将初始聚类划分为离群值和非离群值,将非离群值作为训练集,离群值作为测试集。从区间[P,P]中选取P值,将额外的文档从训练集移到测试集,即离群值和额外的文档共同组成了测试集。利用非离群值训练分类器,对测试集中的文档重新分配标签。重复这个过程,直到迭代结束。 本文数据来源于《四库全书》和《太平御览》,课题组专家从上述两本巨著中抽取出传统文化要素相关的词条短文本,总计12000条数据。为了对本文算法进行评估,对其中2000条数据进行了标签标注工作,共包含10个标签,分别为:朝代、年号、军事战役、历史事件、史料典籍、史学名家、考古、民俗文化、江湖志、野史笔记。 本论文采用准确率(ACC)和归一化互信息(NMI)来衡量算法的性能,互信息表明了两个随机变量互相依赖的程度,归一化互信息常用来评估聚类效果,通过预测标签集和真实标签集来计算两个聚类结果的相似程度,公式如下: 其中N表示正确聚类的文档数量,N表示总文档数,H(X)和H(Y)分别是X,Y的熵。归一化互信息取值在0~1之间,值越大聚类效果越好。 为了验证短文本特征提取方法的有效性,本论文分别使用TF-IDF、Word2vec、BERT预训练模型进行文本的特征提取,并将该三种方法提取的文本表示向量分别作为K-means聚类算法的输入,得到三组初始聚类结果。对这三组初始聚类结果使用上述迭代训练算法进行聚类结果的增强,实验结果如表3所示。相较TFIDF和Word2vec词向量表示,使用BERT预训练模型对聚类效果的提高更为显著。作用于本文古文短文本数据集中,使用Word2vec训练词向量,迭代训练之后ACC和NMI均提高了接近20%,TF-IDF和BERT预训练模型分别提高了8%和3%,实验进一步验证了迭代训练对中文短文本基类聚类结果均有提高作用。 表3 对比实验结果 针对传统短文本聚类算法文本表示特征稀疏、特征维度高、忽略文本语义信息等特点,本文提出了BERT+K-means+迭代训练的融合模型对古文短文本进行聚类研究。对比了其他两种词向量表示方法,实验结果证明,该模型具有最优的结果。因此证明了BERT预训练模型更好的提高了词向量的表征能力,以及迭代训练算法在古文短文本聚类算法中的有效性。
3 算法验证与结果分析
3.1 实验数据
3.2 评价指标


3.3 实验对比及分析
4 结语
猜你喜欢
客联(2022年3期)2022-05-31
汽车实用技术(2022年4期)2022-03-07
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
校园英语·月末(2021年13期)2021-03-15
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电脑爱好者(2017年7期)2017-05-06
电子技术与软件工程(2016年23期)2017-03-06
