
文本无关说话人识别中句级特征提取方法研究综述
2022-04-14 02:18陈晨韩纪庆陈德运何勇军
自动化学报 2022年3期
陈晨 韩纪庆 陈德运 何勇军
说话人识别 (Speaker recognition)又称为话者识别或声纹识别,其能通过对说话人语音信号的分析处理,来自动识别出说话人的身份[1].相比于其他身份认证技术,说话人识别具有不需要与个体直接接触、识别使用的设备成本较低,以及便于与现有的通信系统相结合等优势[2].而这些语音本身所具有的众多优点,则使得说话人识别技术倍受企业与研究者们的关注并得以快速发展[3].
根据识别对象的差异,可以将说话人识别分为两类,即文本相关 (Text-dependent)型与文本无关(Text-independent)型[4].前者要求说话人提供特定发音的关键词或关键句作为训练数据,识别时也必须按照相同的内容发音;而后者则不需要强制规定语音内容.二者相较而言,与文本无关的说话人识别研究对语音内容的要求更自由,因此其拥有更广泛的应用领域[5].
与文本无关的说话人识别研究虽然已经取得了巨大的进展,但其面对的主要困难与挑战却依然存在,即语音信号中存在大量的变化信息 (Variable)[6].具体而言,由于每段语音的表述内容不同,因此必须在自由的语音信号中寻找能够表征说话人身份的个性信息;同时,受到不同录音装置与传输方式的影响,语音信号中也会引入更多的变化信息.因此,提取出能够有效包含说话人个性信息的特征具有很大的挑战性.然而,上述问题的解决将有效推动说话人识别的研究进展.
由于语音信号具有短时平稳的特性,因此在进行前端特征提取时,通常可以采用短时的帧级(Frame-level)特征来刻画语音信号.然而,语音信号具有时变性与上下文相关性,这些与时间相关的动态特性中往往蕴含着丰富的说话人个性信息,从而使得此信息具有长时统计特性[7],而只对帧级特征序列进行简单的取均值操作无法有效获取语音段的统计特性[8-9].因此,如何合理利用一段语音的帧级特征序列,从中提取出包含说话人个性信息的句级 (Utterance-level)特征则显得尤为重要.同时,句级特征提取能够对不同时长的语音信号进行整合,从而使不定长语音信号能用固定维度的特征表示.因此,其可与大多数常用的模式识别算法相结合,具有更强的可操作性.目前的方法在进行句级特征提取时,一般会具有阶段性目标或只具有一个统一目标,本文将根据此分类依据对句级特征提取方法进行分类.其中,第1 类方法由于具有多个阶段,且各阶段均具有独立的优化目标 (任务),本文称其为基于任务分段式学习策略的特征提取方法;而第2 类方法由于只具有统一的优化目标,因此本文称其为基于任务驱动式学习策略的特征提取方法.
基于上述分析,本文总结并介绍与文本无关说话人识别中具有代表性的句级特征提取方法,试图为进一步深入研究特征提取方法奠定理论基础.第1 节简要概述进行句级特征提取之前的前端处理过程;第2 节和第3 节分别介绍基于任务分段式与驱动式策略的句级特征提取方法;第4 节对后端处理的相关内容进行介绍;第5 节对未来研究趋势进行分析;第6 节对全文进行总结.
1 前端处理
在介绍句级特征提取方法之前,这里先简要介绍语音信号的前端处理过程,包括语音活动检测 (Voice activity detection,VAD)、帧级特征提取以及特征规整 (Feature normalization)三部分.
1.1 语音活动检测
语音活动检测能够区分出语音信号中的语音部分与非语音部分,从而为后续的特征提取部分提供有效的语音段.语音活动检测的功能示意图如图1(a)所示,其所对应的语谱图如图1(b)所示,从图中可以看出,语音部分与非语音部分所对应的语谱图具有明显差异,如直接对未进行语音活动检测的语音信号进行特征提取,将引入大量的无效内容.因此,进行语音活动检测对于有效特征的提取具有十分重要的作用.过去常采用基于能量与过零率的双门限方法,其虽然简单易行,能够快速确定出语音部分的起始点与结束点,但在寻找结束帧时并不稳定.目前的方法大多采用窗能量或带上下文的帧能量检测方法.

图1 语音活动检测的功能示意图Fig.1 Schematic diagram of voice activity detection
当语音信号的信噪比较低时,噪声会增加语音部分检出的难度,纯噪声部分更会引入大量的无效内容,此时检测出有效语音片段则显得更为重要.针对以上问题,目前的语音活动检测方法可以划分为两类.一类主要利用特征的频谱-时间特性(Spectro-temporal property)来检测含噪语音信号中的语音片段,这类特征主要包括能量特征[10]、周期性特征[11]、高阶统计特征[12]及融合特征[13]等.另一类则主要通过学习统计模型来进行语音活动检测,例如:决策指导参数估计方法[14]、统计似然比检验方法[15]、平滑似然比检测方法[16]等.近年来随着神经网络方法的发展,一系列以其为基础的方法相继出现,文献[17]对这类方法进行了系统对比.
1.2 帧级特征提取
进行语音活动检测后,即可对语音片段进行帧级特征提取.帧级特征所对应的语音帧时长一般在20~40 ms 之间,常用的特征有梅尔频率倒谱系数(Mel-frequency cepstral coefficients,MFCC)[18]、线性预测倒谱系数 (Linear predictive cepstral coefficients,LPCC)[19]、感知线性预测系数 (Perceptual linear predictive coefficients,PLPC)[20]等.本节将以最为常用的MFCC 特征为例,介绍其提取过程.
图2 为25 ms 语音帧所对应的MFCC 特征提取过程的示意图,其中图2(a)为语音帧的原始波形.在进行MFCC 特征提取前,首先需要对语音信号进行分帧、预加重、加窗等预处理.当采样频率已知时,可以将N个采样点当作一个观测单位,帧移一般取N的1/3~1/2,图中取10 ms,图2 中语音信号的采样频率为8 000 Hz,因此一帧语音 (25 ms)对应的采样点数为200.预加重的目的则在于消除口唇辐射的影响,对语音信号中受到发音系统压制的高频部分进行补偿,预加重系数一般设置为0.9~1.而加窗操作则可以使信号两端趋于平滑,从而防止信号发生畸变,常用的窗函数有汉明窗、汉宁窗或矩形窗等.图2(b)为经过预加重与加汉明窗操作后的语音波形,可以明显观察到语音信号的两端变得更加平滑.然后,对加窗后的各帧信号进行快速傅里叶变换 (Fast Fourier transform,FFT)即可得到各帧的频谱,对频谱取模便可得到功率谱,其取对数后的结果如图2(c)所示.由于声音在内耳的基底膜上以纵波的形式进行传播,而三角滤波器组可以有效模拟基底膜对声音的频响特性,因此可以采用三角滤波器组对语音信号进行滤波.同时,三角滤波器组在实际物理频率上呈不均匀分布、在梅尔频率上服从均匀分布,因此可以将物理频率转换到梅尔频率上进行计算.基于此,三角滤波器组也可以称作梅尔频率滤波器组.图2(d)为具有24 个通道的梅尔频率滤波器组,图2(e)为在其上进行滤波并取对数的输出结果.滤波器组的设计使其对图2(c)中对数功率谱下端的频率变化更加敏感,对数运算则能够进一步扩展系数的取值范围.最后,对滤波器组对数能量进行离散余弦变换 (Discrete cosine transform,DCT)并保留前F个系数作为MFCC特征,F一般取13~21,图2(f)中展示了保留20 个系数的MFCC 特征.值得注意的是,标准的MFCC参数只反映了语音的静态特性,语音的动态特性可以用这些静态特征的差分谱来描述:通过计算静态MFCC 特征的一阶差分 (Delta)与二阶差分 (Deltadelta),并与静态MFCC 特征拼接即可组成具有动态特性的声学特征.

图2 MFCC 特征提取过程示意图Fig.2 Schematic diagram of MFCC extraction
在MFCC 特征的提取过程中,也可以获得一些其他特征,例如:语谱图特征[21]、对数滤波器组(Filter banks,FBank)特征[18]等.其中,语谱图特征是由对数功率谱按帧拼接而成的特征.其所对应的语音段时长更长,因此其中包含的信息更多;随着卷积神经网络 (Convolutional neural network,CNN)[22-23]在说话人识别领域的应用,作为二维特征的语谱图特征也逐渐成为能够利用的说话人特征.对数FBank 特征则为滤波器组输出的对数能量,与MFCC 特征相比,对数FBank 特征并未进行离散余弦变换,其中包含的信息更多,也可以作为说话人特征进行使用;随着深度神经网络的发展,对数FBank 特征的应用也正在逐渐增多.
1.3 特征规整
受语音信号的时变性影响,无法保证帧级特征在不同语音信号上的一致性.因此,需要采用特征规整技术以最小化上述问题所产生的影响.在众多特征规整技术中,最常用的方法为倒谱均值规整(Cepstral mean normalization,CMN)[24]与特征弯折 (Feature warping)[25],它们均能够在一定程度上消减帧级特征序列中的不一致性信息.其中,CMN方法具有很多扩展形式,例如:倒谱均值与方差规整 (Cepstral mean and variance normalization,CMVN)[26]、加窗倒谱均值与方差规整 (Windowed cepstral mean and variance normalization,WCMVN)[26]等.图3 展示了原始声学特征与分别经过CMVN、WCMVN 以及特征弯折方法进行特征规整后所得到特征的直方图,从图中可以看出:经CMVN 方法规整后,声学特征整体分布的形状没有发生改变,改变的只有特征参数的动态数值范围;经WCMVN 方法规整后,声学特征的整体分布则近似映射到高斯分布上;经特征弯折方法规整后,声学特征也被近似映射到高斯分布上,但弯折后的特征在数值上更加集中.
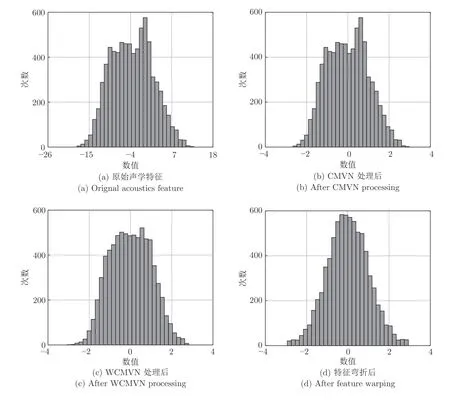
图3 帧级特征序列经特征规整后的直方图对比Fig.3 Histogram comparison of frame-level feature sequences after feature normalization
2 任务分段式策略
前端处理能够去除语音信号中的部分无效内容,并提取出具有一定区分性的帧级特征,但帧级特征所携带的信息量有限,且需要考虑不同时长语音如何转化为统一维度特征的问题,因此需要对帧级特征序列进行进一步的特征提取,以获取信息量更全面且维度统一的句级特征.其中,构建均值超矢量(Mean supervector)[27]是句级特征提取方法中最基础的方法之一,因此本节将以均值超矢量的构建为起点,并以任务分段式策略为线索,根据不同阶段的任务,展开介绍从均值超矢量发展而来的一系列方法.
2.1 均值超矢量的提取
在说话人识别研究中,如何表示具有不定时长的语音信号一直是主要研究问题之一.在早期的研究中,主要通过对帧级特征取均值的方式来获取不同时长语音信号的固定维度特征表示[8].该方法虽然计算速度很快,但识别性能较差.自1980 年以来,研究的主要趋势则转为通过构建从数据到模型的训练方式,来对帧级特征进行整合.例如:高斯混合模型 (Gaussian mixture model,GMM)[28]、高斯混合模型-通用背景模型 (Gaussian mixture model—universal background model,GMM-UBM)[29]、高斯混合模型-支持向量机 (Gaussian mixture model—support vector machine,GMM-SVM)[27]、基于字典学习的方法[30-33]等.以上方法大多通过统计学习的方式来获取说话人特征的统计特性,且为首个句级特征 ——GMM 均值超矢量的出现奠定了理论基础.
GMM 均值超矢量是通过合并GMM 各高斯分量中的均值矢量而获得的超高维特征矢量,其具有维度固定、携带信息量充足、易与众多模式识别算法结合等优点.GMM 均值超矢量的提取方法一经提出,迅速吸引了研究者们的注意,均值超矢量也成为了不可替代的句级特征.本文以具有2 个高斯分量的GMM-UBM 系统为例,在图4 中展示GMM均值超矢量的提取过程.首先,如图4(a)所示,利用大量背景说话人语音数据 (也称为开发集数据)来训练UBM.本质上,UBM 是一个能够近似描述全部说话人语音共性的大型GMM,它由若干个高斯概率密度函数的加权和构成,具有以下形式:

图4 GMM 均值超矢量提取过程示意图Fig.4 Schematic diagram of GMM mean supervector extraction
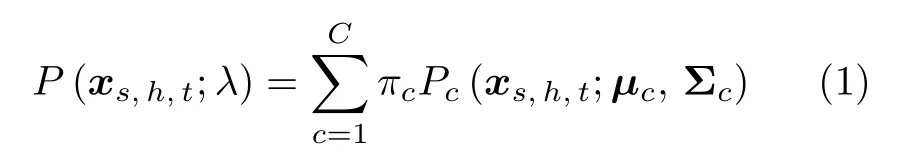
其中,xs,h,t∈RF表示开发集数据中第s位说话人的第h段语音中的第t帧声学特征,一般可以采用MFCC 特征,F为声学特征的维度;λ={πc,µc,Σc}(c=1,2,···,C)为UBM 的参数集,3 个参数分别为权重、均值矢量与协方差矩阵,C为高斯分量总数;Pc(xs,h,t;µc,Σc)表示高斯函数.通过利用开发集数据,经过期望最大化(Expectation maximization,EM)算法[34]的反复迭代,便可得到UBM的参数集λ.
然后,如图4(b)所示,将UBM 作为初始化模型,通过利用最大后验概率 (Maximum a posteriori,MAP)估计[35],对每段语音进行自适应以求出其对应的GMM.具体而言,对于说话人s第h段语音的全部特征序列Xs,h={xs,h,t;t=1,2,···,Ts,h},每帧特征xs,h,t由UBM 中第c个高斯分量产生的概率为


然后利用上述统计参数即可得到说话人s第h段语音所对应GMM 参数的更新公式,即

其中,β为缩放因子,用于确保全部的和为1;αc则具有以下形式:

其中,r为相关因子,用于调控GMM 参数受Xs,h的影响程度.在实际应用中,更新均值矢量对整体性能的提升具有更大的价值,因此UBM 的权值与协方差矩阵往往可以在全部说话人之间共享,从而使得不同语音段所对应的GMM 之间的差异仅体现在均值矢量上.基于此,可以将GMM 中的全部均值矢量拼接为GMM 均值超矢量,并以此作为GMM 的唯一表示.
这种将说话人模型与背景模型相结合的形式,提供了比独立训练GMM 更好的性能,并为后续方法的提出奠定了理论基础.然而,GMM 均值超矢量中仍然包含很多与说话人个性信息无关的信息,需要考虑对这些冗余信息进行补偿.同时,均值超矢量的超高维度也会产生计算量庞大的问题.例如,对于维度为60 维的声学特征与具有1 024 个高斯分量的GMM,其均值超矢量的维度将达到61 440维 (CF=60×1 024).因此,需要考虑如何获取维度适中且能够继承GMM 均值超矢量大多数优点的特征矢量.基于以上分析,下文将介绍能够对GMM均值超矢量进行有效补偿与降维的一系列方法.
2.2 特征空间学习
由于GMM 均值超矢量中包含与说话人相关和与说话人无关的信息,因此可以对GMM 均值超矢量的成分进行分解,假设其可以表示为4 个分量线性组合的形式

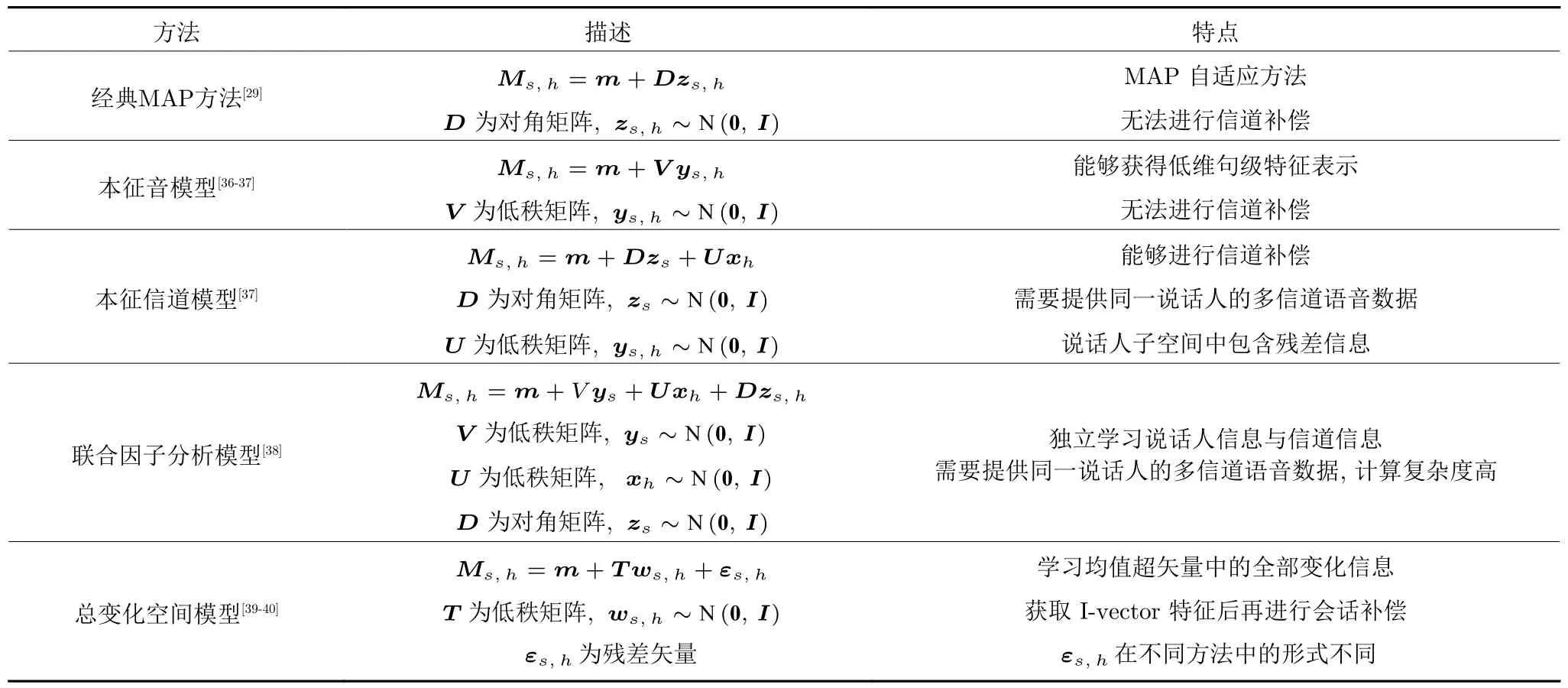
表1 不同特征空间学习方法汇总信息Table 1 Information of different feature space learning methods
2.2.1 经典MAP 方法
由于GMM-UBM 系统中的MAP 自适应技术[29]与式 (6)具有一定的关联性,因此本节将首先对其进行讨论.根据式 (4)可以发现,的更新公式由两个分量组成,分别为与说话人相关的项及与说话人无关的 (1-αc)µc项.可以用更通用的形式将其表示为

其中,D∈RCF×CF为对角矩阵,用于描述不同语音段变化信息;zs,h∈RCF为说话人因子,是服从标准正态分布的随机隐变量.结合式 (6)可知,Dzs,h对应于ms+mh+mr项.由此可见,与第2.1 节的讨论一致,经典MAP 方法的Ms,h中含有与说话人信息无关的冗余信息.
2.2.2 本征音模型
本征音 (Eigenvoice)模型[37]最初是语音识别中的说话人自适应方法[36].本质上其属于MAP 的扩展方法,与经典MAP 方法中采用对角矩阵的方式不同,其将参数限制在由本征音矩阵的列所定义的较低维子空间中,因此能够获得更低维的特征表示.其具有以下形式:

其中,V∈RCF×R(R ≪CF)为低秩本征音矩阵,它的列能够张成说话人子空间;ys,h∈RR为具有标准正态分布的说话人因子;Vys,h与ys,h均可以作为句级特征进行使用.
值得注意的是,此方法中不存在噪声残差假设,因此其在本质上与主成分分析 (Principal component analysis,PCA)[41]等效,模型中GMM 均值超矢量的协方差矩阵为VVT.然而,均值超矢量具有较高的维度,难以在有限的数据量下估计出满秩的协方差矩阵.因此,无法直接通过最大似然估计(Maximum likelihood estimation)得到参数,需要采用EM 算法来进行参数估计.同时,从式 (8)中也可以看出,GMM 均值超矢量Ms,h经由UBM均值超矢量m加上一定的位移Vys,h而获得.因此,在进行GMM 自适应时,GMM 会受到潜在本征音矩阵V的限制.此外,此方法的缺点也显而易见,与经典MAP 方法类似,其无法进行信道补偿.
2.2.3 本征信道模型
从同一说话人不同语音数据中所提取的GMM均值超矢量无法保证完全相同,尤其当这些数据来自不同的录音设备时,信道变化信息必然会增加均值超矢量之间的差异.因此,必须进行信道补偿以确保能够对来自不同信道的语音数据进行正确评分.类似于本征音模型,本征信道模型[37]假设信道信息存在于信道子空间中,其通过对信道信息进行建模,将注册集语音自适应到测试集语音所在的信道上.当本征信道模型与经典MAP 方法结合时,其具有以下形式:

其中,D∈RCF×CF为对角矩阵;zs∈RCF为说话人因子;U∈RCF×K(K ≪CF)为低秩本征信道矩阵,它的列能够张成信道子空间;xh∈RK~N(0,I)为信道因子.由于需要对信道信息进行建模,因此训练数据中需要包含同一说话人不同信道下的语音数据,可见该方法在数据获取上具有一定的难度.同时,结合式 (6)可知,Dzs对应于ms+mr项.由此可见,Dzs中仍然包含一定的残差信息,该信息会对模型的有效性产生影响.
2.2.4 联合因子分析模型
联合因子分析 (Joint factor analysis,JFA)模型[38]是本征音模型与本征信道模型的结合方法,该方法假设说话人信息与信道信息均能够在GMM均值超矢量所在空间的低维子空间中得到表示,且这些低维子空间分别是由本征音矩阵V与本征信道矩阵U的列所张成的空间.基于此,GMM 均值超矢量便能够表示为说话人信息、信道信息与残差信息的线性组合形式.对于说话人s第h段语音所对应的GMM 均值超矢量Ms,h,其具有以下形式:

其中,V∈RCF×R为低秩本征音矩阵,ys∈RR为说话人因子,U∈RCF×K为低秩本征信道矩阵,xh∈RK为信道因子,D∈RCF×CF为对角的残差负荷矩阵,zs,h∈RCF为残差因子.
在式 (10)中,V,U与D均为JFA 模型的超参数,目前存在两种超参数的估计方法,分别为联合估计方法与独立估计方法.利用它们估计出的结果相差不大,但后者的计算复杂度更小.在参数学习过程中,独立估计方法需要先估计V,再估计U与D,然后即可估计出因子ys,xh与zs,h,最后通过保留说话人相关部分Vys,并丢弃信道相关部分Uxh与残差相关部分Dzs,h,来达到信道补偿的目的.由于JFA 模型需要学习信道信息,因此也需要提供每位说话人在不同信道下的语音数据.与上述4 种方法相比,只有JFA 模型同时考虑了式 (6)中的全部4 个分量,这也使得JFA 模型能够获得比上述方法更优的性能.然而,由于JFA 模型需要对不同成分进行建模,因此其计算复杂度较高.
2.2.5 总变化空间模型
联合因子分析模型虽然是一种有效的句级特征提取方法,但其模型假设中仍然存在一些问题:说话人信息与信道信息并非完全相互独立,因此独立地学习说话人本征音空间与本征信道空间会造成说话人信息损失.此外,信道种类多、难以预测,无法通过穷举的方法来学习全部的信道信息,且信道标签信息的采集也具有一定的难度.针对以上问题,可以通过学习一个包含均值超矢量中主要信息的总变化空间 (Total variability space,TVS)[39-40],来代替独立学习的本征音空间与本征信道空间.该方法称为身份-向量 (Identity-vector,I-vector)方法[40],它通过学习高维GMM 均值超矢量与低维特征之间的映射关系,来获取前者的低维特征表示 ——I-vector 特征.而对于I-vector 特征中包括信道信息在内的与说话人身份无关的会话变化(冗余)信息,则可以采用会话补偿的方式对其进行削减.
与JFA 方法不同,I-vector 方法不需要区分说话人与信道.它直接通过学习总变化空间来对GMM均值超矢量进行降维,且提取的I-vector 特征能够继承GMM 均值超矢量的大多数优点.同时,由于I-vector 特征的维度较低,使得一些在高维数据上不适用的传统补偿策略得以适用,具有更高的可操作性.拥有以上优点的I-vector 方法更是由于其优良的识别性能,而受到了广泛关注,并成为说话人识别领域中的主流方法之一,总变化空间学习更是作为I-vector 方法中的关键研究内容之一而备受关注.根据类别信息的利用情况,目前的总变化空间学习方法可以分为两类:无监督方法与有监督方法,下面将从这两方面展开介绍.
2.2.5.1 无监督方法
在无监督的总变化空间学习方面,根据总变化空间模型中假设侧重点的不同,其可以划分为两类:一类将侧重点放在从GMM 均值超矢量映射到I-vector 特征后所剩的残差上,通过对残差引入不同的先验假设,来进行总变化空间的学习;另一类则对从GMM 均值超矢量到I-vector 特征的映射关系进行改进.
1)残差假设
首先介绍基于不同残差假设的无监督I-vector 特征提取方法,最早出现的方法为前端因子分析 (Front-end factor analysis,FEFA)方法[40].在此之后,一系列通过直接或间接对GMM 均值超矢量进行降维处理来学习总变化空间的方法相继出现.它们大多均属于前端因子分析方法的变形方法,例如:基于EM 算法的PCA 方法[42]、概率主成分分析 (Probabilistic principal component analysis,PPCA)[43-44]以及因子分析 (Factor analysis,FA)[44-45]等.这类方法认为:GMM 均值超矢量之间的差异不仅来自于其对应的隐变量I-vector 特征,还来自于进行映射之后所剩的残差.此类方法通过对残差中所剩成分的分析,来帮助总变化空间的学习.
a)前端因子分析 (FEFA).作为I-vector 方法的基础,其没有直接对GMM 均值超矢量进行处理,而是通过建立Baum-Welch 统计量与隐变量I-vector 特征之间的映射关系来学习总变化空间.由于无法显式地展示Baum-Welch 统计量与I-vector 特征之间的关系,且Baum-Welch 统计量与GMM 均值超矢量具有等效性[44],因此这里仍然以GMM 均值超矢量的形式给出FEFA 方法的表达式

其中,T=(T1T,···,TcT,···,TCT)T∈RCF×R(R ≪CF)为低秩的总变化矩阵 (Total variability matrix),Tc∈RF×R为总变化矩阵的子块,ws,h∈RR~N(0,I)为待求的I-vector 特征,Baum-Welch 统计量的计算过程可以参见式 (3).由式 (11)可以看出,FEFA 方法的模型假设中不包含残差项,因此该模型的I-vector 特征中包含了全部变化信息.与前文所述的特征空间学习方法类似,FEFA方法也需要利用EM 算法来进行参数与隐变量估计,在E 步需要估计出ws,h在条件下的后验协方差矩阵L、后验均值E以及后验相关矩阵Υ

其中,µc与Σc分别为UBM第c个高斯分量的均值矢量与协方差矩阵.
在M 步,首先需要计算Baum-Welch 统计量与I-vector 的联合似然函数,然后求取其对参数T的偏导数并令其为0,便可得到参数T的更新公式

经E 步与M 步的反复迭代后,模型最终会趋于收敛.然后,将T代入式 (12)中,即可得到I-vector特征的后验均值E,将其用作待求的I-vector 特征即可.基于EM 算法的PCA 方法[42]与FEFA 方法类似,也不具有残差假设.
b)概率主成分分析 (PPCA).与FEFA 方法不同,PPCA 方法[43-44]具有残差假设,其可以表示为以下形式:

其中,εs,h∈RCF~N(0,σ2I)为残差矢量,且它的协方差矩阵各向同性 (Isotropic),因此εs,h各维之间的离散程度相同.也正是由于εs,h的协方差矩阵各向同性,因此在进行最大似然估计时各参数具有闭式解[43,46].但采用EM 算法进行求解时的模型计算复杂度更低,且经过若干次迭代后参数一定会收敛于全局最优解,因此大多数情况下仍然采用EM算法进行PPCA 方法的参数估计.
c)因子分析 (FA).因子分析方法[44-45]具有与式 (14)相同的表达式,但它对残差协方差矩阵的定义更加自由:其定义εs,h~N(0,Φ),其中 Φ 为各向异性的对角协方差矩阵.其参数估计方法与PPCA 类似,也需要利用EM 算法来完成参数更新.
以上即为3 种基于不同残差假设的总变化空间学习方法,它们在性能方面的差异不大[44],但计算复杂度具有一定差异.考虑到在说话人识别领域中,模型训练过程一般采取离线模式,可以训练好模型后再利用其进行相应的特征提取操作,因此训练阶段一般对效率的要求不高,特征提取过程的时间复杂度则受到更多的关注.基于此,本节将总结与上述3 种方法相应的特征提取过程的时间复杂度,并给出其他汇总信息,如表2 所示.其中,tr(·)表示迹运算,⊙表示哈达玛 (Hadamard)乘积.

表2 基于不同残差假设的无监督总变化空间模型Table 2 Unsupervised TVS model based on different residual assumptions
2)映射关系假设
这类总变化空间学习方法大多针对总变化空间学习过程中GMM 均值超矢量 (或Baum-Welch 统计量)与I-vector 特征的映射关系来进行方法改进,并根据其存在的具体问题给出解决方法.这类方法一般从以下三个角度出发:对映射关系的改进、对不理想数据库的改善,以及对学习速度的提升
a)对于映射关系改进问题,局部变化模型 (Local variability modeling)[47]通过利用GMM 均值超矢量中各高斯分量与I-vector 特征之间的局部可变性,来学习高斯分量与I-vector 特征间的映射关系;基于稀疏编码 (Sparse coding,SC)的方法[48]则利用字典学习来压缩总变化矩阵,从而减少数据所占用的存储空间;广义变化模型 (Generalized variability model)[49]则针对GMM 均值超矢量与I-vector 特征映射关系中高斯分布假设较简单的问题,通过将该分布扩展到高斯混合分布,来更鲁棒地拟合二者之间的映射关系.
b)对于不理想数据库改善问题,针对不同数据库中存在源变化信息 (Source variable),从而导致开发集数据与评估集数据映射关系不一致的问题,基于最小散度标准 (Minimum divergence criterion)的先验补偿方法[50]通过对不同数据库中的先验信息进行建模,来学习能够对其进行补偿的映射关系;针对语音数据中存在噪声与混响的问题,基于不确定性传播 (Uncertainty propagation)的方法[51]则对Baum-Welch 统计量与I-vector 特征的映射关系中不确定性因素所产生的影响进行建模,从而降低环境失真对I-vector 特征表示的影响.
c)对于学习速度提升问题,广义 I-vector 估计(Generalizing I-vector estimation)方法[52]利用子空间正交先验 (Subspace orthogonalizing prior)来替换经典I-vector 方法中的标准高斯先验,从而通过正交属性来提高计算速度;而基于随机奇异值分解 (Randomized singular value decomposition)的方法[53]则通过近似估计的方式来提升计算速度.上述方法的汇总信息如表3 所示.

表3 基于不同映射关系假设的无监督总变化空间模型Table 3 Unsupervised TVS model based on different mapping relations
2.2.5.2 有监督方法
无监督方法虽然能够获取有效的I-vector 特征,但在学习过程中未利用类别信息.这里将介绍基于有监督学习策略的总变化空间学习方法,它们均能够有效利用类别信息来指导总变化空间学习,主要包括偏最小二乘 (Partial least squares,PLS)方法[54]、概率偏最小二乘 (Probabilistic partial least squares,PPLS)方法[55]、有监督主成分分析(Supervised probabilistic principal component analysis,SPPCA)[56]、基于最小最大策略 (Minimax strategy)的方法[57-58]等,下面将展开介绍上述4 种方法.
a)偏最小二乘 (PLS).PLS 方法能有效利用类别信息进行总变化空间学习,它主要通过构建GMM 均值超矢量与类别标签的公共子空间来获取它们之间的关联信息,并以此来增加模型对不同数据的区分能力,而此公共子空间正是总变化空间.定义开发集数据中的全部GMM 均值超矢量可以表示为数据矩阵M=(M1,···,Mn,···,MN)T∈RN×CF,其中Mn为第n段语音所对应的GMM 均值超矢量,n=1,2,···,N,N为开发集数据的样本总数.同时,PLS 方法对类别标签采用one-hot编码的形式,即yn=(0,···,0,1,0,···,0)T∈RK,其中,K为开发集数据的总类别数.定义开发集中全部数据的类别标签可以表示为矩阵Y=(y1,···,yn,···,yN)T∈RN×K.基于以上符号定义,经过标准化后的GMM 均值超矢量矩阵M(1)与类别标签矩阵Y(1)的关系可以表示为以下形式:

其中,R(R ≤K)为模型求解时的迭代次数,也是总变化空间的维度;在每次迭代过程中,均可求得一组wr,tr,ur与qr;T=(t1,···,tr,···,tR)∈RCF×R为总变化矩阵;W=(w1,···,wr,···,wR)∈RN×R为I-vector 特征组成的矩阵,每行对应一个I-vector 特征,在每次迭代中,均可以求得一个得分矢量wr,对应于当前数据矩阵M(r)在总变化空间当前所求基上的投影;Q=(q1,···,qr,···,qR)∈RK×R为负荷矩阵;U=(u1,···,ur,···,uR)∈RN×R为得分矩阵,与W类似,每次迭代均可以求得一个得分矢量ur;E,F为残差矩阵.
在上述总变化空间学习过程中,需要保证GMM均值超矢量与类别标签在公共子空间中投影包含的有效信息最多,从而减少投影过程中的信息损失;同时,还需要保证它们投影的相关性最大,从而建立起均值超矢量与标签之间的强联系.以上需求可以表示为以下优化问题:

式(16)为第r次迭代时的目标函数,对其进行求解即可得到当前迭代下的tr与qr.然后,需要对数据矩阵M(r)与类别信息矩阵Y(r)进行缩减,并从缩减后的M(r+1)与Y(r+1)中继续寻找下一组满足目标函数Jr+1的参数tr+1与qr+1.当进行R次迭代后,即可得到总变化矩阵T,而GMM 均值超矢量在总变化空间上的投影即为I-vector 特征,可由未缩减的数据特征矩阵M(1)进行表示.
b)概率偏最小二乘 (PPLS).概率偏最小二乘方法[55]是偏最小二乘 (PLS)方法的概率扩展形式,它的模型规模、计算复杂度、识别性能均优于PLS方法.PPLS 方法假设GMM 均值超矢量Ms,h与类别标签Ys,h均由公共隐变量ws,h经过一定的线性变换而获得,此过程通过Ys,h来指导Ms,h的产生过程,从而增强Ms,h与Ys,h之间的联系.通过公共隐变量ws,h的联系,Ms,h与Ys,h的关系可以表示为

其中,m∈RCF为GMM 均值超矢量产生过程中的偏置;µY∈RK为类别标签产生过程中的偏置;T∈RCF×R为总变化矩阵,亦为由ws,h向Ms,h转换的变换矩阵,T的列张成了数据空间的一个线性子空间,对应于总变化空间;Q∈RK×R为负荷矩阵;ws,h∈RR~N(0,I)为公共隐变量,亦为待求的I-vector 特征;εs,h∈RCF~N(0,ΦM|w)与ζs,h∈RK~N(0,ΦY|w)为残差矢量,ΦM|w与ΦY|w为误差扰动εs,h与ζs,h的协方差矩阵;且εs,h,ζs,h与ws,h两两之间相互独立.在进行参数求解时,式 (17)可以整合为一个等式
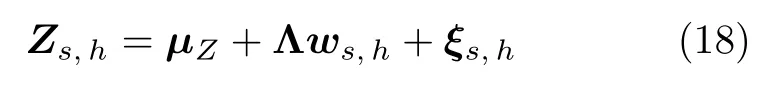
c)有监督主成分分析 (SPPCA).有监督主成分分析方法[56]与概率偏最小二乘 (PPLS)方法类似,但它们对类别标签的处理方式不同.SPPCA 方法并未直接采用GMM 均值超矢量作为输入,而是采用与前端因子分析 (FEFA)类似的方法,将Baum-Welch 统计量作为输入来学习总变化空间.SPPCA 方法具有以下形式:

其中,Ss为长时GMM 均值超矢量,是同一说话人s的全部语音所对应的GMM 均值超矢量.与PPLS方法相比,SPPCA 方法并未显式地使用类别标签,而是隐式地将同类数据聚集在一起,并用于GMM均值超矢量的提取.在参数估计过程中,SPPCA 方法也采用EM 算法进行参数更新.
d)最小最大策略.针对开发集数据与评估集数据的映射关系不一致问题,将最小最大策略 (Minimax strategy)[57]引入到总变化空间的学习过程中,该方法[57]通过这一准则来最小化最大风险,从而获得潜在风险最小的映射关系.这里给出上述不同方法的汇总信息,如表4 所示.

表4 不同有监督总变化空间模型汇总信息Table 4 Information of different supervised TVS models
2.3 会话补偿
GMM 均值超矢量向I-vector 特征映射后,所获得的原始I-vector 特征中仍然存在与说话人身份无关的信息,如语音内容差异性信息、语音时长差异性信息、信道差异性信息、环境噪声等,这些与说话人身份无关的信息被统称为会话变化信息 (Session variable)[59].对于上述信息,需要采用会话补偿方法来对其进行削减.本节将对基于任务分段式策略的会话补偿方法进行总结,将其划分为两类:一类方法通过寻找最佳的投影子空间来进行会话补偿特征空间学习,而另一类方法则通过特征重构的方式进行会话补偿.这里给出上述两类会话补偿方法的汇总信息,如表5 所示.

表5 不同会话补偿方法汇总信息Table 5 Information of different session compensation methods
2.3.1 子空间投影
这类方法大多通过子空间学习的方式,来寻找更能够表征说话人个性信息的投影方向,从而将原始I-vector 特征投影到更具有区分性的子空间中.在众多方法中,最为常用的方法为线性判别分析(Linear discriminant analysis,LDA)[60],其能够学习具有类内散度最小且类间散度最大的子空间,从而有效增强同类数据之间的共性、异类数据之间的区分性.此外,很多其他基于子空间投影思想的会话补偿方法也能获得较为理想的结果.例如:类内协方差规整 (Within-class covariance normalization,WCCN)[61]将降低预期错误率作为子空间学习的优化目标;扰动属性投影 (Nuisance attribute projection,NAP)[62]则以消除扰动方向为优化目标;非参数判别分析 (Nonparametric discriminant analysis,NDA)[63]通过使用最近邻规则,来学习原始I-vector 特征在子空间中的局部类间区分性信息与类内共性信息,进而使得其能够处理非高斯分布的原始I-vector 特征;而局部权重线性判别分析(Locally weighted linear discriminant analysis,LWLDA)[64-65]则以成对的方式来获取说话人类内散度,并通过关联矩阵对其进行缩放,从而既能够解决非高斯分布对会话补偿的限制问题,又能够保留原始I-vector 特征内的局部结构.
上述方法在学习到原始I-vector 特征的投影子空间后,需要将原始I-vector 特征进行投影表示.定义原始I-vector 特征为w,则投影后的I-vector 特征可以表示为

其中,A为投影矩阵,wˆ 为会话补偿 (投影)后的I-vector 特征.
2.3.2 特征重构
第二类方法则需要学习原始I-vector 特征中能够表示说话人个性信息的本质内容,并利用其对原始I-vector 特征进行重构,进而在重构过程中通过引入更多的约束条件来消除与本质内容无关的会话变化信息.这类方法大多以字典学习的方式来进行本质内容学习,它们的目标函数通常能够表示为
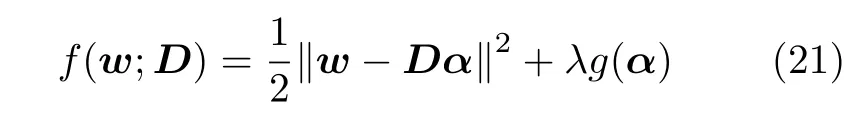
其中,‖·‖表示求模运算 (L2 范数),D为待求字典,g(α)为约束项,可以具有多种形式,也可以为多个约束项的累加形式;λ为约束项系数.
在这类方法中,基于稀疏编码 (Sparse coding,SC)的会话补偿方法[66]在重构原始I-vector 特征时加入稀疏约束,从而将会话变化信息以残差的方去除掉;基于块稀疏贝叶斯学习 (Block sparse Bayesian learning,BSBL)的方法[67]通过利用块内相关性对I-vector 特征进行稀疏重构;基于Fisher 判别字典学习 (Fisher discrimination dictionary learning,FDDL)的方法[68]则通过引入Fisher 正则项来增加字典对不同类别的区分性.
在获得字典D后,即可利用其进行原始I-vector 特征的重构,而重构后的特征Dα与稀疏表示α均可以作为说话人的句级特征进行使用.
3 任务驱动式策略
说话人句级特征的另一类提取方法为基于任务驱动式策略的方法,这类方法通常具有统一的优化目标,能够在统一任务的驱动下进行特征表示学习.这类方法的输入特征可以是帧级特征,例如:MFCC特征、对数FBank 特征等;也可以是对应语音段时长更长的段级特征,例如:对当前MFCC 或对数FBank 特征前后若干帧进行拼接的段级特征、语谱图特征等.在输入原始特征后,即可在任务驱动式策略的指导下进行句级特征提取.这类方法主要从两个角度开展研究:一是基于神经网络方法进行特征映射,并将网络的上层输出作为句级特征进行使用;二是基于联合优化思想,对分段式策略的各阶段进行联合优化,从而提取出面向任务的句级特征.下面将分别从以上两个角度展开介绍不同的句级特征提取方法.
3.1 神经网络方法
自21 世纪初期以来,神经网络方法在自然语言处理、图像处理、语音识别等领域的研究均取得了巨大进展,但其在说话人识别领域一直无法取得理想的性能,且性能一直远远低于I-vector 方法,因此神经网络方法并不像在其他领域一样广受研究者们的重视.直到2014 年随着深度-向量 (Deepvector,D-vector)方法[69]的出现,神经网络方法在说话人识别领域才暂露头角.然而,D-vector 方法为帧级特征提取方法,需要对帧级特征序列求取均值来获取句级的特征表示 ——D-vector 特征,且其识别性能仍然明显低于I-vector 方法.庆幸的是,其与I-vector 特征的融合特征能够取得相对理想的识别性能,这一突破性进展终于将神经网络方法带入到研究者的视线中,而这类从网络架构中所提取出的说话人特征则称作嵌入 (Embedding)特征.在此之后,一系列基于神经网络方法的说话人句级特征提取方法相继出现,这类方法主要通过学习原始数据与类别标签的映射关系,进行特征的表示学习.它们主要从两方面开展研究:一是网络结构,二是目标函数,本节也将从这两个角度展开介绍.
3.1.1 网络结构
本节将以说话人句级特征的发展顺序为线索,介绍5 种具有代表性的网络结构,分别为D-vector 方法[69]、X-vector 方法[70-71]、视觉几何组-中等(Visual geometry group-medium,VGG-M)网络[72-73]、深度残差网络 (Residual network,ResNet)[74-75]以及对生成抗网络 (Generative adversarial network,GAN)[76].
1)D-vector 方法.最初D-vector 方法用于与文本相关的说话人帧级特征提取,其将上下文相关的若干帧对数FBank 特征进行拼接并用作网络的输入,然后通过构建全连接 (Full-connected)深度神经网络 (Deep neural network,DNN)来进行帧级特征映射,激活函数采用maxout 函数,目标函数则采用softmax 损失,并从网络最后一个隐藏层中提取出帧级特征,最后对整段语音的帧级特征求取均值以获取句级特征,其网络结构如图5(a)所示.值得注意的是,D-vector 方法中帧级特征的上下文相关性仅体现在人工选择当前帧的前后若干帧,即通过增加输入层节点的数目来覆盖相关的上下文信息,并未引入需要额外标注的音素 (Phone)或三音素 (Triphone)信息,因此将其扩展为与文本无关的特征提取方法并不困难.
以D-vector 方法为基础,一系列基于神经网络的特征提取方法相继出现,这些方法主要从两方面开展研究.一方面,部分方法延续D-vector 方法的帧级特征提取架构,并设计描述能力更强的神经网络架构来进行帧级特征提取,然后以求取帧级特征均值的方式来获取句级特征.例如:瓶颈 (Bottleneck feature,BNF)特征[77-78]、基于CNN 的帧级特征表示网络[79-80]等.另一方面,其余方法则更关注帧级特征与句级特征之间的关系,它们将句级特征的提取过程嵌入于整个网络中,通过引入统计池化(Statistical pooling)、平均池化(Average pooling)等编码机制,将帧级特征序列转化为句级特征.这类方法包括X-vector 方法、具有平均池化层的VGG-M 网络与ResNet 等,且上述3 种方法均由于优良的识别性能而广受研究者们的关注.
2)X-vector 方法.从语音信号的动态特性可知,语音信号具有时序相关性,因此上下文语音内容的不同会导致同一发音模式的改变,而在原始声学特征中加入一些时序同态特征 (例如:一阶、二阶差分)能够有效提升说话人识别系统的性能.Xvector 方法正是继承了这一思想,为了捕捉到说话人个性信息的长时统计特性,其将能够有效描述语音信号动态特性的时延神经网络 (Time-delay neural network,TDNN)[22]引入到网络架构中.具体而言,X-vector 方法将前端提取的对数FBank特征送入时延神经网络中,然后通过统计池化层来计算帧级特征的统计量,再将这些统计量传至全连接层,激活函数采用修正线性单元 (Rectified linear unit,ReLU)函数,目标函数则采用softmax 损失.一般统计池化层后需要连接两个全连接层,远离输出层的Embedding 特征用于概率线性判别分析 (Probabilistic linear discriminative analysis,PLDA)[81]建模,靠近输出层的Embedding 特征则用于余弦距离打分 (Cosine distance scoring,CDS)方法[39],整个过程的网络结构如图5(b)所示.

图5 两种网络结构对比Fig.5 Comparison of two different network structures
与D-vector 方法相比,X-vector 方法在处理上下文关系时具有更加简单有效的结构.具体而言,Dvector 方法中全连接的DNN 在处理具有上下文关系的长时语音段时,输入层需要覆盖全部的上下文信息.而X-vector 方法中的TDNN 则能够将具有时序关系的上下文信息放置于不同的隐藏层,从而更高效地利用时序关系与网络参数,因此其比DNN 具有更好的长时描述能力[82].此外,TDNN 也能够很好地继承深度神经网络的前向反馈结构,并且可以通过在时域上的权值共享机制 (相当于在时域上的一维CNN)来实现网络的并行训练.
X-vector 方法由于其优良的性能,一经提出后迅速发展为说话人识别领域的主流方法之一.一系列基于它的神经网络方法也随之出现,其中应用最为广泛的是基于分解TDNN (Factorized TDNN,F-TDNN)[83-84]与扩展TDNN (Extended TDNN,E-TDNN)[85]的X-vector 特征提取方法.前者通过将每个TDNN 层的权重矩阵分解为两个低秩矩阵的乘积来减少参数量,同时还限制其中一个矩阵为半正交矩阵来确保信息的完整性.后者则对卷积层的时域上下文结构进行拓宽,并在卷积层之间交织放射层来增加网络的宽度.此外,还有一些其他X-vector 的扩展方法,例如:基于X-vector 方法的短语音特征提取方法[86]、长时语音特征提取方法[87]、加强上下文关系的特征提取方法[88]等.与此同时,随着全球最大规模说话人识别数据库VoxCeleb[73,75,89]的发布,两个作为此数据库基线系统的神经网络方法,也相继成为研究者们的关注热点,它们分别为VGG-M 网络与ResNet.
3)VGG-M 网络.VGG-M 网络最初由文献[72]提出,后被文献[73]加以修改并引入到说话人的特征提取应用中.VGG-M 网络主要通过多个卷积层、池化层与全连接DNN 层的组合叠加来增加网络的深度与宽度,并以此来提升网络的学习能力.其中,卷积层能够对卷积核覆盖范围内的数据进行加权叠加,因此可以学习到局部的上下文相关内容;而池化层能够对数据进行压缩,从而对输入池化层的数据进行降采样.同时,也正是由于VGG-M 网络庞大的参数量,使得其必须依赖大量的开发集数据来完成网络的训练.
VGG-M 网络以语谱图特征作为输入,然后经过多个卷积层与池化层的组合来进行特征表示,池化层采用最大池化(Maximum pooling),激活函数采用ReLU 函数.经过多组卷积层与池化层的组合特征表示后,数据传向平均池化层 (Average pooling),并最终传向全连接层进行特征表示学习,目标函数则采用softmax 函数,最终全连接层的输出可以作为说话人特征进行使用.值得注意的是,虽然输入网络的前端特征采用的是具有固定长度的语谱图特征,但平均池化层能够对任意时长的数据进行均值求取,因此VGG-M 网络最终可以获得句级特征.
4)深度残差网络 (ResNet).当网络的层数增加时,模型的表示能力会随之增强,但同时梯度的优化也会变得更加困难,由此会导致层数多的网络性能却低于层数少的网络这一退化(Degradation)问题.针对这一问题,ResNet 通过残差学习单元(Residual unit)将当前层的残差直接传递给后面的层,使得浅层数据在传输过程中可以跳过一部分网络层,直接传递给更深的网络层,从而解决梯度优化难题.这种方式能够有效避免信号失真,极大地加快了网络的训练效率.
文献[75]给出了两种ResNet 结构,分别为Res-Net-34 与ResNet-50,它们分别具有34 层与50 层的权重层.在此基础上,一系列基于ResNet 结构的说话人特征提取方法相继出现,例如:ResNet-20[90]、Thin-ResNet[91]等.更有一系列方法[92-94]在Res-Net 网络架构的基础上,探究不同目标函数对网络表示能力的影响.
5)生成对抗网络(GAN).随着GAN[76]在图像处理领域的取得巨大成功,其在说话人识别领域中的研究也逐渐成为热点之一.GAN 具有一种对抗博弈的学习方式,由生成器 (Generator)与判别器(Discriminator)构成.其中,生成器用于生成尽可能服从真实数据分布的样本,而判别器则用于对数据来源进行分类判别.基于这种博弈思想,一系列用于句级特征提取的方法相继出现.例如:多任务三元组生成对抗网络 (Multitasking triplet generative adversarial network,MTGAN)[95]通过联合利用生成对抗机制与多任务优化来改进Embedding 特征的编码过程;另一个基于多任务生成对抗网络[96]的方法则通过构建Embedding 编码器、分类器与判别器3 个部分来进行句级Embedding 特征的提取.此外,由于GAN 具有生成数据的功能,其也可用于数据增强[97].
3.1.2 目标函数
目标函数代表了整个网络的统一优化目标,其对网络描述能力的提升起着重要的指导作用.因此,设计出有的放矢的目标函数,能够使所提取的特征更适用于当前任务.目前的目标函数的相关设计与研究主要从两方面开展:一是以多分类为目标,二是以度量特征之间的相似度为目标.
1)以多分类为目标
这一类目标函数主要以最小化分类错误损失为目标,常用的目标函数有softmax 损失、交叉熵(Cross entropy)损失等.其中,softmax 损失的应用最为广泛,且拥有一系列对其进行扩展的改进方法.例如:中心 (Center)损失[98]、大间隔softmax(Large margin softmax,L-softmax)损失[99]、角softmax (Angular softmax,A-softmax)损失[100],以及加性间隔softmax (Additive margin softmax,AM-softmax)损失[101]等,下面分别展开介绍.
a)Softmax 损失.传统的softmax 损失具有各个节点输出的概率密度累加和的形式

其中,N为样本总数,K为类别数,xn为网络输入层的第n个输入特征,yn为xn的类别标签,f(xn)为softmax 层前一层的输入数据,θk为前一层的权重.
b)中心损失.针对softmax 损失中类间距离较小、类内距离较大的问题,中心损失[98]对每类数据定义一个质心,并使每类数据尽量贴近其所属类的质心,从而最小化类内距离.其具有以下形式:

其中,cyn为数据f(xn)所属类的质心.值得注意的是,由于Lc只对类内距离进行约束,因此当将传统softmax 损失与中心损失相结合时,会得到同时对类内距离与类间距离进行约束的目标函数

c)L-softmax 损失.L-softmax 损失[99]首次将角的概念引入到softmax 损失中,对于softmax 损失中的f(xn),可以表示为

其中,αyn,n为f(xn)与θyn的夹角,只有当αyn,n小于f(xn)与其他任意权重θk(k≠yn)的夹角时,f(xn)才属于第yn类.由于余弦函数为递减函数,因此需要保证 cos(αyn,n)>cos(αk,n)(k≠yn).此时,如果将αyn,n改为mαyn,n,则能够使f(xn)与其所在类别权重θyn的夹角比其他夹角小m倍以上,从而使得不同类别决策面之间的距离更远,进而增加特征间的区分性.其中,m≥2且为整数,m取整数的目的是为了更方便地利用倍角公式对其进行展开求解.基于此,L-softmax 损失可以表示为

在L-softmax 损失的基础上,A-softmax 损失[100]添加了对权重θk的标准化;而AM-softmax 损失[101]则在A-softmax 损失的基础上添加了对数据的标准化,并将角度上的倍数关系 (mαyn,n)直接改为相减的关系 (αyn,n-m).
2)以度量相似度为目标
这一类目标函数主要以度量学习 (Metric learning)为基础,通过计算特征间的相似度来控制它们的关系.常用的目标函数有对比损失 (Contrastive loss)[102]、三元组损失 (Triplet loss)[103]等.
a)对比损失.对比损失主要用于训练孪生(Siamese)网络,网络输入为成对的数据,其网络结构示意图如图6(a)所示.当成对的数据属于同一类别时,类别标签y=1,反之则y=0.对比损失主要通过欧氏距离来度量样本之间的相似度,用其他距离进行度量,例如:内积距离、余弦距离等.基于此,对比损失具有以下形式:

图6 两种目标函数对应网络的结构示意图对比Fig.6 Comparison of the structure of the networks corresponding to the two different objective functions

其中,d[f(x1),f(x2)]表示f(x1)与f(x2)的距离,m为间隔.在对比损失这一目标的指导下,当输入的数据对属于同一类别时,距离d[f(x1),f(x2)]会逐渐减小,同类数据会持续在特征空间中形成聚类;当输入的数据对属于异类时,距离则会逐渐变大,直到超过设定的间隔m.
c)三元组损失.用三元组损失训练的网络则称作三元组网络 (Triplet network),其结构示意图如图6(b)所示.三元组损失从对比损失发展而来,但网络的输入为三元组,分别为固定 (Anchor)样本xa、正例 (Positive)样本xp与负例 (Negative)样本xn,因此它们可以组成一对正样本与一对负样本.基于上述符号定义,三元组损失可以表示为

三元组损失的目标是使得同类样本在数据空间中尽可能靠近,异类数据尽可能远离;同时,为了避免样本在数据空间中聚合到一个非常小的空间中,要求负例样本对的距离d[f(xa),f(xn)]应该比正例样本对的距离d[f(xa),f(xp)]至少大m.
本小节介绍了神经网络方法中若干常用的目标函数,表6 展示了上述目标函数的汇总情况.

表6 不同目标函数汇总信息Table 6 Information of different objective functions
3.2 联合优化方法
另一类基于任务驱动策略的方法为联合优化方法,它们通过将原本独立优化的若干个阶段进行联合优化,从而实现在统一任务驱动下进行各个阶段子目标优化的目的.与神经网络方法相比,联合优化方法也具有统一的优化目标 (任务);且这类方法由于在各阶段具有自身的优化目标,因此对各阶段的解释性更强.
这类方法大多以I-vector 方法为基础,并将I-vector 方法中的各阶段与后端分类器进行联合优化.典型的方法有:将会话补偿阶段与后端分类器进行联合优化的深度神经网络-概率线性判别分析(Deep neural network-probabilistic linear discriminative analysis,DNN-PLDA)方法[104]、基于双层(bilevel)结构的方法[105],将总变化空间 (TVS)学习阶段与后端分类器进行联合优化的任务驱动变化模型 (Task-driven variability model,TDVM)[106],以及将I-vector 方法的全部阶段进行联合优化的特征-统计量-身份-向量 (Feature-to-statistics-to-Ivector,F2S2I)方法[107]、任务驱动多层框架 (Taskdriven multilevel framework,TDMF)[108]等.联合优化方法由于能够在分类器的指导下进行不同阶段的联合学习,因此在得到说话人句级特征之后,可以直接采用联合学习的分类器进行识别任务.上述方法的汇总信息如表7 所示,下面将以bilevel 优化方法与TDMF 方法为例,分别展开介绍.

表7 联合优化方法汇总信息Table 7 Information of different joint optimization methods
1)双层 (Bilevel)优化方法.基于双层结构的方法[105]能够有效地联合优化会话补偿阶段与分类器学习阶段,其中会话补偿阶段对应于双层结构的下层,而分类器学习阶段则对应于上层.该方法能够将分类器根据输入数据及其类别标签学习到的区分性信息反馈回会话补偿的优化过程中,从而进行更有利于识别任务的会话补偿.在这一结构中,下层以字典学习的形式进行会话补偿;而上层分类器在考虑自身识别目标的同时,也会兼顾下层字典学习的目标,将其作为约束条件.定义原始I-vector 特征用w∈W ⊆RR表示,其对应的说话人类别标签为y∈Y ⊆R1.其中,W为原始I-vector 特征所在集合,Y为标签所在集合.用于会话补偿的字典D∈RR×P与分类器参数 Θ 可以通过求解以下联合优化问题获得:

其中,fU(α*,y;D,Θ)为上层分类器的目标函数;fL(w;D)为下层字典学习的目标函数,具有式 (21)的形式;D为满足凸约束的字典所在集合;Θ 为分类器参数所在凸集;α*(w;D)为原始I-vector 特征w在字典D上的最优表示.通过下层目标函数与上层目标函数的反复迭代优化,最终即可求得参数D与Θ.
2)TDMF 方法.TDMF 方法[108]采用任务驱动多层联合优化的方式,对I-vector 方法中的各阶段进行联合学习,并将分类器学到的区分性信息反馈回各阶段,从而使得各阶段的学习更具有目的性.这些阶段包括UBM 学习、GMM 自适应、总变化空间学习以及分类器学习,TDMF 方法具有多层(Multilevel)结构[109],能够将以上4 个阶段分别置于不同层中,其示意图如图7 所示.

图7 TDMF 方法示意图Fig.7 Schematic diagram of TDMF method
定义开发集数据中的声学特征可以表示为集合X={xs,h,t∈RF;s=1,2,···,S;h=1,2,···,Hs;t=1,2,···,Ts,h},则TDMF 方法可以表示为以下优化问题:

4 后端处理
在获取说话人句级特征后,需要对特征进行识别.本节将分别介绍说话人识别所常用的后端分类器与性能评估指标.
4.1 后端分类器
在识别阶段,需要计算测试语音与目标说话人语音的相似度,并以此相似度作为识别得分.目前主要有两种常用的识别方法:一种是直接利用余弦距离打分 (CDS)方法[40]计算两个特征之间的余弦相似度,其优点是能够快速获得识别结果;另一种是利用概率线性判别分析 (PLDA)模型[81]进行识别,其优点在于能够进一步提升句级特征的区分性.下面将对以上两种方法展开介绍.
1)余弦距离打分 (CDS).在识别阶段,CDS 方法将测试与目标说话人语音所对应的句级特征的余弦距离作为得分.设目标说话人与测试说话人的特征分别为we与wt,则余弦距离得分的形式为

其中,〈·〉表示内积运算.
2)概率线性判别分析 (PLDA).在实际应用中,受信道畸变等因素的影响,句级特征无法严格服从高斯分布.因此,最初的PLDA 模型对I-vector 特征采用重尾先验 (Heavy-tailed priors)假设[110],来避免非高斯分布对于PLDA 模型的影响.不久之后,经长度规整 (Length normalization,LN)[111]后的I-vector 特征被证明可以近似服从高斯分布,而基于高斯先验假设的PLDA 模型 (长度规整后)的性能也与基于重尾先验假设的 PLDA 模型 (未进行长度规整)的性能相仿.对说话人s第h段语音段的句级特征ws,h∈RR进行长度规整,可以表示为

其中,RR为长度规整后的句级特征;µ为开发集ws,h的均值矢量.除了采用长度规整方法外,也可以采用Kullback-Leibler (KL)散度对特征进行规整[112],其也能起到明显的规整效果.
经规整后的句级特征即可用于训练PLDA 分类器,其假设每位说话人s的不同语音段h所对应的特征s,h均能够由同一个说话人隐变量zs∈RZ表示为

在进行说话人识别时,定义目标说话人与测试说话人经过长度规整后的特征分别为则PLDA 分类器下的说话人匹配得分可以表示为

其中,Q与P为中间变量,可以由变量 Σtot与Σac表示,以上4 个变量可以表示为

上述方法为基于产生式训练方式的PLDA 分类器.由式 (35)可以看出,PLDA 分类器能够计算两个句级特征在不同度量下的相似度,这种处理方式类似于SVM 中核函数的学习过程,故也可采用判别式的训练方式来进行PLDA 分类器学习[113].
在上述研究的基础上,一系列PLDA 模型的改进方法也相继出现,这些方法大多针对会话差异性问题.对于语音内容差异性问题,非线性PLDA (Nonlinear PLDA)模型[114]与非线性束缚PLDA (Nonlinear tied-PLDA)模型[115]先将原始I-vector 特征进行非线性映射,映射到服从高斯分布的空间中,然后联合学习这种非线性映射关系以及PLDA 模型的参数,从而使得经过非线性映射后的I-vector 特征更加服从高斯分布,以消除语音中的差异性内容.对于语音时长差异性问题,基于不确定性传播 (Uncertainty propagation)的方法[116]主要通过对与原始I-vector 特征中不确定性相关的部分进行建模,来学习不同时长语音中的不确定性信息,从而对其进行削减;而孪生PLDA (Twin model PLDA)模型[117-118]则通过建立两个联立的 PLDA模型,来分别学习短语音与长语音中的说话人信息.对于信道与领域差异性问题,多信道简化PLDA(Multi-channel simplified PLDA)模型[119]通过计算每个信道的类内协方差矩阵来学习信道信息并对其进行削减,从而得到只与说话人相关的部分;基于最大后验概率 (MAP)的PLDA 模型[120-121]则通过领域自适应的方法消除不同领域中的差异;而基于贝叶斯联合概率 (Bayesian joint probability)的PLDA 模型[122]则将源域与目标域之间的KL 散度作为正则项约束,从而帮助寻找针对目标域的最佳PLDA 参数.对于噪声问题,基于信噪比 (Signalto-noise ratio,SNR)不变的PLDA 模型[123]将原始I-vector 特征划分为说话人相关、信噪比相关以及信道相关三部分,并对后两部分进行消减,从而得到只与说话人相关的部分;而混合PLDA (mixture of PLDA)模型[124]则以多个PLDA 模型加权和的形式,同时学习原始 I-vector 特征中的说话人相关信息;基于贝叶斯网络 (Bayesian network)的PLDA 模型[125]则从有向图模型的角度出发,研究如何从不利环境中分离出理想环境中PLDA 分数的分布情况.
4.2 评估指标
在得到了特征的匹配得分之后,即可对特征的所属类别进行判决.不同的说话人识别任务,其所对应的判决方法与评估指标也不相同.说话人识别按照识别任务分类,可以分为说话人确认 (Speaker verification)与说话人辨认 (Speaker identification)[4].其中,前者的识别任务为确定某两段语音是否来自同一位说话人,为 “一对一”的判别问题;后者为判断某段语音来自于哪位说话人,为 “一对多”的分类问题.
在介绍评估指标之前,本节先对说话人识别中不同数据集划分的命名与作用进行简要介绍.数据库中全部数据可以划分为开发集数据与评估集数据,有的数据库还会划分出验证集数据.其中,开发集数据用于模型训练,验证集数据用于模型参数有效性验证与参数调节,评估集数据用于性能测试.针对说话人确认任务,评估集数据又可以继续划分为注册集与测试集两部分:注册集数据来自于目标说话人,其对应于待确认的两段语音中的前一段语音,测试集数据则对应于后一段语音.这两段语音共同作为测试语音,用于确认它们是否来自同一位说话人.当两段语音属于同一说话人时,测试语音所对应的说话人被认定为目标说话人,此次测试称作目标测试 (Target trial);当不属于同一说话人时,测试语音所对应的说话人被认定为冒认说话人,此次测试称作非目标测试 (Nontarget trial).针对说话人辨认任务,某些数据库中开发集与评估集数据的类别没有交叉,因此在评估集中也需要划分出注册集与测试集;而另一些数据库则直接将开发集数据中的说话人当作目标说话人,全部评估集数据则直接当作测试集进行使用.考虑到数据库的选择与使用对于说话人识别系统性能的评估具有很大参考价值,本文将对说话人识别领域中常用的数据库及其相关信息进行总结,详情如表8 所示.

表8 常用数据库信息Table 8 Information of common databases
1)说话人确认
在说话人确认系统中,需要对待识别语音的输出得分进行判定,以获得最终的识别结果.一般将得分与一定的阈值进行比较,若大于此阈值,则接受其为目标说话人,否则判定其为冒认说话人 (拒绝).对应于以上两类判定,即接受与拒绝,存在两种错误率,分别为错误接受率 (False acceptance rate,FAR)与错误拒绝率 (False rejection rate,FRR).当设置不同阈值时,会存在不同的FAR 与FRR,对于二者之间的关系,可以通过检测错误权衡 (Detection error trade-off,DET)曲线[5]来进行直观的展示.DET 曲线上的每一个点对应一个判定阈值,越接近原点的DET 曲线识别性能越好.对于阈值的选取,比较常用的方法为等错误率 (Equal error rate,EER)与最小检测代价函数 (Minimum detection cost function,MinDCF)[5].其中,评估指标EER 为FAR 与FRR 相等时的错误率,EER 越小说明说话人识别系统的性能越好.而评估指标MinDCF 则综合考虑以上两类错误发生的不同代价,以及目标说话人与冒认说话人出现的先验概率,每个阈值对应的DCF 可以表示为

其中,Cmiss为错误拒绝代价,Cfa为错误接受代价,PFRR为错误拒绝率,PFAR为错误接受率,Ptarget为目标说话人出现的先验概率,1-Ptarget为冒认说话人出现的先验概率.取式 (37)中的最小DCF即为MinDCF,其越小说明说话人识别系统的性能越好.在不同的说话人评测中,式 (37)中代价与先验概率往往需要设置不同的数值.
2)说话人辨认
在说话人辨认系统中,通常采用正确率 (Accuracy,ACC)进行评估

其中,PACC为正确率,Ntest为测试集样本总数,Ncorrect为测试集中测试正确的样本数.
5 未来研究趋势
前文总结了说话人句级特征提取研究从任务分段式策略到任务驱动式策略的演进历程.随着技术的进步,说话人识别系统的性能不断提升,与实际应用的要求也越来越接近.然而,该领域的研究仍未结束,目前仍有一些关键性的难题亟待解决.如何有效解决这些问题,将是未来发展的主要方向,本节将对一些挑战性问题进行介绍,并总结未来研究发展趋势.
5.1 端到端模型的解释性
近年来,说话人识别的研究趋势正朝着端到端模型的方向快速发展,其中最典型的趋势就是,如何通过一体化的形式将时长不等的语音信号转化为具有固定长度且区分性强的句级特征.在这类研究中,大多数方法主要通过不同结构神经网络的叠加,来实现数据从帧级特征到句级特征的转换.这些方法虽然能够取得较为理想的性能,但其解释性并不强,而如何打开深度学习的黑箱问题,将是未来研究的一个重要发展趋势.考虑到先验信息中包含了人类对于相关领域的认知,因此可以通过引入更多的先验信息来对模型进行设计,从而增强它们的解释性.这类研究可以从3 个角度开展:前端帧级特征表示、帧级特征向句级特征转换的编码机制,以及后端句级特征表示,它们分别对应了数据从信号级输入到帧级特征、帧级特征到句级特征,以及句级特征提取3 个数据转换过程.
1)前端帧级特征表示
在前端特征提取时,目前的方法大多直接采用传统的声学特征,例如:MFCC 特征、FBank 特征与语谱图特征等,它们的前端帧级特征提取阶段与模型学习阶段仍然属于分段式的学习策略,前端特征提取与后端模型学习的目标不一致,这将导致前端所提取的帧级特征不具有任务针对性.因此,需要将前端特征提取阶段与模型学习阶段进行有效关联,这将需要对传统的前端提取过程进行改造,将其设计为能够与后面的模型学习阶段进行有效连接的模型结构.面对这样的需求,需要引入更多的先验信息来设计前端帧级特征提取阶段的模型结构,从而依据语音信号的特性来设计出具有足够表达能力的模型.
2)编码机制
在编码机制方面,能否将帧级特征序列有效转化为句级特征,将严重影响到整个说话人识别系统的性能,因此编码机制的设计不应止步于简单的统计池化或均值池化[133].针对这一问题,可以从帧级特征的时序保持、注意力机制、字典学习等角度,来对帧级特征之间的关系进行编码,从而有效改进帧级特征序列与句级特征之间的映射关系.在未来的研究工作中,对于编码机制的改进仍然存在很多值得研究的问题,可以通过引入更多先验信息来对帧级特征之间的关系进行约束,从而设计出更具有解释性的编码机制,进而提升模型在长时识别场景下的学习能力.
3)后端句级特征表示
在后端句级特征表示方面,目前的方法大多只采用简单的全连接DNN 来进行句级特征的映射表示,这使得句级特征表示缺乏解释性.因此,如何利用先验信息来对句级特征进行进一步表示,也具有一定的研究意义.
5.2 模型的鲁棒性
在实际应用中,复杂环境迫使说话人识别系统不得不对模型的鲁棒性提出很高的需求.具体而言,复杂环境包括环境噪声与信道失配等问题,能够对这些干扰性信息进行有效补偿一直是说话人特征提取研究领域面临的巨大困难与挑战.
在环境噪声方面,录音环境中总是无法避免地包含各类噪声,例如:白噪声、音乐播放、车辆行驶的声音等.这些噪声均会在一定程度上淹没语音信号中所蕴含的说话人个性信息,从而使得系统无法准确获取说话人特征.同时,环境噪声通常无法提前预知,这往往使得系统性能具有极大的不确定性.为了解决这一问题,可以从提高特征对噪声的鲁棒性、建立抗噪模型两个角度开展研究.在信道失配方面,语音信号可以通过各种不同的录音设备获得,如手机、麦克风、固定电话、录音笔等.不同的录音设备会直接导致语音信号传输信道的变化,从而使得语音信号发生频谱畸变,进而严重影响到特征对说话人特性的表示能力,造成测试语音特征与说话人模型在声学空间分布上的失配.目前的方法主要从分段式学习策略的角度对信道失配问题进行补偿.
随着神经网络方法的兴起,信道失配问题往往不再需要单独解决,而可以与环境噪声问题合二为一,这些问题均可以通过学习具有强鲁棒性的神经网络模型来得到补偿.因此,如何设计出具有高抗干扰能力的网络模型,则成为未来研究的重点内容之一.同时,也可以通过数据增强的方式为模型提供更多数据,从而增强模型对不同数据的鲁棒性.
5.3 相关领域扩展
随着说话人识别研究的发展,一些相关领域也取得了相应的发展.其中,说话人电子欺诈 (Speaker spoofing)与说话人分割聚类 (Speaker diarization)是说话人识别研究中联系最密切的扩展应用.
1)说话人电子欺诈
随着人们对电子设备依赖程度的增加,不同的说话人电子欺诈手段陆续出现,例如:声音模仿、语音合成、声音转换与录音重放等.这些随着科技进步而产生的诈骗手段迫使研究者们不得不加强对会话变化信息的重视[134],以往那些需要被削弱的信息(背景噪声、信道、录音距离等)却成为了检测出电子欺诈语音的重要依据.
2)说话人分割聚类
在进行语音录制时,往往会掺杂多位说话人的语音,如果不将多位说话人的语音信号进行分离,将会直接影响到系统的识别性能.这时便需要通过获取语音信号中各时间点所对应的说话人信息,来对多说话人的混合语音进行分割与聚类处理[135-136].根据分割聚类过程的不同,可以分为同步语音分割与异步语音分割.前者指在分割语音片段的同时判断语音片段所对应的说话人类别;后者是将多说话人的混合语音分割成若干个独立的说话人语音片段,然后再将同一说话人的语音片段聚集在一起进行每个说话人身份认证.
5.4 类脑架构推广
随着人工智能相关领域的快速发展,越来越多的类脑架构相继出现.此类架构受大脑多尺度信息处理机制启发,能够使系统实现多种认知能力并高度协同.对于说话人识别领域,也可以借鉴类脑架构进行相应的推广,使其能够适应于不同的说话人识别任务,对不同的语音环境 (噪声、信道、语种、身体状态、语音时长等)也具有适应能力,并逐渐逼近于具有学习能力与进化能力,且能与其他模式识别应用相结合的通用智能.
6 结束语
句级特征提取是从语音信号中捕获说话人信息的重要过程,其能够有效、全面地表示一段语音信号,因此其对说话人身份的鉴别起着至关重要的作用.鉴于此,本文对具有代表性的说话人句级特征提取方法进行了整理与综述,分别从前端处理、基于任务分段式与驱动式策略的特征提取方法,以及后端处理等几方面进行论述,并探索了各类方法之间、同类方法之间的差别与联系,还横向统计了各类方法的实施细节.最后还对未来的研究趋势展开了探讨与分析.在当前研究的主要发展趋势方面,本文抛砖引玉,希望能够帮助相关科研人员了解说话人特征提取问题,并为相关工作开展起到推动的作用.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·高一版(2021年11期)2021-09-05
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
电子制作(2018年19期)2018-11-14
航空世界(2018年12期)2018-07-16
数学大世界(2018年35期)2018-02-22
