
基于BERT对问答平台重复问题的识别
2022-04-15 05:16李晓娜陈子曦李俊民
科教导刊·电子版 2022年7期
李晓娜 蔡 琼 陈子曦 李俊民
(江汉大学 湖北·武汉 430056)
1 问题的提出
随着现代信息科学技术的发展,网络上各类问答平台越来越受到网络用户的欢迎,例如知乎平台用户数量已经破亿,而技术社区问答平台可以作为网络用户相互分享交流经验技术的社区平台,近年来逐步成为网络用户寻找技术类疑难解答的首要渠道。然而随着各分类技术性问题的文本数据量不断攀升,给技术问答平台的日常运营维护带来了挑战。因为随着新用户的不断加入导致用户数量的增加,而新用户提出的疑问可能已经在本平台上被其他用户提出过并且已经存在解决方案了。但由于技术性问题的复杂性,不同用户提出的问题的切入角度不同,用问题标题关键词匹配的搜索系统无法高效指引新用户至现有的问题解决方案。于是,新用户就会在该平台上提出重复的问题,所以这些重复的问题会进一步增加平台后台工作运行的文本量,导致平台重复响应相同的问题,工浪费时间且工作效率极低。对于这种现象,通常的做法是及时找到新增的重复问题并打上相应的标签,然后在用户的搜索结果中隐藏该类重复问题,保证对应已解决问题出现的优先级。所以,本文将会建立一个基于自然语言处理技术的自动标重系统会对该问答平台的日常维护起到极大帮助。
2 数据处理
2.1 数据预处理
2.1.1 去重和去敏
对附件1:对于附件1进行数据清洗,首先检查附件1中是否含有缺失值和异常值。经检验该表格中不含有缺失值和异常值。然后利用pycharm的中的pandas语句读取附件1,开始我们先只提取“translated”一列,因为我们要做的是对中文文本的查重,所以我们就直接删掉英文版问题,以便于我们后期的数据清洗。利用drop_duplicates()语句对全体中文问题文本进行去重,即去掉完全重复的问题,再利用lambda x:re.sub删去敏感词汇。
2.1.2 jieba分词
去重去敏结束之后,我们利用jieba进行分词切割。Jieba分词是一种基于前缀词典及动态规划实现分词,jieba分词主要是基于统计词典,构造一个前缀词典,然后利用前缀动态词典对输入句子进行切分,得到所有的切分可能,根据切分位置,构造一个有向无环图,然后通过动态规划算法,计算得到最大概率路径,也就得到了最终的切分形式。我们利用jieba分词将每个问题文本化为一组分词。
2.1.3 去停用词和标点
我们为了使得问题重复率的检验更加高效成功,所以我们要对前面分词得到后的结果再进行去停用词。我们在pycharm中利用‘stopword.txt’导入常见停用词库,根据我们观察该表格得到的一些额外的停用词,例如‘≮’,‘≯’,‘≠’,‘≮’,‘?’,‘会’,‘月’,‘日’,‘–’等等也计入停用词库,然后对translated整体去停用词。并且去掉所有标点。
2.1.4 整理重复问题组
对附件2:在excel中先将附件2中“duplicates”一列的数据移动到“questionID”一列,然后利用excel中的排序功能对总体数据进行id升序排列,此时这一列有很多id重复,然后我们利用excel中的数据功能找出重复值并且高亮重复值,然后删掉重复值,这时我们发现有很多重复值的label既有0也有1,此时我们优先删掉lebal为0的id,得到新表格。
2.2 中文词特征提取
我们提取词向量使用的是 CountVectorizer和 Tfidf-Transformer方法。CountVectorizer是通过fit_transform函数将文本中的词语转换为词频矩阵CountVectorizer是属于常见的特征数值计算类,是一个文本特征提取方法。对于每一个训练文本,它只考虑每种词汇在该训练文本中出现的频率。CountVectorizer会将文本中的词语转换为词频矩阵,它通过fit_transform函数计算各个词语出现的次数。
3 模型使用
3.1 语义相似度计算
我们对于语义相似度的计算选择的是Google研发的当下最火的BERT。
3.2 数据预处理
我们将原附件2中的所有重复问题,即label为1的问题组留下,其他label为0的问题先删掉,如果存在“一对二”或“一对多”即有两个或两个以上的问题重复,我们将这类数据进行拆分,全部变成一对一的问题组,方便我们模型的建立和使用。
3.3 模型的评估
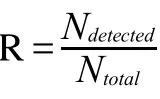
我们对模型进行测试:
随机挑选一个目标问题的id:2,输入在pycharm程序代码中,点击运行,结果显示,id为2的问题找出的重复问题的top 10。经我们人工判定,其中top K列表结果中正确检测到的重复问题编号数量为7个,该样本实际拥有的重复问题数量为10个,所以R=0.7。
4 模型的评价与优化
4.1 决策树模型的评价
决策树的优点:决策树易于理解和实现,人们在在学习过程中不需要使用者了解很多的背景知识,这同时是它的能够直接体现数据的特点,只要通过解释后都有能力去理解决策树所表达的意义。
决策树的缺点:(1)对连续性的字段比较难预测;(2)对有时间顺序的数据,需要很多预处理的工作;(3)当类别太多时,错误可能就会增加得比较快;(4)一般的算法分类的时候,只是根据一个字段来分类。
4.2 BERT模型的评价
BERT的优点:BERT是截至2018年10月的最新state oftheart模型,通过预训练和精调横扫了11项NLP任务,这首先就是最大的优点了。而且它还用的是Transformer,也就是相对rnn更加高效、能捕捉更长距离的依赖。对比起之前的预训练模型,它捕捉到的是真正意义上的bidirectional context信息。
BERT的缺点:BERT在第一个预训练阶段,假设句子中多个单词被Mask掉,这些被Mask掉的单词之间没有任何关系,是条件独立的,然而有时候这些单词之间是有关系的,比如“NewYorkisacity”,假设我们Mask住“New”和“York”两个词,那么给定“is a city”的条件下“New”和“York”并不独立,因为“New York”是一个实体,看到“New”则后面出现“York”的概率要比看到“Old”后面出现“York”概率要大得多。
5 模型的推广
BERT模型的推广:本文解决技术平台对重复问题的识别使用的是一种称之为BERT的新语言表征模型,意为来自变换器的双向编码器表征量(BidirectionalEncoder Representations from Transformers)。不同于最近的语言表征模型(Peters等,2018;Radford等,2018),BERT旨在基于所有层的左、右语境来预训练深度双向表征。因此,预训练的BERT表征可以仅用一个额外的输出层进行微调,进而为很多任务(如问答和语言推理)创建当前最优模型,无需对任务特定架构做出大量修改。
决策树模型的推广:企业管理实践,企业投资决策,由于决策树很好的分析能力,在用户分群、用户流失等领域应用较多。
猜你喜欢
全面腐蚀控制(2021年7期)2021-10-28
校园英语·月末(2021年13期)2021-03-15
中国特种设备安全(2019年8期)2019-10-14
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
世界宪法评论(2016年0期)2016-12-06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
外语学刊(2011年3期)2011-01-22
