
云计算下小样本数据库间差异消除方法研究
2022-04-19 00:46赵有俊
计算机仿真 2022年3期
陈 虹,赵有俊
(景德镇陶瓷大学,江西 景德镇 333001)
1 引言
小样本数据库是目前常见的数据储存形式之一[1]。数据质量将直接影响小样本数据库的工作效率[2]。特别是小样本数据库中的差异数据,会在很大程度上降低小空间存储信息的质量。
王桌芳等人提出一种基于兴趣度度量的多类差异数据挖掘消除方法[3],利用兴趣度度量方法检测大规模差分数据库,计算数据簇之间距离后获取隐藏文本数据特征,然后根据数据过滤算法流程对数据进行处理,从而检测并剔除数据库内的差异数据。朱赞生等人提出一种基于B样条曲线的异常数据剔除方法[4],在构造初始拟合数据的基础上,然后利用B样条曲线构造递推模型,并基于样条平滑方法判断门限,从而判定数据是否异常,并对于异常数据及时剔除。
但上述两种方法对差异数据的消除率还有待提高。为此,本文基于云计算技术设计了小样本数据库间差异消除方法。根据差异数据相关特征确定异常数据的偏差函数,再在时间序列内去掉差异数据点,最终实现对小样本数据库中差异数据的消除。与传统方法相比,本文方法对差异数据的消除率更高,从而提升了小样本数据库的信息储存质量。
2 云计算数据库系统
云计算数据库是现阶段较常使用的数据库之一,其中涵盖大量不同种类的数据信息,能够根据要求构建多种多样的小样本数据库,具有很高的实时性、有效性和快速性。云计算数据库通过集群应用网格技术或分布式文件系统的功能,将网络中大量不同类型的存储设备通过应用软件组合在一起,共同对外提供数据存储和业务访问功能。
云计算数据库体系结构如图1所示。顶层为应用层,主要为用户提供对接服务;中间层为服务层,分为应用服务层和分布式服务层,由中间件相连,主要为应用层提供服务;底层为节点存储层,主要为节点数据提供物理存储,从而形成完整的数据信息库。
利用云计算平台将数据存储在如图1所示的数据库中,结合差异数据消除方法,可以有效保证不同类型的云数据库不存在重复数据,避免数据异构性等差异,有效降低构建的小样本数据库间差异性,从根本上提升数据库储存的实时性、快速性和可靠性。
3 数据库间差异数据消除方法
一般来说,为了增强实验的有效性,需要利用不同样本对象进行多次迭代操作,帮助所设计的方法在最真实环境下获得最优结果,以便更好地进行改进或优化。同时,在本文方法设计过程中,为了提高运算速度,目标数据节点不仅要将源数据节点上的数据集成到目标节点上,还要能够在一定时间内与源数据节点上的集成数据保持同步。当目标数据节点和源数据节点同步数据时,数据长度要尽可能短,尽可能少地使用传输带宽来完成对不同性质差异数据消除。
3.1 差异数据特征提取
假设当局部空间为线性时,每个小样本数据库中的数据采样点总是处于高维空间映射的低维空间中的相应位置。因此,在分析差异数据特征时,需以性质相同的数据为基础,提取相关特征量。假设初始差分样本集为f(x,y),其中,x=0,1…,p-1,y=0,1…q-1,可得出空间相关函数表达式为

(1)
式(1)中,a和b均为正整数。充分结合空间保护的特点,可获得差异数据库中数据的自适应分布函数,其表达公式为

(2)
式(2)中:N代表差异数据库中的数据对象数量,rn代表距数据的有效距离,C(xn)代表数据特征量,k代表数据调整因子[5]。


(3)
式(3)中,ζ代表样本数据特征提取误差个数,σ代表惩罚因子,P(X)代表数据分布函数,l代表任意两数据见的平均间距[6]。通过上述处理,完成了差异数据特征的有效提取。
3.2 差异数据检测
检测不同小样本数据库中存在的差异数据,是保证有效消除差异数据的重要基础。本研究在设定阈值的基础上,以模式识别的方式完成对差异数据的检测[7]。具体过程如下所示:
如果使用不同类型的数据库进行属性匹配操作,数据中存在的性质差异将会严重影响结果的准确性。因此,可通过判断数据库间可能为相同属性数据间的相似程度,用以去除差异数据,从而保证检测和消除结果的质量。
在非线性检测理论的基础上,通过Duffing混沌振子判断小样本数据库间差异数据,其混沌模型可以描述为下式
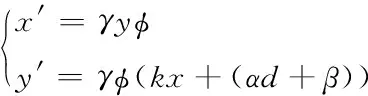
(4)
式(4)中,αd+β代表数据库的非线性恢复力。当αd+β的数值不变时,那么相关振子系统变化趋势取决于策动力。当γ=0时,所对应点必须在(0,0)或(+1,0)上。若γ值持续增大时,混沌状态将转变为大尺度周期状态。在此过程中,平台将展现较强的抗干扰能力。
在检测过程中,需要获得合适的参数和策略动态系数,使系统始终处于由混沌状态到大尺度周期过渡的临界状态。如果设置扰动力φ,且使其与驱动力之间存在小的频率差Δω,那么总驱动力的表达式为
A(φ)=(γcos(x′+y′)+cos(Δω))×t
(5)
式(5)中,t代表时间窗口。由此可知,小频差会严重影响系统的总策略功率,需令系统始终保持混沌与最大尺度周期间的过渡。经过运算得出过度过程的状态为

(6)
3.3 差异数据的偏差函数


(7)
在此基础上,设置B代表集合X的分段数,HB代表分段集,可得出整个时间序列的误差集,其表达式如下

(8)
若时间序列中的第i段由bi代表,g⊆bi可代表偏差集,则从上述分析来看,如果bi时间序列中的偏差点数为z,那么其均方偏差表达式如下
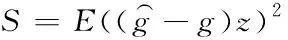
(9)

(10)
式(10)中,u表示偏差点数。
3.4 确定差异数据点及消除
在小样本数据库中,选择一些数据样本并对这些数据的属性展开分类,将每个数据属性的属性特征作为一维数据,对数据属性特征实施聚类。确定数据差异点集的主要原因是运算出偏差函数的最小值[9-10]。
根据相关原理,上文构造了偏差函数W,在此基础上,构造偏差函数W的递推表达式VW如下

(11)
分段数为r的时间序列是x1…xr计算了最小均方差的最优策略,获得其均方偏差计算过程为E(i,j,r)。可以看出,用E(i,j-1,r)代表时间序列j-1的最优策略x1…xr。当分段数为j-1时,此时存在r个偏差[11]。
结合上述过程,若e代表差异数据点,那么需要在时间序列内去掉它,并且偏差函数W的参数需要实时更新。如果e是正常数据点,那么需要添加新的λ变量以更新偏差函数W。因此,需要将e和λ分别进行更新,过程如下

(12)

(13)
通过式(12)和式(13)可知,可通过下式完成对偏差函数W的更新

(14)
通过确定云计算下小样本数据库间差异数据点以及偏差函数,可实现对差异数据的检测,在此基础上,可实现对小样本数据库间差异的消除。同时为了最大程度减少样本自身信息干扰,需要利用种群算法对不同样本对象进行多次迭代操作,帮助所设计的方法在最真实环境下获得最优结果,因此,需要进行个体选择。当子代中大多数个体的适应度不如父代时,用父代中最好的个体代替子代中最差的个体,这样可以保证消除结果的收敛性[12]。
为了建立一个稳定的差异数据选择、消除过程,防止超级个体在种群中过大,需根据个体适应度的顺序确定选择概率,使个体选择在个体间适应度差距较小时也能够顺利完成。具体过程如下:
第一步:计算组内所有个体的适应度值ηn,同时按降序排列,数n代表个体;


(15)
结合式(15),利用差异备份来对差异数据备份文件和差异指示文件进行保存,并完成消除。
差异数据备份文件用G
4 实验结果与分析
为验证本研究设计的云计算下小样本数据库间差异消除方法的有效性,设计如下仿真加以验证。
实验通过2000行以上的C++代码构建差异数据消除引擎模块,并为单机服务器配置2.53GHz英特尔酷睿2双核处理器,存储池采用4TB内存容量,250GB SAS硬盘,通过千兆以太网(西部数字160gbwd1600 aajsata)和1个固态硬盘(金斯敦64gbssd-nov100series 2.5〃sataii)RAID 0磁盘阵列系统连接一个硬盘和两个硬盘。为了避免本次实验结果过于单一、缺乏对比性,将文献[3]中的基于兴趣度度量的多类差异数据挖掘提出方法和文献[4]中的基于B样条曲线的异常数据剔除方法作为对比方法,使用本文方法、文献[3]方法和文献[4]方法对实验环境中的差异数据进行消除。继而检验不同方法的应用性能。
为了增强实验的有效性,根据数据的不同性质将其划分为DOC数据、TXT数据、PPT数据、VMDK数据、EXE数据、PDF数据六种,在此基础上,测试本文方法的消除效果,结果如图2所示。图2中,左纵坐标代表不同性质文件数据的大小,水平横坐标代表六种不同属性的数据,右纵坐标代表差异数据消除率的大小。

图2 差异消除效果对比图
分析图2可知,仅仅在处理DOC文件时,本文方法对差异数据的去除率略小于90%,在处理其余5种类型数据时,本文方法对差异数据的去除率均在90%以上。证明本文方法能够有效去除差异数据,缩小数据量,具有较高的差异去除率。
为了进一步突出本文算法的应用优势,将本文方法与文献[3]方法和文献[4]方法对差异数据的消除效果进行比较分析,具体对比结果如图3所示。图3中,纵坐标为对差异复数据消除率,横坐标为六种不同的数据属性。

图3 不同方法的消除效果对比
通过图3能清晰地反映出三种不同方法对差异数据的消除效果。其中,本文方法对差异数据的消除率相对最高。文献[3]方法对差异数据的消除率整体呈上升态势,但总体消除率小于本文方法。文献[4]方法对差异数据的消除率相对最小,始终处于85%以下。由此可知,相比于两种对比方法,本文方法的消除效果更高,能够有效去除小样本数据库中的差异数据,具有高效性和广泛应用性。
5 结束语
本文提出了一种云计算下小样本数据库间差异消除方法,并利用六种不同属性的数据设计对比实验,检测小样本数据库间差异数据消除率,从而验证了本文方法的高效性。
在研究中,为提高对差异数据的消除速度,需将源数据节点上的数据集成到同一个目标节点上,不同来源的集成数据需保持同步,且数据长度要尽可能短,从而减少传输带宽的影响。
在接下来的研究中,将着重于去除数据库内的冗余数据,进一步提高云计算数据库数据质量。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
商界评论(2022年1期)2022-04-13
现代电子技术(2022年4期)2022-02-21
智能计算机与应用(2021年4期)2021-06-05
数学大王·趣味逻辑(2019年10期)2019-11-06
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
领导决策信息(2018年16期)2018-09-27
草原(2018年2期)2018-03-02
数学学习与研究(2017年3期)2017-03-09
计算技术与自动化(2014年1期)2014-12-12
