
一种改进的字符串匹配模型研究
2022-04-19 00:46焦文欢冯兴杰
计算机仿真 2022年3期
焦文欢,冯兴杰
(中国民航大学信息网络中心,天津 300300)
1 引言
随着云计算、物联网、社交网络等信息技术的迅猛发展以及智能终端、可穿戴设备等电子产品的大量涌现,人类社会的数据种类和规模正以前所未有的速度增长,全球已经进入大数据时代。越来越多的行业需要从海量数据中挖掘蕴藏的内在联系,并通过大数据分析加以利用。如何髙效地实现针对大数据信息的检测分析,成为网络安全、网络搜索引擎、计算生物学、人工智能等领域的关键问题[1-3]。字符串模式匹配技术作为大数据分析的基础和核心,在计算机病毒特征码匹配、文本检索、语音识别和DNA检测等领域被广泛应用,而高效的字符串匹配算法将大大提高大数据分析的效率[4,5]。
2 概述
字符串模式匹配定义为:假设一组特定的字符集合P,对于任意的目标文本串T,找出模式串P在文本串T中所有出现的位置。所有字符来自一个有限的字母表(或字符集)[6]。如果模式串匹配次数为0,则匹配失败;若模式串匹配次数大于或等于1,则匹配成功。模式匹配按功能分类有精确模式匹配、近似模式匹配和正则表达式匹配三种;按照匹配数目分为单模式匹配和多模式匹配[7]。本文主要研究基于单模式匹配和精确模式匹配的字符串匹配技术。
常用的模式匹配算法主要包括:KMP、Boyer-Moore、BMF、Quick Search、TurnedBM等[8-11]。其中,文献[12]对BM算法进行了改进,选取模式串末尾位置对应文本串中的下一个和再下一个字符作为组合字符组,并计算该字符组在模式串中出现的位置,增大失配时模式串向右移动的最大距离;文献[13]提出一种对模式串进行分组预处理并使用字符组计算跳跃集的分组QS算法,给出坏字符组启发规则与最佳分组长度的计算方法。
字符串匹配算法的改进思想主要归纳为两点:①减少模式串与文本串字符比较的次数;②增大模式串移动的最大距离。为满足上述条件,只有保证模式串每次移动的距离为最大安全距离,才能有效实现降低字符比较次数、增大移动距离的目的,进而提高算法执行效率。为此,在分析掌握字符串匹配算法思想及改进思路的前提下,本文提出一种改进的字符串匹配模型,确保模式串每次移动的距离为最大安全距离,并进行分组对比实验和字符串匹配性能分析。
3 相关算法
大多数字符串匹配算法都有两个阶段,即预处理和搜索阶段。预处理阶段通过预处理模式串字符以确定模式串移动距离,搜索阶段使用信息对比查找文本串中出现的匹配模式。
Boyer-Moore算法
Boyer-Moore(BM)算法是字符串模式匹配最流行的算法之一。BM算法基于三种思想,即从右到左字符比较法、坏字符启发式和好后缀启发式。从右到左字符比较思想主要用来收集有关字符的详细信息,并且在搜索阶段使用这些信息;坏字符启发式思想则通过文本串中导致文本串与模式串不匹配的字符调整模式串移动距离;好后缀启发式思想根据模式串和文本串相似的后缀,使用好的后缀启发式将模式串移动到文本的右侧。由于BM算法在许多应用中的有效性,从原始BM算法中衍生出许多算法,以适应多种用途。Boyer-Moore子组算法主要有:Turbo BM、Apostolico Giancarlo、Reverse Colussi、Horspool、Quick Search(QS)、Raita、Tuned BM、Zhu-Takaoka、Fast Search和Ssabs等算法[14]。
Tuned BM算法
Tuned BM(TBM)算法是Boyer-Moore算法的改进,但它执行更容易、更快、实现简单。算法在模式串与文本串的匹配操作中使用坏字符移位功能,并且字符比较过程按任意顺序进行。在文本串T中匹配P[m-1](即模式串P的最后一个字符),若匹配失败,则模式串根据bmBc数组继续向前移动,直到匹配相同字符;在此情况下,比较模式串和目标文本串其它字符是否匹配,若匹配失败,则将模式串向前移动固定距离constShift=bmBc[P[m-1]];然后比较字符P[m-1]和T[constShift+m-1]是否相等,如果相等,比较模式串和目标文本串是否相同,否则,继续移动模式串到文本串中下一个与P[m-1]字符相同的位置[15]。
Tuned BM算法移动距离计算如下

(1)
Zhu-Takaoka算法
BM算法的另一个改进是Zhu-Takaoka(ZT)算法,其中差异表现在坏字符规则的确定阶段[16]。在BM算法中,坏字符仅由一维数组组成,而在ZT算法中,坏字符被修改为二维数组,模式串根据文本串窗口最右边的两个连续字符进行移位。ZT算法的字符比较从右到左进行,当匹配或不匹配发生时,它要么使用好后缀移位,要么使用坏字符移位,选取好后缀移位数组bmGs和坏字符移位数组ztBc中最大值作为模式串移动距离[14]。
Zhu-Takaoka算法移动距离计算如下
skip2Zhu-Takaoka(y)=
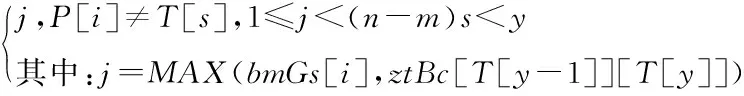
(2)
在Boyer-Moore子组算法中,根据最小尝试移动次数和字符比较次数原则,最有效的算法是ZT算法和TBM算法。然而,TBM算法在模式串不匹配的情况下,移位距离取决于预处理阶段获得的固定移位值,此固定移位值在文本窗口到达结尾之前不会更改,而且TBM算法在DNA数据的长模式串匹配中消耗更多的时间。ZT算法在模式串不匹配的情况下,移位距离值取决于好坏字符表,采用好坏字符数组中较大值作为移位距离,但是ZT算法在短模式串匹配中消耗更多运行时间[14]。
为了克服ZT和TBM算法的局限性和矛盾性,本文提出一种改进的字符串匹配模型。即充分利用ZT和TBM算法正特征的显著优势,排除它们的负属性,克服它们的性能弱点,保证在模式串满足最大安全移动距离的前提下,实现减少字符比较次数和增大模式串移动距离的目的,从而为面向大数据分析提供更加高效的字符串匹配模型。
4 改进模型
改进的字符串模型分为预处理和搜索两个阶段。在预处理阶段,选择preBmBc函数和preZtBc函数对模式串字符进行预处理;在搜索阶段,根据bmBc数组和ztBc数组分别计算模式串总移动步长,采用较大值作为模式串进行下次比较的移动距离。
改进模型最大安全移动距离计算如下

(3)
预处理阶段描述如下:
步骤1:使用preBmBc函数预处理模式串P计算bmBc[ASIZE],其中constShift=bmBc[x[m-1]],然后将bmBc[x[m-1]]赋值为0。
步骤2:使用preZtBc函数预处理模式串P计算ztBc[ASIZE][ASIZE],ztBc为二维数组,ASIZE为字符集合总数。
搜索阶段描述如下:
步骤1:从文本串T和模式串P的起始位置对齐,模式串移动当前总长度为shiftNum;
步骤2:判断P[T[m-1+shiftNum]]值是否为0,如果为0,模式串按照从左到右的顺序比较其它字符,转到步骤5;
步骤3:如果T[m-1+shiftNum]和P[m-1]不相等或者字符串匹配失败,根据bmBc[ASIZE]数组查找下一个P[m-1]的位置,并记录移动总距离shiftTemp。
步骤4:比较shiftTemp和ztBc[T[m-2+shiftNum]][T[m-1+shiftNum]],选取最大值作为模式串移动的最大安全距离,即shift=MAX(shiftTemp, ztBc[T[m-2+shiftNum]][T[m-1+shiftNum]]),同时shiftNum+=shift;转到步骤2。
步骤5:比较模式串除P[m-1]字符以外的其它字符是否和文本串中字符匹配,如果全部匹配,则字符串匹配成功;否则,转到步骤3.
改进模型的实现代码如下:
Void Improved(char *x, int m, char *y, int n)
{
/* Preprocessing */
preBmBc(x, m, bmBc);
preZtBc(x, m, ztBc);
/* Searching */
j=0; ∥ shiftNum
while (j < (n-m)) {
k=bmBc[y[j+m-1]];
i=0; ∥ shiftTemp
if(k==0){
if (memcmp(x, y+j, m-1)==0)
OUTPUT(j);
i+=constShift;
k=bmBc[y[j+m-1+i]];
}
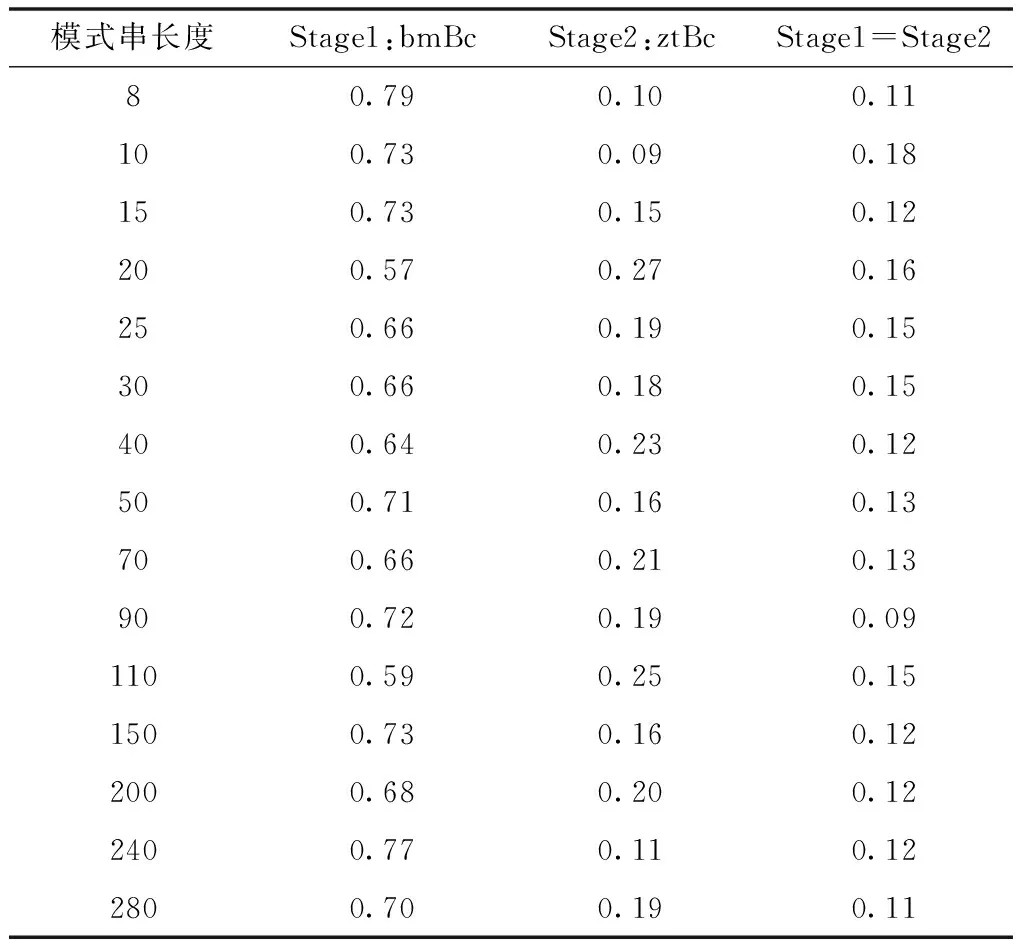
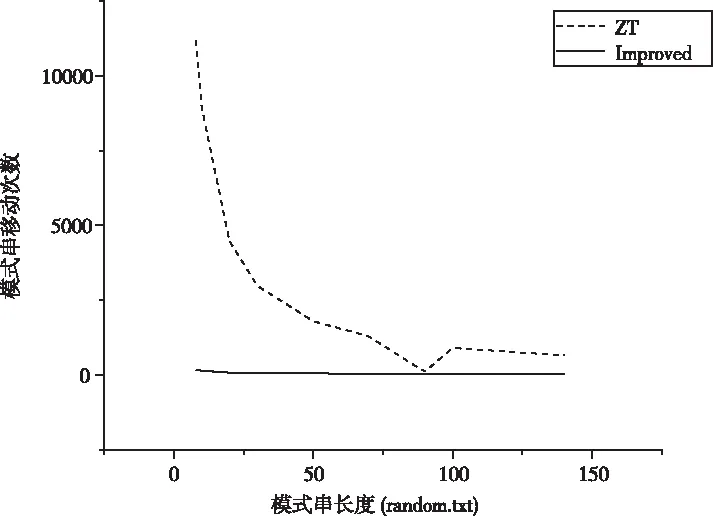
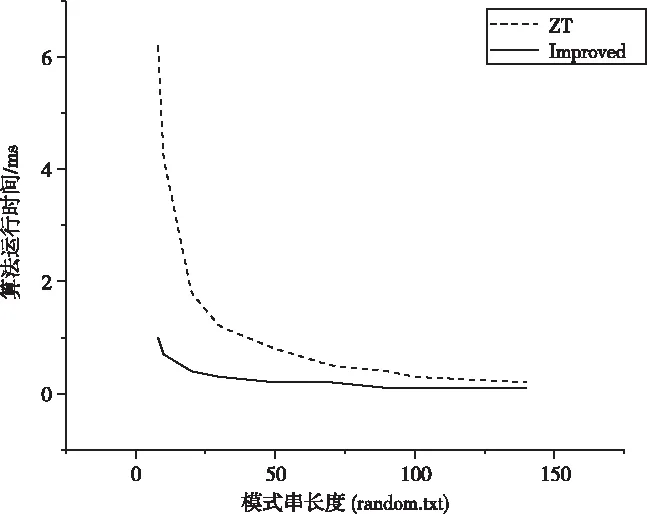
while ((k !=0)&&(j+i i+=k; k=bmBc[y[j+i+m-1]]; i+=k; k=bmBc[y[j+i+m-1]]; i+=k; k=bmBc[y[j+i+m-1]]; } j+=MAX(i, ztBc[T[m-2+j]][T[m-1+j]]);∥shift } } 实验目的:通过对改进模型进行数据分析和实验,验证改进模型在字符集环境下可以有效减少字符比较次数和增大模式串移动距离,在不增加算法时间复杂度的情况下,尽量保证模式串每次移动都能获取最大安全移动距离,提高字符串模式匹配的稳定性和准确性。 实验环境:改进模型采用Visual C#实现,运行于3.4GHz双核Intel CPU和操作系统为Windows Server 2019 64位的工作站上。 实验数据:采用Corpus 数据集[17]中不同数据类型文件分别进行实验分析:实验A采用基因组数据对模型进行实验分析;实验B采用随机字符集和a字符集数据文件对比测试改进模型在无规则数据集和单个字符集中的匹配效率。 实验A:本组实验选取基因序列文件E.coli中前700000个字符作为文本串序列进行实验分析,模式串长度在8-140之间。采用改进模型和QS、TBM、ZT算法进行分组对比实验,从模式串移动次数和字符比较次数两方面进行对比分析。 图1 E.coli数据集模式串移动次数 如上图所示,在相同文本串和模式串长度情况下,改进模型中模式串移动次数最少,模式串移动次数的变化趋势符合改进算法的预期效果。由于改进模型对TBM算法模式串移动距离的计算进行了优化,摒弃了TBM算法的模式串移动固定步长值,采用不断查找bmBc[T[x]]=0的条件累加步长,因此改进模型在执行初期保持了较少的模式串移动次数。 图2 E.coli数据集字符比较次数 从上图可以看出,改进模型前期表现出TBM算法在短模式串下字符匹配的算法优势,后期表现出ZT算法在长模式串下字符匹配的算法优势。由于改进模型大幅度减少模式串移动次数,间接促使匹配过程中字符比较次数的减少。改进模型采用从左到右的顺序依次比较除模式串最后一个字符以外的字符是否相等,同时,只有在模式串最后一个字符匹配时才进行其它字符的比较。在充分利用较少模式串移动次数的同时,进一步从字符尝试比较的条件上进行判断,尽量减少无效的字符比较次数。 下表展示的是改进模型在字符串匹配过程中计算最大安全移动距离的两个阶段值占比。从表中可以看出,改进的bmBc数组摒弃了固定步长的移动方式,通过累加步长的方法提高了命中最大安全移动距离的概率,在不同长度模式串的应用场景下其命中概率都在60%及以上;而bmBc数组的不足被ztBc数组以20%的概率加以弥补,表现为在长短模式串场景下,改进模型都保持了良好的匹配效果。 表1 改进模型最大安全移动距离占比 实验B:本节实验选取随机字符文本文件random.txt中前90000个字符作为文本串序列进行实验分析,对比算法选取ZT算法和改进模型两种。模式串移动次数、字符比较次数结果如图3和图4所示。 图3 random数据集模式串移动次数 图4 random数据集字符比较次数 从上图可以看出,ZT算法在短模式串场景中效果较差,但是随着模式串长度的增大,其模式串移动次数和字符比较次数骤减,算法的优越性迅速体现;而改进模型采用计算最大安全移动距离的方法,不仅在长模式串匹配中保持较好运行效果,而且在短模式串匹配中也保持了稳定的匹配效率。 本节实验选取a字符文本文件aaa.txt作为文本串序列,以aabbaa作为特殊模式串进行实验分析。aaa.txt文件内容为单个a字符集合,对比算法选取TBM算法和改进模型两种。模式串移动次数、字符比较次数结果如表2所示。 表2 a字符集实验结果 从上表可以看出,在aaa.txt文件中TBM算法陷入字符串匹配最坏情况。由于文本串是单个a字符集合,模式串是aabbaa,TBM算法的移动距离一直是1,而且模式串每次移动时,字符从左到右比较次数都为3,算法执行效果较差;改进模型引入preZtBc函数,通过二维数据计算出ztBc[a][a]=4为最大安全移动距离,从而避免算法在单字符集文本串中陷入匹配最坏情况。 TBM算法字符串预处理时间复杂度为O(m+σ),搜索阶段最坏情况下时间复杂度为O(σ2)[15];在ZT算法中,预处理阶段的时间复杂度为O(m+σ2),搜索阶段的时间复杂度为O(mn)[18];改进模型预处理阶段时间复杂度为O(m+σ2),搜索阶段时间复杂度O(mn)。 对比模型在三个数据集上的运行时间如图6所示。 图5 E.coli数据集算法运行时间 图6 random数据集算法运行时间 表3 a字符集算法运行时间 对以上图表进行分析,可以得出在E.coli数据集中改进模型的执行时间一直在TBM算法和ZT算法的时间范围内波动,在保持较少模式串移动次数和字符比较次数的同时,基本保证了算法执行时间的合理性;而在random.txt和aaa.txt文件中,改进模型的时间优势较为明显,且避免在搜索阶段陷入最坏时间复杂度的情况,在数据集合的文本串中一直保持较快的匹配速度,为改进模型在大数据匹配分析中的应用提供了稳定、高效的匹配模型。 改进模型对现有两种算法TBM和ZT进行分析和改进,从两种原始模型中提取出良好特性。模型通过使用preBmBc函数和preZtBc函数预处理模式串从而计算最大安全移动距离,摒弃了TBM算法的固定移动距离机制,尽量保证模型搜索匹配过程中模式串每次都能移动最大安全距离,减少字符比较次数和模式串移动次数,实验表明其在短模式串和长模式串匹配过程中表现良好。 在更高阶段的研究中,将通过对模型进行算法优化和部署高性能计算环境等措施减少其运行时间,从而应用于更快速的流式大数据匹配分析。5 实验分析






6 总结
猜你喜欢
农业工程学报(2022年6期)2022-06-27
健康体检与管理(2022年4期)2022-05-13
化工进展(2022年3期)2022-04-12
电脑报(2021年41期)2021-11-04
建材发展导向(2021年23期)2021-03-08
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
数字技术与应用(2017年3期)2017-05-17
科教导刊·电子版(2016年30期)2016-12-26
中国新通信(2016年17期)2016-11-17
