
基于可见光视觉图像的路面裂缝识别深度学习方法述评*
2022-04-21 05:07卢凯良
计算机工程与科学 2022年4期
卢凯良
(江苏自动化研究所,江苏 连云港 222061)
1 引言
结构裂缝(或称裂纹)不可避免地广泛存在于土木建筑、交通运输和工程机械等诸多行业的各类建造物、结构、零部件或制品中。针对工程结构中的裂缝检测或监测技术手段主要有:(1)无损探伤技术[1,2],包括射线探伤(如CT)、超声波探伤(如声发射[3])、电磁涡流探伤、磁粉探伤和渗透探伤等。无损探伤技术适用于表面、近表面和内部裂缝等全场景,测量精度高;但其是一种主动探测技术,需要发射和接收检测物理介质并可能依赖于耦合介质,因此相应的检测设备通常较为复杂,且价格不菲。(2)结构健康监测技术[4],包括基于应力应变信号和基于振动信号等。该技术借助于预先布置的传感器采集并分析时间历程信号,对结构有无裂缝进行识别,因是间接测量方式,对内部裂缝的识别和定位精度尚需提高。(3)非接触式检测技术,包括红外、激光和超声检测[1 - 3]以及基于可见光视觉图像的检测[5 - 18]等。非接触式检测技术与前2类技术相比,无需与被测对象直接接触,具有不受被测对象的材质限制,检测速度快,易于实现全自动检测等优点,不足之处是目前仅用于检测表面裂缝。
基于视觉图像的表面裂缝识别具有非接触式检测的全部优点,物理介质是可见光,无需发射或能见度差时只需补光光源,整个检测系统成本优势明显。借助于传统手工设计特征工程(Hand- crafted Feature Engineering)、机器学习(Machine Learning)和深度学习(Deep Learning)方法,基于图像的识别技术可以实现裂缝定性、定位、定量各个层次的目标:(1)判断有无裂缝,可视为分类(Classification)问题;(2)探测裂缝的位置,可视为检测/定位(Detection/Location)问题;(3)检测裂缝的分布、拓扑结构和尺寸,可视为分割(Segmentation)问题,按分割精度可分为区域级/补丁级(region/patch-level)和像素级(pixel-level)。
2 裂缝公开数据集
2.1 概述
本文搜集了土木建筑领域路面裂缝和混凝土裂缝的开源数据集,常见的公开数据集如表1所示。这些数据集中的图像样本均是通过个人相机、移动终端摄像头或车载摄像头采集的,采集成本低。图像数目视数据集的使用目的和需求从数十张到数千张不等,图像分辨率因采集设备而不同,根据后续处理算法的需要可以裁剪为小样本(region/patch),例如图像识别深度学习算法中常用的256×256或227×227;还可以通过数据增强进一步增加样本数。总的来说,相对于ImageNet、Pascal VOC等通用大型数据集而言,本文所搜集的裂缝公开数据集尚属专门应用领域的小型数据集。

Table 1 Common public crack datasets
2.2 典型裂缝公开数据集
2.2.1 JapanRoad
JapanRoad数据集样本是从汽车前挡风玻璃处采集的真实道路街景透视图像,可用于裂缝等8类道路缺陷定位检测[6],包含163 664幅道路图像,其中9 053幅图像含有裂缝,采用与PASCAL VOC相同格式的边框(bounding box)标注。
2.2.2 SDNET2018
SDNET2018是一个带补丁级/区域级标注的图像数据集,可用于混凝土裂缝人工智能检测算法的训练、验证和测试。
原始图像是利用16 MP Nikon数码相机拍摄的,包括230幅开裂和未开裂混凝土表面图像(54座桥面、72面墙壁和104条人行道,均位于犹他州立大学校园内)。
每幅图像再被裁剪分割为256×256像素的子图像样本,共计包含超过56 000个样本,样本中包含的裂缝窄至0.06 mm,宽至25 mm。数据集还包括带有各种障碍和干扰(阴影、表面粗糙度、缩放、边缘、孔洞和背景碎片等)的图像样本,详见表2和表3。
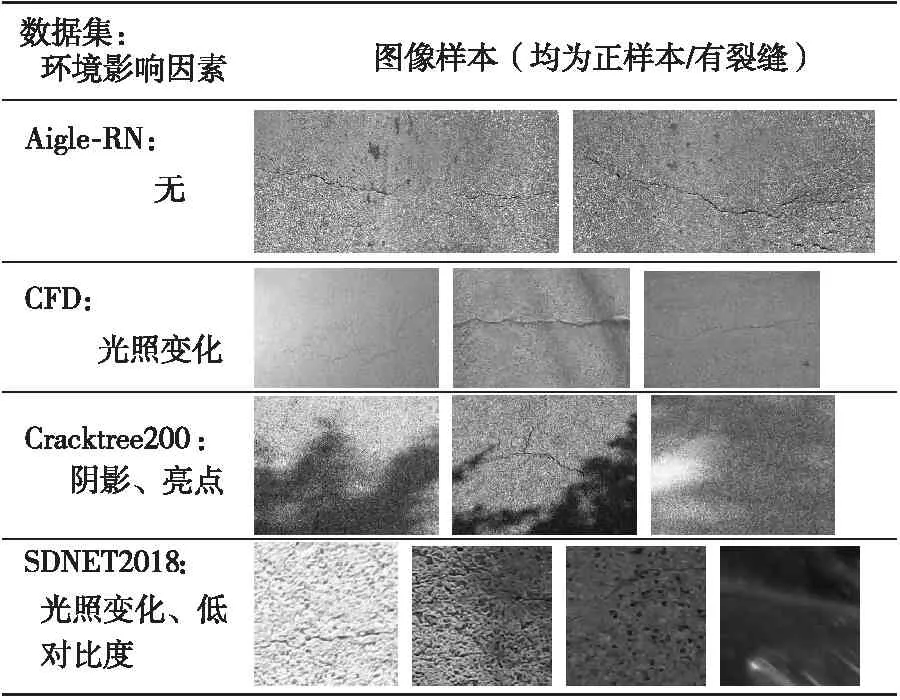
Table 2 Environmental factors in crack datasets
2.2.3 CFD
CFD是反映北京城市路面总体状况的像素级标注的路面裂缝数据集,是常用基准数据集之一。使用手机(iPhone 5)拍摄采集,共包括480×320分辨率的图像样本118个,样本中包含车道线、阴影和油渍等噪声或干扰因素。
2.3 数据集图像样本中的随机可变影响因素
数据集中涉及的随机可变影响因素越多,包含的高级特征越丰富,则经过该数据集训练和验证的学习模型在真实测试场景中的泛化能力越强。这些随机可变影响因素主要包括图像背景、环境影响以及其他干扰因素,并且在图像样本中这些因素通常组合叠加呈现。为了清晰展现,表3中所展示的一组(一行)图像样本尽可能体现单一因素。
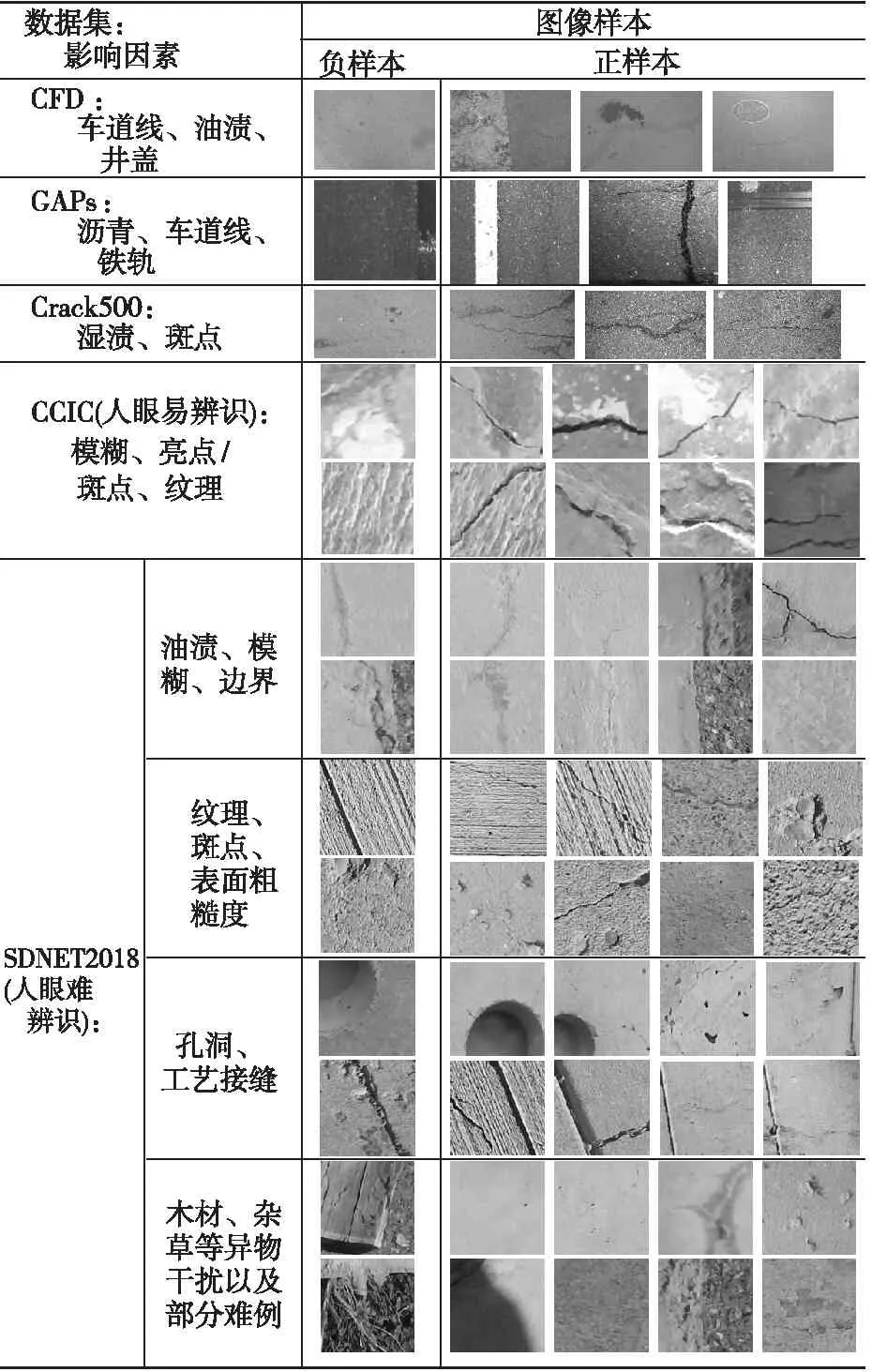
Table 3 Noise interference factors in crack datasets
2.3.1 背景
JapanRoad数据集中的图像背景包括汽车、房屋、天空、行人、绿化带、车道线和电线杆等。CFD数据集中也有少量图像样本具有街道实景背景。还有一类干扰背景如油渍、轮胎制动痕迹和斑点等。
2.3.2 环境影响
环境影响主要指由天气、光照变化引起的亮度变化、阴影、亮点和低对比度等。作为对比,表2列出了不受环境影响的Aigle-RN数据集中的部分样本(因其裂缝纹理特征较复杂,为减少不均匀照明专门进行了预处理)。
2.3.3 干扰因素
除了背景和环境影响,可变影响因素还包括车道线、油渍/沥青/湿渍/斑点、井盖、轮胎制动痕迹、纹理差异、表面粗糙度、边界、孔洞以及其他杂物等噪声干扰因素,如表3所示。
3 裂缝识别算法比较
裂缝识别方法可分为传统手工设计特征工程、机器学习和深度学习3种,各方法中的常见算法及其特点如表4所示。
3.1 传统手工设计特征工程
传统手工设计特征工程通常使用边缘或形态特征检测算法和特征变换(或滤波)算法。边缘或形态特征检测算法包括Canny[7,8]、Sobel[14]、方向梯度直方图HOG(Histogram of Oriented Gradient)和局部二值模式LBP(Local Binary Pattern)等。特征变换(或滤波)算法包括快速傅里叶变换FFT(Fast Fourier Transform)、快速哈尔变换FHT(Fast Haar Transform)、Gabor滤波器和亮度阈值[8]等。
这些算法借助数学计算方式逐步提取或解析出图像中对象的边缘和形态等特征,属于非学习方法,不依赖于数据集;而且所用数学计算多为解析式,一般来说算法的计算量小、速度快。缺点是对随机可变因素的泛化能力弱,且易受这些因素的干扰,自适应能力弱,应用场景或环境一旦改变就需调参、重新设计算法甚至方法失效。
3.2 机器学习方法
机器学习和深度学习均为学习类算法,依赖于数据集。不同的是,机器学习方法的数学表达是显式的、可解释的,而深度学习是隐式的。一般认为,深度学习(神经网络的深度或层级更深)面向高维特征,机器学习面向低维特征;机器学习介于传统手工设计特征工程和深度学习方法之间。
基于常见的机器学习方法例如支持向量机SVM(Support Vector Machine)[7]、决策树(Decision Tree)和随机森林(Random Forrest),相应的裂缝识别算法主要有CrackIT、CrackTree和CrackForest[8,10,14 - 17]等。
3.3 深度学习方法
深度学习方法的使用得益于并行计算硬件(GPU/、TPU/等)的飞跃、大规模数据集(ImageNet、Pascal VOC等)的基准催化作用和算法的不断改进和完善。例如,批标准化(Batch Normalization)、残差连接(Residual Connection)和深度可分离卷积(Depth Separable Convolution)是从2012年起开始声名卓著的。虽然深度学习方法尚存在“黑箱”和解释性问题,不可否认其在计算机视觉、自然语言处理和强化学习等领域取得的最新进展甚至超越人类水平的成绩。目前科学家们正在理论攻关[18],工程师们也通过可视化技术不断提升深度学习过程的可解释性[19]。
卷积神经网络CNN(Convolutional Neural Network)因其能学到的模式具有平移不变性(translation invariant)并且可以学到模式的空间层次结构(spatial hierarchies),自2012年始在计算机视觉识别等领域不断取得突破性进展。基于CNN的图像识别深度学习方法具有特征自动提取、泛化能力强和精度高等优点。按深度学习方法的不同范式,各类算法又可分为自搭架构、迁移学习、编码-解码器、生成对抗网络及其他算法。

Table 4 Typical crack identification algorithms and their characteristics
自搭架构是依据CNN的一般设计原则,针对应用场景的特定数据集来设计和搭建的模型架构,如早期的ConvNet[7]、Structured-Prediction CNN[8]和近期的CrackNet/CrackNet-V[9,10]。这类算法具有对特定应用场景适应性好、模型小和参数少等优点,但泛化能力一般,且模型往往未经优化。

Figure 1 Illustration of ConvNet architecture [7]
迁移学习是利用在大规模通用数据集上预训练的模型架构优化过的CNN主干网络(backbone)学习到可移植的底层特征,再在专门数据集上微调高层和/或输出层的神经网络连接权重,以期学习到面向专门数据集的高维特征。迁移学习适用小型数据集问题,训练快、易调整、泛化好。
编码-解码器由编码器和解码器组成。在CNN中,编码器用于产生具有语义信息的特征图;解码器将编码器输出的低分辨率特征图像映射回原始输入图像尺寸,从而可以逐个像素分类。编码-解码器适用于弱监督和小型数据集情形,其代表模型FPCNet(Fast Pavement Crack detection Network)[15]精度和速度俱佳。
生成对抗网络利用2个网络(判别网络和生成网络)对抗训练,使生成网络产生的样本服从真实数据分布。ConnCrack(combining cWGAN & connectivity maps)[14]和CrackGAN(pavement Crack detection using partially accurate ground truths based on GAN)[16]是裂缝识别的代表性模型。生成对抗网络识别精度高,还可用于难例挖掘。早期版本训练和预测时间较长[14],改进的CrackGAN[16]在前期GAN算法基础上,提出了仅基于裂缝补丁样本CPO(Crack-Patch-Only)的监督对抗学习和非对称U-Net网络架构,可在人工半精确标注(1像素曲线标注)样本上进行端到端训练,并在全尺寸图像上进行裂缝分割预测;还引入了迁移学习算法训练编码器原型网络,以及从预先训练的深度卷积生成对抗网络中迁移知识,以提供端到端训练中所产生的对抗性损失。CrackGAN[16]率先解决了裂缝和背景样本数严重不平衡引发的“全黑”问题,计算效率大幅提升,减轻了标注工作量。
其他算法还包括FPHBN(Feature Pyramid and Hierarchical Boosting Network)[17],该算法融合了特征金字塔和分层增强等技术,模型架构与FPCNet[15]的类似。
4 裂缝识别深度学习方法进展
4.1 自搭架构
4.1.1 ConvNet
(1)数据集。
所用数据集包含500幅分辨率为3 264×2 448的原始图像,裁剪生成包含640 000个样本的训练集、包含160 000个样本的验证集、包含200 000个样本的测试集,样本分辨率均为99×99,标注精度为补丁级。数据集未公开。
(2)网络架构。
网络架构比较简单,包括4个卷积conv(convolution)层(4×4,5×5,3×3,4×4)和2个全连接层fc(fully connection),每个卷积层后都有最大池化层mp(max pooling),如图1所示。
(3) 性能衡量指标。
样本测试的准确度度量指标主要有:
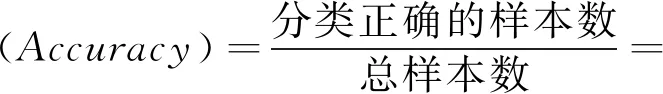
(1)

(2)

(3)
(4)
其中,TP(True Positive)表示真阳例的数量,TN(True Negative)表示真阴例的数量,FP(False Positive)表示假阳例的数量,FN(False Negative)表示假阴例的数量,Total=TP+FN+FP+TN为总样本数。由式(4)可知,F1-score是Precision和Recall的加权调和平均数。

Figure 3 Architecture of Structured-Prediction CNN[8]
(4) 性能与效果。
ConvNet[7]的测试精确率、召回率和F1-score分数分别为0.869 6,0.925 1和0.896 5,均高于SVM和提升(Boosting)算法的,测试效果对比如图2所示。无论在准确度度量指标还是在识别效果上,ConvNet[7]都明显优于传统机器学习方法。由于属早期探索性研究,ConvNet[7]只关注了测试准确度,还未涉及测试速度。
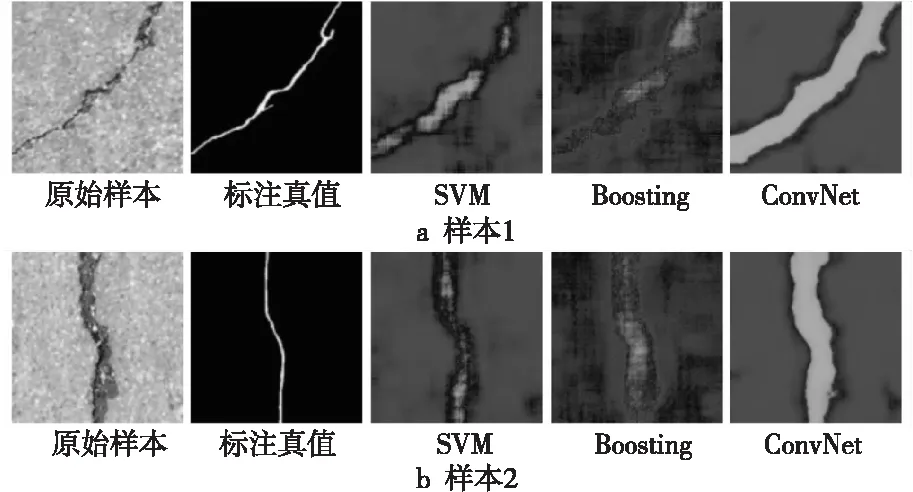
Figure 2 Test performance of two samples[7]
4.1.2 Structured-Prediction CNN
(1)数据集。
Structured-Prediction CNN[8]同时关注了测试准确度和速度,为了形成基准比较,在数据集Aigle-RN上进行了测试,还专门构建了CFD数据集。
(2) 网络架构。
如图3所示,输入样本为3通道的27×27的彩色图像,其他立方体块表示通过卷积或最大池化运算得到的特征图,最后连接2个全连接层和1个输出层。
(3) 性能表现。
在准确度上,表5和表6中的结果再次印证了深度学习CNN方法总体上比机器学习(如CrackForest)表现更优,且远好于传统手工设计特征工程方法(如Canny,Local thresholding)。
在预测速度上,原始图片在NVIDIA GTX 1080Ti GPU上可达到2.6 fps。
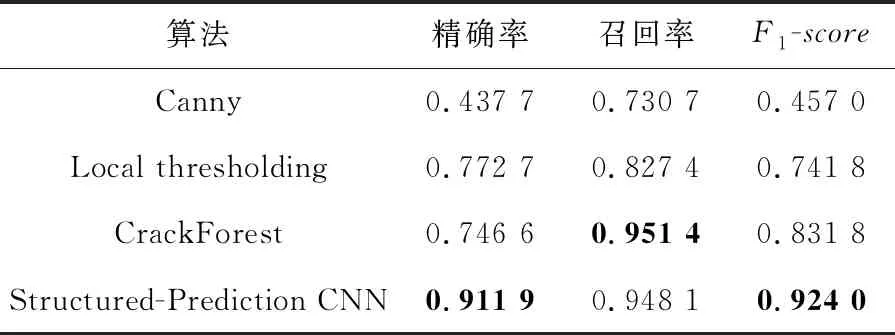
Table 5 Crack detection results of different methods on CFD

Table 6 Crack detection results of different methods on Aigle-RN
(4) 检测效果。
Structured-Prediction CNN[8]采用了27×27的小尺寸输入,且CFD和Aigle-RN均对裂缝进行了像素级标注(2个像素误差),裂缝检测效果远好于ConvNet[7],已用于鳄鱼皮状裂纹的检测,检测效果如图4所示。

Figure 4 Results comparison on CFD and Aigle-RN[8]
4.1.3 CrackNet/CrackNet-V
(1) 数据集。
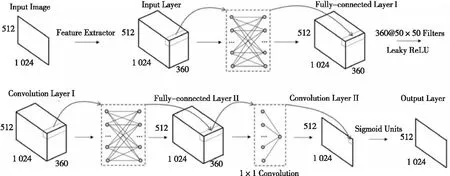
Figure 5 Architecture of CrackNet[9]
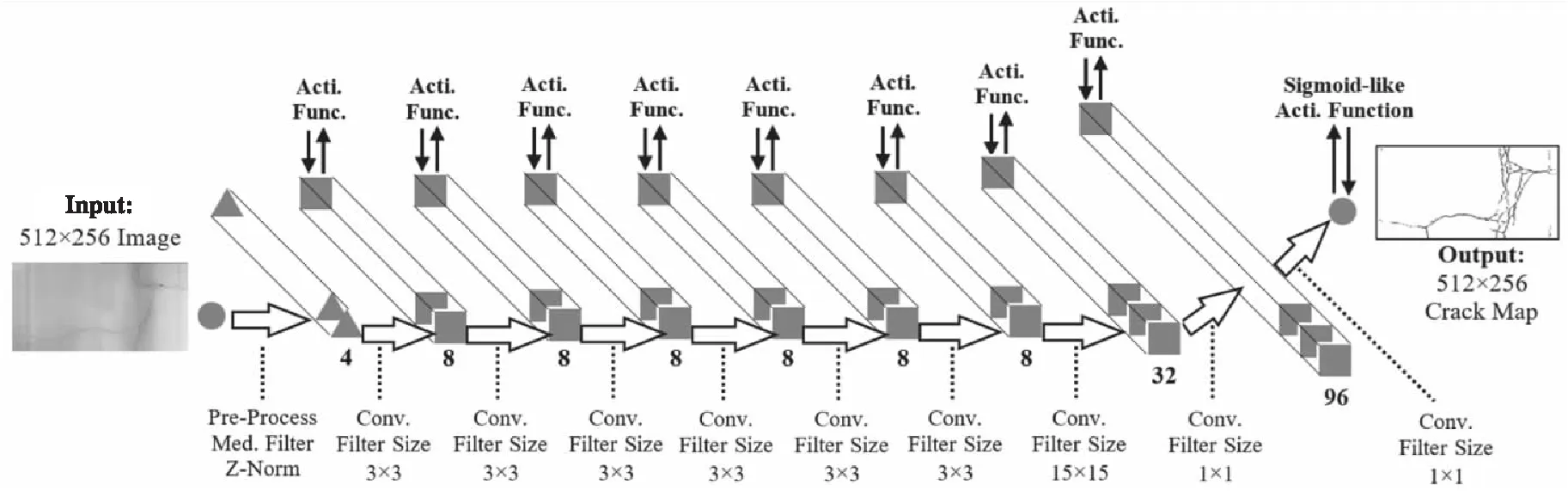
Figure 6 Architecture of CrackNet-V[10]
与之前算法不同的是,CrackNet / CrackNet-V[9,10]使用激光扫描获得的3D沥青路面图像作为输入。相比可见光摄像头采集的图像,激光扫描图像分辨率更高,可过滤部分噪声,相当于做了一次图像预处理,因而图像更加清晰,可以实现像素级裂纹标注和分割。因此,不仅仅是可见光摄像头,激光扫描、红外摄像头甚至声发射等无损穿透式检测或监测传感器采集得到的图像或信号,均可作为深度学习网络的输入,从而不仅可以检测表面裂缝,亦有望探测或监测被测物内部裂缝。
3D沥青路面图像数据集包括训练集的2 568个图像样本、验证集的15个典型图像样本和测试集的500个图像样本。CrackNet[9]输入样本的分辨率为1 024×512,CrackNet-V[10]输入样本的分辨率为512×256。
(2)网络架构。
CrackNet[9]网络架构如图5所示,包括输入层、2个卷积层(卷积核(Filter Size)分别为50×50和1×1)、2个全连接层和输出层;卷积层激活函数(Activation Function)为Leaky ReLU,输出层为Sigmoid,共计1 159 561个参数。
CrackNet-V[10]网络架构如图6所示,增加了预处理(Pre-Process)层,包括中值滤波(Med-Filter)和Z标准化(Z-Norm)。总体上借鉴了VGG模型架构,大量采用3×3卷积,增加了1个15×15卷积层和2个1×1卷积层,比CrackNet[9]的层数更深,由于没有全连接层且卷积核更小,参数反而更少,模型更轻量化。
CrackNet[9]和CrackNet-V[10]均无池化层,输入和输出图像的分辨率不变,故可用于实现像素级分割。
(3) 性能表现。
对比表7和表8可知,在准确度上,CrackNet-V[10]比CrackNet[9]略高;在运算速度上,无论训练和测试(前馈和反馈运算)时长,前者约为后者的1/4,证实了CrackNet-V[10]的架构更优化。
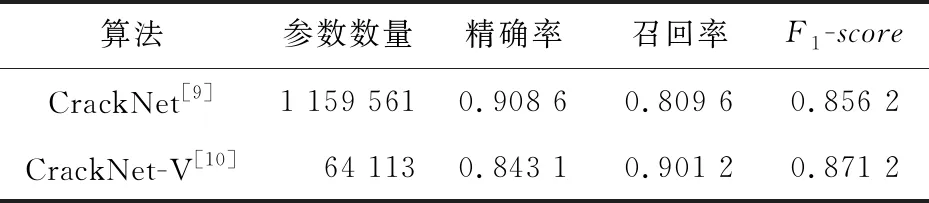
Table 7 Test results comparison between CrackNet and CracNet-V
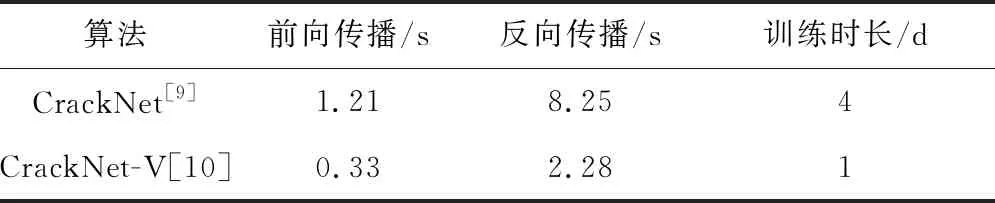
Table 8 Speed comparison between CrackNet and CrackNet-V

Figure 8 Framework and steps of deep(transfer) learning
(4)检测效果。
CrackNet-V[10]对鳄鱼皮状细裂缝的检测效果如图7所示。因为模型架构的特殊优化设计,CrackNet-V[10]可以实现完美像素级裂纹分割;另一方面,检测速度也非常快,在NVIDIAGTX1080TiGPU上测试速度约为0.33s/img,与Structured-PredictionCNN[8]的速度相当。

Figure 7 Crack detection results of CrackNet-V[10]
4.2 迁移学习
4.2.1 迁移学习的框架和步骤
学习方法的一般步骤包括训练(Train)、验证(Validation)、测试(Test)和预测(Predict)。图8展示了深度(迁移)学习的框架和步骤。
迁移学习主要包含以下步骤:
(1)在预训练的基础网络上添加自定义的神经网络层。基础网络由主干网络(常见的如VGG-16[11]、VGG-19[14]、Inception-V3[12]、Xception[13]、Resnet152[14]等)及其在大规模数据集上预训练的权重参数值组成。
(2)冻结基础网络。
(3)在专门的数据集(如SDNET2018/CCIC)上训练所添加的自定义顶层。
(4)解冻基础网络中的某些层。
(5)联合训练未冻结的层和所添加的自定义顶层。
步骤(2)~步骤(5)又统称为微调(Fine-tuning)。
最后,如果满足预设目标,就输出新的网络模型和微调后的权重参数值,用于部署并预测待预测的图像样本,输出概率值和类别;如果不满足,可通过增大数据集、重选主干网络和解冻更多层等措施来重新执行迁移学习过程,从而优化神经网络模型和权重参数,直至满足预设目标。
4.2.2 基准测试结果和性能比较
考虑到精度和效率的折衷以及在低算力平台上的测试部署,本文重点选择了InceptionV3和MobileNetV1/V2在CCIC和SDNET2018数据集上进行性能测试,并与相关文献成果进行比较,结果如表9所示。由于表9用于性能比较的参考文献裂缝数据集有些未公开(尽管类似),且计算平台不尽相同,故本表中的性能比较并非完全严格,仅供参考。预测耗时含图像载入、预处理等时间。从表9中可知:
(1) 应用迁移学习法对裂缝图像分类,测试分类精度已超过ImageNet多分类基准线(参见https://github.com/mikelu-shanghai/Typical-CNN-Model-Evolution);在相近的分类比数据集(如CCIC)上,其结果也优于当前已公开发表的成果[11,12,20]。在人眼易辨识的CCIC数据集上,使用轻量级主干网络MobileNetV1迁移学习的精度达到99.8%。
(2)TL-InceptionV3在人眼难辨识的SDNET2018数据集上的测试精度为96.1%,已较为接近FPCNet[15]的最佳水平97.5%(可用更重量级的主干网络进一步提高迁移学习的精度),测试耗时16.1ms,远低于FPCNet的67.9ms(测试平台均为NVIDIAGTX1080TiGPU)。
4.3 编码-解码器(FPCNet)
以上算法存在2点不足之处:
(1)路面裂缝具有不同的宽度和拓扑,但是CNN/FCN方法的过滤器感受野仅使用特定大小的卷积核(kernel)来提取裂缝特征(特别是VGG之后的模型大量采用3×3),限制了其对裂缝检测的鲁棒性。
(2)未考虑裂纹的边缘、模式或纹理特征对检测结果的贡献不同。
编码-解码器模型FPCNet[15]即是针对这2点不足设计的。
(1) 数据集。
FPCNet使用的测试数据集为CFD(样本裁剪为288×288)和G45(样本裁剪为480×480)。
(2) 网络架构。
FPCNet[17]网络架构包括多重膨胀MD(Multi-Dilation)模块和挤压-激发上采样SEU(SqueezingandExcitationUp-sampling)模块。多重膨胀MD模块如图9所示,该模块级联4个膨胀率分别为1,2,3和4的膨胀卷积通道(每通道2次膨胀卷积核操作)、1个全局池化层+1×1卷积+上采样通道和原始的裂缝多层卷积MC(Multiple-Convolution)特征。之后,执行1×1卷积以获得裂缝多层膨胀卷积特征。除了最后的1×1卷积,每个卷积都保留其特征通道的数量,并且使用填充来确保MC特征的分辨率恒定。
SEU模块如图10所示,H、W和C分别表示特征的长度、宽度和通道数。输入的是MD特征和MC特征,输出的是经过加权融合优化后的MD特征。
SEU模块首先通过转置卷积来恢复裂纹MD特征的分辨率,之后将MC特征添加到MD特征中,以便融合边缘、模式和纹理等的相关裂纹信息,接下来执行全局池化以获得C个信道的全局信息。
随后,在经过对全局信息挤压(Squeezing)和激发(Excitation)2个完全连接层后,通过学习获得每个特征在其通道中的权重,从而使得SEU模块可以为不同的裂缝特征(例如边缘、模式和纹理)自适应地分配不同的权重。
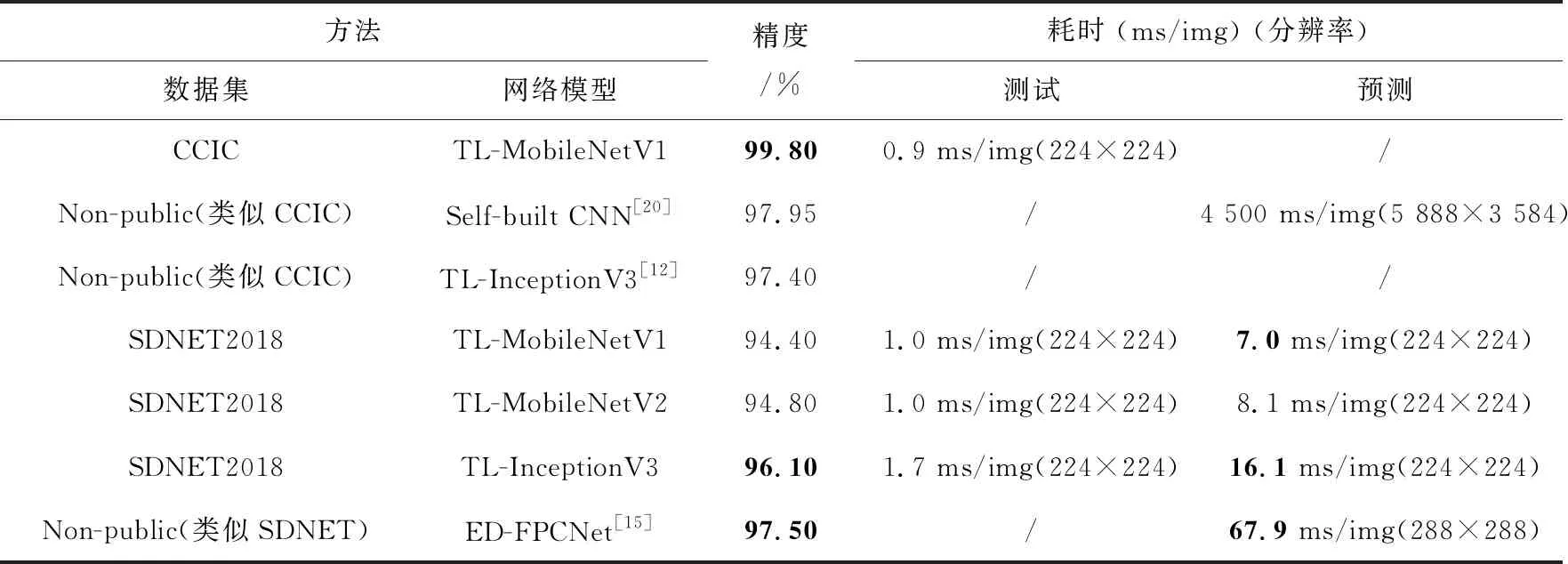
Table 9 Test results and performance comparison of some typical backbone network
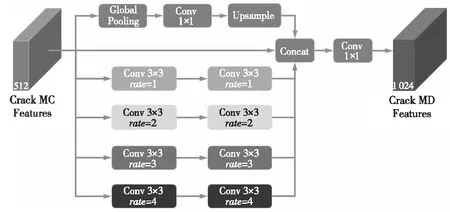
Figure 9 MD module [15]

Figure 10 SEU module[15]
最后,将添加MC后的MD特征中的每个特征与其对应的权重(Fscale)相乘,以获得优化的MD特征。
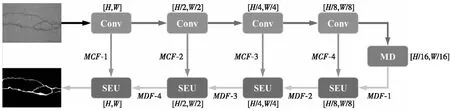
Figure 11 Overall architecture of FPCNet [15]
FPCNet[15]网络的整体架构如图11所示,该网络使用4个卷积层(2个3×3卷积+ReLU)和最大池化作为编码器来提取特征。接下来,使用MD模块来获取多个上下文大小的信息。随后,将4个SEU模块用作解码器。图11中,上排左数第2至第5个箭头表示最大池化;下排右数第1至第4个箭头表示转置卷积,最后1个箭头表示1×1卷积+Sigmoid;MCF表示在编码器中提取的MC特征,MDF表示MD特征。
(3)性能表现。
在CFD数据集上的裂缝检测结果如表10所示,FPCNet[15]的各项评估指标均优于机器学习、CNN等方法,是目前最新的网络之一。FPCNet[15]的预测速度也较快,在NVIDIA GTX1080Ti GPU上单幅288×288的图像样本预测耗时67.9 ms即14.7 fps,能实现实时检测。

Table 10 Results for crack detection on CFD[15]
(4) 检测效果。
FPCNet[15]与Structured-Prediction CNN[8]等在CFD数据集上的检测效果比较如图12所示,这2个网络以及CrackNet/CrackNet-V[9,10]均能达到像素级精度的裂缝检测(标注精度2个像素误差)要求。FPCNet[15]正如其架构设计初衷,对诸如鳄鱼皮状等各类复杂形态裂缝的边缘、纹理和细部的识别精确度较高。
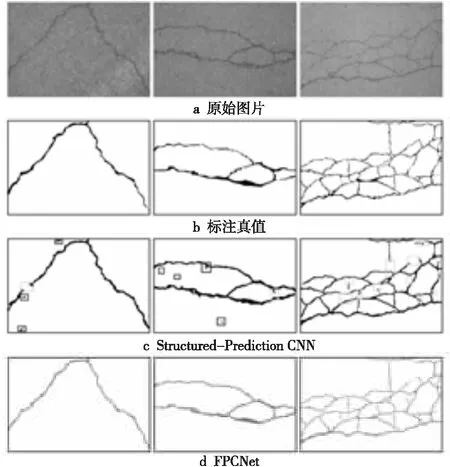
Figure 12 Results comparison of proposed approach with Structured-Prediction CNN on CFD[15]
5 结束语
目前,研究人员已经能够基于单一模型在低算力GPU平台上实现裂缝补丁级实时检测和像素级快速检测。基于InceptionV3的迁移学习和编码-解码器FPCNet对单一测试样本检测总耗时低于100 ms,基于MobileNet更可低于10 ms;在准确度上,在人眼易辨识的CCIC数据集上测试精度可达到99.8%以上;在难辨识的SDNET2018数据集上,迁移学习算法最高接近96.1%。利用集成上述算法的集成方法还可进一步提高测试准确度。
对于工程结构中的裂缝检测或识别问题,相较于无损探伤技术和健康监测技术等接触式检测方式,基于可见光视觉图像的表面裂缝识别非接触式检测方法,可充分发挥其不受被测对象的材质限制、成本低、精度高和易于实现全自动在线检测等优势,因而适用于例行巡检等预防性检测或监测、几何拓扑形式可抽象为2D平面形态的物体缺陷检测等场景。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
石油与天然气地质(2021年3期)2021-06-29
中学生数理化·高一版(2021年2期)2021-03-19
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
领导决策信息(2018年16期)2018-09-27
意林·全彩Color(2018年7期)2018-08-13
北京航空航天大学学报(2018年1期)2018-04-20
数学学习与研究(2017年3期)2017-03-09
海峡姐妹(2016年6期)2016-02-27
