
基于强化学习的立体全景视频自适应流
2022-04-21 02:09兰诚栋饶迎节宋彩霞
电子与信息学报 2022年4期
兰诚栋 饶迎节 宋彩霞 陈 建
①(福州大学物理与信息工程学院 福州 350108)
②(福建省媒体信息智能处理与无线传输重点实验室 福州 350108)
1 引言
虚拟现实技术(Virtual Reality, VR)是一种可以创建和体验虚拟世界的计算机仿真系统。它利用计算机生成一种模拟环境,向使用者提供视觉、听觉、触觉等多种感官刺激,带来一种身临其境的沉浸感受[1]。思科预计到2022年,沉浸式应用所产生的互联网流量将增加20倍[2]。虽然单一的360视频可能是当前VR视频内容中最流行的类型,但它们缺乏3D信息,因此无法以完整的6个自由度(six Degree Of Freedom, 6-DOF)观看[3]。立体全景视频实现在3 DOF 360视频条件下进一步增强沉浸式效果,已经受到人们的关注。
在传统全景视频传输中,由于强化学习方法能够获得长期内的最优决策。利用强化学习进行全景视频的码率选择已经受到大量学者的研究。文献[4]运用强化学习中的异步优势动作评价(Asynchronous Advantage Actor-Critic, A3C)算法通过输入之前时刻带宽、之前时刻预测精度、当前带宽等数据进行视点区域、临近区域、外部区域的码率选择,该算法已成为基于强化学习的全景视频区域码率选择的经典算法。文献[5]同样利用A3C算法进行3个区域的比特流分配。其考虑到为提高视点预测精度,缓存区应该不宜过大。其将缓存区大小也作为奖励函数,鼓励算法偏向适宜的缓存大小来兼顾预测精度和播放卡顿,该算法说明奖励函数的设置对系统工作有重要的影响。
在立体全景视频传输中,文献[6–8]研究了各种量化参数(Quantization Parameter, QP)、不同空间缩放比等情况下的差分平均意见得分(Different Mean Opinion Scores, DMOS)值。其结论不仅说明双目抑制也适用立体全景视频中,也说明当某一视点的空间分辨率在可接受的情况下进行缩放时,其带宽能节省25%~50%。文献[9]将一个视点水平、垂直下采样,并在解码端上采样。而另一视点保持不变,进行非对称传输。上述方法都是固定码率或者下采样进行非对称编码的方法,没有充分考虑网络带宽的实时变化等对用户体验质量(Quality of Experience, QoE)的影响。本文提出一种基于强化学习的立体全景视频自适应流传输方案。通过为一路视点提供基本视频内容信息,另一路视点动态提供辅助立体信息,可以在带宽有限的情况下提供最佳的观看质量[10]。考虑到立体全景视频视点中各瓦片(tiles)的显著性不同,因此左右视点对应瓦片对主观质量的贡献度是不一样的。合理降低每路视点中显著性较低瓦片的码率,提高每路视点中显著性较高瓦片的码率,并利用强化学习合理分配网络带宽数据,依据双目抑制原理,设置合适的奖励函数,从而提高视频整体质量。其具体方法是利用多智能体强化学习对左右视点各瓦片分别进行码率选择,以避免传统强化学习对多个瓦片进行码率选择造成的行动空间爆炸问题。最后,为保证系统的有效性,采用一种分步更新策略来平衡整体奖励和左右视点的局部奖励。
2 基于DASH的立体全景视频自适应流系统
图1展示了基于动态自适应流超文本传输协议(Dynamic Adaptive Streaming over Hypertext transfer protocol, DASH)的立体全景视频自适应流系统框架。DASH技术具有快速的启动时间、较好的用户体验以及较少的缓冲等显著的特点。其较大地缓解了全景视频对网络的高负载,确保了用户的体验质量[11]。由于同一时刻人眼观看的视点区域为视频内容的一部分,因此全景视频通过特定工具,在时间上切割为片段(segments),在空间上切割为瓦片。编码后的瓦片数据集存储在服务器端,服务器端根据客户端反馈的信息进行数据选择和发送。利用HTTP2.0协议,客户端发送一条指令信息能够获取所有要求的瓦片数据。下载后的数据经过解码和缝合,存储在客户端播放缓存中。最后通过头戴设备等播放软件进行渲染和播放。利用从播放设备获取的头部运动数据,通过视点预测,并结合当前带宽数据对视点内和视点外区域瓦片选择不同的码率,可适当降低全景视频传输所要求的带宽需求。合理地为每个瓦片进行码率控制决定着该流传输系统性能的优劣。
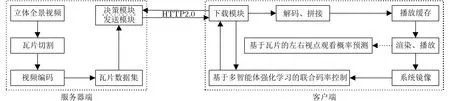
图1 基于DASH的立体全景视频流系统结构图
3 立体全景视频联合码率控制
3.1 基于瓦片的左右观看概率预测方法
在立体视频中,左右两路视频存在一定的视差,对应的瓦片的显著性并不相同,左右视点对于用户的关注度都存在影响。同时,用户的头部运动起着绝对作用。因此,本文提出一种基于瓦片的立体全景视频左右观看概率预测方法。通过分别获取两路视点瓦片的观看概率,并依据双目抑制原理设计合理的奖励函数,从而为左右两路视点各瓦片选择不同的码率。
如图2所示,利用一种节能高效的3维卷积神经网络(Three-Dimension Convolutional Neural Network, 3D-CNN)[12]分别对获取的主视点序列瓦片的静态显著信息、动态显著信息和双目视点的视差信息进行特征提取。同时,利用长短期记忆网络(Long Short-Term Memory, LSTM)在时间序列预测上的较强性能,进行头部运动数据预测。与获取到的显著性数据和视差数据进行拼接融合。最后通过多层全连接层,利用监督学习的方法,分别获取侧重不同信息的左右视点各瓦片的观看概率。某个瓦片的观看概率pi可以简短地表示为
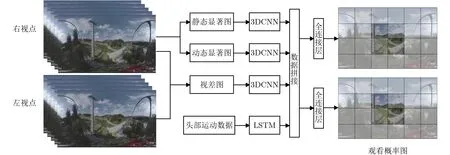
图2 基于tile的视点预测概率模型

3.2 基于多智能体强化学习的联合码率控制模型
假设立体全景视频左右视点分别在时间上分为N个片段,每个片段长度为T,每个片段包含K个瓦片,并且每个片段有Mbit水平。每个片段中每个瓦片所选择的码率为ai,其i ∈{0,M −1}。q(ai)表示码率到感知质量的映射。左右视点每个瓦片的观看概率分别为pLi,pRi。
在单视点情况中,利用强化学习为每个瓦片选择码率,在每一时刻,一共有MK种可能。如此巨大的行动空间在实践中是不可行的。本文利用基于策略-评价(Actor-Critic)[13]的多智能体强化学习,将每个瓦片当成一个智能体,其共享一个状态,进行联合行动。行动空间最终减小为M。其结构如图3(b)所示。
当左右视点都采用多智能体强化学习进行瓦片码率选择时。每个智能体的奖励混杂着单视点中智能体联合行动从环境中获取的局部奖励(如时域光滑度、空域光滑度等),以及左右视点的智能体联合作用时的全局奖励(如缓冲时间等)。混杂局部和全局奖励的奖励函数无法体现奖励函数中各代价函数的贡献,极易造成模型的不稳定,导致每个智能体无法选择最优行动。
针对上述问题,本文采用图3(a)所示的结构,通过引入全局策略进行监督,将全局奖励和局部奖励分开,分别进行优化,从而保证模型的稳定性。
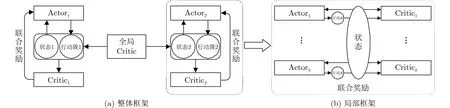
图3 算法结构图
修改后每个智能体的策略梯度为


3.3 奖励函数的设计
奖励函数决定强化学习的学习方向,因此,设计合适的奖励函数,决定系统的工作性能好坏。假设左右视点中每个智能体每个时刻分别共用一个状态,输入状态分别为

变异系数(Coefficient of Variation, CV)可以反映视口空域质量变化大小[4]。左右视点视口中瓦片的视口空域质量变化为



4 实验设计和结果分析
4.1 实验设计
目前尚没有公开的立体全景视频数据集,本文从Youtube网站上分别下载4个分辨率为4K和8K的立体全景视频[16]。利用多媒体视频处理工具FFmpeg对数据集进行空域和时域切片,并依据高效视频编码(High Efficiency Video Coding, HEVC)标准编码。反映用户真实头部运动的数据采用文献[17]中的公开数据集。视点区域大小为水平方向110°,垂直方向90°。投影方式采用常用的等距柱状投影(EquiRectangular Projection, ERP),6×4布局;播放缓冲区大小为3 s。运行环境为Intel Xeon E5-2680 v4 2.40 GHz CPU和2个2080Ti GPU。
当今,5G技术已经已经逐渐在普及完善,利用5G技术传输高清视频是眼下可见的必然选择。因此本文分别验证在4G和5G带宽下利用不同算法传输4K和8K立体全景视频的效果。带宽数据集分别采用文献[18]中的4G带宽数据集,以及文献[19]中的5G带宽数据集。其带宽轨迹如图4所示。
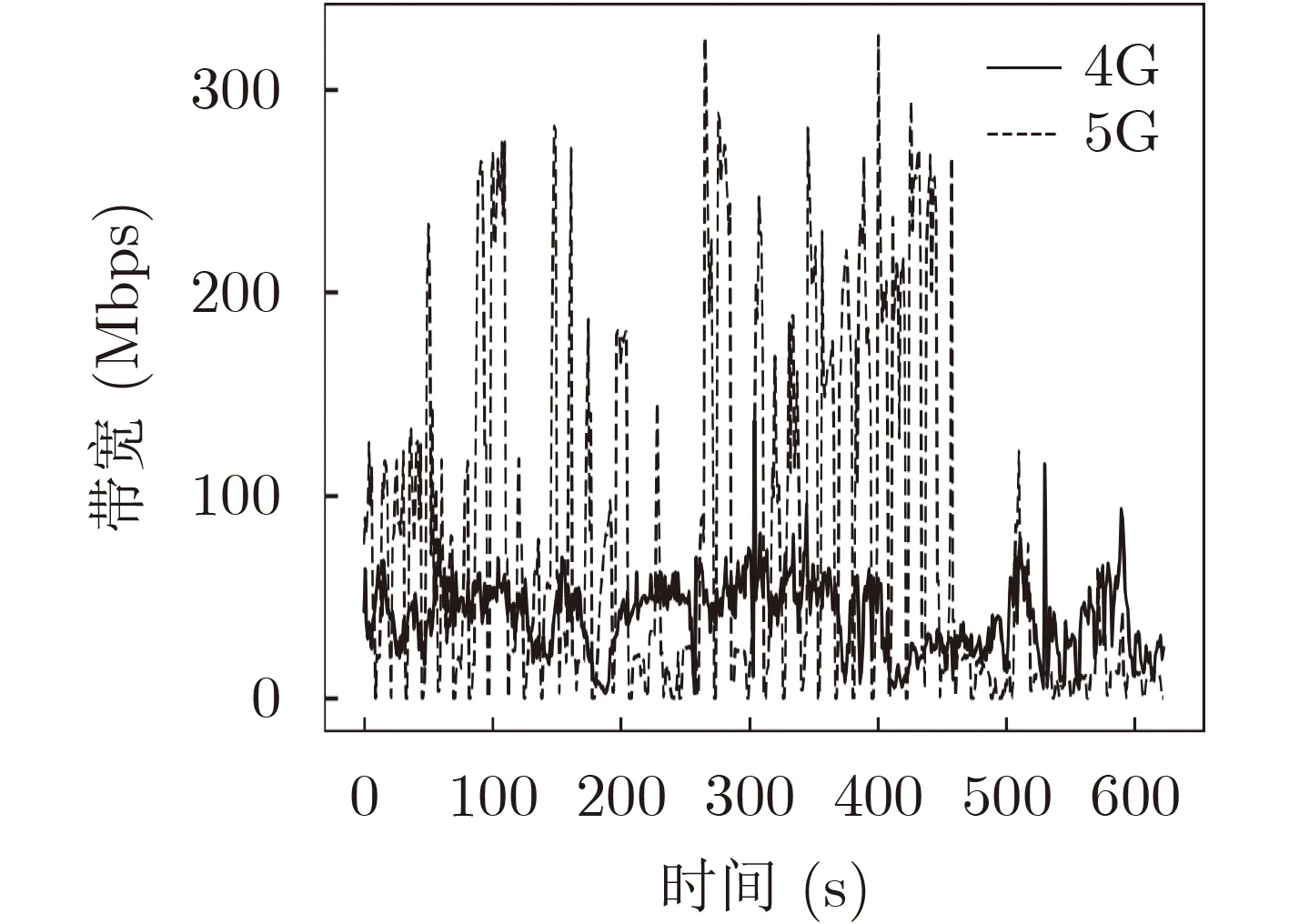
图4 4G和5G带宽轨迹

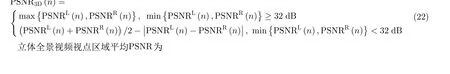


4.2 实验结果和分析
为提高处理速度,每个片段间隔抽取5帧,并缩小为192×108的大小。如表1所示,本文选择了一个视频序列和一个头部运动轨迹进行时间复杂度测试,获取每个片段平均处理时间和预测精度。由于本文算法增加了显著度和视差提取等模块,后续的码率分配环节能够通过不同的观看概率选择码率。从表1可看出,本文算法预测精度有所提高,但是运行时间有所增加。如图1所示,视点预测和码率选择机制部署在客户端,从而减轻了服务器负荷及传输成本,提高了反应速度。当前,5G技术的发展促进了边缘计算与终端间的更好的融合,终端设备的计算能力也在不断增强,利用终端设备进行预测具有很高的操作性。

表1 时间测试与视点预测精度
通过在相同的客观实验环境下,获取3种算法的缓冲时间、时域和空域光滑度,以及式(23)构建的视点区域PSNR值,其反映了整体的感知质量。
图5反映了3种算法在4G和5G网络带宽情况下的各数据的比较,其中图5(a)、图5(b)和图5(c)、图5(d)分别展示了4G和5G带宽下传输4K和8K立体全景视频下的有关数据。实验结果表明,在感知质量V −PSNR3D指标方面,5G带宽下3种算法的整体性能优于4G带宽下的性能,这符合人们的一贯认知和客观事实。但是在5G带宽情况下,3种算法的缓冲时间都在增加,这是因为如图5所示的4G和5G带宽轨迹情况,5G带宽波动相对于4G更加剧烈。剧烈波动的带宽将会给算法的码率选择策略上带来更大的挑战。
基于强化学习的码率选择方法通过不断地学习强化过去对将来的影响,其在复杂情况下更能表现出优良的性能,做出正确的决策。从图5可以看出,在5G网络带宽情况下,本文算法相对于其他两种算法感知质量V −PSNR3D最高,同时能够保持最少的缓冲时间。这是因为根据式(22),在超过一定的阈值下,非对称编码优于对称编码,并且相对于传输左右两个相等码率的瓦片,非对称传输能减小带宽数据,从而减小缓冲时间。从图5(a)和图5(b)可以看出,4G网络带宽下传输8K视频相比于传输4K视频,本文法的V −PSNR3D相对基准算法Plato增益更大。因而,在网络环境更加恶劣情况下,本文算法的感知质量效果更加明显。
图5 各算法性能比较
对空域切割的瓦片分别进行码率分配,降低了视频质量空时域的连续性,导致在时域和空域上一定程度上的不平滑。从图5可以看出,本文算法在时域和空域光滑度上性能较差。本文算法持续更新全局价值网络,间隔更新局部价值网络实现智能体策略网络朝着全局奖励和局部奖励最优方向进行优化。这种非同步更新方法,可能会使全局价值网络或局部价值网络处于欠拟合或者过拟合状态,导致二者不能同时保持较高的性能。下一步将探索全局价值网络和局部价值网络间的同时更新策略,以同步提高二者的性能。在本文算法中,全局价值网络发挥更好的作用,因此体现全局奖励的感知质量V −PSNR3D有所提升,缓冲时间有所下降。然而,体现局部奖励的时域和空域光滑度性能有所不足。
图6展示了不同算法在4G和5G带宽下传输4K和8K立体全景视频的QoE-CDF图,从图6可知,本文算法能达到一个好的均衡,其平均QoE相对其他两种算法在4G带宽下平均能有20%的提高,在5G带宽下平均能有12%的提高。说明5G网络能在一定程度上缓解立体全景视频传输在4G网络下造成的质量下降,也说明非对称传输方法能进一步提高视频整体质量。
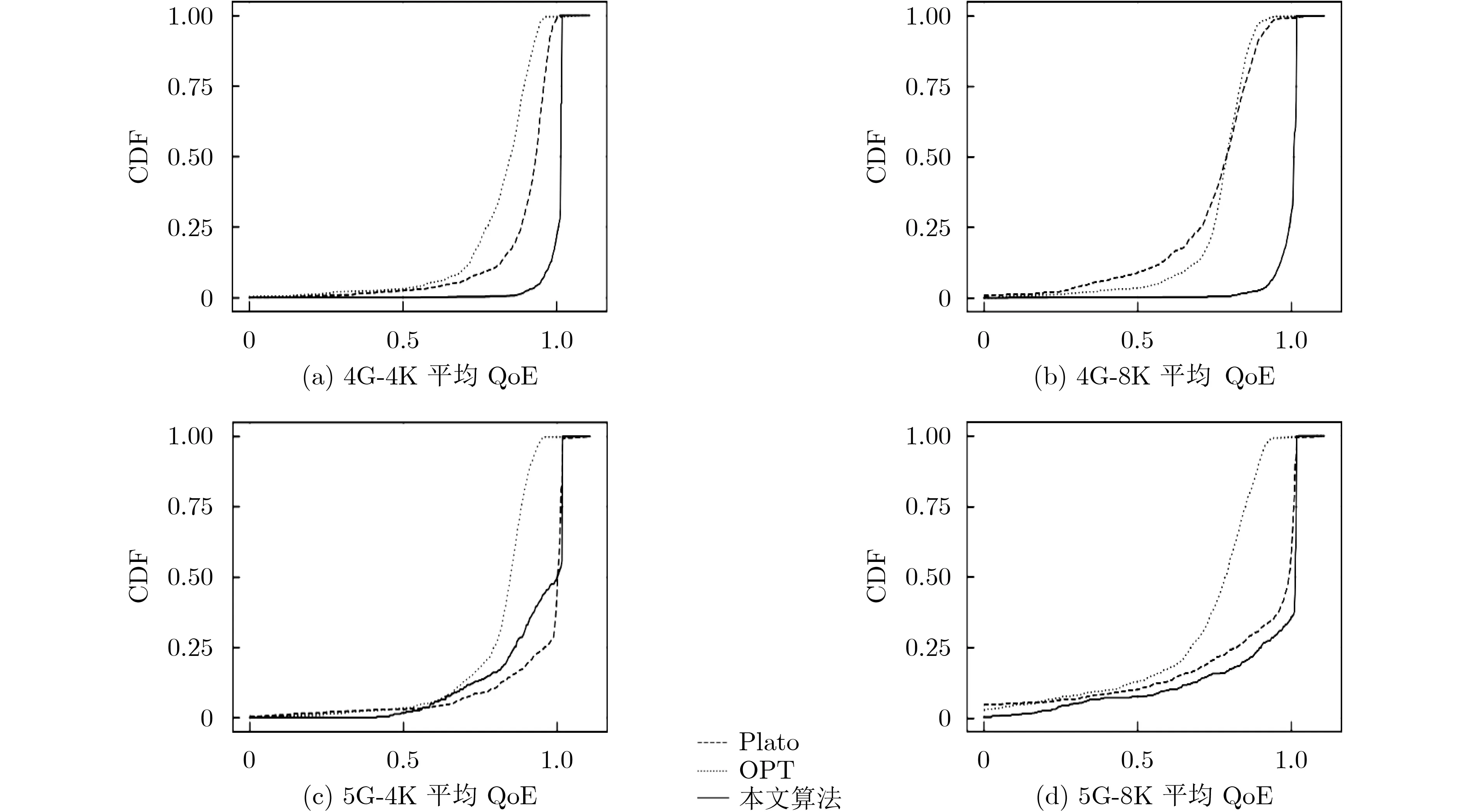
图6 各算法CDF比较
5 结论
本文提出一种基于强化学习的立体全景视频自适应流传输方法,首先提出一种视点预测概率模型,分别获取左右视点每个瓦片的观看概率。其次,提出一种基于多智能体协作的立体全景视频码率选择框架,分别将左右视点的每个瓦片当作一个智能体,每个视点内部的瓦片所构成的多个智能体相互协作,以解决针对瓦片码率选择上的行为爆炸问题。最后,根据双目抑制原理,设置合适的奖励函数。并通过设计整体和局部的学习机制,将视点内部的目标与整体的目标分开学习优化。以达到最终的目的。通过与其他方法进行比较,本文方法在视频感知质量提高和视频缓冲时间的降低具有更加优良的性能。
猜你喜欢
机械研究与应用(2022年2期)2022-05-21
电子测试(2022年4期)2022-03-17
扬子江(2021年4期)2021-08-09
科学技术创新(2021年2期)2021-01-21
浙江大学学报(理学版)(2020年1期)2020-03-12
扬子江(2019年1期)2019-03-08
计算机应用(2018年7期)2018-08-27
环境(2016年7期)2016-05-14
新闻前哨(2015年2期)2015-03-11
宇航学报(2014年2期)2014-12-15
