
白盒SM4的中间值平均差分分析
2022-04-26 06:50张跃宇蔡志强
西安电子科技大学学报 2022年1期
张跃宇,徐 东,蔡志强,陈 杰
(1.西安电子科技大学 网络与信息安全学院,陕西 西安 710071;2.西安电子科技大学 综合业务网理论与关键技术国家重点实验室,陕西 西安 710071;3.中国人民解放军66061部队,山西 阳泉 100141;4.桂林电子科技大学 广西密码学与信息安全重点实验室,广西 桂林 541004)
2002年,CHOW等[1]首次提出白盒安全模型,该模型下的攻击者对算法运行环境具备完全的控制权。算法细节以及运行过程完全暴露在攻击者的视野中,攻击者的能力包括动态观测算法程序运行过程、修改算法运行过程的中间值、对算法程序进行调试分析等。为了保证在白盒安全模型下密码算法的密钥安全性,需要对密码算法进行白盒化处理,处理后的算法称为白盒实现。一般的白盒化方法是用嵌入密钥的查找表网络来代替原计算过程,采用混淆手段对查找表进行保护,同时使用外部编码对整个实现进行保护。白盒化方法由CHOW等在其白盒AES[1]、白盒DES[2]方案中首次提出并使用,后续提出的大多数白盒实现也是基于该方法实现的。
白盒安全性模型中密码算法的运行过程与设计细节完全被攻击者所掌握,因此攻击者可以依据算法设计的缺陷,采用仿射等价、线性等价等手段对算法内部的混淆进行剥离,对混淆剥离后的查找表进行分析,进而提取出密钥信息。典型攻击方法的代表有BGE(olivier Billet-henri Gilbert-charaf Ech-chatbi)攻击[3]、MGH (MICHIELS w-GORISSEN p-HOLLMANN h d)攻击[4]等分析手段。
2016年,BOS等[5]将差分功耗分析应用于白盒实现的软件分析中,首次提出差分计算分析(Differential Computational Analysis,DCA)。差分计算分析不需要攻击者全面掌握算法细节,只需采集白盒实现程序运行过程中的相关变量,通过相应的统计分析方法即可提取出密钥信息。差分计算分析的效率更高,部署更加简便。由于差分计算分析的便捷性与高效性,差分计算分析从首次提出便取得了广泛关注。文献[6-7]对差分计算分析进行了解释与介绍,给出了该分析方法成功进行的理论原因。文献[8]中又提出了改进差分计算分析效率的方法。2019年,RIVAIN等[9]研究了内部编码对差分计算分析的影响,并提出了类似的分析手段;同年,BOGDANOV等[10]又提出了高阶的差分计算分析方法,用以分析含有软件补偿对策的白盒实现。
SM 4算法是我国商用密码标准算法[11]。2009年,肖雅莹等[12]提出了第一个SM 4算法的白盒实现方案(肖-来白盒SM 4),该方案利用CHOW等的白盒化思想,将SM 4算法流程转换为查找表网络,并采用线性编码对查找表进行保护。2013年,林婷婷等[13]结合BGE攻击、差分分析等方法,成功对肖-来白盒SM 4进行了分析。2015年,SHI等[14]提出一种新的白盒SM 4方案,将SM 4算法步骤结合到查找表中,并利用线性编码对查找表进行保护。同年,BAI等[15]又在肖-来SM 4方案的基础上,将查找表的编码复杂化,提出了一种新的白盒SM 4实现BAI-WU(白-武)白盒SM 4。2018年,潘文伦等[16]对肖-来白盒SM 4以及BAI-WU(白-武)白盒SM 4的安全性进行了分析,给出了密钥空间。2020年,姚思等[17]结合混淆密钥与查找表技术,提出了一种新型白盒SM 4实现。作为首个提出的白盒SM 4方案,肖-来白盒SM 4的白盒化方法与查找表混淆手段在后续提出的白盒SM 4方案中都得到了借鉴与应用。
笔者在对差分计算分析进行研究的基础上,首次将差分计算分析用于白盒SM 4的安全性分析,提出了一种针对白盒SM 4的分析方法。该分析方法利用加密过程中所产生的所有中间查表结果,采用均值差分的方法,使用线性组合抵消白盒SM 4中的混淆,称该分析方法为中间值平均差分分析(Intermediate-Values Mean Difference Analysis,IVMDA)。并利用IVMDA实现了肖-来白盒SM 4的密钥提取。
1 SM 4白盒实现方案
肖-来白盒SM 4算法的基本结构与标准SM 4算法结构大致相同:分组长度为128 bit,采用32轮非线性迭代结构;密钥长度为128 bit,通过密钥拓展算法生成32个32 bit轮密钥。肖-来白盒SM 4做出的改进是在每一轮的加密过程中添加线性编码,对每一轮的输入输出进行混淆,在下一轮的输入处对上一轮输出中所添加的混淆进行抵消。白盒SM 4的密钥被提前确定好,每一轮中与密钥相关的计算过程以查找表的形式呈现,查找表同时包含了密钥相关的计算过程以及对输入输出的混淆方法。肖-来白盒SM 4一轮的计算过程如图1所示。


图1 肖-来白盒SM 4一轮过程
X→Y过程以查找表的形式体现,且密钥嵌入查找表中,同时考虑到X→Y的变换是32入32出的变换。直接生成查找表会耗费巨大的存储空间,因此需要进行分割,用4个8入32出的变换以及3个异或操作进行代替,将X=(xi,0,xi,1,xi,2,xi,3)经过Ei,j与S盒及密钥加操作后的值记为(zi,0,zi,1,zi,2,zi,3),改进后的第二部分表达式如式(1)。
(Ri,0zi,0)⊕(Ri,1zi,1)⊕(Ri,2zi,2)⊕(Ri,3·zi,3⊕c[Qi]) 。
(1)
l[Qi]与c[Qi]分别表示Qi变换的线性变换与常数部分,Ri,j(j=0,1,2,3)表示32×8的矩阵。由式(1)可以看出,原来32入32出的查找表被替换成了4个8入32出的查找表以及3个异或操作。一轮加密函数中的F函数可以用5个仿射变换、4个查找表、6个异或操作完成。
2 差分计算分析
差分计算分析是灰盒模型下的差分功耗分析在白盒安全模型下的对应软件版本。该分析使用程序运行过程中的软件执行轨迹来提取密钥信息,软件执行轨迹包括但不限于程序执行期间访问的内存地址、内存数据等变量。差分功耗分析所依据的原理是执行加密操作时所产生的功耗轨迹信息与密钥密切相关[18],差分计算分析则认为软件执行轨迹与密钥同样密切相关。
差分计算分析可分为以下四步进行。
步骤1 攻击者首先执行一次白盒实现程序,采集其软件执行轨迹,利用可视化工具对其进行处理。
步骤2 攻击者使用随机明文获取软件执行轨迹,每一条明文会对应一个软件执行轨迹。
步骤3 对采集到的软件执行轨迹进行格式化,转换成适当的格式,以适应接下来的分析。
步骤4 使用差分功耗分析工具对处理后的软件执行轨迹进行分析,提取出密钥信息。
进行步骤1的主要目的是定位出与密钥相关的计算部分,以便缩小采集范围,节省分析所需的内存空间,在内存空间充足时可跳过该步骤。软件执行轨迹的采集可以利用PIN[19]或者Valgrind[20]等动态二进制分析软件以及相关的插件来完成。而对于软件执行轨迹的格式化只是将采集的信息限制到单一的种类中,比如只采集写入内存的数据或只采集从内存中读出的数据。前几个步骤的目的是对采集到的数据进行处理,使其尽可能地适应差分功耗分析,而在分析步骤中只是将差分功耗分析的对象从电路功耗换成了二进制形式的软件执行轨迹,同时由于软件执行轨迹中不会存在噪声,所以往往分析的结果更加精确。
差分计算分析需要攻击者能够在受控环境下重复多次执行二进制白盒实现程序,并且攻击者掌握白盒实现外部编码的输入编码或者输出编码任一部分。这两点是能够进行差分计算分析的基本定义,只有满足以上两点,才能够完整地运行差分计算分析的全部步骤。
文献[5]中的差分计算分析所需要的软件执行轨迹为白盒程序运行时的内存读写记录,采用均值差分对其进行统计分析。文献[21]在差分计算分析的基础上提出了差分数据分析(Differential Data Analysis,DDA)。该分析与差分计算分析基本类似,不同之处在于需要的软件执行轨迹为加密过程中所有查表结果,利用相关系数(如皮尔逊相关系数)进行统计分析。差分数据分析所需的分析对象为查表结果,该数据较差分计算分析所需的内存访问记录更易于采集,但差分数据分析需要计算数据的皮尔逊相关系数来进行统计分析,该步骤却比差分计算分析中计算均值差分来进行统计分析的方法更复杂。文献[5,21]中实验显示,差分计算分析所需要的软件执行轨迹数目通常为数千条,而差分数据分析所需要的软件执行轨迹数量为数百条。综合以上两种分析的优点,采用更易于采集的查表结果为分析对象,并以复杂度更低的计算均值差分作为统计分析的方法,笔者提出了用于白盒SM 4密钥提取的新型分析方法,名为中间值平均差分分析(Intermediate-Values Mean Difference Analysis,IVMDA)。
3 中间值平均差分分析
介绍中间值平均差分分析,应用该分析对肖-来白盒SM 4进行密钥提取工作,给出了实际分析结果,并根据结果对分析做出相应改进。
3.1 攻击模型与原理说明
中间值平均差分分析的目标是能够在实际应用环境下对白盒SM 4进行密钥提取。传统的白盒安全模型中,攻击者对算法的细节以及运行环境都具备完全的了解以及控制能力,但在实际应用环境中的攻击者往往不具备该攻击条件。根据实际应用环境中白盒实现面临的现实性威胁对攻击者的能力进行定义。白盒实现的攻击者是一个带有恶意目的的合法用户,掌握白盒实现的二进制程序,并具备一定的逆向、代码调试等能力。攻击者不直接掌握外部编码,但可以向外部编码组件发送明文并获得编码后的明文。攻击者不掌握白盒实现方案的算法细节,只了解白盒方案的底层算法种类。攻击者的分析对象是白盒实现的所有查表结果。
中间值平均差分分析也可以认为是一种差分功耗分析在软件层面的变体分析方式,差分功耗分析是利用加密芯片运行过程中产生的功耗信息与密钥的相关性来进行统计分析[18],从而提取出密钥信息。中间值平均差分分析的分析对象是加密过程中的查表结果,每一个表中都嵌入了密钥信息,查表结果与密钥之间必然存在相关性,因此可以利用统计分析的方法对大量样本进行分析,提取密钥。中间值平均差分分析基于以上原理进行密钥的提取工作。
3.2 中间值平均差分分析
中间值平均差分分析整体分为两部分:数据采集部分与数据分析部分。
第1部分数据采集。用SM 4白盒实现对n条随机明文{p0,p1,…,pn}进行加密,顺序采集加密过程中产生的128个查表结果,以列表的形式组织数据,称该列表为一条中间数据流。每一个随机明文进行加密的过程都对应一条中间数据流ti。最终采集到n条明文及其对应的n条中间数据流{t0,t1,…,tn},并以键值对的形式将明文与中间数据流对应组织起来。其中明文作为键,中间数据流作为值。
第2部分对采集到的数据进行分析。根据攻击者的能力,已知白盒实现的底层算法是SM 4,在该算法中与密钥相关的计算部分是S盒,一轮中有4个并列的S盒计算,选取算法第一轮中包含密钥加运算的S盒计算作为中间函数φ(m0,j,rk0,j)。
φ(m0,j,rk0,j)=S(m0,j⊕rk0,j)=e,j∈{0,1,2,3} 。
(2)
式中,rk0,j表示8 bit长的部分轮密钥,而m0,j表示进入S盒的8 bit长的中间向量m0,中间函数的计算结果为e。根据SM 4算法流程,该中间向量m0由平均分为4部分的128 bit的明文的后三部分异或得到,由于掌握外部编码的输入编码部分,因此可以直接使用原明文利用式(3)对中间向量m0进行计算:
m0=pi,1⊕pi,2⊕pi,3。
(3)
采用中间函数φ,遍历部分密钥rk0,j所有可能的值。选取n条明文对应的m0的一部分m0,j计算中间函数φ(m0,j,rk0,j)的结果,rk0,j∈{0,1}8,共有256种可能值,根据rk0,j值将中间函数结果分为256组。对每一组分别进行以下4步的分析。
步骤1 定义一个选择函数φ(e),对组内每一个中间函数结果e,利用式(4)计算其选择函数的结果。
φ(e)=Sn(e)=b∈{0,1},0≤n≤7 。
(4)
式中,Sn(e)是取中间结果的第n位。每一个中间结果e对应8个选择函数结果b;b是一个比特位,取值范围只有0和1;根据n的不同,总共得到8个不同的b,用列表将其组织起来,记作B。
每一组的中间结果e都对应一条明文,而一条明文对应一条中间值数据流,同时每一个中间结果e也对应一个B。因此,在不同的e所对应的B中选取一个元素b,可以将其与一个中间数据流ti对应起来。
步骤2 设定两个集合A0,A1。当b为0时,将对应的中间数据流分入集合A0中,当b为1时,将对应的中间数据流分入集合A1中。随后,利用式(5)和式(6)计算集合A0与集合A1的均值差分。
(5)
(6)
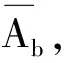
步骤3 对B中所有顺序上的元素执行步骤2中的分组以及计算均值差分,最终得到8个ΔLC值,选取其中最大的记为Δkey,该值与当前组的密钥猜测唯一对应。
步骤4 对于所有的假设密钥值对应的组,执行步骤1中计算选择函数以及根据选择函数结果进行分组并计算均值差分等步骤。最终得到与当前假设密钥值惟一对应的Δkey。比较所有的假设密钥对应的Δkey,Δkey值最大的假设密钥即为最佳的猜测密钥。
对一轮中的四个S盒分别执行以上分析过程即可完整恢复一轮的轮密钥。
3.3 实验结果与分析
采用Python语言实现中间值平均差分分析,对一个肖-来白盒SM 4程序进行密钥提取。在CPU为Intel(R) Core(TM) i5-6300HQ@2.3 GHz,运行内存大小为8 GB的计算机上执行该分析。嵌入白盒实现程序的主密钥为0123456789abcdeffedcba9876543210(十六进制数串),将得到的每一个部分假设密钥及其所对应的Δkey以图片的形式展示在图2中。
第一轮的轮密钥为0xf12186f9。图2中表示了第一轮的4部分猜测密钥值及其对应的Δkey的关系,横坐标key为猜测密钥的值,纵坐标为Δkey,根据中间值平均差分分析的描述,最大的Δkey所对应的横坐标key为正确的密钥猜测,并且正确的密钥猜测对应的Δkey应当为一个明显的峰值。从图中结果显示,并未出现明显的峰值,波形杂乱无章,同时正确密钥所对应的Δkey也不是最大值,该结果表明中间值平均差分分析并未成功提取出密钥信息。重复多次实验均得到以上结果,结合肖-来SM 4方案对该结果进行分析。
在肖-来白盒SM 4方案中,查找表的输入、输出部分存在随机的仿射对输入与输出进行混淆,而输入的混淆会被抵消,因此只有输出部分的混淆对查找表的结果产生影响。根据中间值平均差分分析的原理,查找表的结果与密钥之间必然存在相关性,而实验结果却并没有反映出该相关性。猜测是输出部分的混淆影响了实验结果,设计对照实验对该猜测进行验证。




图2 中间值平均差分分析结果

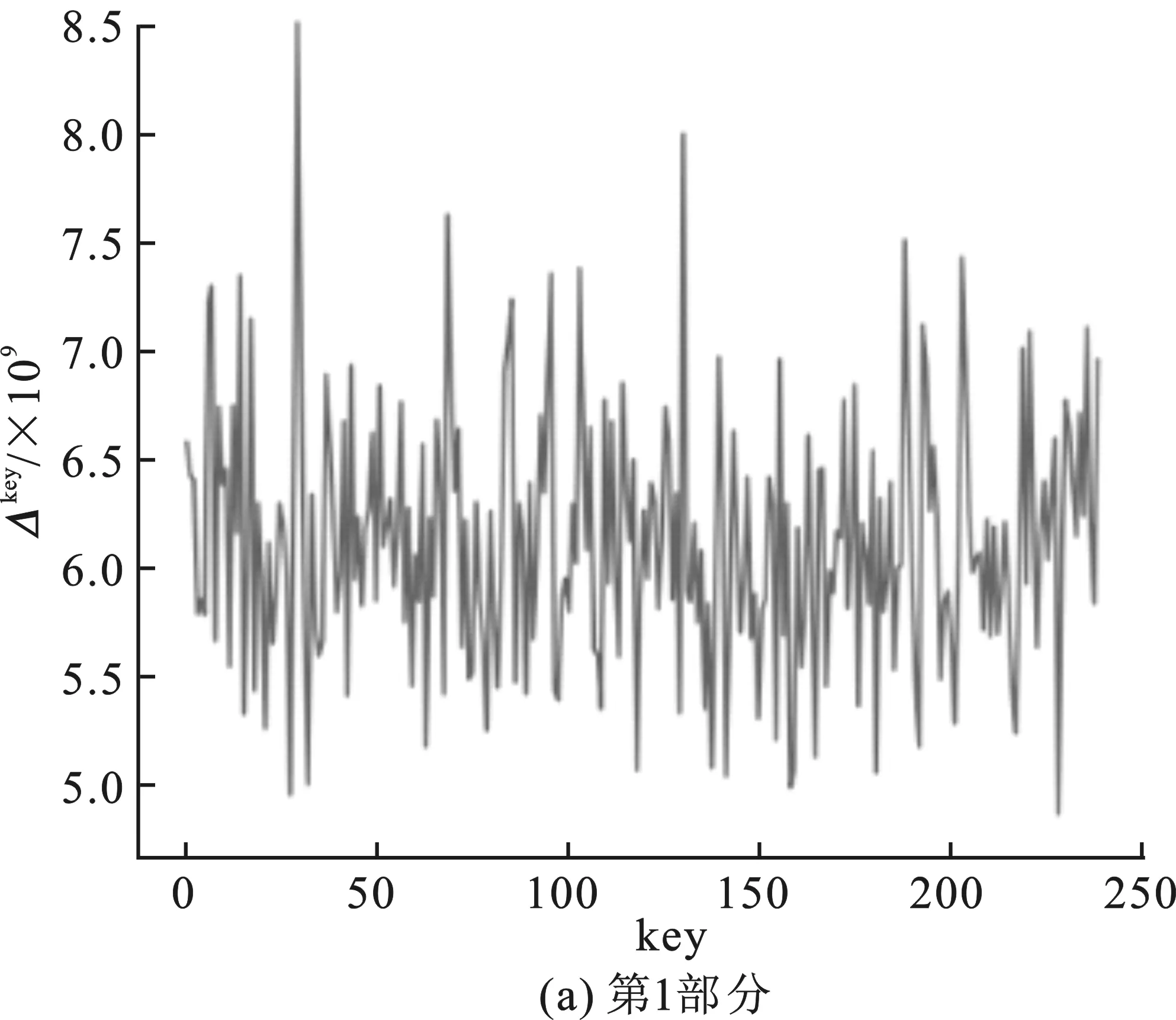



图3 查找表无输出编码的白盒SM 4中间值平均差分分析结果
嵌入查找表主密钥为0123456789abcdeffedcba9876543210十六进制数串,第一轮的子密钥为0xf12186f9。图3(a)~(d)分别表示对第1轮子密钥4部分的猜测结果,图3(a)中最高值对应的横坐标key为31,十六进制为0x1f;图3(b)中最高值对应横坐标key为33,对应十六进制为0x21;图3(c)中最高值对应横坐标key为134,十六进制为0x86;图3(d)中最高值对应横坐标key为249,十六进制为0xf9。后3部分的分析结果为正确密钥值,并且正确密钥对应的Δkey为明显的峰值。同时改变嵌入密钥重新生成查找表,进行多次实验,结果均为后3部分的密钥猜测值与正确密钥值相符。
由于可以固定得到第一轮子密钥的后3部分,因此可以认为在不含输出编码的情况下,中间值均值差分分析可以通过对查找表值的分析得出正确密钥。对比两次实验的结果,可以得出结论:肖-来白盒SM 4实现中查找表的输出编码部分对中间值平均差分分析造成了干扰,导致分析失败。
3.4 对中间值平均差分分析的改进
节3.3的研究与分析表明,查找表输出编码是影响分析的关键因素。肖-来白盒SM 4实现的混淆手段只有线性编码,该编码是对查找表原始输出进行线性组合得到新的结果,使得假设中间函数结果与实际查找表结果不匹配。因此,分析步骤中直接利用中间函数结果进行分组并不能反映密钥与查表值的关系,需要添加相关操作抵消编码影响。笔者采用计算中间函数结果的线性组合的方式来抵消线性编码的混淆作用。
对于中间值平均差分分析的改进只在选择函数的形式上做出了改变,其余部分保持不变。选择函数形式如下:
φ(e)=LCe=b∈{0,1},1≤LC≤255 。
(7)
式中,LC∈{0,1}8取值范围从1至255,该表达式计算出中间函数结果的所有线性组合结果,目的是为了消除白盒实现中的线性编码手段对结果的影响。每一个中间结果e对应255个线性组合结果b;b是一个比特位,取值范围只有0和1。根据LC的不同,总共得到255个不同的b,以列表的形式将其组织起来,记作B。
对于一组的中间结果e,每一个都对应一条明文,而一条明文对应一条中间值数据流,同时每一个中间结果e也对应一个B。因此,在不同的e所对应的B中选取一个元素b,可以将其与一个中间数据流ti对应起来。设定两个集合A0,A1,当b为0时,将对应的中间数据流分入集合A0中,当b为1时,将对应的中间数据流分入集合A1中。随后,计算集合A0与集合A1的均值差分,计算步骤如式(5)和式(6)。对B中所有顺序上的元素执行以上分组以及计算均值差分的步骤,最终得到255个ΔLC值,选取其中最大的记为Δkey;该值与当前组的密钥猜测惟一对应。
对于所有的假设密钥值对应的组,执行以上计算选择函数以及根据选择函数结果进行分组并计算均值差分等步骤。最终得到与当前假设密钥值惟一对应的Δkey。比较所有的假设密钥对应的Δkey,Δkey值最大的假设密钥即为最佳的猜测密钥。
3.5 改进后中间值平均差分分析的实验结果
改进后的中间值平均差分分析采用Python进行实现,对肖-来白盒SM 4的二进制程序进行分析。在CPU为Intel(R) Core(TM) i5-6300HQ@2.3 GHz,运行内存大小为8 GB的计算机上执行该分析。嵌入白盒实现程序的主密钥为0123456789abcdeffedcba9876543210(十六进制数串)。实验结果如图4所示。
根据主密钥可计算出第一轮的轮密钥为0xf12186f9。分析程序对第一轮4部分的密钥进行猜测,图4(a)~(b)表示了4部分猜测密钥值及其对应的Δkey的关系,横坐标key表示猜测密钥的值,纵坐标为Δkey。图4(a)中最高Δkey所对应的横坐标key为241,转为十六进制即为0xf1;图4(b)中最高Δkey所对应的横坐标key为33,转换为十六进制即为0x21;图4(c)中最高Δkey所对应的横坐标key为134,转为十六进制为0x86;图4(d)中最高Δkey对应的横坐标key为249,转换为十六进制为0xf9。分析所得结果与第一轮查找表中实际嵌入的轮密钥完全相符,该分析耗时约为27 min。




图4 改进后中间值平均差分分析对肖-来白盒SM 4分析结果
改变参与分析的明文数量,重复进行实验。明文数量与分析结果的对应关系如表1所示。

表1 明文数量与分析结果
从表1的结果可以看出:随着明文数目的降低,Δkey的最高值与次高值之间的差距越来越小,在随机明文的数量低至一定数目之后,所得到的分析结果会出现错误。实验结果表明,明文数量的下限在50左右波动,同时,随着明文数量的降低,分析所需时间也会下降,在保证分析正确性的前提下只需要60条明文即可完成密钥提取工作。
3.6 与其他分析对比


表2 分析方法的对比
通过以上几方面的对比,可以看出中间值平均差分分析在分析效率、部署简便性以及分析结果的准确性方面要优于潘、林的分析方法。同时,本实验中的中间值平均差分分析采用解释型编程语言Python进行实现,其效率还可以通过利用编译型编程语言重新实现以及引入并行计算等方法进行优化,分析的时间还能大幅缩短。
4 总结与展望
笔者在差分计算分析的基础上提出了中间值平均差分分析。该分析以白盒实现加密过程中的查表结果为分析对象,并且利用线性组合的手段抵消了查找表输出部分的线性编码。相比于之前的针对白盒SM 4方案的安全性分析手段,中间值平均差分分析部署简单、分析效率高、分析结果精确,是一种高效的新型分析方法。为了提高白盒方案的内存效率,近期提出的白盒实现方案均采用线性编码手段对查找表进行保护,如姚思等人的白盒CLEFIA方案[22],而中间值平均差分分析的分析对象即为线性编码保护的查找表。因此,在未来的研究中,可以将中间值平均差分分析推广到类似的白盒方案的安全性分析工作中来。
猜你喜欢
上海师范大学学报·自然科学版(2022年3期)2022-07-11
现代电子技术(2022年11期)2022-06-14
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
阅读(低年级)(2019年2期)2019-04-19
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
上海师范大学学报·自然科学版(2018年3期)2018-05-14
民间故事选刊·上(2018年1期)2018-01-02
计算机应用(2016年10期)2017-05-12
小小说月刊·下半月(2016年6期)2016-05-14
