
基于迁移VGG和线性支持高阶张量机的驾驶行为异常检测
2022-04-27 06:02张志威程军圣
机械设计与制造 2022年3期
张志威,程军圣
(湖南大学机械与运载工程学院,湖南 长沙 410006)
1 引言
根据2018年中华人民共和国最高人民法院发布的《第二届司法大数据专题分析课题之机动车交通事故责任纠纷案件》专题摘要显示,2012年1月1日至2017年6月30日期间,全国各级人民法院一审审结的交通事故案件达449.1万余件,而事故诱因排在前三名的分别是无证驾驶、酒后驾驶以及开车玩手机。对于前两项违规驾驶行为均可以通过法律和临检的方式进行规范,但对于开车玩手机、交谈、取物、进食等违规操作,因为其具有持续时间短,不易检测,难以管控等特点而成为一个难题。因此针对行车过程中的驾驶行为异常检测并予以警示显得尤为必要。
目前,对于驾驶员异常行为检测的方法一般分为三类[1],即通过驾驶员的生理指标(如生理电信号)、驾驶员行为特征以及车辆行为特征来判断驾驶行为是否规范。其中,对于驾驶员行为特征的分析可以较为直观和准确的分析驾驶员的行为状态。文献[2]利用智能手表和健身追踪器等腕式惯性传感器跟踪方向盘的使用情况和输入,依赖运动特征区别其他手部运动并推算出方向盘转角,以此检测不安全驾驶行为,但这种方法仅限于检测手部具有动态活动的异常驾驶行为。文献[3]建立了一个非侵入式系统,基于视觉采集了手臂位置、眼睛状态、面部表情以及面部朝向等特征并利用随机森林分类器对驾驶行为进行判别,该方法采集多通道信息共同配合完成对驾驶行为的判别,系统复杂度高。文献[4]通过手机前后摄像头采集驾驶员和路况信息,设计CarSafe应用APP实现对驾驶员不规范驾驶行为的检测,该方法仅用于检测驾驶员疲劳驾驶、醉酒驾驶和玩手机等不规范行为。文献[5]利用FaceLAB采集视觉数据,基于FaceLAB工作机制和人眼屈光度推导出头部旋转与眼睛固定点之间的相关性,以此来研究具有多年驾龄的驾驶员和驾驶新手视觉特征之间的差异。文献[6]提出了基于肤色分割与Ada‐Boost算法相结合的人脸检测算法,用于人脸跟踪的尺度自适应KCF目标跟踪算法以及YCbCr肤色提取与肤色阈值相结合的手部图像检测方法,结合脸部特征以及手部特征共同判断驾驶行为异常状态。上述研究中较少从视觉角度对驾驶员肢体特征进行深入分析,但往往视觉角度中驾驶行为特征最为明显,因此以视觉角度对驾驶员行为特征展开研究。
基于视觉,通过安装在仪表盘上的摄像头采集图像数据。为了能获取完整的行为特征信息,图像采集区域需包括整个驾驶座,那么图像数据中便存在人的特征、窗外风景以及车内饰等许多冗余信息,并且说话、回头、取物、玩手机等异常的驾驶行为在行车过程中并不会持续过长时间,因此会存在异常驾驶行为数据量较少的问题。对于小批量的高维数据分类,线性支持高阶张量机(SHTM)[7]能够有一个好的分类效果,但对于异常驾驶行为检测中数据存在较多冗余信息的问题,SHTM不能完全满足分类要求。针对该问题,本文拟采用卷积神经网络中的经典模型—视觉几何群19网络(VGG19)[8]对图像数据进行特征提取。但由于数据集样本数较小,对VGG19的训练效果较差,不能达到较好的特征提取效果。为了解决这一问题引入迁移学习方法[9-10]。因此,基于迁移学习方法,提出VGG19和SHTM相结合的迁移VGG-SHTM算法,并用于驾驶行为异常检测。为了检验迁移VGG-SHTM方法的有效性,邀请十位驾驶人员进行驾驶行为异常检测实验,并对比SHTM、VGG19和迁移VGG-SHTM三种方法在实验中的表现。
2 迁移VGG-SHTM原理
2.1 基本定义
在介绍方法之前,根据机器学习以及信号处理相关的领域[11-12]对方法中所涉及到的概念进行定义,相关的符号表示方法,如表1所示。

表1 符号列表Tab.1 List of Symbols
规定了符号的表示方法,下面来介绍一些基本的概念。
定义1(张量)一个N阶张量A∈R I1×I2×…×I N,也称为是N维或者N模数组,I N是第N模态的维度。张量是一维向量和二维矩阵的高阶泛化形式,向量也可称为是一阶张量,矩阵则是二阶张量。
定义2(内积)类似于向量间的内积运算一样,两个大小相同的张量A,B∈R I1×I2×…×I N,其内积表示为定义如下:

定义3(外积)两个张量A∈R I1×I2×…×I N和B∈RI 1'×I2'×…×IN',其外积(张量积)表示为A∘B,定义如下:

定义4(n-模积)张量A∈R I1×I2×…×I N和矩阵U∈R J n×I n的n-模积可以被表示为A×n U,结果为R I1×…×I n-1×J n×I n+1×…×I N空间下的张量结果,定义如下:
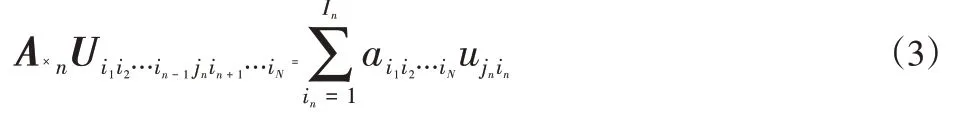
若有一个张量A∈R I1×I2×…×I N和一系列矩阵U∈R J n×I n,其中J n
定义5(CP分解)对于一个张量A∈R I1×I2×…×I N,它的CP分解(秩一分解)形式可以被表示为:

我们称式(4)为长度为R的秩一分解或者说是CP分解。如果R=1则A被称为秩一张量,如果R是组成张量A的秩一张量的最小值,则R被称为是张量A的秩,即R=rank(A)。另外,对于所有u i(N)和u j(N)都相互正交,其中i≠j,1≤i,j≤R,n=1,2,…,N,则说张量A是可正交分解的。另外,中均采用交替最小二乘算法(ALS)[13]求解CP分解结果。
定义6(范数)张量A∈R I1×I2×…×I N的范数为张量中每个元素的平方和相加,然后再进行开方运算,定义如下:

如果有两个大小相同的张量A,B∈R I1×I2×…×I N,两个张量间的距离定义为‖A-B‖F。注意到张量A和B间的距离等于他们向量化表达形式的欧几里得距离。
2.2 SHTM原理
2.2.1 支持张量机
在一个含M个样本的数据集{上采用支持张量机(STM)进行二分类,其中X m为第m个输入样本,y m为对应第m个样本的标签。对于支持张量机,处理二分类问题实质上是处理N个带有不等式约束的二次规划问题,第n个二次规划问题可以用式(6)~式(8)来表示[14]:

式中:w(n)—n个超平面的权重向量;b(n)—偏置;ξm(n)—第m个样本对应于w(n)的误差;C—分类误差和分类间隔间的权衡因子。
2.2.2 线性支持高阶张量机

另外,根据张量的n-模积和内积的定义,可以得到下式:
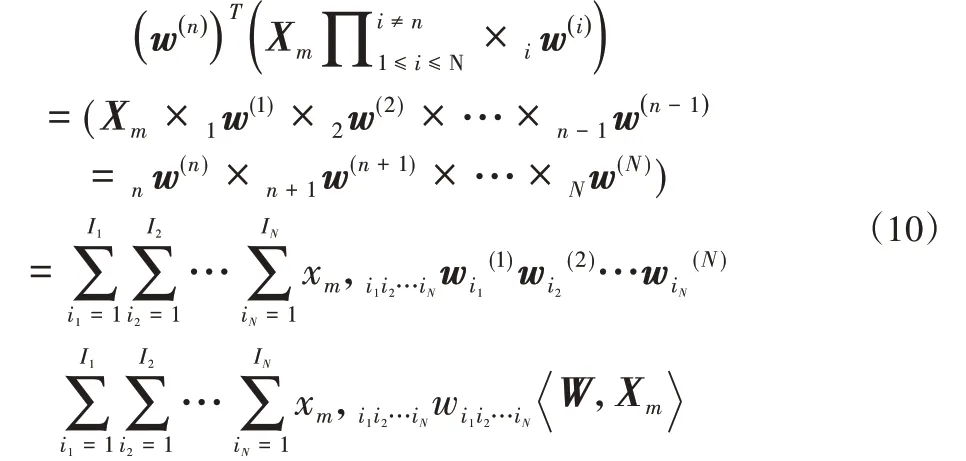
根据式(9)和(10),可将上述STM中提出的第N个二次规划问题转化为下式:
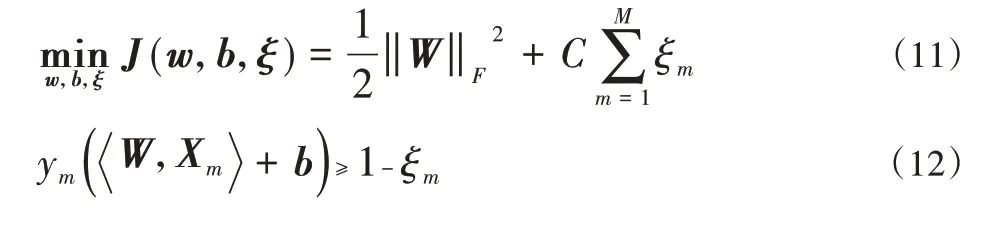

利用拉格朗日乘子法对问题进行优化,得到:

式中:αm、βm—拉格朗日算子。
求L(W,b,α,β,ξ)对W,b,ξm的偏导数,得到:
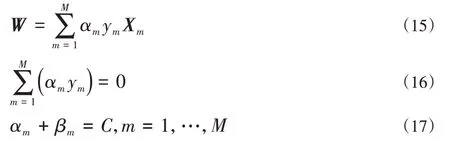
将式(15)~式(17)式带入式(14),并求得拉格朗日乘子法的对偶问题,如下所示:

式(18)中内积计算并不能很好的获取数据的结构信息,考虑到CP分解能够使张量具有更复杂和有意义的表达形式,特别是对于高阶的张量,所以将CP分解融入到内积计算中。根据CP分解定力,可以将X i和X j表示为根据内积的定义,X i和X j的内积计算如下:
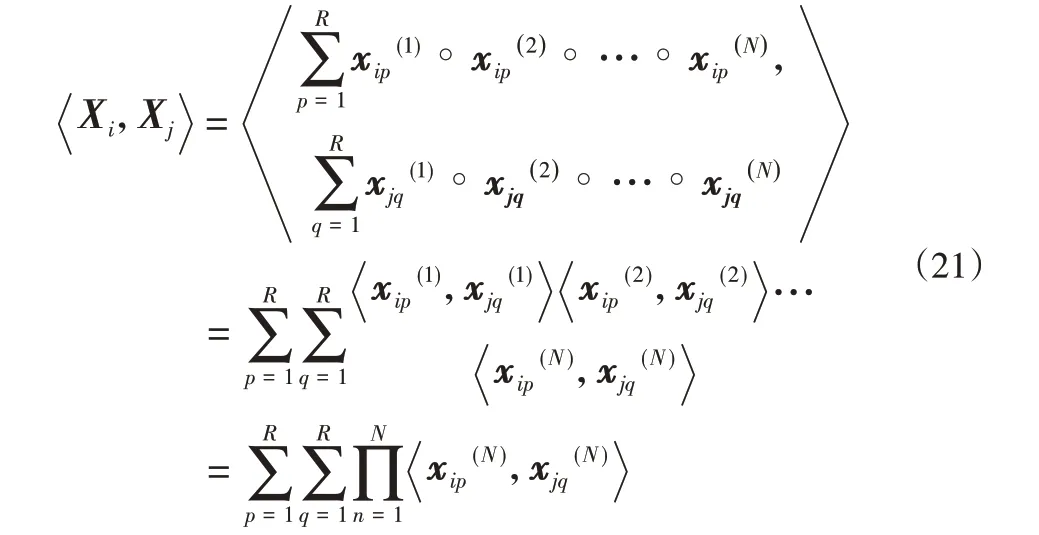
将式(21)带入到式(18)中,可以获得下面的模型:

而对于测试样本X的预测可以表示为:

至此,我们称模型(22)~(25)为线性支持高阶张量机(SHTM)模型,它可以利用QP求解器或者SMO算法进行优化求解。
2.3 迁移VGG-SHTM方法
SHTM在处理冗余信息较多的复杂数据上,其分类精度并不高。文献[15]对SHTM进行了改进,利用多线性主成分分析(MPCA)[16]对输入张量进行降维为了去除冗余信息,提高计算速率,但并未在分类准确率上有明显的提升效果。为了去除高阶张量数据中的冗余信息,提高分类精度,利用VGG19进行有效特征提取,并引入迁移学习的方法,解决训练VGG19过程数据量较小的问题。
2.3.1 VGG19
对比于其他的卷积神经网络方法,VGG19网络采用3×3的小卷积核,通过增加卷积核数量在保证与其他卷积神经网络具有相同感受野的前提下,增加了网络深度提升了网络的性能。同时,因为对部分层进行了预初始化,使得VGG19能够快速的收敛。VGG19的网络结构模型,如图1所示。可将其分为两个部分:第一个部分对输入的图像样本进行特征提取,由卷积层、ReLU层和池化层组成;第二部分根据第一部分提取的特征信息对样本进行分类,由全连接层、ReLU层、dropout层和softmax层组成。不同的层具有不同的功能:

图1 VGG19网络结构Fig.1 Network Structure of VGG19
卷积层:提取输入数据特征并提供位置信息;
ReLU层:增加网络的非线性关系使得网络能解决更复杂的问题;
池化层:保留主要特征,减少参数,防止过拟合,另外还可以保持旋转或平移不变形;
全连接层:整合特征信息,并起到分类器的作用;
dropout层:防止网络过拟合;
softmax层:归一化,输出网络预测样本为每一类的概率。
2.3.2 迁移学习
迁移学习是指一种领域中所学习的知识或者是经验对另一个领域知识的学习或活动的影响。而在深度学习领域中,则指的是将一个已经训练好的神经网络节点参数(权重、偏置)迁移到一个新的网络模型中,再根据新的任务对网络模型参数进行调整。迁移学习方法可以加快网络模型的训练进程并提升网络性能。
在对VGG19进行训练时,异常驾驶行为训练样本数不能满足网络的训练要求,这会严重影响VGG19中特征提取的效果。引入迁移学习方法对VGG19进行训练的流程,如图1所示。利用Ima‐geNet中的大规模数据集对VGG19网络进行预训练,使其具有较强的特征提取能力,再将VGG19中样本分类的部分替换为新的全连接层、softmax层和分类层构成新的网络模型,并用驾驶行为异常检测的数据集对新的网络模型进行fine-tune(微调)操作。这种做法相比于直接用驾驶行为异常检测的数据集对VGG19进行训练,能获得针对驾驶行为特征提取的能力更强的特征提取网络层部分。

图2 迁移学习原理Fig.2 Principle of Transfer Learning
2.3.3 迁移VGG-SHTM
针对SHTM算法在冗余信息较多的样本上分类精度差的问题,利用VGG19对数据进行特征提取,并引入迁移学习解决VGG19训练中样本数较少的问题,提出了迁移VGG-SHTM算法,其流程图,如图3所示。

图3 迁移VGG-SHTM算法流程Fig.3 Algorithm Flow of Transfer VGG-SHTM
从图3中可以看到迁移VGG-SHTM算法的结构,其步骤如下:
(1)预训练,利用ImageNet数据库中的100多万张图像对VGG19网络进行训练,直至损失函数收敛;
(2)微调,将VGG19网络后面的全连接层、softmax层和分类层换成针对二分类的网络层,采用自己的数据集(驾驶行为训练集)对VGG19网络参数进行微调;
(3)取微调完成的VGG19网络全连接层前面的部分(特征提取部分),输入自己的数据集,获得样本数据的特征张量;
(4)将第三步中获得的特征张量数据输入SHTM进行训练。
至此,基于迁移学习训练好的VGG19网络中的特征提取部分以及SHTM即为所提出的迁移VGG-SHTM算法。对比于原始的SHTM,迁移VGG-SHTM增加了对样本的特征提取步骤并进行了优化,可以有效避免驾驶行为图像中繁杂的背景噪声,获得更深层次的特征信息,提高准确率;对比原始的VGG19网络,它不需要大量的样本数据去训练网络就可以获得一个较好的效果。
3 实验分析
3.1 实验说明
实验中,对于VGG19和迁移VGG-SHTM,均在ImageNet数据库上进行预训练,在实验采集的驾驶行为训练数据集上进行微调。实验均采用查全率(实际正例中被分类为正例的比率)进行评价。三种算法均在Matlab上进行编译,平台运行版本为Mat‐lab R2018b,并在操作系统为Windows7,GPU为NVIDIA GeForce RTX 2080Ti,运行内存为64G的台式电脑上运行。
3.2 实验数据集
实验数据通过安装在副驾驶上的手机摄像头进行图像获取,记录驾驶员分心时的行为举止。该数据集总共邀请十位测试员,其中男生7人,女生3人,且每个人的衣着体型等外貌特征均有明显差异。对于每位实验者,采集的图像分为10类,其中包括含目视前方、看左右后视镜的正常驾驶行为(如图4)以及玩手机、打电话、交谈、后座取物、进食、侧向取物及照镜子的异常驾驶行为,如图5所示。实验中将其分为正常驾驶和异常驾驶两类,训练集和测试集中每类包含90张,像素为640×480图片。

图4 正常驾驶行为Fig.4 Normal Driving Behavior

图5 异常驾驶行为Fig.5 Abnormal Driving Behavior
3.3 参数设定
用实验所采集的驾驶员检测数据集进行微调之前,需要用新的全连接层、softmax层以及分类层替换VGG19网络结构中的对样本特征进行分类的部分。为了使新替代层中的学习速度快于迁移的层,应将替代层中的权重学习因子和偏置学习因子设置为较大值,实验中均设置为20。另外,网络中初始学习率设置为10-4。在SHTM中,现在没有一种确定的方法求解CP分解的秩,利用驾驶行为检测数据集,通过改变R的值对SHTM性能做了一个遍历实验,最终平衡分类精度和分类时间,取R=17。
3.4 分类性能
为了更准确的对比SHTM、VGG19和迁移VGG-SHTM三种方法对于驾驶行为异常检测的效果,总共进行10次实验,每次实验分别在不同的训练∕测试集对上进行,依次编为数据集(1~10)。每次实验训练集和测试集样本数量均为180,训练∕测试集中正常和异常类样本数为90。按照3.3设置模型参数,进行实验,所得实验结果,如表2所示。其中迁移VGG-SHTM方法的实验结果用黑体加粗。实验结果以表2的形式给出,为了更直观的显示实验结果,绘制10次实验中三种方法的驾驶行为异常分类查全率曲线,如图6所示。根据表2中的结果显示,在各次实验中,SHTM最低的分类查全率为80.00%,最高的分类查全率为88.33%,平均分类查全率为84.06%;VGG19最低的分类查全率为78.33%,最高分类查全率为92.22%,平均分类查全率为87.28%;迁移VGGSHTM最低的分类查全率为88.33%,最高的分类查全率为93.89%,平均分类查全率为91.39%。另外,三条曲线中黄色带圆圈标记的曲线代表迁移VGG-SHTM分类查全率,基本处在最上方,如图6所示。蓝色带菱形标记的曲线代表VGG19的分类查全率,基本处在中间的位置。最下面位置的红色带五角星标记的曲线表示的是SHTM的分类查全率。因此综合表2和图6中的实验结果,证明迁移VGG-SHTM在10次实验中的分类查全率相较SHTM和VGG19是最高的,其分类效果表现更好。

表2 驾驶行为异常检测结果Tab.2 Test Results of Abnormal Driving Behavior

图6 驾驶行为异常平均分类查全率Fig.6 Average Classification Recall Rate of Abnormal Driving Behavior
另外,为了对算法稳定性进行分析,分别计算在整个实验过程中三种分类方法的极差值和方差值结果,如表3所示。其中迁移VGG-SHTM的计算结果用加黑粗体表示。根据表3中的结果显示,三种方法中,VGG19的分类查全率方差为1.94%,排在第一,分类查全率极差为13.89%,排在第一;SHTM的分类查全率方差为0.52%,排在第二,分类查全率极差为8.33%,排在第二;迁移VGG-SHTM的分类查全率方差为0.27%,排在第三,分类查全率极差为5.56%,排在第三。根据三种方法的极差值和方差值结果显示,迁移VGG-SHTM在驾驶行为检测数据集上的分类结果最为稳定,而VGG19的分类结果跳动幅度最大。

表3 三种分类方法的差值结果Tab.3 Difference Results of Three Classification Methods
从实验结果可以看出,三种方法中SHTM的最高分类查全率和平均分类查全率是最低的,最低分类查全率基本处于最差的水平。迁移VGG-SHTM的最高分类查全率、最低分类查全率和平均分类查全率最高。而VGG19的最高分类查全率和平均分类查全率处于中等水平,最低分类查全率处于最差水平。并且迁移VGG-SHTM的分类查全率方差值和极差值最小,SHTM其次,而VGG19的分类性能最不稳定,具有最大分类查全率极差值和最大分类查全率方差值。表明对于驾驶行为异常分类,SHTM的分类性能最差,分类效果比较稳定;VGG19的分类性能其次,但是其分类准确率跳动性大;迁移VGG-SHTM的分类性能最好,且稳定性最高。实验证明,迁移VGG-SHTM方法能够有效的进行异常驾驶行为检测。
4 结论
基于迁移学习方法,提出VGG19和SHTM相结合的迁移VGG-SHTM算法,并将其用于驾驶行为异常检测中。针对驾驶行为检测数据集,进行驾驶行为异常检测实验,通过对比SHTM、VGG19和迁移VGG-SHTM在数据集上的分类效果,得出以下结论:(1)所提出的迁移VGG-SHTM算法能够有效地克服冗余信息较多的图像分类问题,对比SHTM算法,分类精度得到了提升;(2)将迁移VGG-SHTM应用于驾驶行为异常检测中,获得了很好的效果,证明了对于小批量的驾驶行为检测数据集,该方法具有良好的分类性能。
猜你喜欢
西南师范大学学报(自然科学版)(2022年1期)2022-03-02
华南师范大学学报(自然科学版)(2021年3期)2021-07-03
五邑大学学报(自然科学版)(2020年4期)2020-12-09
杭州电子科技大学学报(自然科学版)(2020年1期)2020-04-09
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
现代电子技术(2018年20期)2018-10-24
现代情报(2018年11期)2018-01-07
