
基于机器学习算法的食品污染物神经毒性预测模型建立
2022-04-28 09:01周悦李潇岚程薇冯艳王艳
现代食品科技 2022年4期
周悦,李潇岚,程薇,冯艳,王艳,2*
(1.上海交通大学医学院公共卫生学院,上海 200025)(2.上海交通大学医学院附属第九人民医院,上海 200011)
神经毒性是外源性化合物引起的神经系统结构或功能的损害,而经口摄入是众多可导致神经毒性中毒症状的化学品重要的暴露方式之一[1,2]。如今随着食品工业的发展,食品种类增多,食品中添加剂使用的增加,许多食品化学污染物如重金属、食品添加剂、农药兽药残留物等,均可诱导发生氧化应激、神经细胞发育受损、神经递质含量变化等各种神经系统损伤,严重威胁人体健康[3-5]。因此,神经毒性评估成为了食品污染物暴露毒性评价必不可少的环节。传统的神经毒性评估主要通过动物实验测试进行。但动物实验周期长且成本高昂,在高通量筛选和人类中枢神经系统的外推性方面存在一定的局限性[6]。因此,迫切需要开发替代方法和工具,来评估化学品的神经毒性。
定量构效关系(Quantitative StructureActivity Relationship,QSAR)是目前常用的毒性预测模型之一,利用化合物的物理化学、几何等结构信息,预测其可能的生物活性[7]。分子描述符分为2D和3D描述符。虽然3D描述符在模拟分子受体配体对接,处理空间化学方面可能有更大的优势,但2D描述符具有无需估算生物活性构象,计算成本低,数据处理快的优点[8],同时预测结果依然优异[9,10]。QSAR已被成功运用于经口毒性判断和内分泌干扰物筛选[11],但针对神经毒性,相关研究多聚焦于同源化合物,纳入同属数据集建立,如多氯联苯类(Polychlorinated Biphenyls,PCBS)[12]、芳基氨基脲类化合物等[13],通过同源化合物间的相似结构构建线性模型,分析特定取代基或分子结构与其神经毒性间关联[14]。因食品中的化学性污染物来源广泛、种类繁多,化合物的结构特征多样,神经毒性症状各异且毒性作用靶点各不相同,化合物可通过影响神经分化成熟、神经元迁移/空间定向、突触形成/可塑性、神经递质、神经营养功能、神经免疫系统、神经内分泌、离子稳态干扰等功能诱发神经毒性[15]。因此,传统QSAR线性模型不适用于食品化学污染物分子结构与神经毒性关联的建立。机器学习算法中的监督学习,在学习框架的基础上半自动化创建分析模型,并通过交叉验证和迭代改进以细化和优化预测模型的准确性,具有“多指标、多关联、多交叉”的特点,尤其适用于大规模样本的归纳研究[16]。
考虑到该模型的适用范围和高通量筛选的需要,本研究将选则2D描述符用于神经毒性预测模型的建立。通过支持向量机、随机森林、神经网络等机器学习算法,构建食品化学污染物神经毒性分类预测模型。据此阐明影响化合物神经毒性的主要分子结构因素。进一步了解化合物性质,为后续化合物的毒性预警及风险评估开展提供参考依据。
1 材料与方法
1.1 数据库的建立与神经毒性资料获取
从现有文献[17,18]、政府通告的违法食品添加物或新检出物、生活常见药物和食品安全污染物中选择了107种化合物组建数据库。化合物组成包括20种杀虫剂(18.69%)、14种阻燃剂(13.08%)、16种多环芳烃(14.95%)、19种食品包装化工原材料(17.76%)、6种食品添加剂或污染物(5.61%)及32种药物(29.91%)。选择现有人类、非人灵长类动物、哺乳动物实验以及体外细胞实验中,有两篇及以上出版物表明其具有神经毒性的化合物做阳性判定。选择现有文献中无神经毒性相关实验,实验结果矛盾或仅单细胞系体外实验阳性的化合物做阴性判定[19]。根据以上判定原则,最终获得包含各类神经毒性机制,如阻碍神经元发育成熟、干扰神经递质传递、影响突触形成等化合物57种,及明确无神经毒性化合物50种。数据库于2020年5月完成建立,于2021年5月对化合物文献检索结果进行更新。
1.2 数据集的建立
按8:2比例随机划分训练集及测试集,训练集用于模型构建,测试集用于模型验证[20,21]。
1.3 描述符的获取与特征选择
分子描述符是化合物物理化学性质的量化表征,其将分子中的结构化学信息,转换成特定的指标或某些标准化实验的结果,其选择一定程度上决定了模型的优劣[22,23]。2D分子描述符一般包括:(1)组成描述符(如分子量、卤素类型);(2)拓扑描述符(如Wiener指数、Randic指数);(3)电子描述符(如极性指数、Hammett常数);(4)几何参数描述符(如分子体积、溶剂接触面积)等[24,25]。本研究从pubchem网站获取化合物的2D分子结构信息,导入MOLD2(2.0)软件后计算得到777个分子描述符。考虑到疏水性在经口毒性预测、药物筛选方面的重要作用,使用Episuite(version 4.1 US EPA 2012)及VEGA(core version1.2.1 IRFMN)软件,计算常见于相关毒性预测模型中的正辛醇-水分配系数(Octanol-Water Partition Coefficient,Kow)纳入研究[26,27],并针对以上778个计算变量开展特征选择。
特征选择主要由以下五个步骤组成。(1)删去恒定、半恒定(相同取值比例>0.85)描述符后剩余472个计算变量。(2)二元logistics回归完成描述符的初步筛选。(3)结合已有文献经验,补充纳入现有研究中广泛运用于预测药物吸收、代谢、毒性的相关描述符,包括:分子量、柔性可旋转键数、Kow、拓扑极性表面积等[24,28]。(4)将472个描述符和训练集89种化合物带入五种机器学习模型并分析计算变量重要性,纳入重要性排名前五位者。(5)删去重复后将以上合计52种计算变量纳入随机森林模型进行拟合,采用递归特征消除法进行重复构建和计算变量筛选,每次构建删除其中最不重要的变量[29]。最终纳入如表1所示5种描述符,主要覆盖化合物可旋转键数、电拓扑、分子极性相关性质,包括1个原子数和键数描述符、2个理化性质描述符、2个拓扑描述符。根据“Rule-of-Thumb”规则,2D-QSAR模型中训练集(N)与描述符(M)的比值(N/M)应不小于5,本研究所得最优模型的N/M为17.80>5,满足此项规则,表明描述符的选择数量适当[30]。

表1 构建QSAR模型所使用描述符Table 1 The descriptors used in QSAR model
1.4 模型的构建
共采用5种机器学习算法[25,28,31]:
由于数据集的各个特征取值范围存在较大差异,对描述符取值进行标准化处理:
式中:
X——化合物描述符参数数值;
μ——参数平均值;
σ——参数标准差。
1.4.1 贝叶斯网络(Bayesian Network,BN)
贝叶斯算法适用于基于定量研究的不确定性推理,利用概率统计对未知样品进行分类。变量间的关系强度由两个概率组成,一为条件概率,可被父节点个数和局部概率影响,二为节点固定先验概率。贝叶斯网络要求各个变量在除父节点以外节点间条件独立,现有研究中可见于方剂配伍规律等药性研究[32]。使用Rstudio(version 4.0.2下同)“e1071”软件包中的“naiveBayes”函数实现。
1.4.2 随机森林(Random Forests,RF)
随机森林算法因其易于理解、执行力高等优势常见于药物安全性评价等药物分析领域[32]。研究中使用随机森林算法的基分类器为cart算法,通过重采样方法生成随机自助训练集,未被纳入训练集样本称为袋外样本。构建多颗树后选择最佳模型输出。使用Rstudio软件“randomforest”软件包进行模型构建和优化,“pROC”软件包进行图形绘制,“varImpPlot”函数进行模型参数重要性可视化。最终构建模型节点中二叉树变量个数(mtry)取值为3。构建基分类器模型数量(ntree)取值为500,最小子节点(nodesize)取值为1,由于特征参数较少,不对最大子节点数加以限制。
1.4.3 类神经网络(Artificial Neural Network,ANN)
类神经网络具有强大的拟合能力和自我学习能力,用于非线性映射回归、多分类预测类研究[33]。从信息处理角度对人脑神经元网络进行抽象,包括接受外部信号数据的输入单元、完成系统结果对外传递的输出单元,和不能由系统外部观察得到的隐藏单元。本研究采用ANN中的多层感知机反向传播算法(BP)的三层人工神经网络进行拟合。使用Rstudio软件“nnet”软件包进行模型构建。同时为进一步增加模型稳定性,避免过度拟合,使用SPSS MODELER(version18.0 IBM)软件中的bagging算法模块对原ANN模型进行优化,合并基分类器规则设定为投票。bagging组件模型数为10。
1.4.4 支持向量机(Support Vector Machine,SVM)
支持向量机相较于类神经网络,更适用于高纬度、小样本回归或二分类研究[34],在现有研究中常根据待测化合物特征加以选择,构建毒性预测模型。作为一种常见的,对数据进行二元分类的广义线性算法,其决策边界是对学习样本求解的最大边距超平面。当线性不可分时,将松弛变量引入超平面,并在模型中产生另一个惩罚系数。使用Rstudio软件“e1071”软件包中的“svm”函数进行模型的构建,核函数为分类非线性SVM中使用最多的高斯径向基核(RBF),运用“tune”函数试错法将γ范围设定为10^[-6,-1],惩罚因子C范围设定为10^[1,4]进行模型优化,最终选择最佳参数γ取值0.1,C取值1000。
1.4.5 K最近邻值算法(K-NearestNeighbor,KNN)
KNN算法依靠距离划分未知样本类别,通过寻找多个离测试样本最邻近的训练样本,以该样本的多数类别作为最终类别,操作简单结果容易解读,可见于部分药物分析模型[35]。但这一计算方法不适用于大样本数据,且样本不平衡时,模型预测偏差较大[36]。本研究通过SPSS.MODELER软件KNN模块进行内部十折交叉验证选择最合适K值,距离计算方法为Euclidean法。最终模型选定K值为6时具有最低错误率。
1.5 模型的评价与验证
本研究采用十折交叉检验进行数据集内部鲁棒性验证,即将原始数据随机平均分为10个子集,每个子集做测试集的同时,其余9个子集合并作为训练集,进行10次训练预测[37]。十次十折交叉验证由Rstudio软件完成。测试集化合物分类进行外部验证,使用Rstudio软件“confusionMatrix”函数输出混淆矩阵,计算其中的真阳性(True Positive,TP)、真阴性(True Negative,TF)、假阳性(False Positive,FP)、假阴性(False Negative,FN),分别计算灵敏度(Sensitivity,SE)、特异度(Specificity,SP)、假阳性率(False Positive Rate,FPR)、假阴性率(False Negative Rate,FNR)、总准确性(Global Accuracy,GA)。通过“pROC”软件包绘制受试者工作曲线(Receiver Operating Characteristic,ROC)并计算曲线下面积(The Area Under The ROC Curve,AUC)进行模型评价。
2 结果与讨论
2.1 描述符共线性分析
5种描述符间相关性分析结果如表2所示,可见任意两个描述符间相关系数<0.75。描述符之间不存在明显的共线性问题。
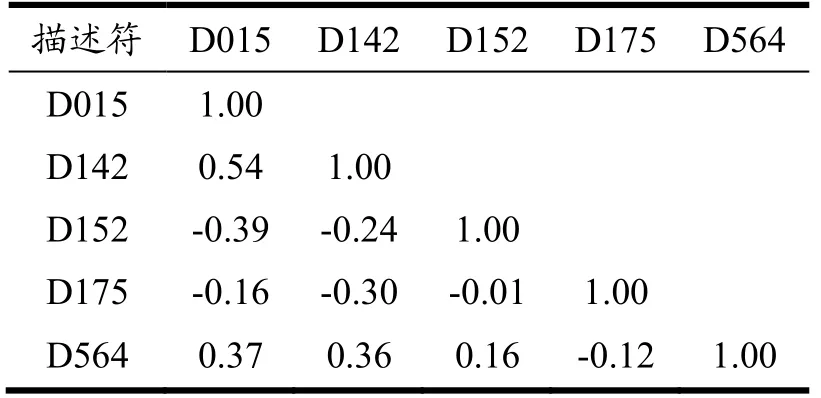
表2 5个分子描述符的相关矩阵分析Table 2 Correlation matrix analysis of five molecular descriptors
2.2 模型质量评价
在进行数据分割后,训练集和测试集分别有89和18种化合物,且类别分布较为均匀无需进行数据不均衡处理。具体数据见图1。
五种机器学习的表现各不相同,根据外部验证的结果,五种模型中随机森林模型综合表现最优。训练集中灵敏度91.49%、特异度100.00%,GA和AUC均超过90%。在测试集中表现也较为稳定,灵敏度、特异度分别为80.00%、87.50%,同时GA和AUC均超过80%。具体数据见表3。

表3 基于5个描述符对于神经毒性预测训练集及测试集的统计结果Table 3 Statistical results of neurotoxicity prediction training set and test set based on 5 descriptors
模型鲁棒性检验结果显示,在五种模型中,随机森林模型表现最为稳定,测试集平均准确率达到70.24%。其次为ANN和KNN模型,准确率分别为67.34%和64.50%。支持向量机和贝叶斯模型的鲁棒性稍差,分别为61.28%和62.91%。
模型的预测准确性方面,随机森林的模型表现也更优,训练集准确性为95.51%,测试集准确性为83.33%,该模型给出的训练集、测试集ROC曲线如图2所示,曲线下面积可达到0.99和0.85,是个较为理想的分类模型。
目前已有少量研究利用机器学习算法建立了的化合物毒性预测模型。如一项基于概率神经网络算法(PNN),纳入47种有机溶剂作为研究对象,预测其神经毒性的分类模型。训练集、测试集中GA分别达0.91、0.93,曲线下面积分别达0.92、0.94[38]。一项基于RF算法,纳入61种农药作为研究对象,预测其熊蜂急性接触毒性的分类模型。训练集、测试集中GA分别达0.83、0.87,曲线下面积分别达0.91、0.92[39]。相较于前两种模型较为局限的化合物类别,本研究纳入的食品污染物种属各异,脱离了传统的线性模型和化合物类型的限制。在扩大模型适用范围的同时,保持了较高的总预测准确度和AUC值,训练集、测试集AUC分别达0.99、0.85。而相较于现有的大样本中药的神经保护作用预测模型(训练集SE:0.67、SP:0.99;测试集SE:0.69、SP:0.98)[40],极大的提高了模型灵敏度,训练集、测试集灵敏度分别达0.91、0.8,适用于大样本数据库化合物神经毒性的初步筛查。
2.3 分类错误案例分析
如上文所述,随机森林算法对数据库中化合物具有较好的分类准确率,但预测模型中仍有一些化合物不能被正确的分类,分类错误的7个化合物的结构、错分类型和描述符数值如表4、表5所示。
表4、表5数据表明,该随机森林模型在特异度上表现良好,但预测化合物时存在一定的的假阴性现象。同时,描述符D564(质量加权Burden矩阵最大特征值)取值可能在一定程度影响模型对于化合物神经毒性的判定,D564取值大的化合物更倾向于被判定为阳性,而D564取值小的化合物则相反。
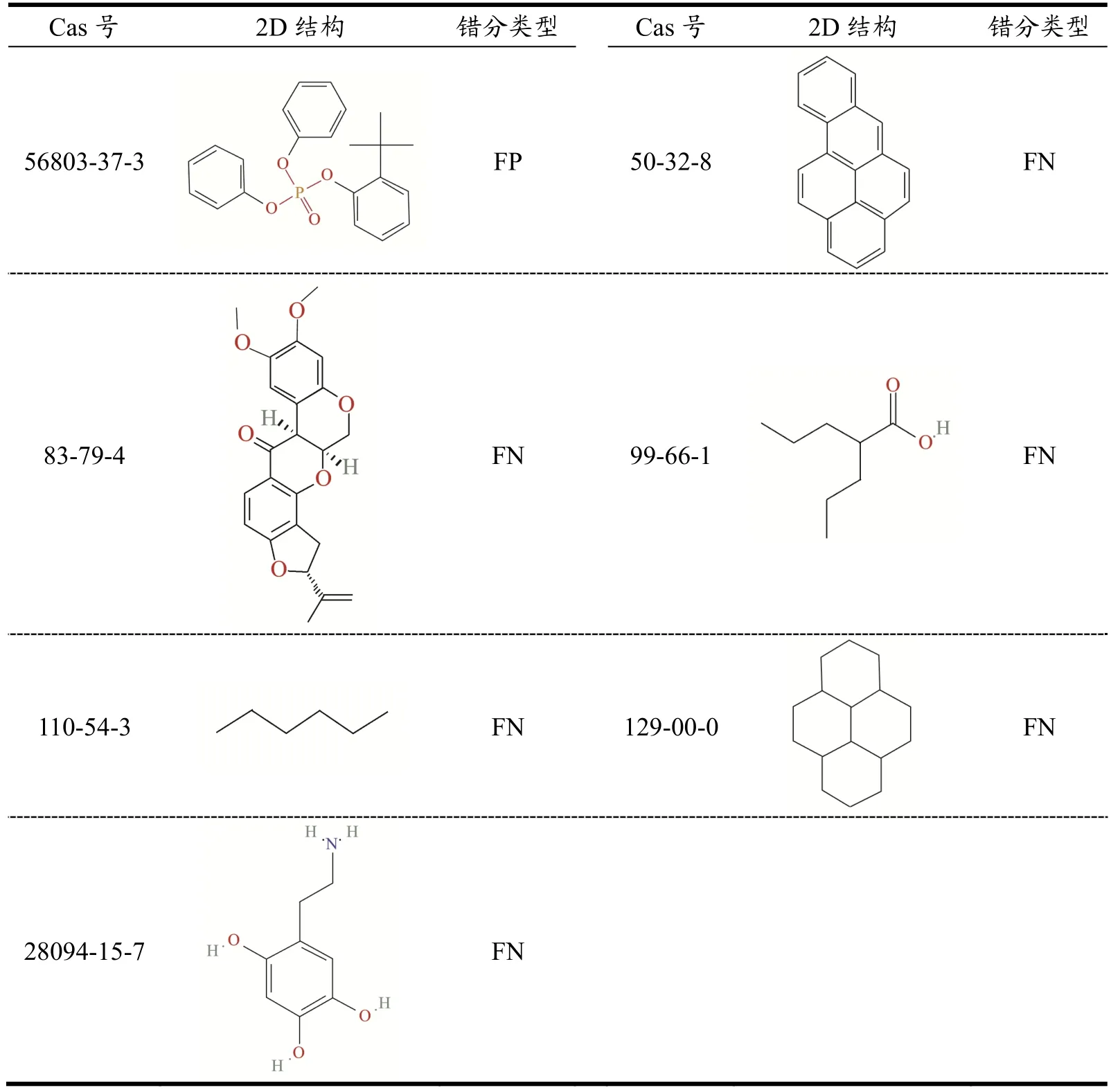
表4 随机森林算法中分类错误化合物Table 4 Misclassified compounds in random forest algorithm
化合物分类错误的原因可能由活性悬崖(化合物具有类似结构但活性不同)和骨架跃迁(化合物具有不同结构但活性相似)导致,如苯并(a)芘和苯并(b)芘。而化合物中质量加权Burden矩阵最大特征值在化合物神经毒性推断方面可能有比较重要的作用。为了进一步验证该结论,我们选取了两种已知神经毒性,且D564描述符相差较大的数据库外化合物作为参考带入模型,具体化合物和描述符取值见表5。结果支持这一推论。本研究模型相较于现有研究中基于SVM算法的周围神经病变预测模型(训练集、测试集GA均为0.89,未见AUC指标)[41],具有更好的模型解读能力,强调了质量加权Burden矩阵最大特征值在化合物神经毒性预测中的作用。未来研究中我们将进一步增加数据库中化合物数量,突破单一模型限制,构建集成模型以提高化合物神经毒性预测准确性和普适性,有望用于指导高风险化合物的毒性测试筛选策略的制定。
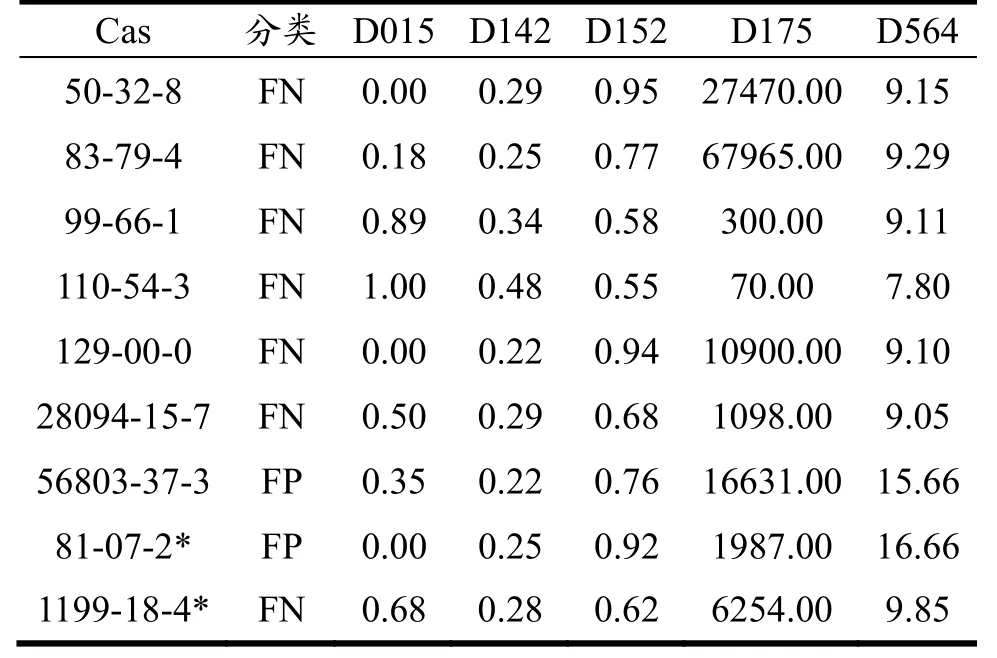
表5 错误分类化合物及库外参考化合物描述符取值Table 5 Misclassified compounds and values of off-library reference compound descriptors
3 结论
3.1 本研究收集整理了具有影响神经分化成熟、神经元迁移/空间定向、突触形成/可塑性、神经递质、神经营养功能、神经免疫系统、神经内分泌、离子稳态干扰等诱发神经毒性机制的食品污染物57种,无神经毒性污染物50种共107种食品污染物,运用5种机器学习算法,建立了食品化学污染物神经毒性预测模型。
3.2 运用R和SPSS软件对778个计算变量进行了筛选,最终确定将5个分子描述符纳入模型,即D015可旋转键数比例、D142 Balaban均方顶点距离指数、D152碳-sp3的平均原子极化率、D175 Wiener最大路径指数和D564质量加权Burden矩阵最大特征。
3.3 5种机器学习算法中,基于随机森林算法建立的分类模型具有最好的预测效果,外部验证中训练集灵敏度91.49%、特异度100.00%,总准确性95.51%,测试集灵敏度80.00%、特异度87.50%,总准确性83.33%,曲线下面积分别达0.99和0.85。内部验证中模型鲁棒性达70.24%。模型预测结果中共有7种化合物不能被正确分类,造成这一结果的原因可能是活性悬崖或骨架跃迁现象的存在。在五种分子描述符中,质量加权Burden矩阵最大特征值对预警化合物高风险结构特征贡献最佳。
猜你喜欢
四川蚕业(2022年2期)2022-11-19
实用手外科杂志(2022年2期)2022-08-31
当代水产(2022年6期)2022-06-29
现代临床医学(2022年1期)2022-02-12
当代水产(2021年6期)2021-08-13
昆明医科大学学报(2021年2期)2021-03-29
中学化学(2017年6期)2017-10-16
中学化学(2017年6期)2017-10-16
中学化学(2017年2期)2017-04-01
试题与研究·高考理综化学(2016年3期)2017-03-28
