
广东省碳排放量测算、影响因素分析及预测模型选择
2022-05-09 10:32任峰龙定洪
生态经济 2022年5期
任峰,龙定洪
(华北电力大学 经济管理学院,河北 保定 071003)
以二氧化碳为主的温室气体排放量的显著增加,已经导致全球极端气候事件频发,严重威胁了人类正常的生产和生活秩序。2019年中国碳排放量101.7亿吨,约占全球碳排放总量的28%,中国的碳排放形势不容乐观,碳减排任重道远。作为负责任的大国,中国积极参与全球环境治理,2015年向联合国提交了“国家自主决定贡献”,承诺2030年碳达峰,碳排放强度比2005年下降60%~65%[1]。2020年中国提出要提高国家自主贡献力度,努力争取在2060年前实现碳中和[2]。中国一系列的表态和承诺显示了中国碳减排的决心。
广东省是中国经济实力最强、人口规模最大的省份之一。2019年广东省的地区生产总值超过10万亿人民币,人口占全国总人口的8.23%,城镇化率超过了70%,在经济、政治、文化等方面充分发挥着“试验田”“桥头堡”和“示范区”的作用。与此同时,广东省的能源消费量和碳排放量持续增长,2019年广东省碳排放权交易市场排放配额总量为4.65亿吨,成为总体规模排名全国第一、全球排名第三的区域性碳市场。因此,就碳排放研究而言,广东省可以看作一个示范案例,为省级低碳发展探索方向和路径。研究广东省碳排放影响因素和选择科学可行的碳排放预测方法具有十分重要的现实意义和理论价值。
现有对碳排放的研究多集中于碳排放量测算、影响因素分析及各层面、各行业的碳排放量预测等。碳排放量的测算多以能源消费碳排放作为重点,刘玉珂和金声甜[3]测算了2005—2016年中部六省能源消费碳排放量,并将其作为后续研究的基础;郭炳南等[4]首先对1997—2014年长三角地区能源消费二氧化碳排放量进行了测算,而后进行实证研究。以上研究得到了一些有意义的成果,然而由于忽视了工业生产、农业活动等碳源和森林、耕地等碳汇的核算,会影响到以碳排放量为基础的相关研究的可靠性。
对于碳排放影响因素,国内外现有文献一般从人口、经济发展、产业结构等方面,采用Kaya恒等式、STIRPAT模型、对数平均迪式分解法(LDMI模型)、结构分解技术等方法对碳排放和各影响因素之间的动态效应关系进行分解分析。刘晓燕[5]运用STIRPAT模型分析了江苏省工业能源消费碳排放的影响因素;付云鹏等[6]利用Kaya恒等式改进模型结合LMDI分解法对中国碳排放量的影响因素进行了分解分析。
在以往碳排放量预测研究中,灰色预测模型、BP神经网络、系统动力学等方法得到了广泛应用。Wang& Ye[7]构建非线性灰色多变量模型预测了中国化石能源消耗的碳排放量;董聪等[8]基于趋势外推法、BP神经网络模型对中国2030年碳排放进行情景预测;刘菁和赵静云[9]利用系统动力学预测了建筑运行使用阶段的碳排放量。随着人工智能技术的发展,机器学习工具在处理非线性问题上展现出了强大的能力,且智能优化算法和机器学习工具结合的混合模型优于单一预测模型,能进一步提高预测精度。徐勇戈和宋伟雪[10]应用模糊布谷鸟搜索算法(FCS)优化支持向量机模型(SVM)对建筑业碳排放预测问题展开了研究;王珂珂等[11]构建了一个基于鲸鱼优化(WOA)算法改进的极限学习机模型(ELM),对中国2019—2040年的碳排放量和碳排放强度进行预测;Qiao等[12]将狮群优化算法(LSO)和遗传算法(GA)相结合预测了2018—2025年部分发达国家和发展中国家的碳排放量。
现有的研究文献为我们进行碳排放相关研究提供了宝贵的方法和理论参考,但综合分析可知,在碳排放量的测算上,以往研究几乎没有考虑工业生产等碳源和森林等碳汇的影响,影响因素的指标选择缺乏科学依据以及研究对象的针对性,且大部分研究多选择时间序列预测、计量回归模型等方法,在预测效果上相较于优化算法与机器学习工具相结合的模型可能存在更大误差。基于以上分析,本文更全面地核算了除能源消费碳排放外的碳源和碳汇,并将其作为预测研究的基础;构建扩展STIRPAT模型分析广东省碳排放的影响因素,并根据广东省在对外交往方面的优势,将对外开放作为一个重要的影响因素指标;为提高预测精度,更好地反映数据之间的非线性映射能力,本文充分利用鸡群算法(CSO)的全局寻优能力和快速学习网(FLN)预测小样本数据精度高的特点,构建出CSO-FLN预测模型,并将预测误差与FLN和ELM模型进行对比分析,以表明其在预测效果上的优越性,为碳排放预测后续研究提供有效的建模方法。
1 碳排放量测算及影响因素分析
1.1 碳排放量测算
参照《IPCC国家温室气体排放清单(2006)》[13]及《省级温室气体清单编制指南》[14]中碳源碳汇的核算内容和方法,本文主要对能源消费、工业生产、秸秆燃烧、牲畜肠道发酵和粪便管理、工业及生活废水排放、稻田甲烷排放等碳源,森林、果园、耕地、城市绿地等碳汇进行核算,碳源量和碳汇量之间的差额即为净碳排放量,各类碳源碳汇的测算方法见表1,各类能源碳排放、秸秆燃烧碳排放的相关计算参数见表2和表3。

表1 碳源碳汇测算方法
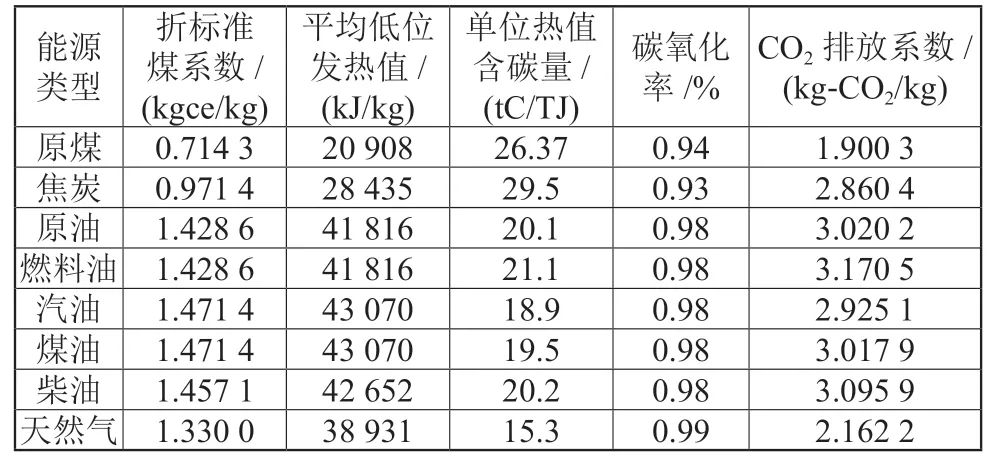
表2 各类能源碳排放的相关系数
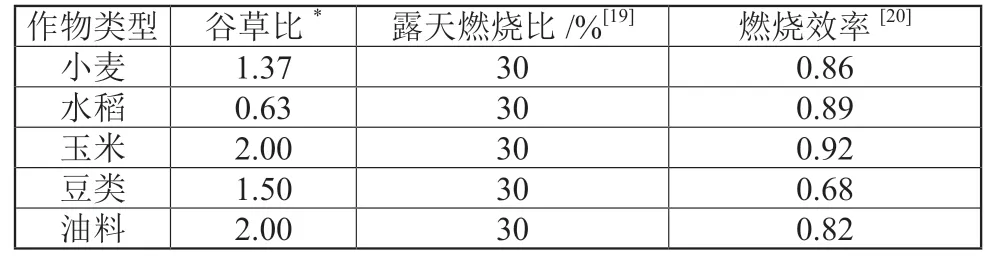
表3 秸秆燃烧碳排放计算主要参数
1.2 影响因素分析
在进行碳排放预测前,分析各种因素对碳排放的影响能为碳排放预测研究提供基础。本研究选取STIRPAT模型即可拓展的随机性环境影响评估模型,来研究各社会经济因素对环境压力(碳排放)的影响。该模型是在经典的IPAT模型的基础上提出的,用于分析P(人口)、A(富裕度)、T(技术)与I(环境压力)之间的关系,其标准形式为:

式中:a表示常数项;b、c、d是需要估计的指数;e表示误差项。该模型是一个多自变量的非线性模型,模型两边取对数后得:

为了从多维度分析广东省碳排放的影响因素,本文考虑广东省在国际交往上的优势和产业发展特点,将对外开放和产业结构作为重要的指标,构建扩展STIRPAT模型如下:
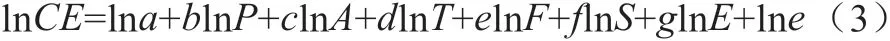
式中:CE表示碳排放量;P为人口数量,以年末常住人口表示;A为富裕度,以人均GDP表示;T为技术水平,以能源强度表示;F为对外开放,以外商直接投资占GDP比重表示;S为产业结构,以第二产业增加值占GDP比重表示;E为能源结构,以煤炭消费量占能源消费总量比值表示。
考虑数据的可获得性,本文将研究区间设为1995—2019年,部分缺失数据通过预测方法得到。各影响因素数据及碳排放量测算所需的数据来自国家统计局网站、《广东省统计年鉴》、《中国能源统计年鉴》、《广东能源平衡表》、IPCC温室气体排放清单核算、中国森林资源统计、林业局有关报告等。为剔除价格因素的影响,GDP等社会经济数据通过GDP指数调整为以1995年为基期的实际数。
2 碳排放量预测模型构建
2.1 鸡群算法
鸡群算法[21]是一种模拟鸡群觅食行为的群智能随机优化算法,表现为子群的划分和等级关系、伙伴关系、母子关系的建立。每个子群由一只公鸡、多只母鸡和小鸡组成,不同类型的鸡遵循不同的觅食规律,鸡的类型和种群关系每隔G代更新一次。
在最小化问题中,每个鸡个体对应优化问题的一个可行解。假设种群中的个体数为N,所求优化问题的维度即食物搜索空间为D维。公鸡、母鸡、小鸡、妈妈母鸡的数目分别为:RN、HN、CH、MN。第t次迭代时,第i个个体的空间位置为为适应度值,用优化问题的目标函数表示,适应度值最好的个体被分配为公鸡,最差的个体被分配为小鸡,其余的个体为母鸡。
公鸡在每个子群中占主导地位,具有更大的食物搜索范围,其位置更新公式为:

式中:randn(0,σ2)表示服从均值为0,标准差为σ2的高斯分布的随机数;k为除公鸡i外随机选择的一只公鸡;fi、fk表示公鸡个体i和k的适应度值;ε表示一个极小的常数,保证分母不为0。
母鸡依据其所在子群的公鸡和种群中其他的公鸡或母鸡寻找食物,且在上一时刻的位置对下一时刻位置的影响会随迭代次数增加递减,以避免陷入局部最优。母鸡的位置更新公式为:
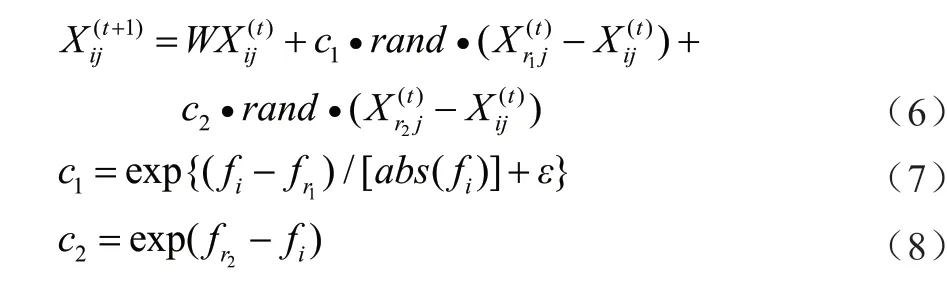
式中:c1表示母鸡所在子群中公鸡的影响因子权重;c2表示鸡群中随机选择的公鸡或母鸡的影响因子权重;r1表示子群的公鸡个体;r2表示整个鸡群中随机选择的公鸡或母鸡,且r1≠r2;rand表示在区间[0, 1]上均匀分布的随机数,W表示二次非线性递减权重函数[22],其表达式为:

式中:Wmax和Wmin分别表示惯性权重的最大值和最小值,设定为0.9、0.4;Tmax表示最大迭代次数。
小鸡跟随其妈妈母鸡搜索食物,其位置更新公式为:
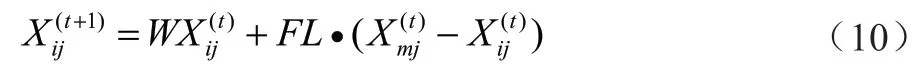
式中:m表示小鸡跟随的妈妈母鸡;FL为跟随系数,FL∈[0, 2];W的含义及取值和母鸡相同。
为了提高CSO算法的性能,本文对母鸡和小鸡的觅食行为进行改进,将母鸡的位置更新方式分为两种:

而小鸡在寻找食物时,不仅跟随在母鸡周围,还会跟随子群中的公鸡觅食,因此小鸡的位置更新公式为:
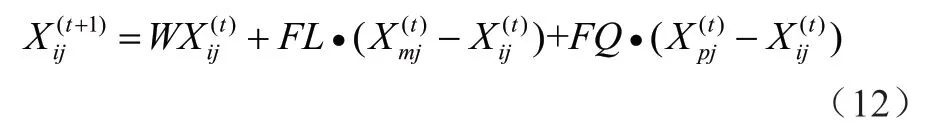
式中:p表示子群中的公鸡;FQ为跟随系数,FQ∈[0, 2]。
2.2 快速学习网算法
快速学习网(FLN)[23]是一种新型双并联前馈神经网络。与极限学习机不同的是,FLN增加了输入层与输出层之间的直接联系,可以看作是一个隐含层到输出层的非线性与输入层到输出层的线性组合模型。它能随机产生输入层和隐含层之间的连接权值和隐含层阈值,设置隐含层神经元个数后就能得到唯一的全局最优解,有较强的处理非线性问题的能力,其网络结构如图1所示。
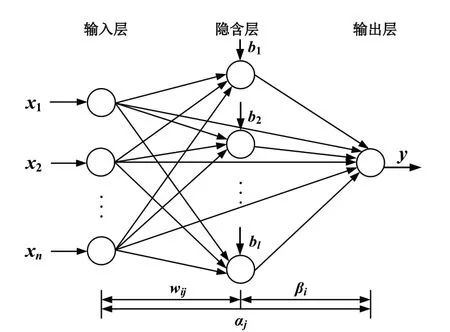
图1 FLN网络结构图
假设有q个样本{(Xi,Ti)}(i=1, 2, …,q),其中,Xi=[xi1,xi2, …,xin]T∈Rn表示第i个样本的n维输入向量,T=[T1,T2, …,Tq]T∈Rq表示样本的输出值。由于本文是对碳排放量进行预测,所以输出层节点数只有一个。令隐含层节点数为l,隐含层激励函数为g(x),B=[b1,b2,…,bl]T表示隐含层节点的阈值向量。输入权重矩阵为Wl×n=[W1,W2,…,Wl]T,隐含层和输出层之间的连接权值为β=[β1,β2, …,βl],输入层与输出层之间的连接权值为α=[α1,α2,…,αn],构建FLN的数学模型为:

式中:Xi表示第i(i=1, 2, …,q)个样本的输入向量;Ti表示第i个样本的输出向量。
用矩阵形式表示为:


式中:M(n+l)×1表示输出权值矩阵;Hq×l表示隐含层输出矩阵;Tq×1为期望输出。
前馈神经网络模型在训练样本时的目标是使输出的误差最小,即最小,其中Yi为预测值,Ti为实际值。训练样本的误差可表示为:

当激励函数g(x)可微时,Wj、bj随机分配,H就变成一个确定的矩阵,训练一个FLN模型相当于求线性 系 统Gq×(n+l)·M(n+l)×1=T的 最 小 二 乘 解M(n+l)×1,其 中

式中:G+为G的Moore-Penrose广义逆矩阵。
FLN模型随机生成输入权值和隐含层阈值,通过最小二乘法计算得到输出层权值矩阵,其计算步骤如下:(1)随机生成输入权值W和隐含层阈值B;(2)计算隐含层输出矩阵H;(3)计算输出权值矩阵M,即将M分为αT和βT。
2.3 CSO-FLN预测模型
由于在FLN模型的训练过程中,隐含层和输入层之间的连接权值以及隐含层的阈值都是随机设定的,可能存在某些随机设定的值为0,导致部分隐含层节点无效的情况。针对随机选择参数的盲目性,本文利用鸡群算法对FLN模型的输入权值W和隐含层阈值B进行迭代寻优,以提高FLN模型的预测精度,CSO优化FLN模型的步骤见图2。将W和B作为鸡群算法的鸡个体,将训练样本的均方根误差(RMSE)作为鸡群算法的目标函数即适应度值,适应度值越小,对应个体代表的输入权值和阈值越好。

图2 CSO优化FLN参数流程

3 结果与分析
3.1 碳排放量测算结果
根据碳源碳汇的测算方法和数据,计算得到广东省1995—2019年的碳排放量及碳排放强度,如图3所示。

图3 1995—2019年广东省碳排放量及碳排放强度变化趋势
总体上看,1995—2019年广东省的净碳排放量呈增长趋势,由1995年的142.798 2百万吨增至2019年的732.683 1百万吨,净碳排放绝对增量为589.884 9百万吨,年均增长率为7.05%,广东省的碳减排情形仍不容乐观。2012年广东省净碳排放量出现了首次下降,随后又继续保持增长态势,此结论与田中华等[24]和林金钱[25]的研究结果一致,这可能与广东省在2012年实施的“十二五”主要污染物总量减排实施方案和淘汰落后产能计划有关。
从碳排放强度来看,研究期间内广东省的碳排放强度大致呈现出下降趋势,由1995年的2.406 8吨/万元下降至2019年的0.680 5吨/万元,碳排放强度绝对减量为1.726 3吨/万元,年均下降率为5.23%。2005年前的碳排放强度表现为波动下降,而2005年后持续下降,但下降速率有所减缓。
3.2 影响因素分析结果
为验证序列数据是否存在非平稳性,避免出现伪回归现象,本文运用EVIEWS软件对所有变量进行单位根检验和协整检验,结果显示所有变量二阶差分后的序列都变得平稳,且变量之间存在稳定均衡关系。运用SPSS对碳排放量和所有影响因素进行普通最小二乘回归分析和多重共线性检验,结果显示,所有变量的方差膨胀因子(VIF值)都大于10,特别是lnGDP的VIF值更是高达342.095,表明变量间存在严重的多重共线性。鉴于此,本研究采用岭回归方法对扩展STIRPAT模型进行重新拟合,岭回归结果(表4)显示,当岭参数k大于0.12后,自变量的回归系数趋于稳定。

表4 扩展STIRPAT模型岭回归结果
由回归结果可知,除能源结构满足10%的显著性水平外,其他影响因素均满足1%的显著性水平,调整R2均大于0.99,且F统计量也通过了1%的显著性水平检验。从回归系数看,人口规模、富裕度、产业结构与碳排放量之间均存在正相关关系,其中产业结构对碳排放的促进作用最大;对外开放、技术水平、能源结构对碳排放增加起抑制作用,三者的抑制效果差异不明显。
3.3 CSO-FLN模型预测精度检验
3.3.1 数据预处理
由于各影响因素的量纲不同,数量级差别较大,需对各变量的原始数据进行归一化处理,归一化公式为:

式中:为归一化后的数据;xi为初始数据;xmin是原始数据最小值;xmax是原始数据最大值。
3.3.2 CSO-FLN模型训练
对预测模型的参数进行初始化,CSO种群规模设置为100个;最大迭代次数为500次;关系更新频率为10次;rpercent、hpercent、mpercent分别设定为0.20、0.65、0.50。输入层神经元数即影响因素个数为6个,输出层神经元为1个,表示碳排放量。结合经验公式将隐含层神经元数设定为4个;隐含层激励函数选用“sigmoid”函数,即g(x)=1/(1+e-x)。将上述6个影响因素作为CSO-FLN预测模型的输入变量,以碳排放量作为输出变量,选取1995—2014年的20个样本作为训练样本Xtrain,用于训练和验证,选取2015—2019年的5个样本作为预测样本,用于检验CSO-FLN模型的预测精度和模型泛化能力。利用MATLAB软件对CSO-FLN模型进行训练,训练结果如图4所示。
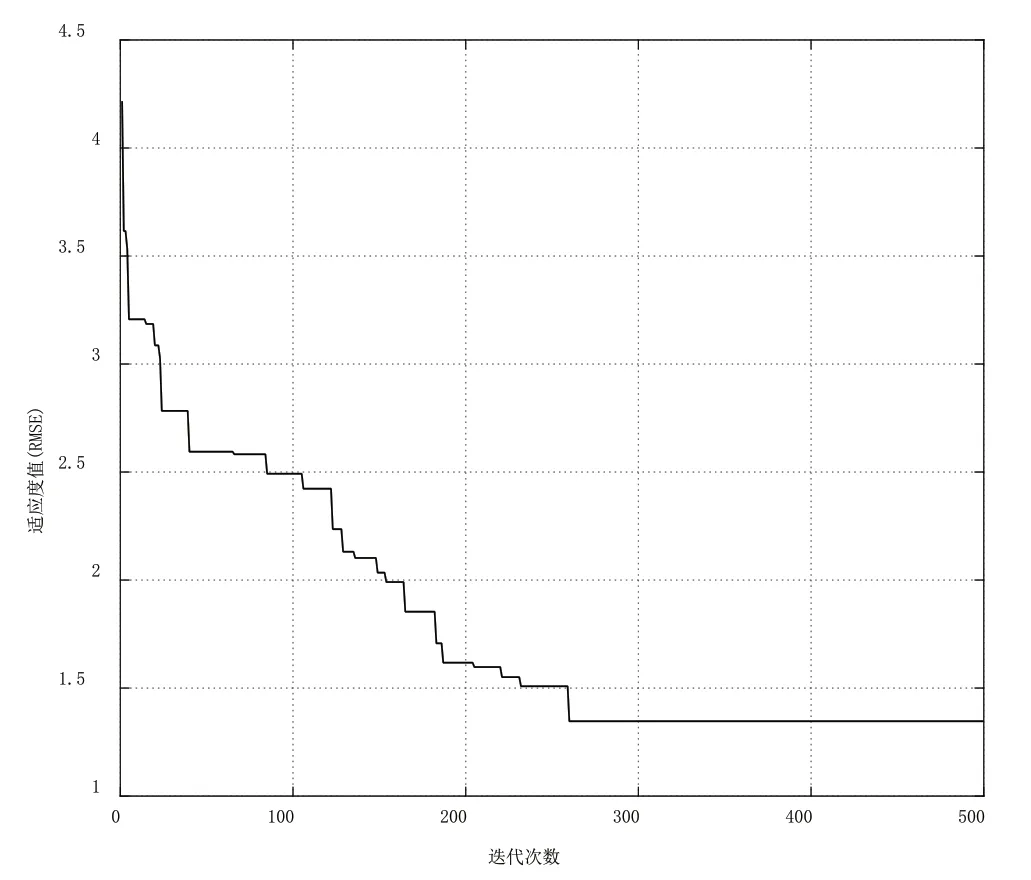
图4 训练样本的适应度值变化趋势
由图4可知,CSO-FLN碳排放预测模型的适应度值随着迭代次数的增加而减小,在经过500次迭代后,得到最优适应度值1.3467,避免了过早收敛和陷入局部最优,说明利用CSO算法优化FLN模型的输入权值和隐含层阈值是有效的。
3.3.3 模型预测效果对比
为探究CSO-FLN模型对碳排放影响因素拟合的优越性,本文依次运用FLN、ELM、CSO-FLN模型对广东省2015—2019年的碳排放量进行预测,并结合平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、均方根误差(RMSE)三个误差指标对各模型的预测精度进行比较分析,计算公式如式(21)~(23)所示。各模型的输入变量、输出变量和样本数据以及内部参数设置均相同,将三种算法分别运行50次,求得预测结果的平均值,得到2015—2019年广东省碳排放量拟合结果如图5所示,三种模型的误差指标计算结果如表5所示。

表5 各模型误差指标计算结果

图5 CSO-FLN、FLN、ELM模型预测结果对比

由预测结果可知,本文构建的CSO-FLN模型的碳排放预测值相比于ELM、FLN模型更接近实际值,说明在分析小样本数据、处理非线性问题时,CSO-FLN模型具有更强的性能。通过对比三个误差指标,可以发现CSO-FLN模型预测结果的平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、均方根误差(RMSE)均小于FLN和ELM模型,证明鸡群算法对快速学习网参数优化的效果明显。总体来说,CSO-FLN模型表现出了良好的预测精度,通过优化FLN的参数能进一步提高预测性能,比FLN、ELM模型更适用于碳排放预测研究。
4 研究结论
本文对广东省各类碳源和碳汇进行了核算,测算出了1995—2019年广东省的净碳排放量和碳排放强度;利用扩展STIRPAT模型分析了广东省碳排放量与各影响因素之间的动态效应关系;运用鸡群算法(CSO)优化快速学习网(FLN)的输入权值和隐含层阈值,构建了CSO-FLN预测模型,通过对比2015—2019年CSOFLN、FLN、ELM模型的碳排放量预测误差指标,验证了本文构建的CSO-FLN模型的优越性和其作为后续广东省2030—2060碳排放量预测方法的可行性。本文得到的主要研究结论如下:
(1)研究期内,广东省的净碳排放量总体呈增长趋势,年均增长率为7.05%,碳排放强度呈下降趋势,年均下降率为5.23%,广东省的碳减排情形仍不容乐观。
(2)扩展STIRPAT模型回归结果显示,人口规模、富裕度、产业结构与广东省碳排放量之间呈正相关关系,其中产业结构对碳排放增长的促进作用最大;对外开放、技术水平、能源结构与广东省碳排放量之间呈负相关关系。
(3)与FLN、ELM模型相比,本文提出的CSOFLM预测模型在2015—2019年广东省碳排放量预测上表现出了更高的预测精度,各项误差指标均小于FLN、ELM模型,能更好地处理小样本预测问题,可作为碳排放发展趋势预测研究的有效模型。
后续研究可结合情景分析方法,设置不同发展情景,利用CSO-FLM模型预测广东省2030—2060年碳排放量及碳排放强度,研究在不同发展情景下广东省能否如期实现碳达峰和碳中和,探索广东省实现碳达峰和碳中和目标的优化路径。
猜你喜欢
吉林畜牧兽医(2022年9期)2022-11-16
文萃报·周五版(2020年37期)2020-10-12
看世界·学术上半月(2020年9期)2020-09-10
读者·校园版(2020年11期)2020-06-04
河北工业大学学报(2019年4期)2019-09-10
农民致富之友(2019年35期)2019-01-13
现代畜牧科技(2018年6期)2018-10-21
科技视界(2016年1期)2016-03-30
物联网技术(2015年7期)2015-07-21
