
湿加松针叶儿茶素和表儿茶素总量近红外光谱预测模型的建立
2022-05-18 03:39曾韦珊黄林旺吕欣欣毛积鹏冯志恒刘天颐黄少伟
中南林业科技大学学报 2022年4期
曾韦珊,黄林旺,吕欣欣,毛积鹏,2,冯志恒,刘天颐,黄少伟
(1.华南农业大学 a.林学与风景园林学院;b.广东省森林植物种质创新与利用重点实验室,广东 广州 510642;2.台山市红岭种子园,广东 台山 529223)
湿加松Pinus elliottii×P.caribaea是湿地松Pinus elliottii与加勒比松Pinus caribaea,包括古巴本种、洪都拉斯和巴哈马变种的杂交子代,为20世纪50年代由澳大利亚昆士兰林业研究所培育,其综合了双亲的优良特性,具有生长速度快、生长量大、耐水湿、树干通直、抗性好等优点[1-2],目前在我国南方省区广泛使用。松针(pine needles)为松科植物Pinaceae 松属Pinus植物的针形叶,其含有丰富的营养成分和黄酮类活性物质,具有多样的保健作用,如抗衰老氧化[3]、抗癌[4]、抑菌[5]等。类黄酮(flavonoids)化合物是具有广泛生物活性的植物次生代谢产物,主要包括查耳酮、黄酮、黄酮醇、黄烷双醇、花色素苷、缩合单宁等,其参与植物的生长发育和防御,是植物色素的主要来源,在植物各个部位都有积累,此外,类黄酮化合物的抗氧化、抗癌、抗诱变、抗紫外线辐射等作用对人类的健康有积极作用,其中黄酮类成分儿茶素和表儿茶素具有抗氧化、抗心血管疾病、抗癌等作用[6]。目前检测植物提取物中活性成分的方法主要有高效液相色谱-质谱(HPLC-MS)、气相色谱-质谱(GC-MS)、紫外分光光度计法等[7],虽然上述测定方法精准度较高,但存在预处理复杂、操作过程中试剂易污染、不易操作、成本高等局限性[8]。
近红外光谱(Near Infrared Spectroscopy,NIRS)技术能将光谱测量、化学计量学和基本测量相结合,对样品成分含量进行快速检测,可以客观地反映样品成分的整体物质基础,并反映其有机成分、矿物质组成和特征成分。相比于其他技术,具有操作简便、高效、低成本、分析时间短等优点[9],已被广泛应用于农林业[10]、食品[11]、医药[12]等领域。在林木研究中,近红外光谱技术被用于营养物质含量检测、品种鉴别、霉变和缺陷判别等方面,如Yi 等[13]预测了在570~1 840 nm波段内的核桃营养成分,其中水、蛋白质、脂肪的决定系数(R2)分别为0.952、0.977 和0.990,预测均方根误差(RMSEP)分别为0.058、0.182和0.191;Manfredi 等[14]利用便携式红外光谱仪与多元统计分析结合对榛子品种分类,发现向后消去偏二乘(backward elimination partial least square,BE-PLS)分类模型的交叉验证准确率达98.18%,比偏最小二乘(partial least square,PLS)高;Canneddu 等[15]用近红外光谱预测影响澳洲坚果风味的过氧化值(peroxide value,PV)和酸度指数(acidity index,AI),过氧化值的R2为0.72,酸度指数的R2为0.8。本研究用96 份湿加松松针粉材料,构建了儿茶素和表儿茶素总量近红外模型,能够快速测定湿加松松针中的活性成分含量,为湿加松高含量活性成分的筛选提供基础。
1 材料与方法
1.1 试验材料
以种植于广东省台山市红岭种子园的6年生湿加松子代测定林为研究材料,于2019年8月随机采取111 个生长旺盛且无病虫害单株的当年生松针组织部位鲜样约100 g,立即将采集到的松针样品带回实验室去除枝梢、枯叶。利用鼓风干燥箱在75℃条件下对松针进行加热干燥,干燥时间为72 h。干燥后的松针经过充分粉碎后过60 目筛,装入密封袋,得到111 份湿加松松针粉末样本。随机选择其中96 份样本作为预测集,其余15 份样本作为外部验证集。
1.2 试验方法
1.2.1 湿加松针叶儿茶素和表儿茶素含量的测定
样品前处理。用电子天平称取200 mg 湿加松松针粉样本,放入2 mL 离心管中。加入600 μL甲醇溶液,涡旋振荡30 s,室温超声15 min。12 000 r/min 4℃离心10 min,吸取上清液并使其过0.22 μm 滤膜,将过滤液装入检测瓶待分析。
液质联用仪分析条件。美国Waters 公司API5000 三重四极杆液质联用仪,色谱条件:色谱 柱ACQU ITY UPLC®BEH C18(2.1×100 mm,1.7 μm),柱温40℃,进样量5 μL。流动相:以0.1%甲酸作A 相,甲醇为B 相,流速0.25 mL/min。洗脱梯度:10% B,0~1 min;10 %~33 % B,1~3 min;33 %,3~10 min B;33%~50% B,10~15 min;50%~90% B,15~20 min;90 % B,20~21 min;90%~10% B,21~22 min;10% B,22~25 min。
质谱条件。电喷雾负离子源(ESI),用多重反应离子监测(MRM)模式进行扫描,离子源温度500℃,电压4 500 V,气帘气是30 psi,碰撞气为6 psi,雾化气和辅助气均为50 psi。
1.2.2 光谱采集
使用型号为DA7200 的近红外光谱分析仪(瑞典波通仪器公司),在进行光谱采集前将样品放置于温度为22℃左右的实验室中24 h,扫描样品前仪器开机预热30 min,光谱扫描波长为950~1 650 nm,光斑直径为3.5 cm,SPC 文件分辨率为5 nm,光谱采集速度约为100 条光谱/s,扫描次数为100 次/s。每一个松针粉样品扫描3 次,重复装样3 次,取平均光谱,保存数据用于后续分析。
1.2.3 光谱预处理
近红外光谱仪除了采集样品本身的信息外,还包含了噪音、样品背景、杂散光等其他信息。为了消除干扰信息,提高模型精准度,需对原始光谱进行异常样品的剔除、降噪、有效信息提取等预处理。常用的预处理方法有:平滑(Smoothing)、导数(Derivative)、数据增强变换(Data enhancement)、标准正态变量变换(Standard normal variable transformation,SNV)、多元散射校正(Multiplicative scatter correction,MSC)和傅里叶变换(Fourier transform,TF)等[16]。平滑算法(Smoothing)假设光谱噪声是以零为中心而产生的均匀随机白噪声,若多次测量求取平均值可消除噪声并提高样品信号;样品的不均匀性、光透过样品或从样品反射回来产生的散射会对样品光谱带来误差,标准正态变量变换算法(SNV)可以用来校正因散射而引起的光谱误差,在光谱研究中有着广泛的应用;多元散射校正将样品集的平均光谱与每个样品任意波长点下反射吸光度值看成近似线性关系,以消除由样本颗粒分布不均匀、颗粒大小不同所产生的散射对光谱的影响,校正光谱信息;导数算法是近红外模型中常用的一种预处理方法,其能够有效消除基线漂移和其他干扰背景,提高模型准确性。
1.2.4 近红外模型的建立
在获得近红外光谱数据以及参照数据以后,依次进行光谱数据预处理、建立近红外模型、模型外部验证3 个步骤。将采集的光谱数据导入The Unscrambler 软件,光谱波长范围为950~1 650 nm,对光谱进行预处理,用偏最小二乘法(Partial Least Square Regression,PLS)回归分析建立模型,在PLS 算法中采用交叉证实法。偏最小二乘判别分析法根据观察或测量到的若干变量值对研究对象进行判别分析,是一种有监督的判别分析方法,其可以减少变量间多重共线性产生的影响,并根据不同处理样本的特征建立一定的判别准则,即要求由各因素构成的数据矩阵X分解得到的隐变量t与由各目标构成的数据矩阵Y分解得到的隐变量u相关程度最大或重叠最大,并利用它对新的观测对象进行类别判定[17]。模型建好后,剔除异常值优化模型,得到湿加松儿茶素和表儿茶素总量预测最优近红外模型。
1.2.5 近红外模型的评价
在建立光谱模型的过程中,需要借助化学计量学指标对模型的好坏进行统计分析。本研究采用样本校正相关系数R2、校正均方根误差RMSEC、交互验证相关系数R2cv、交互验证均方根误差RMSEV、预测均方根误差RMSEP 等参数评价模型的质量,公式如下[18]:

式(1)~(2)中:n为样品数,Si为实测值,为实测值的平均值,为预测值。
在上述指标中,R2、R2cv、RMSEC、RMSEV和RMSEP 是有效评价模型的指标,其中,R2、评价模型的拟合效果,RMSEC、RMSEV 和RMSEP 评价模型的预测精度。模型中校正集相关系数R2和交互验证集相关系数的值越接近1,校正集均方根误差(Root Mean Square Error of Calibration,RMSEC)和交互验证集均方根误差(Root Mean Square Error of Validation,RMSEV)值越小,则模型的预测效果越好[19]。通过验证集进行外部验证检验模型质量,得到的相关系数(Related coefficient,R)越高,预测均方根误差(Root Mean Square Error of Prediction,RMSEP)越低,模型效果越好。此外,模型的校正集、预测集和验证集各个评价指标越接近,说明最终得到的模型效果越好、越理想。
2 结果与分析
2.1 松针粉儿茶素和表儿茶素实测值的数据特征
松针粉样品的儿茶素和表儿茶素含量用液质联用仪测定(表1),96 个校正集样品儿茶素和表儿茶素总量最小值为2.7660 μg·g-1,最大值为66.9120 μg·g-1,平均值为17.5294 μg·g-1,标准差为11.1553 μg·g-1。15 个验证集样品儿茶素和表儿茶素总量最小值为8.5960 μg·g-1,最大值为28.9250 μg·g-1,平均值为15.715 0 μg·g-1,标准差为5.6942 μg·g-1。
2.2 96 个样品近红外原始光谱
近红外光谱是分子在近红外光照射下,伸缩振动产生的倍频与伸缩振动和弯曲振动产生的合频吸收,其与分子的结构密切相关,分子结构不同或所处化学环境不同,产生的光谱信息有明显差异,因此,可通过分析样品吸收光谱时得到的光谱信息,统计数据建立模型。本实验通过软件The Unscrambler 9.7 采集96 个湿加松松针粉样品的近红外反射光谱,得到样品的近红外原始光谱图,如图1所示。光谱波段为950~1 650 nm,从图中可看到一个显著的吸收峰,样品的吸光度在0.2 以下,同一波长不同样品的吸收强度各不相同,但是不同波长下所有样品的走势、波峰、波谷基本相似,在1 460 nm 处吸收峰较强。每份样品在同一波长下的吸光度不同,表明湿加松松针粉样品间儿茶素和表儿茶素总量有差异,近红外光谱和成分含量之间的关系可以通过建立数学模型来反映。

表1 湿加松针叶儿茶素和表儿茶素总量校正集与验证集统计表Table 1 Statistical table of total amount of catechin and l-epicatechin correction set and verification set of Pinus elliottii×P.caribaea needles

图1 96 个校正集样品近红外原始反射光谱Fig.1 Near infrared original reflection spectrum of 96 correction set samples
2.3 近红外模型预处理结果
本研究用一种及多种处理方法结合对近红外原始光谱进行预处理,结果见表2。不同的预处理方式对湿加松儿茶素和表儿茶素总量的建模效果不同,分别采用Smoothing S.Golay、MSC 和Normalize 方式处理模型,模型并未得到明显优化,甚至处理后的参数值比原始参数低;而对模型分别进行SNV、Derivatives S.Golay、Smoothing S.Golay+Derivatives S.Golay+SNV、Derivatives S.Golay+MSC、Smoothing S.Golay+Derivatives S.Golay+MSC、Derivatives S.Golay+SNV、Smoothing S.Golay+Derivatives S.Golay 预处理,模型得到了优化,且预处理方式为Smoothing S.Golay+Derivatives S.Golay 时,模型的校正相关系数R2和交互验证相关系数R2cv值最大,校正均方根误差RMSEC 和交互验证均方根误差RMSEV值最低,模型达到最佳。
2.4 近红外模型的建立
使用The Unscrambler 9.7 软件对近红外光谱数据进行处理,用偏最小二乘法(Partial least squares method,PLS)交叉验证(Cross validation)建立近红外光谱预测模型,建模波段为950~1 650 nm,主成分数为16,预处理方法为Smoothing S.Golay+Derivatives S.Golay,预处理后光谱图如图2所示。建模结果见图3,儿茶素和表儿茶素总量最优模型的校正相关系数R2为0.935 2,交互验证相关系数R2cv为0.754 5,表明模型拟合度高,校正均方根误差RMSEC 为2.145 8,交互验证均方根误差RMSEV 为4.313 3,模型预测能力良好。

表2 湿加松儿茶素和表儿茶素总量不同预处理模型结果Table 2 Results of different pretreatment models of total catechin and l-epicatechin in Pinus elliottii × P.caribaea
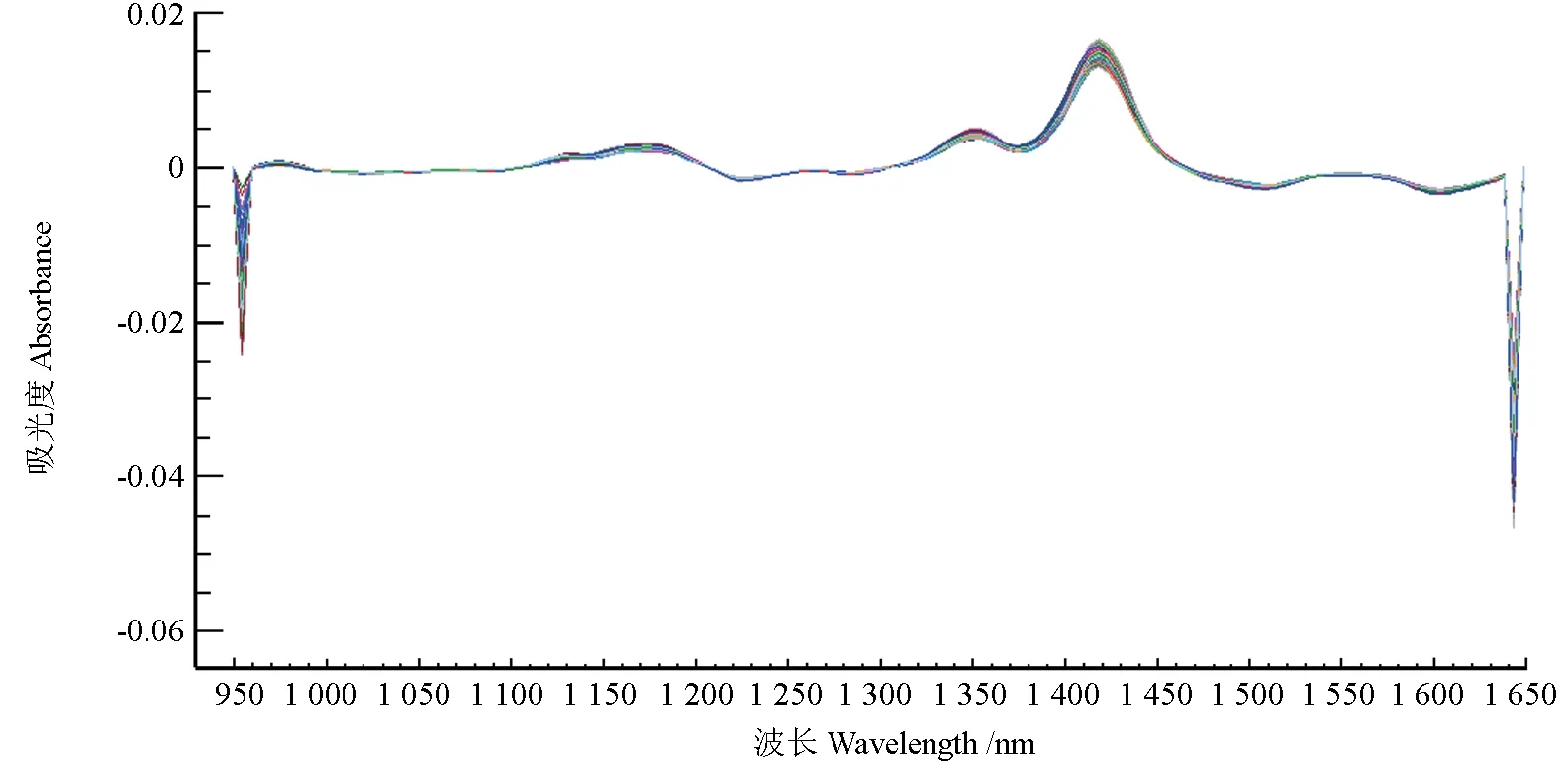
图2 Smoothing S.Golay+Derivatives S.Golay 处理红外光谱图Fig.2 Near infrared spectrogram processed by Smoothing S.Golay+Derivatives S.Golay Method
2.5 儿茶素和表儿茶素定量分析模型的验证
随机选取15 份(不包括校正集样品)样品对已建立的近红外模型进行外部验证,结果表明,松针样品的儿茶素和表儿茶素含量的外部检验相关系数为0.833 9,预测均方根误差RMSEP 为3.739 1,绝对误差在0.02~8.82 之间,相对误差在0.19%~50.53%之间,表明模型的预测值与真实值吻合程度高,可用于样品含量的初步预测。

图3 湿加松针叶儿茶素和表儿茶素总量模型预测结果Fig.3 Prediction results of total needle catechin and l-epicatechin model of Pinus elliottii×P.caribaea
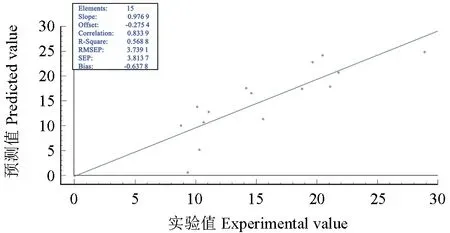
图4 儿茶素和表儿茶素总量模型的外部验证结果Fig.4 External validation results of total catechin and l-epicatechin model
3 讨 论
近红外光谱分析的核心在于基于化学计量学的数学模型建立,在采集光谱的过程中往往会受到仪器自身或者外部测试环境等因素的影响而产生噪声,需对原始光谱进行预处理。光谱预处理方法对建立预测能力强、稳定性好的模型尤为重要,在不同物种最优近红外模型建立中,预处理方法不尽相同,如油菜硫苷近红外模型采用Derivatives SG3+SNV 预处理,建立的模型较好[20];向日葵籽仁油酸、亚油酸和棕榈酸的最佳光谱预处理方法分别为SNV+1st,MSC+1st,SNV[21];在建立杉木中综纤维素和木质素含量近红外模型时,采用二阶微分处理和平滑预处理,所得模型可快速测定木材中综纤维素和木质素含量[22];在梨果糖浓度的近红外光谱预处理方法研究中,王伟明等[23]发现使用平滑预处理得到的模型较好。本研究对湿加松儿茶素和表儿茶素总量的近红外模型采用了10 种预处理方式,发现预处理方法为Smoothing S.Golay+Derivatives S.Golay 时模型最优,建立的模型能够满足样品成分含量的快速测定。
利用近红外光谱技术测定儿茶素和表儿茶素含量,目前已有相关报道,因材料、方法等不同,有些方法对儿茶素含量的评估效果较为理想,有些则效果不佳。李赛楠等[24]建立火炬松表儿茶素近红外预测模型,经过MSC+FD+S.Golay 预处理后,校正相关系数RC为0.973 9,模型达到最优;黄俊仕等[25]建立了检测绿茶滋味品质指标酚氨比近红外预测模型,并将近红外光谱技术与化学计量学方法结合,有效提高检测精度;陈华才等[26]用近红外光谱技术对茶多酚中的总儿茶素含量进行测定,发现波长为1 000~2 500 nm,光谱经过SNV 预处理后,建模效果最好;刘洪林[27]对功夫红茶咖啡碱和5 种儿茶素组分进行近红外快速测定,发现6 种成分中儿茶素模型预测能力最低,表儿茶素居中,总体上各模型预测性能优;郭志明[28]利用近红外光谱检测绿茶中的有效成分,结果发现LS-SVM 模型的泛化能力和预测精度俱佳;陈美丽等[29]对茉莉花中的主要成分建立近红外光谱分析模型,发现模型中儿茶素和表儿茶素的预测值与真实值间相关系数达0.9 以上,模型预测准确性高。
迄今为止,基于近红外光谱技术对湿加松针叶儿茶素和表儿茶素总量测定的研究未见报道。本研究建立的湿加松针叶儿茶素和表儿茶素总量近红外预测模型,准确度高,重复性好,可靠性好,可用于湿加松针叶儿茶素和表儿茶素总量的快速测定和质量评价,有助于今后湿加松高含量活性成分的优良个体的筛选,为今后培育高产、优质的湿加松个体奠定基础。但本试验对仪器的稳定性要求严格且建模所采用的松针样品数量有限,故建立的模型有一定的局限性,今后可加大建模样本量进一步提高模型的预测效果。
4 结 论
本研究采用近红外光谱技术,选择Smoothing S.Golay+Derivatives S.Golay 预处理方法,剔除数据中的异常值,建立了湿加松针叶儿茶素和表儿茶素含量的近红外预测模型。校正相关系数R2为0.935 2,校正均方根误差(RMSEC)为2.145 8,交互验证相关系数R2cv=0.754 5,交互验证均方根误差(RMSEV)为4.313 4,外部验证相关系数R为0.833 9,预测均方根误差(RMSEP)为3.739 1。模型的相关系数较高,表明建立的近红外光谱预测模型精度高,预测效果佳,适用于湿加松针叶儿茶素和表儿茶素含量的快速鉴定,有利于加快对高含量生物活性成分的湿加松个体筛选的研究。
猜你喜欢
动漫界·幼教365(大班)(2020年11期)2020-12-22
科教新报(2020年15期)2020-10-21
家庭医药(2020年6期)2020-06-30
江苏农业科学(2020年9期)2020-06-21
飞天(2019年6期)2019-07-08
饮食与健康·下旬刊(2019年10期)2019-03-09
爱你·阳光少年(2018年9期)2018-05-14
长江文艺(2017年11期)2017-11-23
滇池(2017年7期)2017-07-18
新高考·高二数学(2015年2期)2015-05-27
