
基于BERT-BiLSTM模型的短文本自动评分系统
2022-05-20 03:11夏林中叶剑锋罗德安管明祥刘俊曹雪梅
深圳大学学报(理工版) 2022年3期
夏林中,叶剑锋,罗德安,管明祥,刘俊,曹雪梅
深圳信息职业技术学院人工智能技术应用工程实验室,广东深圳 518172
短文本自动评分是指使用计算机对人工问题的语言文本进行自动评分,由于回答问题的语言文本长度一般都较简短,所以称为短文本.近年来,随着教育信息化水平的不断提升,学生借助各种智能终端、互联网及移动互联网进行同步学习,学习过程中会产生大量的过程性语言文本信息.为进一步提升学习效果,需要对这些过程性语言文本信息进行实时分析,并及时向学生反馈分析评价结果,工作量非常大[1].文本自动评价的机器学习算法通过统计分析文本的字数、单词数、拼写错误数、单词平均字母数、句子数及词频-逆文本频率指数(term frequency-inverse document frequency,TF-IDF)等特征来评价文本,可用于实时分析学习中产生的大量过程性语言文本信息.目前基于该思路的商用文本评分器主要包括 PEG(project essay grader)[2]和E-rater(electronic essay rater)[3],其应用效果好,但无法抽取文本的语义特征.潜在语义分析(latent semantic analysis,LSA)算法[4]不仅能获取文本的语义特征,还能解决同义词问题,但计算消耗资源量大,无法获取文本词序信息.LDA(latent Dirichlet allocation)主题模型[5]很好解决了捕获文本词序信息的问题,其计算资源消耗也比LSA小.然而,上述各类算法对于文本深层语义信息与上下文关联信息的挖掘能力非常有限.
近些年深度神经网络(deep neural networks,DNN)算法在文本分析中得到广泛应用[6],其深层语义信息及上下文关联信息的挖掘能力促进了文本自动评分的发展[7].DNN算法中最重要的是如何通过词向量表达文本[8],使用较多的词向量获取方法包括Word2Vec[9]、C&W[10]及GloVe[11]等.用获取的词向量表示文本并作为DNN 的输入,从而实现对文本评分.DNN 主要分为卷积神经网络(convolutional neural networks,CNN)和循环神经网络(recurrent neural networks,RNN),RNN 捕捉较短上下文依赖关系的能力非常强,但上下文之间的距离越长,RNN 的捕捉能力就越弱.RNN 改进型的长短时记忆(long short-term memory,LSTM)神经网络模型[12]更擅长捕捉长距离的上下文依赖关系信息[13].双向长短时记忆(bidirectional LSTM,BiLSTM)神经网络由前后两个方向的LSTM组合而成,能够捕捉当前词与上下文的依赖关系,从而更好地执行文本评分任务[14-15].
BERT(bidirectional encoder representations from transformers)[16]模型是 Google 公司提出的一种基于深度学习的语言表示模型,在11 种不同的自然语言处理测试任务中效果最佳,其中也包括文本分类任务[17-18].基于BERT 模型的文本分类主要包括预训练(pre-training)和预微调(fine-tuning)两个过程,前者利用大规模未经标注的文本语料进行自监督训练,有效学习文本语言特征及深层次文本向量表示,从而形成预训练BERT 模型;预微调则直接通过预训练好的BERT 模型作为起始模型,根据文本分类任务的特点,输入人工标注好的数据集,完成模型的进一步拟合与收敛.本研究结合BiLSTM 与BERT模型的优点,建立BERT-BiLSTM短文本自动评分模型,并针对已人工标注好的短文本数据集进行分析,克服了文本较短且因用语偏口语化带来的特征稀疏与一词多义问题.
1 基于BERT-BiLSTM 短文本自动评分模型
为解决短文本特征稀疏的问题,采用BiLSTM模型捕获隐藏于上下文深度语义依赖关系中的更多特征;短文本的语义针对性强,一词多义现象普遍,采用BERT模型能够较好解决这一问题.
1.1 BiLSTM网络层
BiLSTM模型由1个正向LSTM与1个反向LSTM叠加而成,其具体结构如图1.其中,x1,x2,…,xN为输入词向量;为t时刻正向LSTM 隐藏层的输出向量,由当前时刻输入向量xt和前一时刻的正向LSTM 输出向量共同确定,记为为t时刻反向LSTM 隐藏层的输出向量,由当前xt和前一时刻反向 LSTM 输出共同确定,记为ht为t时刻的BiLSTM 模型输出,由共同确定的 , 记 为其 中 ,wt为 正 向LSTM输出的权重矩阵;vt为反向LSTM输出的权重矩阵;bt为权重矩阵的偏置.
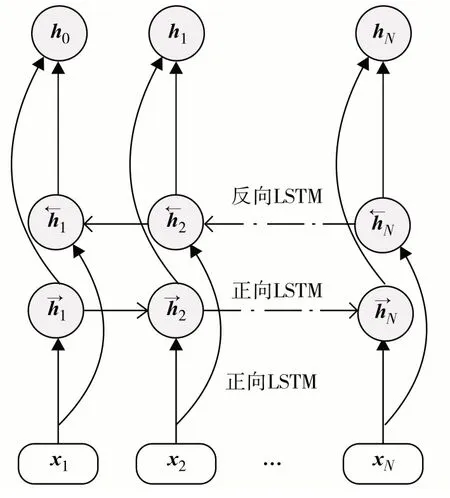
图1 BiLSTM模型结构Fig.1 The architecture of the BiLSTM model
1.2 BERT语言模型
BERT模型是一种旨在取代或改进RNN或CNN的全新架构,其基于注意力机制对文本数据进行建模[19].如图2所示,BERT模型采用12或24层双向Transformer 编码结构,其中,E1,E2,…,EN为输入向量;T1,T2,…,TN为经过多层 Transformer 编码器后的输出向量.BERT 通过大规模语料对模型进行预训练,获取适应通用自然语言处理任务的模型网络参数,再使用当前任务的文本数据对预训练网络参数进行预微调,使模型适应当前任务.
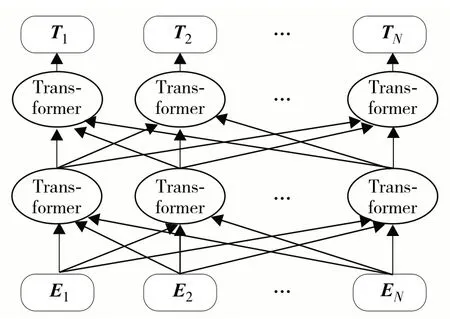
图2 BERT模型结构Fig.2 The architecture of the BERT model
1.2.1 Transformer编码器结构
如图3 所示,Transformer 编码器结构包括自注意力机制(self-attention)和前馈(feed forward)神经网络单元,单元之间设计残差连接层(add&normal).Transformer 是一个基于自注意力机制的Seq2seq 模型,BERT 模型主要使用Seq2seq 的Encoder 部分.自注意力机制单元是Transformer编码器的核心,其计算每个词与其所在句子中所有词的相互关系,据此调整每个词的权重,从而获取每个词新的向量表达式.Encoder 的输入是文本的词向量表示(X1、X2)及每个词的位置信息,将自注意力机制单元的输出进行相加和归一化处理,使输出具有固定均值(大小为0)和标准差(大小为1).归一化后的向量传入前馈神经网络进行残差处理和归一化输出.

图3 Transformer编码器结构Fig.3 The architecture of the Transformer encoder
1.2.2 BERT模型的输入表示
BERT 模型的输入由标记嵌入、分段嵌入和位置嵌入部分叠加表示,如图4.其中,标记嵌入为第1 个标志是E[CLS]的词向量,其初始值可随机产生,E[SEP]为句子间的分隔标志;分段嵌入为区分不同句子向量;位置嵌入表示文本中每个词的位置信息.可见,BERT 模型的输入向量不仅含有短文本语义信息,还包括了不同句子之间的区分信息与每个词的位置信息.
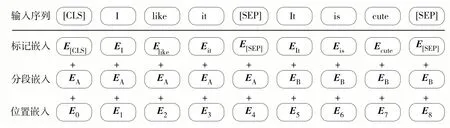
图4 BERT模型的输入Fig.4 Input of the BERT model
1.2.3 BERT模型的预训练与预微调
BERT 模型的预训练过程使用大规模未经标注过的文本语料,经过充分自监督训练后有效学习文本的通用语言特征,得到深层次文本词向量表示,并获得预训练模型.具有逻辑关系与的优点.预训练过程的掩藏语言模型(masked language model,MLM)依据上下文语义信息对随机掩盖的词进行预测,可以更好学习上下文内容特征;下一句预测(next sentence predication,NSP)[20]为每个句子的句首和句尾分别插入[CLS]和[SEP]标签,通过学习句子间的关系特征预测两个句子的位置是否相邻.
预微调过程直接将预训练获取的网络参数作为模型起始,根据下游任务输入人工标注好的数据集,使BERT 模型得到进一步拟合与收敛,得到可用于下游任务的深度学习模型.
1.3 BERT-BiLSTM模型
本研究设计基于BERT-BiLSTM 的短文本自动评分模型,由BERT层和BiLSTM层构成,如图5.其中,为 BiLSTM 层反向 LSTM 隐藏层状态;为 BiLSTM 层正向 LSTM 隐藏层状态 ;T1,T2,…,TN为 BERT 层输出向量;C为BERT短文本级输出向量;E1,E2,…,EN为BERT层词向量输入;E[CLS]为BERT层自动添加的短文本开头表示符号;Tok1,Tok2,…,TokN为短文本输入;[CLS]为随机赋予初值的短文本开头;Softmax回归模型通过分析输入特征向量来对短文本进行分类.BERT 模型针对大规模语料库的预训练可以习得通用语言的语义特征,针对已标注的短文本数据集微调BERT 模型参数,以适应短文本数据集的语义特点.本研究使用的短文本数据集中,有些词的语义与其在通用语言中的语义存在差异,而BERT 模型的输出可以根据上下文信息特点进行调整,即同一词语在不同上下文中对应的向量编码输出不同,这样就可以解决一词多义的问题.BiLSTM 模型能够从前向和后向获取字词与上下文的语义关联信息,进而捕获深层次的上下文依赖关系.

图5 基于BERT-BiLSTM的短文本自动评分模型结构Fig.5 The architecture of the short text automatic scoring model based on BERT-BiLSTM
2 实验与分析
2.1 实验设置
2.1.1 数据集
实验使用的短文本数据集包括训练集和测试集,由Hewlett 基金会提供.训练集和测试集分别包含17 207 篇和5 224 篇已人工评分的短文本,实验从训练集中随机抽取20%的短文本作为校验集.训练集和测试集分别由10个子集组成,见表1.

表1 短文本数据集Table 1 Short text dataset
2.1.2 评价指标与参数设置
本研究采用二次加权kappa(quadratic weighted kappa,QWK)系数[21]κ评估预测分数与专家打分的一致性,且0 ≤κ≤1.κ= 0 表示作文不同评分之间的一致性完全随机;κ= 1 表示作文不同评分之间的一致性完全相同.在预训练好的BERT 模型基础上,采用Adam 优化器对短文本数据集进行预微调,学习率设置为2 × 10-5,权重衰减系数设置为1 × 10-5.
2.2 实验结果与讨论
将本研究BERT-BiLSTM模型的κ值与基准模型CharCNN(character-level CNN)、 CNN、 LSTM 和BERT 进行对比,结果见表2.所有模型均使用相同的数据集,训练集与测试集的短文本篇数相同.

表2 BERT-BiLSTM模型与基准模型的κ值对比1)Table 2 The quadratic weighted kappa coefficients comparison between BERT-BiLSTM model and benchmark models
表2中的合并集表示将子集1至子集10合并为1 个大集合.可见,对比CharCNN、CNN 和LSTM模型,BERT 与 BERT-BiLSTM 的模型的κ值最优;相比BERT 模型,BERT-BiLSTM 模型在子集1、2、5、8、9 及10 上的κ值分别提升了6%、9%、8%、4%、2% 及1%;对比其他所有模型,BERTBiLSTM 模型的κ平均值最高.因此,BERTBiLSTM模型短文本自动评分的整体性能最优.
由表2 还可见,子集3 的κ值最低,这是因为子集3为开放式英语语言文学问题,回答短文本多为学生根据自己的理解对相关语句进行的解释,因此,特征不明显.该子集的上下文关联信息较少,人工评分员在该子集上的评分一致性也很低.
结 语
本研究提出基于BERT-BiLSTM 的短文本自动评分模型,通过BERT 语言模型表示短文本向量、BiLSTM 捕获短文本的上下文信息深层依赖关系,提升了短文本自动评分性能.实验结果表明,本模型不仅在短文本数据集的子集上取得最好的自动评分效果,其整体自动评分性能也优于其他基准模型.后续研究将在本模型的句子表征上融入标点符号及情感词等位置信息,以丰富短文本的句子向量特征表示,并设计出更高效、简洁的神经网络结构,进一步提高短文本自动评分效果.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高一使用)(2021年9期)2021-12-02
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
数学教学通讯·初中版(2015年5期)2015-06-17
都市丽人(2015年4期)2015-03-20
