
基于SSA-PSO-GSA-SVR的全球新冠肺炎疫情分析及预测
2022-05-27 03:43成云云白艳萍谭秀辉
陕西科技大学学报 2022年3期
成云云, 白艳萍, 续 婷, 谭秀辉, 程 蓉
(中北大学 理学院, 山西 太原 030051)
0 引言
时至今日,全球报告的新增病例数仍持续上升,截止到目前为止,全球累计确诊病例已超过4.4亿,仅在过去一周(2月22日28日),全球新增近700多万例新病例,死亡人数新增近4万人[1],相当于每分钟就有近700人被感染新冠病毒,严重危害着人们的身体与身心健康.因此,对疫情传播及发展趋势进行全面、准确、科学的分析和预测,可以为新冠肺炎疫情监测预警系统的建设奠定理论基础,有助于各国家更好的采取预防控制措施.
疫情爆发初期,国内外就有诸多学者对新冠肺炎疫情进行了分析与预测[2-5],有关疫情传播及预测的研究方法主要由传染病动力学模型和时间序列机器学习模型为主要框架.在动力学模型中,SEIR模型作为经典的传染病模型被广泛使用[6-8].但使用传染病动力学模型需要收集和分析大量相关的参数,如R0、就诊率、隔离率等.对于系统中人口数量较多的情况,由于疫情数据的有限性与不完整性,使得动力学模型受到一定的限制.而在机器学习模型中,作为人工智能的核心研究领域,它可以让计算机具备从海量原始数据中提取特征因素、主动寻求系统内部规律的能力,目前已被广泛应用于传染病预测领域[9-11].因此,将其应用到新冠肺炎预警系统中可以突破传统传染病模型的局限性,解决其建模步骤繁杂、考虑因素单一以及提取空间特征受限等问题,从而达到实时、动态预警的目的[12-14].
然而,新冠肺炎传播受多种因素交互影响,具有复杂的非线性特征,且数据样本点较少.针对以上特性,结合SVR在解决小样本问题上的优势将其作为基础预测模型,而单一的SVR模型寻优过程耗时较长,更新速度较慢,对模型的预测精度产生了一定的影响.因此,本文采用PSO-GSA联合算法优化SVR的惩罚参数C和核函数参数g,并利用SSA对原始序列进行去噪得到联合实时动态预测模型(SSA-PSO-GSA-SVR).
1 基本原理
1.1 奇异谱分析
奇异谱分析(Singular Spectrum Analysis,SSA)可以提取出代表原时间序列不同成分的信号,如长期趋势信号、周期信号、噪声信号等[15,16],是一种研究非线性时间序列的有效方法.假设新冠肺炎疫情数据时间序列为XT=(x1,x2,…,xT),其中数据序列x1,x2,…,xT为等间隔采样,长度T为110,具体计算步骤如下:
(1)嵌入
将一维的新冠序列数据映射到多维轨迹矩阵上,如式(1)所示:
(1)
式(1)中:d=10为嵌入维度,以此得到一个Xi=[xi,xi+1,…,xi+d-1]的信号,该步骤的结果是得到一个轨迹矩阵Xi,且Xi为Hankel矩阵,表明每一条沿副对角线的元素都相等.
(2)奇异值分解(SVD)
计算XXT并求得其d个特征值λ1,λ2,…,λd,对应的特征向量为U1,U2,…,Ud,且令d′=max(i,λi>0),由此得到的主成分子空间包含了新冠数据序列的不同的特征,其中每个特征值都代表对应的SVD分量对原始序列的贡献率,则
(2)
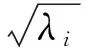
(3)分组
将式(2)划分成m个不同的组以表示不同的新冠肺炎疫情数据序列的节律、噪声等,并将每组内所包含的矩阵相加,则
X=XI1+XI2+…+XIm
(3)
XI=Xi1+Xi2+…+Xip
(4)
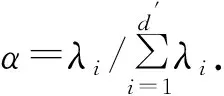
(4)重构
运用对角平均将矩阵还原为长度为N的时间序列,设Y为d×K的矩阵,其元素为yij.令d*=min{d,K},K*=max{d,K}.将矩阵Y变换为Y={y1,y2,…,yN},式(5)为对角平均公式:
(5)
1.2 万有引力搜索算法
万有引力搜索算法(GSA)[17,18]是一种模拟粒子之间万有引力现象的元启发式智能优化算法,其原理为:把搜索空间中运动的粒子看成是优化问题的潜在解,当群体之间存在惯性质量最大的粒子时,其他惯性质量较小的粒子不断趋向靠近惯性质量最大的那个粒子,从而使算法收敛至最佳解.如图1所示,粒子Mi所受到各类粒子的合力F1的方向偏向于惯性质量最大的粒子M4.
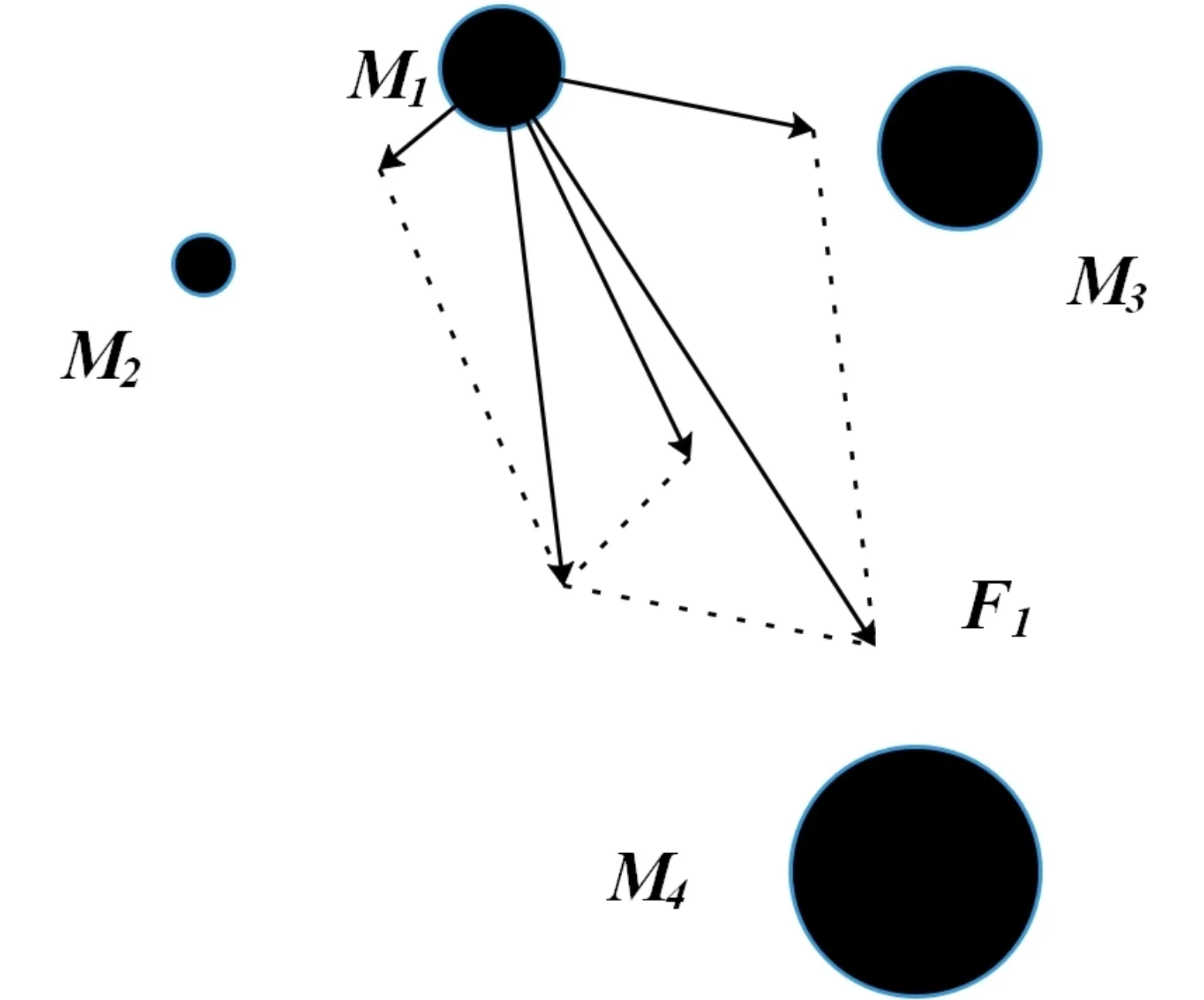
图1 万有引力作用图
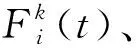
(6)
式(6)中:λ为[0,1]中的一个随机数,β为[0,1]中的一个均匀随机分布.根据牛顿定律,得到粒子惯性质量的更新公式:
(7)
(8)
式(8)中:fiti(t)为粒子i在t次迭代时的适应度函数值,best(t)和worst(t)分别为最佳和最劣的适应度函数值,定义如下:
(9)
以SVR的均方误差MSE作为适应度函数,首先初始化每个粒子的位置和速度,并设置算法的最大迭代次数和参数;然后计算粒子的适应度值,根据文中公式(9)找到best(t)与worst(t)来更新Mi(t);其次计算粒子所受到的合力、加速度,再由公式(6)分别更新粒子的速度和位置;以此迭代循环,直到新冠肺炎疫情预测值的均方误差得到最小的值,终止迭代.
1.3 支持向量回归
支持向量回归(SVR)[19,20]是基于支持向量机(SVM)的一个回归预测算法,在解决小样本、非线性模式识别方面具有独特的优点.其核心思想为:引入核函数将样本空间中非线性回归映射为高维空间中的线性回归问题,即寻找一个最优分类超平面,使得所有训练样本离该最优超平面的误差最小.给定新冠肺炎疫情数据作为训练集D={(x1,y1),…,(xT,YT)},xi∈Rd,yi∈R,i=1,2,…,T,并使用原始疫情数据训练SVR,得到一个最优回归函数:
f(x)=ωTx+b
(10)
式(10)中:w为权值向量,b为偏置向量,根据输入的影响因素xi,由yi=f(xi),得到新冠疫情预测数据yi,通过引入松弛因子,SVR的目标优化函数可表示为:
(11)
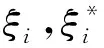
(12)
通过交叉验证选择SVR的最佳参数C和g,在实验中将C和g在2的指数范围网格内进行搜索,先在大范围内粗略寻找最佳参数,缩小C和g的取值范围,然后在此基础上进行精细的参数选择.
2 本文提出的SSA-PSO-GSA-SVR预测算法
综上理论基础和分析,为提高全球新冠肺炎疫情预测模型的预测精度,本文提出了一种SSA-PSO-GSA-SVR联合预测算法,图2为该预测模型整体框架,对原始序列进行SSA去噪得到重构序列,然后构建PSO-GSA联合算法寻找SVR最优的惩罚参数C和核函数参数g,达到优化目的,提出的SSA-PSO-GSA-SVR预测算法主要分为两大块,其算法流程如下:

图2 SSA-PSO-GSA-SVR预测算法流程图
(1)SSA降噪
运用SSA算法将一维新冠疫情时间序列数据转换为多维度序列进行主成分分析,将有效的信号成分进行分组处理,并根据累计贡献率选择若干分量进行重构,然后在重构数据集上进行预测训练.通过SSA分解重构得到的主分量较为规则,具有更好的可预测性.
(2)PSO-GSA优化SVR模型
根据收集到的新冠肺炎疫情数据,使用GSA-PSO-SVR预测模型进行训练时,选取前94组为训练数据,后16组数据为测试数据.通过训练前94组数据,得到训练后的预测模型,用以预测全球新冠疫情发展趋势,通过Matlab软件,编写GSA-PSO-SVR预测算法程序,以实现以下寻优步骤:
PSO算法在求解优化问题时易陷入局部最优,GSA算法具有局部优化能力差、收敛过早等缺点.为解决两种算法在单独求解优化问题时的局限性,构建了一种更为高效的算法-PSO-GSA联合算法,其速度和位置具体更新公式为:
Vi(t+1)=ωVi(t)+c1r1aci(t)+
c2r2(Pbest-Xi(t))
(13)
Xi(t+1)=Xi(t)+Vi(t+1)
(14)
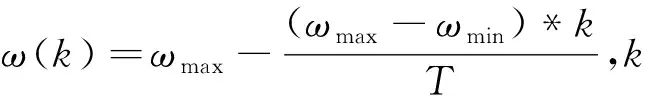
由PSO-GSA算法原理:在迭代初期,粒子的惯性权重ω比较大,具有较好的全局搜索能力,可以较快地确定最优解的大致区域;随着迭代次数的累加,ω的值越来越小,加强了粒子的局部开发能力,从而粒子群在可行解区域内通过微调即可找到全局最优解.
3 新冠肺炎传播仿真模型的数据验证
3.1 数据样本
本文采用的实验数据为世界卫生组织(World Health Organization,WHO)官网公布的全球新冠肺炎疫情数据,按照世卫组织工作区域将全球划分为六个地区:美洲区域、欧洲区域、东地中海区域、东南亚区域、非洲区域、西太平洋区域,如图3所示.以国际周为时间单位(周日为一周的开始),2020年1月26日的疫情数据为分析原点,以此类推至2022年2月22日至2月28日为第110周,实验采用前85%数据进行模型训练,15%数据用于模型的测试.根据新冠肺炎每周新增确诊以及死亡病例用来度量疫情的发展趋势,定义增量病例为每周累计确诊及死亡人数相对前一时间单位的变化量.
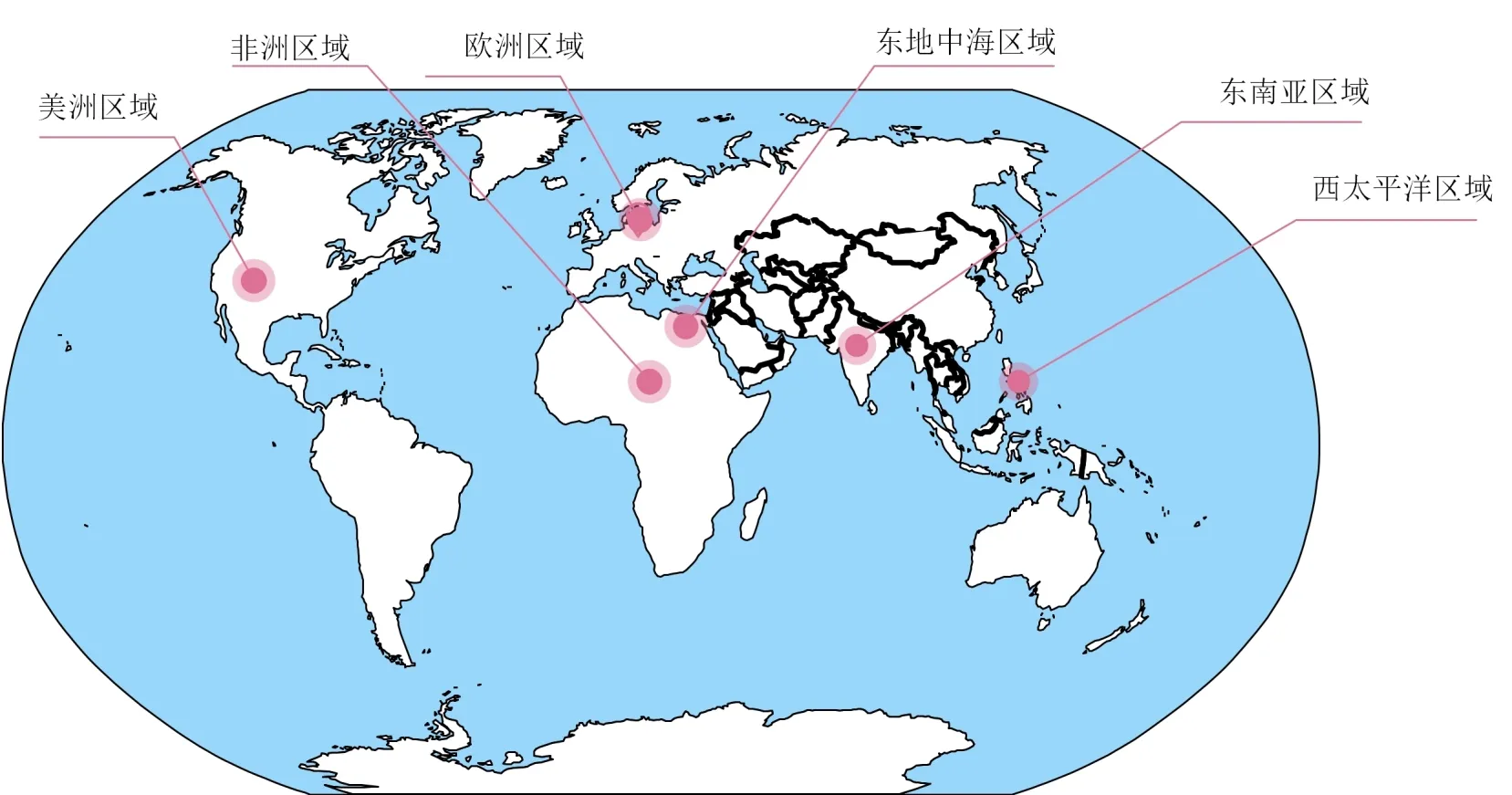
图3 全球世卫组织六个区域总部分布图
3.2 评价指标
为对比评估各个模型的预测效果,选取平均绝对百分比误差(MAPE)作为评价指标,计算公式如下:
(15)
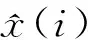
3.3 预测结果对比分析
首先对全球六个区域原始新增确诊及死亡数据序列进行奇异谱分解,由于监测数据共110组,为避免过度分解,设置窗口长度d为10.目前重构信号分量的选取方法有很多,本文以贡献率为依据选取重构分量的个数,其中λi代表新增确诊病例序列贡献率,βi代表新增死亡病例序列贡献率,如表1所示.
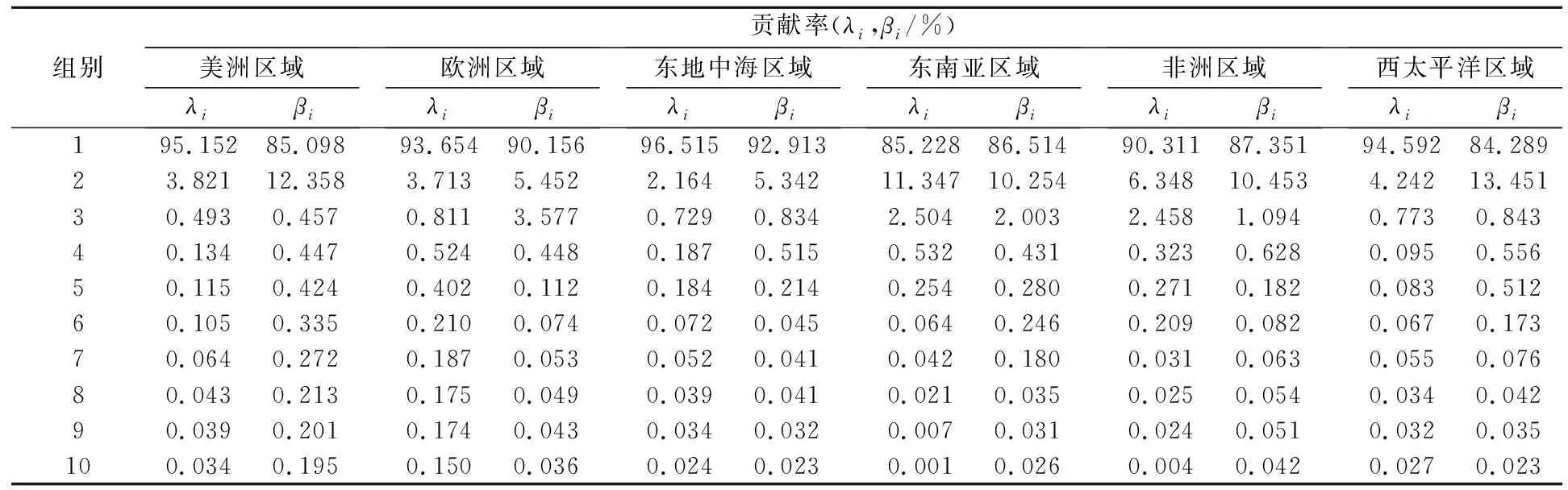
表1 六个地区原始序列组别贡献率
从表1可看出,前2个或3个重构分量的累计贡献率均已经达到了97%,剩余组贡献率减小趋势较为缓慢且均小于1,因此选取前2个或3个分量重构监测序列,剩余组为噪声序列,根据图4和图5可得重构后的序列趋势与原始序列趋势保持一致.
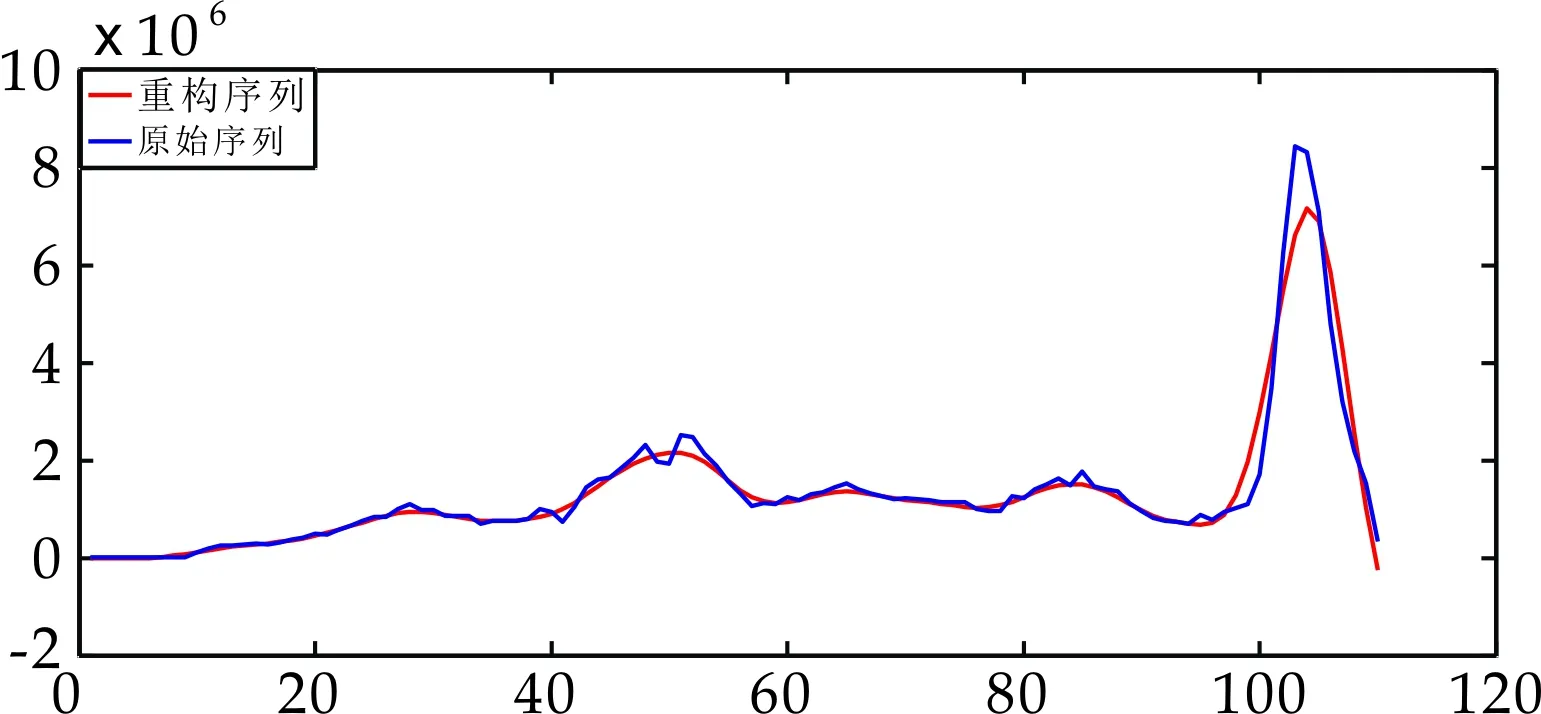
(a)美洲地区
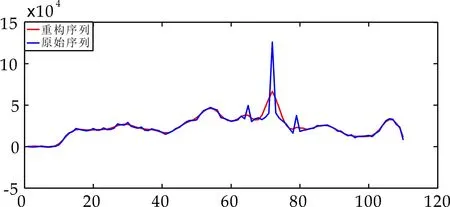
(a)美洲地区
在这一部分,首先以六个区域新冠肺炎确诊及死亡观测样本集为案例验证了SVR模型在疫情趋势预测中的有效性,并对比基于粒子群优化支持向量回归(PSO-SVR)和万有引力搜索算法优化支持向量回归(GSA-SVR)以及基于粒子群和万有引力搜索算法优化支持向量回归(PSO-GSA-SVR)的预测性能,最后将PSO-GSA-SVR联合预测算法应用到基于奇异谱分析(SSA)重构后的序列,构建SSA-PSO-GSA-SVR预测模型.
结合经验公式和多次试验对比,设置PSO算法和GSA算法的参数,种群大小和最大迭代次数分别设置为20和200,G0设置为10,为验证PSO-GSA-SVR算法的稳定性,对模型运行20次后取平均.选取SVR的MSE为适应度函数,测试和验证PSO-GSA算法对SVR参数的寻优性能,当达到最大迭代次数时,输出最小MSE值对应的C和g(最优),并将其赋给SVR进行预测,最终,五种模型对各区域确诊病例与死亡病例的预测结果如图6和图7所示.
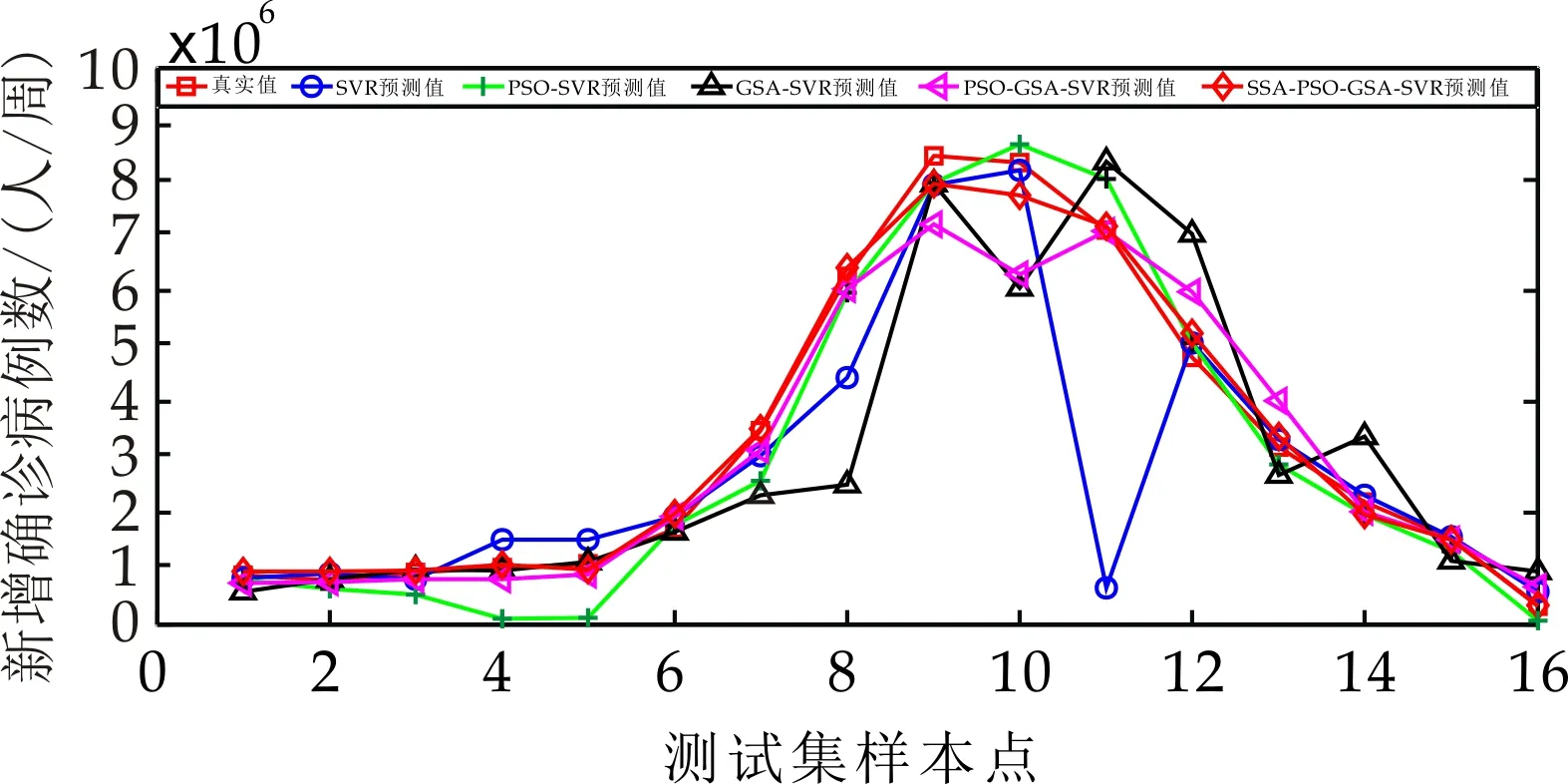
(a)美洲区域确诊病例预测结果
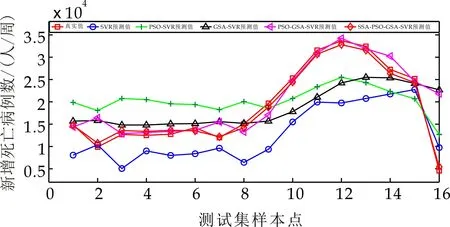
(a)美洲区域死亡病例预测结果
由图6和图7可知,基于不同区域新冠肺炎疫情数据的五种算法都能有效地预测其发展趋势,且训练后基于SSA-PSO-GSA-SVR模型的拟合曲线与原实际新冠疫情数据趋势拟合效果最好,其逼近程度远高于其他四种预测模型,表明SSA-PSO-GSA-SVR预测模型对疫情趋势发展具有较好的预测性能.
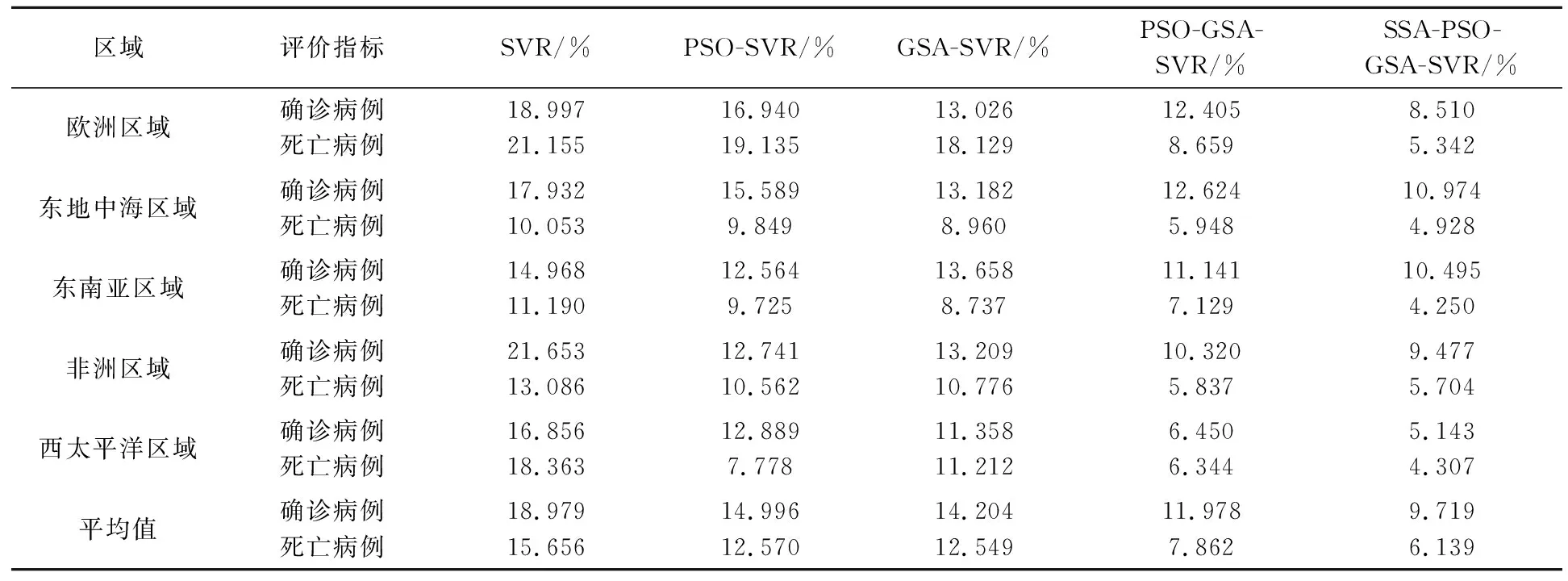
根据表2可得,SVR预测算法的评估指标平均绝对误差值最大,确诊病例和死亡病例的MAPE的值分别为18.979%和15.656%,预测效果较差,PSO-SVR与GSA-SVR预测模型是分别通过PSO和GSA优化算法寻找最优参数后进行SVR预测,两种算法优化后的SVR的MAPE值与传统SVR的MAPE相比,确诊病例的MAPE值分别下降了20.986%和25.159%,死亡病例的MAPE值分别下降了19.711%和19.845%,这表明PSO和GSA算法对SVR参数优化效果明显;而与PSO-SVR与GSA-SVR预测模型相比, PSO-GSA-SVR模型的预测精度也有了一定的提高.从表2可以看出,SSA-PSO-GSA-SVR预测算法平均绝对误差值最小,确诊病例和死亡病例的MAPE的值分别为9.719%和6.139%,因此,与文献[19]和文献[20]提出的PSO-SVR和GSA-SVR模型的预测效果相比,本文提出的SSA-PSO-GSA-SVR模型预测精度有所提高,能够更可靠、更准确地预测新冠肺炎发展趋势.

表2 不同预测模型的评价指标
续表2
4 结论
针对全球新冠肺炎疫情传播问题,本文结合群智能算法和机器学习提出了基于SSA-PSO-GSA-SVR的预测模型,用于预测各区域每周新增确诊与死亡病例人数,并采用平均绝对百分比误差评估各模型的预测效果.在仿真实验中,通过对比不同区域内SVR、PSO-SVR、GSA-SVR、PSO-GSA-SVR以及SSA-PSO-GSA-SVR预测模型的MAPE值,可以看出本文提出的方法预测效果较优,为新冠疫情的传播及发展趋势提供了一种有效的预测模型.同时,验证了支持向量回归在解决小样本问题中的优异性,采用基于奇异谱分析SSA和PSO-GSA联合算法优化SVR的超参数,降低了序列波动对预测造成的影响,提高了预测模型的精度和稳定性.
新冠肺炎传播及发展趋势预测是疫情监测系统建设与科学采取预防控制措施的重要环节.在此背景下,多种机器学习算法融合运用以及新冠疫情信息的不确定性、间隔性、波动性分析等都值得我们深入的思考和研究.为使本文提出的SSA-PSO-GSA-SVR成为一个更加通用的传染病疫情传播及趋势预测模型,下一步的工作本课题组将会在现有模型的基础上从以下几方面进行研究和改进:
(1) 采用统计学方法深入分析全球各区域近期疫情严重程度并对整体疫情走势进行分类;
(2)加入特征因素,目前的大多数新冠肺炎预测研究局限于时间序列建模,缺少分析外在因素对新冠传播的影响,如人口流动性、防护意识等;
(3) 扩展数据集至各个国家,由于数据集的缺失,本文只考虑了确诊病例与死亡病例,在未来工作中将尝试提取新冠肺炎治愈病例并对其分析研究.
猜你喜欢
昆明医科大学学报(2022年1期)2022-02-28
青少年科技博览(中学版)(2021年4期)2021-08-30
今日农业(2021年7期)2021-07-28
北京信息科技大学学报(自然科学版)(2021年2期)2021-05-20
作文评点报·低幼版(2020年25期)2020-07-23
环球时报(2020-06-05)2020-06-05
小读者之友(2020年4期)2020-05-15
新民周刊(2019年40期)2019-10-28
分析化学(2018年12期)2018-01-22
飞碟探索(2015年8期)2015-10-15
