
民航不文明旅客实体识别方法研究
2022-05-28 03:43曹卫东徐秀丽
中国民航大学学报 2022年2期
曹卫东,徐秀丽
(中国民航大学计算机科学与技术学院,天津 300300)
随着国民经济的迅猛发展,越来越多的公众选择乘坐飞机出行,但随之而来的是旅客的各种不文明行为增多,如机上接打电话、擅自打开应急舱门、破坏安检设施设备、在客舱中殴打他人、在停机坪扰乱机场公共秩序等,严重扰乱了民航秩序,妨碍安全出行。 因此,有必要对民航不文明旅客加以识别。
目前,在识别方法方面,国内外学者进行了大量研究。 命名实体识别(NER,namely entity recognition)[1]是自然语言处理的一项基本任务,主要是从文本中寻找实体,并标记实体的位置和类别。Bikel 等[2]最早提出了基于隐马尔可夫模型(HMM,hidden Markov model)的英文命名实体识别方法;Liao 等[3]提出了基于条件随机场(CRF,conditional random field)模型,采用半监督的学习算法进行命名实体识别;Ratinov 等[4]采用未标注文本训练词类模型(word class model)的方法,可有效地提高NER 系统的识别效率。中文命名实体识别也获得了广泛关注。Zong 等[5]提出基于模板的中文人名消歧混合模型;Tian 等[6]提出基于属性特征的自适应聚类的中文名消歧模型。近年来还出现了大量基于神经网络[7]的模型,并取得良好效果。Zhang 等[8]提出了一种使用格子长短时记忆网络(LSTM,long short-term memory)的中文命名实体识别的最新模型。
目前,针对民航不文明旅客实体识别的相关研究较为少见,为解决在一条民航旅客文本记录语句中包含多个实体识别的问题,通过深度学习方法对民航不文明旅客数据进行实体识别,使用BIOES 方法对文本进行标记,与词嵌入、位置嵌入串联后作为输入,通过前向和后向LSTM 学习上下文信息,使用条件随机场模型作为模型的解码层,在输入层、双向长短时记忆网络层(Bi-LSTM,bi-directional long short-term memory)添加dropout 层有效防止网络过拟合,该模型能够更高效地识别民航不文明旅客中的8 种实体类型。
1 数据处理
1.1 Yedda
Yedda 是由新加坡科技大学Yang 等[9]在2018年开发,用于文本(几乎所有语言,包括英语、中文)、符号甚至表情符号等注释的轻量级、高效且全面的开源文本标注工具,可为文本范围注释提供系统的解决方案,应用范围从协作用户注释到管理员评估和分析。通过命令行和快捷键对实体进行注释,从而克服了传统文本注释工具的低效问题。该工具可以批量注释多个实体,并支持将带注释的文本导出为序列文本。Yedda 还通过学习最新的带注释文本来提供明智的建议,此外,更新版本还包括智能推荐和管理员分析,与所有主流操作系统兼容。 与现有的标注工具相比,可将标注时间减少一半。 Yedda 框架如图1 所示。
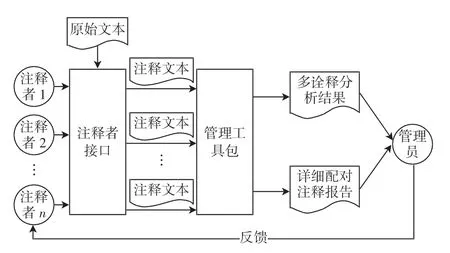
图1 Yedda 框架Fig.1 Yedda framework
1.2 实体语料处理
玻森(Boson)命名实体采用UTF-8 编码进行标注,每行为一个段落标注。所有的实体标注格式为{实体类型:实体文本}。Boson 语料中数据如{Name:乔振}{Flight:南航CZ6262}{Time:2016年2月3日}。 Boson标注的民航旅客信息中的8 类实体如表1 所示。
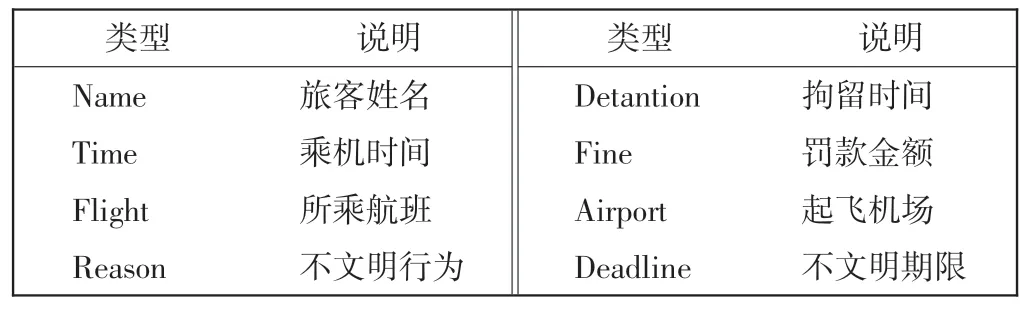
表1 民航旅客信息Boson 实体类别Tab.1 Boson entity category of civil aviation passenger information
中文命名实体识别通常是基于字标注的中文分词。 基于字的标注一般有3 种方法,BIO 标记方法(标识实体的开始、中间部分和非实体部分),BIOS 标记方法(增加S 单个实体情况的标注),BIOES 标记方法(增加E 实体的结束标识),标注类型含义说明如表2 所示。由于BIOES 方法明显优于BIO 方法[10],因此,将NER看作是一个顺序标注问题,并采用BIOES 标记方式。

表2 标注类型说明Tab.2 Description of label type
根据民航不文明旅客信息的特征,将其划分为8种实体类型,数据文本通过Yedda 工具处理后输出的字向量表示如表3 所示。
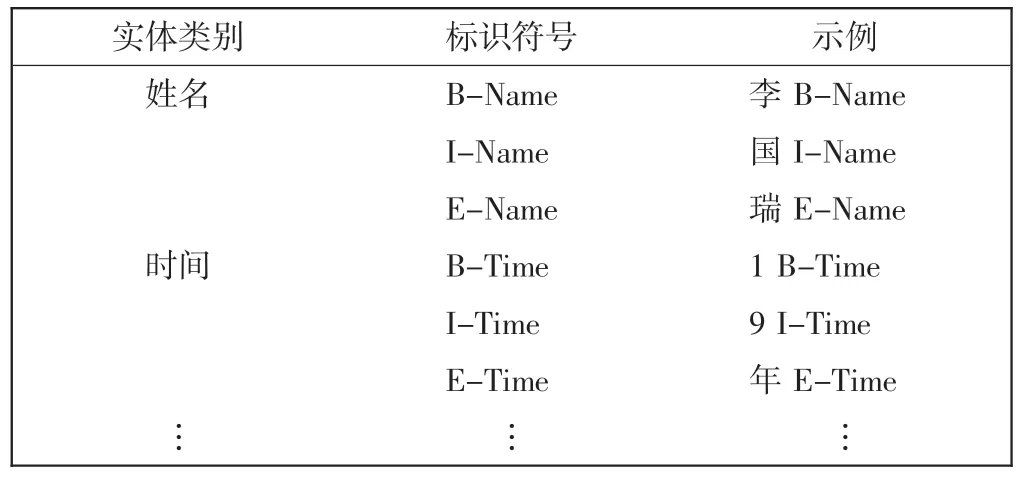
表3 民航不文明旅客实体标注Tab.3 Entity labeling of civil aviation unruly passengers
对于语句“2016年2月3日,乔振乘坐南航CZ6262次航班,在飞机下降阶段,未听从乘务员的连续劝阻继续使用平板电脑,当班安全员报告机长,通知哈尔滨太平国际机场公安机关处理,飞机落地后警方登机处置,对该违法旅客做出行政罚款200 元处理。该名旅客被列入民航旅客不文明行为记录名单,记录期限为一年”。标注后的具体数据集格式如下:{B-Time, ITime, I-Time, I-Time, I-Time, I-Time, I-Time, ITime,E-Time,O,B-Name,E-Name,O,O,B-Flight,I-Flight,I-Flight,I-Flight,I-Flight,I-Flight,I-Flight,E-Flight,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,B-Reason,IReason,I-Reason,E-Reason,O,O,O,O,O,O,O,O, O, O, O, O, O, O, O, B-Airport, I-Airport, IAirport,I-Airport,E-Airport,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O, O, O, O, O, O, B-Fine, I-Fine, I-Fine, I-Fine,I-Fine,E-Fine,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,O,B-Deadline,E-Deadline,O}。
2 Tag+Bi-LSTM+CRF 模型
构建的Tag+Bi-LSTM+CRF 模型如图2 所示。 模型分为4 个部分:输入嵌入层,Bi-LSTM 层,线性CRF层和输出层。 民航不文明旅客实体识别的过程如图3所示。
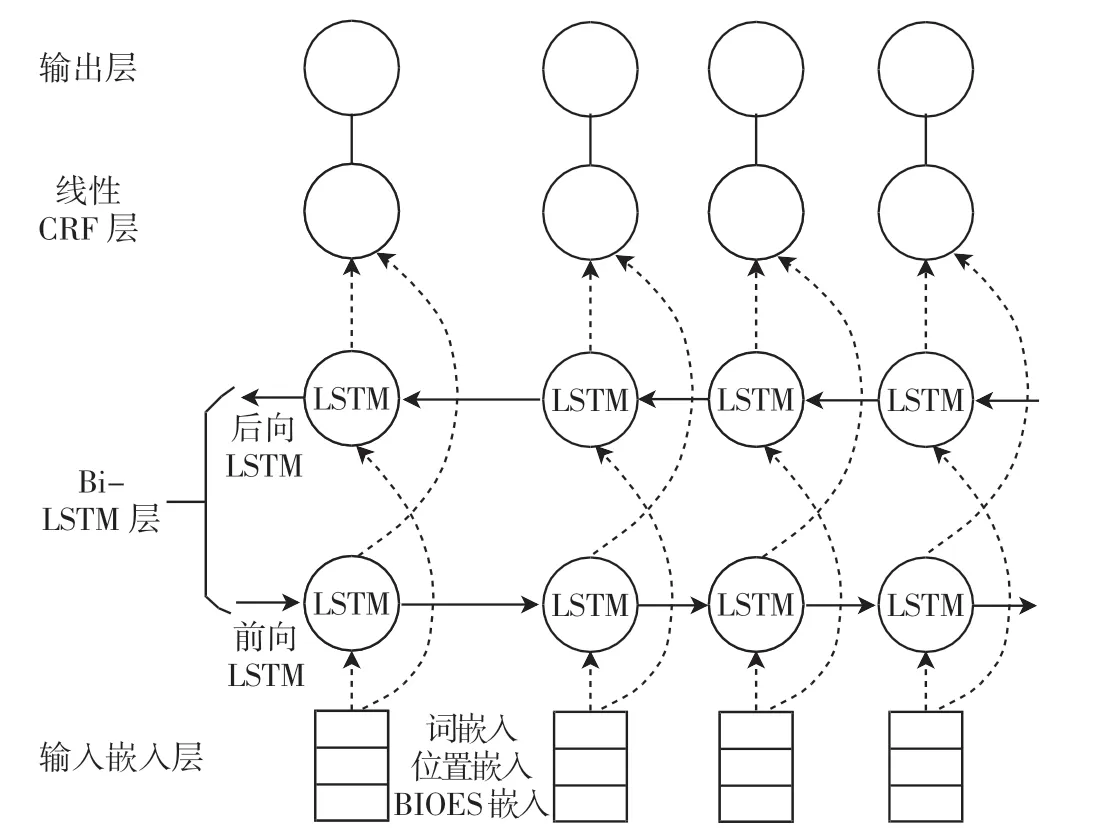
图2 Tag+Bi-LSTM+CRF 模型Fig.2 Tag+Bi-LSTM+CRF model
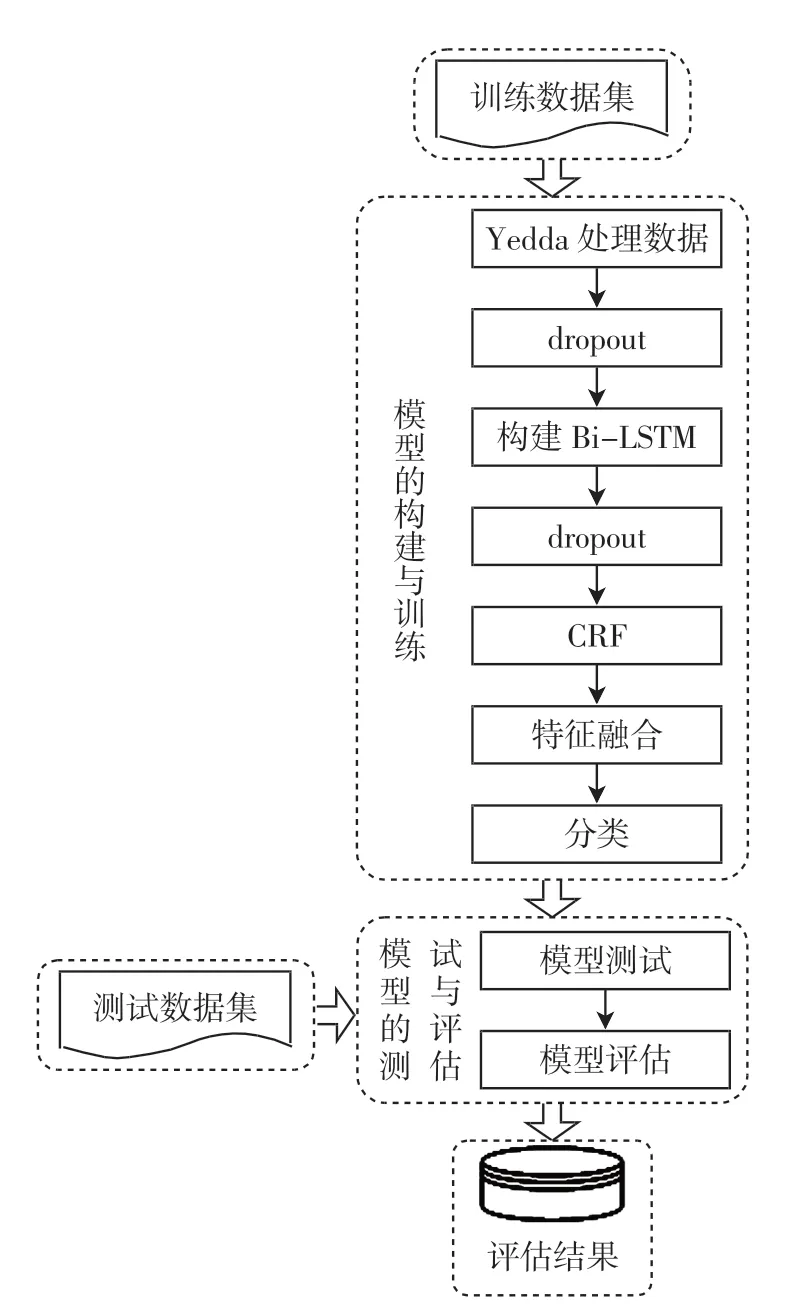
图3 民航不文明旅客的实体识别过程Fig.3 The entity recognition process of civil aviation unruly passengers
在实体识别过程中,第一个任务是创建手动注释的训练数据集来训练模型,在一条民航旅客文本记录语句中包含多实体识别,使用Yedda 工具处理可获得文本的BIOES 嵌入,与词嵌入、位置嵌入串联后构成的向量作为模型输入,以丰富输入表示。在输入Bi-LSTM层前设置dropout 层,使得数据集更容易学习。Bi-LSTM层能够有效地使用过去和将来的输入信息自动提取上下文特征,输出每一个标签的预测分值。 在命名实体识别中,Bi-LSTM 可以使用softmax 进行标记,由于softmax 分别标记每个位置,可能会得到不合适的标签序列,因此模型使用线性CRF 层,使用句子级标签信息对每两个不同标签的过度行为进行建模。 Bi-LSTM层输出的预测分数经过dropout 层随机舍弃部分神经元作为线性CRF 层的输入,通过自学习为输出预测的标签添加一些约束来保证预测标签是合法的。
2.1 输入嵌入层
词嵌入对输入句子中的每个字使用带有随机初始化的单词嵌入,词嵌入的维数为dw。
位置嵌入使用位置嵌入来编码每个单词与句子中两个目标实体之间的相对距离。 关于关系的更有用信息隐藏在离目标实体较近的词中,位置嵌入的维数为dp。
BIOES 嵌入输入语句通常包含两个以上的实体,利用BIOES 标记方法标记实体信息来丰富输入表示。 对于输入句中的每个单词,用B、I、E 标记实体的开始、中间和结束部分(如果单词个数超过3 个字,则第一个字和最后一个字分别用B 和E 标记,其余的字用I 标记),S 表示单个实体,O 表示非实体的词。BIOES 标签嵌入的维数为dt。
将每个字的3 个嵌入[11]连接在一起后,将一个句子转换为矩阵X=[x1x2… xn]作为输入表示,其中列向量xi∈Rdw+2dp+dt。
2.2 Bi-LSTM 层
2.2.1 LSTM
LSTM[12]是一种特殊的循环神经网络(RNN,recur rent neural network),可学习比简单RNN 更长的依赖关系。 LSTM 在短期依赖和长期依赖任务上表现良好,因此,在处理序列数据时被广泛使用。LSTM 在简单RNN基础上增加了3 个函数,能够记忆、更新和忘记内存,很好地克服了渐变消失的问题。
LSTM 模型由当前单元时刻t 的输入向量xt,细胞状态Ct,隐藏层状态ht,遗忘门ft,记忆门it,输出门ot组成。 LSTM 的计算过程如下。
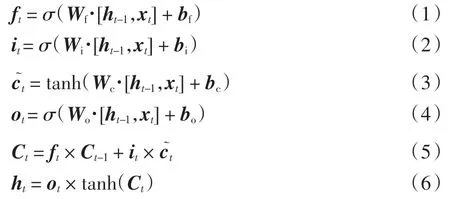
式中:σ 和tanh 表示两种不同的激活函数;t 表示当前单元时刻;t-1 表示上一层单元时刻;xt是输入向量;Ct-1表示上一层的控制门单元,与ft相乘,决定什么样的信息会被丢弃;it表示要保留下来的新信息;表示新数据形成的控制参数,与it相乘,决定什么样的数据会被保留;Ct表示控制门单元的更新, 可传入到下一个阶段;ht表示隐藏层的输出结果,也是当前层的预测结果;Wf、Wi、Wc、Wo分别表示遗忘门、 输入门、 控制门、输出门隐藏状态的权重矩阵;bf、bi、bc、bo分别表示遗忘门、输入门、控制门、输出门的偏差矩阵。 图4 为LSTM 单元的基本结构。
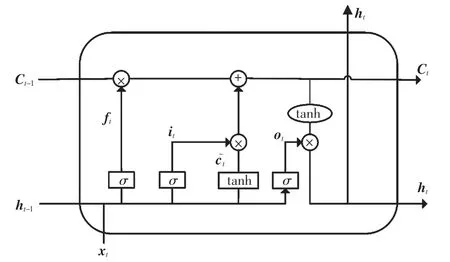
图4 LSTM 单元的基本结构Fig.4 Basic structure of LSTM unit
2.2.2 Bi-LSTM
Bi-LSTM[13]的基本思想是每一个训练序列向前和向后分别是一个LSTM, 且这两个LSTM 连接着同一个输出层。这个结构提供给线性CRF 层输入序列中每一个点完整的上下文信息,并把输出的隐状态按位置拼接,得到完整的隐状态序列,如图5 所示,前向能够获得上文信息ht(1),后向能够获得下文信息ht(2),将前向和后向LSTM 结合就能得到上下文信息ht,即
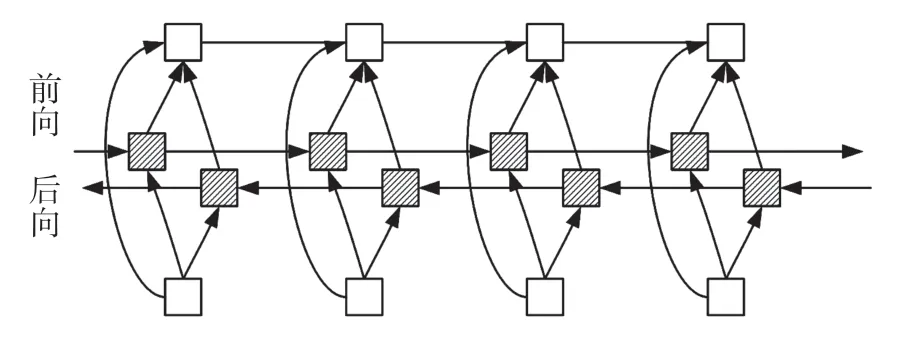
图5 Bi-LSTM 模型Fig.5 Bi-LSTM model

式中⊕表示向量的拼接。
2.3 线性CRF 层
条件随机场[14]是在给定输入的条件下求输出变量的条件概率分布模型,能够通过考虑相邻标签的关系获得一个全局最优的标记序列。线性CRF 层可以将序列标注表述为一个分类问题,将其嵌入到Bi-LSTM 层中,对Bi-LSTM 输出进行处理,得到最优的标记序列。CRF 可以表示为

式中:h=(h1,h2,…,hn)为输入观测序列;n 为序列的长度;y=(y1,y2,…,yn)为对应的预测输出标记序列或状态序列,与观测序列有相同的结构。
为了计算概率估计,CRF 做了两个假设。
假设1该分布为指数族分布,使得
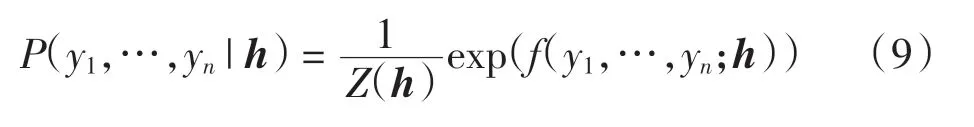
式中:Z(h)是归一化因子;f()可以看作打分函数,将其取指数并归一化后可得概率分布。
假设2概率输出之间的关联关系仅发生在相邻位置,且关联是指数可加的,则只需计算单标签打分函数k()以及相邻标签对打分函数g(),将所有打分结果求和得到总分。 式(9)可简化为
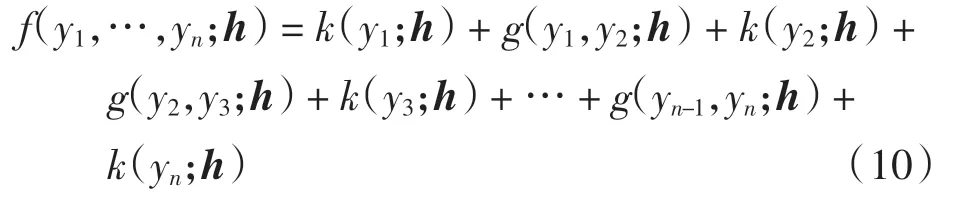
在线性CRF 中,又假设g()与h 无关,则
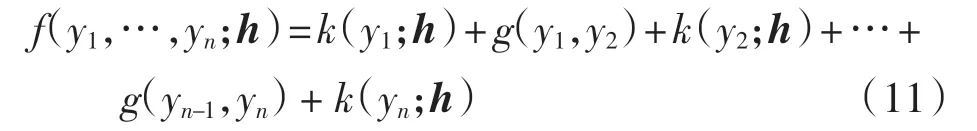
使用最大似然方法对线性CRF 模型进行训练,即
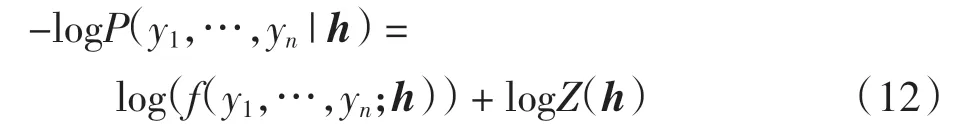
由于CRF 只考虑临近标签的联系,可以使得原来归一化因子为指数级别的计算量降低为线性级别。 使用维特比(Viterbi)算法可以获取CRF 中最优的标签序列。
2.4 输出层
通过线性CRF 层后,模型在所有标签序列中选择预测得分最高的标签序列作为实体识别的结果进行输出。
3 实验分析
3.1 实验环境及配置
实验环境如下:操作系统为Windows 10,处理器为Inter(R)i7-9750H,内存大小为16 GB,开发语言是Python 3.7,采用的深度学习框架为Pytorch,开发环境为Pycharm。
3.2 实验数据
实验数据来源于信用中国、航协网的民航旅客随机记录文本,共收集了民航不文明旅客文本信息4.7万条,每一条文本是一个民航不文明旅客的记录,文件大小为15.1 MB,对其进行标注后,文件大小为42.3 MB。按照训练集、验证集、测试集7∶1∶2 的概率随机分配,划分后的数据集文件详细统计信息如表4所示。

表4 数据集统计Tab.4 Statistics of datasets MB
3.3 评价指标
采用精确率P(precision)、召回率R(recall)和F1值3 个标准作为评价指标。 要计算评价指标,首先要构建一个混淆矩阵,混淆矩阵也称为误差矩阵,以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断汇总,如表5 所示。
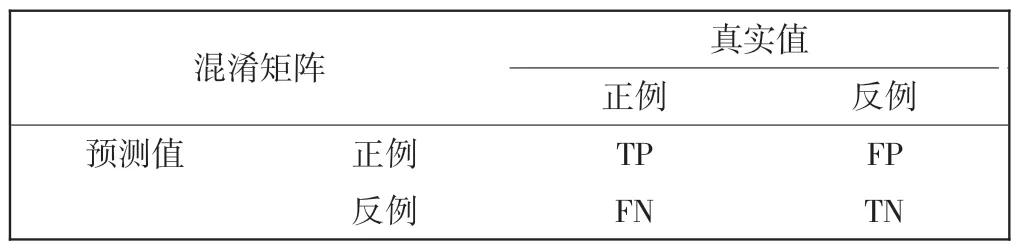
表5 混淆矩阵Tab.5 Confusion matrix
混淆矩阵是对分类模型进行性能评价的重要工具,根据混淆矩阵可计算P、R 和F1 值,计算公式为

矩阵中一些符号含义为:
(1)TP(true positive),将正类预测为正类数,即预测为正例,实际上也为正例;
(2)FN(false negative),将正类预测为负类数,即预测为反例,实际上为正例;
(3)FP(false positive),将负类预测为正类数,即预测为正例,实际上为反例;
(4)TN(true negative),将负类预测为负类数,即预测为反例,实际上也为反例。
3.4 参数配置
模型使用Adam 优化器,参数设置为:dw=200、dp=50,dt=50。 每批数据量的大小batch_size=8,学习率lr=0.005,LSTM 隐向量的维数hidden_size=64,dropout=0.5,迭代次数epochs=25。损失值与迭代次数的关系,如图6 所示,其中:loss 表示训练集的损失值;val_loss 表示测试集的损失值。由图6 可知,在迭代25 次左右时,损失收敛。
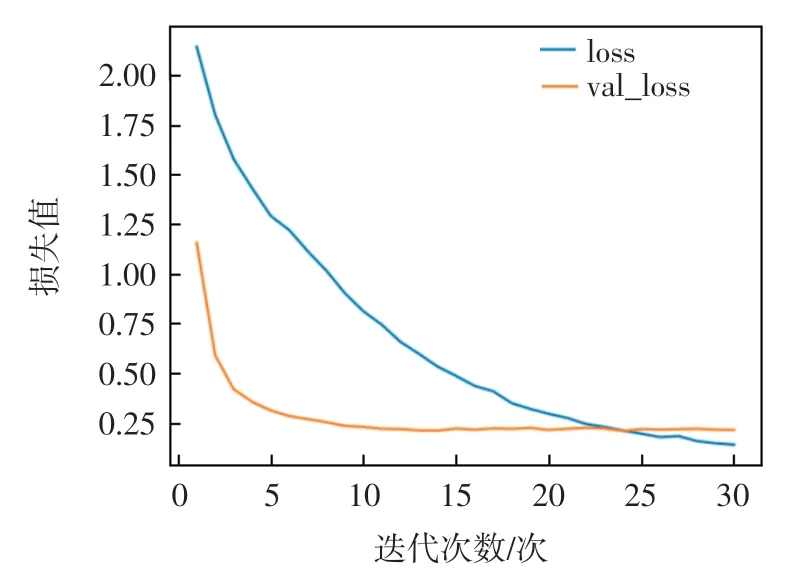
图6 损失值-迭代次数曲线图Fig.6 Loss-epoches graph
3.5 实验结果分析
3.5.1 实体识别结果
在民航不文明旅客数据集上进行实验,对旅客姓名、时间等8 类实体进行识别,具体结果如表6 所示。
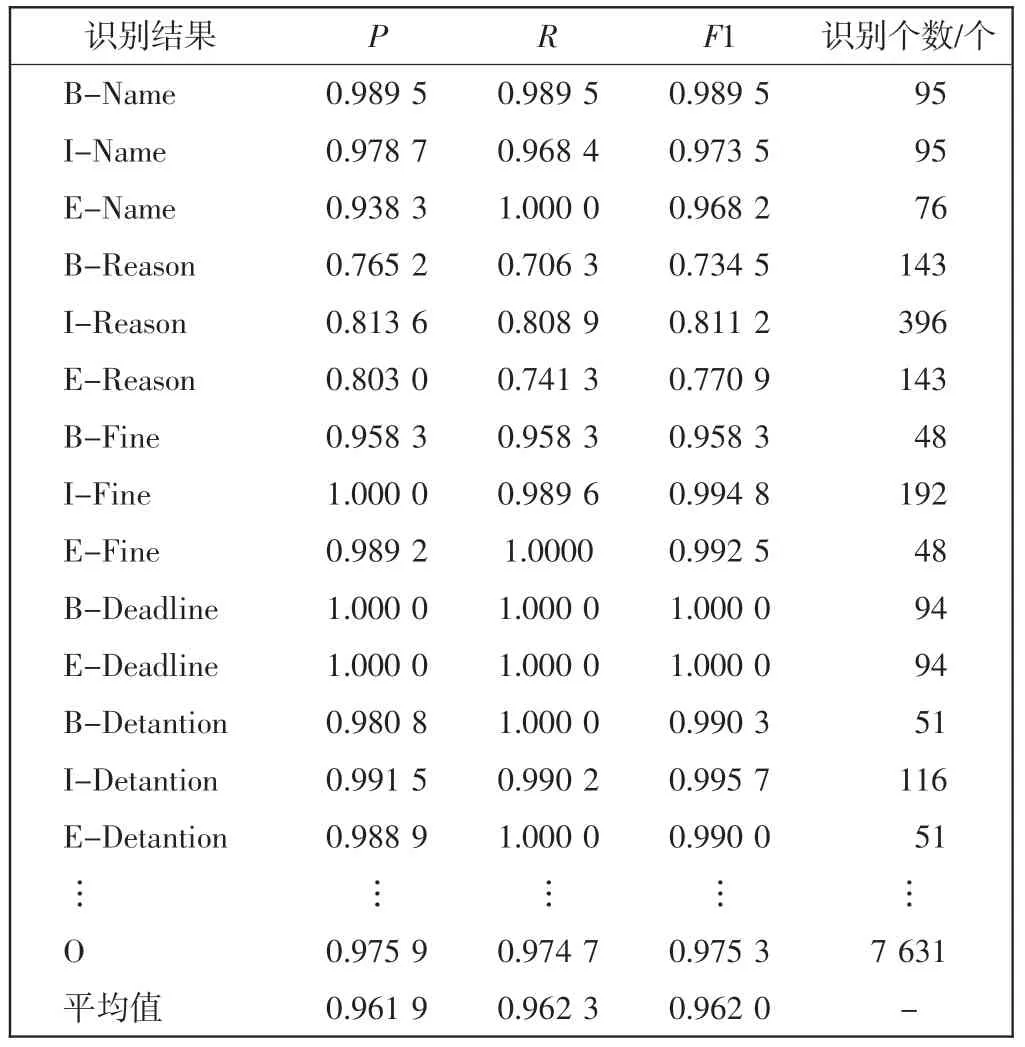
表6 实体识别结果Tab.6 Entity recognition results
由表6 中的实验结果可知:Tag+Bi-LSTM+CRF 模型的实体识别效果较好,其P、R、F1 均值都达到了96%以上。 对于单个实体,根据实体的复杂程度和训练集中的数量不同会有差异。同一个实体的B-、I-、E-识别结果不同是因为在一个实体中,可以包含多个中间的字。 由表6 可看出:①对于罚款金额、拘留时间和不文明期限实体的识别准确率较高,基本能达到99%,原因可能是这几个属性的结果较为稳定,且原始数据集里存在大量的包含这几个属性的重复句子,导致分割得到的测试集包含了一些训练集中的内容;②相对而言,不文明行为实体的识别准确率较低,其准确率为79%左右,原因可能是旅客的不文明行为多种多样,且没有统一的行为描述词;③姓名、航班、机场等实体的识别效果和平均识别效果差距不大。
3.5.2 对比实验
为了验证Tag+Bi-LSTM+CRF 模型对民航不文明旅客实体识别的有效性,将该模型与已有的经典模型如HMM、CRF、双向Bi-LSTM 进行对比,对8 类实体识别的结果进行综合评估,实验结果如表7所示。
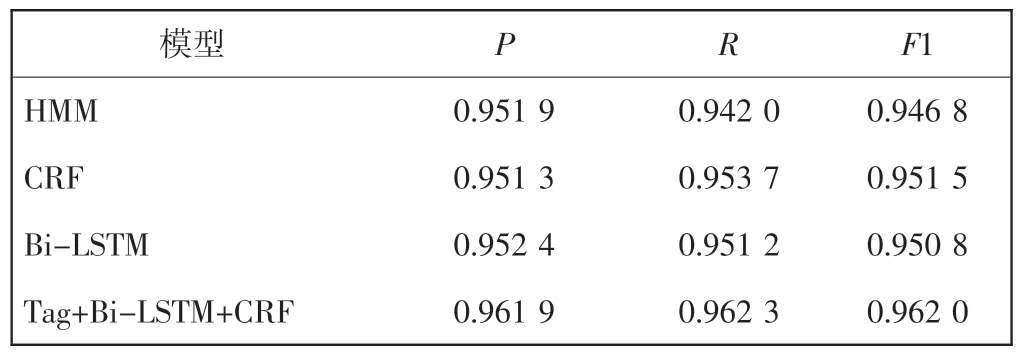
表7 实验结果对比Tab.7 Comparison of experimental results
从表7 可看出:Tag+Bi-LSTM+CRF 模型对民航不文明旅客实体识别表现出更好的总体性能,能够识别出民航不文明旅客数据中的8 类实体,可以用在民航不文明旅客服务规则库的命名实体识别上;HMM 模型的表现效果最差,可能原因为HMM 只依赖于每一个状态和其对应的观察对象,而实体识别问题不仅和单个词相关,而且和序列长度、单词上下文都相关;CRF模型和Bi-LSTM 模型的效果相当,但这两个模型的性能依赖于数据规模的大小和应用场景,在数据规模较小时,CRF 的实验效果要略优于Bi-LSTM,当数据规模较大时,Bi-LSTM 的效果会超过CRF,从场景来说,如果需要识别的任务不需要太依赖长久的信息,此时Bi-LSTM 等模型只会增加额外的复杂度。考虑到数据规模大、识别任务不需要太依赖长久的信息,结合了Bi-LSTM 和CRF,充分利用了模型的优点,实现了最佳性能。
3.5.3 网络优化器对实验结果的影响
网络优化器对实体识别的结果有很大影响,因此选用合适的优化器是非常重要的。本实验通过对比不同的优化器对实体识别效果的影响,选取了Adam、AdaGrad、SGD 进行实验,结果如图7 所示。
由图7 可知,当选用Adam 优化器时,命名实体识别的P、R 和F1 均达到最大值,而使用SGD 优化器,各项性能指标都最低。
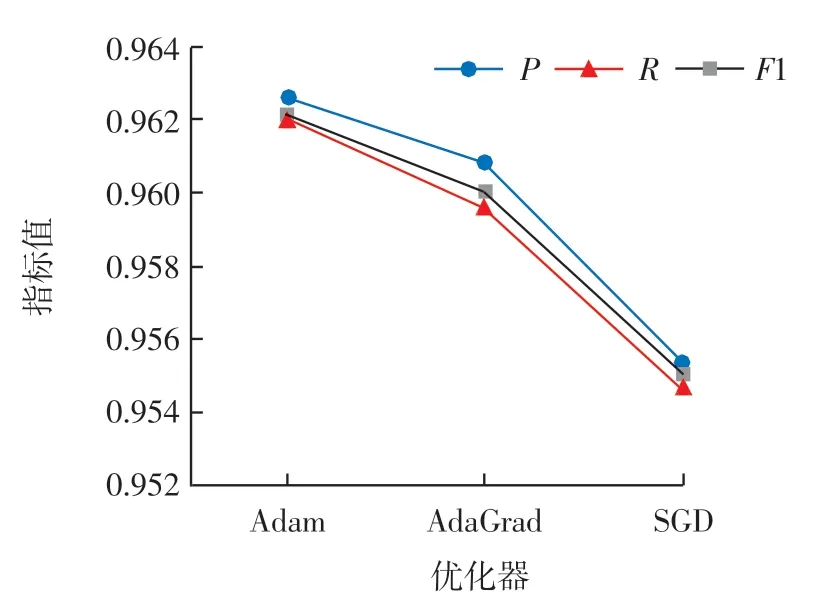
图7 网络优化器对实验结果的影响Fig.7 The influence of network optimizer on experimental results
3.5.4 dropout 对实验结果的影响
为增强模型的泛化能力,在Bi-LSTM 和CRF 层之间加入了dropout 层,不同的取值会影响模型的效果,如图8 所示,当dropout=0.5 时,模型的各项性能达到最优。
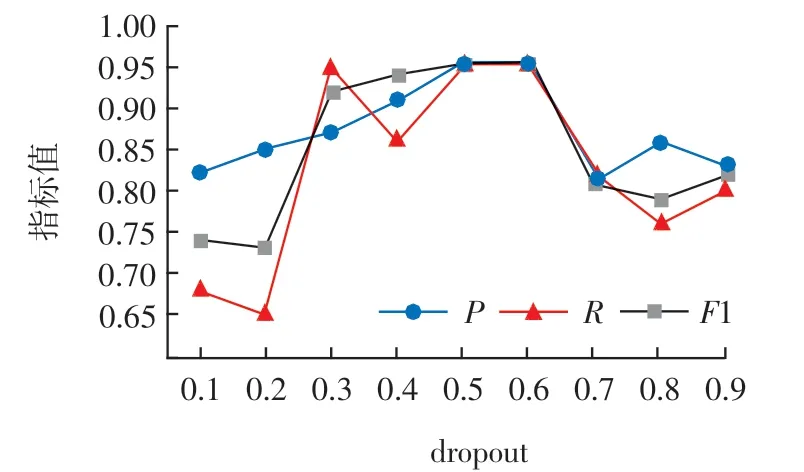
图8 Dropout 曲线Fig.8 Dropout curve
4 结语
结合民航不文明旅客数据记录每条数据包含多个实体的特点,提出基于字的Tag + Bi-LSTM + CRF的实体识别模型。与经典模型相比,该模型表现较好,对民航不文明旅客信息实体识别精确率、召回率与F1均高达96%以上,能有效获取民航不文明旅客行为、等级、处罚、期限等信息。但由于旅客记录数据有些属性值相对简单,且描述较为单一,其对应属性的F1 值较高,而描述相对复杂属性的F1 值相对较低。 在未来的工作中需要继续优化神经网络结构,采集更多不规则的民航不文明旅客数据集,提高模型训练性能。
猜你喜欢
计算机系统应用(2021年11期)2022-01-06
云南画报(2021年7期)2021-11-13
数学大王·趣味逻辑(2020年8期)2020-08-14
当代陕西(2019年5期)2019-03-21
海峡姐妹(2018年3期)2018-05-09
故事大王(2018年3期)2018-05-03
21世纪商业评论(2018年3期)2018-03-02
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
