
基于NLP的不规范航行通告识别方法
2022-05-28 03:43项恒,张驰,李猛
中国民航大学学报 2022年2期
项 恒,张 驰,李 猛
(中国民航大学空中交通管理学院,天津 300300)
随着中国民航业的快速发展,飞行员需要处理的与飞行相关的信息越来越多,导致飞行员在短时间内无法全面了解其中的关键信息。 这些信息主要集中在飞行前收到的飞行前信息通报(PIB,preflight information bulletin)中。飞行前信息通报中对飞行安全影响最大的是航行通告(NOTAM,notice to airman)。这些航行通告中包括很多与本次飞行不相关的航行通告,也包括一些不规范的航行通告,对航班飞行有着重大安全隐患。
对航行通告的处理,相关学者进行了诸多研究。陈凤兰[1]采用改进的模糊评价法对造成不规范航行通告的因素进行识别;徐慧[2]通过对某地区的不规范航行通告进行统计分析,与实际工作流程相结合,提出航行通告安全风险管理方法;王小文等[3]针对传统航行通告中E 项文本没有固定格式、表述不规范的问题,提出了一种事件驱动的数字化航行通告时空数据模型和编码方法,构建了一种新的数据集规范;张珣[4]基于新型数据访问面向服务架构(SOA,service oriented architecture)构建出航行通告处理系统,具备新报浏览、本场运行图标注等功能;胡静[5]基于数据分发服务(DDS,data distribution service)规范及服务质量(QoS,quality of service)策略完成航行通告发布/订阅模型的中间件设计,实现航行通告的高效分发。近年来,国内对航行通告的研究多为改进航行通告系统的处理方法与分发方式,鲜有关于航行通告内容翻译处理及不规范航行通告识别等方面的研究。针对航行通告中存在Q 代码与E 项正文不匹配的问题,可使用文本相似度技术进行不规范航行通告的识别,该技术被广泛应用于智能问答、文本推荐等领域。 张海超等[6]采用文本相似度技术计算专利要求书之间的相似度,以对专利侵权现象进行检测。 航行通告E 项正文部分存在大量专业术语及缩略语,飞行员解读需要花费大量时间,可通过机器翻译技术将其翻译为中文。 由于机器翻译在术语翻译时准确度较低,周珂等[7]使用融合主题的机器翻译技术, 将术语翻译与特定语料训练出的翻译模型融合,提高了术语翻译的准确度。
本研究基于统计机器翻译完成对航行通告E 项正文部分的翻译,利用数据库技术对Q 代码进行翻译;采用特定语料训练的Word2vec 模型计算两者之间文本相似度,并通过数据实验制定不规范航行通告的识别标准。
1 问题描述及方法设计
飞行中有关安全的短期或临时更改的信息,如跑道关闭或限制,都是通过PIB 中的航行通告传达。 因此,航行通告的规范与否对于飞行安全有至关重要的作用。
近年来,随着民航业的快速发展,航行通告数量呈爆发式增长,其中不规范的航行通告数量也在迅速增加。以中国民用航空西北地区空中交通管理局为例,2018年共发出航行通告5 511 份,其中不规范航行通告165 份[8]。不规范航行通告分布情况如图1 所示,其类别如下:1.航行通告代码(Q 代码)选择不合理;2.航行通告正文描述口语化;3.取消通告正文描述不规范;4.同样内容的航行通告不同日期拍发Q 项和A 项不同;5.Q 项未填写坐标半径;6.航行通告正文描述不规范;7.航行通告未按编发要求描述了两个事件;8.雪情通告道面摩擦系数估算不合理;9.航行通告B 项不合理。
从图1 中可看出,由于Q 代码及E 项正文导致航行通告不规范的共有136 份,约占不规范航行通告数量的82.4%。因此,采用语义相似度对不规范航行通告中的Q 代码和E 项正文部分不规范的航行通告进行识别。
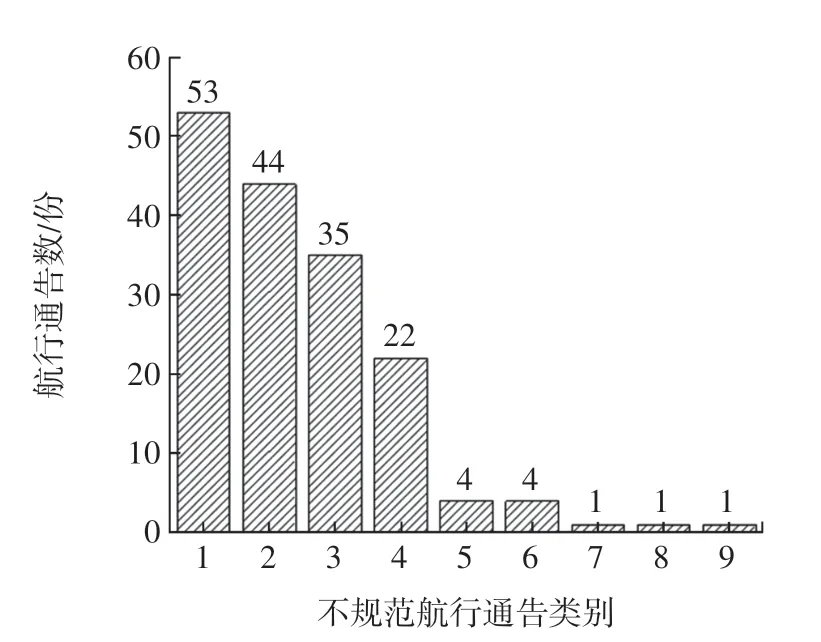
图1 不规范航行通告分布情况Fig.1 Distribution of non-normative NOTAMs
2008年,中国民用航空局颁发了《航行通告填发指导手册》[9],规定了航行通告的拍发规则和格式要求。航行通告中:Q 代码“QXXXX”(其中Q 为识别码,其后两个连续字母表示主题,最后两个字母描述主题的状态)是目前情报人员用于提取航行通告的主要依据[10];E项正文为航行通告主体部分,用于描述本条航行通告的具体内容,是对航行通告Q 代码描述的展开。E 项正文和Q 代码具有一定关联度。
基于自然语言处理(NLP, natural language processing)的不规范航行通告识别方法主要分为两部分:①将航行通告中的E 项正文和Q 代码翻译成中文;②通过特定语料训练的Word2vec 模型计算两者之间文本相似度,并通过数据实验制定不规范航行通告的识别标准。 整体方法设计如图2 所示。

图2 不规范航行通告识别方法设计Fig.2 Design of non-normative NOTAMs identification method
2 统计机器翻译模型的构建
2.1 翻译模型
统计机器翻译中的翻译模型(简称翻译模型)通过对大量源语言和目标语言的平行语料进行统计分析(其中,源语言为E 项正文,目标语言为中文),找到单词之间隐含的对应关系,从而进行源语言翻译。双语平行语料库中,单词的一一对应关系不是固定的,一个或多个目标语言单词都有一定概率对应一个或多个源语言单词,只是概率不同。训练翻译模型的目的是从双语平行语料库中找到单词之间最大的对应概率。 翻译模型的构建步骤(图3)如下。

图3 翻译模型构建流程Fig.3 Construction process of translation model
1)语料预处理
收集到的航行通告中E 项正文数据格式比较杂乱,需要进行预处理,使其成为机器可识别的文本。
语料预处理包括分词、删除无关符号等阶段。由于数字、日期等不可枚举,故用正则表达式对特殊类型进行泛化,最终形成源语言和目标语言两个平行文件。两个文件中的每句话都具有一一对应的顺序关系。
2)词对齐处理
使用分词工具GIZA++进行词对齐处理,图4 为对齐结果的可视化显示。GIZA++的缺点是无法找到词之间映射关系。为了找到该种映射关系,可使用默认的探索法grow-diag-final 算法[11]进行句子对齐。
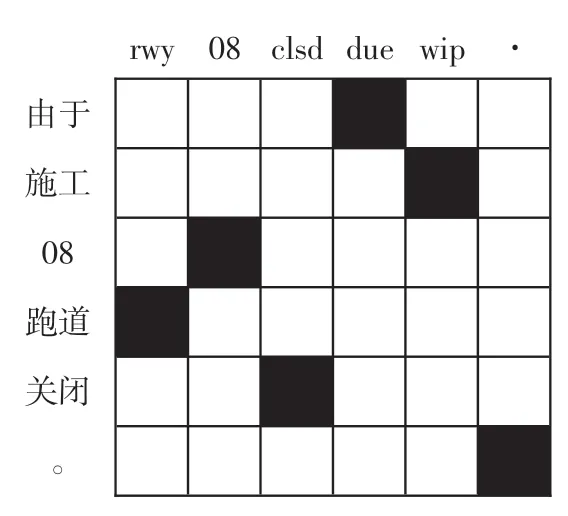
图4 对齐矩阵Fig.4 Alignment matrix
3)词语评分
词语评分是用来检查经过训练之后双语平行语料库中的单词之间的对齐关系[12]。grow-diag-final 算法处理完训练数据后,就可进行源语言到目标语言词语的评分计算,计算方法如下
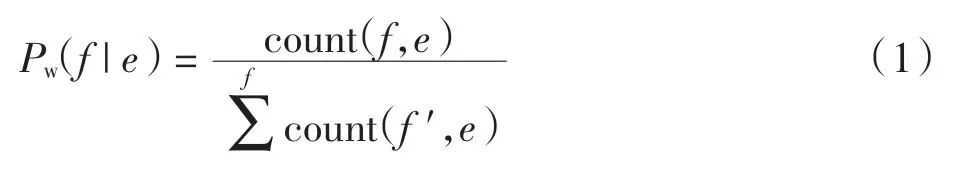
式中:Pw为词翻译概率;f 为词语原文;e 为词语译文;f′为词语原文均值。
4)短语抽取
使用分词工具GIZA++进行词对齐处理后,需要进行短语抽取。对于目标语言短语中的所有单词都能在源语言短语中找到与之对应的单词,相应地,对于源语言短语中的所有单词都能在目标语言短语中找到与之对应的单词。由对齐矩阵(图4)可得短语抽取表[13],如表1 所示。

表1 短语抽取表Tab.1 Table of phrase extraction
5)短语评分
短语评分计算如下
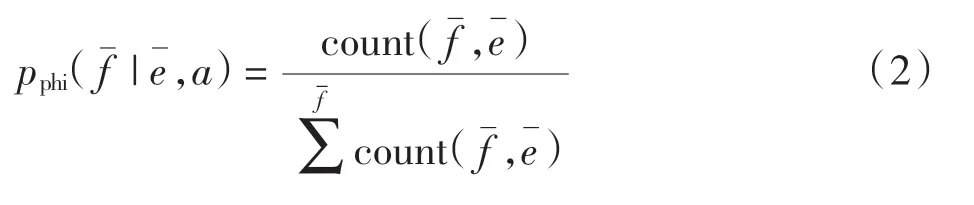
式中:pphi为短语由源语言翻译成目标语言的概率;f为短语原文;为短语译文;a 为无关变量, 用来表示短语()中已进行词对齐。短语由源语言翻译成目标语言,概率越大,短语评分越高。
2.2 语言模型
统计机器翻译模型中的语言模型是用于计算源语言句子在目标语言中出现的可能性,即计算该句子在目标语言中句法、语义上的合理程度,通常表示为目标语言的N 元模型或其变形。
通过训练好的翻译模型翻译出来的译文可能有多个,但由于翻译模型只是对源语言进行准确翻译,并没有考虑到语序问题,导致一部分翻译出来的译文可能不符合中文的表达方式或语法规则,从而出现词序扭曲[14]的情况。通过语言模型对不符合中文表达方式或语法规则的译文排除掉,留下经过语言模型筛选的最优译文。
采用IRSTLM 工具包训练语言模型[15],句子概率计算如下

式中:P(w1)表示句子第1 个词为w1的概率;P(w2|w1)是在已知第1 个词w1的前提下第2 个词w2出现的概率;P(w3|w2w1)是在已知前两个词的前提下第3 个词w3出现的概率。
2.3 评价模型
机器翻译质量评测算法(BLEU,bilingual evaluation understudy)是一种比较常用的机器翻译评测方法。该评测方法的基本思想是将机器翻译结果与人工翻译结果进行比较,通过评分来判断机器翻译结果的优劣及翻译结果的准确性。 BLEU 评测的计算方式如下

式中:S 为BLEU 算法的得分;N 为考察的语法阶数,一般取N=4, 即BLEU-4;pn是翻译结果中n 元词语出现次数占人工翻译结果中n 元词语出现次数的比例;B 是句子长度过短的惩罚因子,即
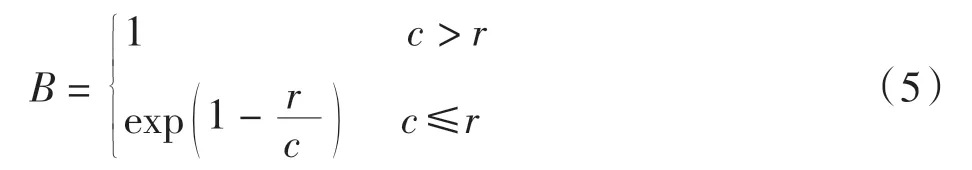
式中:c 为机器翻译结果中的单词数量;r 为人工翻译结果中与机器翻译结果中意思相近的单词数量。S 的取值范围在0~1 之间,得分越高,说明翻译结果越准确[16]。
2.4 Word2vec 算法
Word2vec 算法的原理是将单词以向量表示,通过向量计算单词与单词、句子与句子之间的关系,如词语相似性、语义关联性等[17]。
Word2vec 算法计算文本相似度主要采用连续词袋(CBOW,continuous bag-of-words)模型和跳字(Skip-Gram)模型。 CBOW 模型和Skip-Gram 模型的区别在于:CBOW 模型原理是利用上下文计算当前单词出现的概率;Skip-Gram 模型则是利用当前单词来计算上下文出现的概率[18]。模型计算前,每个单词都是随机生成的M 维向量,经过中文语料库数据训练后,获得单词的最佳向量。
训练模型采用的是Skip-Gram 模型,Skip-Gram模型在词向量上具有更高的准确性。 对于训练单词序列w1,w2,…,wT,Skip-Gram 模型是通过单词之间的关系,求出最大平均对数概率,即得到句子的向量表示,计算方法为

式中:d 表示以wt作为中心词上下文中相邻单词的个数(即训练窗口),d 值越大,准确率越高,训练时间也越长;p(wt+j|wt)定义为已知中心词wt计算上下文单词wt+j出现的概率。
3 实验结果分析
3.1 模型训练及参数设置
统计机器翻译需要人工翻译大量的航行通告E项正文作为翻译模型的训练数据,其训练数据中的航行通告主要来源于美国联邦航空管理局网站。
统计机器翻译中的翻译模型训练采用的是开源机器翻译软件Moses,采用GIZA++工具进行词对齐处理,采用IRSTLM 工具包进行3 元语言模型训练。解码部分使用Moses 解码器,词汇化(MSD,mono swap discontinuous)调序模型。 评价模型采用BLEU-4 作为评价系统翻译标准。 通过数据翻译测试,平均得分达到0.223,翻译效果较为理想。
Word2vec 模型训练数据分布情况如表2 所示。

表2 语料库分布情况Tab.2 Distribution of corpus
Word2vec 算法计算中文文本相似度的程序采用Python 语言编写。 算法的主要训练参数设置如下:①采用Skip-Gram 模型计算文本相似度;②词向量维度与训练语料库的大小有关,本次模型训练取M=100;③由于航行通告文本一般较短,训练窗口d 取默认值5。
3.2 结果分析
对航行通告中Q 代码与E 项正文的中文语义相似度进行计算。将Word2vec 算法计算出的结果与余弦相似度、词频-逆文档频率(TF-IDF,term frequencyinverse document frequency)等算法计算结果进行对比,如表3 所示,其中:第1、2 组数据为不规范航行通告中翻译结果;第3 组为规范航行通告翻译出的结果。
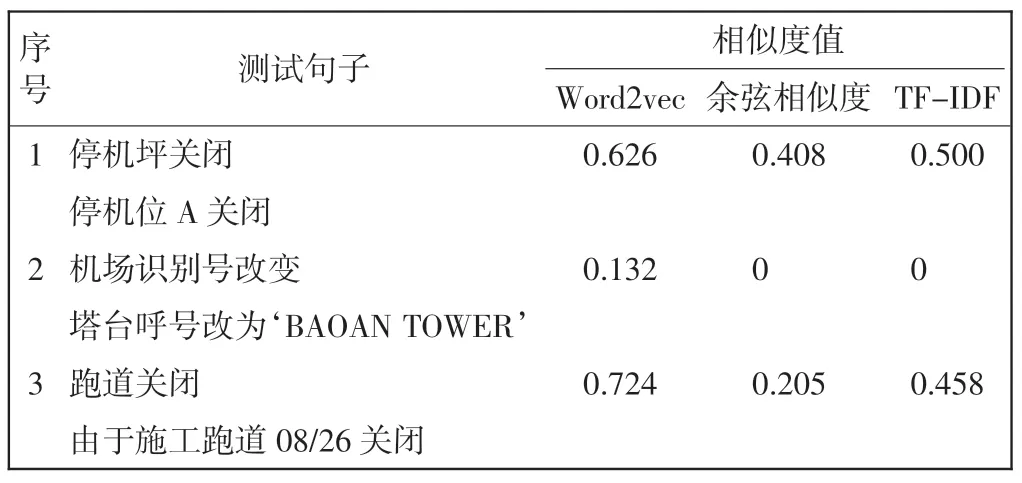
表3 不同算法相似度对比Tab.3 Comparison of similarity between different algorithms
通过表3 对比可以看出,通过特定数据训练出来的Word2vec 模型,在航行通告文本相似度计算方面具有更好的效果,具体分析如下。
(1)利用余弦相似度算法计算,没有考虑句子长度等问题,只是从方向上进行判定;TF-IDF 方法以词语出现的频率作为衡量相似度的标准,不够全面,且没有考虑单词位置对句子产生的影响;Word2vec 算法充分考虑单词上下文,能够较好识别测试文本的语义,对短文本的相似度计算有较高精度。
(2)通过特定语料库训练出的Word2vec 模型在一些民航专有名词的识别上精度更高,针对不规范航行通告的识别方法更加可靠,但在某些相似的专有名词识别上,精确度不够,如“停机坪”“停机位”等名词。
从美国联邦航空管理局网站上随机抽取500 组航行通告作为模型测试数据,使用翻译模型进行E 项正文翻译,然后通过Word2vec 算法计算E 项正文与Q代码间的相似度,如图5 所示。

图5 数据测试结果Fig.5 Data testing result
由图5 数据测试结果可看出,500 条航行通告E项正文与Q 代码文本相似度值主要分布在0.7~1.0 之间。 基于此,设定0.7 作为不规范航行通告的识别标准。通过所提识别方法测得,共481 条航行通告相似度值在0.7 以上,不规范航行通告识别准确率为96.2%。实验结果表明,基于NLP 的不规范航行通告识别方法在判断Q 代码与E 项正文不规范的航行通告上具有可行性和适用性。
4 结语
通过NLP 技术进行不规范航行通告的识别,得到如下结论。
(1)航行通告中Q 代码用于系统的自动识别,不规范的Q 代码将影响PIB 的正确提取,所提出的基于NLP 方法来识别不规范航行通告,可有效识别航行通告中Q 代码选择错误的情况。
(2)航行通告的E 项文本没有明确拍发标准,对于不同的情报人员,相同的状况会有多种描述方法,飞行员需要花费较长时间进行解读,而航行通告系统中采用统计机器翻译中的翻译模型,将E 项文本翻译成中文,可以减少飞行员阅读航行通告的时间,提高飞行安全。
(3)现阶段,航行情报不断朝着数字化方向发展,航行通告可视化已成为航行通告的发展趋势,提出的基于统计机器翻译方法及不规范航行通告的识别方法对未来航行通告可视化发展具有一定意义。
(4)本研究提出了通过将民航领域航行通告中的专用术语翻译成中文,并结合文本内容与主题之间的语义关系进行不规范信息的识别,此方法也可以推广到其他领域,为其他领域的相关术语翻译及与主题不符的信息识别提供了借鉴。
目前该方法由于数据训练量较小,在E 项长文本的翻译上效果较差,下一步的研究还需要通过更多的数据训练模型,使得机器翻译效果更准确。
猜你喜欢
纺织标准与质量(2022年3期)2022-08-10
散文诗(2022年14期)2022-08-08
疯狂英语·新读写(2021年6期)2021-08-05
儿童故事画报(2020年7期)2020-08-03
小学科学(2020年6期)2020-06-22
中国化妆品(2018年8期)2018-12-06
创新作文(1-2年级)(2017年7期)2017-12-26
中文信息(2017年9期)2017-11-08
河南教育·基教版(2016年2期)2016-03-10
爆笑show(2015年5期)2015-07-09
