
基于时间触发光纤通道网络的交换调度算法
2022-05-28 06:16孙万录
电子科技大学学报 2022年3期
白 焱,孙万录,宋 平,李 伟
(1. 中国科学院沈阳计算技术研究所有限公司 沈阳 110042;2. 空装驻沈阳地区第一军事代表室 沈阳 110051;3. 沈阳航盛科技有限责任公司 沈阳 110051)
时间触发光纤通道(time trigger fiber channel,TTFC)具有全局时钟和预定义的传输时间表[1],通过解决一部分光纤通道(fiber channel, FC)网络数据交换的冲突问题,改善了重要业务的传输确定性和实时性,提升了航电任务系统的整体性能,成为了航电网络通信的发展方向。
TTFC 网络支持时间触发(time trigger, TT)和事件触发(events trigger, ET)多种优先级业务。TT业务具有最高优先级,通过离线通信调度保证其准确性,TT 业务可在定义的延迟和抖动范围内在TTFC交换网络上无冲突地精确传送[2]。ET 业务按优先级从高到底可划分为流量控制(rate-constrained, RC)和尽力而为(best-effort, BE)两种不同的优先级业务[3]。TTFC 交换机是TTFC 网络的关键组件,TTFC交换机在传统FC 交换机基础上增加了时钟触发TT 业务的数据交换。传统FC 交换机的实现由于受硬件的交换加速能力限制,大多采用无阻塞的交叉开关矩阵(crossbar)式直通交换结构[4],并根据信元缓存位置的不同分为输入和输出两种排队方式。而输入队列会出现线头(head of line, HOL)堵塞现象,通常采用虚拟输出队列(virtual output queue, VOQ)的方法来解决HOL 问题[5]。
为提升交换转发效率,降低转发延迟,减少交换调度开销,FC 交换机采用针对多优先级的变长调度算法来实现交换调度。OSP (orthogonal subspace projection)、p-iDRR (prioritized iDRR)等算法虽支持多优先级,但算法设计时采用固定长度的信元,其应用变长信元交换时会引入额外开销。RRM 算法在输出端指针同步时会增加性能的损耗等,这些问题在vp-RRM 算法中已得到了很好地解决。
在TTFC 网络中,由于TT 业务的加入,占用了交换端口的部分流量,同时TT 业务对各端口流量的占用不同,导致在进行ET 业务数据交换时,端口流量也不均匀。目前对于TTFC 网络的研究,大多从网络模型仿真的角度对网络的实现算法进行分析,暂没有文献结合TTFC 网络特点,对ET 业务的交换调度效率进行深入分析[6]。vp-RRM 算法基于端口序号进行轮询调度,每个队列的输出是无差别的,但流量的非均匀分布会导致个别队列等待时间较长,吞吐性能变差[7]。因此,本文在加权轮询调度算法的基础上,提出了基于流量自适应的多优先级变长轮询调度算法(traffic adaptive variablelength priority round robinmatching, tavp-RRM),该算法针对非均匀流量状态下的交换调度算法进行改进,使流量大的端口得到更多的调度机会,以此提升网络的吞吐效率。
1 tavp-RRM 算法
tavp-RRM 算法可基于端口流量队列的长度自适应调整其请求优先级,使负载量大的端口优先进行数据交换,从而提升TTFC 网络的吞吐率。其优点包括:支持非定长信元、非固定时隙、支持单播和广播队列、采用流水线工作和使用VOQ 等。
1.1 tavp-RRM 算法原理
算法原理如下:
1) 为了提升TTFC 网络的有序性,广播和组播业务均规划为TT 业务,ET 业务仅处理单播业务,因此在本文中,不讨论该算法对组播和广播业务的适用性。
2) 支持多优先级调度。TTFC 网络的ET 业务按优先级分为RC 和BE 两种业务。如图1 所示,业务信元传输至TTFC 交换机后,将依据其优先级存入各个VOQ 中。VOQ 向输出端口发起请求时,VOQ 的优先级会根据其队列长度及等待时间进行调整。优先级从高到低依次为P3、P2、P1、P0,RC 业务的起始优先级为P2,可提升的优先级为P3,BE 业务的起始优先级为P0,可提升的优先级为P1。

图1 VOQ 架构示意图
3) 输出端口同时收到多个输入端口的请求时,对优先级最高的输入端口先进行授权。
tavp-RRM 调度算法在研发阶段即注重硬件的可实现性,经过多次迭代,完成输入、输出端口的最优匹配[8]。通过在每个输入、输出端口设置多个仲裁器,通过循环优先级仲裁来依次匹配所有有效的输入和输出,以保证每一次迭代的独立性。
1.2 tavp-RRM 算法执行过程
tavp-RRM 算法的执行过程与 RRM 类似,分为“请求−授权−接受”,步骤如下:
1) 请求
输入端口接收到信元后,会向信元的输出端口发起包含当前数据优先级的请求,请求的优先级由3 种因素决定,分别为ET 业务的优先级、当前VOQ 的队列长度及当前VOQ 的等待时间。图2 给出了ET 业务VOQ 队列优先级的确定流程。

图2 ET 业务VOQ 队列优先级的确定流程
基于以下原则来确定阈值:
① 队列长度的阈值点距离队列满不小于2 个FC最长帧的空间,防止阈值生效太晚,从而导致对外部输入端产生流控;
② 队列长度的阈值点应大于队列半满的位置,避免阈值被频繁触发;
③ 队列排队时间阈值应小于系统可接收的最大延迟。
本文在仿真及实验验证过程中,以队列深度的3/4 作为队列长度阈值,以100 µs 作为队列排队时间阈值。
2) 授权
每个输出端口处设有1 个调度器,调度器通过轮询调度算法来匹配多个端口的请求,在均匀业务状态下具有良好的公平性。由于输入端的业务数据按照业务类型(RC 或BE)分配队列缓存,因此每个输出端口对不同类型的业务通过轮询指针r0 和r1 分别维护其调度状态。r1 对应RC 业务,优先级为P2 或P3;r0 对应BE 业务,优先级为P0 或P1。调度器进行调度时,先过滤出当前最高优先级的请求,在根据r0 或r1 的当前位置按顺序开始轮询查找,对找到的第一个请求进行授权,并通过r0 或r1 更新到当前授权位置的下一个位置处。
3) 接受
输入端口会同时向多个输出端口发起调度请求,当输入端口同时接收到多个端口的授权时,同一时刻只能接受一个授权。因此,输入端口需要对接收到的授权进行仲裁来选择最终接受方。输入端口的接受仲裁对不同类型的业务通过轮询指针c0 和c1 分别维护其仲裁状态。c1 对应RC 业务,优先级为P2 或P3;c0 对应BE 业务,优先级为P0 或P1。仲裁器进行仲裁时,先过滤出当前最高优先级的请求,在根据c0 或c1 的当前位置按顺序开始轮询查找,对找到的第一个授权进行接受,并通过c0 或c1 更新到当前授权位置的下一个位置处。图3 为一个4×4 端口的调度过程,在请求授权阶段,输出端口 1 在优先级 P2、P3 之间选择高优先级P3 对应的输入端口3;输出端口2 在3 路BE 业务中选择输入端口,输入端口1 由于其队列长度大于门限值,请求将优先级调整为为P1,因此选择高优先级P1 对应的输入端口1;输出端口3 在两个相同优先级 P0 端口间选择,此时输出端口3 对应BE 业务的r0=3,按照轮询机制,最终选择输入端口4 进行授权;输出端口4 在优先级P1、P0 间选择高优先级P1 对应的输入端口1。

图3 4×4 端口的调度过程
接受阶段,输入端口1 同时收到输出端口2 和输出端口4 的授权,由于两个授权的优先级相同均为P1,按照轮询机制从当前BE 的指针c0=3 启动轮询。输入端口1 优先查询到输出端口4 的授权,因此选择输出端口4 的授权进行接受。输入端口3 和4 由于仅接收了1 个授权,直接接受即可。
2 仿真分析
使用计算机仿真可以大幅降低crossbar 调度算法性能分析的难度,本节将通过计算机仿真来分析tavp-RRM 算法的吞吐量。吞吐量是指输出端口的平均利用率,即在一个时隙内平均发送的信元数量。在分析吞吐量性能时,本文将vp-RRM 算法作为比较的对象,vp-RRM 算法和tavp-RRM 的差异在于对优先级的管理不同,下面选取均匀业务流和非均匀业务流对两种算法的吞吐量性能进行对比。
1) 均匀业务流
输入端负载均相同,即 γi=γ,所有业务流在VOQ 中均匀分布。均匀业务流模型下,tavp-RRM和vp-RRM 的吞吐量均为相同的恒定值:

2) 非均匀业务流

业务流模型1 的算法吞吐量对比如图4 所示,根据式(2)可推算得知,1 个输出端口同时只转发两个输入端口的数据,在交换调度时竞争较少,转发效率本来较高,基于端口流量队列的长度自适应调整其请求优先级的功能(traffic adaptive, TA)作用不明显,vp-RRM 和tavp-RRM 仿真结果基本一致。

图4 业务流模型1 的算法吞吐量对比

图5 展示了在16×16 的crossbar 中tavp-RRM和vp-RRM 算法的吞吐量。从图中可以看到,当w=0 时,业务流为均匀业务流,tavp-RRM 算法的吞吐量与vp-RRM 算法一致;当w=1 时,业务流集中到同一个端口,达到满额负荷,tavp-RRM 算法的吞吐量与vp-RRM 算法相同。其他状态下tavp-RRM 算法的吞吐量性能始终优于vp-RRM,且w在0.5 附近时,性能差异达到最大。图5 的仿真结果说明tavp-RRM 算法相对于vp-RRM 算法,在多个输入端口向同一个输出端口发生转发竞争,且流量不均匀时,具有更高的交换调度效率。

图5 业务流模型2 的算法吞吐量对比
3 实验验证
本文采用复旦微电子公司的JFM7K325TFPGA设计了4×4 端口,速率为2.125 Gb/s 的TTFC 交换机。为了进行算法对比测试,TA 功能支持通过软件配置进行使能或关闭。
通过对交换机的TT 业务转发进行规划,使交换机各端口的TT 业务占用不同的带宽。TT 业务在端口1 至端口4 的输入带宽占用分别为9%、12%、15%和18%,输出带宽在非输入端口均匀分布。
使用JSDU 公司的XgigLoadTester 测试仪对TTFC 交换机进行ET 业务的吞吐量测试,由于测试仪不支持TT 业务注入,为了在测试中模拟TT业务引入的非均匀性,TTFC 交换机采用如下设计:初始化TTFC 交换机各端口的TT 调度配置,并在TT 业务的转发时隙,强制TT 转发路径处于忙状态,时隙内不进行ET 业务的转发[10]。
具体测试说明如下:
1)各端口激励数据均采用帧长为1024 B 的ET 帧;
2)测试拓扑采用图6 所示的不带自环的全网络拓扑模型。受测试仪功能限制,VOQ 分布采用均匀分布,通过TT 业务的影响引入非均匀因素;
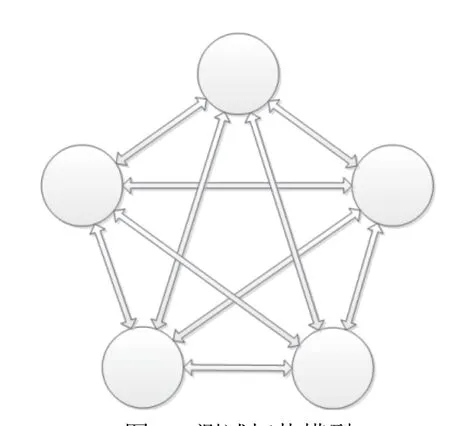
图6 测试拓扑模型
3)各端口测试激励初始为100%负载;
4)分别在TA 功能使能和关闭的状态下进行测试。
各端口在未开启TA 功能和开启TA 功能后的对比如表1 所示。tavp-RRM 算法的实测吞吐量性能优于vp-RRM,吞吐量提升在5%以上,表明TA功能对于非均匀流量环境下的吞吐量有改善作用。

表1 实测结果对比
4 结 束 语
本文根据TTFC 网络中ET 业务流量不均匀的特点,提出一种多优先级交换调度方案,基于端口流量队列长度进行优先级的自适应调整,使带宽资源紧张的VOQ 得到更多的授权机会,从而改善TTFC 网络的吞吐量性能,提高交换调度效率,更加适用于TTFC 网络的事件触发业务的交换调度。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
无线互联科技(2022年8期)2022-06-23
西安航空学院学报(2021年1期)2021-07-24
科学家(2021年24期)2021-04-25
汽车工程(2021年12期)2021-03-08
科学导报·学术(2020年26期)2020-10-21
科学与财富(2016年24期)2017-03-29
青年文学家(2016年32期)2016-12-23
智能制造(2015年10期)2015-11-04
城市建设理论研究(2011年28期)2011-12-31
