
基于聚类分析的煮茧工艺参数
2022-05-30 09:56段春稳任强胜卜献鸿王建平
纺织科技进展 2022年5期
段春稳 ,任强胜 ,卜献鸿 ,李 帆 ,黎 钢 ,王建平
(1.四川省丝绸科学研究院有限公司,四川 成都 610031;2.四川省丝绸工程技术研究中心,四川 成都 610031;3.现代茧丝绸制造技术资源四川省科技资源共享服务平台,四川 成都 610031)
制丝是将蚕茧加工成生丝的过程,包括混剥选茧、煮茧、缫丝、复摇整理、生丝检测等工序。煮茧是制丝生产的重要环节,煮茧质量直接影响到生丝质量、原料茧消耗、产量完成水平[1]。煮茧需要根据蚕茧原料特性,结合专业知识和煮茧经验来确定煮茧工艺,但由于蚕茧原料特性包含指标较多,专业技术人员水平及经验局限,煮茧工艺设计往往不能充分发挥蚕茧原料特性,并且在“试煮”过程中造成了大量原料浪费。
随着信息技术的发展,制丝行业生产过程中形成了大量繁杂的数据,包括茧质调查数据、煮茧生产数据、缫丝生产数据等,这些数据都是用于指导生产的重要技术指标,但由于数据的多样性、动态性、复杂性,以及目前制丝行业的技术局限,这些数据对煮茧工艺并未形成实质性的关联和指导。
介绍一种基于K-means聚类分析方法[2],对制丝行业形成的生产数据进行分析,为煮茧工艺参数设计提供指向性设计方案。
1 煮茧工艺
煮茧的目的是通过水、蒸汽等介质对蚕茧的作用,使干胶变成明胶[3-4],降低茧丝的胶着力,使茧丝能够依次离解,为缫丝创造条件。煮茧工艺的设计过程是根据蚕茧指标初步确定煮茧工艺,包括渗透、吐水、蒸煮、调整、保护过程的温度及时间。煮茧工艺设计方案目前参考解舒率、茧层率、蚕茧干燥程度、净度(环纇、纇结)等指标进行设置。不同原料的煮茧方法按解舒好、茧层厚的煮茧方法;解舒好、茧层薄的煮茧方法;解舒不良、茧层厚的煮茧方法;解舒不良、茧层薄的煮茧方法;干燥程度不同的煮茧方法;洁净差的煮茧方法[5]进行。煮茧结果按偏生、偏熟、适度、白斑、瘪茧、浮茧等状态来区分。目前煮茧工艺以蚕茧指标大概范围,来指导大概的参数区间,以经验判断为主。这种方法获得的煮茧工艺参数是一种随机、模糊的估算结果,其中反复调整和人为因素等不确定性导致了生产的不稳定和大量浪费且效率低下。
随着信息技术在缫丝行业的应用,在制丝大生产过程中,采集、存储了大量的茧质数据、工艺数据,这些数据若能有效用于煮茧工艺设计,能提高生丝的产量和质量,降低茧耗。
2 制丝生产数据的特点
2.1 多样性
制丝过程中形成了大量的茧质调查数据、煮茧生产数据、缫丝生产数据,这些数据既有关联,又有交叉,还有差异,其类型、形态、来源具有多样性。例如茧源特性一项,涉及的指标就非常多,包括蚕茧原料的基础数据和测试数据两部分,其中原料基础数据包含品种、季别、产地、饲养方式、茧型大小、茧层厚薄等指标;测试数据包含茧丝长、解舒率、茧层率、解舒丝长、单丝纤度、清洁、洁净、万米吊糙等指标。
2.2 时效性与动态性
制丝生产数据时效性、动态性较强,但由于技术局限,制丝生产数据往往存在滞后性,对煮茧工艺不能起到一对一的指导作用,往往通过滞后的数据指导下一批蚕茧进行工艺设计,使得煮茧工艺设计较依赖经验判断。
2.3 复杂性
制丝过程是一个复杂的系统。数据之间的关系呈现不确定性,数据间可能无法通过数学形式表示,数据关系较为复杂。
3 数据挖掘技术
数据挖掘(Data Mining),又称作数据库知识发现(Knowledge Discovery from Database,KDD),是从数据中获取价值的一个过程,可以形式化地表示为“数据+工具+方法+目标+行动=价值”[6]。数据挖掘分为有指导的数据挖掘和无指导的数据挖掘。有指导的数据挖掘是利用可用的数据建立一个模型,这个模型是一个特定属性的描述;无指导的数据挖掘是在所有的属性中寻找某种关系。其中,分类、估值和预测属于有指导的数据挖掘;关联规则和聚类属于无指导的数据挖掘。
作为无指导的数据挖掘方法的一种,聚类分析是从无标记数据集中获取信息和知识的重要手段,是数据挖掘、统计学、模式识别等领域的重要研究内容[7]。聚类分析算法可以作为一种强有力的能够发现制丝数据之间内在关系的、隐含的信息和知识的工具。结合制丝生产数据特点,探索将聚类分析方法用于制丝数据分析,为煮茧工艺参数设计提供指向性设计方案,是实现煮茧数字化、智能化的有效途径之一。
3.1 K-means聚类分析算法的实现探讨
K-means(K 均值算法)一种经典的划分方法,是目前应用较广泛的聚类分析方法,K-means算法的步骤如下[8]:
(1)从数据集中随机选出k个数据对象作为初始的聚类中心;
(2)将其他的数据对象按照某种聚类度量划分最近的聚类中心,从而将数据集划分为k个簇;
(3)计算每个簇中的数据对象的均值作为新的聚类中心;
(4)重新划分数据对象,不断重复这个过程,直到每个簇中数据对象不再变化为止。
其算法公式为:
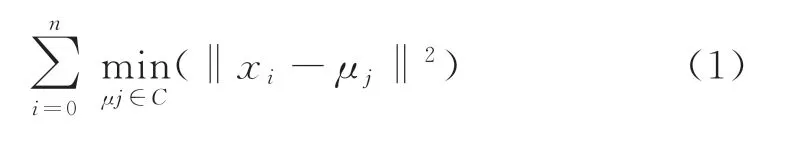
3.2 制丝数据聚类分析
3.2.1 架构设计
运用Python计算机编程语言实现聚类算法,具体通过Scikit-learn机器学习框架进行制丝数据分析,在实施方案中可以使用K-means++初始化方案,来解决K-means高度依赖于质心初始化和运算效率低的问题,并借助轮廓系数法提高聚类效率。
K-means聚类分析方法在制丝工艺数据分析中的模式探索:煮茧工艺设计目标最终体现在生丝品质和产量、茧耗上,选择以洁净成绩为聚类核心,对洁净成绩优秀的缫丝工艺进行特征提取,通过构建解舒率、茧层率、蒸煮温度等特征提取算法,测算出能够体现最优煮茧工艺的数值结果。
选择洁净成绩在94.5以上的制丝生产样本数据50条进行特征提取。对解舒率、茧层率和蒸煮温度3个特征值进行数据分析。通过pandas库将数据导入Python,对数据进行清洗和处理,在Scikit-learn 框架下进行K-means聚类。
导入的样本数据的散点图如图1所示。
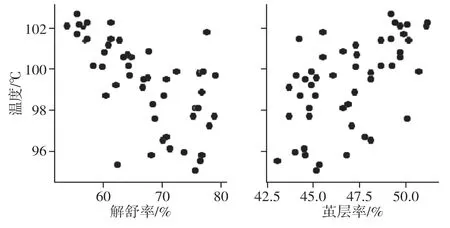
图1 样本数据散点图
从数据集的散点图不能直观地看出他们之间的规律,将通过聚类分析来探究数据之间的关系。
3.2.2 K-means算法实现
随机选择k值,以k=4为例,对数据进行针对解舒率、茧层率、蒸煮温度值的三维聚类代码及聚类结果,如图2所示。
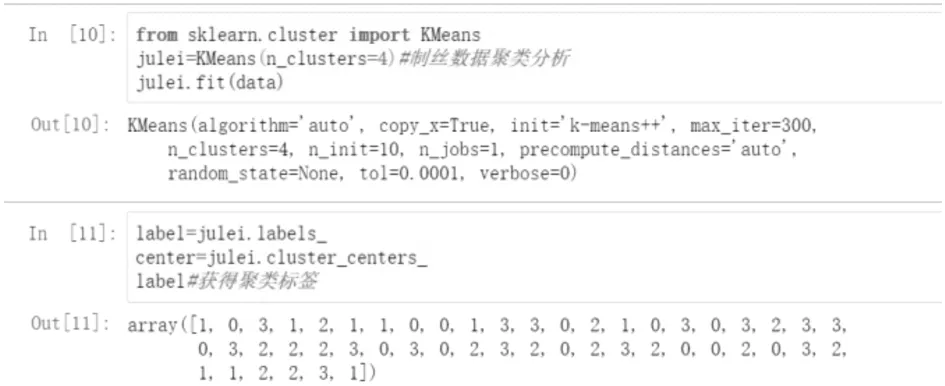
图2 三维聚类代码及聚类结果
由聚类结果可以看出:上述所列50个样本分别按要求划分为4簇,所属的聚类标签如图2所示,即第一个样本属于第1簇,第二个样本属于第0簇,第三个样本属于第3簇,以此类推。
3.2.3 基于轮廓系数的聚类簇数确定
上述过程得到的聚类结果,我们不能判定其聚类效果,需要多次运行K-means算法来确定聚类的簇数k,聚类效率低。轮廓系数法结合内聚度和分离度2种因素,可以对相同原始数据上的不同聚类结果进行评价[9]。因此,我们利用轮廓系数来确定聚类簇数:若s(i)的类内内聚度为a(i),类间分离度为b(i),则s(i)的轮廓系数为:

轮廓系数s(i)在-1和1之间变化,s(i)的值越接近1聚类效果越好。根据公式(2),对聚类结果进行轮廓系数计算,其代码及运算结果如图3所示。

图3 聚类结果轮廓系数代码及运算结果
k=4时的轮廓系数为0.429 126 416 366 412 5。之后,分别计算k=2~(n-1)的聚类结果的轮廓系数,其代码和结果如图4所示。
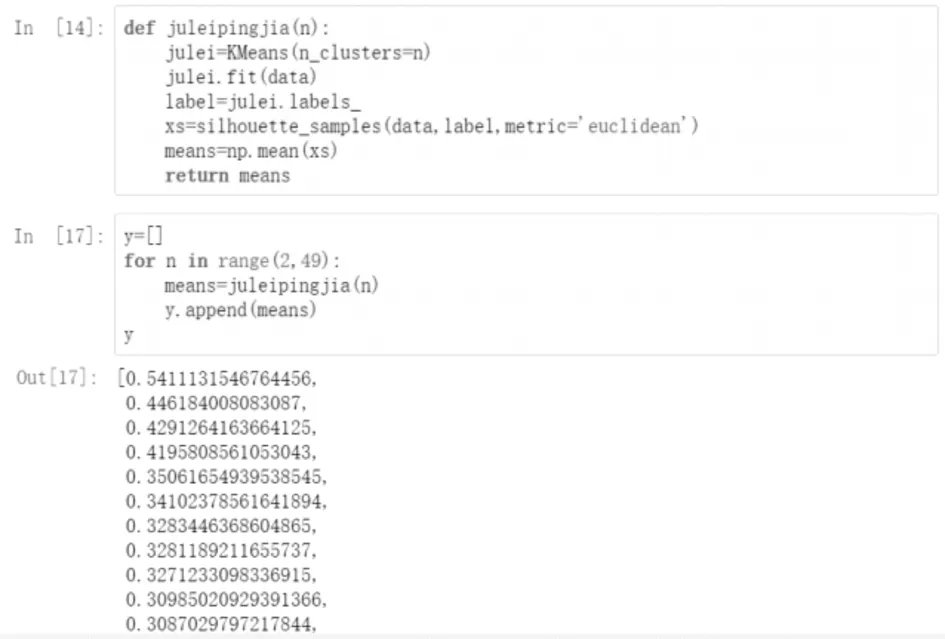
图4 聚类代码及结果(k=2)
从结果可以看出当k=2 时轮廓系数最大,为0.541 113 154 676 445 6,聚类效果最好。因此,对数据集进行k=2的聚类,其聚类代码及结果如图5所示。
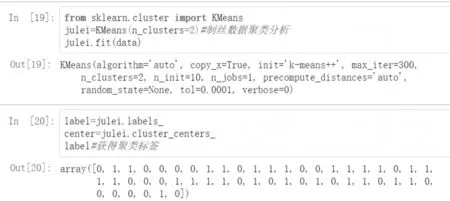
图5 聚类代码及结果(k=2)
通过聚类算法,将50个样本数据分成了聚类标签为0和1的2类。
3.2.4 聚类结果有效性评价
在得出聚类结果后,需要对每一类对象进行描述分析,分析这一类对象最典型的共性是什么,从而理解为什么这些对象会被分到一类中,解读这些数据的相似性。这一步需要凭借技术和经验进行人为解读。
为了便于对聚类结果进行解读,通过可视化软件对上述聚类结果进行可视化呈现,如图6所示。
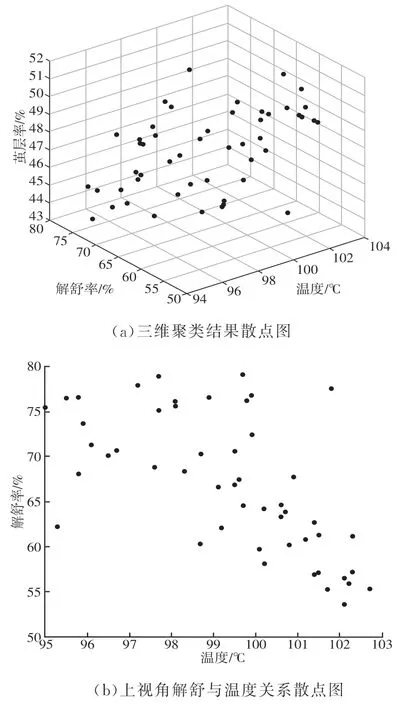
图6 样本聚类结果散点图
从图6可以看出聚类结果将数据样本聚为边界清晰的2类。通过对聚类结果的解读,其聚类所得的2个簇,回到数据表本身进行分析,可以得出解舒率、茧层率、煮茧温度之间的对应关系大致区间范围,见表1。

表1 解舒率、茧层率及煮茧层对应关系
这一结果是通过数据分析得来的,与实际生产经验所得以及教科书指向意见一致。证明了采用聚类分析对制丝数据进行分析,用于指导煮茧工艺设计的可行性。由于50个样本数据代表性存在一定的局限,下一步将采用更多的样本数据做进一步分析。
4 结束语
K-means聚类分析方法在对制丝过程中形成的大量数据进行聚类分析,能够挖掘出数据价值,提取出来的特征数据及其聚类结果对煮茧工艺设计具有一定的指向性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
九江学院学报(自然科学版)(2022年2期)2022-07-02
南京理工大学学报(2022年1期)2022-03-17
计算机应用与软件(2021年7期)2021-07-16
小读者(2021年4期)2021-06-11
大众投资指南(2021年35期)2021-02-16
广州文艺(2020年7期)2020-07-30
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
电子技术与软件工程(2016年24期)2017-02-23
小樱桃·童年阅读(2016年11期)2016-12-19
