
基于多级脉冲特征集融合的行人重识别方法
2022-05-30 10:48费孝如叶武剑刘怡俊吕友成姜子星
电脑知识与技术 2022年29期
关键词:特征融合
费孝如 叶武剑 刘怡俊 吕友成 姜子星

摘要:针对提取监控视频中行人的时空特征相对困难和使用步态这一时空特征进行小样本学习后,准确率相对较低的问题,提出一种基于多级脉冲特征集融合的行人重识别方法(MSSF)。首先,通过脉冲卷积提取基于步态图像帧的局部行人脉冲特征,在此基础上,将局部脉冲特征映射为具有全局行人属性的脉冲特征集;接着通过融合不同深度级别的脉冲特征集来表征行人的时空多维特征,并使用水平金字塔进一步提取更具区分度的特征;最后,通过时空梯度反向传播优化网络参数。实验在CASIA-B数据集上进行,在小样本学习后,跨视角正确率最高达到了71.7%,提升4.91%,验证了所提方法的有效性。
关键词: 行人重识别;步态特征;脉冲神经网络;多级脉冲;特征融合;时空梯度
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2022)29-0008-04
1 概述
行人重识别(Person Re-identification)也称行人再识别,是指从单帧图像或视频序列中查找特定目标行人的过程,是一个图像检索问题。随着监控安防应用的发展和普及,行人重识别作为远距离公共监控场景下难以进行人脸识别的重要补充,其需求日益增长且相关技术得到了广泛的关注[1]。由于监控设备的差异、光照强度的变化、行人衣着的变换和行走角度的变化等影响,不同时间地点的监控视频中行人的外观会产生很大变化,因此行人重识别研究面临很多困难。
行人重识别研究一般可分为基于单帧图像和基于视频序列两种。基于单帧图像的行人重识别主要通过卷积神经网络提取行人衣服的颜色和样式等外观特征来进行分析[2-4],这样的行人特征往往是容易改变的,且受光线和监控设备的影响较大,只适用于短时间内的行人检索。而基于视频序列的行人重识别研究可以充分利用监控视频数据,提取行人在时间和空间维度上的特征,防止只依赖不稳定的外观特征,更贴近实际应用。Yao等人[5]将行人完整步行周期内的视频图像进行平均处理得到骨骼步态能量图。Niall等人[6]提出了一种结合卷积、时间池化的新型循环神经网络来联合提取视频中的行人特征。Li等人[7]提出了一种多尺度三维卷积网络来提取视频时间维度特征,并结合二维卷积提取的空间维度特征来提升行人重识别的鲁棒性。
目前,大部分基于视频序列的行人重识别方法提取视频序列中更具区分度的时空特征能力有限,进而导致在小样本学习中无法获得较高的准确率。因此,本文提出了一种基于多级脉冲特征集融合(MSSF)的行人重识别方法,通过引入对时空信息敏感的脉冲神经网络,对行人的步态这一时空特征进行分析,来提高网络模型提取时空特征的能力。首先,通过脉冲卷积操作提取基于行人步态图像帧的脉冲特征,以表征行人的局部时空特征;在此基础上,将基于图像帧的脉冲特征映射为脉冲特征集,来表征全局的时空特征;接着,通过融合不同深度级别的脉冲特征集进一步提取更具區分度的特征,并使用水平金字塔提高特征表征能力;最后,通过时空梯度反向传播优化网络参数。实验在CASIA-B数据集上进行,结果表明,本文所提出的MSSF模型可以有效提取行人的时空特征,提升了小样本学习下跨视角情况的步态识别准确率。
2 方法
2.1 网络模型框架
本文提出的MSSF模型,主要包括基于图像帧的脉冲特征提取、多级脉冲特征集融合和水平金字塔混合特征映射三大部分,分别对应图1中的模块A、B和C。本模型首先通过脉冲神经网络,提取不同感受野下局部脉冲特征;接着,通过卷积操作,将多个不同深度级别的不同局部脉冲特征映射为脉冲特征集,并进行汇总融合;最后,通过水平金字塔将特征映射为更具区分度的条带状特征,以提高网络的识别精度。
2.2 多级脉冲特征集融合
如图1中A部分所示,输入的行人序列首先经过3层脉冲卷积操作后,得到了3列具有不同深度的基于图像帧的局部脉冲特征。为了更好地提取时间维度上的特征,本文将每一列作为一个集合进行统计学的平均或最大值池化操作,提取出具有全局特性的多级脉冲特征集,如图1中的B部分所示。同时,为了有效地提高识别的准确率和鲁棒性,本文使用水平金字塔映射(HPM,Horizontal Pyramid Mapping)方法将特征分割成条带状[8-9],如图1中的C部分所示。由于特征映射的对象是B部分提取出的全局特征和C部分提取出的局部特征,故本文将该方法称为水平金字塔混合特征映射。
最终,通过水平金字塔混合特征映射模块,将行人的特征映射到更具有辨别度的深层空间,此时最终的特征可以重新调整其维度,使其方便计算特征之间的距离,进而完成行人重识别的训练和测试过程。
2.3 损失函数
由于脉冲信号离散的特性,需要在层与层之间的空间维度和层内部的时间维度分别做反向传播,因此本文采用时空反向传播STBP(Spatio-Temporal Back Propagation)[11-12]来训练所提出的MSSF模型。
3 实验分析
3.1 实验环境和数据集设置
本文实验在Centos7服务器上完成,实验基于Python和PyTorch进行。
本文采用标准数据集CASIA-B [13]进行实验,该数据集包含有124个行人样本的视频序列图像,且每个行人均有3种不同状态(正常状态NM、背包状态BG和含有外套状态CL)和11个行走角度(0°, 18°, 36°, … , 180°)。
在所有实验中,图片根据文献[14]中的方法统一对齐为64×44大小。在训练过程中,一个批次中有4个不同的行人,每个行人有8组样本,每组样本由30张视频序列图组成。同时,本文采用置信度最高的图片的正确率(rank-1正确率)作为评价指标[15]。
為了验证所提出的MSSF模型是否能够提取更具区分度的时空特征,本文采用小样本数据集划分方法进行实验,将CASIA-B中的前24个行人作为训练集,后100个行人作为测试集。本次对比实验仅对比正常状态(NM)下重识别效果。
3.2 实验结果与分析
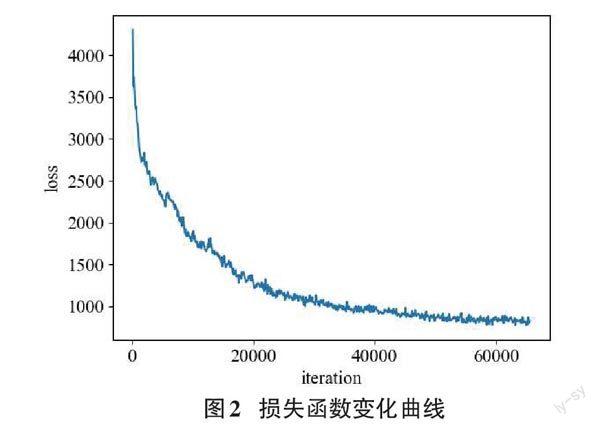
首先,根据时空反向传播训练过程中的损失变化情况,绘制了如图2所示的损失曲线。图中横坐标为训练迭代次数,纵坐标为损失值,可以发现所提出的MSSF模型在STBP下可以有效地进行拟合。
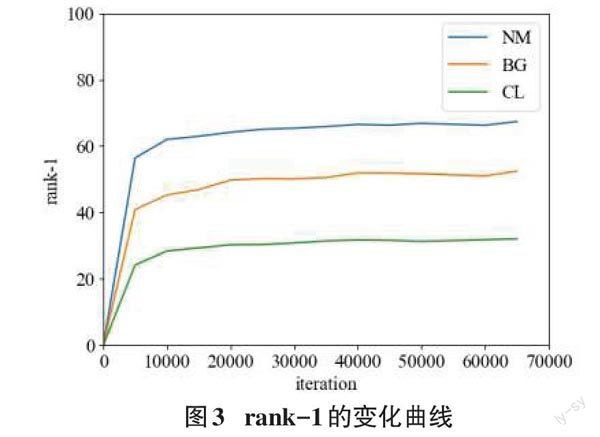
接着,针对数据集中的NM、BG和CL三类不同的行人状态,本网络模型在所有角度的测试集上进行测试,得到平均准确率变化曲线如图3所示。图3中,横坐标表示训练迭代次数,纵坐标表示rank-1准确率。可以看出NM状态下的准确率最高,最终达到64%,BG和CL最终达到52%和32%。
随后,将所提出的MSSF模型提取的不同深度级别的脉冲特征进行可视化,如表1所示。第一列为初始时刻step=0时的输入视频序列图像,以该张图为例,给出了三个深度级别下的特征图。首先,在第一级别的特征图中,可以发现经过脉冲卷积后的基于图像帧的脉冲特征能够有效地表征行人的外形轮廓和内部形状的局部特征,在映射为脉冲特征集后,可以明显地发现,基于脉冲特征集的特征将基于帧的特征进行了汇总整合,能够表征更为丰富的全局特征。随着级别的升高,基于图像帧的脉冲特征所呈现的维度更加抽象,脉冲特征集也在前者的基础上形成了能够吸收局部特征的高维全局特征。
最后,为了验证所提出的模型在小样本学习情况下的准确率,本文与Weig. Fusion[16],FBW-CNN[17],CMCC[18]和ASTSN[19]进行实验对比,结果如表2所示。可以发现,除了0°时,所提出的MSSF比ASTSN低1.7%以外,其余各角度的平均rank-1正确率均优于其他方法。
4 结论
本文提出了一种基于多级脉冲特征集融合的行人重识别方法,通过脉冲信息表征行人图像帧的局部特征,并将不同深度级别和不同图像帧的脉冲特征融合为全局脉冲特征,最终通过水平金字塔映射为更具区分度的时空特征。实验结果表明:在小样本训练中,本文提出的模型具有优势。
但是,目前的识别方法距离实际应用还有很大差距,在准确率方面还有很多提升空间,在脉冲编码和网络设计等方面仍然需要继续优化。
参考文献:
[1] Leng Q M,Ye M,Tian Q.A survey of open-world person re-identification[J].IEEE Transactions on Circuits and Systems for Video Technology,2020,30(4):1092-1108.
[2] Wang G A,Yang Y,Cheng J,et al.Color-sensitive person re-identification[C]//Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence.August 10-16,2019. Macao,China.California:International Joint Conferences on Artificial Intelligence Organization,2019:933-939.
[3] Hong P X,Wu T,Wu A C,et al.Fine-grained shape-appearance mutual learning for cloth-changing person re-identification[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Nashville,TN,USA.IEEE,2021:10508-10517.
[4] Jin X,Lan C L,Zeng W J,et al.Style normalization and restitution for generalizable person re-identification[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Seattle,WA,USA.IEEE,2020:3140-3149.
[5] Yao L X,Kusakunniran W,Wu Q,et al.Robust gait recognition using hybrid descriptors based on Skeleton Gait Energy Image[J].Pattern Recognition Letters,2021,150:289-296.
[6] McLaughlin N,Martinez del Rincon J,Miller P.Recurrent convolutional network for video-based person re-identification[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas,NV,USA.IEEE,2016:1325-1334.
[7] Li J N,Zhang S L,Huang T J.Multi-scale 3D convolution network for video based person re-identification[J].Proceedings of the AAAI Conference on Artificial Intelligence,2019,33:8618-8625.
[8] Fu Y,Wei Y C,Zhou Y Q,et al.Horizontal pyramid matching for person re-identification[J].Proceedings of the AAAI Conference on Artificial Intelligence,2019,33(1):8295-8302.
[9] Wang G S,Yuan Y F,Chen X,et al.Learning discriminative features with multiple granularities for person re-identification[C]//Proceedings of the 26th ACM international conference on Multimedia.Seoul,Republic of Korea.New York:ACM,2018:274-282.
[10] Schroff F,Kalenichenko D,Philbin J.FaceNet:a unified embedding for face recognition and clustering[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition.Boston,MA,USA.IEEE,2015:815-823.
[11] Wu Y J,Deng L,Li G Q,et al.Direct training for spiking neural networks:faster,larger,better[J].Proceedings of the AAAI Conference on Artificial Intelligence,2019,33(1):1311-1318.
[12] Zheng H L,Wu Y J,Deng L,et al.Going deeper with directly-trained larger spiking neural networks[J].Proceedings of the AAAI Conference on Artificial Intelligence,2021,35(12):11062-11070.
[13] Yu S Q,Tan D L,Tan T N.A framework for evaluating the effect of view angle,clothing and carrying condition on gait recognition[C]//18th International Conference on Pattern Recognition (ICPR'06).Hong Kong,China.IEEE,2006:441-444.
[14] Takemura N,Makihara Y,Muramatsu D,et al.Multi-view large population gait dataset and its performance evaluation for cross-view gait recognition[J].IPSJ Transactions on Computer Vision and Applications,2018,10(1):1-14.
[15] Chao H Q,He Y W,Zhang J P,et al.GaitSet:regarding gait as a set for cross-view gait recognition[J].Proceedings of the AAAI Conference on Artificial Intelligence,2019,33:8126-8133.
[16] 呂蕾,张金玲,朱英杰,等.一种基于数据手套的静态手势识别方法[J].计算机辅助设计与图形学学报,2015,27(12):2410-2418.
[17] 王松林.基于Kinect的手势识别与机器人控制技术研究[D].北京:北京交通大学,2014.
[18] 胡弘,晁建刚,杨进,等.Leap Motion关键点模型手姿态估计方法[J].计算机辅助设计与图形学学报,2015,27(7):1211-1216.
[19] 徐胜,冯文宇,刘志诚,等.基于机器视觉的复杂环境下精确手势识别算法研究[J].系统仿真学报,2021,33(10):2460-2469.
【通联编辑:唐一东】
猜你喜欢
电脑知识与技术(2018年14期)2018-07-12
现代电子技术(2018年9期)2018-05-05
现代电子技术(2018年1期)2018-01-20
数字技术与应用(2017年11期)2018-01-11
现代电子技术(2017年16期)2017-09-07
软件导刊(2017年7期)2017-09-05
无线互联科技(2017年12期)2017-07-18
科技资讯(2017年11期)2017-06-09
电子技术与软件工程(2017年5期)2017-04-23
现代电子技术(2017年7期)2017-04-14
