
面向中文搜索的网络加密流量侧信道分析方法
2022-05-31 06:18祝跃飞
电子与信息学报 2022年5期
李 玎 林 伟 芦 斌 祝跃飞
(战略支援部队信息工程大学 郑州 450001)
(数学工程与先进计算国家重点实验室 郑州 450001)
1 引言
网络加密流量侧信道分析借鉴了传统侧信道分析的思想,绕过破解数据加密算法本身,利用网络应用客户端与服务器之间交互产生的数据包长度、时间、方向所组成的序列和统计特征,试图推断出用户敏感信息,如使用的设备类型[1]、浏览的网站[2]或视频[3]、语音通话内容[4]、视频直播动作[5]、键盘输入口令[6]等。网络侧信道分析在用户无感的情况下被动监听网络流量,相比域名劫持、证书劫持等主动攻击方法,其代价较低,成为近年来网络监管和打击犯罪的重要手段。
以搜索引擎为代表的网络应用通常提供增量式搜索的服务,即在用户输入的过程中根据部分查询内容提供实时更新的建议列表。为提高响应速度,浏览器会在用户每次击键时立即向服务器发送查询请求。尽管搜索和应答内容会被加密,但加密数据包序列仍然会泄露用户击键时间、查询和建议长度等信息。2010年,Chen等人[7]提出模糊集缩减的搜索查询分析方法。攻击者通过匹配建议列表长度对应的数据包长度序列,可以一次推断用户的一个按键。然而在2012年,以谷歌为代表的搜索引擎率先改进了查询推荐策略,服务器会根据时事热点、地理位置等因素生成不同长度的建议列表。为此,Schaub等人[8]在2014年提出随机化匹配的分析方法。对于同一搜索查询,假设建议列表长度符合高斯分布,并将数据包长度属于某个已知前缀字符串的概率乘积作为查询的预测值。该方法虽然可以应对变化的建议列表,但因状态爆炸存在实践上的困难。2017年,Oh等人[9]借鉴网站指纹攻击的思想,通过构造以下行流量为主的247个统计和序列特征作为关键字指纹,实现对用户输入关键字的识别。该方法同样依赖于稳定的服务器应答,因此容易受到概念漂移的影响,当搜索建议或结果发生改变时分类器的预测精度将降低。2019年,Monaco[10]首次提出只利用搜索请求数据包特征的分析方法。该方法基于数据包长度增量实现了击键探测,但宽松的状态转移条件会导致错误地接收无关背景流量。此外,采用语言生成模型从固定的词典中推断查询,搜索空间会随词典规模呈指数级增长,使攻击者的相对信息增益过低。
现有工作已经证明了网络搜索侧信道分析的可行性,但在如何利用更加稳定且区分度高的流量特征以提高识别准确率等方面依然有待进一步研究。此外,这些研究工作只涉及英文输入的搜索查询,缺少针对中文搜索的分析方法,存在一定的局限性。针对上述问题,本文提出了一种面向中文搜索的网络侧信道分析方法。该方法通过监听增量式搜索产生的网络加密流量获得击键数据包的长度和时间,然后综合利用侧信道泄露的拼音音节和击键时间信息推断用户可能输入的中文查询。本文的主要贡献为:(1)分析了中文搜索信息泄露的根本原因,即请求数据包长度增量和时间间隔的可区分性,基于信息论对信息泄露进行理论量化;(2)构建了3阶段的侧信道分析模型,利用数据包长度增量可区分性实现击键探测,降低了背景流量对探测准确率的影响,通过基于状态的多层匹配和基于时间的查询推断,大幅提高了查询识别准确率;(3)针对中文搜索常用的百度、搜狗、360和必应搜索引擎,在实际环境中收集了模拟用户搜索的流量数据集,对理论量化值进行了实验验证,并针对性地提出了可能的缓解机制。
2 背景知识
本节介绍了中文搜索侧信道信息泄露的原因。其中,单行模式拼音输入法的内在属性造成了增量式搜索网络流量的信息泄露,而HTTP/2头部压缩算法进一步增加了其泄露的信息量。
2.1 单行模式拼音输入法
拼音是汉语的拉丁化方案,通过26个字母组成的约400个音节拼写出所有汉字。由于拼音使用的广泛性,拼音输入法成为键盘输入汉字的首选。使用拼音输入法时,用户不需要指明音节的边界,输入法会自动在音节之间插入撇号或空格分隔符。当用户输入新音节的第1个字母时,拼音字符串的长度会增加超过1个字符。通过拼音字符串的长度变化,可以推测用户输入拼音的长度和数量。
传统输入法将音节缓存在浮动面板中,只有当用户完成候选字选择时目标应用才能获取输入。为了使目标应用能够对输入音节做出响应,新型输入法采用所谓单行模式,即在浮动面板中仅保留1行候选汉字,将输入音节直接缓存在目标应用中。常用的单行模式输入法如表1所示。采用单行模式的拼音输入法虽然提升了用户体验,但是会将输入的音节暴露给目标应用,间接导致了本文利用的中文搜索信息泄露。

表1 常见单行模式拼音输入法
2.2 AJAX增量式搜索
AJAX(Asynchronous JavaScript And XML)是一种动态网页开发技术,支持网页在后台与服务器进行交互,能够在不刷新页面的情况下更新网页内容。AJAX技术使增量式搜索成为可能。当探测到用户输入时,网页会将当前搜索框中的内容作为URL查询部分的参数,通过HTTP请求发往服务器,服务器根据算法生成建议列表并应答。用户在必应搜索中输入“毒品”的过程如图1所示。相比服务器应答,搜索请求的内容与时事热点等因素无关,且发送时间不受网络延迟的影响,因此具有更稳定的特征。
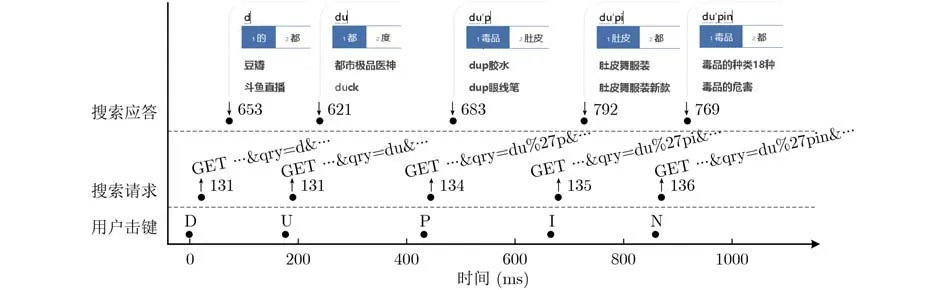
图1 AJAX增量式搜索实例
为保护用户输入的查询,搜索引擎普遍采用TLS协议加密应用层数据。然而,现有TLS版本中的数据加密算法均保留了原始明文长度。例如,在TLS 1.3版本的加密套件中,数据加密虽然基于块加密算法AES,但是在GCM或CCM链接模式下会自然转化为流加密算法。根据RFC 3986,撇号和空格在URI规范中属于特殊字符,因而URL中的拼音分隔符会被百分号编码,在查询字符串中占据3个字符。在一次搜索中,由于HTTP头部和URL中的其余部分通常保持不变,查询字符串的长度变化会完整保留在加密数据包序列中。除了长度特征,搜索产生的请求数据包序列还会暴露击键时间特征。由于AJAX增量式搜索会在用户每次击键时立即向服务器发送查询请求,击键时间被完整保留在请求数据包中。根据人体运动Fitts定律[11],击键所需的手部运动距离越远,击键所用的时间越长,因此数据包时间会泄露一定的原始输入信息。
2.3 HTTP/2头部压缩算法
HTTP/2协议旨在通过管线化请求和头部压缩算法来提高HTTP/1.1协议的请求效率。根据RFC 7541,HTTP/2头部压缩算法一方面使用索引值代表固定的头部字段,如Host等,另一方面通过静态哈夫曼编码来压缩变化的字符串,如请求URL。在编码字符串中,每个ASCII字符使用固定比特长度的哈夫曼编码代替,编码后的总长度用最后一个比特的反码填充到整字节。由于小写字母的哈夫曼编码长度为5~7 bit,短字母更可能导致字节的零增长,因此,编码URL的长度增量序列会泄露有关拼音的少量信息。

3 泄露信息量化

图2 HTTP/2头部哈夫曼编码字符串
本节对中文搜索网络流量泄露的信息进行量化,针对用户输入过程中查询长度和击键时间的变化分别定义了数据包长度增量和时间间隔可区分性,并考虑搜索应用的参数和模型对信息泄露带来的影响。
3.1 数据包长度信息
定义数据包长度增量可区分性为不同击键导致的数据包长度增量差异。假设{s1,s2,...,sn}表示击键序列X={x1,x2,...,xn}产 生的数据包长度序列,n为击键次数,xi取 值为26个字母,D={d1,d2,...,dn−1}表示数据包长度增量序列,即di=si+1−si。根据不同击键导致的查询字符串长度变化,将xi分为两种类型:集合A表示增长1字符的非音节首字母,集合B表示增长4字符的音节首字母。对于HTTP/2网站,当x∈A时导致0或1字节增量,x∈B时导致2或3字节增量,即哈夫曼编码不影响数据包长度增量可区分性。
上述对于长度增量可区分性的分析是基于HTTP请求中非查询部分保持不变的假设,该假设并非对所有搜索引擎都成立。百度和必应搜索的请求URL中包含指示指针位置即当前字符数的“cp”参数,当该参数值产生进位或哈夫曼编码比特数发生变化时,可能会影响总长度的变化。此外,百度搜索还在URL中包含上一次查询字符串的“pwd”参数,以及在第3次击键请求中添加若干固定长度的Cookie。从表2可知,可变URL参数的存在仍然可以保证数据包长度增量可区分性。
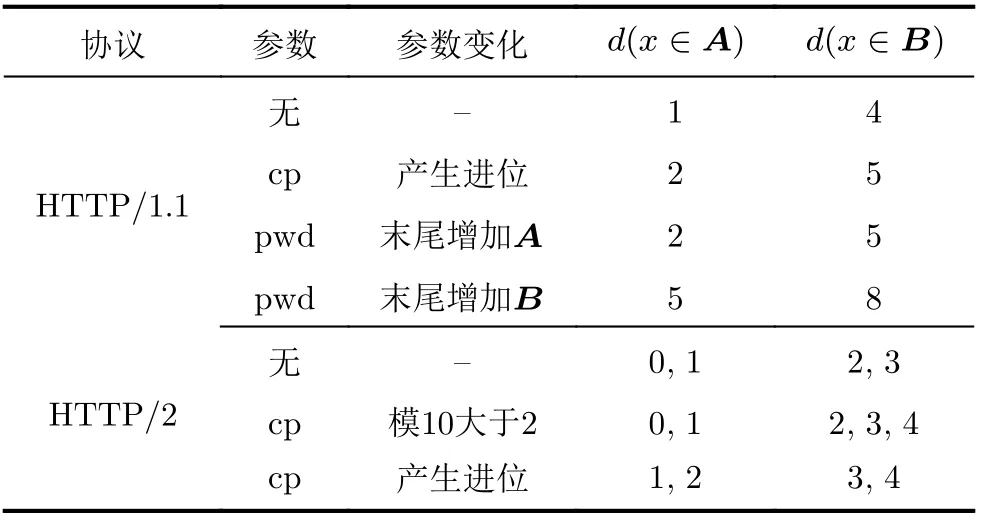
表2 URL参数对数据包长度增量可区分性的影响
基于数据包长度增量可区分性,进一步量化信息增益。对于攻击者来说,用户击键的初始不确定性为X的信息熵H(X) , 观察到序列D后的剩余不确定性为条件熵H(X|D), 获得关于X的信息增益为

对于给定的序列D,通过贝叶斯公式可以得到用户击键序列的条件概率
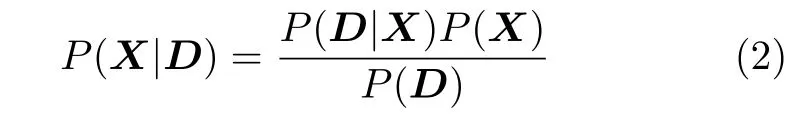
其中,P(D|X)的取值与是否采用哈夫曼编码有关:对于HTTP/1.1网站,有P(D|X)∈{0,1},攻击者只能推断拼音音节数量及长度;对于HTTP/2网站,有P(D|X)∈{r/8,0≤r ≤8},攻击者能够获取关于拼音字母的额外信息。
采用包含140469个词条的清华大学开放中文词库(THUOCL)作为搜索查询集对信息增益进行量化。假设攻击者通过数据包序列能够确定击键次数n,图3(a)显示了I(X;D)随查询拼音字母长度的变化。随着查询长度增加,序列D的独特性使信息增益不断增加,HTTP/2哈夫曼编码泄露的额外信息使增益更快地接近最大熵。此时,X的不确定性变得很小,攻击者有极大概率一次性猜对目标。通过推导可得,当每个查询具有相等的先验概率时,攻击识别准确率为
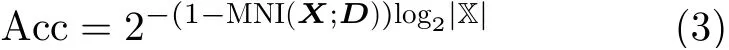
其中, M NI(X;D)=I(X;D)/H(X)为相对信息增益,| X|为X取值集合的基数。图3(b)显示了识别准确率与拼音字母长度的关系,理论上攻击者利用数据包长度信息泄露可以准确识别长度大于25个字符的查询。

图3 数据包长度增量泄露信息量化
3.2 数据包时间信息
定义数据包时间间隔可区分性为不同击键双字母对(bigram)导致的数据包时间间隔差异。假设{t1,t2,...,tn}表 示击键序列X产生的数据包时间序列,τ={τ1,τ2,...,τn−1}表示数据包时间间隔序列,其中τi=ti+1−ti。文献[6]验证了用户输入SSH口令时的数据包时间间隔可区分性。虽然HTTP搜索请求与SSH请求高度相似,但是部分搜索引擎采用节流计时器来限制请求数量,计时器到期之前的多次击键会被合并到一个请求中,因此可能影响搜索请求数据包的数量和时间。
除了节流计时器的影响之外,攻击者观察到的数据包时间间隔还会受到网络延迟抖动的影响。统计数据显示[13],亚太地区的IP数据包平均延迟约为75 ms,平均延迟抖动不超过0.01 ms。由于用户平均击键时间间隔远大于普通的网络延迟抖动,正常情况下网络状态的变化所带来的影响基本可以忽略。第6节将进一步评估人工增加的大量延迟抖动对数据包时间间隔可区分性的影响。
对数据包时间间隔可区分性带来的信息增益做进一步量化。与包含大量单词的字母文字相比,中文输入的字母组合相对固定,例如,英文单词中不同bigram的数量接近最大值262,而拼音中只包含112个,即中文输入的最大熵比英文低2.6 bit。假设随机变量β表示bigram,则攻击者观察到τ时的信息增益为

根据文献[6],特定bigram的击键时间间隔近似符合高斯分布,即P(τ|β)~N(µβ,σβ) ,其中µβ和σβ分别表示均值和方差。采用包含20个用户击键数据的CMU数据集[14]对每个拼音bigram的分布参数进行最大似然估计(β样本数大于10),得到τ的概率分布如图4(a)所示,可以看到,不同手部运动行为的β之间存在一定的可区分性。图4(b)显示了3个不同用户对于给定τ的信息增益I(β;τ),虽然输入每个bigram只有0.4~0.5 bit的信息增益,但由于较长查询的积累效应,攻击者可以进一步确定用户输入的搜索查询。
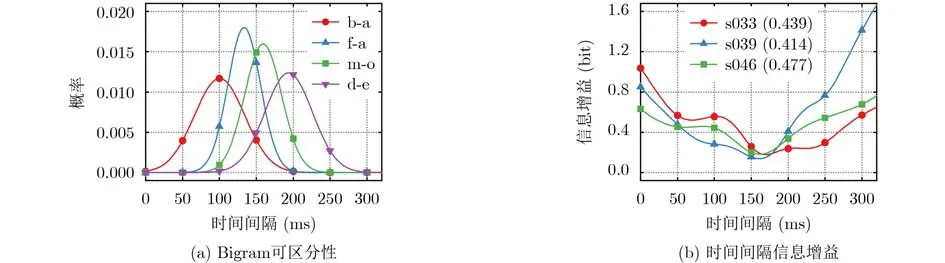
图4 数据包时间间隔泄露信息量化
4 侧信道分析方法
本节描述了中文搜索侧信道分析方法,实现对网络流量泄露信息的利用。该分析方法分为3个阶段,其中,击键探测和歧义缩减阶段利用了数据包长度信息,查询推断阶段利用了数据包时间信息。
4.1 击键探测
击键探测利用数据包长度增量可区分性建立确定有穷状态机(Deterministic Finite Automaton,DFA),通过接收最长数据包序列的动态规划算法从背景流量中检测出击键数据包序列。
击键探测前,首先对网络流量进行预处理。在数据传输过程中,网络状况的变化会增加网络延迟抖动,可能造成数据包乱序。当网络出现严重拥塞时,TCP协议会根据滑动窗口来重传未收到应答的数据包。因此,利用递增的TCP序号调整乱序的数据包,并根据重复的序号去除重传数据包。此外,为了消除其他网络应用以及无关TLS连接产生的背景流量的影响,利用TLS协议握手数据包中的SNI(Server Name Indication)字段过滤出包含击键数据包的TLS连接。数据预处理不仅降低了网络状态变化和无关网络流量对数据包长度增量带来的影响,并且能够最大限度地提高击键探测的效率。
根据查询字符串长度增量建立DFA模型M=(Q,Σ,δ,q0,F) ,其中,状态集Q包含不同的击键类型,输入集Σ表示可接收的长度增量,转换函数δ表示Q×Σ →Q上的映射,即δ(q,d)表示从状态q沿着边d到达的状态,q0表示起始状态,F表示结束状态集。为了简化模型,假设用户仅使用26个字母输入正确的拼音音节,不使用退格键(Backspace)、删除键(Delete)或方向键修正已输入的内容,并且查询字符串中不包含英文、数字或特殊字符。图5显示了不同HTTP版本下的DFA模型,对于HTTP/2网站,利用状态A0和B0记录编码URL长度的零字节增长(不计分隔符)。
总之,作为我们现一代交通工程技术人员有责任也有义务通过艰苦努力积极探索改善钻孔灌注桩质量缺陷处理的新技术,新方法,在以后的交通工程建设中得到有效的发挥,为以后的桥梁工程建设作一份贡献。
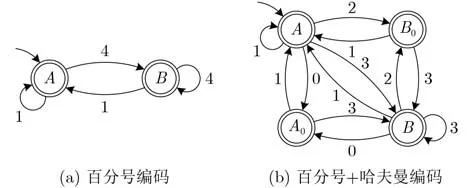
图5 查询字符串长度增量DFA模型
为了从大量的网站背景流量中检测出击键数据包序列,构建基于DFA模型的动态规划算法,如表3所示。在DFA模型接收的过程中,由于部分搜索引擎的请求URL中包含可变参数,数据包长度增量会呈现表2中变化的特征。为此,在检测数据包序列的过程中,根据已接收数据包的状态序列和URL可变参数特征,将查询字符串长度增量动态转化为数据包长度增量。

表3 击键探测算法
4.2 歧义缩减
歧义缩减通过匹配符合击键数据包状态序列Q的候选查询,有效缩减搜索查询集的规模,降低用户输入的不确定性。通过歧义缩减,理论上可以获得图3(a)的信息增益,并达到图3(b)的识别准确率。
为提高候选查询的匹配效率,设计了如表4所示的多层匹配算法。其中,第1层为长度匹配,根据状态序列Q的长度即击键次数匹配查询的拼音字母长度;第2层为音节匹配,将状态序列Q约简为指示音节分隔符的状态序列Q¯={q¯1,q¯2,...,q¯n},q¯i ∈{A,B},匹配查询的拼音音节排列;第3层为增量匹配,针对HTTP/2网站,将状态序列Q与查询在不同初始比特余数r0下的哈夫曼编码长度增量序列进行匹配,进一步减小相同长度查询之间的歧义。算法层数越高,匹配过程的计算复杂度越大,随之带来的信息增益也越大。对于规模庞大的搜索查询集,该结构可以有效减少复杂的高层匹配次数,通过预先计算每个查询的状态序列Q¯′和Q′r,可以提高算法整体的性能。

表4 多层匹配算法
4.3 查询推断
查询推断利用数据包时间间隔可区分性建立循环神经网络(Recurrent Neural Network,RNN),学习用户击键的时间序列特征,从候选查询中预测概率最大的输入序列。相比Song等人[6]采用的隐马尔可夫模型,RNN具有更强的非线性表示能力,能够刻画击键序列的长时依赖关系。考虑到击键时间间隔不仅与当前bigram有关,还与前后bigram改变的手部位置相关,因此采用如图6所示的双向RNN(BRNN)网络[15],利用双向隐层节点的连接关系,学习击键时间间隔前后的依赖关系。
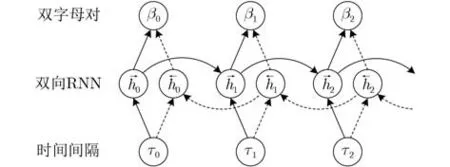
图6 击键时间间隔预测双字母对的BRNN模型
中文输入以拼音音节为单位进行记忆,且通过状态序列Q可以良好地划分音节,因此只针对音节内部的bigram序列建立预测模型。对于长度为n的拼音音节p,BRNN模型以n−1个击键时间间隔τ={τ1,τ2,...,τn−1}作为输入,通过双向tanh激活函数和softmax层输出n−1个bigram的概率,即

其中,U, W, V分别表示输入层、隐藏层和输出层参数,b,c分别表示各层的偏置值。
训练模型时,采用包含16.8万用户键盘记录的136 M击键数据集[12],从中筛选台式机或笔记本电脑QWERTY键盘记录作为训练数据。基于模型预测结果,通过bigram序列的联合概率确定音节p的概率,进而根据音节序列确定击键序列X的概率,即

5 实验评估
本节对所提出的侧信道分析方法进行实验评估。首先介绍流量数据的收集方法以及实验数据集的构造,然后通过一系列针对性的实验对侧信道分析方法性能进行全面评估。
5.1 数据收集
为收集真实的网络加密流量,构建了模拟用户在搜索引擎中输入中文查询并捕获网络流量的数据收集工具。该工具利用Selenium实现浏览器网页自动加载与搜索框定位,通过PyAutoGUI模拟用户点击搜索框并输入搜索查询,使用Scapy在后台捕获网络流量并保存为pcap文件。为模拟用户输入中文搜索查询的击键时间间隔,从136 M击键数据集中进一步筛选出1850个汉语母语用户的击键记录,通过最大似然估计得到P(τ|β)分布参数,并随机采样得到模拟的击键时间间隔。
为验证2.4节量化的理论识别性能,同样以THUOCL作为搜索查询集,从中随机选取拼音长度从10到40字符的查询各60个,组成包含1800个查询的样本空间。选取的查询中不包含字母、数字或特殊字符。使用数据收集工具分别在百度、搜狗、360和必应搜索中捕获查询样本的加密流量,组成包含7200个样本的流量数据集。数据收集环境基于Windows 10系统上运行的Chrome浏览器(v87版本),模拟用户输入时使用标准QWERTY键盘以及系统内置的微软拼音输入法。
5.2 实验设置
实验评估基于构造的中文查询流量数据集,其中每个样本代表攻击者通过网络监听捕获的搜索流量,并且用户输入的搜索查询属于攻击者已知的集合THUOCL。针对分析方法的各个阶段,采用不同的评估指标进行评价。击键探测属于二分类问题,即未知网络流量中的击键数据包能否被DFA模型正确地接收,因此使用F1分数作为评估指标,其中假阳类表示被标记的非击键数据包,假阴类表示未被标记的击键数据包。整体性能使用查询识别准确率作为评估指标,即攻击者一次猜对用户输入查询的数量与查询样本总数的比例。在整体评估的基础上,设计了多个攻击场景来评估不同信息来源对查询识别准确率的贡献度。此外,通过对推断查询阶段的消融实验,进一步验证推断模型的有效性。
5.3 结果分析
5.3.1 击键探测性能
表5显示了击键探测在不同搜索引擎中的F1分数及完整击键探测(F1=100%)比例。利用DFA模型严格的接收条件,攻击者可以准确地识别各个搜索引擎的击键数据包。在击键探测失败的样本中,百度搜索第3次击键请求的“H_PS_PSSID”和“BDSVRTM”Cookie的长度同时发生变化,导致DFA模型接收失败;360搜索的页面被重定向到so.com/haosou.html,该域名的搜索功能不是AJAX增量式搜索,因此没有击键数据包产生;搜狗搜索由于采用周期为100 ms的等待计时器模型,部分击键时间间隔较小的请求被合并;相比之下,必应搜索由于采用递归模型,发生请求合并的概率大幅降低,符合2.4节的理论分析。
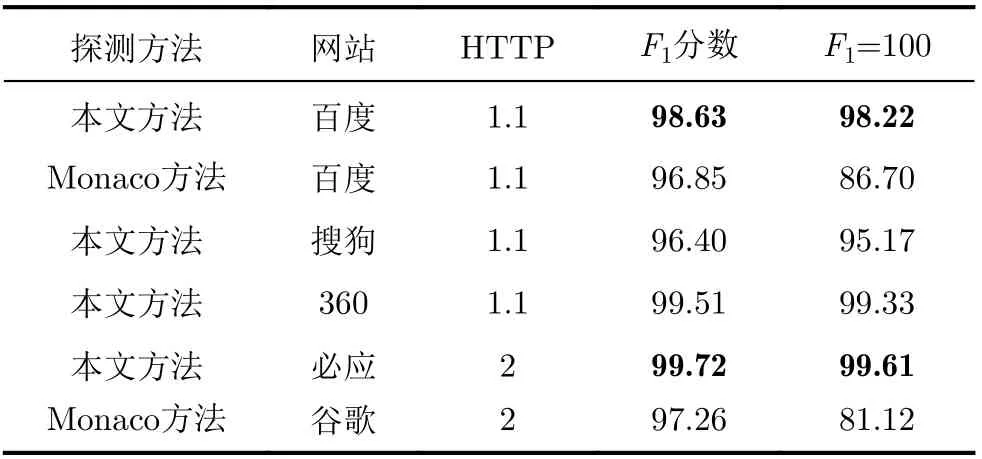
表5 击键探测性能结果(%)及对比
对比文献[10]中基于无状态DFA模型的两阶段探测方法,本文方法能够对HTTP请求中特殊的可变参数进行识别,同时利用DFA模型严格的接收条件避免错误地接收背景流量。从实验结果来看,本文方法对百度搜索的完整击键探测性能提升11.52%。
5.3.2 查询识别准确率
表6显示了不同搜索引擎中的查询识别准确率。对于非HTTP/2网站查询,分析方法的平均识别准确率为61.32%~65.94%;而对于必应搜索,由于哈夫曼编码URL泄露了音节内部的信息,平均识别准确率达到76.06%。图7(a)显示了各个搜索引擎中的查询识别准确率与拼音字母长度的关系,并与2.4节的量化值进行对比。可以看出,分析方法的实际性能与理论量化值基本吻合,对于长度在25个字符以上的查询能够准确地识别。搜狗搜索由于节流计时器合并了较多请求,部分结果未达到量化值。此外,请求URL中的“cp”,“pwd”等可变参数未对数据包长度增量可区分性造成影响。

图7 整体性能评估
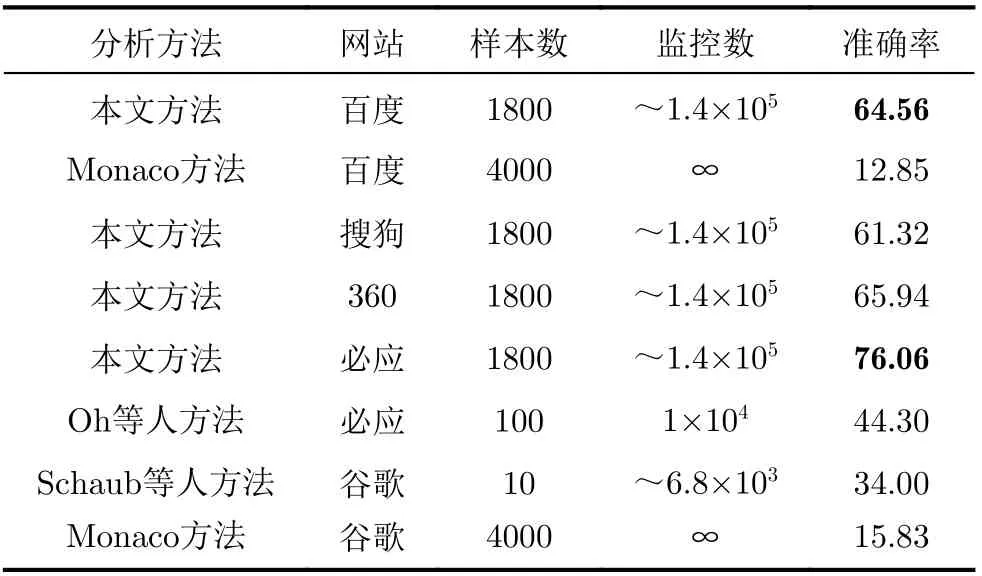
表6 查询识别准确率结果(%)及对比
将本文提出的分析方法与Schaub等人[8]的方法、Oh等人[9]的方法和Monaco[10]的方法结果进行对比,识别性能比现有方法均有大幅提高。其中,与Oh等人采用的指纹攻击方法相比,本文方法在更大规模的监控集上实现了更准确的识别,对于必应搜索查询的识别准确率提升31.77%。
5.3.3 信息泄露来源
为探究侧信道分析方法实际利用的信息泄露来源,分别评估4个场景下的识别性能:只采用音节匹配,只采用增量匹配,采用音节匹配和击键时间信息,以及采用增量匹配和击键时间信息。图7(b)显示了不同场景下针对必应搜索的查询识别准确率。对于长度为20个字符的查询,采用完整信息来源的识别准确率从只采用音节信息的36.67%提升到80%;不采用时间信息的识别准确率与理论量化值基本吻合,说明较好利用了数据包长度信息;时间信息带来的性能提升相对较小,原因一方面是BRNN模型训练没有采用特定用户击键数据集,导致样本偏差较大,另一方面是必应搜索的递归计时器模型损失了少量原始击键时间信息。
5.3.4 查询推断消融实验
为进一步分析本文方法对击键时间信息的依赖程度,以及验证查询推断阶段BRNN模型的有效性,分别使用单向RNN模型、隐马尔可夫模型(Hidden Markov Model, HMM)[6]、单隐层多层感知器(MultiLayer Perceptron, MLP)和基准的等概率模型(Equal)进行对比分析,结果如表7所示。其中,RNN接近BRNN的识别准确率,差别在于RNN只学习了之前的bigram对当前击键时间间隔的影响,忽略了后续bigram造成的影响;HMM和MLP相比RNN的总体效果更差,因为HMM基于齐次马尔可夫假设,即当前时间间隔只与前一个bigram相关,无法刻画用户击键的长时依赖关系,而MLP无法捕获时间顺序信息,忽略了bigram改变的手部位置对击键时间间隔的影响。

表7 查询推断消融实验(%)
6 可能的缓解机制
由于侧信道分析方法利用了搜索请求泄露的长度和时间信息,理论上通过混淆数据包长度和时间特征可以降低识别准确率。以具有完整信息来源的必应搜索作为对象,评估以下4种针对性的缓解机制。
(1)填充数据包:将数据包填充到固定长度或固定字节的整数倍可以消除长度带来的信息增益,但是会产生较多额外的带宽消耗。另一种随机填充可在带宽消耗较小的前提下,破坏数据包长度增量可区分性。随机填充1 Byte时,攻击者通过放宽DFA接收条件能够以一定的概率区分音节信息。图8(a)显示了填充概率对查询识别准确率的影响,以50%的概率填充数据包可以降低30.5%的识别准确率。
(2)伪造数据包:借鉴KeyDrown[16]伪造键盘事件和OB-PWS[17]伪造搜索请求的思想,由于哈夫曼编码URL长度会产生零字节增量,伪造相同长度的数据包会被DFA错误地接收。图8(a)显示了伪造数据包概率对查询识别准确率的影响,以较小带宽消耗的30%概率伪造数据包可以使识别准确率降低到7.8%。
(3)延迟数据包:网络延迟影响数据包的到达时间,过大的延迟抖动会使数据包乱序。攻击者利用TCP序号可以调整数据包逻辑乱序,但延迟抖动会消除击键时间泄露的信息。图8(b)显示了采用Laplace分布[18]增加的网络延迟抖动对查询识别准确率的影响,40 ms的延迟抖动可以使识别准确率降低15.7%。

图8 缓解机制评估
(4)合并数据包:由于节流计时器会将周期内的用户输入合并到同一个请求,增加节流周期可以增加合并数据包的概率,从而使击键探测过程失败。图8(b)显示了增加节流周期对查询识别准确率的影响,虽然降低了增量式搜索的实时响应速度,但是增加50 ms节流周期可以使识别准确率降低到17.6%。
7 结束语
本文提出了一种面向中文搜索的网络加密流量侧信道分析方法,通过被动监听网络流量,攻击者可以在用户无感的情况下推断其输入的搜索查询。本文以理论分析和实验评估相结合的方式证明了信息泄露普遍存在于具有增量式搜索的网络应用中,并针对性地提出了可能的缓解机制。在下一步工作中,将考虑非中文字符以及输入误差带来的影响,并针对特定用户建立击键时间模型以提高时间信息带来的增益。
猜你喜欢
北京航空航天大学学报(2022年5期)2022-06-06
当代陕西(2022年6期)2022-04-19
当代水产(2021年8期)2021-11-04
考试与评价·七年级版(2020年6期)2020-11-02
中学生数理化·中考版(2019年9期)2019-11-25
快乐作文(1.2年级)(2019年9期)2019-09-10
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
作文周刊·小学一年级版(2018年32期)2018-01-15
指挥与控制学报(2015年4期)2015-11-01
