
可重构结构下四叉树编码划分并行设计与实现
2022-06-02 06:57李远成
无线电工程 2022年6期
王 欣,蒋 林,曹 非,李远成
(1.西安科技大学 电气与控制工程学院,陕西 西安 710600;2.西安科技大学 计算机科学与技术学院,陕西 西安 710600)
0 引言
高效视频编码(High Efficiency Video Coding,HEVC)标准是新一代视频编码国际标准。与上一代标准H.264/AVC相比,在编码结构上放弃了宏块的概念[1],采用了对图像进行四叉树划分的方式。这种四叉树递归结构在将压缩效率提升了1倍的同时,也极大地增加了编码计算复杂度与编码时间[2]。因此,降低四叉树编码过程中的计算复杂度与减少编码时间是研究的问题之一[3]。
针对高效视频编码中编码复杂度高的问题,一些研究通过算法的简化,降低四叉树编码复杂度[4]。文献[5]针对快速编码单元(Coding Unit,CU)编码过程中四叉树遍历计算出现的冗余信息,提出了一种灵活的复杂度分配机制,该分配机制将CU深度决策问题转换为分类问题。但是,该方法存在计算量大和存储成本高的问题。从视频编码算法的角度考虑[6],优化后的算法计算量仍然巨大,单从算法层面去进行优化[7-8],仍然无法满足实时视频编码的需求。所以,在优化编码算法的同时,采用FPGA进行并行加速也是提升编码效率的一种更有效的方式。文献[9-11]在优化编码算法的同时进行了FPGA加速,缩短了编码时间,但也占用了较大的硬件资源和专用的DSP。文献[10]基于多核处理器实现了解码器,虽然有效利用了多核的并行性,但其使用了多达64个处理单元,硬件成本较高。
针对高效视频编码中编码复杂度高的问题,可以通过FPGA加速来提高编码效率。利用硬件加速器来实现视频编码加速,执行计算密集型算法,以满足视频应用的性能要求,是当前的研究热点。四叉树编码算法的数据以CU的形式参与运算,运算步骤相对独立,计算过程中数据依赖性低,具有较高的并行性,适合可重构阵列处理器进行并行运算。四叉树编码的过程中会将图像的数据最大划分为树形结构单元(Coding Tree Unit,CTU),且编码过程可以划分成不同的模块,不同的CTU间便可以采用流水线作业思想进行加速作业。
综上所述,基于可重构阵列处理器,提出了一种新的四叉树CU划分并行化设计方案,在不考虑功耗的情况下,重点研究设计方案在并行加速与硬件资源消耗等方面的性能,实现四叉树CU在可重构阵列上的高效灵活部署。
1 四叉树CU划分算法及并行性分析
1.1 四叉树CU划分算法
HEVC编码结构首先是将视频划分为图像组(Group of Picture,GOP),CTU是HEVC里的基本处理单元。在每个CTU内部按照四叉树的循环分层结构划分为不同的CU,CU是HEVC总体框架的基本单元。一幅图像划分为CTU以及一个CTU划分为CU的图像,划分结构示意图如图1所示。
CU的循环四叉树分层结构如图2所示。CU是否继续划分取决于分割标志位(Splitflag)。对于编码单元CUd,假设其大小为2N×2N,深度为d。若它对应的Splitflag值为0,则CUd不再进行划分;反之,CUd将会作为四叉树划分的根源被划分为4个独立的编码单元CUd+1,编码单元CUd+1的深度和大小变为d+1和N×N。HEVC标准中最大的编码单元(Largest Coding Unit,LCU)为64×64。
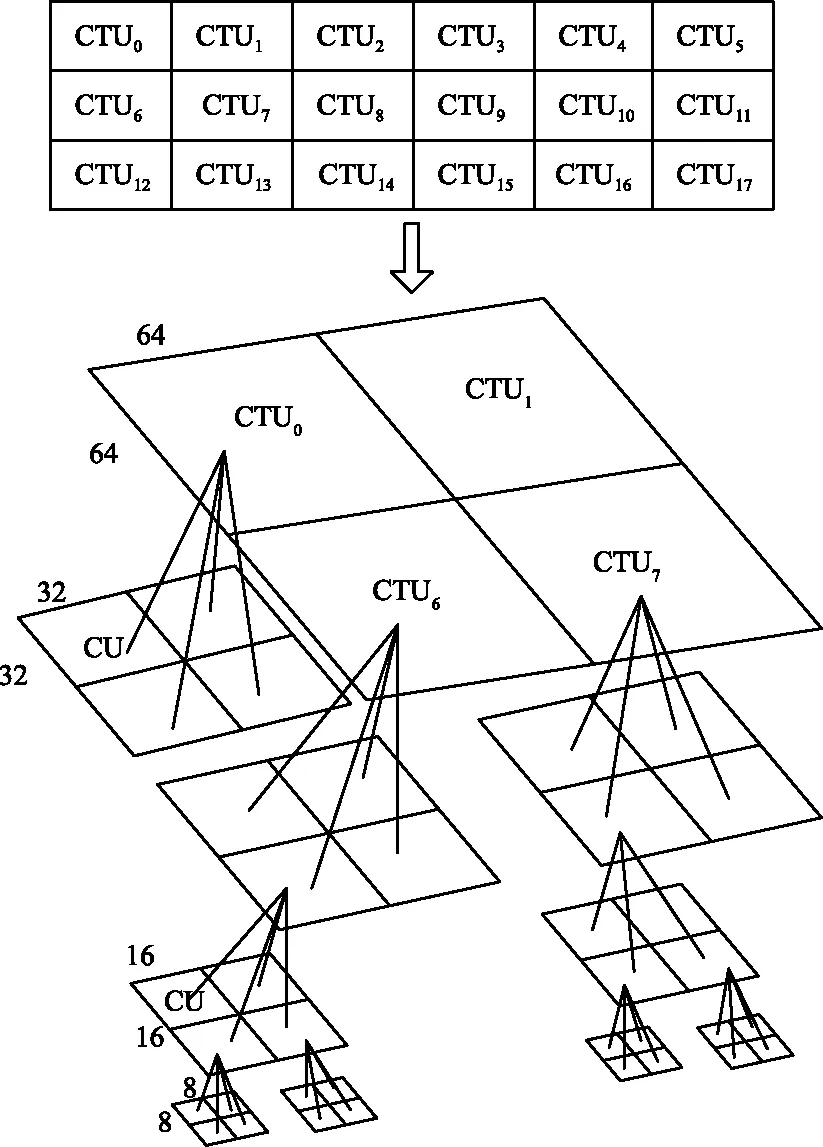
图1 图像划分结构示意Fig.1 Schematic diagram of image division structure
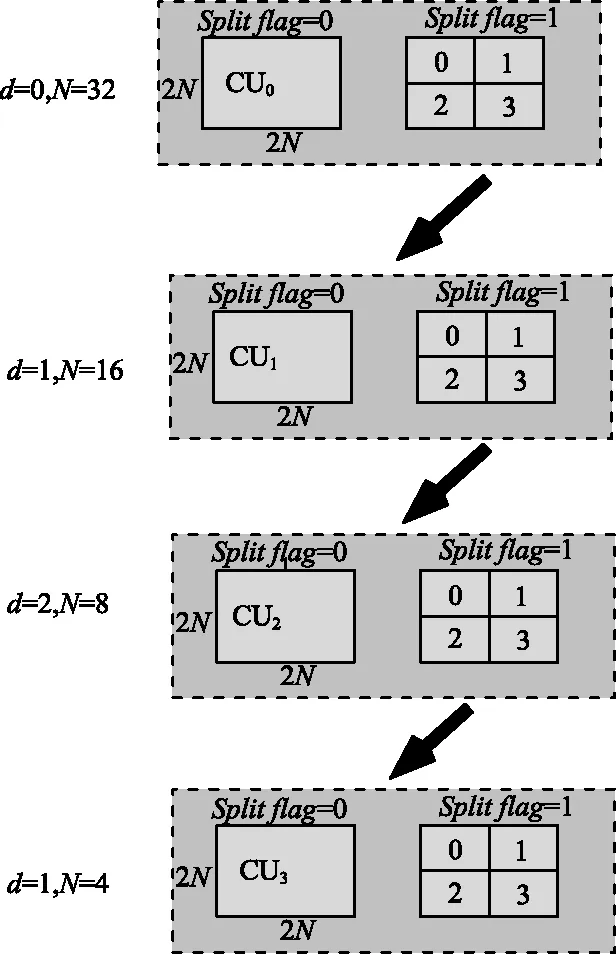
图2 CU的循环四叉树分层结构Fig.2 Cyclic quadtree hierarchical structure of coding unit
在HEVC测试模型参考软件中会有很多种可能的分割方法,通过寻找率失真(Rate Distortion,RD)最小的方法作为最佳分割[12]。率失真的计算公式如下:
J=SATD(S,P)+λmodeRmode,
(1)
式中,SATD(S,P)为经过帧内预测后得到的残差块的SATD;λmode为拉格朗日因子;Rmode为编码当前模式所需要的比特数。SATD是指将残差信号进行哈达玛变换后再求元素绝对值之和。
算法对每个CU均进行率失真的计算,计算方法如下:
JCUi=JCU0+JCU1+JCU2+JCU3,
(2)
式中,JCUi(i=0,1,2,3)表示当前CU的率失真;JCU0,JCU1,JCU2,JCU3表示分割后4个更小的CU的率失真。
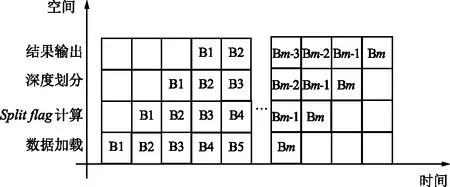
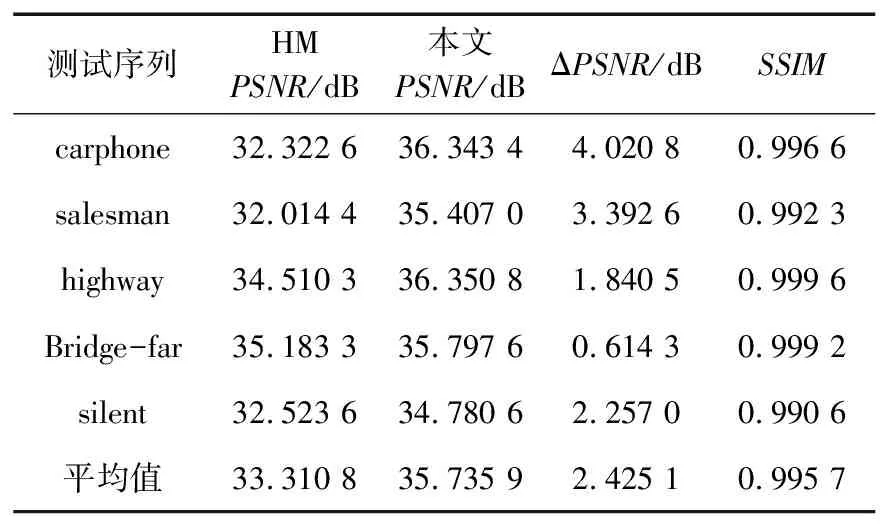
通过递归的方式获取所有的CU的率失真,对每一深度进行分割后CU与分割前CU的率失真比较,选取率失真小的作为最优CU分割方法。若J分割前>J分割后,此时Splitflag值为1,CUd将会作为四叉树划分的根源被划分为4个独立的编码单元CUd+1。若J分割前 HEVC这种灵活的单元表示方法可以使得在平缓区域编码效率大大提高的同时提供数据并行处理的结构单元。 考虑到HEVC标准的特点,在四叉树编码划分的过程中信息划分为相互独立的部分,每一部分交给不同的处理单元PE来处理。结合分布式共享存储结构,从数据级并行的角度进行算法加速。数据并行实现示意图如图3所示。 图3 并行实现示意Fig.3 Schematic diagram of data parallel implementation 在CTU进行四叉树编码划分的内部,由于每个CTU的数据之间要进行比较判别运算,相邻数据之间存在依赖关系,因此,可将CTU划分成不同的块,多块CTU被分别送到不同的PE处理单元中并行进行判别运算处理,当每个PE处理结果出现判别结束的标志时,将这个PE的输出结果基于CTU到CU间的循环嵌套分层结构再进行下一层次的判别运算。若所有进行多块CTU的PE划分到最后,则将多块CTU的数据再整合进行判别,最终得到编码划分结果。在整个HEVC编码过程中,可以分为不同的模块,主要进行数据加载、率失真的计算与比较、不同深度的数据划分和编码划分结果的输出,各个功能的模块组成串行的四级流水,而分别在各个模块的内部,针对不同的子数据进行数据并行。这样,在四叉树CU的划分过程中基于可重构阵列处理器混合功能并行和数据并行2种并行方式对编码过程进行加速。 可重构阵列处理器(基于FPGA实现的BEE4平台),能够满足四叉树CU划分的并行化设计需求[13]。可重构阵列处理器由主控器和可重构处理单元阵列组成。可重构阵列处理器的部分硬件结构如图4所示,主要包括数据输入存储、阵列处理器、全局控制器、指令存储器和数据输出存储器5部分。 图4 可重构阵列处理器部分硬件结构Fig.4 Part of the hardware structure of the reconfigurable array processor 可重构阵列处理器结构中每16个处理单元(Process Element,PE)组成一个簇(Processing Element Group,PEG),采用4×4的矩阵结构。采用分布式共享存储结构,这种结构是一种最直接且并行度很高的高速交换单元结构。在逻辑上整个片上存储采用统一的编址方式,在物理上分布于各个PE,实现了存储的并行访问。具有“逻辑共享、物理分布”特性的分布式存储结构,所表现出的并行化设计优势,适合四叉树编码划分算法这种数据密集型算法。 基于可重构阵列处理器硬件结构以及1.2节中四叉树编码划分的并行性分析,从功能并行和数据并行2种并行方式对编码过程进行加速及映射实现。 2.2.1 基于分布式存储的并行映射实现——数据并行 四叉树编码划分的16个PE并行映射图如图5所示。 步骤1:将要划分的原始图像帧数据存储在数据输入存储DIM中。PE00与DIM相连,将外部存储中原始的一帧图像分为64 pixel×64 pixel的CTU数据通过PE进行数据下发,分别下发给00~33号这16个PE。 步骤2:每个PE并行对其数据进行判别运算,若PE中的数据判别结果Splitflag值为1,直接将PE的RAM中的16×16的CU块数据分割成8×8的CU,此时输出depth为3;若每个PE中判别结果Splitflag值为0,若PE00,PE01,PE10,PE11内数据判别Splitflag值均为0,则判别这4个PE的Splitflag值;若Splitflag值为1,此时输出depth为2;与此同时,PE02,PE03,PE12,PE13;PE20,PE21,PE30,PE31;PE02,PE03,PE12,PE13均并行采取相同的操作。 步骤3:若PE00,PE01,PE10,PE11的输出结果Splitflag值为0,且PE02,PE03,PE12,PE13的输出结果Splitflag值为0;PE20,PE21,PE30,PE31的输出结果Splitflag值为0;PE02,PE03,PE12,PE13的输出结果Splitflag值为0,则判别这4部分的输出的Splitflag值,若Splitflag值为1,则输出depth为1;否则,输出depth为0。 图5 基于可重构阵列处理器的四叉树编码划分映射Fig.5 Quadtree coding division mapping based on reconfigurable array processor 2.2.2 基于流水线加速并行——功能并行 在采用16个PE进行四叉树编码的过程中,可以将划分过程分为数据加载、率失真的计算与比较、不同深度的数据划分以及编码划分结果的输出等不同的模块。有的PE在算法的执行过程中会处于空闲状态,为了最大化地减少编码时间,使用如图6所示的流水线方式实现CTU间并行加速,其中B1~Bm是指在四叉树划分过程中不同深度模块的操作。 图6中,将图像的像素块通过原始数据加载、Splitflag值计算、深度划分和结果输出这4个部分进行四叉树编码划分。当第一个CTU数据加载完成后,第二个CTU开始原始数据加载。因此,采用此流水线方式能够缩短编码划分的执行时间。采用16个PE进行四叉树编码划分的方案采用流水线方式加速的设计方法,算法如下所示: if addparallel(“Quadtree”,1)finish∥激活四叉树编码划分操作 The core 1exec Quadtree(image_orgin,image_code); endif addparallel(input,the_core)={ i=get_input_core_ID(input); if the coreiisfreedom∥确定处理单元是否空闲 return finish; else continue to wait;∥同步 endif} 其中,addparallel(“Quadtree”1)询问处理单元是否处于freedom状态,对于繁忙状态则需要等待,进行线程同步;反之,直接进行运算处理。 图6 四叉树编码划分时空间流水线作业图Fig.6 Spatial pipeline operation diagram of quadtree coding division 在编译方式上,与通用编译为单一目标处理器的汇编指令不同,可重构编译通过软硬件划分,将划分结果分别生成主控制器的控制码以及配置阵列处理器上的配置信息。可重构阵列处理器的执行方式是通过主处理器将任务下发给可重构阵列处理器执行,采用主控制器选择片上配置存储器中的信息,将信息下发给处理簇PEG执行,每个簇再通过片上配置存储器将存储的可重构配置信息分配到PE中进行运算。 重构配置信息执行示意图如图7所示。首先,通过分析四叉树CU的划分算法与可重构阵列结构的关系得到四叉树CU算法的配置信息。然后,将配置信息载入到片上配置存储器,在可重构计算阵列执行时,载入PEG。最后,在并行执行的过程中,PEG00载入四叉树编码划分配置信息后重复执行N次四叉树编码划分,最后得到四叉树编码划分的结果。 图7 可重构配置信息执行示意Fig.7 Schematic diagram of reconfigurable configuration information execution 为了验证四叉树编码并行化实现方案的可行性,在基于BEECube公司BEE4开发平台搭建的可重构阵列处理器原型系统上进行验证和测试[14]。首先,将算法代码编译为可重构阵列处理器汇编指令代码;接着,用指令翻译器将汇编代码指令翻译成二进制代码;然后,使用Questasim10.1d进行功能仿真验证,通过Xilinx公司的ISE14.7开发环境对设计进行综合,并分析其性能;最后,在参考软件HM中测试编码性能,并将本文提出的四叉树编码划分并行化方案在可重构阵列处理器测试平台中进行FPGA硬件测试。 3.2.1 运行时间分析 实验通过串行和并行2种实现方案对算法并行模块运行时间做对比分析。算法的运行时间通过Qusetasim进行功能仿真得到。在depth_balloons测试序列中找到4种具有代表性的CTU划分模型,如图8所示。测试模型a不进行划分,最大深度为0;测试模型b是一个深度为1的根节点划分为最大深度3;测试模型c是一个深度为2的根节点划分为最大深度3;测试模型d是全划分为最大深度3。 在算法执行过程中,记录4种测试模型从开始到结束的时间来计算运行时间。4种测试序列在不同实现方案下的运行时间对比如表1所示。 (a) 测试模型a (b) 测试模型b (c) 测试模型c (d) 测试模型d 表1 不同测试模型下不同方案运行时间对比 由表1可以看出,用于测试的4种测试模型a~d的数据量是逐步增加的,测试模型a~d体现并行性的程度是逐渐提高的。与单个PE串行相比,并行方案在4种测试模型下的平均加速比达到了9.64,在可重构阵列处理器上PE资源的使用比例,即在一个簇内的PE资源利用率提高了93.75%。 由统计的运行时间可以看出,并行加速比都随着测试模型数据并行性的增加而增加。本文基于可重构阵列处理器所设计的并行方案在不同的测试模型中均可提高数据的并行性,减少编码时间,特别是在数据量越大、数据划分越复杂的情况下。因而针对四叉树编码这种数据密集型算法,并行方案能够有效减少算法的运行时间。 文献[15]提出了一种基于四叉树模型的快速帧间编码算法,同时考虑CU深度级别的边缘信息,提出了一种快速CU划分方案。根据提出的四叉树模型和CU大小的相关性尽早确定可能的深度范围,加快编码过程。其实验平台为Inter© CoreTMi5 CPU,16 GB内存。本文基于可重构阵列处理器的结构特点进行算法的并行实现,减少编码时间。采用本文所提出的并行化方案对PartScence,Basketballdrive,BQTerrace和Cactus测试序列进行编码划分,编码时间对比如图9所示。与文献[15]相比,本文对测试序列Cactus进行四叉树划分的编码时间减少最多,相比文献[15]编码时间总体提升约36倍。 图9 编码时间对比Fig.9 Coding time comparison chart 3.2.2 编码性能对比分析 本文与3D-HEVC参考软件(HM)中几种测试序列在编码过程中CU划分结果分析统计并进行了对比,结果如图10和11所示。 图10 HM划分结果Fig.10 HM division result 图11 本文划分结果Fig.11 Division results of test 从图10和11中的数据对比可以得出,本文与HM测试模型相比编码划分结果的精准率为86%。 使用本文的方法作为编码划分的方法,选取了5组测试序列在BeeCube公司的BEE4搭建的可重构阵列处理器测试平台中进行验证测试。采用的峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似性(Structural Similariy Index Measurement,SSIM)是2种常用的图像质量评价指标,对完整Ι帧的测试结果图像进行分析,如表2所示,相比HM测试一个完整Ι帧的结果,平均PSNR值增加了2.425 1 dB,平均SSIM值为0.995 7。 表2 测试性能分析 3.2.3 硬件资源对比分析 为了更好地说明本文设计方案的优势,将算法对应的硬件设计综合情况与其他同类型文献进行对比。实验数据如表3所示,文献[16]在Xilinx Virtex 6的开发平台上设计基于HEVC的视频编码算法,硬件设计上采用全流水线方式工作,最大只能支持5条路径并行,本文中支持最大16个PE并行。与本文相比,文献[16]的LUT的资源与寄存器的资源消耗增加了很多;在实现了更高的并行度的情况下,本文方案硬件消耗相对较少,ISE硬件综合资源消耗图如图12所示,LUT资源仅使用了31 730个,REG资源仅使用了9 664个。 图12 硬件资源消耗Fig.12 Hardware resource consumption 文献[17]在Xilinx Zynq ZC706上实现,编码器以140 MHz的工作频率实现编码,工作频率略高于本文。本文和文献[17]在功能上都可以支持任意大小块划分。但相比于文献[16],本文的硬件消耗(LUT资源+REG资源)减少62%,且没有使用乘法器进行运算,使用加法器和移位操作代替乘法器进行运算,计算速度更快,无需使用DSP资源。 文献[18]基于Virtex 7现场可编程门阵列设计硬件的混合并行和数据流级架构的HEVC编码。在功能上可以支持任意大小块划分。相比于文献[18],在工作频率略高的情况下本文的硬件消耗也明显减少。LUT资源仅占其使用量的28%,REG资源仅占其使用量的80%。 综上所述,本文基于可重构阵列处理器的设计方案在较低的硬件消耗下实现了四叉树编码的并行化设计,并行加速比达到9.64,且在结构上具备灵活性。 表3 硬件结果对比 针对3D-HEVC标准中四叉树编码划分存在的编码复杂度高、数据量大、编码时间长和资源消耗大的问题,基于可重构阵列处理器提出了一种新的四叉树CU并行划分方案,完成并行映射、功能仿真以及FPGA测试。该方案利用可重构阵列结构分布式共享存储的特点,充分挖掘数据之间的并行性,实现计算资源PE的最大化利用,减少编码划分的时间。实验结果表明,四叉树CU划分在更具备灵活性的同时,与单个处理单元PE串行相比,16个PE并行设计的加速比达到9.64,很大程度上减少了编码时间。相比于文献[12]编码效率总体提升了约36倍。簇内PE的资源利用率提高了93.75%。与文献[14]相比,在不使用DSP资源的情况下资源消耗降低了62%。与文献[15]专用硬件对比,LUT资源消耗减少了78%,REG资源消耗减少了20%。总之,基于可重构阵列处理器的四叉树编码并行划分方案,在不影响编码质量的同时,提升了编码效率,且硬件资源消耗也相对较少。1.2 四叉树编码划分的并行性分析

2 基于可重构阵列处理器的四叉树编码划分并行实现
2.1 可重构阵列处理器硬件结构

2.2 四叉树编码划分并行实现

2.3 重构信息配置

3 实验及结果分析
3.1 实验平台环境
3.2 实验结果









4 结束语
猜你喜欢
当代陕西(2022年4期)2022-04-19
摄影世界(2022年1期)2022-01-21
小学生学习指导(中年级)(2021年12期)2021-12-30
北京航空航天大学学报(2021年9期)2021-11-02
家庭影院技术(2021年6期)2021-07-28
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
天津诗人(2017年2期)2017-11-29
微型计算机(2009年17期)2009-05-19
