
基于最小边际损失的人脸识别方法的研究*
2022-06-02 14:41阴法明仇剑鹏
电子器件 2022年1期
阴法明 ,仇剑鹏
(1.南京信息职业技术学院智能交通学院,江苏 南京 210023;2.东南大学信息科学工程学院,江苏 南京 210096)
由于深度神经网络(deep neural network,DNN)的快速发展,在过去的十年中,基于DNN 的任务在计算机视觉领域中取得了很大进展,包括人脸识别[1],物体检测[2],动作识别[3]。因为有更好的损失函数和更好的数据集,人脸识别取得了更为显著的进步。面部数据集的数量和质量对DNN 模型性能是会产生重要影响的。人脸数据库有很多,例如,MS-Celeb-1M[4],VGGFace2[5],MegaFace[6]和CASIA WebFace[7]。其中,MS-Celb-1M 和MegaFace 都存在长尾分布[8]问题,这意味着有少部分人有大量图像,还有大部分人的图像数量十分有限。使用具有长尾分布的数据集,训练好的模型容易在数据量大的样本上过拟合,从而降低了长尾部分的泛化能力。具体来说,拥有丰富样本的类往往和类中心有较大差距;与之相反的是,有限样本的类在类中心之间具有相对较小的余量,因为它们仅占据空间中的小区域,所以易于压缩。边际差异问题是由于长尾分布导致的,也导致人脸识别算法性能下降。
除了训练集和数据分布外,影响识别性能的另一个重要因素就是损失函数,该函数指导网络在训练过程中优化其权重。目前性能最佳的损失函数可以大致分为两种类型:基于欧氏距离的损失函数和基于余弦距离的损失函数。其中大多数是通过添加惩罚或直接修改Softmax 而从Softmax Loss 中获得的。
基于欧氏距离的损失函数包括对比损失[9],三重损失[10],中心损失[11],范围损失[9]和边际损失[12]。这些功能通过最大化类间距离或最小化类内距离来提高特征的辨别能力。对比损失要求网络采用两种类型的样本对作为输入,正样本对(来自同一类的两个人脸图像)和负样本对(来自不同类的两个人脸图像)。对比损失最小化正样本对的欧氏距离,同时惩罚距离小于阈值的负样本对。三重损失(Triplet Loss)使用三元组作为输入,包括正样本,负样本和锚点。锚点也是正样本,其最初接近某些负性样本而不是某些正性样本。在训练期间,锚-正对被拉在一起,而锚-负对被尽可能地推开。然而,对于对比损失和三重损失来说,样本对和三元组的选择都是非常耗时的。中心损失,边际损失和范围损失增加了另一个判罚规则,以实施与Softmax Loss 的联合监督。具体而言,中心损失通过计算和限制类内样本与相应类中心之间的距离来对Softmax 增加一个判罚。边际损失考虑批次中的所有样本对,并让来自不同类别的样本对的距离大于阈值,同时使来自相同类别的样本的距离小于阈值。然而,使一类中两个最远的样本的距离小于来自不同类别的两个最近样本的距离的规则,是过于严格的,这使得训练过程难以收敛。范围损失计算每个类中样本的距离,并选择具有最大距离的两个样本对作为类内约束;同时,范围损失计算每对类中心(也称为中心对)的距离,并使具有最小距离的中心对获得比指定阈值更大的余量。然而,每次仅考虑一个中心对并不全面,因为更多的中心对可能具有小于指定阈值的距离,因此由于学习速度慢,训练过程难以完全收敛。
基于余弦距离的损失函数包括L2-Softmax Loss[13],L-Softmax Loss[14],A-Softmax Loss[15],AMSoftmax Loss[16]和ArcFace[17]。基于Softmax Loss,L2-Softmax Loss 将特征描述符的L2 范数限制为恒定值。L2-Softmax Loss 带来更好的几何解释,同时关注质量好的和坏的人脸数据。L-Softmax 将Softmax 层的输出从W·f重新计算为|W|·|f|·cosθ,将欧氏距离转换为余弦距离,并将乘法角度约束加到cosθ,以扩大不同身份之间的角度差值。基于L-Softmax Loss,A-Softmax 应用权重归一化,因此W·f被进一步重新表示为|f|·cosθ简化了训练目标。然而,在使用相同的乘法角度约束之后,L-Softmax 和A-Softmax Loss 都难以收敛。因此,这两种方法采用退火优化策略来帮助算法收敛。为了提高A-Softmax 的收敛性,Wang[16]提出了AM-Softmax,它用加性角约束代替乘法角约束,即将cos(mθ)变换为cos(θ-m)。此外,AM-Softmax 还应用了特征归一化,并引入了全局缩放因子s=30,这使得|W|·|F|=s。因此,训练目标|W|·|f|·cosθ再次简化为s·cosθ。ArcFace 也使用附加角度约束,但它将cos(mθ)改变为cos(θ+m),这使得它具有更好的几何解释。AM-Softmax 和ArcFace 都采用权重归一化和特征归一化,将所有特征限制在超球面上。但是,它们似乎过于要求所有功能都位于超球面而不是更宽的空间,权重规范化和特征规范化能否使培训程序受益? 这个问题难以明确回答,有些证据表明软特征归一化可能会带来更好的结果[18]。
现有损失函数不考虑保证边际偏差问题。为了纠正这种边际偏差,本文建议为所有类别设置最小边际,然后根据最小边际设计损失函数。根据Softmax 损失,中心损失和边际损失的原理,本文中提出了一种新的损失函数,最小边际损失(Minimum Edge Loss,MEL),旨在强制所有类中心对的距离大于指定的最小边际。与范围损失不同,MEL 惩罚所有不合格的类中心对,而不是仅惩罚具有最小距离的中心对。MEL 重新使用Center Loss 不断更新的中心位置,并通过Softmax Loss 和Center Loss 的联合监督指导训练过程。据我们所知,没有损失函数考虑设定类中心之间的最小差值。用这样的约束来纠正由训练数据中的类不平衡引入的边缘偏差是有必要的。为了证明所提方法的有效性,对LFW[19]和YTF[20]数据集进行了实验。结果表明,MEL 取得了比Softmax Loss,Center Loss,Range Loss 和Marginal Loss 更好的性能,计算成本没有增加。
1 从Softmax 损失到MEL 损失
1.1 Softmax 损失和中心损失
Softmax Loss 是最常用的损失函数,如式(1)所示:
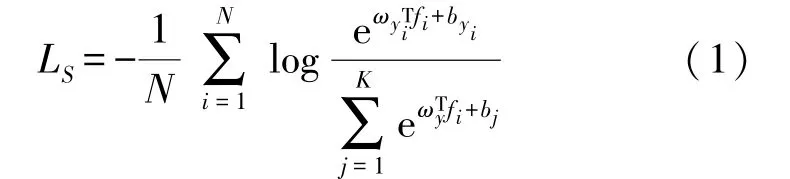
式中:N是批量大小,K是批次的类号,fi∈Rd表示属于第yi类的第i个样本的特征,ωj∈Rd表示最终完全连接层中权重矩阵ω∈Rd×n的第j列,bj是第j类的偏置项。从式(1)可以看出,Softmax Loss 旨在最小化预测标签和真实标签之间的差异,意味着Softmax Loss的目标只是区分训练集中不同的类的特征,并不是学习辨别特征。这样的目标适用于近似任务,例如对象识别和行为识别的大多数应用场景。但是在大多数情况下,人脸识别的应用场景是开放式任务,因此特征的判别能力对人脸识别系统的性能有很大影响。为了提高特征的辨识能力,Wen 等人[11]提出中心损失,以尽量减少类内距离,如下所示:

式中:cyi表示第i类的类中心。中心损失计算类中心和类内样本之间的所有距离,并与Softmax Loss一起使用:
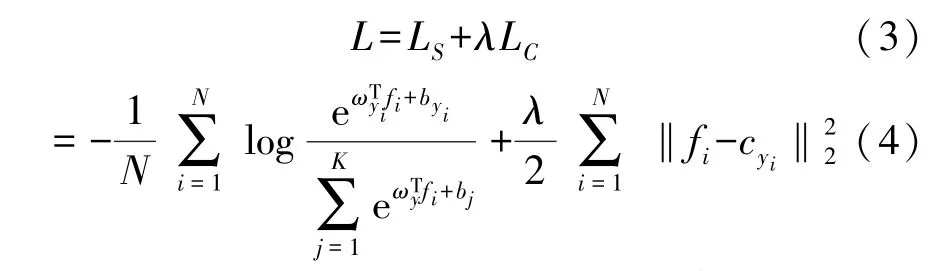
式中:λ是用于平衡两个损失函数的超参数。
1.2 边际损失和范围损失
将Softmax Loss 与Center Loss 相结合后,内部紧凑性得到显着提升。但仅仅使用Softmax Loss 作为类间约束是不够的,因为它只会鼓励特征的可分离性。所以邓等人[12]提出了边际损失,它也采用Softmax Loss 的联合监督:
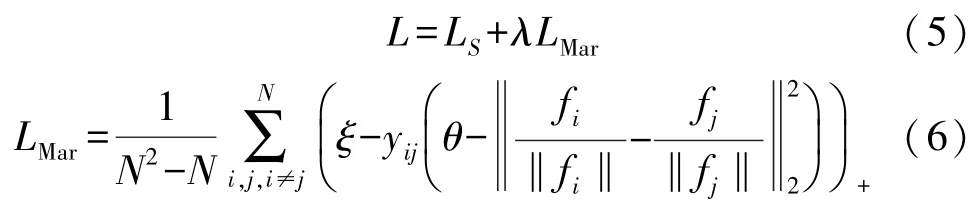
式中:LMar代表边界损失,fi和fj分别是批次中第i和第j个样本的特征;yij∈{±1}表示fi和fj是否属于同一类,θ是分离正对和负对的阈值,ξ是除了分类超平面的误差范围。边际损失考虑批次中样本对的所有可能组合,并指定阈值θ以约束所有这些样本对,包括正对和负对。边际损失迫使正对的距离接近阈值θ,同时迫使负对的距离远超过阈值θ。但是利用相同的阈值θ来约束正负对是不合适的。因为通常情况是类中两个最远的样本的距离大于两个不同但最接近的类的两个最接近的样本。强行改变这种情况将使训练程序难以收敛。
与上述方法类似,Zhang 等人提出的范围损失[8]也适用于Softmax Loss 作为监控信号:

与边际损失不同,范围损失由两个独立的损失组成,即LRintra和LRinter分别用于计算类内损失和类间损失(见方程(8))。

式中:K是当前批次中的类号,Dij是第i类中样本对的第j个最大距离,Dcentre是当前批次中两个最近类别的中心距离,和表示具有最短中心距离的χQ和χR的类中心,M是边际阈值。测量一个类中的所有样本对,并选择具有大距离的n个样本对来构建用于控制类内紧凑性的损失。如文献[12]中所述,实验表明n=2 是最佳选择。旨在强制具有最小距离的类中心对具有大于指定阈值的更大余量。但是有更多的中心对可能具有小于指定阈值的距离。由于学习速度慢,每次仅考虑一个中心对,导致训练过程需要很长时间才能完全收敛,因此不够全面。
1.3 最小边际损失
根据Softmax Loss 和Center Loss,我们在本文中提出了最小边际损失(MEL)。MEL 与Softmax Loss和Center Loss 结合使用,Center Loss 用于增强类内紧凑性,Softmax 和MEL 用于改善类间可分离性。Softmax 负责保证分类的正确性,而MEL 旨在优化类间距离。总损失如下所示:
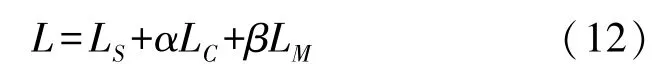
式中:α和β是用于调整Center Loss 和MEL 影响的超参数。
MEL 指定一个最小边缘的阈值。通过重用由Center Loss 更新的类中心位置,MEL 根据指定的最小边缘过滤所有类中心对。对于距离小于阈值的那些对,将相应的罚分加到损失值中。MEL 的细节表述如下:
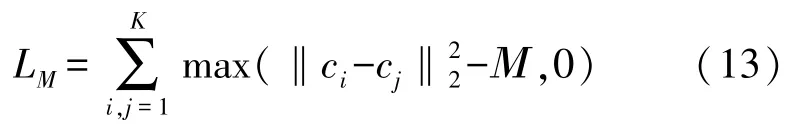
式中:K是批次的类号,ci和cj分别表示第i和第j类的类中心,M表示指定的最小边界。在每个训练批次中,中心损失使用以下两个等式更新类中心:

式中:γ是类中心的学习率,t是迭代次数,δ(条件)是条件函数。如果满足条件,则δ(条件)=1,否则δ(条件)=0。在Range Loss 中,类的中心是通过批量平均此类的样本来计算的。但是,批次的大小是有限的,并且某一类的样本数量更受限制。因此,与真实类中心相比,以这种方式生成的类中心并不精确。与Range Loss 相比,MEL 的学习中心更接近真实的中心。
1.4 讨论
1.4.1 MEL 是否可以真正扩大小于指定最小边距的最近班级中心对的距离
为了验证这一点,我们使用方案Ⅰ(Softmax Loss+中心损失)和方案Ⅱ(Softmax Loss +Center Loss +MEL)训练的深度模型从MS-Celeb-1M 数据集中提取所有图像的特征。2.1 节中介绍了处理数据集的详细信息和这两个模型的训练过程。方案Ⅰ和方案Ⅱ之间的区别在于方案Ⅱ使用MEL 作为监督信号的一部分,但方案Ⅰ没有。通过提取的特征,我们计算每个类的中心位置,然后计算每个类中心与其对应的最近邻居类中心之间的距离。这些类中心距离的分布如图1 所示。图1(a)和(b)分别显示了方案Ⅰ和方案Ⅱ的距离分布。图1(c)对方案Ⅰ和方案Ⅱ进行了比较,从中可以看出,方案Ⅱ在前五个区间具有较小的值,而在其余的区间具有较大的值。这表明MEL 扩大了一些相邻中心对的距离,因此增加了具有大余量的中心对的数量。

图1 每个类中心与其对应的最接近分类之间的距离分布
1.4.2 MEL 是否可以真正改善人脸识别模型的性能
为了回答这个问题,本文对不同的基准数据集进行了大量实验。实验类型包括面部验证,面部识别,基于图像的识别和基于视频的识别。结果表明,该方法可以胜过基本方法以及一些最先进的方法。
2 实验
2.1 实验细节
(1)训练数据
在所有实验中,本文使用MS-Celeb-1M 数据集作为我们的训练数据。
(2)数据预处理
用MTCNN[21]对所有图像进行面部对齐和面部检测。如果在训练图像上面部检测失败,图片将被丢弃不参与训练;所有训练和测试图像都被裁剪为160 pixel×160 pixel RGB 图像。为了增加训练数据,我们还对训练图像执行随机水平翻转。为了提高识别精度,本文将原始测试图像的特征与其水平翻转对应物的特征相结合。请注意,本文没有对实验中涉及的其他测试集进行数据清理。
(3)神经网络设置
基于Inception-ResNet-v1[22],我们根据五种监督方案实施了Tensorflow[23]的五种模型:Softmax Loss,Softmax Loss+Center Loss,Softmax Loss+MEL,Softmax Loss+Range Loss 和Softmax Loss+Center Loss+MEL。为方便起见,本文分别在实验结果中使用“Softmax Loss”,“Center Loss”,“Marginal Loss”,“Range Loss”和“MEL”来表示这五种方案。本文在一个GPU(GTX 1070)上训练这五个模型,我们设置90 作为批量大小,512 作为嵌入大小,5×10-4作为权重衰减,0.4作为完全连接层的保持概率。迭代总数为275 K。学习率以0.05 开始,每100 K 次迭代除以10。所有方案都使用相同的参数设置,除了Softmax Loss+Center Loss+MEL 在训练开始之前加载经过训练的Softmax Loss+Center Loss 模型作为预训练模型,这样可以使前者获得更好的识别性能。
(4)测试设置
在测试过程中,本文会尽力找到能够带来最高性能的参数设置。式(12)中的α和β分别设定为5×10-5和5×10-8。MEL 的最小边距设置为280。每个图像的深度特征是从全连接层的输出获得的,并且连接原始测试图像的特征和其水平翻转的对应物,因此产生的特征每幅图像的尺寸为2 pixel×512 pixel。最终验证结果是通过将阈值与两个特征的欧氏距离进行比较来实现的。
2.2 参数β 和M
β是用于调整MEL 在组合中的影响的超参数。M是指定的最小边际。这两个参数影响本文所提出方法的性能。因此,如何设置这两个参数是一个值得研究的问题。
总损失仅反映模型在训练集上的表现。我们对MS-Celeb-1M 数据集进行了两次实验,并评估了这两个参数对总损失的影响。在第一个实验中,我们将β修正为5×10-8,并观察M对总损失的影响,如图2(a)所示。在第二个实验中,我们将M固定为280,并评估β和总损失之间的关系,如图2(b)所示。从图2(a)可以看出,将M设置为0,即不使用MEL,是不合适的,因为它会导致高的总损失。当M为280 时,出现最低的总损失。从图2(b)中,我们可以观察到总损失在β的宽范围内保持稳定,但在β是5×10-8时达到最低值。因此,在随后的实验中,我们分别将M和β固定为280 和5×10-8。
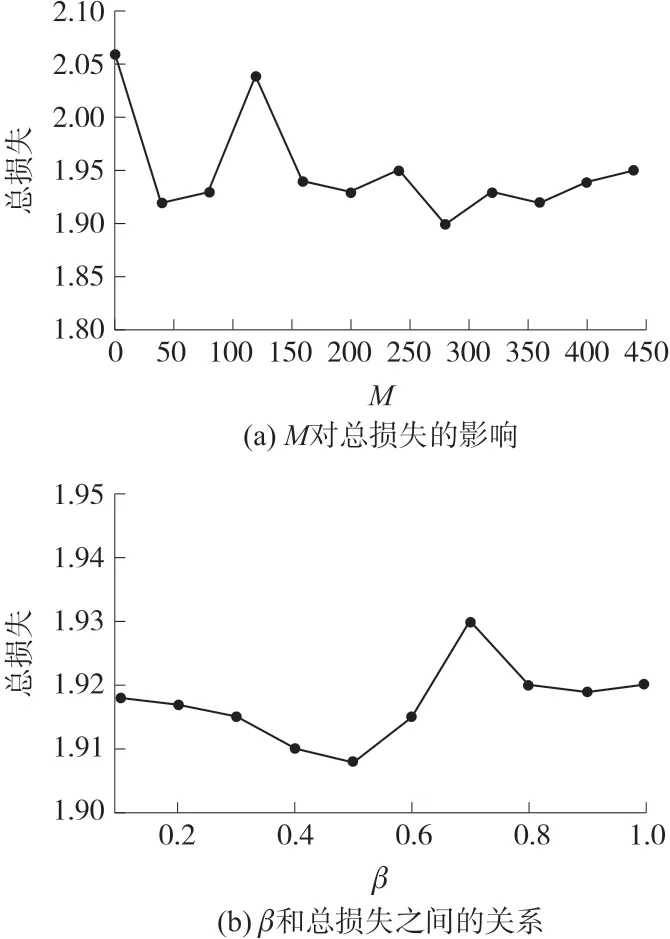
图2 MS-Celeb-1M 数据集在两组模型上的人脸验证准确性
2.3 LFW 数据集与YTF 数据集上最新方法进行比较
在本节中,参照2.1 节中的方法,对LFW 和YFW数据进行预处理。LFW 数据集是从网上收集的,其中包含13 233 张面部图像,面部姿势和表情有很大差异。这些面部图像来自5 749 个不同的身份,其中4 069 个具有一个图像,而剩余的1 680 个身份具有至少2 个图像。YTF 数据集包含从YouTube 获得的3 425 个视频。这些视频来自1 595 个身份,每个人平均有2.15 个视频。视频剪辑的帧数范围为48 到6 070,平均值为181.3 帧。此外,我们遵循标准实验协议,不受标记的外部数据的限制[30],以评估相关方法在给定的5 000 视频对上的性能。
表1 显示了不同方法在LFW 和YTF 上的识别率,我们可以从中观察到以下内容:
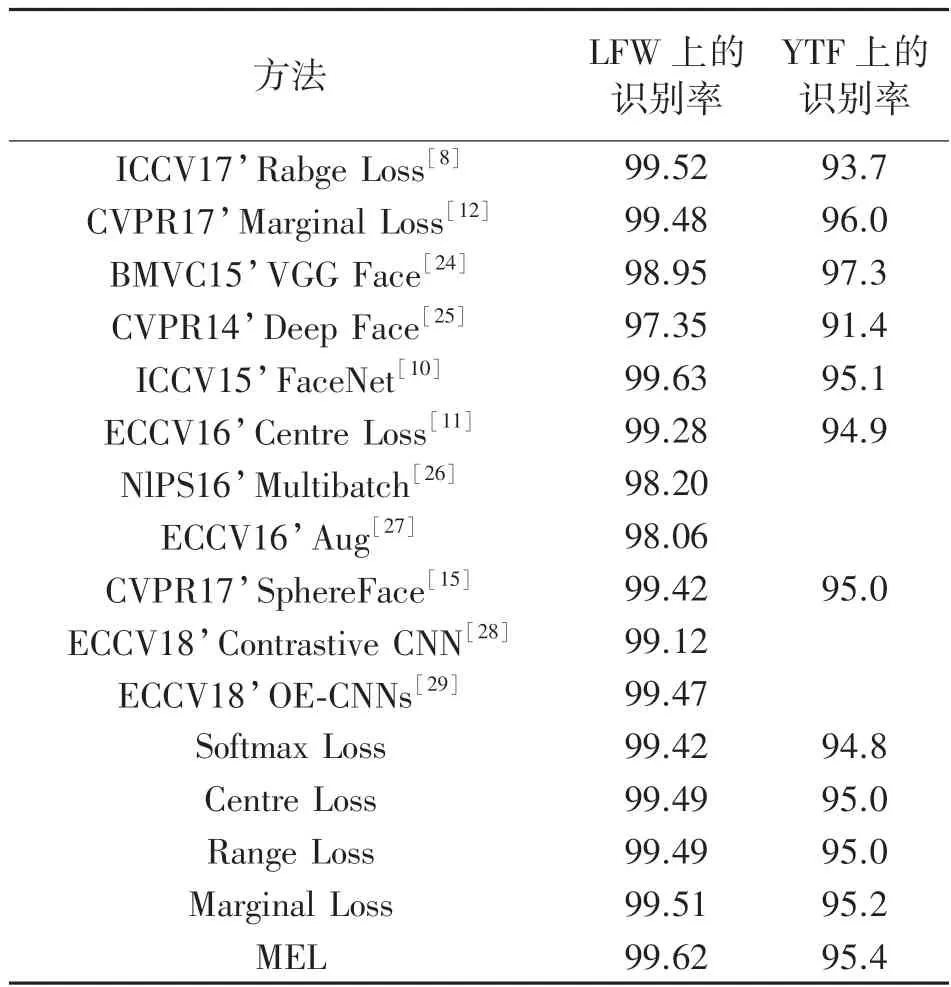
表1 LFW 和YTF 数据集的最新方法的识别率比较
(1)本文提出的MEL 优于Softmax Loss 和Center Loss,提高了LFW 和YTF 数据集的验证性能。在LFW 上,准确度从99.42%和99.49%提高到99.62%,而在YTF 上,准确度从94.8%和95.0%提高到95.4%。此外,MEL 在LFW 和YTF 数据集上都优于Range Loss 和Marginal Loss。在LFW 上,准确度从99.49%和99.51%提高到99.62%,而在YTF 上,准确度从95.0%和95.2%提高到95.4%。这证明了MEL 的有效性,也证明了Softmax Loss+Center Loss+MEL 组合的有效性。
(2)与现有技术方法相比,该方法对LFW 的精度为99.62%,对YTF 的精度为95.4%,高于大多数方法。
3 总结
本文提出了一个新的损失函数,最小边际损失(MEL)来指导深度神经网络学习高度辨别性的面部特征。MEL 第一个考虑在不同类别之间设置最小余量的损失。本文证明了所提出的损失函数在CNN 中很容易实现,本文的CNN 模型可以通过标准SGD 直接优化。本文对常用的公共可用数据集进行了大量实验。本文将MEL 与过去几年在顶级会议和期刊上发布的方法进行比较。本文还直接将MEL 与相同框架下的相关损失函数进行比较。结果表明MEL 具有最先进的性能。
猜你喜欢
建材发展导向(2021年19期)2021-12-06
数学小灵通·3-4年级(2021年5期)2021-07-16
锦绣·上旬刊(2020年10期)2020-12-14
临床骨科杂志(2020年1期)2020-12-12
天津经济(2020年7期)2020-08-20
今日农业(2019年15期)2019-01-03
消费导刊(2018年8期)2018-05-25
探测与控制学报(2015年4期)2015-12-15
共产党员(辽宁)(2015年2期)2015-12-06
读者·校园版(2015年19期)2015-05-14
