
基于像素级估计的视频显著性检测
2022-06-15 12:50李春华郝娜娜刘玉坤白玉华
河北工业科技 2022年3期
李春华 郝娜娜 刘玉坤 白玉华









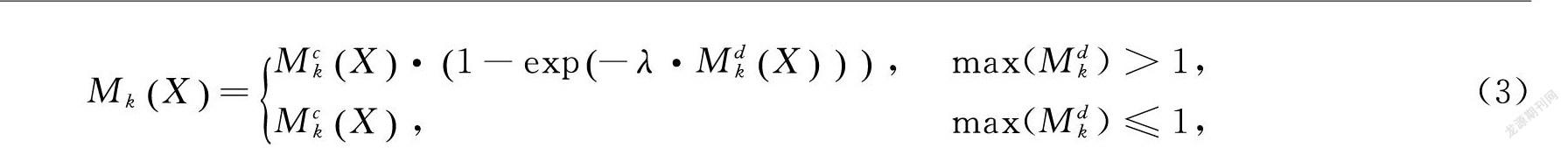

摘 要:为了减少背景噪声干扰,准确地从复杂视频中提取显著目标,提出一种具有时空一致性的视频显著区域检测算法。将视频帧划分为超像素,以超像素为基本单元提取光流特征,在时空一致性原则指导下动态融合颜色、边界信息和光流特征,获取视频显著图。在此基础上,借助视频帧的细节和区域特征对视频显著图进行细化增强。实验结果表明,算法的准确率召回率曲线在复杂图像数据库中高于传统经典算法,具有足够高的鲁棒性,能够减少相機运动和背景运动以及突变情况对跟踪检测的影响。所提方法能够在各种运动模式下和外观复杂场景中较为完整地提取显著目标,可作为预处理技术,改善目标跟踪、行为检测、视频压缩等的性能。
关键词:计算机图像处理;光流梯度;运动显著图;前景显著性估计;像素级显著性估计
中图分类号:TP391 文献标识码:A
DOI: 10.7535/hbgykj.2022yx03003
Video saliency detection based on pixel-level estimation
LI Chunhua,HAO Nana,LIU Yukun,BAI Yuhua
(School of Information Science and Engineering,Hebei University of Science and Technology,Shijiazhuang,Hebei 050018,China)
Abstract:In order to reduce the interference of background noise and accurately extract salient targets from complex videos,the design combined the optical flow characteristics generated by foreground motion in the video with superpixel estimation to detect salient targets in the video.Firstly,the video frame was segmented by super-pixel,and the motion saliency map was generated by combining the intra-frame color,boundary information and the optical flow gradient of inter-frame motion variation.This method has sufficient robustness to extract the foreground objects with various motion patterns and complex appearance scenes.Then,considering the details and regional features of the video frame,the pixel-level saliency map was formed by using the background and foreground saliency estimation of the super-pixel.These clues enhance the refinement of saliency.Finally,the motion saliency map and the pixel level saliency map were dynamically fused by spatiotemporal consistency.The experimental results show that the accuracy-recall rate curve of the algorithm is higher than that of the traditional classical algorithm in complex image databases.The designed video detection algorithm can be used as the processing plug-in of target tracking to reduce the influence of camera motion,background motion and mutation on tracking detection.
Keywords:
computer image processing;optical flow gradient;motion sketch;foreground visibility estimation;pixel level saliency estimation
视觉系统能够迅速捕捉到视野中的重要对象,这种认知过程使得人类可以实时解读复杂场景。显著性检测技术模仿人类这一视觉机能,预测观察者可能注视的场景区域。近年来,显著性检测广泛应用于目标检测和识别[1-2]、行为检测[3]和图像或视频压缩[4-5]中,成为计算机视觉的研究热点。根据人类视觉系统的注意机制,显著区域的检测可分为两类:一类自上而下[6-7],与任务控制处理相关,由高级认知任务驱动,使用图像高级别特征来计算显著区域,如利用人脸检测模型或局部对称预测人体固定点的位置;另一类自下而上[8],利用底层特征如颜色特征、纹理特征和空间距离等来构造视觉显著图。相对而言,自下而上的视觉注意机制更加简单易行,便于推广应用。
作为一项开创性的工作,ITTI等[9]基于生物学上的视觉注意结构和特征整合理论提出了一个众所周知的显著性检测模型。该模型首先使用不同尺度的中心环绕算子计算亮度、颜色和方向特征图,然后进行归一化求和生成显著性图,该显著性模型分别标注出亮度、颜色和方向特征中与其周围区域具有高对比度的区域。ZHU等[10]利用初始先验的思想级联中心先验、暗道先验获得图像的显著性值,但对于待检测视频中包含快速变化、复杂背景或运动方向变化不定时,检测性能不尽人意。李春华等[11]使用超像素先验条件,借助三维凸包定位显著目标区域,得到更加准确的显著图。
与图像显著性相比,提取动态场景中显著目标的算法较少,这主要是因为时间维度增加了检测难度。视频序列中目标运动模式多样、场景复杂多变、存在相机运动,使得视频显著性检测具有挑战性。现有的视频显著性检测算法大多只是简单地将运动特征添加到图像显著性模型中,计算运动显著概率[12-13]。这些方法通常忽略了视频显著性应当具有时空一致性的约束,即前景或背景区域的显著性值不应当沿着时间轴显著变化。
针对现有视频显著性检测算法存在时空不一致的问题,本文将颜色和边界信息与光流梯度结合识别视频显著目标,以运动映射图的形式将每帧图像显著目标的像素级特征动态结合,提取显著性区域。实验结果表明,加入颜色和边界信息的光流梯度可以有效减少相机运动以及背景运动造成显著对象定位不准确的问题。
1 算法描述
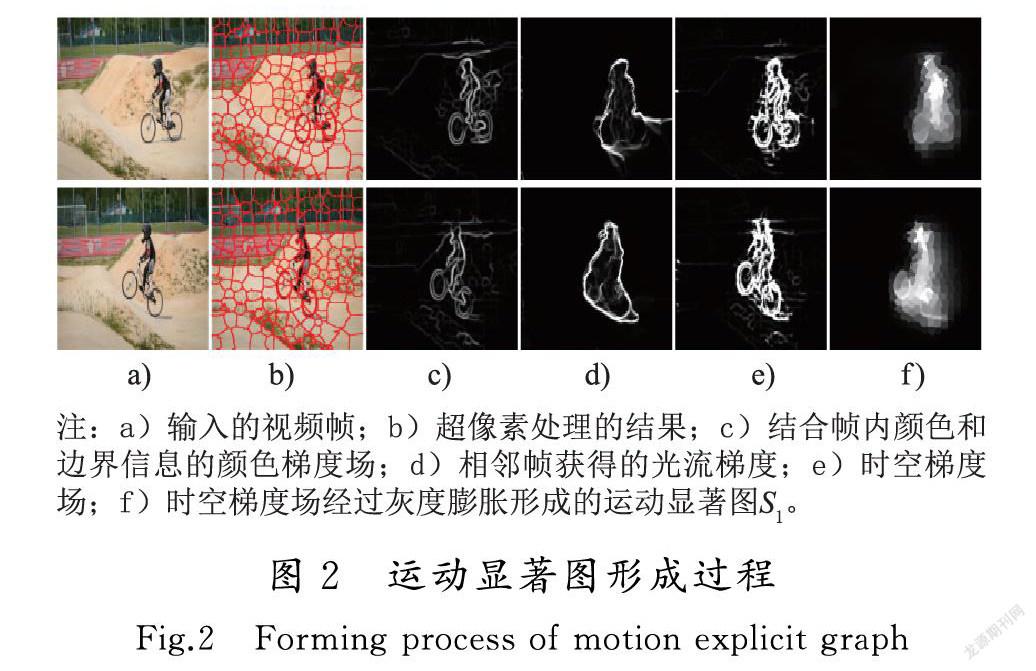
本文提出的算法包括运动显著图、像素级显著性估计以及显著图融合3部分。算法的实现过程如图1所示。首先在超像素分割的基础上利用光流梯度特征初步获取当前帧与前一帧的运动变化,结合帧内颜色和边界信息将其转化为运动显著图;利用视频帧的细节特征,对每一帧进行像素级显著性估计;最后,将获得的运动映射图与显著性估计动态加权融合得到最后的时空显著图。
1.1 运动显著图
光流梯度方法利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧和当前帧之间的对应关系,从而计算出相邻帧之间物体的运动信息。由于运动梯度比运动显著线索更可靠[14],本文通过运动梯度与颜色梯度结合生成时空梯度来计算运动显著图。
輸入一个视频序列I=I1,I2,…,In,使用线性迭代聚类 (simple linear iterative clustering,SLIC)[15]分割每帧的超像素,保留视频内容的初始结构元素。边界和不连续性揭示了视频帧的重要内容,它们作为超像素之间的边界,被保留下来。令第k帧Ik的超像素集为Pk=Pk,1,Pk,2,…,对各超像素计算X=x,y处的颜色梯度值:
MckX=SymbolQC@I′kX,(1)
式中I′k是帧Ik的超像素抽象模型。
令Ik的光流场为ck,通过相邻帧之间的光流变化量,利用大位移运动估计法[16]计算Ik帧的光流梯度:
MdkX=SymbolQC@ckX。(2)
将得到的颜色梯度值和光流梯度值整合到帧Ik的时空梯度场Mk中:
MkX=MckX·1-exp-λ·MdkX, max(Mdk)>1,MckX, max(Mdk)≤1,(3)
式中:λ是指数函数的比例因子,根据经验令λ=1;当max(Mdk)≤1时,光流梯度值可以忽略不计,时空梯度场中只有颜色梯度参与计算,场景几乎静止不动;当maxMdk>1时,光流算法对于运动目标具有极强的分辨能力。因此光流梯度特征显著图较为准确地指出视频中的显著目标区域。
对于视频帧的每个像素,利用时空梯度场上、下、左、右4个方向的梯度流值最小的像素流值作为运动显著梯度流,对最小的像素梯度值大于0.2的前景进行灰度膨胀,区分出视频帧的显著目标,作为视频的运动显著图S1。
由于光流显著图包含了视频帧中所有的运动变化量,所以将颜色、边界信息与光流梯度特征结合,可以有效去除背景运动、相机运动以及突变情况造成的影响,提高检测结果的准确性。
运动显著图形成过程如图2所示。
1.2 像素级显著性估计
在上节边界检测中没有考虑图像细节特征,所以需要进行帧内显著性估计,将图像的细节特征体现出来。文献[17]利用边界信息从图像超像素中收集背景种子,从背景显著图中选择前景种子,计算出前景显著图,然后将背景显著图和前景显著图统一映射,这种算法在复杂背景以及前景不显著的情况下,检测效果仍然不佳。文献[18]侧重背景区域分割,将前景种子集进行流行排序,通过4个方向的显著图映射得到了良好的效果。但是这种方式不宜用于视频显著性检测。为解决上述难题,本文采用前景种子随机游走排序算法。首先通过去除错误边界来优化图像边界,并通过背景查询生成显著性估计概率;然后,通过背景估计的互补值生成前景显著性估计概率;最后,从前景显著性估计中提取种子作为参考,并使用文献[19]所提出的正则化随机游走排序算法计算像素级显著图。
1.2.1 背景显著性估计
对于输入视频帧序列,如果一个超像素与背景种子具有较大的颜色差异,那么它更有可能成为显著对象。另一方面,背景种子对距离较近的超像素贡献较大,而对距离较远的超像素贡献较小。因此,利用空间加权的颜色对比度来估计基于背景的显著性,将背景种子集表示为BG,所以Ik帧中第i个超像素的显著性:
Sbi=∑n≠i,n∈BGd(ai,an)(1-d(bi,bn)/θ),(4)
式中:dai,an和dbi,bn分别为背景种子集BG中第i个超像素和第n个超像素的颜色和空间距离的欧几里得的归一化值;θ为调节因子,用于调节颜色和空间距离的重要性。为了避免有些超像素出现零自相似性,通过式(5)重新计算所有基于边界背景的显著性估计概率:
S-bi=1BG(Sbi+1BG-1∑m∈BGδ(m,i)Sbm),(5)
δ(m,i)=1, m=i,0, m≠i,(6)
式中:BG为背景种子集的数值表示;Sbm为第m个超像素的背景显著图。
1.2.2 前景显著性估计
首先使用自适应阈值算法对背景的显著图进行二值化,然后选择基于背景的显著值大于阈值的超像素来组成前景种子集。使用自适应阈值生成的前景种子比使用固定阈值生成的前景种子更准确和可靠,因为显著性值的范围在不同图像中是变化不定的。前景种子为前景显著图计算提供了足够的对象信息,如图3 c)所示,其中非前景种子被遮蔽。
用前景种子计算每个超像素的空间颜色相似度,来描述超像素的前景显著性:
Sfi=∑n≠i,n∈FGβd(ai,an)+d(bi,bn),(7)
式中:dai,an和dbi,bn分别为前景种子集FG中第i个超像素和第n个超像素的颜色和空间距离的欧几里得表示;β和是用于平衡颜色和位置距离之间重要性。图3 d)示出了一些前景显著图,从中可以看出,由于背景噪声与所选前景种子形成强烈对比,背景的显著图中的背景噪声被较好抑制。尽管如此,还是有一些失败的案例。例如,在图3 d)的底部行中,背景显著图中错误地将一些背景区域检测为显著对象,导致前景种子将噪声引入前景显著图中。
1.2.3 像素级显著性估计
重启随机游走是基于过去的表现,无法预测将来的发展步骤和方向[13]。正则化随机行走排序显著优于随机游走,本节使用它优化前面获取的显著性图。将1.2.1节和1.2.2节获得的背景种子和前景种子整合到PkM中。当k=1时,对应背景种子集BG;当k=2时,对应前景种子集FG。k=2的情况下,将前景种子集作为参考,利用随机游走算法重新排序,获得优化的前景显著图,即像素级显著图S2,其尺寸与输入图像的尺寸一致。如图3 e)所示。
1.3 时空显著图
通过光流梯度特征和背景、前景显著性估计,分别获得了运动显著图和超像素级显著图。基于光流梯度特征的显著图能够更加准确地突出视频中运动变化,而基于背景、前景的像素级显著性估计能够更好地抑制背景噪声,突出显著目标的细节特征。因此,采用了一种动态集成机制区域,综合利用光流和背景前景信息,如式(8)和式(9)所示:
S=ρ×S1+(1-ρ)×S2,(8)
ρ=mean(S1×S2)mean(S1×S2)+mean(S1+S2)/2,(9)
式中:S1,S2分别表示运动显著图和像素级显著图;ρ为空间显著性的权重,由时间显著性的散度来决定。当运动目标较小或运动区域较集中时,应减小ρ值,从而增加时间显著性的权重。当运动目标分散时,增加空间显著性的权重。通过这种方法可以得到更真实的时空显著图。
2 实验结果分析
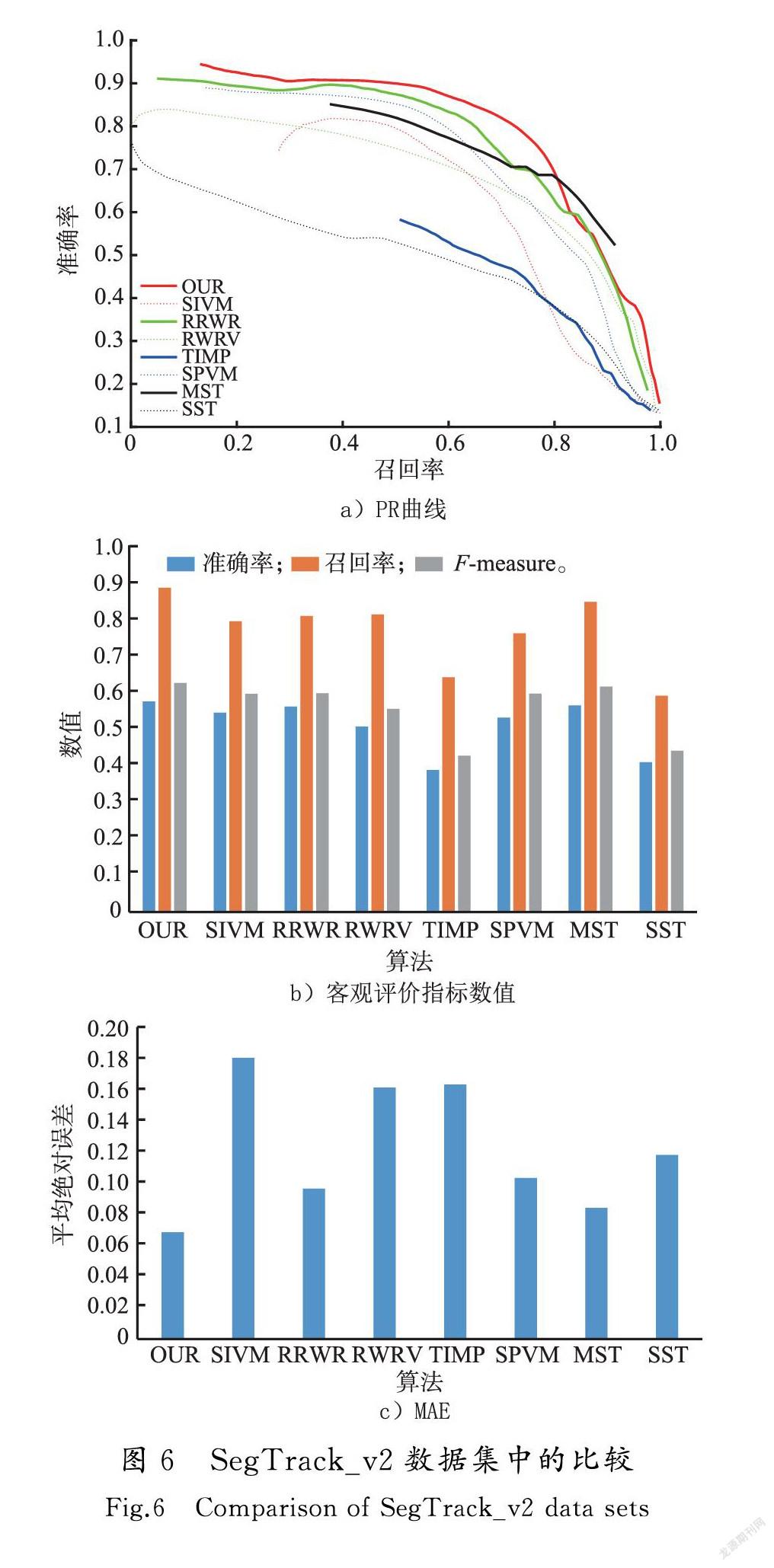
将本节算法与现有7种经典流行算法进行比较,7种经典算法分别为MST算法[20]、SIVM算法[21]、SST算法[22]、TIMP算法[23]、SPVM算法[24]、RWRV算法[13]、RRWR算法[19],在SegTrack_v2[25]和DAVIS[26]两大公开数据集中进行测试。在本次测试对比中,采用主观效果比较和客观指标比较。
2.1 主观效果比较
本节将各种经典算法与本章算法在视觉主观方面进行比较,图4表示传统经典算法和本文算法在SegTrack_v2数据库和DAVIS数据库中的测试结果。从图4中可以看出,本文算法可以完整、准确地显示显著区域,保持清晰的目标边界,还能够有效抑制背景噪声。
图4中GT为真实检测,结果从图4中可以看出,MST算法能检测出简单背景视频中的目标区域,但当背景杂乱时,背景噪声没有被充分抑制消除且与前景对比度低,检测效果不理想,如图4中的soccerball,girl,原因在于MST算法是在频域范围内进行的显著性定义,当处理复杂背景时,容易将高频部分的噪声区域误判定为前景区域,使得检测效果不佳;SST算法不管是处理目标突出的视频还是背景复杂的视频检测效果都不好;SIVM算法能够检测出前景区域,但在抑制背景噪声方面的性能较差;TIMP算法虽然能将前景目标都完整地检测出,但是仍然会有背景噪声影响,并且检测物不明亮会造成目标细节缺失;SPVM算法相较与TIMP算法更好地抑制背景噪聲,但是在背景模糊的情况下,如图4 frog中牺牲了前景细节,且把soccerball中的部分目标当成背景抑制掉了;RWRV算法基于重启随机游走算法,运用运动独特性、时间一致性以及突变特征找到时间显著性和运动显著性,然后将两者结合找出运动目标的转移概率,为下一帧做映射,从而进行迭代计算显著性,虽然这种方法考虑了视频检测的时空一致性,但是在抑制背景噪声方面还有待提高;RRWR算法基于正则化随机游走排序算法,该方法在前景种子基础上对超像素进行排序,达到了较好的效果,但是由于超像素分割不精确,也会出现检测结果不理想的情况,如图4 girl,本文算法(OUR算法)针对以上检测方法的不足,提出了基于光流梯度特征和像素级估计算法,本文算法的检测结果能够较好地抑制背景噪声,完整地检测出显著区域,整体性能优于对比算法。
虽然本文算法能够对大部分视频中的显著区域完整检测出,但当目标对象出现在图像边缘附近或者目标区域颜色接近背景区域时,检测结果不尽人意。图5为本文算法的部分失败案例。原因在于当图像中目标所占的比例过于低和当目标区域颜色接近背景区域时,构建的像素级显著估计不能完整地将显著区域包裹在内,图像的检测结果不够完整,准确度降低。
2.2 定量实验分析
为了避免仅凭主观效果评价显著图算法的局限性,本节算法分别在SegTrack_v2和DAVIS数据集中进行测试,并采用准确率-召回率(precision-recall,PR曲线)、F-measure值和平均绝对误差(MAE)来定量分析算法的性能。准确率表示的是得到的显著图中正确区域所占的比例,召回率表示的是显著图与图集中的真值图相对应的正确区域的比例。PR曲线的初始值越高,随着召回率的增大曲线越平稳则表明算法检测效果越佳。F-measure测量值用来评价算法的总体性能。
precision=∑Gt(x,y)×S(x,y)∑S(x,y),(10)
recall=∑Gt(x,y)×S(x,y)∑Gt(x,y),(11)
F-maesure=(1+β2)precision×recallβ2×precision+recall,(12)
式中:Gt(x,y)表示Ground Truth圖;S(x,y)为显著图,根据经验β2=0.3。
平均绝对误差(MAE)表示二值图与真值图的接近程度,数值越小,两种图像越接近算法性能越好。它被定义为
MAE=1W×H∑Wx=1∑Hy=1S(x,y)-G(x,y)。(13)
在SegTrack_v2数据集上选用6个不同场景的视频段(bmx,frog,cheetah,soldier,girl和monkey),包含222张300×300的视频帧参与测试。如图6所示为样本测试的PR曲线、客观评价指标数值和MAE值。由图6 a)可以看到本文算法的PR曲线略高于RRWR,SPVM,SIVM等算法的曲线,说明在相同召回率的情况下,本文算法准确率的值高于其他算法,本文算法提取到的显著区域更加准确。随着召回率的增加,分割阈值逐渐减小,使得更多区域被判断为显著区域,所以各个算法对应的准确率下降,唯独MST算法的准确率比本章算法稍高一点。图6 b)表示在自适应阈值下得到的各项指标数值,可以看出本文算法的综合指标F-measure值最高。由图6 c)可以看出本文算法的错误率最低,说明准确率更高。
在DAVIS数据集上选用6个不同场景的视频段(kite-surf,bus,car-turn,bmx-bumps,hike和soccerball),包含420张300×300的视频帧参与测试。如图7所示为样本数据得到测试的PR曲线和指标数值。图7 a)可以看出PR曲线在召回率比较小时,本文算法比其他算法性能好。但是随着召回率升高,本文算法和RWRV算法性能接近,表明在图像数据复杂度变高时,这两种算法检测效果具有稳定性。在对比结果评价指标方面,可以看出precision值高于其他算法,有相对较高的查准率,综合评价指标F-measure值最高,MAE值最低。综合两种结果表明本文算法在该数据集中有良好的表现,性能有所提升。
3 结 语
提出了一种像素级视频显著性检测算法,将光流显著图与像素级显著图动态结合进行时空一致化处理,获得了较为准确、完整的视频显著性图。首先,运动光流梯度特征联合颜色和边界信息准确定位视频中显著目标,为检测结果的准确性提供了基础;其次,将背景种子、前景种子作为参考,进行帧内像素级估计,为检测结果的完整性提供了保障;最后,运动显著图和像素级显著图动态融合,分情况考虑视频内容,使本文算法更具有普遍性。在公开数据集SegTrack_v2和DAVIS数据库中的测试实验结果,反映了本文算法的客观评价指标PR曲线和F-measure值优于传统算法,其中F-measure值在2个数据集中分别为0.631和0.679。本文算法利用加入边界和颜色因素的光流梯度特征能够较好地解决传统视频检测模型中前景提取效果差的问题,充分突出了改进光流和动态融合方式的时空一致性优势。但是,当目标对象出现在边缘附近或者目标区域颜色接近背景区域时,检测结果不理想。接下来将就当目标物出现在边缘以及目标区域与背景区域颜色接近的视频中时,如何提高显著区域检测结果的准确性继续开展深入研究。
参考文献/References:
[1] SULTAN S,JENSEN C D.Metadata based need-to-know view in large-scale video surveillance systems[J].Computers & Security,2021,111:102452.
[2] 薛培林,吴愿,殷国栋,等.基于信息融合的城市自主车辆实时目标识别[J].机械工程学报,2020,56(12):165-173.
XUE Peilin,WU Yuan,YIN Guodong,et al.Real-time target recognition for urban autonomous vehicles based on information fusion[J].Journal of Mechanical Engineering,2020,56(12):165-173.
[3] LAHOULI I,KARAKASIS E,HAELTERMAN R,et al.Hot spot method for pedestrian detection using saliency maps,discrete Chebyshev moments and support vector machine[J].IET Image Processing,2018,12(7):1284-1291.
[4] ZHENG Bowen,ZHANG Jianping,SUN Guiling,et al.Fully learnable model for task-driven image compressed sensing[J].Sensors,2021,21(14):4662.
[5] REKHA B,KUMAR R,SCIENCE C.High quality video assessment using salient features[J].ndonesian Journal of Electrical Engineering,2017,7(3):767-772.
[6] MARCHESOTTI L,CIFARELLI C,CSURKA G.A framework for visual saliency detection with applications to image thumbnailing[C]//2009 IEEE 12th International Conference on Computer Vision.Kyoto:IEEE,2009:2232-2239.
[7] KANAN C,TONG M H,ZHANG Lingyun,et al.SUN:Top-down saliency using natural statistics[J].Visual Cognition,2009,17(6/7):979-1003.
[8] CHENG Mingming,MITRA N J,HUANG Xiaolei,et al.Global contrast based salient region detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(3):569-582.
[9] ITTI L,KOCH C,NIEBUR E.A model of saliency-based visual attention for rapid scene analysis[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1998,20(11):1254-1259.
[10]ZHU Chunbiao,LI Ge,WANG Wenmin,et al.An innovative salient object detection using center-dark channel prior[C]//2017 IEEE International Conference on Computer Vision Workshops (ICCVW).Venice:IEEE,2017:1509-1515.
[11]李春華,秦云凡,刘玉坤.改进凸包的贝叶斯模型显著性检测算法[J].河北科技大学学报,2021,42(1):30-37.
LI Chunhua,QIN Yunfan,LIU Yukun.Bayesian model saliency detection algorithm based on improved convex hull[J].Journal of Hebei University of Science and Technology,2021,42(1):30-37.
[12]XI Tao,ZHAO Wei,WANG Han,et al.Salient object detection with spatiotemporal background priors for video[J].IEEE Transactions on Image Processing,2017,26(7):3425-3436.
[13]KIM H,KIM Y,SIM J Y,et al.Spatiotemporal saliency detection for video sequences based on random walk with restart[J].IEEE Transactions on Image Processing,2015,24(8):2552-2564.
[14]WANG Wenguan,SHEN Jianbing,SHAO Ling.Consistent video saliency using local gradient flow optimization and global refinement[J].IEEE Transactions on Image Processing,2015,24(11):4185-4196.
[15]ACHANTA R,SHAJI A,SMITH K,et al.SLIC superpixels compared to state-of-the-art superpixel methods[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(11):2274-2282.
[16]CHEN Jun,CAI Zemin,LAI Jianhuang,et al.Efficient segmentation-based patchmatch for large displacement optical flow estimation[J].IEEE Transactions on Circuits and Systems for Video Technology,2019,29(12):3595-3607.
[17]WANG Jianpeng,LU Huchuan,LI Xiaohui,et al.Saliency detection via background and foreground seed selection[J].Neurocomputing,2015,152:359-368.
[18]YANG Chuan,ZHANG Lihe,LU Huchuan,et al.Saliency detection via graph-based manifold ranking[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition.Portland:IEEE,2013:3166-3173.
[19]LI Changyang,YUAN Yuchen,CAI Weidong,et al.Robust saliency detection via regularized random walks ranking[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Boston:IEEE,2015:2710-2717.
[20]TU W C,HE Shengfeng,YANG Qingxiong,et al.Real-time salient object detection with a minimum spanning tree[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:2334-2342.
[21]RAHTU E,KANNALA J,SALO M,et al.Segmenting Salient Objects from Images and Videos[M].Heidelberg:Springer,2010:366-379.
[22]SEO H J,MILANFAR P.Static and space-time visual saliency detection by self-resemblance[J].Journal of Vision,2009,9(12):15.1-27.
[23]ZHOU Feng,KANG S B,COHEN M F.Time-mapping using space-time saliency[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:3358-3365.
[24]LIU Zhi,ZHANG Xiang,LUO Shuhua,et al.Superpixel-based spatiotemporal saliency detection[J].IEEE Transactions on Circuits and Systems for Video Technology,2014,24(9):1522-1540.
[25]PERAZZI F,PONT-TUSET J,MCWILLIAMS B,et al.A benchmark dataset and evaluation methodology for video object segmentation[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:724-732.
[26]LI Fuxin,KIM T,HUMAYUN A,et al.Video segmentation by tracking many figure-ground segments[C]//2013 IEEE International Conference on Computer Vision.Sydney:IEEE,2013:2192-2199.
